📖 目录
- 一、项目概述
- 二、架构总览
- 三、环境准备
- [四、部署 MinIO + 创建 Bucket](#四、部署 MinIO + 创建 Bucket)
- [五、部署 Kafka (KRaft 模式)](#五、部署 Kafka (KRaft 模式))
- [六、部署 Iceberg REST Catalog (SQLite 后端)](#六、部署 Iceberg REST Catalog (SQLite 后端))
- [七、准备 Flink 连接器 JAR](#七、准备 Flink 连接器 JAR)
- 八、核心难点:PatchedFlinkCatalogFactory
- [九、部署 Flink (Standalone on K8s)](#九、部署 Flink (Standalone on K8s))
- [十、Flink SQL 流式任务](#十、Flink SQL 流式任务)
- [十一、StreamPark 集成](#十一、StreamPark 集成)
- 十二、端到端验证
- 十三、踩坑清单速查
- 十四、重启恢复流程
- 十五、关键文件清单
项目概述
本项目使用Qwen3.7模型,在 macOS 本地环境搭建了一套完整的轻量级实时数仓平台,技术栈包括 Minikube (K8s)、Apache Flink 1.19.1、Apache Iceberg 1.10.2、MinIO 对象存储和 Kafka 消息队列。所有组件部署在 Minikube 单集群的 data-platform namespace 中,资源控制在 4 CPU / 6 GB 内存以内。
最终实现的数据流为:Kafka → Flink (SQL 流式处理) → Iceberg (Parquet) → MinIO (S3)。
架构总览
┌─────────────────────────────────────────────────────────┐
│ Minikube (4CPU/6GB) │
│ ┌──────────┐ ┌──────────┐ ┌───────────────────────┐ │
│ │ MinIO │ │ Kafka │ │ Iceberg REST │ │
│ │ (S3) │ │ (KRaft) │ │ (SQLite 元数据) │ │
│ │ 256Mi │ │ 512Mi │ │ 256Mi │ │
│ └────┬─────┘ └────┬─────┘ └───────┬───────────────┘ │
│ │ │ │ │
│ ┌────┴──────────────┴────────────────┴──────────────┐ │
│ │ Flink 1.19.1 (Standalone on K8s) │ │
│ │ JobManager: 1400Mi/1000m │ │
│ │ TaskManager: 1400Mi/1000m │ │
│ │ 连接器: Kafka SQL + Iceberg REST + S3 FileIO │ │
│ └───────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
│ │
NodePort 服务 port-forward
│ │
┌────────┴─────────────────────┴─────────────┐
│ macOS 宿主机 │
│ StreamPark 2.1.5 (localhost:10000) │
│ Flink Web UI (localhost:8081) │
│ MinIO Console (localhost:9001) │
└────────────────────────────────────────────┘资源分配 (总计 ~3.4 GB):
| 组件 | 内存限制 | CPU 限制 | 说明 |
|---|---|---|---|
| MinIO | 256Mi | 200m | S3 兼容对象存储 |
| Kafka | 512Mi | 300m | KRaft 模式 (无 ZooKeeper),堆内存限制 256m |
| Iceberg REST | 256Mi | 200m | 内置 SQLite 做元数据后端 |
| Flink JobManager | 1400Mi | 1000m | 进程内存 1024m |
| Flink TaskManager | 1400Mi | 1000m | 进程内存 1024m |
一、环境准备
1.1 安装 Minikube 和 Helm
bash
brew install minikube helm
minikube start --memory=6144 --cpus=4 --disk-size=60g踩坑 1:资源规划要一步到位。 Minikube 创建后无法调整 CPU/内存,必须删除重建。建议在开始前就规划好 4CPU/6GB。
1.2 创建 namespace
bash
kubectl create namespace data-platform1.3 Docker 镜像准备
由于 Docker Hub 在国内网络不稳定,推荐先在本地拉取镜像,再通过 docker save + minikube cp + docker load 的方式导入 Minikube:
bash
docker pull flink:1.19.1-scala_2.12-java11
docker pull apache/iceberg-rest-fixture:latest
docker pull apache/kafka:3.8.0
docker pull minio/minio:latest
for img in flink:1.19.1-scala_2.12-java11 apache/iceberg-rest-fixture:latest \
apache/kafka:3.8.0 minio/minio:latest; do
docker save $img -o /tmp/${img//[:\/]/_}.tar
minikube cp /tmp/${img//[:\/]/_}.tar /tmp/
minikube ssh "docker load -i /tmp/${img//[:\/]/_}.tar"
done二、部署 MinIO + 创建 Bucket
MinIO 作为 S3 兼容的对象存储,存放 Iceberg 的 Parquet 数据文件。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: minio
namespace: data-platform
spec:
replicas: 1
selector:
matchLabels: { app: minio }
template:
metadata:
labels: { app: minio }
spec:
containers:
- name: minio
image: minio/minio:latest
args: ["server", "/data", "--console-address", ":9001"]
env:
- { name: MINIO_ROOT_USER, value: "minioadmin" }
