时间序列模型
前置知识
时间序列
按照时间组成的序列
机器学习模型:AR、MA、ARMA、ARIMA
神经网路模型:LSTM
平稳序列 / 非平稳序列
- 平稳序列(stationary series):基本上不存在趋势的序列,各观察值基本上在某个固定的水平上波动
- 非平稳序列(non-starionary series):包含趋势、季节性或周期性的序列,可能只有一种成分,也可能是多种成分的组合
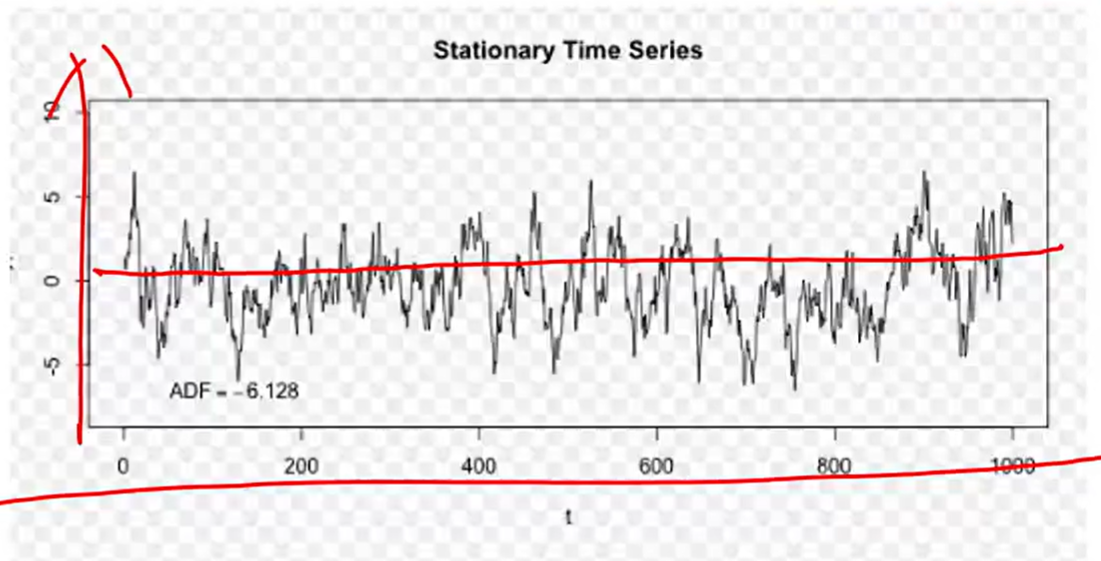
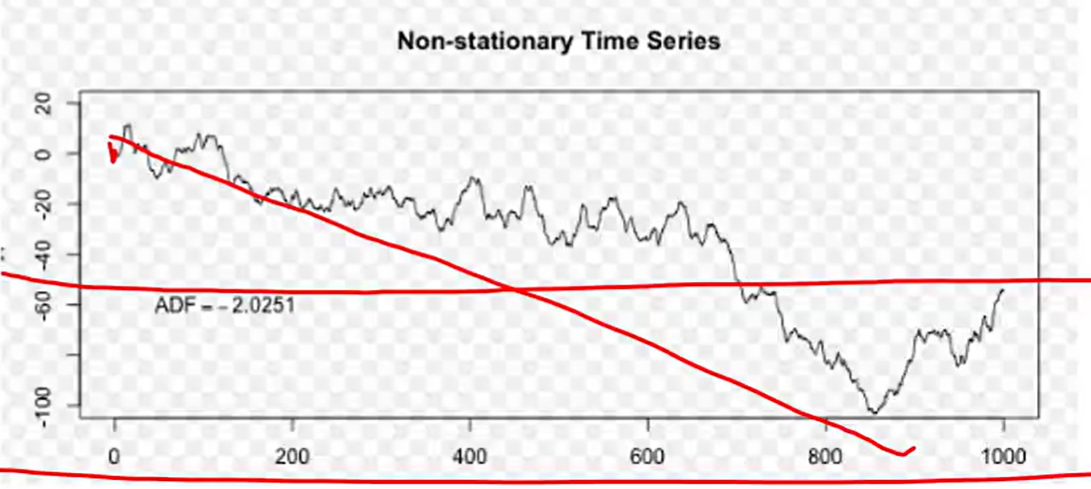

可以直接调statsmodels包,使用ARIMA时序模型
自回归模型(AR,Auto Regressive)

滑动平均模型(MA,Moving Average)

自回归滑动平均模型(Auto Regressive Moving Average,ARMA)


差分自回归滑动平均模型(Auto Regressive Integrated Moving Average,ARIMA)

平稳序列 更好用来预测,例如:在股市中(简单理解),当跌到很低时,就可以考虑买入,当升很高时,考虑卖出,以获取收益。
在自然界/其他场景中,一般非平稳序列是比较常见的,我们期望是平稳序列,因此就引入了差分方法。
事实上,ARIMA 就是对序列先进行差分,然后进行 ARMA
差分方法:
将时间序列前后相减,获得平稳序列

这里是 f(x) = x^2,需要差分 2 次,如果是 d 次方,则差分 d-1 次,即可得到平稳序列
模型使用方法
调包

order:(p, d, q)代表 (AR阶数、差分次数、MA阶数),属于超参数,在实际使用中需要自己调整值来获得比较好的时间预测模型。
也可以用超参数的网格搜索,让程序给出多种可能性,根据多种结果,分析并最终选择最合适的超参数。
设置阶数值的范围参考思路:以股票为例,想看多久前的时刻,是过去5天的,还是10天的?可以设置为5,因为一周的时间是5天(周末休市),是有周期性的。
评价模型预测结果好坏指标 ------ AIC
AIC 代表 误差,越小表示预测效果越好
bash
# 用ARMA进行时间序列预测
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
# 使用新的ARIMA模块替代已弃用的ARMA
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.api import qqplot
# 创建数据
data = [3821, 4236, 3758, 6783, 4664, 2589, 2538, 3542, 4626, 5886, 6233, 4199, 3561, 2335, 5636, 3524,
4327, 6064, 3912, 1356, 4305, 4379, 4592, 4233, 4281, 1613, 1233, 4514, 3431, 2159, 2322, 4239, 4733,
