从现在开始就开始用ubuntu和vscode了
先大概说一下Centos和ubutun,自己碰到的一些会用到的不同点
1.Ubuntu 默认 root 是 "锁定(禁用密码)" 状态,不能直接 su - root 登录;要sudo passwd root 给 root 设密码,就解锁了。CentOS 默认 root 有密码,可以直接 su - 切 root。
2.**Ubuntu 系统里自带的那个 ubuntu 用户 = 特权用户(有 sudo 权限)你自己新建的普通用户 = 普通用户(默认没 sudo 权限,要自己提权:**sudo usermod -aG sudo 你的用户名,)
3.包管理器
ubutun:sudo apt install 软件名
centos:sudo yum install 软件名
进程通信
为什么要进行进程间通信
• 数据传输:一个进程需要将它的数据发送给另⼀个进程
• 资源共享:多个进程之间共享同样的资源。
• 通知事件:一个进程需要向另⼀个或⼀组进程发送消息,通知它(它们)发生了某种事件(如进 程终止时要通知父进程)。
• 进程控制:有些进程希望完全控制另⼀个进程的执行(如Debug进程),此时控制进程希望能够 拦截另⼀个进程的所有陷⼊和异常,并能够及时知道它的状态改变。
怎么通信
通信的本质就是先让不同的进程先看到同一份资源("内存"),然后再有通信的条件

管道
什么是管道
• 管道是Unix中最古老的进程间通信的形式。
• 我们把从⼀个进程连接到另⼀个进程的⼀个数据流称为⼀个"管道"
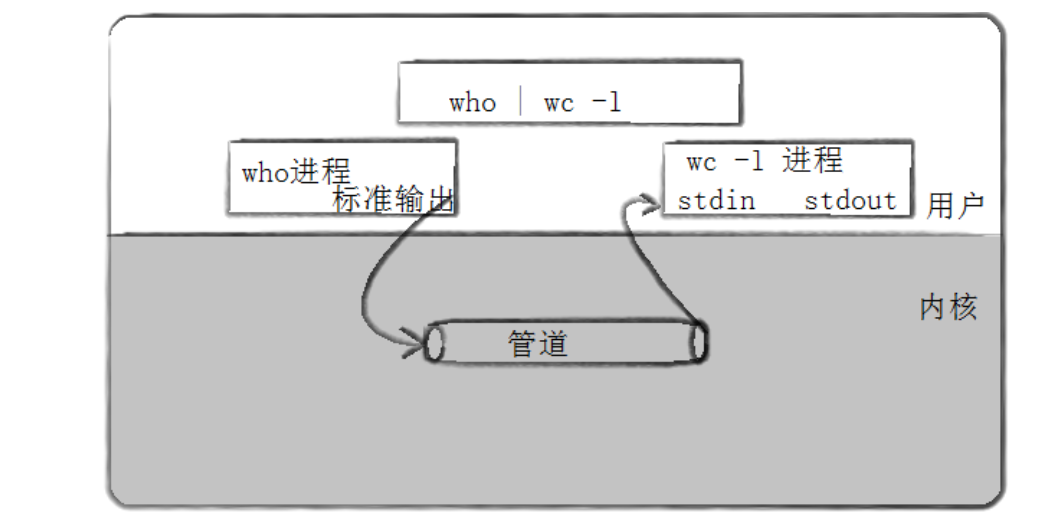
匿名管道
以两张图来理解,通过匿名管道来理解进程通信
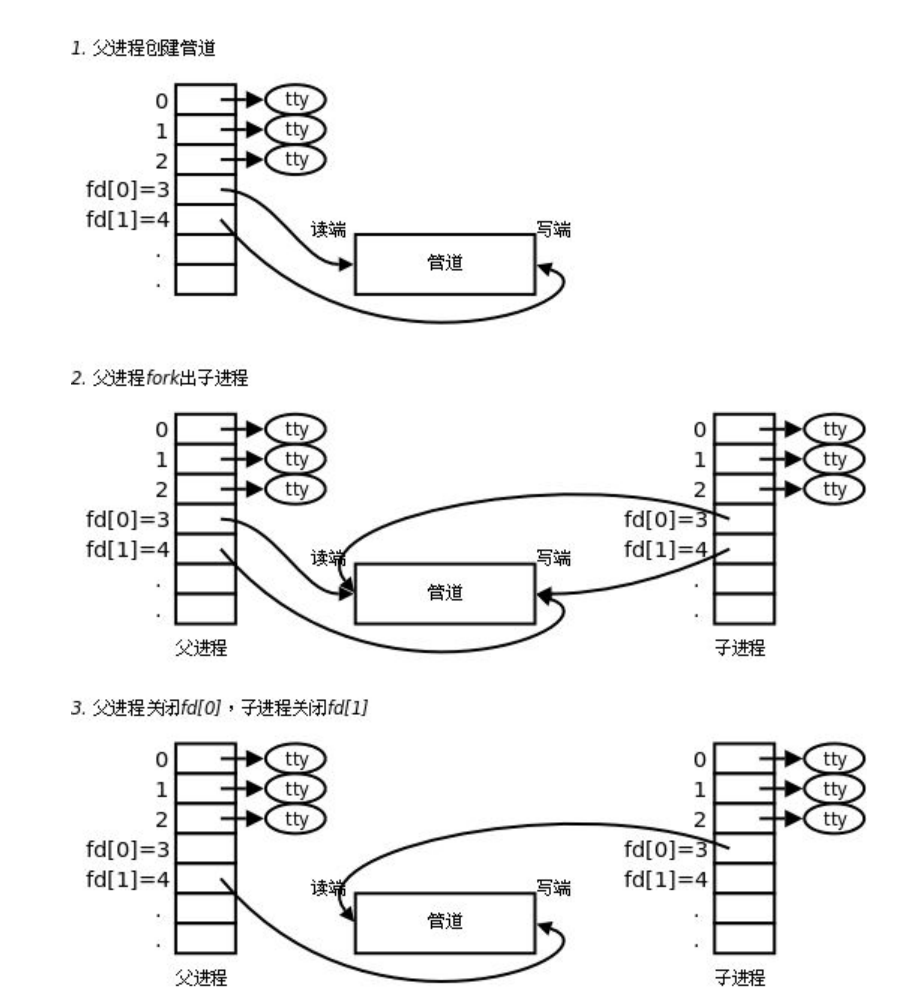
1.父进程调用pipe()创建管道