- { name: MINIO_ROOT_PASSWORD, value: "minioadmin" }
ports:
- { containerPort: 9000, name: api }
- { containerPort: 9001, name: console }
resources:
requests: { memory: "128Mi", cpu: "50m" }
limits: { memory: "256Mi", cpu: "200m" }
---
apiVersion: v1
kind: Service
metadata:
name: minio
namespace: data-platform
spec:
selector: { app: minio }
ports:
- { port: 9000, targetPort: 9000, name: api }
- { port: 9001, targetPort: 9001, name: console }创建 warehouse bucket 用于 Iceberg 数据:
bash
kubectl run mc-init --image=minio/mc --restart=Never -n data-platform -- \
sh -c "mc alias set local http://minio:9000 minioadmin minioadmin && \
mc mb --ignore-existing local/warehouse"踩坑 2:MinIO 重启后 bucket 丢失。 MinIO 使用 emptyDir 存储,Pod 重启后数据丢失。每次重启后需要重新执行
mc mb --ignore-existing local/warehouse。生产环境应使用 PVC。
三、部署 Kafka (KRaft 模式)
使用 Kafka 3.8.0 的 KRaft 模式,无需 ZooKeeper,节省资源。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka
namespace: data-platform
spec:
replicas: 1
selector:
matchLabels: { app: kafka }
template:
metadata:
labels: { app: kafka }
spec:
containers:
- name: kafka
image: apache/kafka:3.8.0
env:
- { name: KAFKA_NODE_ID, value: "1" }
- { name: KAFKA_PROCESS_ROLES, value: "broker,controller" }
- { name: KAFKA_CONTROLLER_QUORUM_VOTERS, value: "1@kafka:9093" }
- { name: KAFKA_LISTENERS, value: "PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093,EXTERNAL://0.0.0.0:9094" }
- { name: KAFKA_ADVERTISED_LISTENERS, value: "PLAINTEXT://kafka:9092,EXTERNAL://kafka:9094" }
- { name: KAFKA_LISTENER_SECURITY_PROTOCOL_MAP, value: "PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT" }
- { name: KAFKA_CONTROLLER_LISTENER_NAMES, value: "CONTROLLER" }
- { name: KAFKA_INTER_BROKER_LISTENER_NAME, value: "PLAINTEXT" }
- { name: KAFKA_HEAP_OPTS, value: "-Xmx256m -Xms256m" }
- { name: KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR, value: "1" }
- { name: CLUSTER_ID, value: "MkU3OEVBNTcwNTJENDM2Qk" }
ports:
- { containerPort: 9092, name: internal }
- { containerPort: 9094, name: external }
resources:
requests: { memory: "256Mi", cpu: "100m" }
limits: { memory: "512Mi", cpu: "300m" }
---
apiVersion: v1
kind: Service
metadata:
name: kafka
namespace: data-platform
spec:
selector: { app: kafka }
ports:
- { port: 9092, targetPort: 9092, name: internal }
- { port: 9094, targetPort: 9094, name: external }
---
apiVersion: v1
kind: Service
metadata:
name: kafka-external
namespace: data-platform
spec:
type: NodePort
selector: { app: kafka }
ports:
- { port: 9094, targetPort: 9094, nodePort: 30094 }踩坑 3:Kafka OOMKilled。 Kafka 默认堆内存 1GB,远超 512Mi 限制。必须通过
KAFKA_HEAP_OPTS=-Xmx256m -Xms256m限制堆内存。
踩坑 4:Pod 重启后 Kafka topic 丢失。 每次重启后需要重新创建 topic:
bashkubectl exec -n data-platform $KAFKA_POD -- kafka-topics.sh \ --create --if-not-exists --topic orders --bootstrap-server localhost:9092 \ --partitions 2 --replication-factor 1
四、部署 Iceberg REST Catalog (SQLite 后端)
使用 apache/iceberg-rest-fixture 镜像,内置 SQLite JDBC 驱动,无需额外的 PostgreSQL 数据库。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: iceberg-rest
namespace: data-platform
spec:
replicas: 1
selector:
matchLabels: { app: iceberg-rest }
template:
metadata:
labels: { app: iceberg-rest }
