本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/
技术交流 QQ 群:1097156200

Wine Quality 可复现机器学习实验:随机森林二分类预测高质量葡萄酒
做机器学习入门的时候,很多人第一个想法是找个大项目、上深度学习。但我的经验是:先把一个经典小数据集吃透,比囫囵吞枣地跑十个项目更有价值。
这次选的是 Kaggle 上非常经典的 Wine Quality --- Red & White 数据集。选它的原因很简单------数据不大、结构清晰、不需要 GPU,而且结果很容易解释给别人听。
项目已经开源,地址在这里:
text
https://github.com/coderWang404/xingshuProjects/tree/main/2026-06-05-wine-quality-aihub克隆下来,装好依赖,一条命令就能跑通全部实验。
1. 先看一下数据长什么样
Wine Quality 数据集记录了红白葡萄酒的 11 项理化指标(比如酸度、糖分、酒精度、密度等),以及一个 0-10 的质量评分。合并红白两个文件后,一共 6497 条记录。
我扫了一下 quality 列的分布,发现一个很有意思的事:
| quality 分值 | 占比 |
|---|---|
| 3-4 分 | 很低 |
| 5 分 | 约 30% |
| 6 分 | 约 40% |
| 7 分 | 约 15% |
| 8-9 分 | 很少 |
中位数和 75% 分位数都是 6 分。也就是说,绝大多数酒被评为"中等",7 分及以上已经能挤进前 20% 了。所以我把 quality >= 7 定义为"高质量",这个阈值不是拍脑袋定的------它是数据本身告诉我的。
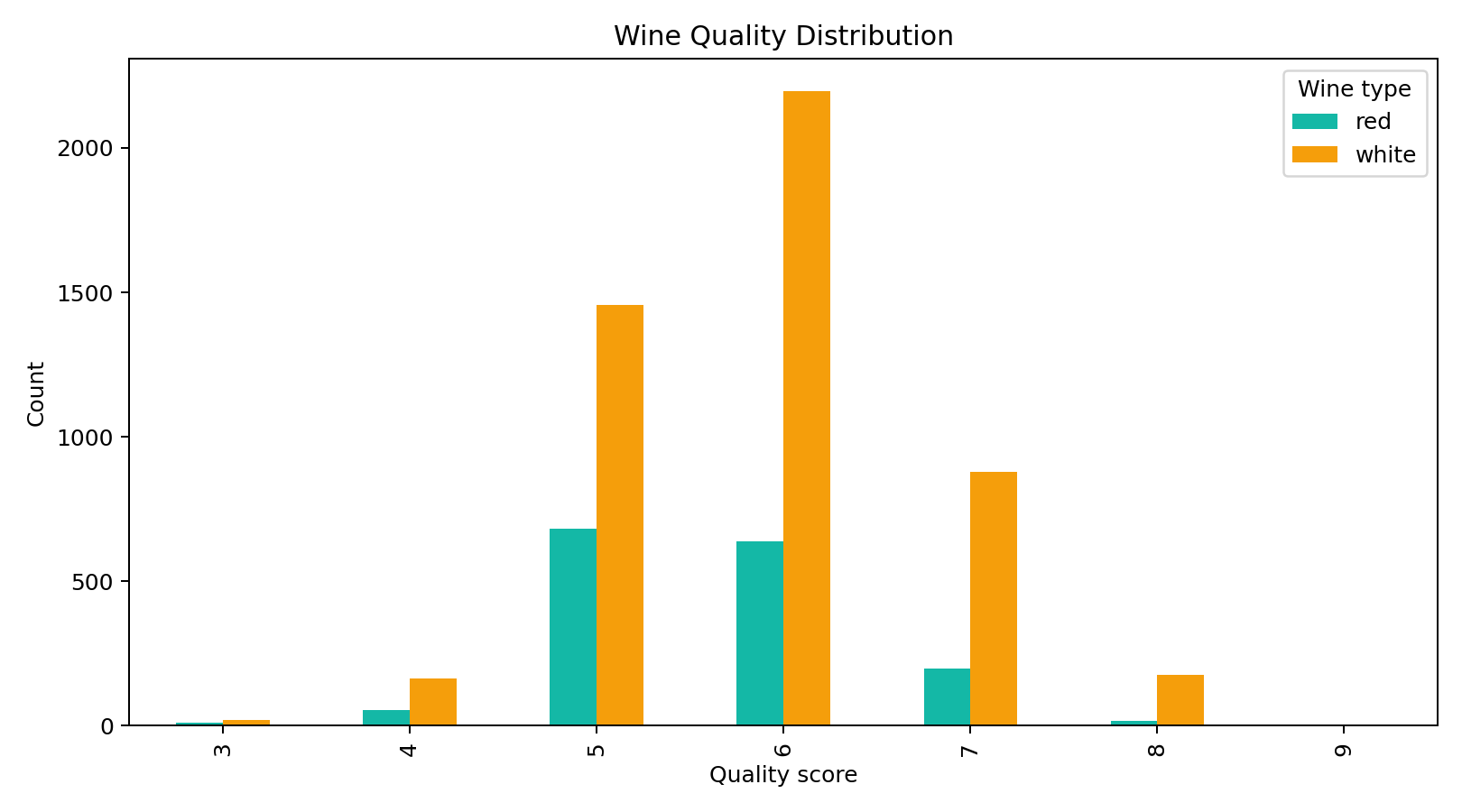
从图里能直观看到,高质量样本(7 分以上)是明显的少数类,占比只有 19.66%。这意味着后面建模时必须处理类别不均衡,否则模型很容易偷懒------全部猜"普通",也能对 80%。
2. 环境准备
