先看一段 C++ 程序。请花半分钟读一下,心中估一个数------你觉得它跑完大概要多久?
cpp
constexpr int N = 1'000'000;
constexpr int NG = 262144;
auto* buf = new uint64_t[NG];
std::memset(buf, 0xfe, NG * 8); // 全填 0xfe,表示"空槽"
for (int i = 0; i < N; ++i) {
int g = (i >> 7) & (NG - 1); // 前 128 次 g=0,接下来 128 次 g=1,依此类推
uint64_t w = buf[g]; // 读 64 位 word
uint64_t fb = w & 0x8080808080808080ULL;
uint64_t e = ( (w ^ 0xfefefefefefefefeULL) - 0x0101010101010101ULL )
& ~(w ^ 0xfefefefefefefefeULL) & 0x8080808080808080ULL;
int pos = fb ? (std::countr_zero(fb) / 8) : 0;
((uint8_t*)buf)[g * 8 + pos] = (i & 0x7f); // 写入 1 byte
}程序看起来比较奇怪,但是是有实际意义的,会在最后揭露。这段程序做的事其实不复杂:
- 有一个
uint64_t数组(262144 个元素),全部初始化为0xfe - 循环 100 万次,遍历方式简单说来是这样的:前 128 次迭代读写
buf[0],接着 128 次读写buf[1],再 128 次读写buf[2]......每 128 次前进一步。从缓存角度看这很友好,反复命中同一个 cache line - 每次循环:读一个 64 位值,做一点位运算,然后修改其中的 1 个字节写回去
而且循环本身是 i 从 0 到 N-1 的顺序推进,g 也顺次递增,每组用完再切下一组,预取器很容易预测------整段代码从时间局部性、空间局部性到硬件预取的角度来看,几乎挑不出毛病。
据此估算:每次迭代一条 mov 加载、几条 ALU 位运算、一条 mov 写回。位运算在超标量调度下几乎不占额外周期,假设写回全命中 L1 缓存,每次迭代大约需要 5-8 个周期。100 万次 × 6 周期 ÷ 2.5 GHz ≈ 2.4 ms。
实际跑一下:
css
Time: 178 ms178 毫秒。 平均每次迭代 ≈ 178 纳秒。考虑到我所用的 M5 芯片跑在 2.5 GHz,这相当于每次迭代花费了约 445 个时钟周期。
思考...
如果每次迭代只做一条读、几个位运算、一条写,凭什么花掉 445 个周期?
