导读
在大型代码库的开发场景中,AI编程助手(CodingAgent)面临的主要瓶颈并非代码理解能力,而是缺乏对代码库整体结构和关系的全局认知,导致其反复低效地"重新摸索"。Graphify通过构建代码知识图谱,为AI提供了结构化的"导航地图",将高成本的原始理解过程转化为一次性的基础设施构建。这种方法显著提升了AI的查询效率和分析精度,在测试中实现了耗时和Token消耗的大幅降低。
01 CodingAgent 在代码仓库里,90% 的时间都是迷路的
以下场景相信很多研发同学都很熟悉:当我们在一个大型代码仓库上变更代码时,需要熟悉整个项目的业务逻辑或者需要评估代码变更造成的影响,我们一般使用 CodingAgent 通读整个项目的代码:
-
CodingAgent 开始根据目录结构猜测项目入口;
-
从项目入口文件开始逐级调用工具阅读代码;
-
当上下文渐渐塞满后,开始压缩上下文,此时开始丢失上下文信息;
-
经过漫长时间的代码阅读,消耗了无数 Token 后,CodingAgent 最终给出结论,结论还可能因为上下文窗口限制导致不精确。
当我们过了一段时间又需要在该仓库上进行开发时,我们还需要将上述流程走一遍...
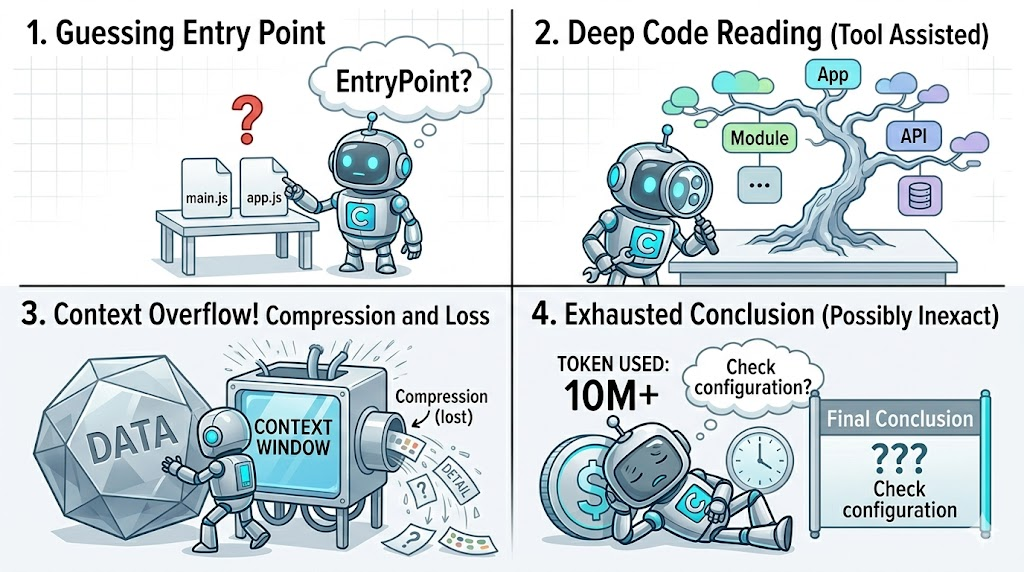
这其实不是特定 CodingAgent 的问题。Reddit 的 r/ClaudeCode 下面有条讨论热度不低的帖子,标题叫《Claude Code isn't getting worse. Your codebase is just getting bigger》------代码库一过万行,AI 就开始挑着读,而且读得顾头不顾尾。
真正的问题其实很明显:CodingAgent 的瓶颈从来不是"理解代码的能力"。模型参数再多,上下文窗口再长,你把它空投到一片从未见过的代码库里,它依然要一寸寸摸索 ------ 像新员工入职第一天就被叫去做重构,问的都是些很基础的问题:"这段代码在哪儿?谁在用它?"
如果没有地图,聪明这件事反而成了累赘。一个聪明人走进原始森林,能做的事情和一个笨人走进原始森林,其实差不多。
02 Graphify 是给 CodingAgent 的地图
故事起源于 AI 大神 Karpathy 分享的个人知识库:将论文、推文、截图和笔记等放入一个raw/文件夹,然后用 LLM 自动"编译"与维护一个 Wiki 库用于导航与检索 ------ 一种"预编译好的结构化知识库"。方法很优雅,不过他也期待:
"... there is room here for an incredible new product instead of a hacky collection of scripts."
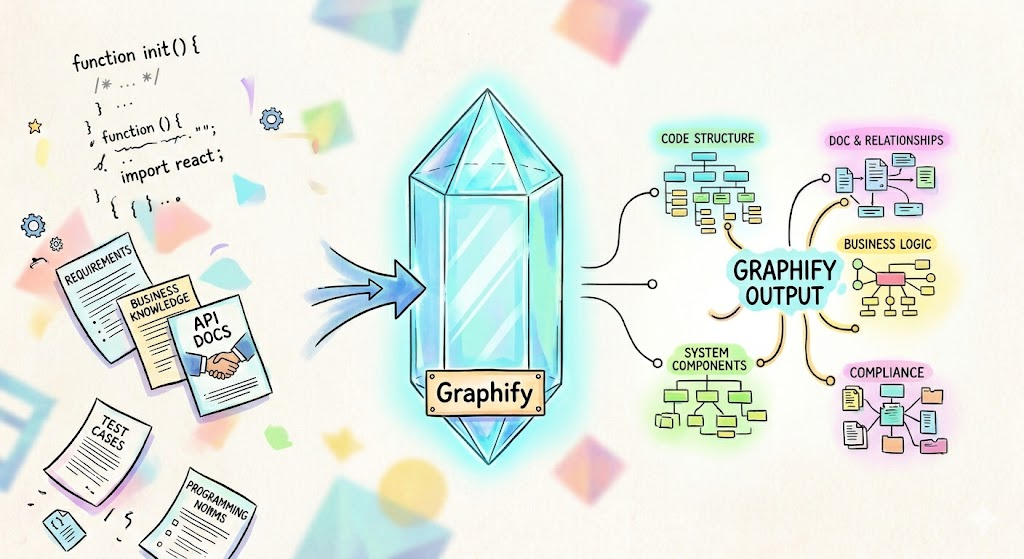
Graphify 就是这里的"Incredible product",它把 LLM-Wiki 向前推了一步:不只是 Markdown,而是知识图谱,从而打开新世界的大门。
2.1 Graphify 是用来生成代码地图的
Graphify 的官方定位是"一款 AI 编程助手的技能",它并不是大家通常认知里的个人知识管理,而是用于构建更容易被 CodingAgent 使用的知识地图。它不嵌入文件、不靠相似度检索,而是把实体和关系建成一张显式图谱,查询时在图上做遍历。
这种方式其实更接近一个资深工程师摸陌生代码库的方式------先在脑子里搭起系统的结构,再顺着结构走,而不是对源代码做一次模糊搜索。
它的核心能力是把下面这些分散的研发物料转变成一张结构化"地图":
-
代码(类、函数、导入、调用图、docstring、解释性注释)
-
需求、设计、接口文档以及论文、图片等辅助理解材料
有了这张"地图",你的 CodingAgent 就可以更好地理解、设计与编写代码。
2.2 Graphify 同时是代码仓库的第二大脑
你或许会说,现在 Claude Code、Codex 等 Agent 的 Coding 能力已经很强大了,为什么我们还需 Graphify 呢?答案就藏在"能跑"和"跑得好"之间的那道沟里。
对于边界清晰、依赖简单、业务通用且失败代价低的新项目或者模块,CodingAgent 凭自身能力确实可以完成大部分工作。但随着时间推移,代码库会积累三件东西:****复杂度、历史债、隐性知识,****项目也变得不再那么"干净"了。
复杂度来自业务本身------一个看起来简单的表单背后,可能牵着十几张数据表、三套外部系统对接、两套不同客户的定制逻辑。
历史债来自迭代------某段"特殊处理"的注释写着"临时方案",但已经稳定运行了三年没人敢动。
隐性知识最麻烦------它存在于离职工程师的脑子里,存在于没有更新的设计文档里,存在于口口相传的"这块你要小心"里。
这三样东西,CodingAgent 靠读源码是不能够稳定理解的。
问题的本质是业务与系统知识没有被结构化沉淀。只有口口相传、不健全的文档;AI 一遍遍重读源码,结果就是理解成本越来越高。
Graphify 做的事情,本质上是把这些知识从"人脑可读"变成"AI 可导航",它把代码结构、模块关系、业务语义、设计意图,编译成一张显式的知识图谱。
这张图谱不是给人看的摘要,而是给 AI 用的导航系统------告诉它系统长什么样,各部分之间怎么连接,某个概念落在哪些接口和文件上。
所以说,Graphify 更像是 AI 编程助手的"第二大脑":
LLM 是第一大脑,负责推理和代码生成;Graphify 则是第二大脑,负责告诉 LLM:现有系统怎么设计的,长什么样,代码怎么写的,某个新需求应该从哪里下手,改动可能影响到哪里,等等------而这恰恰是第一大脑在面对陌生代码库时最缺的部分。
两个大脑分工协作,CodingAgent 才能从"每次都要重新摸索"变成"直接定位、精准作答"。
2.3 为什么不直接使用 LLM:上下文再大,也只是个漏斗
Microsoft Research 2025 年做过一组实验,结论挺直白:LLM 的上下文利用率在 100K token 之后就会掉到 60% 上下。你塞得越满,它输出得越糟------不是窗口容量的问题,是注意力分配的问题。