依赖极少,一个 requirements.txt 就搞定了:
text
pandas
numpy
scikit-learn
matplotlib建议先建个虚拟环境:
bash
git clone https://github.com/coderWang404/xingshuProjects.git
cd xingshuProjects/2026-06-05-wine-quality-aihub
python -m venv venv
source venv/bin/activate # macOS/Linux
# venv\Scripts\activate # Windows
pip install -r requirements.txt3. 运行实验
bash
python experiments/wine-quality/run_experiment.py脚本会先检查本地有没有数据文件,没有的话自动从 UCI 仓库下载。运行完会在 outputs/ 目录输出所有图表和指标文件。
4. 为什么选随机森林?
坦白说,这个项目完全可以用 XGBoost 或者逻辑回归来做,但我最后选了 RandomForest,有几个实际考虑:
第一,表格数据 + 可解释性。 这是一个典型的结构化数据场景,特征全是数值型理化指标,没有图像或文本。树模型天然适合这种数据,而且不需要像神经网络那样调一堆超参数。
第二,类别不均衡。 高质量样本只有 19.66%,不加处理的话模型会严重偏向多数类。我用 class_weight="balanced" 让模型在训练时自动给少数类加权------这相当于告诉模型:"别看高质量样本少,但猜对它们更重要。"
第三,Permutation Importance。 随机森林可以很方便地计算特征重要性。做实验不只是为了跑出一个数字,还要能回答"模型为什么这么判断"。Permutation Importance 比默认的 Gini Importance 更可靠,因为它直接测量打乱某个特征后模型性能的下降程度。
具体参数:
python
model = RandomForestClassifier(
n_estimators=260,
