目录
[1 · 算法原理](#1 · 算法原理)
[2 · 算法实现(C)](#2 · 算法实现(C))
[2 - 1 · 快速排序主框架](#2 - 1 · 快速排序主框架)
[2 - 2 · Hoare版本(C)](#2 - 2 · Hoare版本(C))
[2 - 3 · lomuto前后指针法(C)](#2 - 3 · lomuto前后指针法(C))
[2 - 4 · 挖坑法(C)](#2 - 4 · 挖坑法(C))
[3 · 时间复杂度分析](#3 · 时间复杂度分析)
[3 - 1 · 理想情况](#3 - 1 · 理想情况)
[3 - 2 · 最坏情况](#3 - 2 · 最坏情况)
[4 · 基础版快排的缺陷及优化](#4 · 基础版快排的缺陷及优化)
[4 - 1 · 待排序记录有序时的缺陷](#4 - 1 · 待排序记录有序时的缺陷)
[4 - 2 · 优化取基准值,三数取中法](#4 - 2 · 优化取基准值,三数取中法)
[4 - 3 · 小区间优化](#4 - 3 · 小区间优化)
[5 · 快速排序的非递归实现](#5 · 快速排序的非递归实现)
[5 - 1 · 为什么要考虑非递归](#5 - 1 · 为什么要考虑非递归)
[5 - 2 · 基本思路](#5 - 2 · 基本思路)
[5 - 3 · 代码实现(C)](#5 - 3 · 代码实现(C))
[6 · 三路划分](#6 · 三路划分)
[6 - 1 · 快排性能的关键点](#6 - 1 · 快排性能的关键点)
[6 - 2 · 三路划分思想解析](#6 - 2 · 三路划分思想解析)
[6 - 3 · 代码实现(C)](#6 - 3 · 代码实现(C))
[7 · 自省排序](#7 · 自省排序)
导言
快速排序是一种高效的排序算法,在平均情况下具有优越的性能(时间复杂度通常为,使其在众多排序算法中脱颖而出。它广泛应用于实际系统和算法教学中,尤其在平均性能方面表现优异。
以下将简要概述本文的技术路线,帮助读者系统性地理解快速排序:
- 原理:介绍快速排序的核心思想,包括分治法策略和基准元素的选择机制。
- 实现:展示代码实现。
- 优化:讨论常见优化技巧。
1 · 算法原理
快速排序是Hoare于1962年提出的⼀种⼆叉树结构的交换排序方法。
其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两个子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
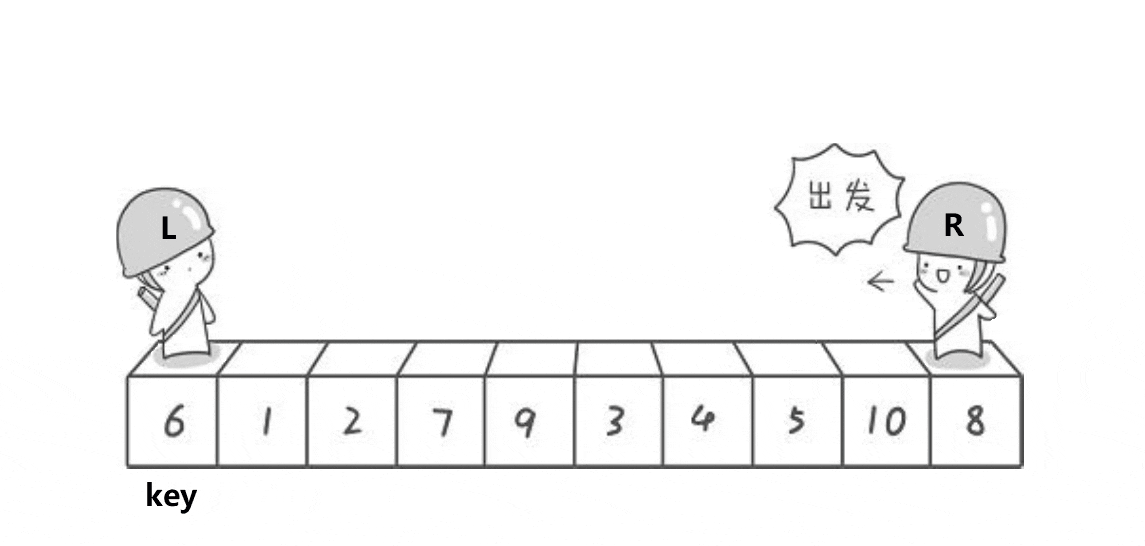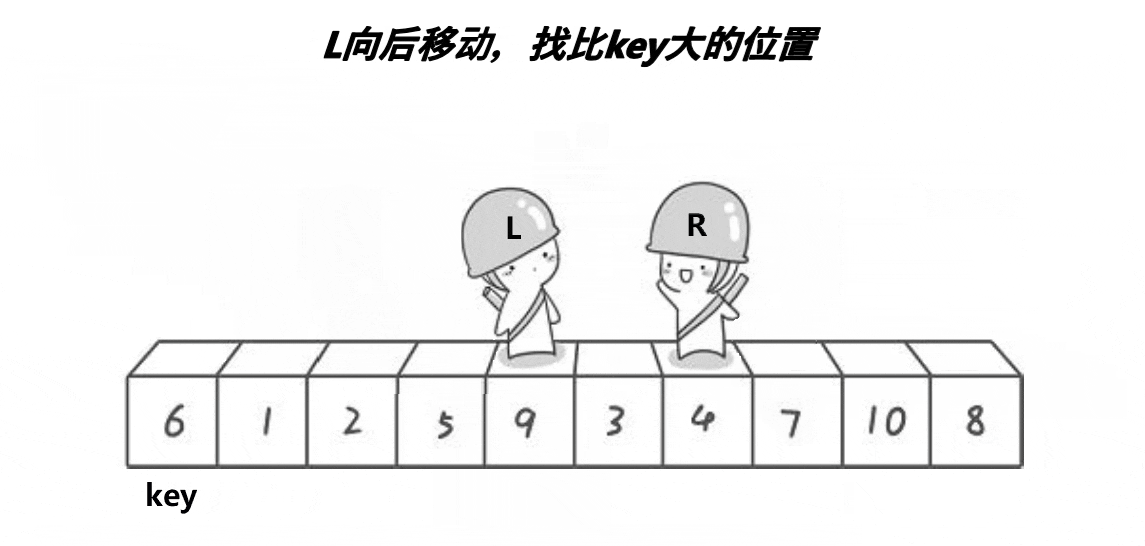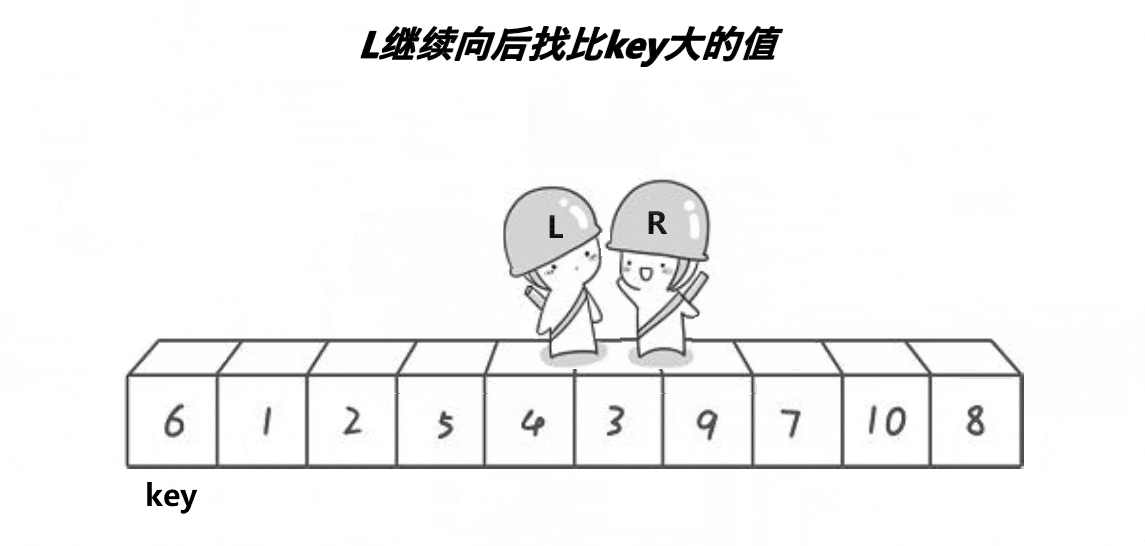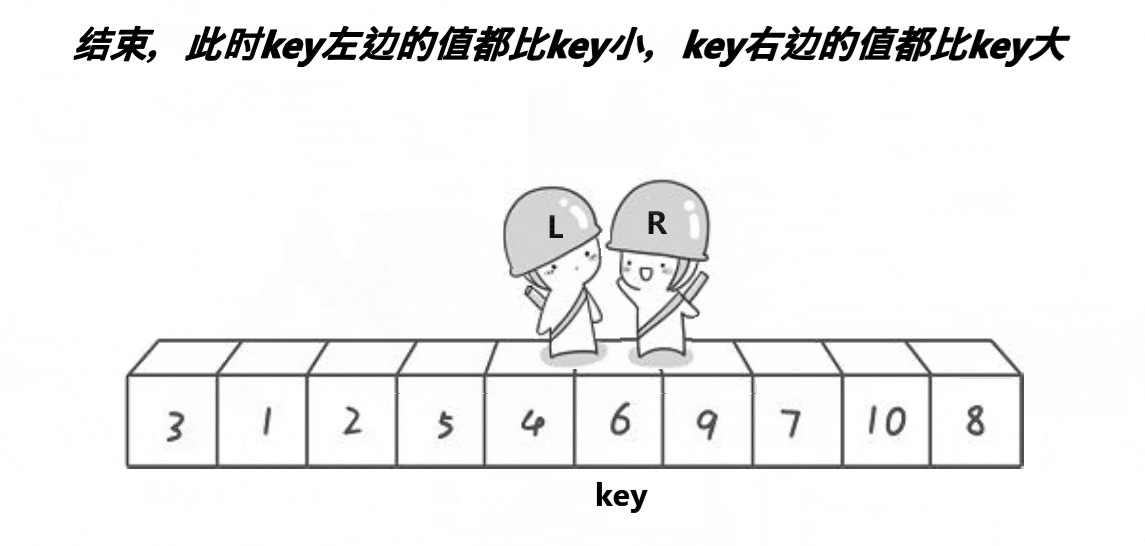
方便理解,下面是一张Hoare法实现快排的动图
2 · 算法实现(C)
2 - 1 · 快速排序主框架
通过上面的介绍,不难看出,在快速排序中,单趟将一个元素的位置确定好,并分隔出左右子区间,后续再对左右子区间进行快排,循此往复。那么快排的实现,我们可以使用递归。
因此我们可以搭建出一个快排的主框架:
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
