系列文章目录
B站视频内容智能分析系统(二):Docker Compose 一键部署
B站视频内容智能分析系统(六):Text-to-SQL 结构化查询
文章目录
- 系列文章目录
- 前言
- [一、为什么要做 Text-to-SQL](#一、为什么要做 Text-to-SQL)
- [二、4-Agent Pipeline 总览](#二、4-Agent Pipeline 总览)
- [三、Agent 1:意图理解](#三、Agent 1:意图理解)
- [1. 自然语言 → 结构化意图](#1. 自然语言 → 结构化意图)
- [2. 日期推断](#2. 日期推断)
- [四、Agent 2:Schema 检索](#四、Agent 2:Schema 检索)
- [1. 静态 Schema](#1. 静态 Schema)
- [2. 为什么不用 LLM 做 Schema](#2. 为什么不用 LLM 做 Schema)
- [五、Agent 3:SQL 生成](#五、Agent 3:SQL 生成)
- [1. Prompt 设计](#1. Prompt 设计)
- [2. 重试纠错](#2. 重试纠错)
- [六、Agent 4:SQL 审查](#六、Agent 4:SQL 审查)
- [1. 四维审查](#1. 四维审查)
- [2. 审查结果](#2. 审查结果)
- 七、UP主名称三层标准化
- [1. 问题背景](#1. 问题背景)
- [2. LLM Prompt 注入](#2. LLM Prompt 注入)
- [3. 后处理模糊匹配](#3. 后处理模糊匹配)
- [4. 查询文本注入](#4. 查询文本注入)
- 八、结果格式化
- 九、完整流程串起来
- 总结
前言
前面五篇讲了从视频到知识库的完整链路:采集→转写→精炼→入库。这篇开始进入查询侧------用户怎么用自然语言来查数据。
这个系统有两种查询通道:Text-to-SQL(结构化查询)和 RAG(语义检索)。这篇先讲 Text-to-SQL。
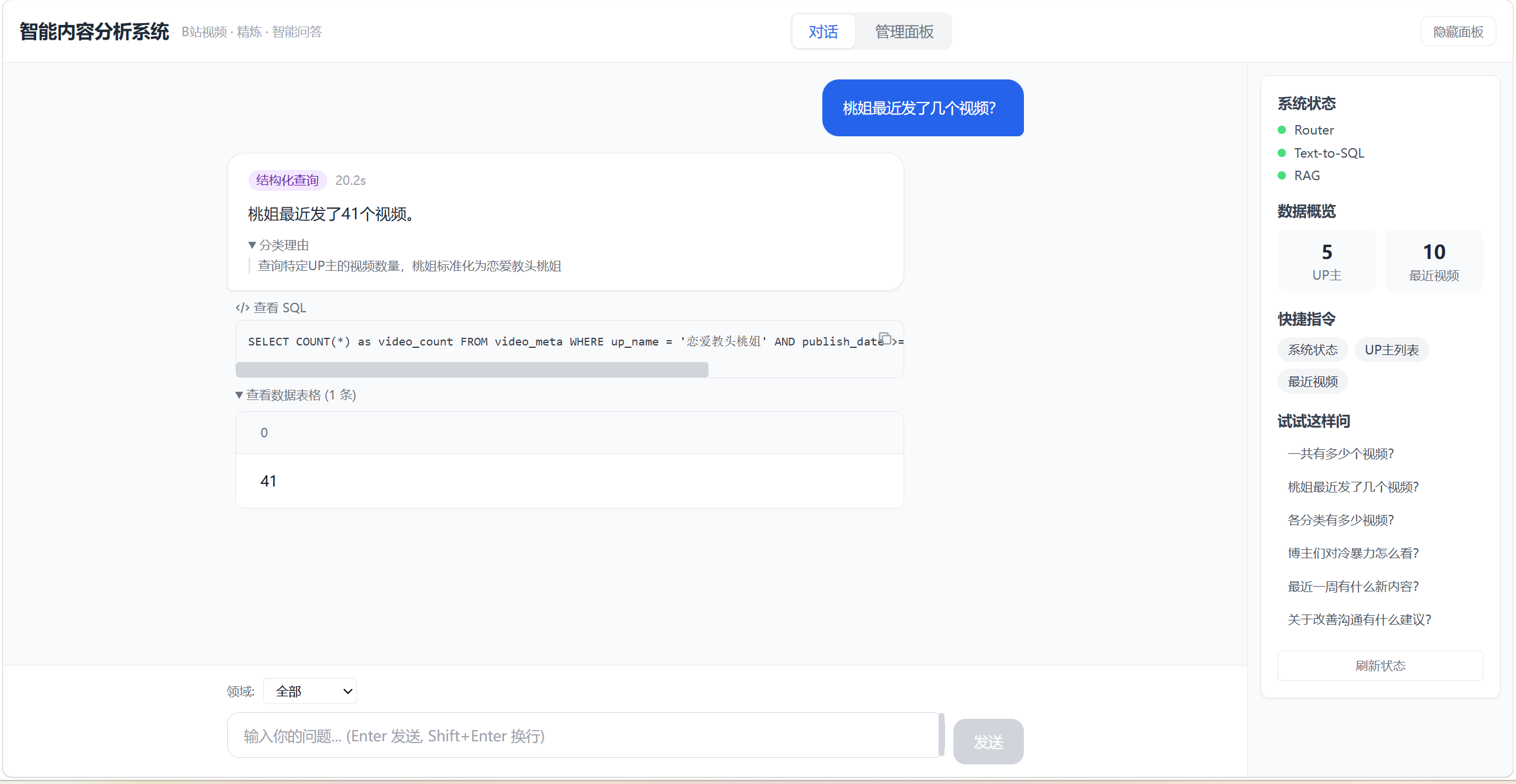
Text-to-SQL 的目标是:用户说"桃姐最近发了几个视频?",系统自动生成 SQL 并执行,返回结果。听起来简单,但 LLM 直接生成 SQL 经常会出错------表名写错、字段不存在、语法不对......所以我做了一个 4-Agent Pipeline,每个 Agent 各管一步,层层把关。
一、为什么要做 Text-to-SQL
RAG 擅长回答"博主们对冷暴力怎么看"这种语义类问题,但对于"桃姐发了几个视频""哪个博主更新最频繁"这种统计类问题就无能为力了------它检索的是文本片段,做不了聚合计算。
Text-to-SQL 补上了这块短板。把自然语言转成 SQL,直接在 DuckDB 上执行,什么 COUNT、GROUP BY、ORDER BY 都能用。
两个通道互补:
- Text-to-SQL:精确统计、排序、过滤 → "几个""最多""最近"
- RAG:观点检索、内容理解 → "怎么看""有什么建议"
二、4-Agent Pipeline 总览