max_depth=9,
min_samples_leaf=4,
class_weight="balanced",
random_state=42,
n_jobs=-1,
)260 棵树对于 6497 条数据已经足够了,再往上加边际收益很小。深度限制在 9 是为了防止在训练集上过度生长------如果让树无限深,它可能会记住某些噪声模式,而不是学到真正有用的规律。min_samples_leaf=4 也是同样的目的:要求叶子节点至少有 4 个样本,避免生成过于细碎的决策规则。
5. 结果分析:Accuracy 0.82 是一个陷阱
先上核心指标:
| 指标 | 数值 |
|---|---|
| Accuracy | 0.8185 |
| Precision | 0.5278 |
| Recall | 0.7422 |
| F1 | 0.6169 |
| ROC AUC | 0.8790 |
如果只看 Accuracy,你可能会觉得"还不错,80% 多都对"。但仔细看分类报告就会发现问题:
text
precision recall f1-score support
ordinary 0.93 0.84 0.88 1044
good 0.53 0.74 0.62 256测试集 1300 条样本中,1044 条是普通酒,256 条是高质量酒。模型对普通酒的识别很稳(precision 0.93),但对高质量酒的 precision 只有 0.53------也就是说,模型每预测 100 瓶"好酒",其实只有 53 瓶真的是好酒,另外 47 瓶是普通酒被误伤了。
但这个"误伤"是坏事吗?不一定。看 Recall:0.7422。这意味着真正的 256 瓶好酒中,模型成功找出了 190 瓶左右(74%)。代价是放进来不少"假阳性"。
换句话说,这个模型的性格是:宁可错杀一千,不可放过一个。它更适合做"初筛"------先把所有可能的候选都捞进来,然后让人工或更严格的规则去二次把关。
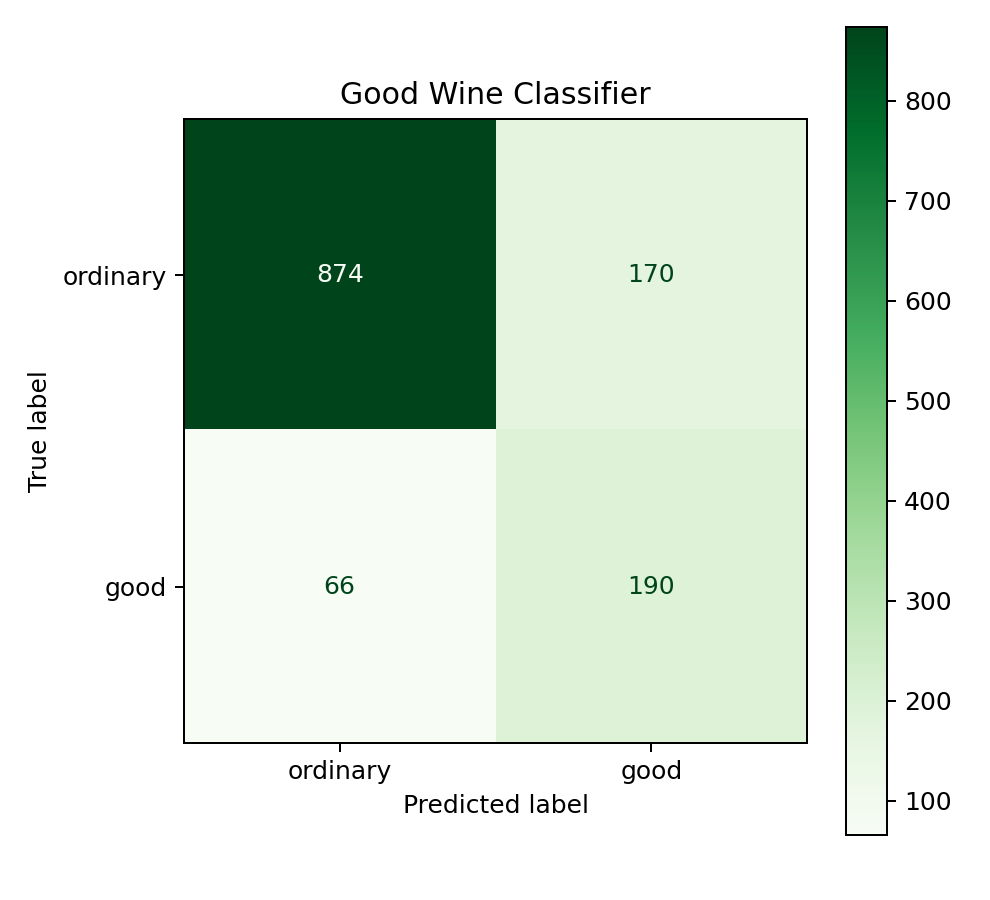
从混淆矩阵也能看出同样的规律:右上角(假阴性,漏掉的好酒)比左下角(假阳性,误判的普通酒)少得多。模型宁愿"多捞",也不愿意"漏掉"。