//分成三个部分,[left,meet-1] meet [meet+1, right]
int meet = PartSort(a, left, right);
//递归
QuickSort(a, left, meet - 1);
QuickSort(a, meet + 1, right);
}将区间中的元素进行划分的 PartSort 方法主要有以下几种实现方式:
2 - 2 · Hoare版本(C)
基本思路:确定基准值,然后创建两个指针,一个从右开始向左找小,另一个从左开始向右找大,右边的先开始找**(为了确保相遇位置小于基准值)**,如果左右都找到了,那么就交换两处的值,再开始下一轮寻找,直到左右指针相等。此时将基准值处与相遇处交换。
代码实现如下:
int PartSort1(int* a, int left, int right)
{
//霍尔法
int key = left;
while (left < right)
{
//从右开始,找小,或走到left
while (left < right && a[right] >= a[key])
{
--right;
}
//左边找大,或走到right
while (left < right && a[left] <= a[key])
{
++left;
}
Swap(&a[left], &a[right]);
}
//此时key位置与 left 或 right 位置的值交换
Swap(&a[key], &a[left]);
return left;
}2 - 3 · lomuto前后指针法(C)
基本思路:创建两个指针,一般基准值定为最左边的元素,那么一个指针指向最左边(前指针),另一个指向最左边的下一个(后指针)。后指针持续向后查找,如果找到比基准值小的,那么先让前指针+1,再交换两个指针指向处的值;如果找到大于等于基准值的,前指针不动,后指针接着向后找。直至后指针走出范围,将基准处的值与前指针指向处交换,返回前指针处。
代码实现如下:
int PartSort2(int* a, int left, int right)
{
//前后指针法
int key = a[left];
int prev = left;
int cur = prev + 1;
//快指针找小
while (cur <= right)
{
if (a[cur] < key)
{
//找到了让prev的下一个位置与cur位置交换
prev++;
Swap(&a[cur], &a[prev]);
}
++cur;
}
Swap(&a[left], &a[prev]);
return prev;
}对上面的代码还能进行优化,防止自己与自己交换:
//防止自己和自己交换的写法
if (a[cur] < key && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}2 - 4 · 挖坑法(C)
基本思路:先记录下基准值,然后将基准值处当作一个坑,创建两个指针,一个从右开始向左找小,另一个从左开始向右找大,先从右开始,如果找到了,将指针指向处的值放入坑中,并且当前位置变成新的坑,随后走另一个指针的查找。直至两指针相遇,此时将基准值放入当前的坑,并返回坑的位置
代码实现如下:
int PartSort3(int* a, int left, int right)
{
//挖坑法
//先存住left位置数据,将left作为第一个坑