一个用户问题经过 4 个 Agent 依次处理:
用户问题:"桃姐最近发了几个视频?"
↓
Agent 1: IntentAgent → 意图理解
{"query_target": "video_count", "filters": {"up_name": "恋爱教头桃姐", "date_range": "recent"}}
↓
Agent 2: SchemaAgent → Schema 检索(静态,不需要 LLM)
{"tables": ["video_meta"], "fields": {"video_meta": ["up_name", "publish_date"]}}
↓
Agent 3: SQLGenAgent → SQL 生成
{"sql": "SELECT COUNT(*) FROM video_meta WHERE up_name = '恋爱教头桃姐' ORDER BY publish_date DESC LIMIT 10"}
↓
Agent 4: ReviewAgent → SQL 审查
{"passed": true}
↓
执行 SQL → DuckDB → 结果 → LLM 格式化为自然语言回答整个 Pipeline 还有重试机制:如果 SQL 审查不通过或执行报错,会把错误信息反馈给 SQLGenAgent 重新生成,最多重试 3 次。
python
class TextToSQLPipeline:
def run(self, question, pre_intent=None):
iterations = 0
last_error = None
while iterations < MAX_RETRIES:
iterations += 1
# Agent 1: 意图理解
intent = self.intent_agent.run(question) if not pre_intent else ...
# Agent 2: Schema 检索(静态)
schema = self.STATIC_SCHEMA
# Agent 3: SQL 生成(重试时带上次错误)
sql_result = self.sql_gen_agent.run(intent, schema, retry_hint=last_error)
# Agent 4: SQL 审查
review = self.review_agent.run(sql, intent, schema)
if review.get("passed"):
query_result = execute_sql(sql)
answer = self.format_result(query_result, question, sql)
return {"success": True, "sql": sql, "answer": answer}
else:
last_error = "SQL 审查未通过: " + review["issues"]三、Agent 1:意图理解
1. 自然语言 → 结构化意图
IntentAgent 的任务是把用户的自然语言问题转成结构化的查询意图:
输入:"桃姐最近发了几个视频?"