- 内核会创建一个匿名管道(内存缓冲区),它**没有文件路径、没有文件名,只存在于内核内存中,**不会在磁盘上创建任何文件
- 管道天生区分读端和写端:
pipefd[0]绑定读端,pipefd[1]绑定写端。 - 父进程的文件描述符表中,
fd=3指向管道读端,fd=4指向管道写端。
2.父进程调用fork()创建子进程
- 子进程会完整拷贝父进程的文件描述符表,所以子进程也有
fd=3(读端)和fd=4(写端),且都指向同一个管道对象。 - 此时管道的引用计数变为 2,内核不会轻易释放这个缓冲区。
- 这一步就解决了 "怎么让两个进程打开同一个管道" 的问题:靠的就是
fork()的文件描述符继承机制。
3.父子进程关闭不用的一端,形成单向通信
- 父进程 :关闭读端
pipefd[0],只保留写端pipefd[1],负责往管道写数据。 - 子进程 :关闭写端
pipefd[1],只保留读端pipefd[0],负责从管道读数据。 - 此时管道就变成了一个单向通道:父进程写的数据,子进程可以直接读到,实现了父子进程间的单项通信。
1点细节:管道的 "复用代码" 设计,这就是 Linux "一切皆文件" 的体现:
- 管道和普通文件一样,都可以用
read()/write()系统调用来操作。 - 内核为管道单独设计了一套文件操作函数集(
struct file_operations),但用户态不需要关心,只需要像操作普通文件一样用系统调用即可。
补充一个小知识点:
size_t = unsigned long(64 位无符号)
-
32 位系统
int= 32 位ssize_t= 32 位→ 这时候可以混用
-
64 位系统(现在 99% 都是)
int= 32 位(永远不变)ssize_t= 64 位 (等于 signed long)→ 长度不一样!用 int 会截断、出错!