spec:
containers:
- name: iceberg-rest
image: apache/iceberg-rest-fixture:latest
env:
- { name: AWS_ACCESS_KEY_ID, value: "minioadmin" }
- { name: AWS_SECRET_ACCESS_KEY, value: "minioadmin" }
- { name: AWS_REGION, value: "us-east-1" }
- { name: CATALOG_CATALOG__IMPL, value: "org.apache.iceberg.jdbc.JdbcCatalog" }
- { name: CATALOG_URI, value: "jdbc:sqlite:/tmp/iceberg_catalog.db" }
- { name: CATALOG_WAREHOUSE, value: "s3a://warehouse/" }
- { name: CATALOG_IO__IMPL, value: "org.apache.iceberg.aws.s3.S3FileIO" }
- { name: CATALOG_S3_ENDPOINT, value: "http://minio:9000" }
- { name: CATALOG_S3_PATH__STYLE__ACCESS, value: "true" }
ports:
- { containerPort: 8181 }
resources:
requests: { memory: "128Mi", cpu: "50m" }
limits: { memory: "256Mi", cpu: "200m" }踩坑 5:Iceberg 元数据重启丢失。 SQLite 数据库存储在
/tmp/iceberg_catalog.db(容器临时文件系统),Pod 重启后丢失。每次重启后需要重新创建 namespace:
bashcurl -X POST http://localhost:8181/v1/namespaces \ -H 'Content-Type: application/json' \ -d '{"namespace":["default"]}'
五、准备 Flink 连接器 JAR
这是整个部署中最复杂的环节。Flink 官方 Docker 镜像不包含第三方连接器,需要手动准备并通过 hostPath 挂载注入 Pod。
5.1 下载 JAR 列表
在宿主机 /tmp/flink-connectors/ 目录下载以下 JAR:
| JAR 名称 | 来源 | 说明 |
|---|---|---|
flink-sql-connector-kafka.jar |
Maven Central (3.2.0-1.19) | Kafka SQL 连接器 |
iceberg-flink-runtime-1.19.jar |
Maven Central (1.10.2) | Iceberg Flink 运行时 (需打补丁) |
iceberg-aws-bundle.jar |
Maven Central (1.10.2) | AWS SDK v2 (S3 访问) |
flink-s3-fs-hadoop.jar |
Flink 1.19.1 发行包 | S3 文件系统插件 |
hadoop-common.jar |
Maven Central (3.3.6) | Hadoop 通用库 |
hadoop-auth.jar |
Maven Central (3.3.6) | Hadoop 认证 |
hadoop-annotations.jar |
Maven Central (3.3.6) | Hadoop 注解 |
hadoop-hdfs-client.jar |
Maven Central (3.3.6) | Hadoop HDFS 客户端 |
hadoop-shaded-guava.jar |
Maven Central (1.1.1) | Hadoop Shaded Guava (关键依赖) |
hadoop-mapreduce-client-core.jar |
Maven Central (3.3.6) | MapReduce 核心 (SELECT 查询需要) |
woodstox-core.jar |
Maven Central (6.4.0) | XML 解析 |
stax2-api.jar |
Maven Central (4.2.1) | StAX API |
commons-configuration2.jar |
Maven Central (2.8.0) | 配置管理 |
commons-lang3.jar |
Maven Central (3.12.0) | 字符串工具 |
re2j.jar |
Maven Central (1.7) | 正则引擎 |
hive-metastore.jar |
Maven Central (2.3.9) | Hive Metastore (FlinkCatalog 类引用) |
libthrift.jar |
Maven Central (0.13.0) | Thrift 库 |
libfb303.jar |
Maven Central (0.9.3) | Facebook Thrift |
5.2 导入 Minikube
bash
# 将所有 JAR 复制到 Minikube 容器的 /opt/flink-connectors/
docker cp /tmp/flink-connectors/. minikube:/opt/flink-connectors/踩坑 6:Init Container 网络失败。 最初尝试用 Init Container 在线下载 JAR,但 Minikube 内网络不稳定导致反复失败。最终方案:在宿主机下载好,通过
docker cp导入 Minikube,再通过 K8shostPathvolume 挂载到 Flink Pod。
六、核心难点:PatchedFlinkCatalogFactory
这是本项目最关键的技术突破点。Iceberg 1.10.2 的 FlinkCatalogFactory 与 Flink 1.19.1 存在三个兼容性问题,需要通过自定义 Java 类解决。
问题 A:SPI 注册缺失
iceberg-flink-runtime-1.19.jar 的 META-INF/services/org.apache.flink.table.factories.Factory 只注册了 FlinkDynamicTableFactory,缺少 FlinkCatalogFactory。Flink 1.19 的 FactoryUtil.discoverFactory() 通过此 SPI 文件发现 Catalog 工厂。
问题 B:factoryIdentifier() 返回 null 导致 NPE
Iceberg 的 FlinkCatalogFactory 继承自 CatalogFactory,其默认 factoryIdentifier() 方法返回 null。Flink 1.19 的 discoverFactory() 内部执行 null.equals(identifier) 抛出 NullPointerException。
