支持向量机(SVM)
支持向量机(Support Vector Machine, SVM)是一种强大且应用广泛的监督学习算法,主要用于分类问题。它的核心思想是在特征空间中寻找一个最优的超平面,以最大化不同类别数据点(特别是离超平面最近的支持向量)之间的间隔。
| 概念 | 数学符号 | 参与对象 | 输出结果 | 核心本质 |
|---|---|---|---|---|
| 点积 | a⋅b\mathbf{a} \cdot \mathbf{b}a⋅b | 两个一维向量 (1D ×\times× 1D) | 一个数值 (标量) | 对应元素相乘后求和 |
| 内积 | ⟨a,b⟩\langle \mathbf{a}, \mathbf{b} \rangle⟨a,b⟩ | 两个一维向量 | 一个数值 (标量) | 点积的抽象统称(在实数域中即为点积) |
| 矩阵乘法 | ABABAB | 两个二维矩阵 (2D ×\times× 2D) | 一个二维矩阵 (2D) | 行向量与列向量的批量点积 |
一. 最优超平面
1. 定义
在线性可分的情形下,能够将两类数据完美分开的决策边界(直线/超平面)是有无数条的。但是,考虑数据分布的噪声和模型的泛化能力,我们需要寻找一种最优的决策边界。
线性可分的意思是在一个包含两类数据的数据集中,你能否找到一个"平直的边界"将这两类数据完美地、没有任何错误地一分为二。
最优超平面的三个直观条件:
- 完全分开两类: 该直线/平面必须能够分开了正例和负例。
- 最大化间隔: 该直线/平面使得两类数据点到它的"间隔(Margin)"最大化。
- 居于正中: 该直线/平面处于间隔中间,到两侧最近的所有"支持向量(Support Vectors)"的距离完全相等。
结论: 在线性可分条件下,满足上述三个条件的最优决策边界(最大间隔边界)有且只有一条。 并且,区别于基于概率的逻辑回归,SVM基于"最大间隔"的决策边界完全由距离超平面最近的几个点(支持向量)决定,而不会因为其他非支持向量数据点的变化而改变。
线性可分的严格定义:
对于训练样本集 {(xi,yi)}i=1N\{ (x_i, y_i) \}_{i=1}^N{(xi,yi)}i=1N (其中类别标签 yi∈{−1,+1}y_i \in \{-1, +1\}yi∈{−1,+1}),它是线性可分的当且仅当存在权重向量 www 和偏置 bbb,使得对所有样本均满足:
yi(w⋅xi+b)>0y_i (w \cdot x_i + b) > 0yi(w⋅xi+b)>0
对于一个训练样本集 {(xi,yi)}i=1N\{ (x_i, y_i) \}_{i=1}^N{(xi,yi)}i=1N,其中特征向量为 xix_ixi,类别标签为 yiy_iyi(为了方便计算,通常设定为正类 +1+1+1 和负类 −1-1−1)。
"线性可分条件"成立,当且仅当存在一组参数(权重向量 www 和偏置 bbb),能够使得针对所有的样本点,都严格满足以下条件:
- 当样本属于正类(yi=+1y_i = +1yi=+1)时,w⋅xi+b>0w \cdot x_i + b > 0w⋅xi+b>0
- 当样本属于负类(yi=−1y_i = -1yi=−1)时,w⋅xi+b<0w \cdot x_i + b < 0w⋅xi+b<0
这两个条件可以合并为一个极其优雅的核心不等式:
yi(w⋅xi+b)>0(对于所有 i=1,2,...,N)y_i (w \cdot x_i + b) > 0 \quad (\text{对于所有 } i=1, 2, \dots, N)yi(w⋅xi+b)>0(对于所有 i=1,2,...,N)
只要找到一组 www 和 bbb 使得上述不等式对所有数据都成立,这个数据集就是线性可分的。
2. 怎么找到一个最优超平面
我们感觉超平面A是最优的。因为它与两个类的距离都足够大。
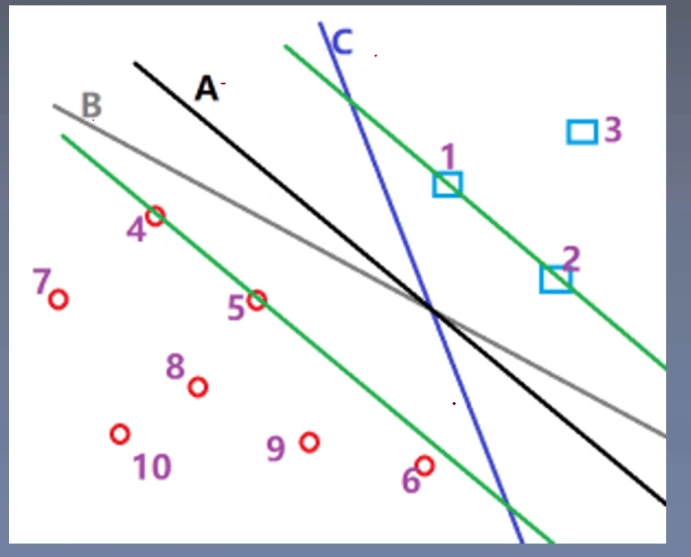
结论:
我们试图要去找到一个超平面,这个超平面可以使得与它最近的样本点的距离必须大于其他所有超平面划分时与最近的样本点的距离。
在svm中,这叫间隔最大化
3. 升维
想象一件事情
有一根棍子,它是二维的 
-
当有人拿着棍子指着你时,你只能看到棍子的横截面,是一个点,它是一维的。我们无法将两个点区分开来。因为它们重叠了。

-
当有人拿着棍子指着深度之眼,我们能看到整根棍子,这时候是二维的。我们可以一刀把棍子劈开来,把红豆和绿豆区分开来。所以,红豆和绿豆虽然在一维的时候不能分开,但在二维时就线性可分型了。

但也有可能二维仍然不能分开
-
这时候我们把棍子真正看成一个三维中的棍子,是有体积的。如果把棍子立在地上,很有可能红豆都在靠南侧,绿豆都在靠北侧,那么我们像劈柴一样把这个棍子劈开,也一样线性可分。
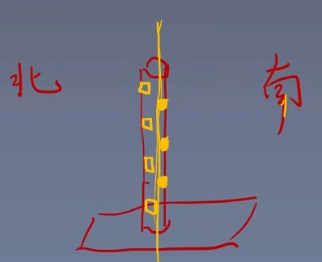
-
如果三维还不能线性可分,那就升到4维。
总会从某一个维度开始,它变得线性可分了
同时,我们发现,高维中的超平面,映射到低维空间中时,可能会变成曲线或其他形式的划分形式。这也就是为什么,在svm中我们同样使用超平面来划分,但SVM可以划分非线形的数据集。它本质上仍然是线形超平面,不过是高维中的线形超平面。
注:只要升维(到无穷维)一定会线形可分
-
不会升到无穷维了仍然线形不可分。首先要明白,我们的数据集一定是基于真实的某种分布,分为A类的样本和B类的一定在本质上有区别。只要有区别,就一定可以区分开来,一定在某个高维度上线性可分。
-
假如在N维空间中线性可分了,我们为什么要上升到无穷高的维度呢?可不可能在在N+1维不可分了?