又Linux的系统调用(read,write等等)返回值很大,所以用ssizet_t(有<0情况,不用size_t,很大可能越int的界,不用int),
通过一个demo代码,来演示一下
#include <iostream>
#include <unistd.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include<string.h>
using namespace std;
void ChildWrite(int wfd)
{
char buffer[1024];
int cnt=0;
while(1)
{
snprintf(buffer,sizeof(buffer),"i am a child pid:%d,cnt:%d",getpid(),cnt++);
write(wfd,buffer,strlen(buffer));//默认strlen没有把"/0"写进去
sleep(1);
}
}
void FatherRead(int rfd)
{
char buffer[1024];
while(1)
{
buffer[0]=0;
ssize_t n=read(rfd,buffer,sizeof(buffer)-1);
if(n>0)
{
buffer[n]=0;
cout<<"child say"<<buffer<<endl;
}
}
}
int main()
{
// 1.创建管道
int fds[2] = {0}; // fds[0]:读端。fds[1]:写端
int n = pipe(fds);
if (n < 0)
{
cerr << "pipo error" << endl;
return 1;
}
cout << fds[0] << endl;
cout << fds[1] << endl;
pid_t id = fork();
if (id == 0)
{
// child
// f-r,c-w,child要写就把读端关掉
close(fds[0]);
ChildWrite(fds[1]);
close(fds[0]); // 为了代码的完整性,最后写完了也得关上写端
}
//f
close(fds[1]);
FatherRead(fds[0]);
waitpid(id,nullptr,0);
close(fds[0]);
return 0;
}5种特性
1.匿名管道通常用于有血缘关系的进程之间通信(父子或兄弟)
2.管道文件自带同步机制。写得慢,读就慢,写得快,读就快,即彼此读写会互相影响
3.管道是面向字节流的。(1)管道的 write 和 read 次数不要求一一对应 ,写 N 次的数据,可以被一次读完;写 1 次的数据,也可以被 N 次读完。(2)数据是连续的字节流,没有 "消息边界"读出来就是直接连续的一串,没有分界。
4.管道是单向通信的,属于"半双工"的特殊情况
半双工:任何一个时刻,一个发,一个收(像正常说话,一个说一个听)
全双工:任何一个时刻,可以同时发收(像吵架,双方都说)
而管道一旦创建了就不能更换发收的对象了,就是说你创建的时候是发的那就一直是发的,是收的那就一直是收的
5.普通文件(管道也是普通文件)的生命周期是随进程的。一个进程退出和相应的文件的引用计数就减一,为0时,OS就自动关闭这个文件了
4种通信情况
1.写慢,读快。此时读端在等写端,写数据到管道的缓冲区时(缓冲区为空),就会处于阻塞
2.写快,读慢。此时读得慢,当写满了的时候,就不能再写了,就要等读端把数据读出去,写端此时处于阻塞
3.写关了,读继续。如果管道的缓冲区还有内容就都读完后返回0,没有就直接返回0,表示读到文件尾
4.读关了,写继续。管道已经没有任何接收数据的一方,继续写入只会浪费资源没有任何意义。OS 向写进程发送 SIGPIPE 信号终止进程。代码实现验证:
void ChildWrite(int wfd)
{
char buffer[1024];
int cnt=0;
while(1)
{
snprintf(buffer,sizeof(buffer),"i am a child pid:%d,cnt:%d",getpid(),cnt++);
write(wfd,buffer,strlen(buffer));//默认strlen没有把"/0"写进去
sleep(1);
}
}
void FatherRead(int rfd)
{
char buffer[1024];
while(1)
{
buffer[0]=0;
ssize_t n=read(rfd,buffer,sizeof(buffer)-1);
if(n>0)
{
buffer[n]=0;