Chroma 的 "Context Rot" 研究把这件事扒得更透。他们测了 GPT-4.1、Claude 4、Gemini 2.5 这一大批主流模型,共 18 个,结论惊人一致:token 越多,质量越差,哪怕还没撞到窗口的上限。
Morph LLM 的实测更具体------Claude Code 跑一个 35 分钟的任务,通常会累积 80K 到 150K 的 token 消耗。就算你的模型挂着 1M 的窗口,50K 左右它就已经开始犯糊涂。
打个比方:1M 上下文像一个超大号的冰箱------你觉得这下能塞下一家人一周的菜了。但 AI 真正需要找昨天那盒牛奶的时候,它站在冰箱门口翻半天,面前一片琳琅满目,就是找不出来。
2.4 为什么不使用 Vector RAG:RAG 是个近视眼
现在主流 AI Agent 的检索方案叫 Vector RAG------把代码、把文档切成小块,做向量化,再做相似度匹配。简单、通用、拿来就能用。
但它有一个永远过不去的短板:它只能找出"长得像"的东西,找不到"逻辑上连着"的东西。
FalkorDB 拿 Diffbot 的 KG-LM Benchmark 做过一组对比,数字相当扎心。单跳查询,比如"重置密码怎么办",Vector RAG 能答对 94%,和 GraphRAG 基本打平。但一旦进入多跳------"找出签约人也批准了附录的合同"------Vector RAG 的准确率从 94% 骤降到 34%。再复杂一点,"批准这笔预算的人的下属是谁?",Vector RAG 只剩 28%,GraphRAG 稳稳站在 89%。文档规模一过 10 万,Vector RAG 有四成的查询直接失败。
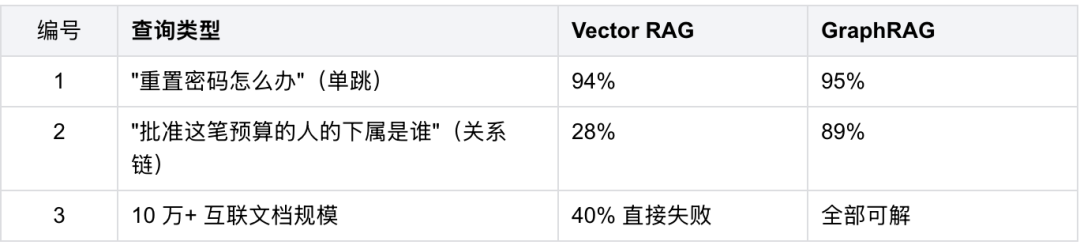
这个短板在代码世界里体现得更露骨。"谁调用了调用 X 的函数?"、"这个数据结构一共有多少个消费者?"------Vector RAG 能把相关的片段分别搜出来,就是没办法把它们串成一条线。它像一个近视眼,只看清眼前那一小块相似度,读不到背后藏着的关系网。
03 上手 Graphify:快速构建代码仓库知识图谱
现在拿一个我们的真实项目 Dave 流程引擎来看看 Graphify 可以如何帮助 AI 认识一个大型软件系统的,该代码仓库共计 253 个文件,约 67,703 行代码。
3.1 安装
全局安装 Graphify 并于 Claude Code 中安装 Skill,安装文档请参考:https://github.com/safishamsi/graphify/blob/v7/README.md
pip install graphifyy && graphify installPyPI 包当前暂时叫
graphifyy,因为graphify这个名字还在回收中。CLI 命令和 skill 命令仍然都是graphify。
安装完成后,会于~/.claude/skills/graphify目录下安装 SKILL.md 文件。
3.2 如何生成图谱
从项目根目录启动 Ducc,调用 graphify skill 生成图谱:
> ./graphify .
⏺ 生成详细步骤,此处省略...
⏺ ---
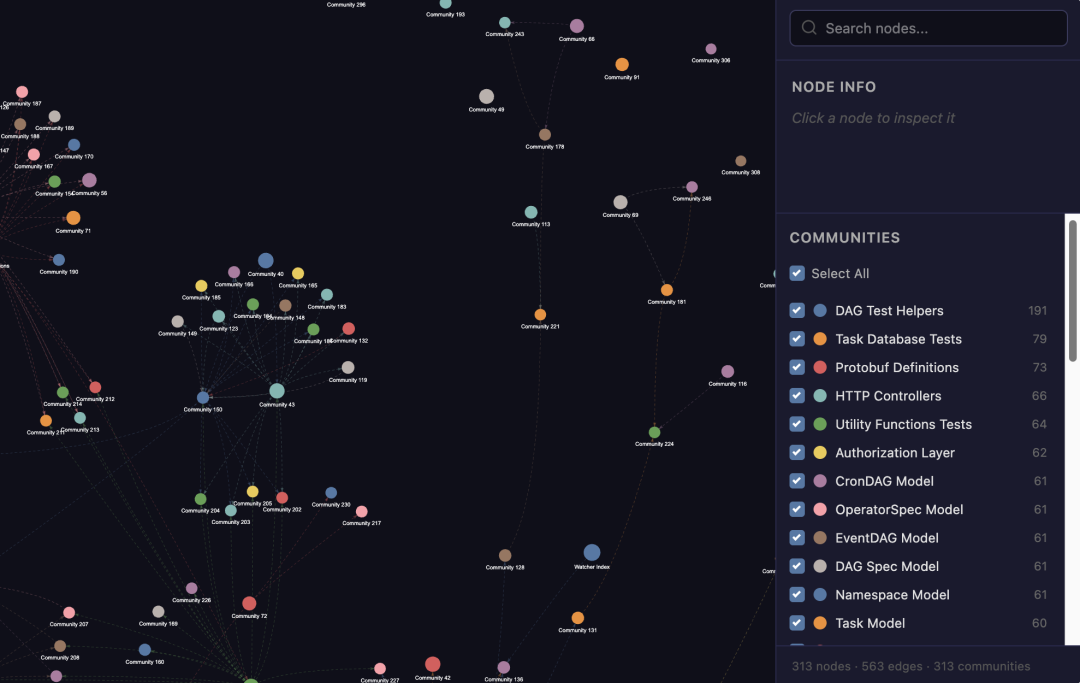
Graph complete. Outputs in /Users/zhangjinlong01/Documents/projects/bsp/dave/server/src/graphify-out/
graph.html - interactive graph (community view, 313 nodes), open in browser
GRAPH_REPORT.md - audit report
graph.json - raw graph data
Token reduction: 10x fewer tokens per query (256k words → ~34k tokens per question)
---初始化创建图谱使用 claude sonnet 4.6 模型,共耗时 5 分钟 23 秒,消耗 tokens:2.4k input、20.6k output。
图谱生成完成后,在项目根目录下会自动生成graphify-out目录,在该目录下生成以下文件:
> tree -LACa 1 ./graphify-out/
# ./graphify-out/
# ├── .graphify_labels.json
# ├── .graphify_python
# ├── .graphify_root
# ├── GRAPH_REPORT.md <-- 摘要报告
# ├── cache <------------ 增量缓存
# ├── cost.json
# ├── graph.html <------- 可交互图谱
# ├── graph.json <------- 可持久查询的图结构
# ├── manifest.json
# └── wiki <------------- 构建可供 Agent 抓取的 wiki(index.md + 每个 community 一篇文章)生成的可视化图谱一览:
3.3 如何使用图谱
在 CodingAgent 中可以通过以下 3 种方式使用图谱。
常驻模式
CLAUDE.md 文件中增加了以下系统指令,让 AI 在回答问题或者试图 grep/glob 搜索时,优先看"地图",而不是直接看代码:
## graphify
This project has a knowledge graph at graphify-out/ with god nodes, community structure, and cross-file relationships.
Rules:
- ALWAYS read graphify-out/GRAPH_REPORT.md before reading any source files, running grep/glob searches, or answering codebase questions. The graph is your primary map of the codebase.