ROC AUC 0.8790 说明模型整体区分能力还不错------如果把阈值调高,可以提高 precision 但降低 recall;调低则相反。具体怎么选,取决于业务里"漏掉好酒"和"误判普通酒"哪个代价更高。
6. 特征重要性:alcohol 一枝独秀
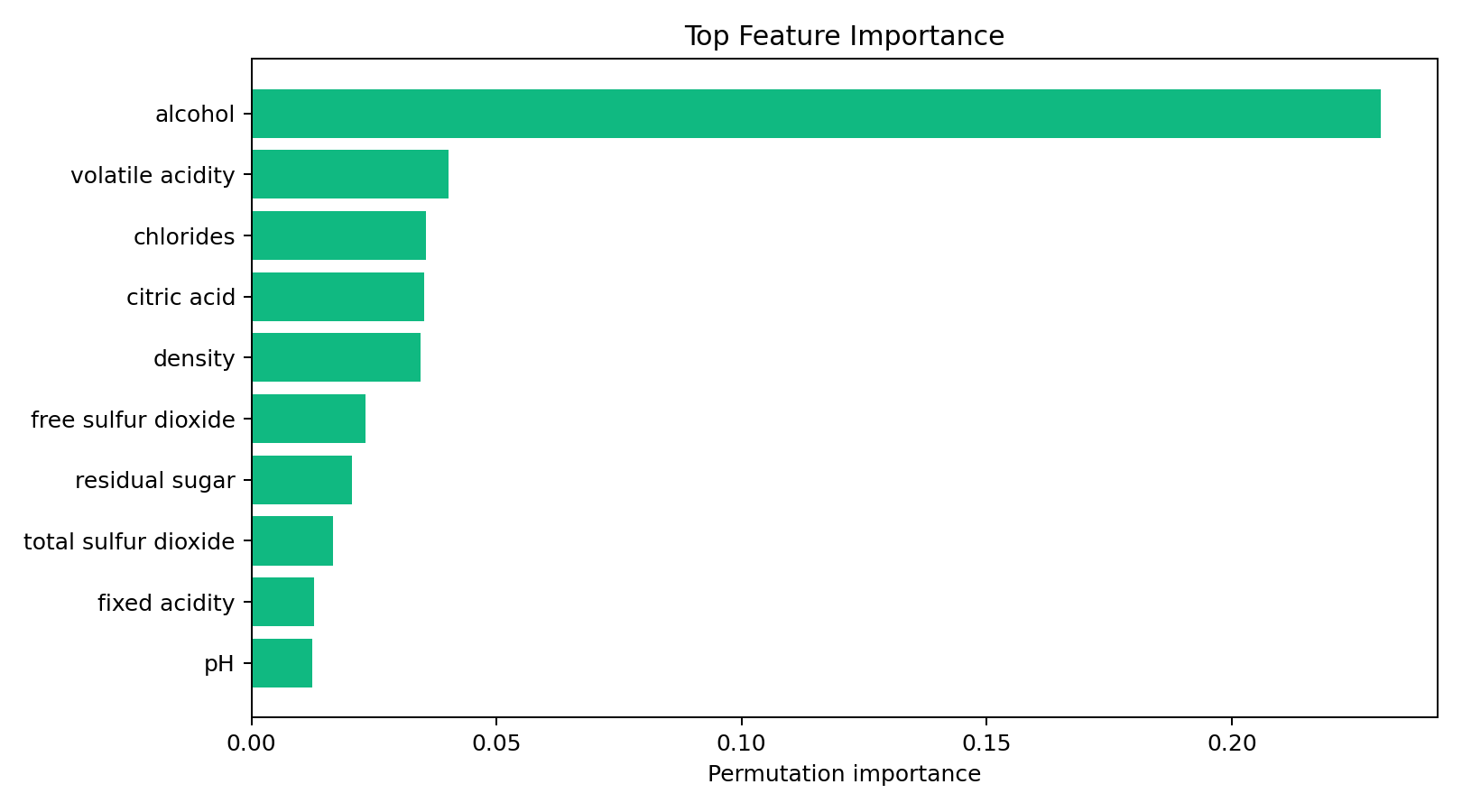
Permutation Importance 的结果让我有点意外------不是"某个特征稍微领先",而是 alcohol 碾压式第一:
| 排名 | 特征 | 重要性 | 标准差 |
|---|---|---|---|
| 1 | alcohol | 0.23049 | 0.01941 |
| 2 | volatile acidity | 0.04025 | 0.00804 |
| 3 | chlorides | 0.03562 | 0.01328 |
| 4 | citric acid | 0.03532 | 0.01177 |
| 5 | density | 0.03460 | 0.01178 |
alcohol 的重要性(0.23)是第二名 volatile acidity(0.04)的近 6 倍。而且它的标准差只有 0.019,说明这个结果很稳定------不管怎么打乱测试集,alcohol 始终是头号重要特征。
从葡萄酒常识的角度,这也说得通。酒精度通常和葡萄的成熟度、酿造工艺直接相关,而这些正是影响酒质的核心因素。
不过第二名到第五名之间的差距非常小(0.040 vs 0.035 vs 0.035 vs 0.034),而且它们的标准差都比较大。这意味着这几个特征的相对排名不太稳定------换一批测试数据,volatile acidity 和 chlorides 谁排第二可能会互换。所以结论是:alcohol 毫无疑问是最关键特征,但后面的几个理化指标共同构成了第二梯队,不能单独拎出某一个说"这就是第二重要的"。