是 false sharing 吗?但是单线程程序没有缓存一致性协议介入,false sharing 压根不成立,排除。
是 cache miss 吗?但是连续 128 次都在操作同一个 slot,反复命中 L1d,缓存命中率高得不能再高。
分支预测出问题了吧?但是循环体里没有不可预测的 if,迭代次数在编译期就能推断,分支预测器毫无压力。
那总不会是 TLB miss?可是整个数组才 2 MB,连 L2 都装得下,TLB 覆盖绰绰有余。
继续思考......
逐个排除之后,一个不起眼的细节突然变得醒目------每次迭代读了一个完整的 uint64_t,但只修改了其中的一个 byte,然后写回去那个改动的 byte。
读 → 改 1 byte → 写回 → 下一条又读同一个 64 位 word。
等一下。
下一条迭代执行 w = buf[g] 的时候,我们刚才写进去的那个 byte 在哪?它还在 Store Buffer 里。
为什么要有个 Store Buffer?因为 store 指令太慢了。一条 store 要把数据写进 L1d,但目标缓存行可能不在 L1d 里------比如被别的核心持有,需要先发 RFO(Request For Ownership)抢过来,来回几百个周期。如果没有 Store Buffer,流水线就得干等------store 不完成,后面的指令全卡住。Store Buffer 的存在就是为了把流水线和写回 L1d 的漫长过程解耦:store 把数据往里一丢就算完事,流水线继续往前走,后台再慢慢排空。
可以把 Store Buffer 想象成 L1d 的一个"寄存处"------写进去的东西暂时放在这里,还没正式归档。与此同时,它还有一个加分能力叫 Store-to-Load Forwarding:如果后续的 load 恰好命中 store buffer 里某条还没排空的 store,CPU 直接把最新值转发给 load,不用等 L1d。
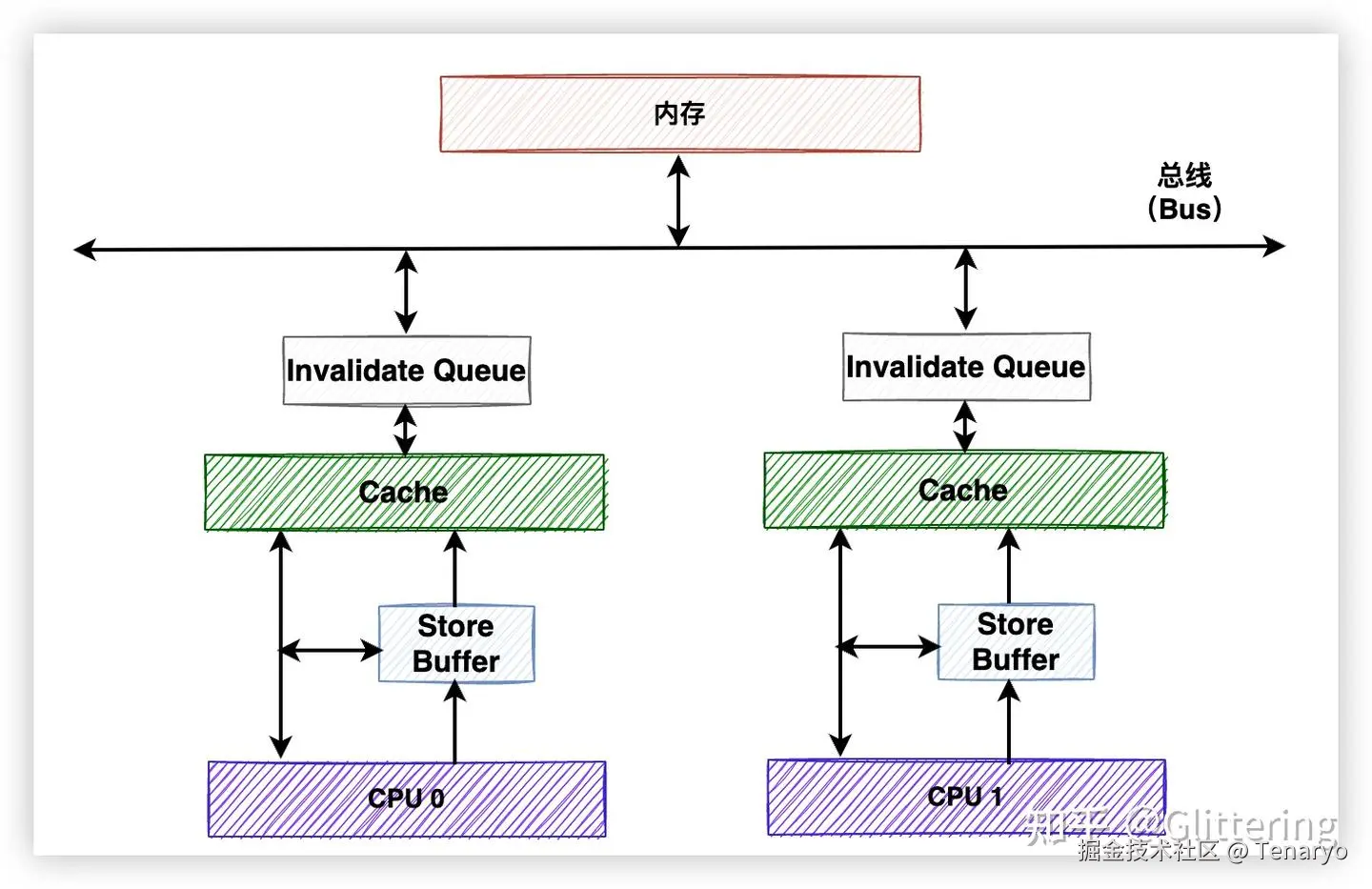
这听起来完美------不是吗?我们刚写了一个 byte,下次读的时候 CPU 直接转发过来,什么都不用等。
但问题恰恰卡在"转发"这一步。
我们的 store 只写了 1 个 byte 。下次的 load 却要读 8 个 byte (完整的 64 位 word)。store buffer 里只有那个被修改的 byte 的新值------剩下 7 个 byte 还在 L1d 里。CPU 不能简单地把 store buffer 里的 1 个 byte 转发给一条 8 byte 的 load------"你的数据不全,缺的那7个字节去哪拿?"