2268, 5397, 5821, 6115, 6631, 6474, 4134, 2728, 5753, 7130, 7860, 6991, 7499, 5301, 2808, 6755, 6658,
6944, 6372, 8380, 7366, 6352, 8333, 8281, 11548, 10823, 13642, 9973, 6723, 13416, 12205, 13942, 9590,
11693, 9276, 6519, 6863, 8237, 10122, 8646, 9749, 5346, 4836, 9806, 7502, 9387, 11078, 9832, 6886, 4285,
8351, 9725, 11844, 12387, 10666, 7072, 6429]
data=pd.Series(data)
data_index = sm.tsa.datetools.dates_from_range('1901','1990')
#print(data_index)
# 绘制数据图
data.index = pd.Index(data_index)
data.plot(figsize=(12,8))
plt.show()
# 创建ARIMA模型,使用order=(7,0,0)表示ARMA(7,0)
arma = ARIMA(data, order=(7,0,0)).fit() # 这里就是训练
print('AIC: %0.4lf' %arma.aic) # Loss
# 模型预测
predict_y = arma.predict(start='1990', end='2000')
# 预测结果绘制
fig, ax = plt.subplots(figsize=(12, 8))
ax = data.loc['1901':].plot(ax=ax)
predict_y.plot(ax=ax)
plt.show()长短期记忆网络(LSTM)
结合面试高频考点、基础语法、数据操作、性能优化、实战场景、易错点分类整理,附问题+参考答案,适配数据分析、算法、后端开发等岗位,可直接用于背诵和笔记。
Pandas 面试高频问题(分模块)
一、基础概念 & 数据结构(入门必问)
1. 介绍 Pandas 两大核心数据结构:Series 和 DataFrame
答
- Series :一维带标签数组,由索引(index) + 值(values) 组成,可理解为单列数据,支持不同数据类型。
- DataFrame :二维表格型数据结构,多行多列,可看作多个 Series 按列拼接,拥有行索引、列名,是日常使用最多的结构。
- 共性:基于 NumPy 实现,运算高效,支持向量化操作。
2. Series 和 Python 原生列表、字典的区别?
答
- 对比列表:Series 自带索引,支持向量化运算;列表无索引,循环遍历低效。
- 对比字典:字典是无序(Python3.7+有序)键值对;Series 索引有序,支持切片、数学运算、对齐操作。
- Series 同列数据类型统一,字典/列表可混合类型。
3. 什么是索引(Index)?索引有什么作用?