- IF graphify-out/wiki/index.md EXISTS, navigate it instead of reading raw files
- For cross-module "how does X relate to Y" questions, prefer `graphify query "<question>"`, `graphify path "<A>" "<B>"`, or `graphify explain "<concept>"` over grep --- these traverse the graph's EXTRACTED + INFERRED edges instead of scanning files
- After modifying code, run `graphify update .` to keep the graph current (AST-only, no API cost).显示触发
显示触发是通过使用/graphify技能实现的:
/graphify query "DAG流程是如何进行调度的"
/graphify explain "Task Controller"
/graphify path "Task Controller" "Etcd Watcher / Dispatcher"MCP
Graphify 同时也提供了 MCP 以供 AI 调用,此种方式在日常使用中非常见方式,因此不在此赘述。
如何更新图谱
软件是一个不断更新迭代的系统,那么当代码或者文档发生修改后,如何保持知识图谱的同步,防止知识"过期"?可以使用技能:
/graphify update .如果说第一次建图就像数据库的"初始化索引",后面则更像"增量维护索引",Graphify 生成的图谱应该像代码一样进入仓库维护。Graphify 提供了较完善的自动维护手段,包括:

04 揭开面纱:原理拆解
4.1 生成阶段:把知识写成普通文件
在你调用技能生成图谱后,其创建过程可以粗略表示如下:

第一阶段:AST 提取
用 Tree-sitter 解析 21 种主流语言。Tree-sitter 是增量式 parser 生成器,每种语言都有社区维护的 grammar------丢进去源代码,吐出结构化的语法树。
Graphify 遍历这棵树,把函数定义变成节点,把 import 变成依赖边,把函数调用变成调用边。
规则驱动,整个过程一点 LLM token 都不用消耗。
第二阶段:LLM 语义抽取
AST 只看得到结构,看不到"这个函数想做什么"。此时会并行调用 Claude 子 Agent 处理文档、论文和图片,从中提取概念、关系和设计动机,和前面抽取的 AST 节点连在一起,形成一个"代码 + 语义"的双层图。
相对更结构化的代码,文档的语义抽取则需要让模型先读取文档,再抽取其中的概念、关系、理由、相似性等,然后把这些结果写入 Graph。
特别注意,文档的抽取结果只是一个核心语义层 --- 保存了"文档中的核心语义概念及它们之间的关系",而不是拆碎的原文(不同于 RAG)。
第三阶段:Leiden 社区聚类
这是图论里的一个经典算法,比老式的 Louvain 算法在稳定性上更好。它会将图谱中的高度相关的节点关系组织成一个个"主题"。------这个概念其实和微信好友圈差不多。
比如,代码或文档里那些靠得很近、互相频繁引用的部分,会"长成"一个社区。这个结果很有价值,因为它更接近真实的软件结构。
每个社区代表一个功能簇:可能是一个微服务,可能是一个领域模块,可能是一个独立的业务逻辑组。
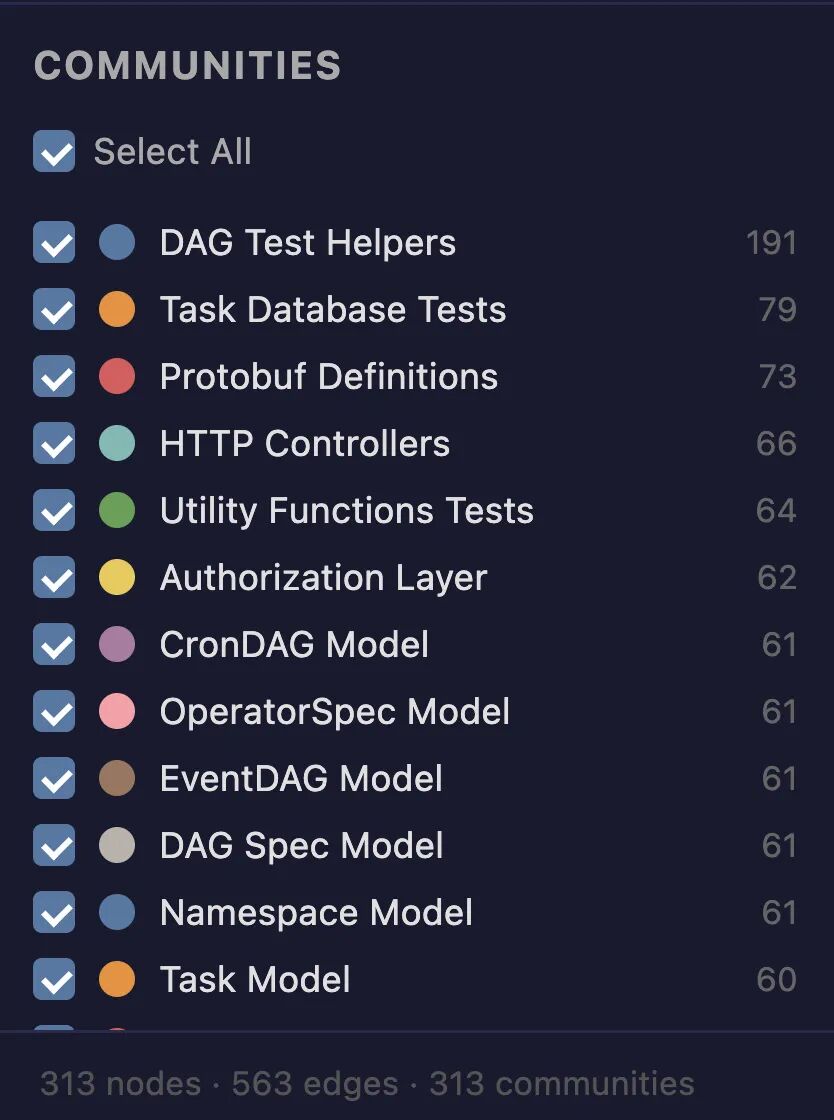
第四阶段:输出结果
将结构化结果生成为 GRAPH_REPORT、graph.json、graph.html 等不同视图,分别服务于不同的使用场景。
Graphify 的输出中可以看到一些 "God Nodes",这是指连接度特别高、能代表系统核心抽象的枢纽节点。还有 "Hyper Edges",这是表示一种多节点的 Group 关系,比如"这几个模块共同组成一个流程"。
4.2 查询阶段
在没有图谱之前,通常只能由模型根据输入问题进行推理,比如首先从目录结构推断程序入口,然后逐步文件探索;或者关键词做 grep/blob 查找,再对一些关联文件读取分析。
这种方式对小型且结构清晰的代码库是有效果的,但对于中大型的代码仓库,最大的问题是覆盖度有限导致分析偏差,Token 消耗较大。
而在 Graphify 里的执行过程大致如下:
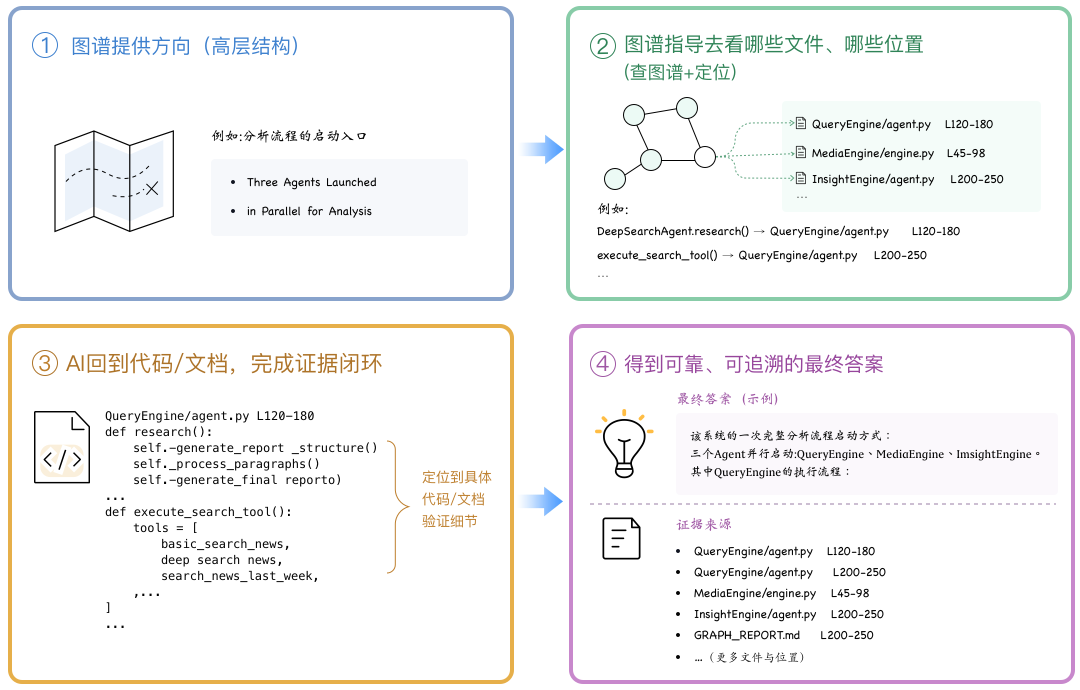
所以,大部分时候执行/graphify query不是直接从图谱里得到答案,而是:
-
图谱先给 AI 助手提供方向(地图+定位)
-
图谱告诉 AI 助手去看哪些源文件、哪些位置
-
AI 助手通过代码或文档完成证据闭环,得到答案
05 效果对比:有图谱 vs 无图谱
官方给了一个很抓眼球的数据:在混合语料例子里,查询时最多能做到 71.5x fewer tokens。
这不是说所有项目都能固定达到这个数字,但它传达的方向很明确:真正昂贵的不是模型本身,而是每次都重新读原始文件。
Graphify 的做法,是把高成本的"原始理解"变成一次性构建,把后续查询变成低成本图谱导航。这也是为什么它的价值不只是可视化,而是"把理解变成基础设施"。
5.1 查询业务执行流程
【测试问题】
通读项目代码,给出 DAG 流程从创建 -> DAG 调度执行 -> Task 调度执行 -> DAG 执行完成(含各种完成态)的完整流程
【测试方法】
在使用 Graphify 与不使用 Graphify 增强的两种场景下,分别让 CodingAgent 自主探索,输出答案,并对比各自所花时间、Token 成本。
关键约束:限制 AI 不能参考任何项目中已有的说明与报告文档;防止 AI 参考已有的结论性信息。
【测试工具】
Claude Code/Claude Sonnet 4.6,为了更务实的考察 Graphify 的效果,这里特地没有使用最强模型。
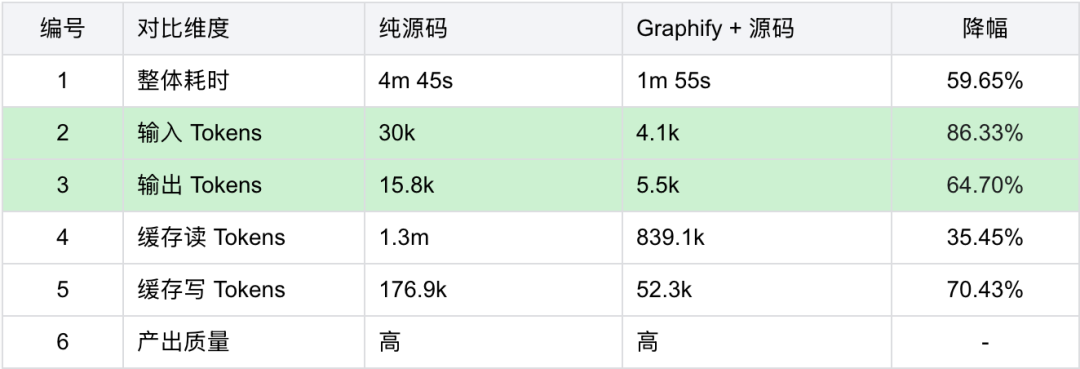
【测试结论】
使用 Graphify + 源码时,较使用纯源码,耗时降低约 60% ,输入输出 Tokens 降低了约 80%。
【测试过程】
使用纯源码
执行过程:
成本消耗:
产出:
现在我已经掌握了所有关键代码。让我来分析 Bug 根因并生成解决方案。
---
## Bug 根因分析与解决方案
### 核心问题
三个场景判断"是否允许手动执行"时,**对上游状态的判断逻辑不一致,且均未结合 TriggerRules 进行精细化判断**。
---
### 场景对比表
| 场景 | 位置 | 上游完成态判断 | 是否结合 TriggerRule |
|------|------|--------------|---------------------|
| 1. DAG 详情接口 | `service/dag.go:587` | `TS_SUCCESS` \| `TS_IGNORED` | ❌ 没有 |
| 2. 手动触发接口 | `service/task.go:672--673` | `TS_SUCCESS` \| `TS_FAILED` \| `TS_UPSTREAM_FAILED` \| `TS_SKIPPED` | ❌ 没有 |
| 3. 调度器 | `scheduler/scheduler.go:764` | `pendingTask != nil`(无任何上游状态校验) | ✅ 间接(由调用链保证) |
---
### Bug 1:DAG 详情接口 `canRunOperatorManually`
**文件:** `service/dag.go:575--594`
**问题:**
```go
// 当前代码:只允许 TS_SUCCESS 和 TS_IGNORED
if t.Task.GetState() != pb.TaskProto_TS_SUCCESS && t.Task.GetState() != pb.TaskProto_TS_IGNORED {
return false
}
```
1. 上游状态集合过窄。例如,上游节点因为其上游失败而变为 `TS_UPSTREAM_FAILED` 或 `TS_SKIPPED` 时,当前节点如果 TriggerRule 是 `ALL_FAILED`/`ONE_FAILED`/`ALWAYS`,本应允许手动执行,但被错误地拦截了。
2. 完全没有 TriggerRule 逻辑,对所有节点一视同仁只允许上游全成功的情况。
---
### Bug 2:手动触发接口 `ScheduleManually`
**文件:** `service/task.go:667--678`
**问题:**
```go
// 当前代码:只要上游任务"已完成"(4种终态之一)就放行
switch upstreamTask.Task.GetState() {
case pb.TaskProto_TS_SUCCESS, pb.TaskProto_TS_FAILED, pb.TaskProto_TS_UPSTREAM_FAILED, pb.TaskProto_TS_SKIPPED:
continue
}
// else: 上游不存在任何 task → 直接拒绝(第676行)
```