还有一个有趣的细节:wine_type_white 的重要性是 -0.00076,几乎为零。白葡萄酒样本虽然是红葡萄酒的 3 倍多(4898 vs 1599),但"是红酒还是白酒"这件事,对预测质量几乎没什么帮助。模型不是靠颜色来分好坏的------它是靠酒精度、酸度、密度这些理化指标。
7. 实验输出
运行脚本后,experiments/wine-quality/outputs/ 会生成以下文件:
text
metrics.json # 完整指标 JSON
dataset_profile.csv # 数据统计
feature_importance.csv # 全部特征重要性
classification_report.txt # 分类报告
quality_distribution.png # 质量分布图
feature_importance.png # 特征重要性图
confusion_matrix.png # 混淆矩阵图
summary.md # 实验摘要所有输出都是自动生成的,随机种子固定为 42,所以每次运行结果完全一致。
8. 总结
这个实验从头到尾只有一个目的:做一个任何人都能复现的、有分析深度的轻量项目。
几个关键收获:
- 数据决定了阈值。quality >= 7 不是我随便定的,而是看了分布后发现的天然分界点。
- Accuracy 会骗人。82% 的准确率背后,是模型对少数类的识别能力仍然有限。Precision 和 Recall 的权衡比 Accuracy 更值得讨论。
- alcohol 是真的强。不是强一点,是碾压式的强。而且后面的特征排名不太稳定,分析时要小心不要过度解读。
- 这个模型适合做什么? 初筛。它的性格是"宁可误判,不可漏掉",刚好适合作为第一层过滤网。
如果你想拿它当学习模板,clone 下来改几个参数试试:把 max_depth 从 9 改成 5 或 15,看看过拟合和欠拟合长什么样;把 class_weight="balanced" 去掉,看看 Accuracy 会怎么变化------这些改动都会让你对随机森林和类别不均衡有更直观的理解。
本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/技术交流 QQ 群:1097156200