答
索引是 Pandas 中行/列的标签,分为行索引、列索引。
作用:
- 快速定位、筛选数据;
- 数据合并、拼接时自动索引对齐;
- 分组、透视、重采样等操作的核心依据。
常见索引类型:普通索引、多层索引(MultiIndex)、时间索引(DatetimeIndex)。
4. 如何创建 Series、DataFrame?
答
- Series:可从列表、数组、字典创建;
- DataFrame:可从二维列表、字典、NumPy 数组、Excel/CSV 文件、数据库创建。
示例(简写):
python
pd.Series([1,2,3])
pd.DataFrame({"col1":[1,2],"col2":[3,4]})二、数据读取与写入(工程常用)
1. Pandas 支持哪些数据源读写?常用参数有哪些?
答
支持 CSV、Excel、JSON、SQL、Parquet、HDF5、HTML 等。
高频函数:read_csv / read_excel / to_csv / to_excel。
高频参数考点:
filepath_or_buffer:文件路径;sep:分隔符,csv 默认,;header:指定哪一行作为列名;index_col:指定某列作为行索引;usecols:只读取指定列,减少内存占用;skiprows:跳过前 N 行;encoding:编码(utf-8/gbk,解决中文乱码);dtype:指定列数据类型,提前优化内存。
2. 读取大文件 CSV 内存溢出怎么解决?
答
- 使用
chunksize分块读取,迭代处理数据; usecols只加载需要的列;dtype压缩数据类型(如 int64 → int32,float64→float32);- 改用
parquet等列式存储格式,压缩率更高。
三、数据查看、选择、切片(最高频)
1. loc、iloc、[] 三者区别与用法?(必考)
答
loc:按标签索引 (行/列名称),闭区间,支持条件筛选。
语法:df.loc[行标签, 列标签]iloc:按位置索引 (数字下标,从0开始),闭区间。
语法:df.iloc[行下标, 列下标][]:简易写法- 单
[]:优先取列; - 切片形式
df[1:3]:取行。
- 单
核心区分 :想按名字找用 loc,按下标位置找用 iloc;生产优先用 loc/iloc,语义更清晰。
2. 布尔索引如何实现条件筛选?举例
答
通过条件表达式生成布尔数组,筛选结果为 True 的行。
示例:筛选 age > 18 的数据
python
df[df["age"] > 18]
# 多条件:&(且)、|(或)、~(非),每个条件必须加括号
df[(df["age"]>18) & (df["gender"]=="男")]注意:多条件运算符不能用 and/or,必须用 & / |。
3. 如何查看数据基本信息?
答
df.head(n)/df.tail(n):查看前/后 n 行;df.shape:行数、列数;df.info():字段类型、缺失值统计;df.describe():数值列统计指标(均值、方差、分位数等);df.columns/df.index:查看列名、行索引。
四、缺失值、重复值、异常值处理(业务必考)
1. Pandas 中缺失值表示是什么?如何检测、处理缺失值?
答
-
缺失值标识:
- 数值型:
NaN; - 时间类型:
NaT;
PythonNone也会被识别为缺失。
- 数值型:
-
检测缺失值:
df.isnull()/df.isna():判断是否缺失,返回布尔表;df.isnull().sum():统计每列缺失数量。
-
处理方式:
- 删除 :
dropna(),参数how、thresh、subset; - 填充 :
fillna()- 固定值填充:
fillna(0) - 统计值填充:均值、中位数、众数
- 前后值填充:
fillna(method='ffill')前向填充 /bfill后向填充。
- 固定值填充:
- 删除 :
2. 如何处理重复数据?