cout<<"child say"<<buffer<<endl;
}
else if(n==0)
{
cout<<"n :"<<n<<endl;
cout<<"child 退出,father也退出"<<endl;
break;
}
else{
break;
}
//读一次就直接break,结束Fatherread函数,进而执行close(fd[0]),关闭读端
break;
}
}
int main()
{
// 1.创建管道
int fds[2] = {0}; // fds[0]:读端。fds[1]:写端
int n = pipe(fds);
if (n < 0)
{
cerr << "pipo error" << endl;
return 1;
}
cout << fds[0] << endl;
cout << fds[1] << endl;
pid_t id = fork();
if (id == 0)
{
// child
// f-r,c-w,child要写就把读端关掉
close(fds[0]);
ChildWrite(fds[1]);
close(fds[0]); // 为了代码的完整性,最后写完了也得关上写端
}
//f
close(fds[1]);
FatherRead(fds[0]);
close(fds[0]);//放到等之前,读完就关
sleep(5);//在进程回收前sleep方便看到Z+僵尸状态
int status=0;
int ret= waitpid(id,&status,0);
if(ret>0)
{
printf("exit code:%d,exit signal:%d",(status>>8)&0xFF,status&0x7F);
sleep(5);//父进程先sleep5s,不直接退出,方便看状态码结果
}
return 0;
}运行结果:
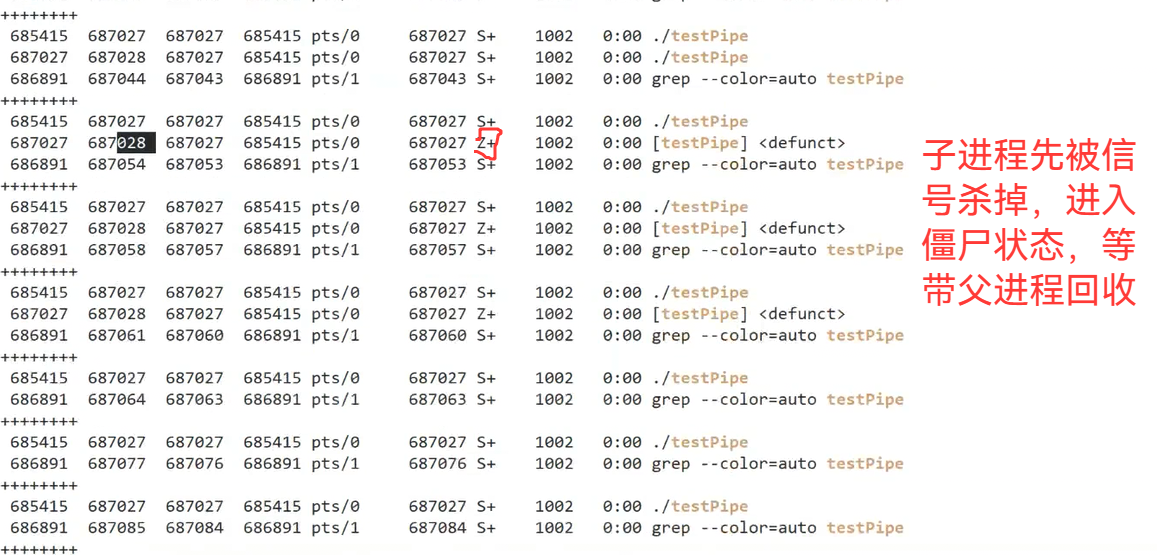
可以看到退出码为13:

管道的容量
Linux 中匿名管道的缓冲区大小通常是 65536 字节(64KB)。
原子写入

PIPE_BUF :POSIX 规定的原子写入阈值,在 Linux 上是 4096 字节。
即当单次写入的数据量 < PIPE_BUF(Linux 上是 4096 字节)时,写入操作是原子的。
就是说:多个进程同时往同一个管道写数据时,只要每次写的都小于 4096 字节,它们的数据不会互相穿插、混乱,操作系统会保证每次写入是一个完整的 "数据包"。
当单次写入的数据量 ≥ PIPE_BUF 时,写入就不是原子的了。 多个进程同时写的时候,数据可能会被操作系统 "拆分",导致不同进程的数据穿插在一起,出现 "混乱" 的情况。
eg:
进程 A 执行一次 write:AAA 进程 B 执行一次 write:BBB
合法(原子写入,无穿插) AAABBB / BBBAAA
绝对不会出现(穿插、拆分) AABAB / ABABB
进程池
1.池化技术
提前批量创建一批资源,统一管理、重复复用,不用每次用都「新建 + 销毁」,省时间、减开销
(池 = 资源池子(像游泳池,人反复进出,不用每次挖新池子)
优点:避免频繁创建销毁,提升运行效率。
进程池
场景:频繁创建子进程干活(如批量任务、管道读写)
- 普通方式:来一个任务
fork()一个子进程 → 干完exit销毁。 缺点:fork 开销大,频繁创建销毁很慢。 - 进程池: 程序启动 预先创建 N 个子进程 放在池里,一直待命。 来了任务直接分配给空闲子进程,任务结束子进程不退出,放回池继续待命。
和管道搭配:池内子进程统一通过管道 / 队列接收任务,不用反复创建进程 + 管道。
内存池
频繁 malloc /free 会产生内存碎片、效率低。 所以直接一次性申请一大块内存,内部切分复用,减少系统调用。
2.hpp
.hpp = 头文件 + 实现 合二为一
.hpp 文件里:声明、函数实现、类方法全部写在一起,不分文件。
因为 模板、内联函数、类内方法 天生不能拆分到 .cpp,所以可以采取这种方式
进程池代码实现
版本一
ProcessPool.hpp:
#pragma once
#include <iostream>
#include <unistd.h>
#include <stdio.h>
#include <sys/wait.h>
#include <vector>
#include "Task.hpp"
using namespace std;
// 先描述
class Channel
{
public:
Channel(int fd, pid_t id)
: _wfd(fd), _subid(id)