问题 C:Hive 依赖链
原始的 FlinkCatalogFactory.createCatalog() 方法会触发 Hive Metastore 相关类的加载,导致大量额外的依赖链。
解决方案:PatchedFlinkCatalogFactory
创建一个继承 FlinkCatalogFactory 的子类,重写关键方法:
java
package org.apache.iceberg.flink;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.table.catalog.Catalog;
import org.apache.flink.table.factories.CatalogFactory;
import org.apache.iceberg.catalog.Namespace;
import org.apache.hadoop.conf.Configuration;
import java.util.Collections;
import java.util.Map;
import java.util.Set;
public class PatchedFlinkCatalogFactory extends FlinkCatalogFactory {
@Override
public String factoryIdentifier() {
return "rest"; // 解决 NPE:返回非 null 标识符
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
return Collections.emptySet();
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
return Collections.emptySet();
}
@Override
public Catalog createCatalog(CatalogFactory.Context context) {
String name = context.getName();
Map<String, String> options = context.getOptions();
String defaultDb = options.getOrDefault("default-database", "default");
Configuration hadoopConf = clusterHadoopConf();
// 直接创建 REST catalog loader,绕过 Hive 依赖链
CatalogLoader catalogLoader = CatalogLoader.rest(name, hadoopConf, options);
// 关键:baseNamespace 必须用 Namespace.empty()
// 如果用 Namespace.of(defaultDb),会导致 namespace 被拼接为
// default%1Fdefault(两级),REST API 返回 400
return new FlinkCatalog(
name, defaultDb, Namespace.empty(),
catalogLoader, options, true, 60000L
);
}
}编译与注入流程:
bash
# 1. 编译 (必须使用 --release 11,因为 Flink 使用 JRE 11)
FLINK_LIB="/path/to/flink-1.19.1/lib"
ICEBERG_JAR="$FLINK_LIB/iceberg-flink-runtime-1.19.jar"
javac --release 11 \
-cp "$ICEBERG_JAR:$FLINK_LIB/flink-table-api-java-uber-1.19.1.jar:\
$FLINK_LIB/flink-table-runtime-1.19.1.jar:$FLINK_LIB/flink-dist-1.19.1.jar:\
$FLINK_LIB/flink-core-1.19.1.jar:$FLINK_LIB/hadoop-common.jar:\
$FLINK_LIB/hadoop-auth.jar" \
org/apache/iceberg/flink/PatchedFlinkCatalogFactory.java
# 2. 注入到 iceberg-flink-runtime jar (不能用 jar uf,shaded jar 有重复条目)
python3 << 'PYEOF'
import zipfile, shutil
src = "/path/to/iceberg-flink-runtime-1.19.jar"
dst = src + ".new"
patch = "/path/to/PatchedFlinkCatalogFactory.class"
with zipfile.ZipFile(src, 'r') as zin:
with zipfile.ZipFile(dst, 'w', zipfile.ZIP_DEFLATED) as zout:
for entry in zin.namelist():
if entry == "org/apache/iceberg/flink/PatchedFlinkCatalogFactory.class":
with open(patch, 'rb') as f:
zout.writestr(entry, f.read())
else:
zout.writestr(entry, zin.read(entry))
shutil.move(dst, src)
PYEOF踩坑 7:
jar uf无法用于 shaded uber-jar。 执行jar uf iceberg-flink-runtime.jar PatchedFlinkCatalogFactory.class会报ZipException: duplicate entry: LICENSE。必须用 Pythonzipfile模块逐条目重建 JAR。
踩坑 8:Namespace.of(defaultDb)导致 namespace 双重编码。FlinkCatalog构造函数的第三个参数是baseNamespace。如果传入Namespace.of("default"),当 Flink 解析iceberg_catalog.default.orders_iceberg时,Iceberg 会将 baseNamespace 和 database 拼接为["default", "default"],REST URL 变成default%1Fdefault,服务端返回 400 "Suspicious Path Character"。正确做法是传入Namespace.empty(),让 database 名直接映射到 Iceberg namespace。
七、部署 Flink (Standalone on K8s)
不使用 Flink Operator,直接用 K8s Deployment 部署 Flink Standalone 集群。核心设计:通过自定义 command 在启动脚本中完成 JAR 复制和 config.yaml 生成。