不会,随着维度的上升,我们获得的信息越来越多。当第N维的数据已经足够划分时,更多的信息量并不会出现不可分的这种情况。
4. 向量机分类
- 线性 →\rightarrow→ 最优超平面
- 非线性(核函数) →\rightarrow→ 非线性超平面
5. SVM根本目标
SVM的根本目标是最大化支持向量到分割平面的距离:
maxd ⟺ maxd2⇔max1∣∣w∣∣2⇔min∣∣w∣∣2⇔min12∣∣w∣∣2\max d \iff \max d^2 \Leftrightarrow \max \frac{1}{||w||^2} \Leftrightarrow \min ||w||^2 \Leftrightarrow \min \frac{1}{2}||w||^2maxd⟺maxd2⇔max∣∣w∣∣21⇔min∣∣w∣∣2⇔min21∣∣w∣∣2
结合线性可分性的约束条件,最优超平面的寻找可形式化为一个标准的"凸优化问题(二次规划问题 Quadratic Programming)":
目标函数(二次项): min12∣∣w∣∣2\min \frac{1}{2} ||w||^2min21∣∣w∣∣2
限制条件(一次项): yi⋅(w⋅xi+b)≥1(i=1,⋯ ,N)y_i \cdot (w \cdot x_i + b) \ge 1 \quad (i=1,\cdots,N)yi⋅(w⋅xi+b)≥1(i=1,⋯,N)
6. 总结
- SVM使用间隔最大化思想构造最优超平面。
- 构造出来的超平面使得其与最近的点的距离最大。
- SVM也可划分非线性数据集。
- 它通过高维中的线性超平面在低维中的投影来完成非线性的划分。因此从直观上来讲,我们的模型必定有一个升维的操作。
二.函数间隔与几何间隔
1. 函数间隔
γ~i=yi(w⋅xi+b)\widetilde{\gamma}_i = y_i(w \cdot x_i + b)γ i=yi(w⋅xi+b)
2. 几何间隔
γi=yi(w∣∣w∣∣⋅xi+b∣∣w∣∣)=γ~i∣∣w∣∣\gamma_i = y_i \left( \frac{w}{||w||} \cdot x_i + \frac{b}{||w||} \right) = \frac{\widetilde{\gamma}_i}{||w||}γi=yi(∣∣w∣∣w⋅xi+∣∣w∣∣b)=∣∣w∣∣γ i
3. 从感知机到间隔
(1). 感知机的局限与信心的度量
在感知机模型中,分类的依据是超平面 w⋅x+b=0w \cdot x + b = 0w⋅x+b=0。
- 如果 w⋅xi+b>0w \cdot x_i + b > 0w⋅xi+b>0,预测为正类(yi=+1y_i = +1yi=+1)。
- 如果 w⋅xi+b<0w \cdot x_i + b < 0w⋅xi+b<0,预测为负类(yi=−1y_i = -1yi=−1)。
感知机只关心符号(正负)是否正确。但直觉告诉我们:
- 如果一个点算出来的 w⋅xi+b=100w \cdot x_i + b = 100w⋅xi+b=100,说明它离超平面非常远,我们对把它分入正类这件事情充满信心。
- 如果算出来的 w⋅xi+b=0.01w \cdot x_i + b = 0.01w⋅xi+b=0.01,说明它几乎就贴在分界线上,我们对这个分类结果信心不足。
因此,∣w⋅xi+b∣|w \cdot x_i + b|∣w⋅xi+b∣ 的大小,就可以用来度量分类的"确信度"或"距离的远近"。
(2). 函数间隔的含义
为了把"分类是否正确"和"确信度有多大"结合起来,我们引入了公式:
γ~i=yi(w⋅xi+b)\widetilde{\gamma}_i = y_i(w \cdot x_i + b)γ i=yi(w⋅xi+b)
- 符号一致性: 如果分类正确,yiy_iyi 和 (w⋅xi+b)(w \cdot x_i + b)(w⋅xi+b) 同号,乘积必定为正数。
- 大小: 乘积绝对值越大,确信度越高。
这就是函数间隔。它非常直观,但它有一个致命的漏洞!
函数间隔的漏洞: 假设我们的超平面是 2x1+3x2−5=02x_1 + 3x_2 - 5 = 02x1+3x2−5=0。如果在方程两边同时乘以 2,变成 4x1+6x2−10=04x_1 + 6x_2 - 10 = 04x1+6x2−10=0。
在几何空间里,这两条线是完全同一条线 ,位置根本没有动!
但是,如果你去算函数间隔 γ~i\widetilde{\gamma}_iγ i,你会发现函数间隔直接翻倍了!
这意味着,只要我无限放大参数 www 和 bbb,函数间隔就可以被"虚假地"无限放大。它根本无法代表真实的物理距离。
(3). 几何间隔的含义
为了填补函数间隔的漏洞,我们要对函数间隔进行"归一化(惩罚)"。
回忆解析几何中,二维平面中一个点 (x0,y0)(x_0, y_0)(x0,y0) 到直线 Ax+By+C=0Ax + By + C = 0Ax+By+C=0 的真实物理距离公式是:
d=∣Ax0+By0+C∣A2+B2d = \frac{|Ax_0 + By_0 + C|}{\sqrt{A^2 + B^2}}d=A2+B2 ∣Ax0+By0+C∣
把它推广到高维空间,点 xix_ixi 到超平面 w⋅x+b=0w \cdot x + b = 0w⋅x+b=0 的真实距离就是:
d=∣w⋅xi+b∣∣∣w∣∣d = \frac{|w \cdot x_i + b|}{||w||}d=∣∣w∣∣∣w⋅xi+b∣
(注:∣∣w∣∣||w||∣∣w∣∣ 就是向量 www 的 L2 范数,也就是 w12+w22+...+wn2\sqrt{w_1^2 + w_2^2 + ... + w_n^2}w12+w22+...+wn2 )
我们在前面乘上标签 yiy_iyi(假设分类已经正确,去掉绝对值符号),就得到了几何间隔:
γi=yi(w∣∣w∣∣xi+b∣∣w∣∣)=γ~i∣∣w∣∣\gamma_i = y_i \left( \frac{w}{||w||} x_i + \frac{b}{||w||} \right) = \frac{\widetilde{\gamma}_i}{||w||}γi=yi(∣∣w∣∣wxi+∣∣w∣∣b)=∣∣w∣∣γ i
结论:几何间隔是除以了 ∣∣w∣∣||w||∣∣w∣∣ 的函数间隔。
现在,无论你怎么缩放参数,几何间隔永远不变,它代表的就是点到超平面的真实物理空间距离!