答
- 检测重复行:
df.duplicated(),返回布尔序列; - 删除重复行:
df.drop_duplicates()
常用参数:subset指定依据哪些列去重,keep保留首行/末行。
3. 简单说下异常值的常用处理思路
答
- 统计法:箱线图、3σ 原则筛选异常值;
- 处理方式:删除、替换为均值/中位数、截断、单独标记。
五、数据清洗、列操作、映射替换
1. map、apply、applymap 区别?(高频)
答
三个都是元素/函数映射,适用场景不同:
- map :仅用于 Series,一对一映射(字典/函数),多用于类别翻译、字段映射。
- apply :Series / DataFrame 都可用;
- Series:逐元素执行函数;
- DataFrame:按行/按列 执行函数(
axis=0列,axis=1行),最常用。
- applymap :旧版本 Pandas 专用,对 DataFrame 每一个元素 执行函数;
新版本推荐统一使用df.map()。
总结 :列映射用 map;行列复杂逻辑用 apply。
2. 如何新增列、修改列、删除列?
答
- 新增列:直接赋值
df["new_col"] = 值/表达式; - 修改列:对原有列重新赋值;
- 删除列:
df.drop(columns=["col1"])或del df["col1"]。
3. replace 替换函数用法?
答
用于值替换,支持单值、多值、字典映射替换:
python
df["col"].replace("旧值", "新值")
df["col"].replace({"A":1, "B":2})六、分组、聚合、透视(业务核心,重点)
1. groupby 分组原理与常用搭配?(必考)
答
- 原理:按照指定列将数据划分为多个组,后续对每组做聚合运算。
- 基础语法:
df.groupby(分组列)[聚合列].聚合函数() - 常用聚合函数:
sum、mean、count、max、min、size。 - 多聚合:
agg()支持同时多个统计、不同列不同聚合规则。
示例:
python
# 单列分组 + 多聚合
df.groupby("category")["price"].agg([sum, mean])
# 不同列不同聚合
df.agg({"col1":"sum", "col2":"mean"})2. groupby 之后索引如何还原为普通列?
答
groupby(..., as_index=False)分组时不将分组列设为索引;- 分组后执行
reset_index()重置索引。
3. 透视表 pivot_table 和 pivot 区别?
答
- pivot:简单透视,不支持聚合、不支持重复索引,功能弱;
- pivot_table :强大透视表,支持聚合函数、缺失值填充、多级索引,是 Excel 透视表的 Pandas 实现,业务首选。
4. 窗口函数 rolling 作用?(时序场景高频)
答
滑动窗口计算,常用于时间序列 (移动平均、滑动统计)。
示例:计算近7行滑动均值
python
df["val"].rolling(window=7).mean()搭配 shift() 可做滞后特征,时序特征工程必备。
七、表合并、拼接(merge / concat)
1. concat 和 merge 的区别?(必考)
答
-
pd.concat :拼接
- 分为行拼接 (上下合并,
axis=0)、列拼接 (左右合并,axis=1); - 基于索引对齐,无关联键概念;
- 适用:结构相同的多张表合并。
- 分为行拼接 (上下合并,
-
pd.merge :关联/连接(类似 SQL join)
- 基于关联字段(主键) 左右拼接;
- 支持 左连接(left)、右连接(right)、内连接(inner)、全连接(outer);
- 适用:多张表通过主键关联查询。
2. merge 四种连接方式说明
答
- 内连接(inner):只保留两张表匹配上的数据(默认);
- 左连接(left):以左表为准,右表匹配不上补缺失值;
- 右连接(right):以右表为准;
- 全连接(outer):保留左右表所有数据。
3. 合并时出现重复列名如何处理?
答
使用 merge 的 suffixes 参数,给重复列加后缀区分。
八、时间序列处理(时序算法岗位重点)
1. 字符串转时间格式用什么函数?
答
pd.to_datetime(),支持各种时间字符串解析,可指定 format 提升解析速度。
2. 时间索引常用操作:重采样 resample
答
resample 基于时间索引做频率转换、聚合,时序核心函数。
示例:日数据转为月均值
python
df.resample("M")["value"].mean()常用频率:D日、W周、M月、Q季度、Y年。
3. 时间偏移、时间差计算?