7.1 启动脚本设计
Flink Docker 镜像的 docker-entrypoint.sh 处理 FLINK_PROPERTIES 环境变量,但当自定义 command 时会绕过入口脚本。因此必须在启动脚本中手动写 config.yaml:
bash
# 复制连接器 JAR
cp /connectors/flink-sql-connector-kafka.jar $FLINK_HOME/lib/
cp /connectors/iceberg-flink-runtime.jar $FLINK_HOME/lib/
# ... (其余 JAR 同上)
# 生成 config.yaml
echo "jobmanager.rpc.address: flink-jobmanager" > $FLINK_HOME/conf/config.yaml
echo "taskmanager.numberOfTaskSlots: 2" >> $FLINK_HOME/conf/config.yaml
echo "state.backend: hashmap" >> $FLINK_HOME/conf/config.yaml
echo "rest.bind-address: 0.0.0.0" >> $FLINK_HOME/conf/config.yaml
echo "jobmanager.memory.process.size: 1024m" >> $FLINK_HOME/conf/config.yaml # JM 需要
echo "blob.server.port: 6124" >> $FLINK_HOME/conf/config.yaml
echo "blob.fetch.num-retries: 10" >> $FLINK_HOME/conf/config.yaml
# 启动 (必须用 exec 替换 PID 1)
exec $FLINK_HOME/bin/jobmanager.sh start-foreground踩坑 9:
FLINK_PROPERTIES环境变量不生效。 自定义command: ["/bin/bash", "-c"]会绕过docker-entrypoint.sh,FLINK_PROPERTIES不会被解析为config.yaml。必须在脚本中用echo逐行写入配置文件。
踩坑 10:Flink 拒绝启动 --- 缺少内存配置。 手动写config.yaml时,如果不包含jobmanager.memory.process.size(JM) 或taskmanager.memory.process.size™,Flink 会启动失败。容器内存限制 1400Mi,进程内存设为 1024m。
踩坑 11:TM 连接 localhost:6123。 如果不在 config.yaml 中设置jobmanager.rpc.address: flink-jobmanager,TM 会默认连接 localhost,找不到 JM。
踩坑 12:Blob 传输超时。 Flink SQL Client 会将 lib/ 下所有 JAR (~80MB) 作为 blob 从 JM 传输到 TM。在资源受限环境中容易超时。设置blob.server.port: 6124和blob.fetch.num-retries: 10可以显著提高稳定性。
7.2 YAML heredoc 缩进问题
踩坑 13:K8s YAML 中的 heredoc 缩进。 在 K8s
args字段中使用cat << 'EOF'时,YAML 的缩进空格会成为文件内容的一部分,导致 config.yaml 解析失败。推荐使用echo "key: value" >> file逐行写入。
7.3 S3 文件系统插件
flink-s3-fs-hadoop.jar 必须放在 $FLINK_HOME/plugins/s3-fs-hadoop/ 目录下(不是 lib/),Flink 的插件机制要求文件系统实现放在 plugins/ 子目录中。
八、Flink SQL 流式任务
8.1 SQL 定义
sql
SET 'execution.checkpointing.interval' = '10s';
CREATE CATALOG iceberg_catalog WITH (
'type' = 'rest',
'uri' = 'http://iceberg-rest:8181', -- K8s 内部服务名
'warehouse' = 's3a://warehouse/',
'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO',
's3.endpoint' = 'http://minio:9000', -- K8s 内部服务名
's3.path-style-access' = 'true',
's3.access-key-id' = 'minioadmin',
's3.secret-access-key' = 'minioadmin'
);
USE CATALOG iceberg_catalog;
CREATE TEMPORARY TABLE kafka_orders (
order_id BIGINT,
user_id BIGINT,
product_id INT,
quantity INT,
price DECIMAL(10,2),
city STRING,
status STRING,
order_time TIMESTAMP(3),
dt AS DATE_FORMAT(order_time, 'yyyy-MM-dd'),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'kafka:9092', -- K8s 内部服务名
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);
CREATE TABLE IF NOT EXISTS orders_iceberg (
order_id BIGINT,
user_id BIGINT,
product_id INT,
quantity INT,
price DECIMAL(10,2),
city STRING,
status STRING,
order_time TIMESTAMP(3),
dt STRING
) PARTITIONED BY (dt) WITH (
'format-version' = '2'
);
INSERT INTO orders_iceberg
SELECT * FROM kafka_orders;8.2 提交方式
通过 Pod 内 Flink SQL Client 提交(使用 K8s 服务名):
bash
JM_POD=$(kubectl get pods -n data-platform -l component=jobmanager \
-o jsonpath='{.items[0].metadata.name}')
# 将 SQL 写入 Pod 内文件
kubectl exec -n data-platform $JM_POD -- bash -c 'cat > /tmp/submit.sql << "EOF"
... (上面的 SQL) ...