三.线性支持向量机
找最优超平面
0-1. 补充:凸函数
(1). 凸函数的严格数学定义
几何: 在函数图像上任意取两个点连成一条线段,这条线段上的所有点,都必须位于函数图像的上方或图像上。
代数定义: 假设函数 f(x)f(x)f(x) 的定义域是凸集,如果对于定义域内的任意两个点 x1,x2x_1, x_2x1,x2,以及任意一个比例参数 t∈0,1t \in 0, 1t∈0,1,都严格满足以下不等式:
f(tx1+(1−t)x2)≤tf(x1)+(1−t)f(x2)f(t x_1 + (1-t) x_2) \le t f(x_1) + (1-t) f(x_2)f(tx1+(1−t)x2)≤tf(x1)+(1−t)f(x2)
那么 f(x)f(x)f(x) 就是凸函数。
(注:公式左边是"横坐标取平均后,对应的函数值";右边是"两个函数值连线上的点"。前者必须小于等于后者。)
(2).凸函数性质
凸函数的任何局部极小值,在数学上被严格保证就是全局最小值(Global Minimum)。
0-2.补充:拉格朗日乘子法
(1).定义
拉格朗日乘子法是一种在多元微积分中,用于寻找受约束条件下函数局部极值(最大值或最小值)的经典数学方法。
简单来说,当你想要求解一个函数的最优解,但系统变量必须满足某些特定的"边界"或"规则"(即等式约束)时,这个方法就能派上用场。
(2).几何理解
假设你想在三维空间中找到一座山(目标函数)上的最高点,但你被限制只能沿着一条特定的小路(约束条件)行走。
- 等高线(Level Curves): 想象目标函数的等高线图。每一圈代表函数的一个固定值。
- 约束曲线(Constraint Curve): 你的约束条件在图纸上表现为一条曲线。
- 相切点(Point of Tangency): 当你沿着约束曲线走时,如果穿过一条等高线,意味着你在上坡或下坡。只有当你走到的位置,约束曲线与某条等高线刚好相切时,你才达到了这条路上的最高点或最低点。
- 梯度(Gradients): 在相切的这一点,目标函数的梯度(指向等高线增加最快方向的法向量)与约束曲线的梯度必须是平行的。
(3).数学表达
假设我们要寻找目标函数 f(x,y)f(x,y)f(x,y) 的极值,且受限于约束条件 g(x,y)=cg(x,y) = cg(x,y)=c。
由于在极值点,两者的梯度向量互相平行,我们可以引入一个比例常数 λ\lambdaλ(拉格朗日乘子),得出以下方程:
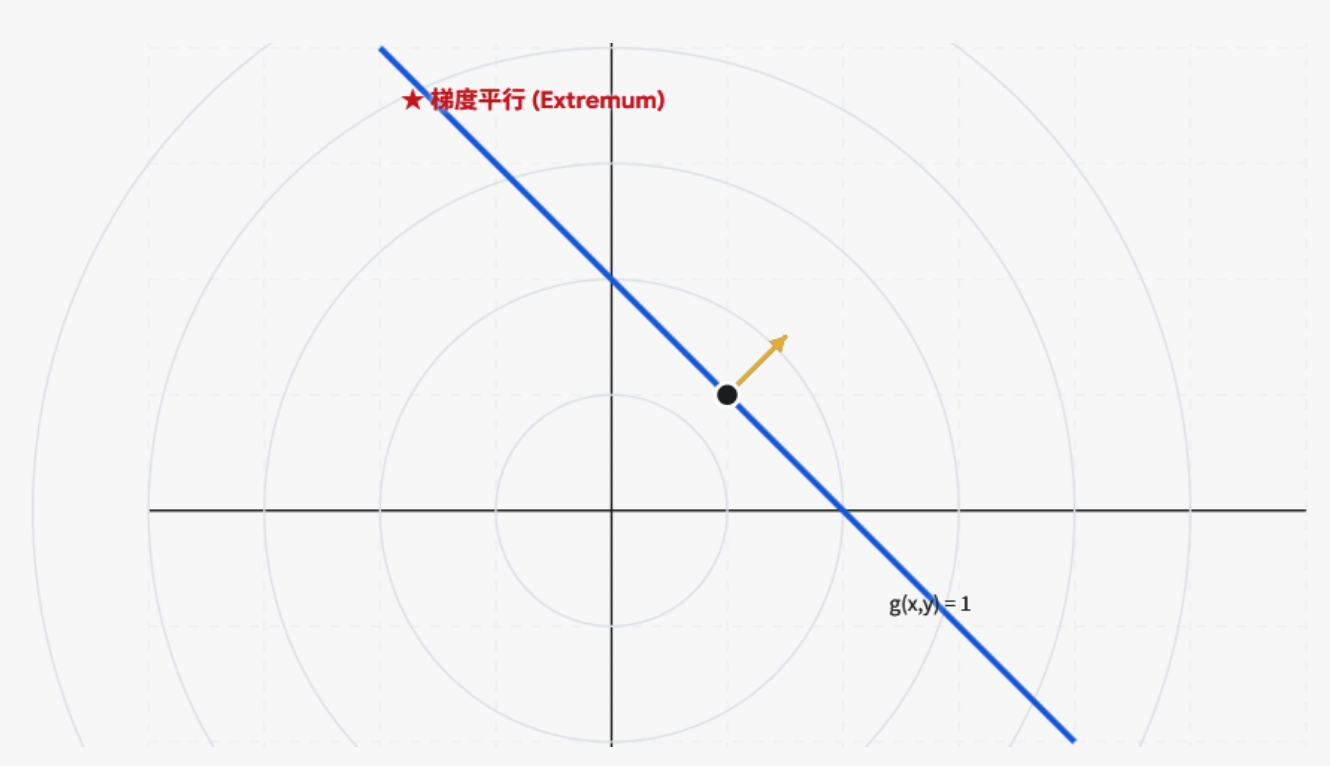
∇f(x,y)=λ∇g(x,y)\nabla f(x,y) = \lambda \nabla g(x,y)∇f(x,y)=λ∇g(x,y)
为了将上述条件和约束条件统一起来方便计算,我们通常会构造一个新的函数,称为拉格朗日函数:
L(x,y,λ)=f(x,y)−λ(g(x,y)−c)\mathcal{L}(x, y, \lambda) = f(x, y) - \lambda (g(x, y) - c)L(x,y,λ)=f(x,y)−λ(g(x,y)−c)
(4).标准求解步骤
使用拉格朗日乘子法通常包含以下三个步骤:
- 构造拉格朗日函数: 写出 L(x,y,λ)\mathcal{L}(x, y, \lambda)L(x,y,λ)。
- 求偏导数并令其为零: 对所有的变量(如 xxx、yyy)以及乘子 λ\lambdaλ 分别求偏导,并令它们等于 0。这会产生一个方程组:
- ∂L∂x=0\frac{\partial \mathcal{L}}{\partial x} = 0∂x∂L=0
- ∂L∂y=0\frac{\partial \mathcal{L}}{\partial y} = 0∂y∂L=0
- ∂L∂λ=0\frac{\partial \mathcal{L}}{\partial \lambda} = 0∂λ∂L=0 (这个等式实际上就是还原了原有的约束条件 g(x,y)=cg(x,y) = cg(x,y)=c)
- 解方程组: 联立解出所有的 x,yx, yx,y 和 λ\lambdaλ。得到的 (x,y)(x, y)(x,y) 坐标就是可能的极值点(驻点)。最后将这些点代回原目标函数 f(x,y)f(x,y)f(x,y) 中,即可确定具体的最大值或最小值。
(5).示例
问题: 寻找函数 f(x,y)=x2+y2f(x,y) = x^2 + y^2f(x,y)=x2+y2 在约束条件 x+y=1x + y = 1x+y=1 下的最小值。
-
构造函数:
L(x,y,λ)=x2+y2−λ(x+y−1)\mathcal{L}(x, y, \lambda) = x^2 + y^2 - \lambda(x + y - 1)L(x,y,λ)=x2+y2−λ(x+y−1)
-
求偏导并设为 0:
- ∂L∂x=2x−λ=0 ⟹ x=λ2\frac{\partial \mathcal{L}}{\partial x} = 2x - \lambda = 0 \implies x = \frac{\lambda}{2}∂x∂L=2x−λ=0⟹x=2λ
- ∂L∂y=2y−λ=0 ⟹ y=λ2\frac{\partial \mathcal{L}}{\partial y} = 2y - \lambda = 0 \implies y = \frac{\lambda}{2}∂y∂L=2y−λ=0⟹y=2λ
- ∂L∂λ=−(x+y−1)=0 ⟹ x+y=1\frac{\partial \mathcal{L}}{\partial \lambda} = -(x + y - 1) = 0 \implies x + y = 1∂λ∂L=−(x+y−1)=0⟹x+y=1
-
代入求解:
将 xxx 和 yyy 的表达式代入第三个方程:λ2+λ2=1 ⟹ λ=1\frac{\lambda}{2} + \frac{\lambda}{2} = 1 \implies \lambda = 12λ+2λ=1⟹λ=1。
由此得出,x=0.5x = 0.5x=0.5,y=0.5y = 0.5y=0.5。
所以最小值为 f(0.5,0.5)=0.52+0.52=0.5f(0.5, 0.5) = 0.5^2 + 0.5^2 = 0.5f(0.5,0.5)=0.52+0.52=0.5。
1. 最大间隔分离超平面
参数说明:
- γ^\hat{\gamma}γ^:函数间隔
- γ\gammaγ:几何间隔
初始目标函数:maxw,bγ\max_{w,b} \gammaw,bmaxγ