1. 上游存在 `TS_FAILED`/`TS_UPSTREAM_FAILED`/`TS_SKIPPED` 时一律放行,但对于默认 TriggerRule(`ALL_SUCCESS`)的节点,上游失败应当拒绝手动触发(因为该节点理应被标记为 `TS_UPSTREAM_FAILED`,不应再手动触发)。
2. 上游不存在 Task 时直接拒绝,但对于 `TRIGGER_RULE_ALWAYS` 节点,没有上游 task 也应该允许手动触发。
3. 与 DAG 详情接口判断逻辑不一致,导致"详情页显示可手动执行,但触发时报错"或"详情页显示不可手动执行,但实际可以触发"的矛盾。
---
### Bug 3:调度器 `markOperatorAsRunning`
**文件:** `scheduler/scheduler.go:764--766`
**问题:**
```go
// 当前代码:有 pendingTask 就放行,不再校验上游状态是否满足 TriggerRule
if (dag.GetManually() || origOp.GetManually()) && pendingTask == nil {
return
}
```
调度器依赖调用链中更上层的 `triggeredState` 来过滤,但这里有个漏洞:`markOperatorAsRunning` 被调用时,上游状态已经满足了 `TriggerRule` 的条件(`TS_RUNNING` 状态),所以调度器本身逻辑是对的,但**缺乏注释说明**,且与场景1、2的拒绝逻辑在语义上形成割裂,容易引发混淆性 Bug。更关键的是,`ScheduleManually` 写入 `pendingTask` 时没有校验 TriggerRule,导致调度器会执行本不应该被手动触发的节点。
---
### 解决方案
**核心思路:** 提取一个统一的 `canRunManuallyWithTriggerRule` 辅助函数,三个场景共用同一套判断逻辑。
#### Step 1:在 `service/dag.go` 中重写 `canRunOperatorManually`,引入 TriggerRule 判断
```go
// canRunOperatorManually 判断一个 Operator 是否可以被手动触发执行。
// 规则:
// 1. DAG 必须处于 RUNNING 状态
// 2. DAG 或 Operator 至少有一个设置了 manually=true
// 3. 所有直接上游 Operator 必须已有 Task,且结合 TriggerRule 判断上游状态是否满足触发条件
func canRunOperatorManually(vDag model.VersionedDag, op *pb.OperatorProto, vTasks []model.VersionedTask) bool {
if vDag.Dag.GetState() != pb.DagProto_DS_RUNNING {
return false
}
if !vDag.Dag.GetManually() && !op.GetManually() {
return false
}
return upstreamSatisfiesTriggerRule(vDag.Dag.GetDagSpec(), op, vTasks)
}
// upstreamSatisfiesTriggerRule 结合 TriggerRule 判断上游状态是否满足当前节点的触发条件。
func upstreamSatisfiesTriggerRule(dagSpec *pb.DagSpecProto, op *pb.OperatorProto, vTasks []model.VersionedTask) bool {
upstreamOps := util.FindDirectUpstreamOperators(dagSpec, op)
if len(upstreamOps) == 0 {
// 无上游节点,任何 TriggerRule 均可直接触发
return true
}
var successCount, failedCount, skippedCount, total int
total = len(upstreamOps)
for _, upstreamOp := range upstreamOps {
vTask, ok := util.SliceFinds(vTasks, func(vt model.VersionedTask) bool {
return vt.Task.GetOperator().GetName() == upstreamOp.GetName()
})
if !ok {
// 上游节点尚未有 Task(未执行),对于 ALWAYS 规则以外的情况均不满足
// 统一归为"未完成",由下方 TriggerRule 分支处理
return false
}
switch vTask.Task.GetState() {
case pb.TaskProto_TS_SUCCESS, pb.TaskProto_TS_IGNORED:
successCount++
case pb.TaskProto_TS_FAILED, pb.TaskProto_TS_UPSTREAM_FAILED:
failedCount++
case pb.TaskProto_TS_SKIPPED:
skippedCount++
default:
// 上游处于运行中/等待中等非终态,尚未完成
return false
}
}
// 所有上游都已到达终态,按 TriggerRule 判断是否满足触发条件
switch op.GetTriggerRule() {
case pb.OperatorProto_TRIGGER_RULE_ALL_SUCCESS:
// 全部成功(或 IGNORED)才允许
return failedCount == 0 && skippedCount == 0
case pb.OperatorProto_TRIGGER_RULE_ONE_SUCCESS:
// 至少一个成功
return successCount > 0
case pb.OperatorProto_TRIGGER_RULE_ALL_FAILED:
// 全部失败
return failedCount == total && successCount == 0 && skippedCount == 0
case pb.OperatorProto_TRIGGER_RULE_ONE_FAILED:
// 至少一个失败
return failedCount > 0
case pb.OperatorProto_TRIGGER_RULE_ALWAYS:
// 无论上游状态如何均可触发(上游到达任意终态即可)
return successCount+failedCount+skippedCount == total
default:
return false
}
}
```
> `TS_IGNORED` 在语义上等同于 `TS_SUCCESS`(人工跳过,不影响下游),归入 `successCount`。
#### Step 2:在 `service/task.go` 的 `ScheduleManually` 中复用同一判断逻辑
```go
// 替换原有的上游状态逐个遍历判断(lines 667--678)
// 改为调用统一的 upstreamSatisfiesTriggerRule
vTasks, _ := ts.ti.GetDagTasks(ns, id)
if _, ok := util.SliceFinds(vTasks, func(t model.VersionedTask) bool {
return t.Task.GetOperator().GetName() == op.GetName()
}); ok {
return &util.BadRequestError{Msg: "the task has been scheduled already"}
}
if ok, _ := ts.scs.CanSchedule(dag, toScheOp, time.Now()); !ok {
return &util.BadRequestError{Msg: "op is denied to schedule by scheduleControl"}
}
// ★ 改为使用 upstreamSatisfiesTriggerRule 统一判断
if !upstreamSatisfiesTriggerRule(dagSpec, toScheOp, vTasks) {
return &util.BadRequestError{Msg: "upstream state does not satisfy trigger rule for manual execution"}
}
```
由于 `upstreamSatisfiesTriggerRule` 当前在 `service/dag.go` 中,需要将其移到两个 service 都能访问的位置(建议放在 `util/` 包或 `service/` 包中作为包级函数)。
#### Step 3:调度器无需改动,但需补充注释
`scheduler/scheduler.go:762--766` 的逻辑是正确的(调度器的 TriggerRule 校验在更上层的 `triggeredState` 中完成),只需补充注释说明:
```go
// Check whether the operator needs to be scheduled manually.