输出:
{
"query_type": "video",
"query_target": "video_count",
"filters": {
"up_name": "恋爱教头桃姐",
"date_range": {"type": "recent"}
},
"aggregation": "count",
"limit": 10
}query_target 有 5 种类型:
| query_target | 含义 | 示例问题 |
|---|---|---|
video_count |
视频数量统计 | "桃姐有几个视频" |
video_list |
视频列表 | "最近有什么新视频" |
up_info |
UP主信息 | "有哪些博主" |
category_stats |
分类统计 | "各分类有多少视频" |
video_summary |
视频摘要 | "桃姐最近聊了什么" |
Prompt 里注入了当前日期,让 LLM 能正确处理"今年""上个月"这类相对时间:
python
INTENT_SYSTEM_PROMPT = """你是一个意图理解专家。
## 当前日期
今天是 {current_date},年份是 {current_year}。
## 重要规则
- 如果用户没有指定年份,使用当前年份(2026年)
- 例如用户说"三月一日",应解析为 2026-03-01
"""2. 日期推断
一个常见的问题是"最近"到底是什么意思。在 Prompt 里定义了规则:
- "最近"→
recent(默认最近 10 条) - "这周"→
this_week - "这个月"→
this_month - 具体日期 →
custom+start_date/end_date
Pipeline 里还会做一次转换,把 Router Agent 传过来的意图格式适配到 T2S 的格式:
python
def _convert_router_intent(self, router_intent, question):
q = question.lower()
if any(kw in q for kw in ["几个", "多少", "数量", "统计"]):
query_target = "video_count"
elif any(kw in q for kw in ["up主", "博主", "有哪些人"]):
query_target = "up_info"
elif any(kw in q for kw in ["分类", "各分类"]):
query_target = "category_stats"
else:
query_target = "video_list"这种关键词启发式是对 LLM 意图理解的补充------大多数情况下 Router Agent 已经做了初步分类,T2S 只需要微调。
四、Agent 2:Schema 检索
1. 静态 Schema
SchemaAgent 原本是用 LLM 来匹配表和字段的,但我们的系统只有 2 张表(video_meta 和 up_info),完全不需要 LLM 来做。直接硬编码:
python
STATIC_SCHEMA = {
"tables": [
{
"name": "video_meta",
"description": "视频元数据表",
"columns": ["bvid", "up_name", "up_uid", "title", "publish_date",
"category", "duration", "summary", "tags", "created_at"]
},
{
"name": "up_info",
"description": "UP主信息表",
"columns": ["uid", "name", "total_videos", "last_update",
"config_file", "created_at"]
},
],
"joins": ["video_meta.up_uid = up_info.uid"],
"reasoning": "Static schema --- only 2 tables in the system",
}2. 为什么不用 LLM 做 Schema
很多 Text-to-SQL 系统用 LLM 来动态匹配 Schema------从数据库的所有表和字段中,找到和当前查询相关的。这在表很多(几十上百张)的时候很有用。
但我们的系统只有 2 张表、十几个字段。用 LLM 做 Schema 匹配完全是浪费------每次多花 1-2 秒,还可能匹配错。直接硬编码,又快又准。
这是一个实用主义的选择:系统复杂度要和实际场景匹配,不要为了"完整"而引入不必要的 LLM 调用。
五、Agent 3:SQL 生成
1. Prompt 设计
SQLGenAgent 是核心的 SQL 生成器。Prompt 里给了大量的示例:
python
SQL_GEN_SYSTEM_PROMPT = """你是一个SQL生成专家。
## 重要提示
- 必须使用DuckDB语法
- 日期格式:DATE 'YYYY-MM-DD'
- 字符串用单引号
## 示例
### 查询某个UP主的视频数量
SELECT COUNT(*) as video_count FROM video_meta WHERE up_name = '某UP主'
### 查询最近发布的10个视频
SELECT bvid, title, up_name, publish_date FROM video_meta
ORDER BY publish_date DESC LIMIT 10
### 查询各分类的视频数量统计
SELECT category, COUNT(*) as count FROM video_meta
GROUP BY category ORDER BY count DESC
### 查询某个UP主最近一周的视频
SELECT title, publish_date, duration FROM video_meta
WHERE up_name = '某UP主'
AND publish_date >= CURRENT_DATE - INTERVAL '7 days'
ORDER BY publish_date DESC
"""Prompt 里给示例的好处是:LLM 会模仿示例的风格和语法来生成 SQL,减少语法错误。特别是 DuckDB 特有的语法(比如 INTERVAL '7 days'),如果不在示例里展示,LLM 可能会生成 MySQL 语法。
2. 重试纠错
SQLGenAgent 支持一个 retry_hint 参数------如果上次生成的 SQL 有问题,把错误信息带上,让 LLM 修正:
python
def generate(self, intent, schema, retry_hint=None):
user_content = SQL_GEN_USER_PROMPT.format(intent=..., schema=...)