初始约束条件:yi(w∣∣w∣∣⋅xi+b∣∣w∣∣)≥γi=1,2,...,Ny_i \left( \frac{w}{||w||} \cdot x_i + \frac{b}{||w||} \right) \ge \gamma \quad i = 1, 2, ..., Nyi(∣∣w∣∣w⋅xi+∣∣w∣∣b)≥γi=1,2,...,N(即所有的点都必须被正确分类,且不能踩进间隔带里面)
因为:γ=γ^∣∣w∣∣\gamma = \frac{\hat{\gamma}}{||w||}γ=∣∣w∣∣γ^
所以等价于
约束条件:yi(w⋅xi+b)≥γ^i=1,2,...,N y_i(w \cdot x_i + b) \ge \hat{\gamma} \quad i = 1, 2, ..., Nyi(w⋅xi+b)≥γ^i=1,2,...,N
令函数间隔 γ^=1\hat{\gamma} = 1γ^=1
我们知道,如果将超平面的参数 www 和 bbb 同比例放大或缩小,超平面的实际几何位置是不会改变的,但函数间隔 γ^\hat{\gamma}γ^ 会随之同比例改变。
既然函数间隔的大小可以由我们随意缩放,为了计算方便,我们不妨强行令 γ^=1\hat{\gamma} = 1γ^=1。将 γ^=1\hat{\gamma} = 1γ^=1 代入上面的公式。
目标函数: maxw,bγ=1∣∣w∣∣\max_{w,b} \gamma = \frac{1}{||w||}w,bmaxγ=∣∣w∣∣1
约束条件: yi(w⋅xi+b)≥1i=1,2,...,Ny_i(w \cdot x_i + b) \ge 1 \quad i = 1, 2, ..., Nyi(w⋅xi+b)≥1i=1,2,...,N
转换为凸二次规划问题
- 最大化 1∣∣w∣∣\frac{1}{||w||}∣∣w∣∣1,其实就等价于最小化 ∣∣w∣∣||w||∣∣w∣∣。
- 为了后续求导方便(把平方求导产生的 2 抵消掉),我们进一步将其等价替换为最小化 12∣∣w∣∣2\frac{1}{2}||w||^221∣∣w∣∣2。
由此,我们得到了最终公式,这也是SVM硬间隔最大化的标准基本型:
目标函数: minw,b12∣∣w∣∣2\min_{w,b} \frac{1}{2}||w||^2w,bmin21∣∣w∣∣2
约束条件: yi(w⋅xi+b)−1≥0i=1,2,...,Ny_i(w \cdot x_i + b) - 1 \ge 0 \quad i = 1, 2, ..., Nyi(w⋅xi+b)−1≥0i=1,2,...,N
2. 引入拉格朗日函数
为了求解上述带有不等式约束的最优化问题,我们应用拉格朗日乘子法,通过给每一个约束条件分配一个"罚款系数"(拉格朗日乘子 α\alphaα)并将约束直接"揉"进目标函数中来构造拉格朗日函数,从而将带约束的问题变成一个纯粹的函数极值问题。
构造规则:
对每一个不等式约束 yi(w⋅xi+b)−1≥0y_i(w \cdot x_i + b) - 1 \ge 0yi(w⋅xi+b)−1≥0,我们都引入一个对应的拉格朗日乘子 αi≥0\alpha_i \ge 0αi≥0。
拉格朗日函数 LLL = 原始目标函数 - ∑αi×(约束条件)\sum \alpha_i \times (\text{约束条件})∑αi×(约束条件)
所以原本的目标函数,是为了有最大的最小距离;约束条件是为了能分对且在最小距离外。我们构建拉格朗日函数是为了将两件事放在一个公式里同时表达出来,而拉格朗日乘子是为了调整两个事情的重要性。
推导过程:
L(w,b,α)=12∣∣w∣∣2−∑i=1Nαiyi(w⋅xi+b)−1L(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{N} \alpha_i y_i(w \\cdot x_i + b) - 1L(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)−1
将后面一项的方括号展开,负负得正,就得到了:
L(w,b,α)=12∣∣w∣∣2−∑i=1Nαiyi(w⋅xi+b)+∑i=1NαiL(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{N} \alpha_i y_i(w \cdot x_i + b) + \sum_{i=1}^{N} \alpha_iL(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi
参数说明:
- αi\alpha_iαi :对应第 iii 个样本的拉格朗日乘子向量 α=(α1,α2,...,αN)T\alpha = (\alpha_1, \alpha_2, ..., \alpha_N)^Tα=(α1,α2,...,αN)T,且必须满足 αi≥0\alpha_i \ge 0αi≥0。
- L(w,b,α)L(w,b,\alpha)L(w,b,α):这就是整合了所有信息的拉格朗日函数。
目标:
minw,bmaxαL(w,b,α)\min_{w,b} \max_{\alpha} L(w,b,\alpha)w,bminαmaxL(w,b,α)
博弈的本质与惩罚机制(极小极大博弈理解):
在 minw,bmaxαL(w,b,α)\min_{w,b} \max_{\alpha} L(w,b,\alpha)minw,bmaxαL(w,b,α) 中,存在两个互相博弈的角色:
- 约束条件的判定: 括号内的 yi(w⋅xi+b)−1y_i(w \\cdot x_i + b) - 1yi(w⋅xi+b)−1,如果大于 0 代表极其安全 ,等于 0 代表恰好压线 ,小于 0 代表违规。
- 内部的 maxα\max_{\alpha}maxα(警察):它的目标是让拉格朗日函数 LLL 尽可能【最大化】。
- 如果你敢违规(结果 < 0): 负负得正,警察 αi\alpha_iαi 会直接把自己放大到 +∞+\infty+∞ ,导致整个 LLL 爆炸成正无穷大。
- 如果你极其安全(结果 > 0): 负正得负,警察为了不让 LLL 变小,只能无奈地把 αi\alpha_iαi 设为 000。此时这个样本点在公式中彻底消失,对模型毫无贡献。
- 如果你恰好压线(结果 = 0): 无论 αi\alpha_iαi 取什么正数,这一项都是 0。警察会赋予这些点 αi>0\alpha_i > 0αi>0 。(注意:这些 αi>0\alpha_i > 0αi>0 的点,就是决定最终边界的【支持向量】!)