答
pd.Timedelta 计算时间间隔;shift() 实现时间序列前移/后移。
九、性能优化 & 踩坑问题(进阶/中高级面试)
1. Pandas 性能优化手段?
答
- 数据类型优化:将
int64/float64转为更小类型,字符串列用category(类别少的时候大幅省内存); - 避免循环:优先向量化运算,禁止 for 循环逐行处理;
- 大文件分块读取
chunksize; - 只加载需要的列
usecols; - 复杂逻辑用
apply代替原生循环,极致场景结合 NumPy。
2. 什么是链式索引?有什么风险?
答
类似 df["col"][0] 连续两次取索引,属于链式索引。
风险:Pandas 无法确定返回的是视图还是副本 ,修改数据可能出现 SettingWithCopyWarning 警告,数据修改失效。
解决:统一使用 loc/iloc 单次索引赋值。
3. 解释 SettingWithCopyWarning 警告及解决方案
答
原因:对 DataFrame 的切片副本 进行赋值,Pandas 不确定你是否要修改原数据。
解决:
- 筛选数据后使用
copy()显式生成新对象; - 全程使用
loc做数据选取与赋值。
4. Pandas 深拷贝、浅拷贝区别?
答
- 浅拷贝
df.copy(deep=False):新对象引用原数据,修改值会互相影响; - 深拷贝
df.copy(deep=True)(默认):完全独立新数据,互不干扰。
十、手写代码类面试题(实操)
- 读取 csv 文件,处理缺失值,按某列分组求均值;
- 两表根据 ID 左连接;
- 实现多条件筛选;
- 时间列转换 + 按月重采样聚合;
- 使用 map 完成类别字段映射。
面试精简背诵版(快速复盘)
- 两大结构:Series(一维)、DataFrame(二维)
- 取值:loc按标签、iloc按下标,禁止链式索引;
- 缺失值:
isnull检测,dropna删除,fillna填充; - 函数映射:map(列)、apply(行/列);
- 分组聚合:
groupby + agg,透视用pivot_table; - 表操作:concat 上下/左右拼接,merge 类似SQL关联;
- 时序:
to_datetime转时间,resample重采样,rolling滑动窗口; - 优化:改数据类型、用向量化、少循环、大文件分块。
结合上一轮整理的 Pandas 手写代码面试题 ,按题型分类,给出题目 + 完整代码 + 步骤解析 + 运行说明,覆盖基础操作、清洗、筛选、分组、拼接、时序、实战场景,面试直接套用。
统一前置环境:
pythonimport pandas as pd import numpy as np
一、基础读写 + 缺失值处理(入门必考)
题目1
读取 data.csv 文件,查看基本信息;统计每列缺失值数量;对数值列缺失值用均值填充 ,字符列缺失值用未知 填充;最后保存为 clean_data.csv。
完整代码
python
# 1. 读取csv文件
df = pd.read_csv("data.csv", encoding="utf-8")
# 2. 查看数据基本信息
print("数据形状:", df.shape)
print("\n数据概览:")
print(df.head())
print("\n字段类型与缺失值:")
print(df.info())
# 3. 统计每列缺失值数量
print("\n每列缺失值统计:")
print(df.isnull().sum())
# 4. 区分类型填充缺失值
# 数值列:均值填充
num_cols = df.select_dtypes(include=[np.number]).columns
df[num_cols] = df[num_cols].fillna(df[num_cols].mean())
# 字符/对象列:填充"未知"
str_cols = df.select_dtypes(include=[object]).columns
df[str_cols] = df[str_cols].fillna("未知")
# 5. 保存清洗后数据
df.to_csv("clean_data.csv", index=False, encoding="utf-8")
print("数据清洗完成,已保存为 clean_data.csv")关键考点
read_csv/to_csv读写,index=False不导出行索引;isnull().sum()统计缺失值;select_dtypes按数据类型筛选列;fillna批量填充。
二、条件筛选(布尔索引,高频)
题目2
现有学生数据表 df,字段:name, gender, age, score。
要求:
- 筛选 年龄大于18 且 分数大于80 的男生;
- 提取结果的
name和score两列; - 重置行索引。
测试数据(可直接运行)
python
# 构造测试数据
data = {
"name": ["张三", "李四", "王五", "赵六"],
"gender": ["男", "女", "男", "女"],
"age": [19, 17, 20, 18],
"score": [85, 76, 92, 88]
}
df = pd.DataFrame(data)完整解题代码
python
# 多条件筛选:& 表示且,每个条件必须加括号
cond = (df["age"] > 18) & (df["score"] > 80) & (df["gender"] == "男")