EOF'
# 提交
kubectl exec -n data-platform $JM_POD -- /opt/flink/bin/sql-client.sh -f /tmp/submit.sql踩坑 14:
CREATE TABLE IF NOT EXISTS与 schema 不匹配。 如果 Iceberg 中已存在同名但 schema 不同的表,IF NOT EXISTS会保留旧表,后续INSERT INTO时因列数/类型不匹配而失败。解决方法:先通过 REST API 删除旧表:
bashcurl -X DELETE "http://localhost:8181/v1/namespaces/default/tables/orders_iceberg" \ -H 'Content-Type: application/json' -d '{"purgeRequested": true}'
踩坑 15:Iceberg catalog 内的表不能指定
'connector' = 'iceberg'。 当使用 Iceberg Catalog (而非 default_catalog) 创建表时,不需要也不能指定connector属性,因为 Catalog 本身已知道是 Iceberg 类型。
踩坑 16:default是 Flink SQL 保留字。 引用default数据库名时需要用反引号:```default.orders_iceberg``。或者不写数据库名,因为USE CATALOG后默认数据库就是default`。
九、StreamPark 集成
StreamPark 2.1.5 提供了 Web UI 和 API 来管理 Flink 应用。
9.1 添加 Flink 环境
bash
TOKEN=$(curl -s -X POST "http://localhost:10000/passport/signin" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d 'username=admin&password=streampark&loginType=PASSWORD' \
| python3 -c "import sys,json; print(json.load(sys.stdin)['data']['token'])")
curl -X POST "http://localhost:10000/flink/env/create" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Authorization: $TOKEN" \
-d 'flinkName=Flink-1.19.1-K8s&flinkHome=/path/to/flink-1.19.1&description=Flink 1.19.1 for K8s'9.2 添加 Flink 远程集群
bash
curl -X POST "http://localhost:10000/flink/cluster/create" \
-H "Content-Type: application/x-www-form-urlencoded" \
-H "Authorization: $TOKEN" \
-d 'clusterName=flink_02&executionMode=1&versionId=2&address=http://127.0.0.1:8081&description=Remote Flink cluster'踩坑 17:StreamPark API 认证 --- 必须用 form-urlencoded。
POST /passport/signin如果使用Content-Type: application/json,会返回{"code":0,"status":"success"}但静默丢弃 token 。必须使用application/x-www-form-urlencoded,且loginType必须是枚举名"PASSWORD"而非整数0。
踩坑 18:StreamPark REMOTE 模式的双向网络问题 (macOS)。 StreamPark 在宿主机编译 SQL 时需要访问 Iceberg REST 和 Kafka,但编译后的 JobGraph 在 K8s Pod 内运行时需要使用 K8s 服务名。macOS Docker Desktop 的网络隔离导致 minikube IP (192.168.49.2) 从宿主机不可达。最终方案:通过 Pod 内 Flink SQL Client 直接提交任务,StreamPark 用于集群监控。
十、端到端验证
10.1 发送测试数据
bash
echo '{"order_id":9001,"user_id":1,"product_id":100,"quantity":2,"price":99.50,"city":"Beijing","status":"paid","order_time":"2026-06-11T16:40:00"}