- 外部的 minw,b\min_{w,b}minw,b(你):你的目标是让 LLL 尽可能【最小化】。
- 因为你害怕得到 +∞+\infty+∞ 的毁灭性结果,所以你(w,bw, bw,b)被"逼迫"绝对不能违规,只能乖乖地在"所有点都完全合规"的范围里,去寻找让你原本目标 12∣∣w∣∣2\frac{1}{2}||w||^221∣∣w∣∣2 最小的参数。这就完美实现了"在满足分对和在间隔外的前提下,寻找最大间隔"的初衷!
转换成:
maxαminw,bL(w,b,α)\max_{\alpha} \min_{w,b} L(w,b,\alpha)αmaxw,bminL(w,b,α)
在数学上,只要一个函数满足"对其中一个变量是凸的,对另一个变量是凹的"(称为凸凹性),它就必然存在"双重锁定"的鞍点。
L(w,b,α)=12∣∣w∣∣2−∑i=1Nαiyi(w⋅xi+b)−1L(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{N} \alpha_i y_i(w \\cdot x_i + b) - 1L(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)−1
前面的 12∣∣w∣∣2\frac{1}{2}||w||^221∣∣w∣∣2 是关于 www 的凸函数;
后面的 −∑αi...-\sum \alpha_i ...−∑αi... 是关于 α\alphaα 的线性函数(线性函数既是凸的又是凹的,完全满足条件)。
正是因为 SVM 的目标函数长成了这副极其标致的"凸凹"模样,我们才能在数学上 100% 确定:不管谁先出牌,最终算出来的一定是同一个点!
我们原先的优化目标就转化为求解这个拉格朗日函数的极小极大问题
将拉格朗日函数 L(w,b,α)=12∣∣w∣∣2−∑i=1Nαiyi(w⋅xi+b)+∑i=1NαiL(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{N} \alpha_i y_i(w \cdot x_i + b) + \sum_{i=1}^{N} \alpha_iL(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi分别对 w,bw, bw,b 求偏导数并令其等于0
{∇wL(w,b,α)=w−∑i=1Nαiyixi=0∇bL(w,b,α)=−∑i=1Nαiyi=0\left\{ \begin{aligned} \nabla_w L(w, b, \alpha) &= w - \sum_{i=1}^{N} \alpha_i y_i x_i = 0 \\ \nabla_b L(w, b, \alpha) &= -\sum_{i=1}^{N} \alpha_i y_i = 0 \end{aligned} \right.⎩ ⎨ ⎧∇wL(w,b,α)∇bL(w,b,α)=w−i=1∑Nαiyixi=0=−i=1∑Nαiyi=0
得
{w=∑i=1Nαiyixi∑i=1Nαiyi=0\begin{cases} w = \sum_{i=1}^{N} \alpha_i y_i x_i \\ \sum_{i=1}^{N} \alpha_i y_i = 0 \end{cases}{w=∑i=1Nαiyixi∑i=1Nαiyi=0
将上式代入拉格朗日函数L(w,b,α)=12∣∣w∣∣2−∑i=1Nαiyi(w⋅xi+b)+∑i=1NαiL(w,b,\alpha) = \frac{1}{2}||w||^2 - \sum_{i=1}^{N} \alpha_i y_i(w \cdot x_i + b) + \sum_{i=1}^{N} \alpha_iL(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi,得
L(w,b,α)=12(∑i=1Nαiyixi)(∑j=1Nαjyjxj)−∑i=1Nαiyi(∑j=1Nαjyjxj⋅xi+b)+∑i=1NαiL(w,b,\alpha) = \frac{1}{2} \left( \sum_{i=1}^{N} \alpha_i y_i x_i \right) \left( \sum_{j=1}^{N} \alpha_j y_j x_j \right) - \sum_{i=1}^{N} \alpha_i y_i \left( \sum_{j=1}^{N} \alpha_j y_j x_j \cdot x_i + b \right) + \sum_{i=1}^{N} \alpha_iL(w,b,α)=21(i=1∑Nαiyixi)(j=1∑Nαjyjxj)−i=1∑Nαiyi(j=1∑Nαjyjxj⋅xi+b)+i=1∑Nαi
L(w,b,α)=12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)⏟由 12∣∣w∣∣2 展开而来−∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)⏟由后半部分乘 xi 展开而来−∑i=1Nαiyib⏟由后半部分乘 b 展开而来+∑i=1NαiL(w,b,\alpha) = \underbrace{ \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) }{\text{由 } \frac{1}{2}||w||^2 \text{ 展开而来}} - \underbrace{ \sum{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) }{\text{由后半部分乘 } x_i \text{ 展开而来}} - \underbrace{ \sum{i=1}^{N} \alpha_i y_i b }{\text{由后半部分乘 } b \text{ 展开而来}} + \sum{i=1}^{N} \alpha_iL(w,b,α)=由 21∣∣w∣∣2 展开而来 21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−由后半部分乘 xi 展开而来 i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−由后半部分乘 b 展开而来 i=1∑Nαiyib+i=1∑Nαi
L(w,b,α)=(12−1)∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−b(∑i=1Nαiyi)+∑i=1NαiL(w,b,\alpha) = \left( \frac{1}{2} - 1 \right) \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - b \left( \sum_{i=1}^{N} \alpha_i y_i \right) + \sum_{i=1}^{N} \alpha_iL(w,b,α)=(21−1)i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−b(i=1∑Nαiyi)+i=1∑Nαi