res = df[cond][["name", "score"]]
# 重置索引,drop=True 丢弃原索引列
res = res.reset_index(drop=True)
print(res)输出结果
name score
0 张三 85
1 王五 92考点提醒
- 多条件不能用
and/or,必须用&(且)、|(或)、~(非); - 所有条件外层必须加括号;
reset_index(drop=True)面试常用写法。
三、map / apply 映射与自定义函数(核心考点)
题目3
基于上面学生表:
- 使用
map将gender列:男→1,女→0; - 使用
apply新增一列level:分数≥90为"A",80~89为"B",80以下为"C"。
完整代码
python
# 1. map 做字典映射(仅适用于 Series)
gender_map = {"男": 1, "女": 0}
df["gender"] = df["gender"].map(gender_map)
# 2. apply 自定义逻辑(逐行/逐元素处理)
def get_level(score):
if score >= 90:
return "A"
elif score >= 80:
return "B"
else:
return "C"
# 作用于单列
df["level"] = df["score"].apply(get_level)
print(df)输出
name gender age score level
0 张三 1 19 85 B
1 李四 0 17 76 C
2 王五 1 20 92 A
3 赵六 0 18 88 B扩展:apply 按行处理(多列判断)
如果需要同时使用多列数据,设置 axis=1:
python
def judge(row):
if row["age"]>18 and row["score"]>80:
return "优秀"
else:
return "普通"
df["tag"] = df.apply(judge, axis=1)四、分组聚合 groupby + agg(业务必写)
题目4
基于学生表,按 gender 分组,完成统计:
- 年龄:平均值
- 分数:总和、最高分、最低分
分组后重置索引。
完整代码
python
# 多列、多聚合规则
group_res = df.groupby("gender").agg(
年龄均值=("age", "mean"),
分数总和=("score", "sum"),
分数最高=("score", "max"),
分数最低=("score", "min")
).reset_index() # 分组后重置索引
print(group_res)老式写法(兼容旧版本,面试也可写)
python
group_res = df.groupby("gender")[["age", "score"]].agg({
"age": "mean",
"score": ["sum", "max", "min"]
}).reset_index()考点
agg支持命名列 + 聚合函数;groupby默认分组列变为索引,reset_index()还原为普通列;- 常用聚合:
mean/sum/max/min/count/size。
五、表拼接:concat 与 merge(SQL类高频)
题目5 (concat 上下/左右拼接)
有两张结构相同的学生表 df1、df2,上下合并 ;
再构造一张班级表 df_class,按 name 左右拼接。
完整代码
python
# 构造测试数据
df1 = pd.DataFrame({"name":["张三","李四"], "score":[85,76]})
df2 = pd.DataFrame({"name":["王五","赵六"], "score":[92,88]})
df_class = pd.DataFrame({"name":["张三","李四","王五"], "class":["一班","二班","一班"]})
# 1. concat 行拼接(上下合并,axis=0 默认)
df_all = pd.concat([df1, df2], ignore_index=True)
print("上下合并结果:")
print(df_all)
# 2. concat 列拼接(左右合并,axis=1)
# 一般关联表优先用 merge,concat 仅用于索引对齐场景
df_concat_col = pd.concat([df1, df2], axis=1)
print("\n列拼接结果:")
print(df_concat_col)题目6 (merge 表关联,模拟 SQL JOIN)
基于上面 df_all 和 df_class,按 name 做左连接,保留所有学生信息。
完整代码
python
# 左连接:以左表 df_all 为准
df_merge = pd.merge(
left=df_all,
right=df_class,
on="name", # 关联字段
how="left" # 连接方式:left/right/inner/outer
)
print("左连接结果:")
print(df_merge)输出
name score class
0 张三 85 一班
1 李四 76 二班
2 王五 92 一班
3 赵六 88 NaN核心区分(面试口述)