{"order_id":9002,"user_id":2,"product_id":200,"quantity":1,"price":150.00,"city":"Shanghai","status":"paid","order_time":"2026-06-11T16:40:30"}
{"order_id":9003,"user_id":3,"product_id":100,"quantity":3,"price":75.80,"city":"Guangzhou","status":"pending","order_time":"2026-06-11T16:41:00"}' \
| kubectl exec -i -n data-platform $KAFKA_POD -- \
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic orders10.2 验证结果
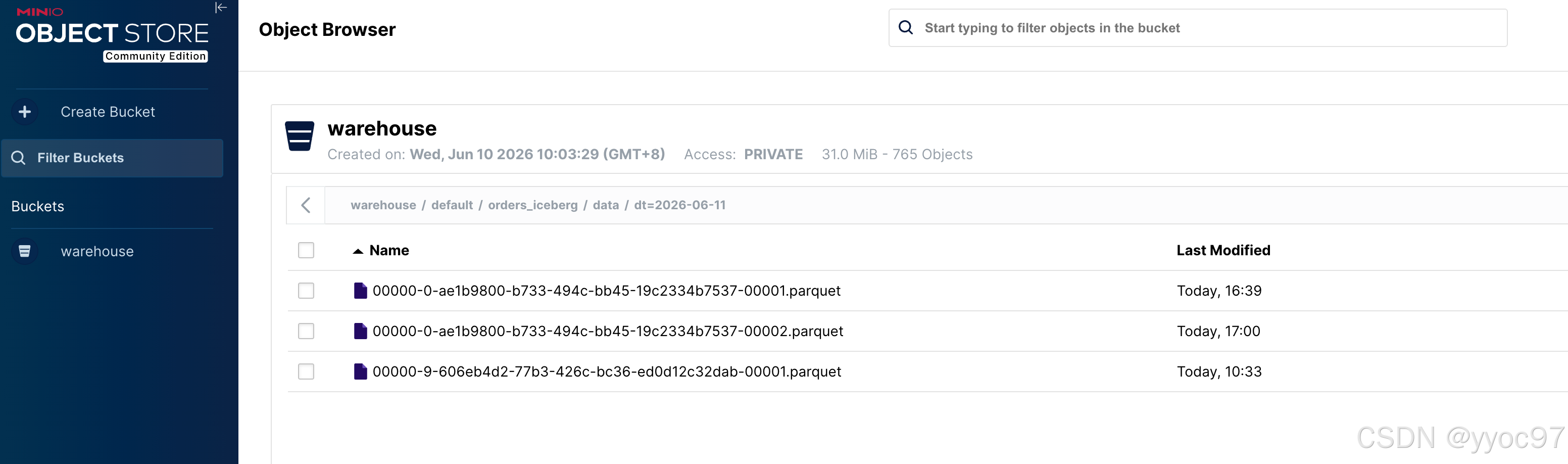
等待 10-20 秒(一个 checkpoint 周期)后,MinIO 中会出现新的 parquet 文件:
warehouse/default/orders_iceberg/data/dt=2026-06-11/
├── 00000-0-ae1b9800-...-00001.parquet (3 rows, batch 1)
└── 00000-0-ae1b9800-...-00002.parquet (2 rows, batch 2)Iceberg 元数据可通过 REST API 查看:
bash
curl http://localhost:8181/v1/namespaces/default/tables/orders_iceberg \
| python3 -c "import sys,json; d=json.load(sys.stdin); \
print(d['metadata']['snapshots'][-1]['summary'])"输出:
python
{'operation': 'append',
'flink.job-id': '335c0ddd7334653a2c937fbb817f11fa',
'total-records': '3',
'total-data-files': '1',
'engine-version': '1.19.1',
'iceberg-version': 'Apache Iceberg 1.10.2'}十一、踩坑清单速查
| # | 问题 | 根因 | 解决方案 |
|---|---|---|---|
| 1 | Minikube 无法调整资源 | 创建后不可变 | 创建时规划好 4CPU/6GB |
| 2 | MinIO bucket 重启丢失 | emptyDir 存储 | 重启后 mc mb --ignore-existing |
| 3 | Kafka OOMKilled | 默认 1GB 堆内存 | KAFKA_HEAP_OPTS=-Xmx256m |
| 4 | Kafka topic 重启丢失 | 临时存储 | 重启后 --create --if-not-exists |
| 5 | Iceberg 元数据重启丢失 | SQLite 在 /tmp | 重启后重新创建 namespace |
| 6 | Init Container 下载 JAR 失败 | 网络不稳定 | 宿主机下载 + docker cp + hostPath |
| 7 | jar uf 在 shaded jar 上报错 |
重复 LICENSE 条目 | 用 Python zipfile 模块 |
| 8 | default%1Fdefault namespace 双重编码 |
Namespace.of(defaultDb) 拼接 |
改用 Namespace.empty() |
| 9 | FLINK_PROPERTIES 不生效 |
自定义 command 绕过入口脚本 | 手动 echo 写 config.yaml |
| 10 | Flink 启动失败 --- 缺少内存配置 | config.yaml 未包含内存参数 | 写入 *.memory.process.size |
| 11 | TM 连接 localhost:6123 | 缺少 rpc address 配置 | jobmanager.rpc.address: flink-jobmanager |
| 12 | Blob 传输 JM→TM 超时 | lib/ JAR 太大 | 设 blob.server.port: 6124, num-retries: 10 |