L(w,b,α)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1NαiL(w,b,\alpha) = -\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_{i=1}^{N} \alpha_iL(w,b,α)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
即
minw,bL(w,b,α)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαi\min_{w,b} L(w,b,\alpha) = -\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_{i=1}^{N} \alpha_iw,bminL(w,b,α)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
接下来求 minw,bL(w,b,α)\min_{w,b} L(w,b,\alpha)minw,bL(w,b,α) 对 α\alphaα 的极大,即是对偶问题
目标函数: maxα−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαi\max_{\alpha} -\frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_{i=1}^{N} \alpha_iαmax−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
前置条件: {∑i=1Nαiyi=0αi≥0,i=1,2,...,N \begin{cases} \sum_{i=1}^{N} \alpha_i y_i = 0 \\ \alpha_i \ge 0, \quad i = 1, 2, ..., N \end{cases} {∑i=1Nαiyi=0αi≥0,i=1,2,...,N
求将 max\maxmax 转换为 min\minmin:
最终目标函数: minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαi\min_{\alpha} \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum_{i=1}^{N} \alpha_iαmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
最终约束条件: {∑i=1Nαiyi=0αi≥0,i=1,2,...,N \begin{cases} \sum_{i=1}^{N} \alpha_i y_i = 0 \\ \alpha_i \ge 0, \quad i = 1, 2, ..., N \end{cases} {∑i=1Nαiyi=0αi≥0,i=1,2,...,N
接下来就是怎么求解ααα的问题了。后面再讲。
补充说明:
当我们通过上述对偶问题求解出最优的 α∗\alpha^*α∗ 后,可以利用公式 w∗=∑i=1Nαi∗yixiw^* = \sum_{i=1}^{N} \alpha_i^* y_i x_iw∗=∑i=1Nαi∗yixi 来恢复出最优超平面的权重向量 w∗w^*w∗。
带星号代表的是"最优解
四.非线性支持向量机
在真实的业务场景中,数据极少是完美线性可分的。
这通常分为两种情况:
- 一种是存在少量噪声导致原本可分的数据越界;
- 另一种是数据本身就呈复杂的非线性分布。
1. 存在噪声:软间隔与松弛变量
在现实数据中,往往存在一些"顽固分子"(噪音或离群点)使得数据无法被一条直线完美且严格地分开。为了让模型有一定的容错率,我们允许少数点越过雷池,但必须为这种违规行为付出代价。
我们已经知道怎么找到最优超平面了,但天空中仍然有一片乌云。
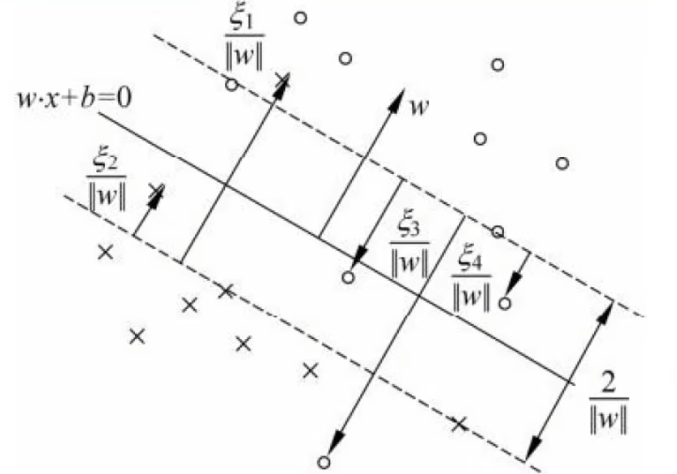
yi(w⋅xi+b)≥1−ξiy_i(w \cdot x_i + b) \ge 1 - \xi_iyi(w⋅xi+b)≥1−ξi
初始目标函数: minw,b,ξ12∣∣w∣∣2+C∑i=1Nξi\min_{w,b,\xi} \frac{1}{2}||w||^2 + C \sum_{i=1}^{N} \xi_iw,b,ξmin21∣∣w∣∣2+Ci=1∑Nξi
初始约束条件: {yi(w⋅xi+b)≥1−ξi,i=1,2,...,Nξi≥0,i=1,2,...,N\begin{cases} y_i(w \cdot x_i + b) \ge 1 - \xi_i , \quad i = 1,2,...,N \\ \xi_i \ge 0 , \quad i = 1,2,...,N \end{cases}{yi(w⋅xi+b)≥1−ξi,i=1,2,...,Nξi≥0,i=1,2,...,N
核心参数说明:
ξi\xi_iξi (Xi):松弛变量 (Slack Variable)
它代表了模型给第 iii 个样本发放的"特批违规额度"。原本硬性要求距离必须 ≥1\ge 1≥1,现在底线被放宽到了 1−ξi1 - \xi_i1−ξi。
如果 ξi=0\xi_i = 0ξi=0: 该点极其乖巧,完全在安全线以外。(完全合规)
如果 0<ξi<10 < \xi_i < 10<ξi<1: 该点突破了安全防线,踩进了缓冲带,但总体还是分对了。(轻度违规)
如果 ξi≥1\xi_i \ge 1ξi≥1: 该点不仅越过了安全线,甚至越过了中心边界,被彻底分错了!(严重违规,如图中的 ξ2\xi_2ξ2 和 ξ4\xi_4ξ4)
CCC:惩罚参数
既然发放了违规额度 ξi\xi_iξi,就绝不能让它无限大,否则模型就没有底线了。因此,我们把所有的违规额度 ∑ξi\sum \xi_i∑ξi 加进目标函数里一起求最小化。而 CCC 就是调节"宽容度"的旋钮:
当 CCC 极大时(严厉): 对违规的罚款极其沉重。模型宁可把间隔画得极窄,也要拼命保证把所有点分对(逼近硬间隔,容易过拟合)。
当 CCC 较小时(宽松): 违规的成本很低。模型为了追求更宽广的间隔(更好的泛化能力),愿意大度地容忍几个错误点。
最终目标函数: minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαi\min_{\alpha} \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum_{i=1}^{N} \alpha_iαmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