# 重试时附加错误提示
if retry_hint:
user_content += f"\n\n## 上次生成的 SQL 有误,请修正\n{retry_hint}"比如第一次生成的 SQL 用了 LIMIT 但 DuckDB 的某些场景下需要用 TOP,审查 Agent 发现问题后,Pipeline 会把审查意见传给 SQLGenAgent 重新生成。
这种"生成→审查→纠错→重新生成"的循环,能显著提高 SQL 的正确率。
六、Agent 4:SQL 审查
1. 四维审查
ReviewAgent 从四个维度检查 SQL:
python
REVIEW_SYSTEM_PROMPT = """你是一个SQL审查专家。
## 审查维度
### 1. 语法正确性
- 字段名、表名是否正确
- 关键字是否正确使用
### 2. 逻辑正确性
- 查询逻辑是否符合意图
- WHERE条件是否正确
### 3. 性能检查
- 是否有潜在的全表扫描
- 是否有多余的JOIN
### 4. 安全性
- 是否有注入风险
- 是否有恒成立或永假的WHERE条件
"""2. 审查结果
审查 Agent 输出结构化 JSON:
json
{
"passed": true,
"issues": [],
"suggestions": ["可以添加 ORDER BY 使结果更清晰"]
}或者有问题时:
json
{
"passed": false,
"issues": [
{
"severity": "error",
"type": "syntax",
"description": "字段 'video_count' 不存在于 video_meta 表中",
"suggestion": "使用 COUNT(*) as video_count"
}
]
}passed 为 true 的条件是没有任何 severity: "error" 的问题。warning 级别的问题不会阻止执行,但会记录在案。
七、UP主名称三层标准化
这是我觉得这个项目里最有意思的设计之一。
1. 问题背景
用户在前端提问时,不会用 UP主 的完整名称。比如 UP主 的完整名称是"恋爱教头桃姐",但用户只会说"桃姐"。如果 SQL 里写 WHERE up_name = '桃姐',肯定查不到任何结果。
这个问题看起来简单------做个模糊匹配不就行了?但实际上比想象的复杂:
- "桃姐" → "恋爱教头桃姐"(包含关系)
- "安佳" → "安佳佳"(简称)
- "啊柚" → "啊柚的碎碎念"(部分匹配)
- "夹性学姐" → "夹性学姐在这"(去掉后缀)
每种情况的匹配策略不一样,所以我做了三层标准化。
2. LLM Prompt 注入
第一层是在 Router Agent 的意图分类 Prompt 里,直接把所有 UP主 的完整名称列表注入进去:
python
# 从 DuckDB 查询所有已知 UP主 名称
up_names = conn.execute(
"SELECT DISTINCT up_name FROM video_meta"
).fetchall()
# 注入到 Prompt
prompt = f"""
## 已知UP主完整名称列表
以下是从数据库中查询到的所有UP主完整名称。
用户可能使用简称或昵称,你需要将其标准化为以下完整名称之一:
{up_names_text}
## 重要规则
- 用户说"桃姐" → up_name 应设为 "恋爱教头桃姐"
- 如果你在 reasoning 中说"桃姐标准化为恋爱教头桃姐",
那 up_name 就必须是 "恋爱教头桃姐"
"""这层靠 LLM 的理解能力来做标准化。大多数情况下 LLM 能正确匹配------它知道"桃姐"是"恋爱教头桃姐"的简称。
但 LLM 不总是靠谱的。有时候它会输出用户的原始输入"桃姐"而不是全名"恋爱教头桃姐"。所以需要后处理。
3. 后处理模糊匹配
第二层是在代码里做模糊匹配兜底:
python
def _normalize_up_name(self, name: str) -> Optional[str]:
"""将用户输入的简称/昵称匹配到已知UP主全名"""
# 1. 精确匹配
if name in self._up_names:
return name
# 2. 全名包含简称
matches = [n for n in self._up_names if name in n]
if len(matches) == 1:
return matches[0]
# 3. SequenceMatcher 子序列匹配
best_match = None
best_score = 0.0
for n in self._up_names:
score = SequenceMatcher(None, name, n).ratio()
if score > best_score and score >= 0.6:
best_score = score
best_match = n
return best_match三层匹配策略:
- 精确匹配:用户输入的就是全名,直接返回