// Presence of 'pendingTask' means the operator has been scheduled manually via ScheduleManually(),
// which already validates upstream state against TriggerRule before writing the pending task.
// If no pendingTask exists, skip auto-scheduling for manually-configured operators.
if (dag.GetManually() || origOp.GetManually()) && pendingTask == nil {
logger.Info("op needs to be scheduled manually")
return
}
```
---
### 重构后的一致性对比
| 场景 | 修改后逻辑 | TriggerRule |
|------|-----------|-------------|
| 1. DAG 详情 `canRunOperatorManually` | 调用 `upstreamSatisfiesTriggerRule` | ✅ 结合 |
| 2. 手动触发 `ScheduleManually` | 调用 `upstreamSatisfiesTriggerRule` | ✅ 结合 |
| 3. 调度器 `markOperatorAsRunning` | 依赖 `triggeredState`(上层保证)+ 补充注释 | ✅ 已有保证 |
---
### 各 TriggerRule 下的行为说明
| TriggerRule | DAG 详情显示可手动执行的条件 | 手动触发允许的条件 |
|---|---|---|
| `ALL_SUCCESS`(默认) | 所有上游 SUCCESS/IGNORED | 同左 |
| `ONE_SUCCESS` | 至少 1 个上游 SUCCESS/IGNORED | 同左 |
| `ALL_FAILED` | 所有上游 FAILED/UPSTREAM_FAILED | 同左 |
| `ONE_FAILED` | 至少 1 个上游 FAILED/UPSTREAM_FAILED | 同左 |
| `ALWAYS` | 所有上游已达终态(任意状态) | 同左 |
---
### 文件改动汇总
| 文件 | 改动 |
|------|------|
| `service/dag.go:575--594` | 重写 `canRunOperatorManually`,引入 `upstreamSatisfiesTriggerRule` |
| `service/dag.go`(新增) | 新增 `upstreamSatisfiesTriggerRule` 函数(或移至 `util/`) |
| `service/task.go:667--678` | 替换上游状态遍历逻辑,改为调用 `upstreamSatisfiesTriggerRule` |
| `scheduler/scheduler.go:762--766` | 补充注释,无逻辑改动 |使用 Graphify + 源码
执行过程(在此过程中读取的很多文件是通过图谱定位的):
成本消耗:
产出:
AG 生命周期流程:
---
## DAG 完整生命周期流程
### 一、DAG 创建
```
HTTP POST /v1/oos/dag
└── DagController.Add() [controller/dag.go:52]
└── DagService.Add() [service/dag.go:74]
├── ForCreate() [service/dag.go:151]
│ ├── 生成 dagID (d-xxxx)
│ ├── DereferenceDagSpec() 解析 ref 引用
│ ├── ValidateGraph() 拓扑校验(无环等)
│ └── 检查 childDepth ≤ maxChildDepth
│
├── 无 Semaphore → dm.Add(ctx, dag) 写入 etcd,State=DS_RUNNING
└── 有 Semaphore:
├── Conflict=REJECT → runDagWithSemaphore() 原子事务写入,State=DS_RUNNING
└── Conflict=其他 → State=DS_PENDING,写入 etcd 等待信号量
```
DAG 初始状态:**DS_RUNNING**(正常)或 **DS_PENDING**(等待信号量)。
---
### 二、DAG 调度触发(观察者模式)
```
EtcdWatcher 检测到 etcd key 变化
└── DagModel → DagIndex 更新
└── DagSchedulerImpl.LoadDagInc() [scheduler/scheduler.go:194]
├── State=DS_RUNNING/DS_PENDING/DS_ROLLBACK → scheduleDag()
├── State=DS_SUCCESS/FAILED/CANCELED → 通知父 DAG(InitializerOfDag)
└── State=DS_FAILED + autoRollback=true → scheduleDag() 触发回滚
TaskWatcher 检测到 Task 变化
└── DagSchedulerImpl.LoadTaskInc() [scheduler/scheduler.go:240]
└── Task 状态变化 → scheduleDag(task所属dagID)
```
`scheduleDag()` 将 DAG 加入 `pendingDags` map,通过 channel 触发调度循环。
---
### 三、DAG 调度执行(核心循环)
```
doScheduleDag() [scheduler/scheduler.go:285]
├── 检查 revisionBarrier(等 Task Index 赶上 DAG revision)
│
├── State=DS_RUNNING → scheduleRunningDag()
├── State=DS_ROLLBACK → scheduleRollbackDag()
├── State=DS_FAILED → autoRollbackDag()(若 autoRollback=true)
└── State=DS_PENDING → schedulePendingDag()(信号量检查)
```
#### `scheduleRunningDag()` 详细流程 [scheduler/scheduler.go:328]
```
1. runDagInitOperators() 执行 DAG 级初始化算子,失败 → DS_FAILED
2. TopologicalSort() 对 Operators 拓扑排序
3. 遍历每个 Operator(按拓扑序):
│
├── 已有 Task(已调度过):
│ ├── TS_RUNNING → scheduleRunningTask() 检查超时
│ ├── TS_UP_FOR_RETRY → scheduleUpForRetryTask()
│ ├── TS_SUCCESS/SKIPPED/IGNORED/FAILED/UPSTREAM_FAILED/CANCELED → totalFinished++
│ └── 检查 pauseOnComplete / pauseOnFailure / pauseOnAnyFailedChildren → pauseDag()
│
└── 未调度 Operator(需要新建/激活 Task):
├── 检查上游是否全部完成(finished < len(upstream) → skip)
├── 检查 ScheduleControl(时间窗口控制)
├── triggeredState() 根据 TriggerRule 决定 Task 初始状态:
│ ├── ALL_SUCCESS / ONE_SUCCESS → TS_UPSTREAM_FAILED(有失败时)
│ ├── ALL_FAILED / ONE_FAILED → 按失败数量决定 TS_RUNNING or TS_SKIPPED
│ └── ALWAYS → TS_RUNNING
│
├── → TS_UPSTREAM_FAILED → markOperatorAsUpstreamFailed() 写 etcd
├── → TS_SKIPPED → markOperatorAsSkipped() 写 etcd
└── → TS_RUNNING → markOperatorAsRunning()
└── runOperator()
```
---
### 四、Task 调度执行
#### `runOperator()` [scheduler/scheduler.go:798]
```
runOperator()
├── 合并 context(dag.InitContext + initOperatorsContext + 上游 Task.OutputContext)
├── runTaskInitOperators() 执行算子级初始化,失败 → TS_FAILED
├── evaluateOperatorProperties() 表达式求值(动态属性)
├── 检查 condition:false → TS_IGNORED
├── scheduleDelayMilli > 0 → TS_PENDING(延迟调度)
│
└── 确定执行方式:
├── 有子 DAGSpec(子DAG算子):
│ ├── 无 loops → task.Children=[{loopIndex:0, DS_PENDING}]
│ └── 有 loops → task.Children=[多个 loop 条目]
│
├── 有 baseOperator(普通算子):