concat:纯拼接,按索引对齐,适合结构相同的表;merge:按关键字段关联,等价 SQL JOIN,业务关联表首选。
六、时间序列专项(时序算法岗位必考)
题目7
构造时序数据,完成:
- 字符串时间列转为标准时间格式;
- 将时间设为行索引;
- 按月份重采样,对数值列求均值;
- 计算7日滑动平均。
完整代码
python
# 构造时序数据
data = {
"time": ["2025-01-01","2025-01-02","2025-02-01","2025-02-02"],
"value": [10,20,30,40]
}
df = pd.DataFrame(data)
# 1. 字符串转时间格式
df["time"] = pd.to_datetime(df["time"])
# 2. 设置为时间索引
df = df.set_index("time")
# 3. 按月重采样 + 求均值 M=月 D=日 W=周 Y=年
res_month = df.resample("M")["value"].mean()
print("按月重采样均值:")
print(res_month)
# 4. 7日滑动窗口平均(此处数据少,仅演示语法)
df["rolling_7"] = df["value"].rolling(window=7).mean()
print("\n增加滑动平均列:")
print(df)七、重复值、异常值处理
题目8
处理重复行与异常值:
- 查看重复行;
- 基于
name列去重,保留第一条; - 使用箱线图思路,剔除分数异常值(简单实现)。
完整代码
python
# 构造带重复、异常数据
df = pd.DataFrame({
"name":["张三","李四","张三","王五"],
"score":[85, 76, 85, 200] # 200 为异常值
})
# 1. 检测重复行
print("重复行标记:")
print(df.duplicated())
# 2. 按name去重,保留首次出现
df_drop_dup = df.drop_duplicates(subset=["name"], keep="first")
# 3. 简单异常值处理(四分位数法)
Q1 = df_drop_dup["score"].quantile(0.25)
Q3 = df_drop_dup["score"].quantile(0.75)
IQR = Q3 - Q1
# 上下界
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
# 筛选正常数据
df_normal = df_drop_dup[(df_drop_dup["score"] >= lower) & (df_drop_dup["score"] <= upper)]
print("\n剔除异常值后:")
print(df_normal)八、综合实战大题(面试压轴题)
综合题目
现有销售表 sales.csv,字段:date, product, sales
需求:
- 读取数据,处理缺失值;
- 将
date转为时间类型; - 按 产品 + 月份 分组,统计每月销售额总和;
- 计算每个产品的月销售额7日滑动均值;
- 结果导出为
result.csv。
完整综合代码
python
import pandas as pd
# 1. 读取数据
df = pd.read_csv("sales.csv", encoding="utf-8")
# 2. 缺失值填充
df["sales"] = df["sales"].fillna(df["sales"].mean())
df["product"] = df["product"].fillna("未知产品")
# 3. 时间转换
df["date"] = pd.to_datetime(df["date"])
# 4. 产品+月份分组求和
df["month"] = df["date"].dt.month # 提取月份
group_df = df.groupby(["product", "month"])["sales"].sum().reset_index()
group_df.rename(columns={"sales": "month_sales"}, inplace=True)
# 5. 滑动平均(按产品分组后计算)
def rolling_mean(series):
return series.rolling(window=7, min_periods=1).mean()
group_df["rolling_7"] = group_df.groupby("product")["month_sales"].apply(rolling_mean)
# 6. 导出结果
group_df.to_csv("result.csv", index=False, encoding="utf-8")
print("综合处理完成,结果已导出")九、面试手写速记要点
- 筛选:多条件用
& | ~,条件必加括号; - 缺失值:
isnull()→dropna()/fillna(); - 映射:单列用
map,复杂逻辑/多列用apply; - 分组:
groupby + agg + reset_index三连; - 拼接:同结构用
concat,关联表用merge; - 时序:
to_datetime转时间,resample重采样,rolling滑动窗口。