| 13 | YAML heredoc 缩进污染文件内容 | YAML 缩进成为文件内容 | 用 echo 逐行写入 |
| 14 | CREATE TABLE IF NOT EXISTS schema 不匹配 | 旧表 schema 不同 | 先 DELETE 再 CREATE |
| 15 | Iceberg catalog 内不能指定 connector | Catalog 已隐含类型 | 移除 'connector'='iceberg' |
| 16 | default 是 SQL 保留字 |
Flink SQL parser | 用反引号或省略 |
| 17 | StreamPark API 返回空 token | JSON body + 整数 loginType | form-urlencoded + loginType=PASSWORD |
| 18 | StreamPark REMOTE 模式双向网络不通 | macOS Docker 网络隔离 | Pod 内 SQL Client 提交 |
| 19 | factoryIdentifier() NPE |
Iceberg FlinkCatalogFactory 未实现 | PatchedFlinkCatalogFactory 返回 "rest" |
| 20 | SELECT 查询 FileInputFormat 缺失 |
缺少 hadoop-mapreduce-client-core | 添加 JAR 到 lib/ |
| 21 | UserGroupInformation crash |
hadoop-shaded-guava 缺失 |
添加 hadoop-shaded-guava-1.1.1.jar |
| 22 | javac 编译版本不兼容 |
Flink JRE 11 vs 宿主机 JDK 21 | javac --release 11 |
十二、重启恢复流程
由于使用临时存储,每次 Docker Desktop / Minikube 重启后需要执行以下恢复步骤:
bash
# 1. 启动基础设施
minikube start
# 2. 重建易失资源
kubectl exec -n data-platform $KAFKA_POD -- kafka-topics.sh \
--create --if-not-exists --topic orders --bootstrap-server localhost:9092 \
--partitions 2 --replication-factor 1
curl -X POST http://localhost:8181/v1/namespaces \
-H 'Content-Type: application/json' -d '{"namespace":["default"]}'
kubectl exec -n data-platform $MINIO_POD -- mc alias set local http://localhost:9000 minioadmin minioadmin
kubectl exec -n data-platform $MINIO_POD -- mc mb --ignore-existing local/warehouse
# 3. 建立 port-forward
kubectl port-forward svc/flink-jobmanager 8081:8081 -n data-platform &
kubectl port-forward svc/iceberg-rest 8181:8181 -n data-platform &
# 4. 重新提交 Flink SQL 任务
kubectl exec -n data-platform $JM_POD -- /opt/flink/bin/sql-client.sh -f /tmp/submit.sql十三、关键文件清单
flink-iceberg-platform/
├── flink-iceberg-lite.yaml # 主部署文件 (Iceberg REST + Flink JM/TM)
├── minio/minio-deployment.yaml # MinIO 部署
├── kafka/kafka-deployment.yaml # Kafka 部署
├── demo/flink-sql-orders.sql # Flink SQL 流式任务
└── demo/generate-orders.sh # Kafka 测试数据生成脚本
/tmp/flink-connectors/ # 连接器 JAR 目录 (hostPath 挂载源)
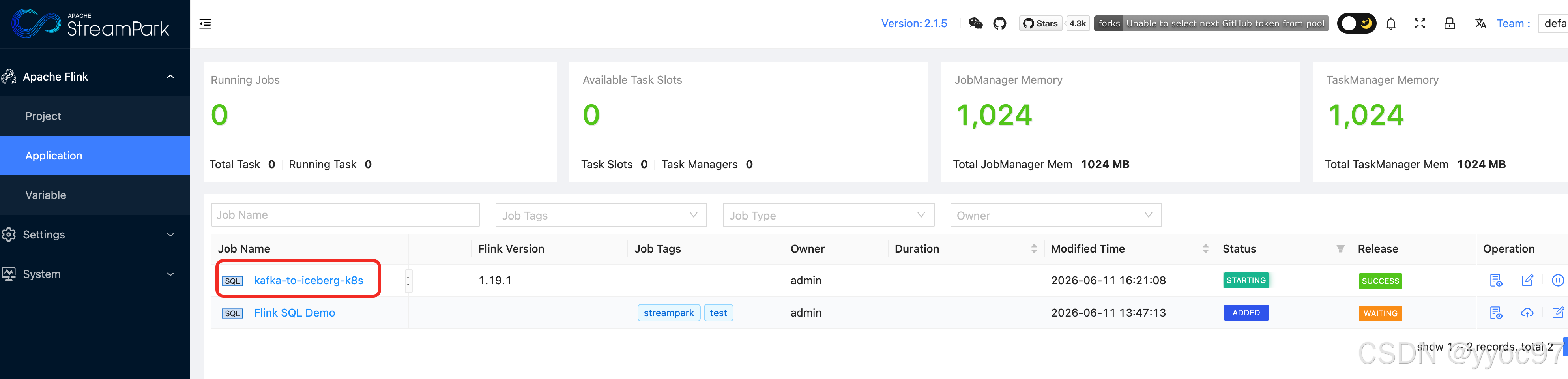
/tmp/iceberg_patch/ # PatchedFlinkCatalogFactory 源码和编译产物十四、效果
创建的flink任务
写入的元数据