│ └── WorkerAssigner.Assign() [scheduler/assigner.go:30]
│ ├── 按 workerSelectors 过滤在线 Worker
│ ├── 检查 hostAgent 是否在线
│ ├── waitOnAgentMilli > 0 → TS_PENDING(等待 Agent)
│ └── 无可用 Worker → 暂不写入,下次重试
│
└── 两者均无 → TS_FAILED
```
写入 etcd 后,Agent(worker)通过 WatcherIndex 感知到分配给自己的 Task,拉取执行。
#### Task 运行中超时检测 `scheduleRunningTask()` [scheduler/scheduler.go:553]
```
TS_RUNNING Task:
├── 有 children(子DAG)→ scheduleTaskChildren() 调度子 DAG
├── 无 assignee(eager dag 超时重跑)→ retryTask()
└── 超时检测:
├── lastScheduleTimestamp + timeout ≤ now:
│ ├── tries < retries → TS_UP_FOR_RETRY,设置 nextScheduleTimestamp
│ └── tries ≥ retries → TS_FAILED
└── 未超时 → delayScheduleDag() 注册超时定时器
```
---
### 五、DAG 完成判定
#### `markDagAsFinished()` [scheduler/scheduler.go:1432]
```
当 totalFinished ≥ len(dagSpec.Operators) 时触发:
检查所有叶子节点(leaf operators)的 Task 状态:
├── 所有叶子 failed==0 → DS_SUCCESS
└── 任意叶子 failed>0 → DS_FAILED(取第一个失败原因)
有信号量:releaseSemaphore() 原子事务(更新 DAG 状态 + 释放信号量计数)
无信号量:ds.Update() 直接写 etcd
```
---
### 六、完成态汇总
#### DAG 最终状态
| 状态 | 触发条件 |
|------|---------|
| **DS_SUCCESS** | 所有叶子 Task 成功/跳过/忽略/取消 |
| **DS_FAILED** | 任意叶子 Task 失败 / 初始化算子失败 / 拓扑排序失败 |
| **DS_CANCELED** | 用户手动取消 |
| **DS_IGNORED** | 条件不满足被忽略 |
| **DS_ROLLBACK** | 手动触发或 `autoRollback=true` 且 FAILED 时自动触发 |
| **DS_ROLLBACK_SUCCESS** | 回滚子DAG执行成功 |
| **DS_ROLLBACK_FAILED** | 回滚子DAG执行失败 / 构建回滚DAG失败 |
#### Task 最终状态
| 状态 | 含义 |
|------|------|
| **TS_SUCCESS** | Agent 执行成功 |
| **TS_FAILED** | Agent 执行失败 / 超时耗尽重试 / 初始化算子失败 |
| **TS_SKIPPED** | TriggerRule 未满足(上游全跳过/全失败等) |
| **TS_IGNORED** | condition 表达式求值为 false |
| **TS_UPSTREAM_FAILED** | 上游存在失败且 TriggerRule=ALL_SUCCESS/ONE_SUCCESS |
| **TS_CANCELED** | 用户手动取消 |
| **TS_UP_FOR_RETRY** | 超时但未耗尽重试次数,等待 retryInterval 后重调度 |
---
### 完整状态流转图
```
┌─────────────────────────────────────────┐
│ DAG 创建 │
└──────────────────┬──────────────────────┘
无信号量/REJECT │ 有信号量+QUEUE
┌────────┴───────────┐
DS_RUNNING DS_PENDING
│ │ 信号量释放
│◄───────────────────┘
┌──────────▼──────────┐
│ scheduleRunningDag │
│ (每次Task状态变更) │
└──────────┬──────────┘
所有Task完成 │
┌─────────────────────┤
│ 叶子有失败 │ 叶子全部成功/跳过
▼ ▼
DS_FAILED DS_SUCCESS
│
│ autoRollback=true
▼
DS_ROLLBACK
│
├──→ DS_ROLLBACK_SUCCESS
└──→ DS_ROLLBACK_FAILED
用户手动:→ DS_CANCELED / DS_IGNORED
eager超时:→ DS_FAILED / DS_ROLLBACK(按 onTimeout 配置)
```5.2 查询模块运行机制
【测试问题】
流程引擎的认证、授权及多租户是如何实现
【测试方法】
在使用 Graphify 与不使用 Graphify 增强的两种场景下,分别让 CodingAgent 自主探索,输出答案,并对比各自所花时间、Token 成本。
关键约束:限制 AI 不能参考任何项目中已有的说明与报告文档;防止 AI 参考已有的结论性信息。
【测试工具】
Claude Code/Claude Sonnet 4.6
【测试结论】
使用 Graphify + 源码时,较使用纯源码,耗时降低约 30% ,输入输出 Tokens 降低了约 55%。
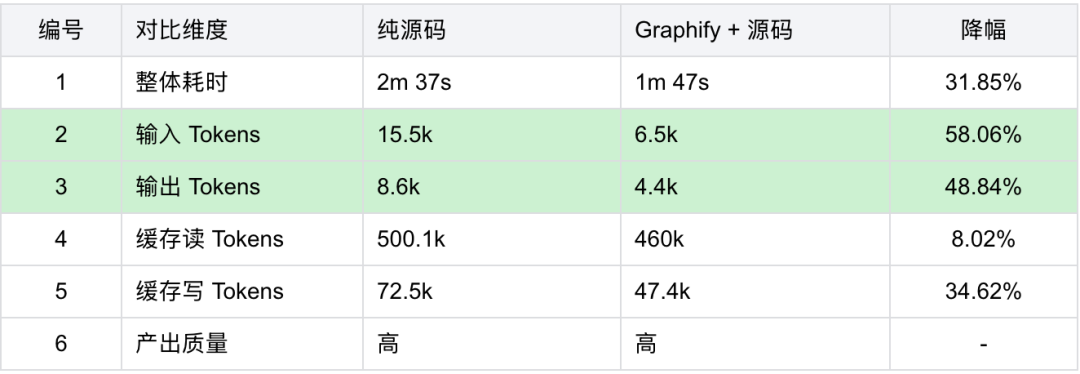
【测试过程】
使用纯源码
执行过程:
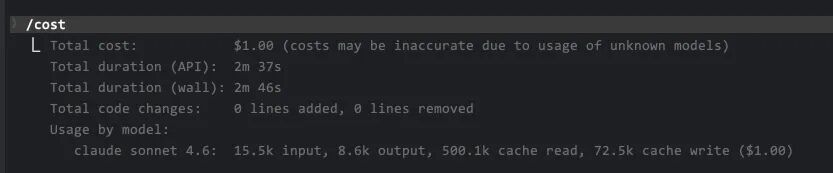
成本消耗:
产出:
## 认证、授权与多租户实现
### 一、认证(Authentication)
系统提供**两种可独立开启的认证机制**,均以 Gin middleware 形式挂载:
#### 1.1 UUAP 认证(百度 SSO)
- 从 Cookie 读取 `UUAP_P_TOKEN` / `UUAP_S_TOKEN`
- 用 `SHA256(appKey + pToken + sToken + timestamp + secretKey)` 计算签名,调用外部 UUAP HTTP 接口验签
- 成功后将 `username`、`email` 写入 gin context
#### 1.2 Service Token 认证(机器间调用)
- 从 Header 读取 `X-Auth-Service`(服务名)和 `X-Auth-Token`(令牌)
- 在配置预置的 token 表中查找匹配
- 成功则从 Header `X-Auth-Username` 中取调用方声明的用户名写入 context
#### 1.3 关键设计:软认证
两个 `Auth()` 方法**认证失败不拦截请求**,仅影响 context 中是否有 `username`。两种认证器会先检查 context 中是否已有 `username`,实现互斥短路------先到先得,可叠加使用。
---
### 二、授权(Authorization)
#### 2.1 接口设计
```go
type Authorizer interface {
Read/Update/Create/Delete/All(c context.Context, resource any) error
Authorize(username, namespace, resource, resourceName, verb string) error
}
```
两个实现:
- `AuthorizerImpl`:真实 RBAC 逻辑,`authorization.enable=true` 时启用
- `DummyAuthorizer`:所有操作直接放行,开发环境默认使用
#### 2.2 RBAC 鉴权流程
```
username → GetUserRoles(namespace, username) → []Role
→ 遍历 Role.Rules
→ match rule.Resources == resource
→ match rule.ResourceNames == resourceName(支持通配符 "*")
→ match rule.Verbs == verb
→ 任意 rule 完全匹配 → 放行
→ 全部不匹配 → 403 Forbidden
```
#### 2.3 资源抽象
当传入 `DagResource` 时,系统会自动查询 DAG 对应的 DagSpec 名称,再转为 `RawResource{Resource: "dag", ResourceName: dagSpecName}`,实现**基于 DAG 模板名称的细粒度权限控制**。
受 RBAC 保护的资源类型:`dag`、`dagSpec`、`operatorSpec`、`cronDag`、`eventDag`、`scheduleControl`、`clusterScheduleControl`、`role`、`clusterRole`。
#### 2.4 授权位置
授权**不是 middleware**,而是在每个 controller handler 中**手动内联调用**:
```go
// 每个 handler 内部
username := c.GetString("username") // 来自认证 middleware
if err := dc.auth.Create(c, DagResource{...}); err != nil {
c.JSON(http.StatusForbidden, ...)