int key = a[left];
int hole = left;
while (left < right)
{
//右边找小
while (left < right && a[right] >= key)
{
--right;
}
//数据入坑,原位置成为新的坑
a[hole] = a[right];
hole = right;
//左边找大
while (left < right && a[left] <= key)
{
++left;
}
//数据入坑,原位置成为新的坑
a[hole] = a[left];
hole = left;
}
//循环结束,坑位置填上存的值
a[hole] = key;
return hole;
}3 · 时间复杂度分析
3 - 1 · 理想情况
理想的情况是每次分隔都在当前区间的中间位置,此时整体递归情况类似于一棵二叉树,时间复杂度为,即区间遍历 * 二叉树高度。
3 - 2 · 最坏情况
最坏情况是待排序记录有序,此时右指针会一直找不到小,直到左右指针相遇。此时对区间的分隔只分出右区间,而此时快速排序也就退化成了冒泡排序,时间复杂度为
4 · 基础版快排的缺陷及优化
4 - 1 · 待排序记录有序时的缺陷
当待排序记录有序,此时不仅存在上文所说的效率退化的问题,同时存在栈溢出的风险,因为递归的深度太深了。
4 - 2 · 优化取基准值,三数取中法
上面提到的缺陷很大原因是我们固定将最左边的值选作基准值,因此我们在选基准值的时候,比较最左边 ,中间 ,最右边的值,选它们三个的中间值作为基准值,将基准值交换给最左边的值,保证整体逻辑。
代码实现如下:
//优化取key ,三数取中
int GetMid(int* a, int left, int right)
{
int mid = left + (right - left) / 2;
if (a[left] > a[mid])
{
if (a[mid] > a[right])
{
return mid;
}
else
{
return a[left] < a[right] ? left : right;
}
}
else
{
if (a[mid] < a[right])
{
return mid;
}
else
{
return a[left] > a[right] ? left : right;
}
}
}4 - 3 · 小区间优化
将快排整体的递归看作一棵二叉树,那么在区间较小的时候,也就是在二叉树的较底层,此时区间很小,但是需要调用的递归操作很多。
对于一颗完全二叉树,最底层占整体数据的 50% , 倒数第二层占 25%, 倒数第三层占 12.5%,那么对于小区间,持续递归分割其实是很没有必要的,此时我们可以选择一个排序来帮助我们优化。
对于帮忙优化的排序的选取,会首先想到希尔排序和堆排序这两个较快速的排序,但是毕竟是小区间,发挥不出希尔排序的优势,并且堆排序还得先建个堆,在数据量小的情况下效率也没那么理想,因此小区间优化选用的是插入排序。
加上小区间优化,代码如下:
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
//小区间优化
if (right - left <= 10)
{
InsertSort(a + left, right - left + 1);
}
//分成三个部分,[left,meet-1] meet [meet+1, right]