最终约束条件: {∑i=1Nαiyi=00≤αi≤C,i=1,2,...,N\begin{cases} \sum_{i=1}^{N} \alpha_i y_i = 0 \\ 0 \le \alpha_i \le C , \quad i = 1, 2, ..., N \end{cases}{∑i=1Nαiyi=00≤αi≤C,i=1,2,...,N
接下来就是怎么求解ααα的问题了。后面再讲。
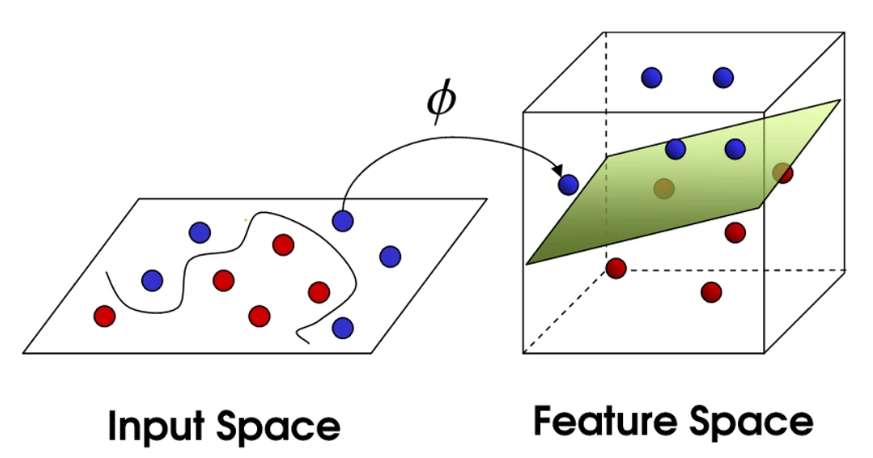
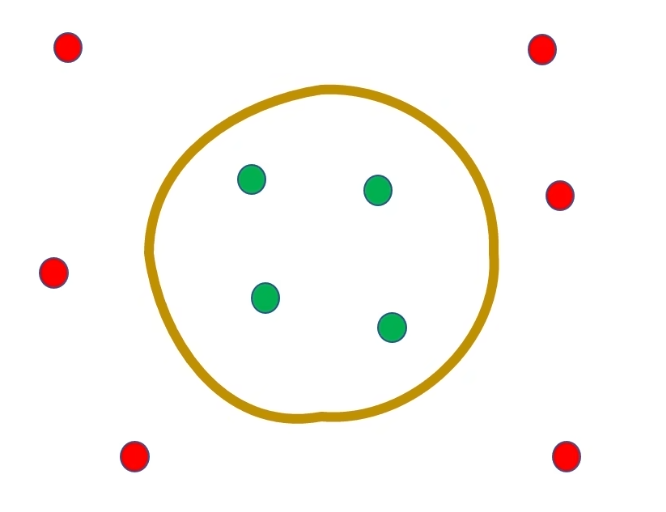
2. 广义线性可分:特征映射
对于具有非线性边界的数据(如环形分布的数据集),我们可以通过映射函数 ϕ(x)\phi(x)ϕ(x) 将低维特征空间的非线性数据映射到高维甚至无限维特征空间中,使其在高维空间中变得线性可分。
- 高维可分定理: 在一个 MMM 维空间上随机取 NNN 个训练样本并随机赋予 +1+1+1 或 −1-1−1 的标签。当维度趋于无穷时(M→+∞M \to +\inftyM→+∞),这些样本线性可分的概率趋于1(P(M)→1P(M) \to 1P(M)→1)。
- 示例映射: 将二维向量 X=x1,x2TX = x_1, x_2^TX=x1,x2T 映射为三维向量 ϕ(X)=x12,2x1x2,x22T\phi(X) = x_1\^2, \\sqrt{2}x_1 x_2, x_2\^2^Tϕ(X)=x12,2 x1x2,x22T。
映射后的优化问题(非线性可分转化为高维线性可分):
目标函数: min12∣∣w∣∣2+C⋅∑i=1Nξi\min \frac{1}{2}||w||^2 + C \cdot \sum_{i=1}^N \xi_imin21∣∣w∣∣2+C⋅∑i=1Nξi
约束条件: yi(w⋅ϕ(xi)+b)≥1−ξiy_i (w \cdot \phi(x_i) + b) \ge 1 - \xi_iyi(w⋅ϕ(xi)+b)≥1−ξi 且 ξi≥0\xi_i \ge 0ξi≥0
3. 拉格朗日函数的构造与极小极大博弈
为了把所有的约束条件"揉"进目标函数,我们为两个不等式约束分别引入了拉格朗日乘子 αi≥0\alpha_i \ge 0αi≥0 和 μi≥0\mu_i \ge 0μi≥0。
L(w,b,ξ,α,μ)=12∣∣w∣∣2+C∑i=1Nξi⏟原始目标函数−∑i=1Nαiyi(w⋅xi+b)−1+ξi⏟乘子 αi 结合间隔约束−∑i=1Nμiξi⏟乘子 μi 结合 ξi 非负约束L(w, b, \xi, \alpha, \mu) = \underbrace{\frac{1}{2}||w||^2 + C\sum_{i=1}^{N} \xi_i}{\text{原始目标函数}} - \underbrace{\sum{i=1}^{N} \alpha_i y_i(w \\cdot x_i + b) - 1 + \\xi_i}{\text{乘子 } \alpha_i \text{ 结合间隔约束}} - \underbrace{\sum{i=1}^{N} \mu_i \xi_i}_{\text{乘子 } \mu_i \text{ 结合 } \xi_i \text{ 非负约束}}L(w,b,ξ,α,μ)=原始目标函数 21∣∣w∣∣2+Ci=1∑Nξi−乘子 αi 结合间隔约束 i=1∑Nαiyi(w⋅xi+b)−1+ξi−乘子 μi 结合 ξi 非负约束 i=1∑Nμiξi
参数说明:
- w,bw, bw,b:待求的核心模型参数。
- ξi\xi_iξi :松弛变量。代表模型发放给第 iii 个样本的"特批违规额度"。
- CCC :惩罚系数。设定模型对样本违规的惩罚力度(CCC 越大越严厉,CCC 越小越宽容)。
- αi\alpha_iαi :对应"间隔约束"的乘子,监督样本是否违规,必须满足 αi≥0\alpha_i \ge 0αi≥0。
- μi\mu_iμi :对应"松弛变量非负约束"的乘子,必须满足 μi≥0\mu_i \ge 0μi≥0。
同理,我们的优化目标转化为求解该拉格朗日函数的极小极大问题:
maxα,μminw,b,ξL(w,b,ξ,α,μ)\max_{\alpha, \mu} \min_{w,b,\xi} L(w, b, \xi, \alpha, \mu)α,μmaxw,b,ξminL(w,b,ξ,α,μ)
4. 对偶问题的完整推导
第一步:分别对主变量 w,b,ξiw, b, \xi_iw,b,ξi 求偏导数并令其等于 0
{∇wL=w−∑i=1Nαiyixi=0∇bL=−∑i=1Nαiyi=0∇ξiL=C−αi−μi=0\left\{ \begin{aligned} \nabla_w L &= w - \sum_{i=1}^{N} \alpha_i y_i x_i = 0 \\ \nabla_b L &= -\sum_{i=1}^{N} \alpha_i y_i = 0 \\ \nabla_{\xi_i} L &= C - \alpha_i - \mu_i = 0 \end{aligned} \right.⎩ ⎨ ⎧∇wL∇bL∇ξiL=w−i=1∑Nαiyixi=0=−i=1∑Nαiyi=0=C−αi−μi=0
整理得到三个极其重要的代数关系:
{w=∑i=1Nαiyixi∑i=1Nαiyi=0αi+μi=C\begin{cases} w = \sum_{i=1}^{N} \alpha_i y_i x_i \\ \sum_{i=1}^{N} \alpha_i y_i = 0 \\ \alpha_i + \mu_i = C \end{cases}⎩ ⎨ ⎧w=∑i=1Nαiyixi∑i=1Nαiyi=0αi+μi=C
第二步:将关系式代回拉格朗日函数
我们将长公式展开,并把带有 ξi\xi_iξi 的项单独提取出来合并:
L=12∣∣w∣∣2−∑i=1Nαiyi(w⋅xi+b)+∑i=1Nαi+∑i=1NCξi−∑i=1Nαiξi−∑i=1Nμiξi⏟包含 ξi 的所有项L = \frac{1}{2}||w||^2 - \sum_{i=1}^{N} \alpha_i y_i (w \cdot x_i + b) + \sum_{i=1}^{N} \alpha_i + \underbrace{\sum_{i=1}^{N} C \xi_i - \sum_{i=1}^{N} \alpha_i \xi_i - \sum_{i=1}^{N} \mu_i \xi_i}_{\text{包含 } \xi_i \text{ 的所有项}}L=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi+包含 ξi 的所有项 i=1∑NCξi−i=1∑Nαiξi−i=1∑Nμiξi
