在上一篇文章中决策树的特征划分选择中的ID3算法,这篇文章总结一下决策树中常用的特征划分选择方法.
信息增益(ID3使用的划分方式)
ID3算法就是通过计算信息熵和信息增益得到如何划分可以使分类结果更"纯净"能使结果更纯净的划分就是更好的划分。
熵(Entropy):是热力学中的概念,是系统的混乱度或无序度的度量。系统越混乱,熵就越大。
信息熵:在信息论中引用了热力学中的概念,用来描述信息的有序和混乱程度,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
H(X)=−∑i=1npilog2pi=∑i=1npilog21piH(X) = -\sum\limits_{i=1}^{n}p_i log_2p_i=\sum\limits_{i=1}^{n}p_i log_2\frac{1}{p_i}H(X)=−i=1∑npilog2pi=i=1∑npilog2pi1
在这个公式中对数函数一般是以2为底数,但是实际上也可以为其他的数。其中nnn代表X的nnn种不同的离散取值。而pi{p_i}pi表示X取值为iii的概率
信息增益(Information Gain)代表了在知道了 某个条件下,信息的不确定性减少的程度。信息增益的计算公式为:
g(D,A)=H(D)−H(D∣A)g(D,A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
其中H(D)H(D)H(D)为熵,即D的不确定性,H(D∣A)H(D|A)H(D∣A)为条件熵,表示在A的条件下D的不确定性。
假设训练数据集D和特征A,计算信息增益的步骤如下:
第一步:计算数据集D的经验熵:
H(D)=−∑k=1K∣Ck∣∣D∣log2∣Ck∣∣D∣=−∑k=1Kp(x)log21p(x)H(D) = -\sum\limits_{k=1}^{K}\frac{|C_k|}{|D|} log_2\frac{|C_k|}{|D|}= -\sum\limits_{k=1}^{K}p(x) log_2\frac{1}{p(x) }H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣=−k=1∑Kp(x)log2p(x)1
其中,∣Ck∣|{C_k}|∣Ck∣为第kkk类样本的数目,∣D∣|D|∣D∣为数据集D的数目,p(x)p(x)p(x)即代表 某一类样本的概率 。
第二步:计算特征A对数据集D的条件熵H(D|A)
H(D∣A)=∑i=1n∣Di∣∣D∣H(Di)=−∑i=1n∣Di∣∣D∣∑k=1K∣Dik∣∣D∣log2∣Dik∣∣D∣H(D|A) = \sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}H(D_i)=-\sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}\sum\limits_{k=1}^{K}\frac{|D_{ik}|}{|D|} log_2\frac{|D_{ik}|}{|D|} H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣D∣∣Dik∣log2∣D∣∣Dik∣
第三步:计算信息增益:
g(D,A)=H(D)−H(D∣A)g(D,A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
一般而言,信息增益越大,则意味着使用属性A来进行划分所获得的"纯度提升" 越大。因此,我们可使用信息增益来进行决策树的划分属性选择。ID3决策树学习算法就是以信息增益为准则来选择划分属性的。
信息增益率(C4.5使用的划分方式)
ID3算法是决策树最基础的算法,但是还是有很多值得改进的地方。
- ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
- ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大,会影响模型选择特征。
- ID3算法对于缺失值的情况没有做考虑
- 没有考虑过拟合的问题
因此对ID3算法改进,就有了C4.5算法。、
-
对于第一个问题,不能处理连续特征, C4.5的思路是将连续的特征离散化。比如m个样本的连续特征A有mmm个,从小到大排列为a1,a2,⋯,ama_1,a_2,\cdots,a_ma1,a2,⋯,am,则C4.5取相邻两样本值的平均数,一共取得m−1m-1m−1个划分点,其中第iii个划分点TiT_iTi表示为Ti=ai+ai+12T_i = \frac{a_i+a_{i+1}}{2}Ti=2ai+ai+1.对于这m−1m-1m−1个点,分别计算以该点作为二元分类点时的信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。比如取到的增益最大的点为ata_tat,则小于ata_tat的值为类别1,大于ata_tat的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