int meet = PartSort(a, left, right);
//递归
QuickSort(a, left, meet - 1);
QuickSort(a, meet + 1, right);
}**注意:**由于我们插入排序的区间可能会偏离,所以插入排序的第一个参数需要传a + left。比如下面这种情况。
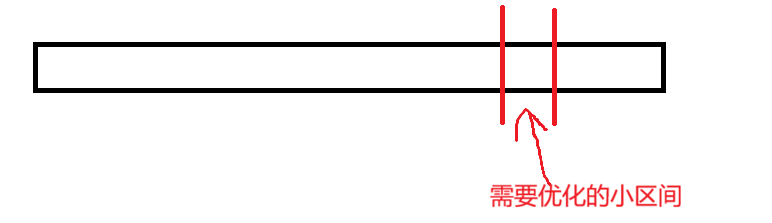
5 · 快速排序的非递归实现
5 - 1 · 为什么要考虑非递归
即使加上了上面的两个优化,但是对于递归太深,栈溢出的风险是没法解决的,这时就需要非递归的实现来优化。
5 - 2 · 基本思路
既然不能递归,但是我们需要模拟递归这个过程,这是就需要借助一个数据结构,栈和队列都可以,为了更贴近与上面递归的过程,这里选择栈。
先将left 和 right 入栈,随后走 PartSort 分割,之后判断分割出的左右区间长度,如果区间长度 <= 1 ,此时就无需对该区间排序了,而如果区间长度 > 1 ,那么这个区间仍需排序,此时将该区间的 left 与 right 入栈。直至栈为空,排序完成。
由于传参时需要知道左右区间,因此入栈时会进行两次入栈操作,一次入left,一次入right,而取数据,出栈也需进行两次,一次取left,一次取right,并且由于栈的性质,后进先出,因此取数据时需要注意顺序。
5 - 3 · 代码实现(C)
void QuickSortNonR(int* a, int left, int right)
{
Stack s;
StackInit(&s);
StackPush(&s, right);
StackPush(&s, left);
while (!StackEmpty(&s))
{
int begin = StackTop(&s);
StackPop(&s);
int end = StackTop(&s);
StackPop(&s);
int meet = PartSort(a, begin, end);
if (meet < end - 1)
{
StackPush(&s, end);
StackPush(&s, meet + 1);
}
if (meet > begin + 1)
{
StackPush(&s, meet - 1);
StackPush(&s, begin);
}
}
StackDestroy(&s);
}6 · 三路划分
6 - 1 · 快排性能的关键点
决定快排性能的关键点是每次单趟排序后,key对数组的分割,如果每次选key基本⼆分居中,那么快排的递归树就是颗均匀的满⼆叉树,性能最佳。但是实践中虽然不可能每次都是⼆分居中,但是性能也还是可控的。在用上了上面的优化之后,在绝大数情况下性能已经很好了,但是在一种情况下仍不太行:**数组中有大量重复数据时。**此时效率也会有所退化。
6 - 2 · 三路划分思想解析
三路划分,听名字也知道是划分成3个区域,即分成 小于基准值 等于基准值 大于基准值 三个区域。
实现思路:
- 取left处的值作为基准值key
- 定义一个指针cur 进行遍历
- 当cur 走到小于 key 的地方,将 cur 位置的值与left 位置的值交换,left++,cur++,由于left位置就是key值,无需二次判断