{
_name = "channel-" + to_string(_wfd) + "-" + to_string(_subid);
}
void Send(int code)
{
ssize_t n = write(_wfd, &code, sizeof(code));
(void)n;
}
void Close()
{
close(_wfd); // 这里写宏观上,后面在ChannelManager循环的方式调用这个函数,把每一个写端都关了
//为什么要这样关闭,后面通过循环把每一个写端都关了过后,等读完了过后就会break,进而技术work然后exit子进程退出
}
void Wait()
{
pid_t i = waitpid(_subid, nullptr, 0);
(void)i;
}
~Channel() {}
int Fd() { return _wfd; }
pid_t Subid() { return _subid; }
string Name() { return _name; }
private:
int _wfd;
pid_t _subid;
string _name;
};
const int gdefaultnum = 5;
// 再组织
class ChannelManager
{
public:
ChannelManager()
: _next(0)
{
}
Channel Seclet()
{
_next %= gdefaultnum;
return _channels[_next++];
}
void PrintChannel()
{
for (auto &channel : _channels)
{
cout << channel.Name() << endl;
}
}
void ChannelManagerwait()
{
for (auto &e : _channels)
{
e.Wait();
cout<<"回收"<<e.Name()<<endl;
}
}
void ChannelManagerClose()
{
for (auto &e : _channels)
{
e.Close();
cout<<"关闭"<<e.Name()<<endl;
}
}
~ChannelManager() {}
void Insert(int wfd, pid_t subid)
{
// Channel c(wfd,subid);
//_channels.push_back(c);这样写会有拷贝
// push_back:先创建对象,再拷贝 / 移动到容器里
// emplace_back:直接在容器内存里就地构造对象,无拷贝 / 无移动
_channels.emplace_back(wfd, subid);
}
private:
vector<Channel> _channels;
int _next;
};
class ProcessPool
{
public:
ProcessPool(int num)
: _process_num(num)
{
_tm.Register(PrintLog);//.hpp头文件+定义,所以可以找到PrintLog
_tm.Register(DownLoad);
_tm.Register(UpLoad);//不插入那么_task.size()就为0,Code()中返回code时就会直接模0,程序崩溃
}
void Work(int rfd)
{
int code = 0;
while (1)
{
ssize_t n = read(rfd, &code, sizeof(code)); // 每次规定只读4个字节,即正确读到父进程写的任务码
if (n > 0)
{
if (n != sizeof(code))
{
continue;
} // 没有正确读到就继续读
// 根据读到的任务码来work
printf("子进程[%d]收到一个任务码:%d\n", getpid(), code);
_tm.Excute(code);
}
else if (n == 0)
{
printf("读到文件结尾了,子进程退出\n");
break;
}
else
{
printf("读取失败");
break;
}
}
}
bool start()
{
for (int i = 0; i < _process_num; i++)
{
// 1.创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
return false;
// 2.创建子进程
pid_t subid = fork();
if (subid < 0)