return
}
```
---
### 三、多租户(Namespace 隔离)
#### 3.1 Namespace 概念
`Namespace` 是多租户隔离单元,以 Protobuf 存储在 etcd,包含 `Name`、`Description` 和可扩展的 `Context map`(任意元数据)。
#### 3.2 三个系统预置 Namespace
| Namespace | 常量 | 用途 |
|---|---|---|
| `default` | `DefaultNamespace` | 普通默认命名空间 |
| `__builtin__` | `BuiltinNamespace` | 系统内置资源(OperatorSpec 等) |
| `__cluster__` | `ClusterNamespace` | 集群级全局权限域 |
#### 3.3 Role 与 Namespace 绑定
- etcd key 格式:`{roleKeyPrefix}{namespace}/{roleName}`(如 `/role/myns/admin`)
- `RoleIndex` 以 `map[namespace]{ roles, userRoles }` 嵌套存储
- 鉴权时只在指定 namespace 内查找用户角色,实现完全隔离
#### 3.4 集群级权限(对标 K8s ClusterRole)
- `/v1/oos/role`:namespace 级 Role,namespace 由请求体指定
- `/v1/oos/clusterRole`:强制将 `role.Namespace = __cluster__`,代表全局权限
---
### 四、中间件链(完整顺序)
```
HTTP 请求
├── [1] ParseRequestID → context["reqid"]
├── [2] LoggingRequest → 日志 + Prometheus 延迟指标
├── [3] RecoveryWithZap → panic 恢复
├── [4*] UUAPAuth → context["username"] (可选)
├── [5*] ServiceTokenAuth → context["username"] (可选)
│
└── Controller Handler
├── auth.Authorize(username, namespace, resource, ...) ← 硬鉴权
└── 业务逻辑
```
> Agent 子应用(`hostAgentApp`/`httpsAgentApp`)不挂载认证 middleware,依赖内网隔离或 mTLS。
---
### 五、设计特点总结
1. **软认证 + 硬授权**:认证失败不阻断,授权失败才返回 403
2. **RBAC 实时同步**:Role 数据存 etcd,通过 watcher 实时同步到内存索引 `RoleIndex`,无需重启生效
3. **Namespace 为多租户边界**:所有资源携带 namespace 字段,权限在 namespace 内隔离生效
4. **`__cluster__` 为全局权限域**:跨 namespace 的集群级操作单独管控,与 Kubernetes RBAC 设计高度一致
5. **授权开关**:`authorization.enable` 控制是否启用真实 RBAC,关闭时 `DummyAuthorizer` 全放行,便于开发调试使用 Graphify + 源码
执行过程:

成本消耗:
产出:
已掌握全貌,现在可以给出完整分析。
---
## 认证、授权与多租户实现分析
### 一、认证(Authentication)
系统提供**两种独立认证机制**,均以 Gin middleware 形式挂载,两者可同时开启,互为补充(任意一个成功设置 `username` 即视为已认证)。
#### 1. UUAP SSO(人员登录)
`internal/authentication/uuap.go`
```
Cookie: UUAP_P_TOKEN + UUAP_S_TOKEN
↓
签名:SHA256(appKey + pToken + sToken + timestamp + secretKey)
↓
POST 到 UUAP 验证接口
↓
成功 → c.Set("username", ...) + c.Set("email", ...)
```
- 适用场景:浏览器/前端用户
- 凭证:UUAP 双 Token Cookie
- 签名防重放:带时间戳的 HMAC-SHA256
#### 2. ServiceToken(服务调用)
`internal/authentication/service_token.go`
```
Headers: X-Auth-Service + X-Auth-Token + X-Auth-Username
↓
查配置表:tokens[service] 中是否包含该 token
↓
成功 → c.Set("username", X-Auth-Username)
```
- 适用场景:服务间调用(机器账号)
- 凭证:预配置的静态 token 表(`map[string][]string`,key=服务名,value=token 列表)
- 配置路径:`config.yml` → `authentication.serviceToken.tokens`
#### 3. 装配方式(`main.go:407-416`)
```go
// 两个 middleware 顺序注册,均为"soft auth"------不会阻断请求,只负责设置 username
if cfg.Authentication.UUAP.Enable {
app.AddMiddleware(authentication.UUAPAuth(...))
}
if cfg.Authentication.ServiceToken.Enable {
app.AddMiddleware(authentication.ServiceTokenAuth(...))
}
```
> 注意:认证 middleware **不强制拦截**,只负责将 `username` 写入 context。真正的强制检查在授权层------`Authorize()` 方法在 `username` 为空时直接返回 `"the user doesn't login"` 错误。
### 二、授权(Authorization)
`internal/authorization/authorizer.go`
采用 **RBAC(基于角色的访问控制)** 模型,核心接口:
```go
type Authorizer interface {
Read(ctx, resource) error // 读
Update(ctx, resource) error // 改
Create(ctx, resource) error // 增
Delete(ctx, resource) error // 删
All(ctx, resource) error // 通配
Authorize(username, namespace, resource, resourceName, verb string) error
}
```
#### 鉴权流程
```
HTTP 请求
↓ (context 中取 username)
AuthorizerImpl.Read/Update/Create/Delete/All()
↓ toRawResource() --- 将 DagResource 解析为 {Namespace, Resource, ResourceName}
↓
Authorize(username, namespace, resource, resourceName, verb)
↓
RoleIndex.GetUserRoles(namespace, username) // 内存索引,O(1)
↓
遍历该用户在此 namespace 下的所有 Role.Rules:
- match(rule.Resources, resource) // 资源类型匹配,支持通配符 "*"
- match(rule.ResourceNames, resourceName) // 资源名匹配(可选)
- match(rule.Verbs, verb) // 操作匹配
↓
全部命中 → 放行;否则 → 403 Forbidden
```
#### 全局开关 + DummyAuthorizer
```go
// main.go:378-387
var auth authorization.Authorizer = &authorization.DummyAuthorizer{} // 默认全放行
if cfg.Authorization.Enable {
// 启用真实 RBAC
roleIndex := index.NewRoleIndex()
...
auth = authorization.NewAuthorizer(logger, roleIndex, ds)
}
```
`DummyAuthorizer` 所有方法直接返回 `nil`,用于**禁用授权检查**(开发/无鉴权部署场景)。
---
### 三、多租户(Namespace)
系统以 **Namespace** 作为租户隔离边界,贯穿整个资源模型。
#### 隔离层次
| 层次 | 实现 |
|------|------|
| **etcd 存储** | 每类资源 key 前缀独立,如 `/namespace/`、`/role/`、`/dag/` |
| **内存索引** | `RoleIndexImpl.nsIndex` 是 `map[namespace]→{roles, userRoles}`,按 namespace 严格隔离 |
| **RBAC 绑定** | Role 携带 `namespace` 字段,`GetUserRoles(ns, username)` 仅返回该 namespace 下的角色 |