- 包含匹配:"桃姐" 在 "恋爱教头桃姐" 里,命中
- 子序列匹配 :用
SequenceMatcher计算相似度,≥ 0.6 就认为匹配
4. 查询文本注入
第三层是在 SQL 生成的 Prompt 里,提示 LLM 可以使用模糊匹配:
python
SQL_GEN_SYSTEM_PROMPT = """
### 查询UP主视频(模糊匹配,名称可能不完整时使用)
SELECT bvid, title, up_name, publish_date FROM video_meta
WHERE up_name LIKE '%UP主关键词%'
ORDER BY publish_date DESC
### 查询某个UP主的视频数量
SELECT COUNT(*) as video_count FROM video_meta WHERE up_name = '某UP主'
-- 注:如果名称可能不完整,也可用 WHERE up_name LIKE '%某UP主%'
"""这样即使前两层标准化都失败了,SQL 里用 LIKE '%桃姐%' 也能查到数据。
三层标准化的效果:
| 层 | 方法 | 处理 |
|---|---|---|
| 第一层 | LLM Prompt 注入全名列表 | LLM 理解语义匹配 |
| 第二层 | 代码后处理模糊匹配 | SequenceMatcher 兜底 |
| 第三层 | SQL 中使用 LIKE | 数据库层面兜底 |
实际使用中,第一层就解决了 90% 的情况,第二层兜到 99%,第三层是最后的保险。
八、结果格式化
SQL 执行成功后,查询结果是原始的行列数据,需要转成自然语言回答:
python
def format_result(self, query_result, question, sql):
"""用 LLM 把查询结果转成自然语言"""
if not query_result:
return "没有找到相关数据。"
# 单值结果直接取
if len(query_result) == 1 and len(query_result[0]) == 1:
result_str = str(query_result[0][0])
else:
result_str = "\n".join(str(row) for row in query_result)
# 用 LLM 生成自然语言回答
prompt = RESULT_FORMAT_PROMPT.format(
question=question,
query_result=result_str
)
answer = self.llm.invoke([HumanMessage(content=prompt)])
return answer.strip()比如 SQL 返回 [(8,)],LLM 会生成:"知识库中共有 8 个视频。"
如果 LLM 格式化失败了,就降级为简单拼接:"查询结果:8"。
九、完整流程串起来
看一个完整的查询流程:
用户:"桃姐最近发了几个视频?"
↓
[Router Agent]
意图分类 → structured
UP主标准化 → "桃姐" → "恋爱教头桃姐"
↓
[Text-to-SQL Pipeline]
Agent 1 (IntentAgent):
{"query_target": "video_count", "up_name": "恋爱教头桃姐", "date_range": "recent"}
↓
Agent 2 (SchemaAgent):
静态 Schema → video_meta 表
↓
Agent 3 (SQLGenAgent):
SELECT COUNT(*) FROM video_meta
WHERE up_name = '恋爱教头桃姐'
ORDER BY publish_date DESC LIMIT 10
↓
Agent 4 (ReviewAgent):
passed: true ✅
↓
执行 SQL → [(8,)]
↓
结果格式化 → "桃姐最近发布了 8 个视频。"
↓
[返回给用户]
{
"answer": "桃姐最近发布了 8 个视频。",
"route_type": "structured",
"sql": "SELECT COUNT(*) FROM video_meta ...",
"sql_result": [[8]],
"response_time": 2.3
}整个过程大概 2-3 秒,主要耗时在 4 次 LLM 调用上(IntentAgent、SQLGenAgent、ReviewAgent、结果格式化各一次)。
总结
Text-to-SQL 的 4-Agent Pipeline 虽然看起来复杂,但每个 Agent 各司其职:意图理解、Schema 匹配、SQL 生成、SQL 审查。重试纠错机制让 SQL 正确率从"直接生成"的 70% 提升到了 95% 以上。UP主名称三层标准化解决了用户说简称、数据库存全名的匹配问题。下一篇讲 RAG 语义检索------BM25 + 向量混合搜索是怎么做的。