-
对于第二个问题,信息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比的变量gR(D,A)g_R(D,A)gR(D,A),它是信息增益和特征熵的比值。表达式如下:
gR(D,A)=g(D,A)HA(D)g_R(D,A) =\frac{g(D,A)}{H_A(D)}gR(D,A)=HA(D)g(D,A)
其中
HA(D)=−∑i=1n∣Di∣∣D∣log2∣Di∣∣D∣H_A(D) = -\sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|}HA(D)=−i=1∑n∣D∣∣Di∣log2∣D∣∣Di∣
其中nnn为特征A的类别数,DiD_iDi 为特征AAA的第iii个取值对应的样本个数。∣D∣|D|∣D∣为样本个数。特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
-
对于第三个缺失值处理的问题,主要需要解决的是两个问题,一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。
对于第一个子问题,对于某一个有缺失特征值的特征A。C4.5的思路是将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值A的数据D1,另一部分是没有特征A的数据D2. 然后对于没有缺失特征A的数据集D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比,最后乘上一个系数,这个系数是无特征A缺失的样本加权后所占加权总样本的比例。
对于第二个子问题,可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如缺失特征A的样本a之前权重为1,特征A有3个特征值A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
-
对于第四个问题,C4.5引入了正则化系数进行初步的剪枝。具体方法这里不讨论
C4.5虽然改进或者改善了ID3算法的几个主要的问题,仍然有优化的空间。
- 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。后面讲CART树的时候我们会专门讲决策树的减枝思路,主要采用的是后剪枝加上交叉验证选择最合适的决策树。
- C4.5生成的是多叉树,即一个父节点可以有多个节点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
- C4.5只能用于分类,如果能将决策树用于回归的话可以扩大它的使用范围。
- C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多准确性的话,那就更好了。
基尼指数(CART算法使用的划分方式)
CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。
具体的,在分类问题中,假设有K个类别,第k个类别的概率为pkp_kpk, 则基尼系数的表达式为:
Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2Gini(p) = \sum\limits_{k=1}^{K}p_k(1-p_k) = 1- \sum\limits_{k=1}^{K}p_k^2Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
如果是二类分类问题,计算就更加简单了,如果属于第一个样本输出的概率是ppp,则基尼系数的表达式为:
Gini(p)=2p(1−p)Gini(p) = 2p(1-p)Gini(p)=2p(1−p)
对于个给定的样本D,假设有K个类别, 第k个类别的数量为CkC_kCk,则样本D的基尼系数表达式为:
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2Gini(D) = 1-\sum\limits_{k=1}^{K}(\frac{|C_k|}{|D|})^2Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
可以看出基尼系数表达式采用二次运算,对比熵模型的表达式的对数运算更加简单。尤其是二分类的计算,基尼系数更加简单。同样和熵模型的度量方式比,基尼系数对应的误差也比较小。
因此CART分类树算法采用更简单的基尼系数,同时每次仅仅对某个特征的值进行二分,而不是多分,这样CART分类树算法建立起来的是二叉树,而不是多叉树,从而简化计算提高运算速度。
CART算法非常简洁高效,但是它对样本变化很敏感。如果样本发生一点点的改动,可能就会导致树结构的剧烈改变。
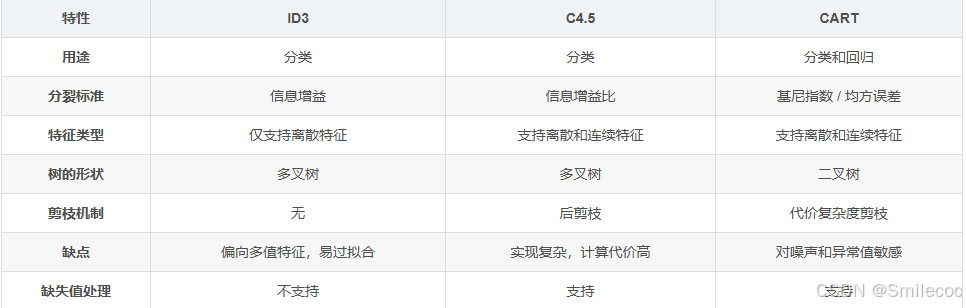
这三种决策树的划分选择方法的总结如下表:
参考文章:
https://www.cnblogs.com/pinard/p/6050306.html
