Gemma4模型
介绍
Gemma 4 是 Google DeepMind 于 2026 年 4 月 3 日发布的新一代开源多模态大模型家族,基于 Gemini 技术,主打 "强推理 + 全场景部署 + Apache 2.0 免费商用",端侧到数据中心全覆盖。
优点
Gemma 4 有好几种大小,从能塞进手机、树莓派的,到要用服务器才跑得动的都有
规格
- E2B
- E4B
- 26B
- 31B
实践部分
查看AMD GPU信息
bash
python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"输出结果
PyTorch: 2.10.0+git8514f05
ROCm available: True
Device: AMD Radeon Graphics查看AMD显卡具体信息
命令如下
amd-smi显示结果
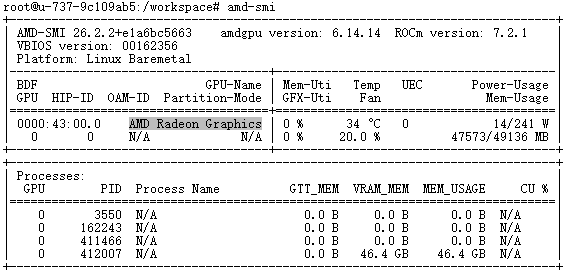
设置国内源
bash
pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/安装Modelscope
bash
pip install modelscope下载模型
bash
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"启动 vLLM 服务
bash
uv pip uninstall torchvision # 经测试,在该云环境中,需卸载重新安装这个库才能正常使用
uv pip install vllm torchvision \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U启动后的界面:
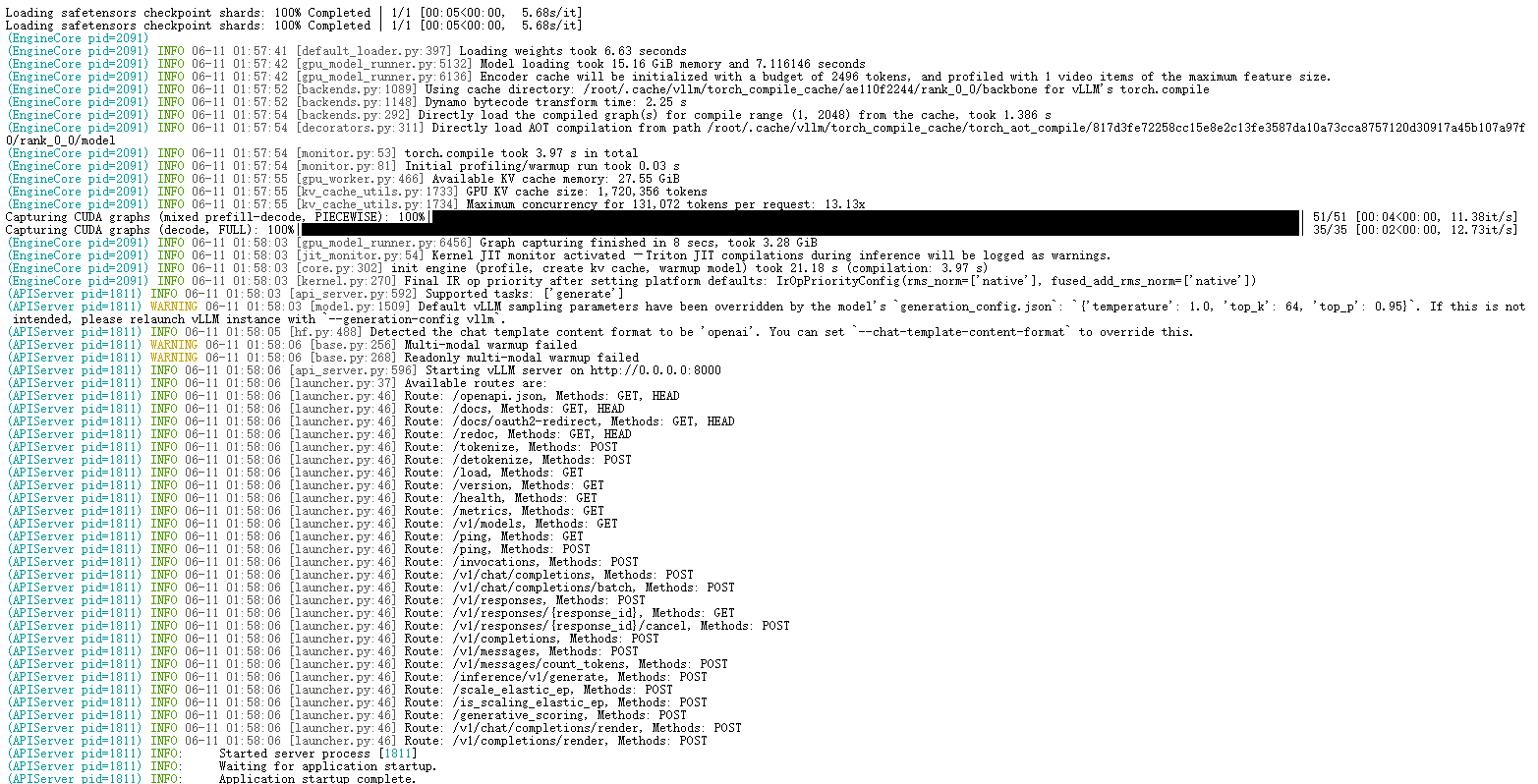
Tips:这边如果遇到显存不足,可以降低最大上下文长度后再启动,命令如下:
bash
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it --max-model-len 8192对话测试
新开一个新的终端,复制如下命令:
bash
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it出现这个界面的时候就可以开始和大模型进行对话

我们输入如下提示词:
你是谁,你能做什么`运行结果

对话完成后按两下Ctrl+C就可以退出回话了
总结
拉敲了一堆东西,那么我们到底这一节做了什么事情了,总结为以下四步:
第一步:先检查显卡能不能用。
第二步:把模型下载到本地。
第三步:用 vLLM 把模型启动成一个服务。
第四步:另开一个终端连上去对话。