L=12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−b(∑i=1Nαiyi)+∑i=1Nαi+∑i=1N(C−αi−μi)ξiL = { \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) } - { \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) } - b \left( \sum_{i=1}^{N} \alpha_i y_i \right) + \sum_{i=1}^{N} \alpha_i + \sum_{i=1}^{N} (C - \alpha_i - \mu_i) \xi_iL=21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−b(i=1∑Nαiyi)+i=1∑Nαi+i=1∑N(C−αi−μi)ξi
因为C−αi−μi=0C - \alpha_i - \mu_i = 0C−αi−μi=0,∑αiyi=0\sum \alpha_i y_i = 0∑αiyi=0
L=(12−1)∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1NαiL = \left( \frac{1}{2} - 1 \right) \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_{i=1}^{N} \alpha_iL=(21−1)i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
L=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1NαiL = -\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) + \sum_{i=1}^{N} \alpha_iL=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi
第三步:写出最终的对偶问题
虽然目标函数和硬间隔长得一样,但约束条件发生了微妙的改变。
因为我们有 αi≥0\alpha_i \ge 0αi≥0,μi≥0\mu_i \ge 0μi≥0,且 αi+μi=C\alpha_i + \mu_i = Cαi+μi=C。这意味着 αi\alpha_iαi 不能无限大了,它被死死地限制在了 CCC 的天花板之下(如果超过 CCC,μi\mu_iμi 就会变成负数,违背规定)。
综合起来,就是 0≤αi≤C0 \le \alpha_i \le C0≤αi≤C。
我们将其转换为求最小值的标准格式,最终软间隔支持向量机的对偶问题如下:
最终目标函数:
minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαi\min_{\alpha} \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum_{i=1}^{N} \alpha_iαmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
最终约束条件:
{∑i=1Nαiyi=00≤αi≤C,i=1,2,...,N\begin{cases} \sum_{i=1}^{N} \alpha_i y_i = 0 \\ 0 \le \alpha_i \le C , \quad i = 1, 2, ..., N \end{cases}{∑i=1Nαiyi=00≤αi≤C,i=1,2,...,N
总结规律:
软间隔与硬间隔的目标函数在数学形式上完全一致 ,唯一的区别仅仅是拉格朗日乘子 αi\alpha_iαi 多了一个上限约束 CCC。
接下来就是怎么求解ααα的问题了。后面再讲。
五. 核函数
直接将特征映射到极高维甚至无穷维来解决线性不可分问题时,面临的最大障碍是:www 也会随之变成无穷维,这不仅导致无法存储,且内积计算的复杂度呈指数级爆炸。核函数巧妙地化解了这一危机。
梳理一下:
- 由于公式的需要,我们需要计算原始空间中 xix_ixi 和 xjx_jxj 的内积(在实数向量中即点积)。
- 此外,我们需要将样本映射到高维去,加入映射函数为 ϕ(x)\phi(x)ϕ(x),那么 ϕ(xi)\phi(x_i)ϕ(xi) 和 ϕ(xj)\phi(x_j)ϕ(xj) 的维度数目进一步扩大,计算它们的内积会让运算变得极其复杂。(因为维度太高了)
- 我们希望存在一个函数 K(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩K(x_i, x_j) = \langle \phi(x_i), \phi(x_j) \rangleK(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩,但函数 KKK 的计算方式更简单。也就是说,我将样本通过函数升维得到 ϕ(xi)\phi(x_i)ϕ(xi) 和 ϕ(xj)\phi(x_j)ϕ(xj),接下来要计算它们的内积 ,能不能有个很简单的计算公式,计算出来的结果和 ⟨ϕ(xi),ϕ(xj)⟩\langle \phi(x_i), \phi(x_j) \rangle⟨ϕ(xi),ϕ(xj)⟩ 一样?那样我就不用再去苦哈哈地算无穷维的内积 结果了,直接用简单的函数 KKK 计算不是更好吗?
- 这个简便方式,就是核函数
1. 核函数的定义与优势
核函数 K(xi,xj)K(x_i, x_j)K(xi,xj) 本质上是一个数值标量,用来直接表示两个原本低维样本在被映射到高维特征空间后的"内积":
K(xi,xj)=ϕ(xi)Tϕ(xj)K(x_i, x_j) = \phi(x_i)^T \phi(x_j)K(xi,xj)=ϕ(xi)Tϕ(xj)
-
使用的充要条件(半正定性):
① K(xi,xj)=K(xj,xi)K(x_i, x_j) = K(x_j, x_i)K(xi,xj)=K(xj,xi) (交换性)
② 对于任意样本和系数,存在 ∑i=1N∑j=1NCiCjK(xi,xj)≥0\sum_{i=1}^N \sum_{j=1}^N C_i C_j K(x_i, x_j) \ge 0∑i=1N∑j=1NCiCjK(xi,xj)≥0 (半正定性)。
-
核技巧的优势: 能够在低维空间中直接计算出样本在高维空间的内积,从而大幅降低计算复杂度,并且完美避开了显示表达无限维特征向量的难题。
2. 常用核函数
-
多项式核函数 (Polynomial Kernel):
K(x,z)=(x⋅z+1)pK(x, z) = (x \cdot z + 1)^pK(x,z)=(x⋅z+1)p
-
高斯核函数 (Gaussian Kernel / RBF Kernel): (最常用,能够将数据映射到无穷维特征空间)
K(x,z)=exp(−∣∣x−z∣∣22σ2)K(x, z) = \exp \left( -\frac{||x - z||^2}{2\sigma^2} \right)K(x,z)=exp(−2σ2∣∣x−z∣∣2)