- 当cur 走到大于key 的地方,将 cur 位置的值与right位置的值交换,right--,此时cur 不加,因为right位置换过来的值是不确定的,需要再次判断
- 当cur 走到等于key 的地方,cur++
- 直至 cur > right,遍历结束,此时等于key值的区间为 left,right
6 - 3 · 代码实现(C)
typedef struct
{
int _left;
int _right;
}WayIndex;
WayIndex PartSort3Way(int* a, int left, int right)
{
int mid = GetMid(a, left, right);
Swap(&a[left], &a[mid]);
int key = a[left];
//从left+1 开始找
int cur = left + 1;
while (cur <= right)
{
if (a[cur] < key)
{
//找到小与left交换,++left
//由于换过来的是key ,不用再次判断
Swap(&a[cur], &a[left]);
++left;
++cur;
}
else if (a[cur] > key)
{
//找到大与right交换,--right,
// 不确定换过来的值,所以cur不动,再判断一次
Swap(&a[cur], &a[right]);
--right;
}
else
{
++cur;
}
}
WayIndex meet;
meet._left = left;
meet._right = right;
return meet;
}
void QuickSortBy3Way(int* a, int left, int right)
{
if (left >= right)
{
return;
}
//分成三个部分,[left,meet-1] meet [meet+1, right]
WayIndex meet = PartSort3Way(a, left, right);
//递归
QuickSort(a, left, meet._left - 1);
QuickSort(a, meet._right + 1, right);
}**注意:**由于最后部分排序最后得到的是一个等于基准值的区间,所以定义了一个结构体来进行存储。
7 · 自省排序
上面的三路划分法在应对大量重复数据的时候有优势,但正常情况下还是要比 hoare 和 lomuto 法要多进行几次交换。
C++的 sgi版本的stl 里面官配的 sort 用的是自省排序,正常情况下是快排,但是当符合某种效率退化的情况,会改变排序方式。
自省排序(introsort) 是introspective sort采用⽤了缩写,他的名字其实表达了他的实现思路,他的思路就是进行自我侦测和反省,快排递归深度太深 (sgi stl中使用的是深度为2倍排序元素数量的对数值)那就说明在这种数据序列下,选key出现了问题,性能在快速退化,那么就不要再进行快排分割递归了,改换为堆排序进行排序 。也有小区间优化 ,当区间长度 < 16 时,改为插入排序。
总结
快速排序特别适用于处理大型数据集,在软件工程中被广泛用于标准库中的排序函数实现。它是对一般随机数据非常高效的通用排序算法选择。
理解快速排序的核心在于掌握"分治"思想以及高效率的分区操作。
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。