return false;
else if (subid == 0)
{
// 子进程
// 3.关闭不要的文件描述符
close(pipefd[1]); // 子进程读
Work(pipefd[0]);
close(pipefd[0]);
exit(0);
}
else
{
// 父进程
// 3.关闭不要的文件描述符
close(pipefd[0]);
_cm.Insert(pipefd[1], subid); // 以子进程的pid和父进程写端文件描述符pipedfd[1],构建一条父进程-管道-子进程关系即
// 通信信道,循环多次就构建多条这样的关系即多个通信信道
}
}
return true;
}
void Run()
{
// 1.选一个信道
Channel c = _cm.Seclet();
cout<<"选择了一个子进程:"<<c.Name()<<endl;
// 2.派发任务
int taskcode = _tm.Code();
c.Send(taskcode);
cout<<"发送了一个任务码:"<<taskcode<<endl;
}
void Stop()
{
_cm.ChannelManagerClose();
_cm.ChannelManagerwait();
}
private:
ChannelManager _cm;
int _process_num;
TaskManager _tm;
};#include"ProcessPool.hpp"
#include<unistd.h>//这里还要再写一次#include<unistd.h>因为ProcessPool写了progma once
int main()
{
ProcessPool pp(gdefaultnum);
pp.start();
int cnt=10;
while(cnt--)
{
pp.Run();
sleep(1);
}
pp.Stop();
//说一下大概流程,先start会创建管道和子进程,然后子进程work(),父进程Insert(),子进程的work()里面read因为写端还没有写就会
//阻塞等待,等到Run()时就会选择一个信道和send()任务码(即write任务码)等到子进程read后>0且==4就会Excute()执行任务,
//最后Stop()先全部关闭w端后,如果管道缓冲区还有就读完后break没有就直接break反正就结束Work()然后exit子进程退出,最后再Stop()
//里面的ChannelManagerWait()回收子进程
return 0;
}Task.hpp:
#pragma once
#include <cstdio>
#include<iostream>
#include <unistd.h>
#include <vector>
#include <ctime>
#include<cstdlib>
using namespace std;
typedef void (*task_t)();
void DownLoad()
{
printf("我是一个下载的任务\n");
}
void PrintLog()
{
printf("我是一个打印日志的任务\n");
}
void UpLoad()
{
printf("我是一个上传的任务\n");
}
class TaskManager
{
public:
TaskManager()
{
srand(time(nullptr));
}
void Register(task_t t)
{
_tasks.push_back(t);
}
int Code()
{
return rand() % _tasks.size();
}
void Excute(int code)
{
if (code > 0 && code < _tasks.size())
{
_tasks[code]();
}
}
~TaskManager()
{}
private:
std::vector<task_t> _tasks;
};Makefile:
process_pool:Main.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f process_pool运行结果:
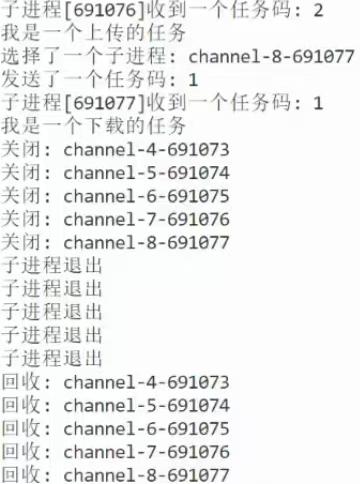
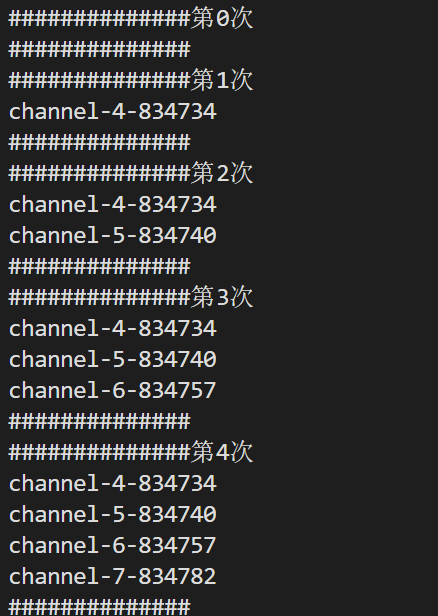
2
但版本一有一个隐藏得很深的bug
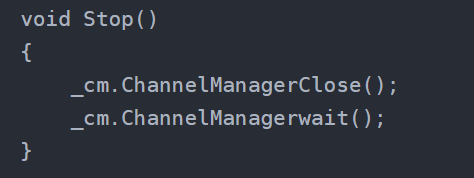
这是我们版本一写的,即先全部关掉写端后,再全部回收
但如果改成关掉一个再回收一个呢?