| **API 参数** | 所有资源操作(DAG、DagSpec、Role 等)均要求传入 `namespace` 参数 |
#### RoleIndex 的 namespace 隔离(`internal/index/role.go`)
```go
type NamespacedRoleIndex map[string]struct {
roles *util.OrderedIndex[string, model.VersionedRole]
userRoles *util.InvertedIndex[string, string, model.VersionedRole]
}
func (ri *RoleIndexImpl) GetUserRoles(ns string, username string) []model.VersionedRole {
index, ok := ri.nsIndex[ns] // 先按 namespace 分区
if !ok { return nil }
values, _ := index.userRoles.GetValues(username)
...
}
```
#### 数据流
```
创建 Namespace → POST /v1/oos/namespace
↓
nsModel → etcd (/namespace/<name>)
↓
nsIndex (内存)
创建 Role(含 namespace + users + rules)
↓
roleModel → etcd (/role/<name>)
↓
RoleIndex.nsIndex[namespace] 更新
DAG 操作请求(带 namespace)
↓
Authorizer.toRawResource() → {namespace, "dag", dagSpecName}
↓
RoleIndex.GetUserRoles(namespace, username)
↓
按 rules 匹配放行/拒绝
```
---
### 四、整体架构总结
```
请求
│
├─ Middleware 1: UUAPAuth → 设置 username (人员账号)
├─ Middleware 2: ServiceTokenAuth → 设置 username (服务账号)
│
↓
Controller (e.g. DagController)
│
├─ auth.Create(ctx, DagResource{Namespace: ns, DagSpecName: name})
│ ↓
│ AuthorizerImpl.Authorize(username, ns, "dag", name, "create")
│ ↓
│ RoleIndex.GetUserRoles(ns, username) ← 内存,etcd watch 实时同步
│ ↓
│ 规则匹配(resource / resourceName / verb,支持 "*" 通配)
│
└─ 通过 → 业务逻辑
拒绝 → 403
```
**设计亮点:**
1. 认证与授权完全解耦,middleware 只管身份识别,controller 层自行调用 authorizer
2. 角色数据存储在 etcd,通过 `RoleIndex` 缓存在内存,鉴权路径无额外 I/O
3. `DummyAuthorizer` + 配置开关实现零侵入的功能降级
4. Namespace 作为一等公民贯穿 RBAC,天然支持多租户资源隔离06 开源项目对比:Graphify vs GitNexus
代码图谱这条线下,有两个开源项目走在了前面,而且它们的路线选择几乎是镜像对称的。
6.1 GitNexus:把知识锁进自己的工具
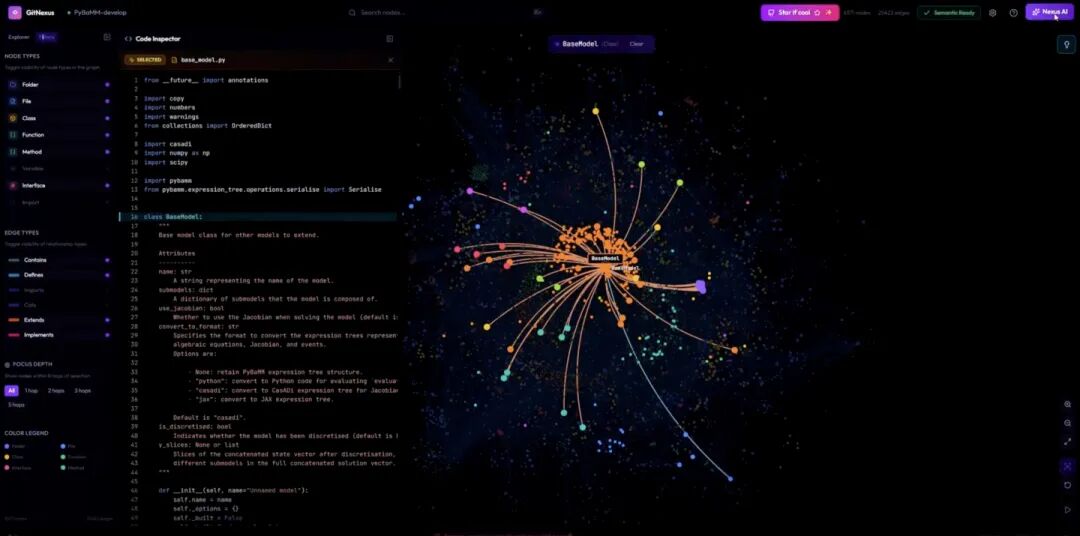
GitNexus 对外主打的口号是 "Zero-Server 代码智能引擎"------所有索引和可视化都跑在浏览器里,不依赖任何云端服务。听着很酷,但稍微扒一下它的架构,你会看到另一面。
Parser 部分是 AST 抽取,这没问题。存储层走的是嵌入式图数据库,二进制格式,默认写到用户 HOME 目录下的 ~/.gitnexus/。
最关键的一点在访问层------它只通过 MCP Server 对外暴露查询接口。换句话说,CodingAgent 想拿到你的代码结构,必须经由它的 MCP 中介。
这意味着什么?意味着你的代码知识,被锁在了它自己的工具里。
你用它的 CLI 建完索引,结果躺在它的数据库里,想要访问只能按它的规矩办事。
换一台机器要重建,团队共享要额外一层工程化操作。它把自己变成了必经之路。
6.2 Graphify:把知识写成普通文件
Graphify 走的完全是反过来的路,通过上面的原理剖析(参阅 5.1 章节),我们知道它通过四个阶段最终生成了文件类型的知识图谱。
CodingAgent 可以通过读取文件直接获取图谱数据,不需要额外组件支持,自然也没有额外的组件限制。并且可以将生成的知识图谱纳入 GIT 管理,从而实现团队共享,真正让图谱流动了起来。
6.3 别让工具变成必经之路
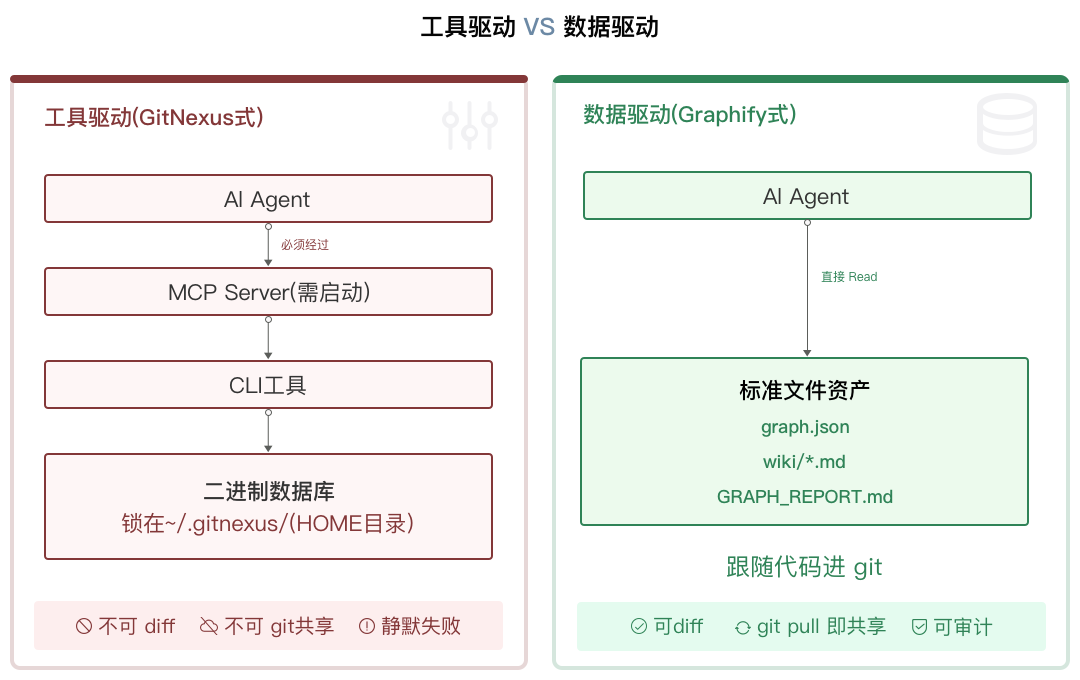
最本质的差异已经浮出水面:GitNexus 把知识锁在自己的工具里,Graphify 把知识变成了可流通的数据。
这并不是说 GitNexus 的索引技术做得差------它的索引引擎本身是合格的,问题在于它把自己变成了整条工作流的必经之路。
从 CLI 到 MCP Server 再到嵌入式数据库,中间有多个衔接环节,任何一环出问题------哪怕是 MCP 连接静默失败,整条链路就瘫了,而你甚至很难第一时间意识到它已经断了。
Gaphify 选的是完全相反的方向,直接将知识图谱生成文件,并且可以伴随代码一起进入 GIT 管理,在团队协作这种场景下,哪种方式更经用,答案其实已经挺明显了。
GEEK TALK
07 Graphify 并不是银弹
那么,是不是只要把项目的源代码、设计文档、规范文档都交给 Graphify,给 AI 编程助手一张"地图",它就能彻底胜任开发了?
答案显然不是:Graphify 是一块非常重要的拼图,它能显著提升 AI 对系统结构的理解效率,却不能替代源码、业务文档、架构约束,也不能替代一套稳定的研发流程。
7.1 它不能替代源代码
Graphify 的价值,是先帮 AI 找到相关结构、相关概念、相关模块和相关来源,但它并不负责替代源码本身。比如下面这些问题,最后仍然要回到代码里确认:
-
某个函数的参数签名到底是什么
-
某段分支逻辑最终是怎么执行的
-
某个异常到底在哪里被抛出
所以,合理的用法不是"让 Graphify 直接给答案",而是:
先用 Graphify 查地图,再回到源码看现场。
Graphify 负责缩小搜索范围,告诉 AI 该看哪里;源码负责提供最终证据,告诉 AI 事实到底是什么。
7.2 它更适合"带着问题查地图"
Graphify 生成的图谱,非常适合带着明确问题去查询,比如:
-
这个业务概念和哪些代码相关?
-
哪些接口处理了这个场景?
-
如果更改这个接口,可能影响哪些代码和业务?
但真实开发中,需求一开始往往并不是这样清晰的问题,而是一段描述:
"供应商主数据变更,需要新增审批流程,并在审批通过后同步校验到采购、财务和库存系统。"
这时候,AI 还没有明确的"问题锚点",如果直接拿这段话去查 Graphify 的代码与文档图谱,效果未必很好。
所以很多时候你需要借助其他方法来逐步细化需求,收敛出一些具体问题;再通过 Graphify 查询这些问题背后的知识,帮助 AI 理解系统并辅助编码。
7.3 大规模项目开发需要"组合拳"
Graphify 擅长的是****问题驱动的知识查找与穿透,****但大规模项目里有很多天然属于"整体认知型"的知识,更适合作为完整文档被 AI 线性读完。通过拆分后的图节点再回溯理解,反而可能破坏叙事、因果和约束的完整性。
比如业务理解需要完整阅读业务目标、领域术语和业务流程等,因为这些内容有顺序、有因果,碎片化的"跳跃式"阅读很难拼出全貌。
再比如编码规范,包括命名、异常处理、提交约定等,这些知识不应该是"用到时查一下"就够了,而应该是 AI 写代码时默认遵守的规则(Rules)。
因此,很多时候与其让 AI 到图谱里零散检索,不如直接把它导航到对应的上下文文档,让它完整阅读。
7.4 图谱本身也可能出错
无类型的动态语言是图谱的天敌:函数签名不带类型信息,AST 解析出来的"调用边"往往是错的。
Java Spring 的依赖注入、反射、动态分发同样让静态分析寸步难行:AST 看不到运行时才决定的调用关系,图谱里本该有的那些边,就这么静悄悄地缺了一大片。
在最需要图谱的复杂项目里,图谱偏偏可能是错的------而且错得很隐蔽,你不容易发现。
08 后记:AI 时代的地图,是给 CodingAgent 的
过去两年我们一直在研发工作中使用 CodingAgent,但是很多同学目前对于 CodingAgent 的使用还处于比较初始的阶段:
塞一段代码过去,让它给个答案,不满意就换一个 Prompt。这在小规模的任务上这么用还行,代码库规模一上来,这种用法就开始失灵。
原因说白了就九个字:智能不等于全局认知。
一个在某个领域最聪明的人,你把他空投到北京胡同深处,他照样要问路。AI 也一样。模型参数再多,训练数据再丰富,它都没有办法凭"看过的代码"反推出你手头这个具体项目的架构长什么样。这不是模型能力的问题,是信息的不对称。
知识图谱就是那张很多人没想到要给 CodingAgent 准备的地图。它不性感------不是那种让你用一次就惊艳的黑科技。它需要你先花时间构建、持续维护、和代码一起走进 GIT。但一旦这件事做了,你的 CodingAgent 就从"每到路口都要问路"的迷茫访客,变成了"直接走捷径"的熟人。
所以下次 CodingAgent 又在你代码库里瞎逛的时候------别急着升级模型,也别忙着加 1M 上下文,先给它画一张地图。