这时候 CPU 走的是 Partial Store-to-Load Forwarding 路径。它不是单纯转发,而是:
- 停下来等那个 byte store 写进 L1d
- 再从 L1d 读回完整的 64 位值(其中 1 个 byte 是新写的,7 个 byte 是原来的)
- 把读回的值交给 load 指令
Intel/AMD 上这条路径需要 5-8 个额外周期。Apple Silicon 虽然 store buffer 更深,但 partial forwarding 同样慢。每次迭代都在等这个"1 byte 写入 → 8 byte 读出"的合并完成------积少成多,100 万次就是 178ms。
尝试 1:全 Word 写入
既然 byte→word 转发很慢,那我们换个写法------不要写 1 个 byte,改成构造好完整的 64 位值后一次性写回去(full-word RMW):
cpp
// 之前(byte store):
((uint8_t*)buf)[g * 8 + pos] = (i & 0x7f);
// 改为(full-word store):
uint64_t new_w = (w & ~(0xFFULL << (pos * 8)))
| ((uint64_t)(i & 0x7f) << (pos * 8));
buf[g] = new_w;结果是:
arduino
Slow (byte store) : 178 ms
Full-word RMW : 75 ms ← 快了 2.4 倍有一定改善,但这仍然不够快------因为下一条迭代还是读写同一个数组元素。即使 word→word forwarding 比 byte→word 快,CPU 仍然在对着同一个地址反复读-改-写:
store → store buffer → load 命中 store buffer(转发)→ 读的值再修改 → 又一个 store 进 store buffer
这条依赖链把迭代串行化了,导致乱序执行几乎派不上用场,数据依赖下 CPU 只能干等。
真正的修复:把依赖链打断
核心问题很简单:每次迭代都在读自己上一次写的东西。 如果我们让连续迭代访问不同的数组元素,就不会有这个依赖链了。
具体做法------在计算下标 g 的时候,不要在 hash 之后仍然保持低位的顺序性。给 hash 值加一个 bit mixer,把连续的输入打散到全空间:
cpp
// 之前(顺序下标):
int g = (i >> 7) & (NG - 1);
// 改为(hash mixer 打散):
auto mix = [](uint64_t h) {
h ^= h >> 33; h *= 0xff51afd7ed558ccdULL;
h ^= h >> 33; h *= 0xc4ceb9fe1a85ec53ULL;
h ^= h >> 33; return h;
};
int g = mix(i) & (NG - 1);mixer 是 MurmurHash3 的 finalizer,三个 XOR + 两个乘法 + 三个 shift,5ns 之内完成。但因为 mix(i) 和 mix(i+1) 的值完全不相关,相邻两次迭代访问的数组元素大概率是不同的。
再看结果:
java
Slow (sequential) : 178 ms
Fast (hashed) : 1 ms ← 178 倍加速1ms。瓶颈从 445 个周期/迭代降到约 3 个周期。
原理解释很简单------Mixer 把写入"打散"以后:
- 第 i 次迭代写入
buf[A],数据进 store buffer - 第 i+1 次迭代读
buf[B](A ≠ B),直接命中 L1d------因为buf[B]不在 store buffer 的转发路径上,而它上次被修改已经是在很多个迭代之前,store buffer 早就把数据排空进 L1d 了 - L1d hit 只需要 3-4 个周期,比 byte→word forwarding 的十几周期省了一个数量级
注意:mixer 是双射(bijection),不会把两个不同的 key 混成相同的 hash。它只是把输入空间重新排列了一遍,不引入任何碰撞。对正确性零影响,对性能全是帮助。
实战:Swiss Table 的性能优化
以上不是一个虚构的 toy example。这段 benchmark 是我在实现 Swiss Table(Go 语言内置 map 的底层算法)时遇到的真实瓶颈。
测试场景:顺序插入 100 万个整数键值对。
初始版本用的是 std::hash<int>(在 aarch64 上等价于 identity------即 hash(x) = x)。由于连续键的 hash 值也是连续的,低 7 位(h₂)循环变化而高位(h₁)保持不变。这导致每 128 个连续键落入同一个"控制字组"------也就是 demo 中 g 不变的情况。
结果:
- 插入 100 万条:438 ms
std::unordered_map同样操作:12 ms
加 mixer 后:
- 插入 100 万条:10 ms(比 std 更快)
- 整体 benchmark 均有显著提升
| 场景 | 优化前 | 优化后 | std 对照 |
|---|---|---|---|
| 顺序插入 | 438ms | 10ms | 12ms |
| 随机插入 | 226ms | 9ms | 35ms |
| 混合操作 | 834ms | 53ms | 70ms |
| 密集迭代 | 5ms | 19ms | 12ms |
不是算法换成了更优的,不是重写了存储布局,就一条------在 hash 后面接了一个 5 行的 bit mixer,彻底消除了连续键触发的 RAW store-to-load forwarding 瓶颈。
结语
几十年前大家说"优化就是找一个更快的算法"。但在现代超标量、深度流水线、带 store buffer 和乱序执行的 CPU 上,硬件在执行你的程序时究竟经历了什么,往往比大 O 复杂度更重要。
一个 byte store 长啥样?一条 load 走的是 store buffer 还是 L1d?连续迭代访问同一地址会不会把乱序窗口卡死?这些问题如果能回答出来,几行代码就能撬动上百倍的性能差异。
而这正是「底层系统基石」系列想要达成的目标。
想深入了解 Store Buffer 的完整工作机制,请移步系列文章 缓存篇 V ------ 写策略、Store Buffer 与内存屏障,那里从硬件层面解释了 store buffer 如何与流水线解耦、store-to-load forwarding 的转发路径、以及不同 ISA 对内存排序模型的差异。