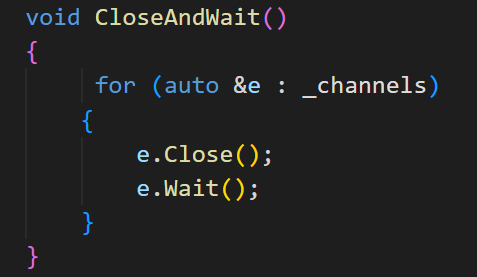
运行结果:
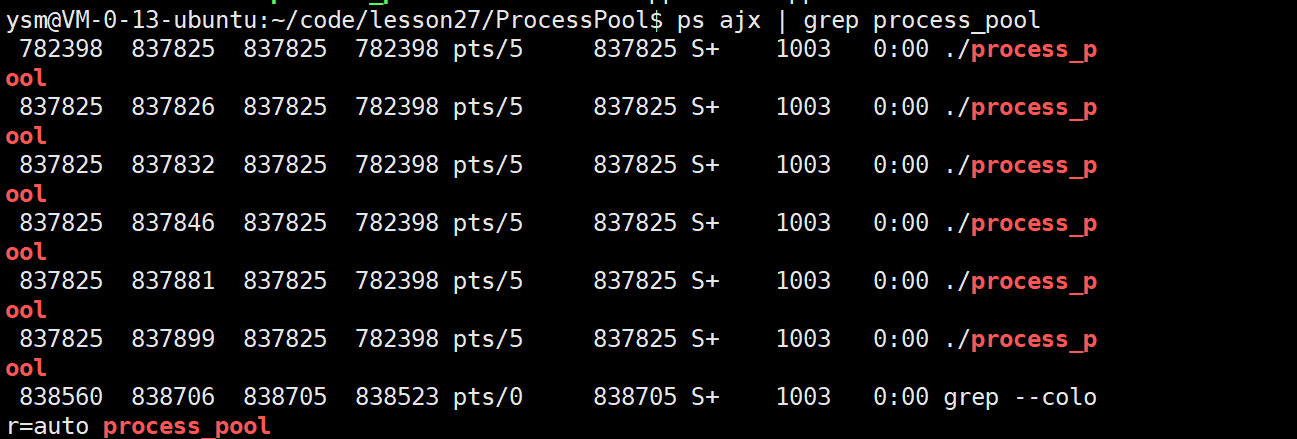
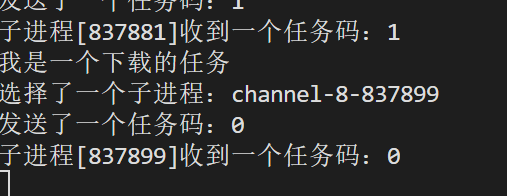
我们发现最后并没有回收成功,而是一直卡在这,那这是为什么呢?
我们先来看一下

仅展示一下要修改的代码
方法2运行结果: