刚开始用 OpenAI API 时,很多人会把 token 简单理解成"字数"。这个说法方便,但并不准确。 更接近事实的说法是:token 是模型真正读取、计算和生成文本时使用的基本单位。
1. Token 不是"一个词",也不是"一个字"
在 OpenAI models 里,文本不会直接以"整句话"的形式进入模型。它会先经过 Tokenization,被切成一小段一小段的 token。一个 token 可能是一个完整单词, 也可能只是单词的一部分;它也可能包含空格、标点,甚至因为大小写和位置不同而变成不同的 token。
所以,token 更像是模型内部使用的"文本积木"。人看到的是句子,模型看到的是一串 token ID。
示意:一句话被拆成 token 后,大概会变成这样

注意这里的空格也可能被算进 token 里。比如 Red、 red、 Red 在 tokenizer 看来不一定是同一个东西。
2. 估算 token:英文可以粗略换算,中文最好实际测
OpenAI 的文档给了几个英文场景下的经验值。它们不是严格公式,但足够用来做初步估算:
1 token约等于 4 个英文字符
100 tokens约等于 75 个英文单词
30 tokens大约是 1--2 句英文
100 tokens大约是 1 个英文段落
但如果你的输入是中文、代码、表格、JSON、医学报告、日志文件,就不要太相信这种粗略换算。 不同语言、不同 model、不同 encoding,token 数都会变。实际项目里,建议直接用 Tokenizer 或 tiktoken 计算。
对开发者来说,最稳妥的做法不是"猜 token",而是在请求发出去之前就统计 token。 特别是做 RAG、长文总结、日志分析、医学影像报告处理时,提前计算 token 可以避免超出 context window。
3. API 调用时,token 是怎么流动的?
一次 API 请求可以理解成三个步骤:先把输入文本拆成 token,模型处理这些 token, 最后再把生成出来的 token 转回人类能读的文本。
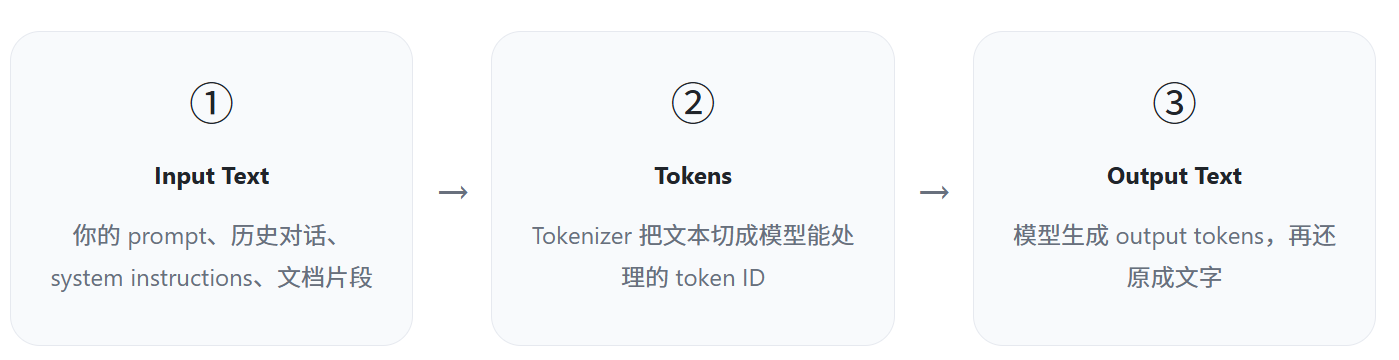
这也是为什么同样一句话,放在不同位置、前面有没有空格、大小写是否一致,都可能影响 Tokenization 的结果。对普通聊天影响不大,但对成本估算、批处理和长上下文系统来说,这些细节会被放大。
4. 几种常见 token:别只盯着 input tokens
很多人第一次看 API usage 时,只注意到了 input tokens 和 output tokens。 实际上,token usage 里通常还会出现其他类别。
| 类型 | 含义 | 你该怎么理解 |
|---|---|---|
| Input tokens | 请求里输入给模型的 token。 | 包括 system prompt、user message、历史对话、检索片段等。 |
| Output tokens | 模型最终生成的 token。 | 回复越长,output tokens 越多。写长文、生成代码、输出 JSON 时尤其明显。 |
| Cached tokens | 对话历史或重复上下文中可复用的 token。 | 某些情况下会以较低成本计费,适合长对话或固定系统提示较多的场景。 |
| Reasoning tokens | 部分 advanced models 内部推理时使用的 token。 | 用户不一定直接看到,但它们可能计入 usage。复杂推理任务会更明显。 |

5. Token limit:不是你想塞多少文本都可以
每个 model 都有自己的最大 token limit。这里的限制通常是 input tokens + output tokens 的总和,也就是常说的 context window。
举个例子,如果你把一份很长的文档、几十轮历史对话、复杂 system prompt 全部塞进一次请求, 模型不一定能完整接收。即使某些 high-capacity models 支持很长的上下文,也不意味着实际项目里应该无脑塞满。
超出 token limit 时,常见处理方式有三种:
✓缩短 prompt
删掉无效寒暄、重复说明、低价值背景,把任务目标写得更直接。
✓分块处理 chunks
长文档不要一次性全部输入,可以切成多个 chunks,再做汇总或检索。
✓先总结再输入
对历史对话、报告、日志先做 summary,再把压缩后的信息交给模型。
6. Token 和价格:为什么"长 prompt"会变贵
OpenAI API 的计费和 token usage 直接相关。不同 model 的价格不同, input tokens、output tokens、cached tokens 的价格也可能不同。
这件事在小规模测试时不明显。你手动问十几次,可能感觉不到差异。 但一旦进入批量处理,比如一天处理几万条聊天记录、几千份文档、几十万行安全日志, prompt 里每多一段无用说明,都会变成真实成本。
做 API 应用时,prompt 不是越长越专业。真正好的 prompt 应该是: 任务边界清楚、输入结构稳定、输出格式明确、无关上下文尽量少。
7. 实际开发里,怎么数 token?
如果只是临时查看一段文本,可以用 OpenAI 的 Tokenizer 工具。 它能直观看到文本被切成了哪些 token。
如果你是在项目里做自动化统计,更推荐用 tiktoken。 它是 OpenAI models 常用的 fast BPE tokenizer,可以在代码里按目标 model 计算 token 数。
import tiktoken
model = "gpt-4.1"
encoding = tiktoken.encoding_for_model(model)
text = "Token 是模型处理文本的基本单位。"
tokens = encoding.encode(text)
print(len(tokens))
print(tokens)这里有一个容易忽略的点:你应该按实际使用的 model 去计算,而不是随便拿一个 encoding 估算。 因为 Tokenization 会随 model 和 encoding 变化。
8. 最后给一个简单判断标准
如果你只是日常聊天,没必要时时刻刻计算 token。知道它大概影响上下文长度和费用就够了。
但如果你在做 API 项目,尤其是 RAG、长文档问答、代码生成、批量文本分析、日志审计、 医学报告处理,那 token 就不是一个抽象概念,而是系统设计的一部分。
一句话总结:token 是模型眼里的文字单位,也是 API 成本、上下文长度和系统稳定性的共同入口。 理解 token,不是为了背概念,而是为了少踩"为什么超长了""为什么变贵了""为什么模型没看到前文"的坑。