Python + 文本清洗 + CountVectorizer + 多模型分类对比
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。
1 项目概述
垃圾短信看起来只是手机里的一条普通消息,背后却可能包含营销骚扰、钓鱼链接、诈骗诱导和隐私窃取等风险。单靠黑名单和关键词规则去拦截,短期内有用,但一旦发送方更换号码、替换敏感词、加入变形表达,规则就很容易失效。这个项目把垃圾短信识别拆成一个标准的文本分类任务:先把原始短信内容整理干净,再把文本转换成机器能理解的数值特征,最后训练多个分类模型,比较哪一种模型更适合落地使用。
整套流程从数据集读取开始,经过数据清理、标签编码、文本去噪、特征提取、模型训练、结果评估几个环节,最后用准确率、精确率、召回率、F1 分数、AUC 和 Cohen's Kappa 系数进行综合评价。相比只给出一个模型结果,这种多模型对比更适合学生项目展示,也更容易说明为什么选择某个模型作为最终方案。
项目的核心不是堆算法名称,而是把"短信内容"一步步变成"可计算、可判断、可评估"的分类结果。正常短信和垃圾短信在长度、词汇、表达方式上存在差异,这些差异经过清洗和向量化后,就可以进入机器学习模型进行学习。通过可视化图表,可以直观看到数据分布和模型效果,整体结构比较完整。

图1 项目整体流程展示
2 数据来源与样本结构
项目采用 Kaggle 平台上的 SMS Spam Collection Dataset。该数据集面向短信垃圾信息识别任务,共包含 5574 条英文短信,其中正常短信 ham 占比较高,垃圾短信 spam 占比较低。原始数据主要由两个字段组成:v1 表示类别标签,v2 保存短信正文。后续处理时,将字段重命名为 label 和 message,便于统一分析。
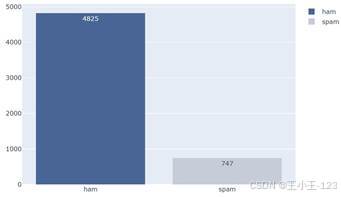
从样本结构看,正常短信有 4825 条,垃圾短信有 747 条,整体属于典型的不均衡分类数据。这个特点很重要,因为模型如果只追求总体准确率,可能会更倾向于判断为数量更多的正常短信。因此,项目没有只看 Accuracy,而是同时关注 Precision、Recall、F1 和 AUC,用多个指标判断模型是否真正识别出了垃圾短信。
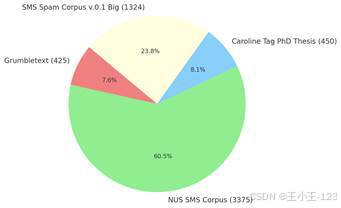
数据来源也具有一定多样性,包括 Grumbletext 中整理出的垃圾短信、NUS SMS Corpus 中的合法短信、Caroline Tag 博士论文中的合法短信,以及 SMS Spam Corpus v.0.1Big 中的混合样本。多来源数据能让短信文本表达更加丰富,也更接近真实场景中的消息差异。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图2 短信数据来源占比 | 图3 正常短信与垃圾短信数量分布 |
3 数据探索与文本特征
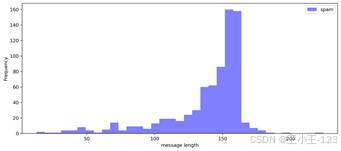
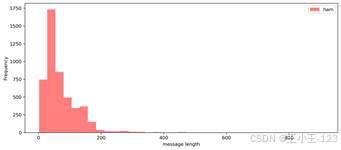
在建模前,先对短信长度进行了探索。垃圾短信的长度分布呈现出一定集中区间,较多样本集中在 130 到 170 个字符附近,说明垃圾短信通常会包含较完整的促销信息、链接提示、获奖诱导或联系方式。正常短信则明显更短,大多数集中在 0 到 100 个字符之间,尤其在 50 个字符以内数量最多,内容更偏日常沟通。
这种差异对分类是有帮助的。短信长度本身虽然不能单独决定一条消息是不是垃圾短信,但它能反映文本模式:垃圾短信往往需要把奖励、活动、链接、联系方式、催促语等内容写完整,而正常短信更多是简短交流。项目通过直方图展示了两类短信长度差异,使数据特点在建模前就能被清楚看到。
除了长度分布,项目还对数据字段进行了统计。message 字段共有 5572 条记录,其中有 5169 个不同内容,说明文本重复度并不高;最常见的短信内容为 "Sorry, I'll call later",出现 30 次。这些基础统计可以帮助判断数据质量,也能为后续去重、清洗和特征提取提供依据。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图4 垃圾短信长度分布 | 图5 正常短信长度分布 |
4 数据预处理与特征工程
文本数据不能直接送入机器学习模型,必须先做预处理。项目先用 pandas 读取 spam.csv,去除缺失值列,保留 label 和 message 两个核心字段。随后对短信内容进行清洗,包括去除 HTML 标签、清理方括号中的无关内容、删除 URL 链接、移除停用词、去掉数字和标点符号等,让模型尽量关注短信中的有效语义信息。
标签处理也很关键。项目将 ham 映射为 0,将 spam 映射为 1,完成二分类任务所需的数值化标签。这样模型在训练时就能把一条短信对应到明确类别,预测阶段也能输出正常或垃圾两种结果。
特征提取采用 CountVectorizer,也就是常见的词袋模型。它会扫描所有短信内容,建立词汇表,并统计每个词在文本中出现的次数,最终把一句短信转换成数值矩阵。虽然词袋模型不会考虑词语顺序和上下文语义,但对于基础垃圾短信分类来说,它结构简单、速度快、效果稳定,适合教学项目和轻量级实验。
完成向量化之后,文本就从"自然语言"变成了"特征矩阵"。这一转换是整个项目最重要的桥梁:前面做的是数据清洗,后面做的是模型训练,中间必须靠特征工程把两部分接起来。
5 模型构建过程
5.1 朴素贝叶斯模型
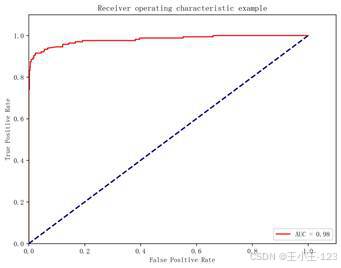
朴素贝叶斯非常适合文本分类任务,计算速度快,对高维稀疏文本特征比较友好。项目中的朴素贝叶斯模型准确率达到 96.77%,召回率达到 90.36%,AUC 为 0.98。它的特点是对垃圾短信识别较敏感,召回表现突出,适合希望尽可能多拦截垃圾短信的场景。
5.2 逻辑回归模型
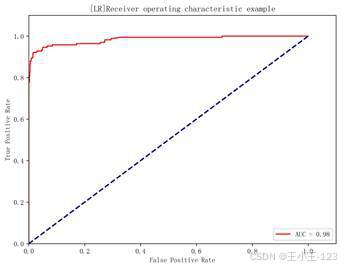
逻辑回归虽然结构简单,但在二分类任务中非常稳。项目中逻辑回归准确率达到 97.58%,精确率为 97.28%,F1 分数为 0.9137,Cohen's Kappa 系数为 0.8997,是整体表现最均衡的模型。它不仅结果好,而且解释性强、训练速度快,适合作为轻量级垃圾短信检测方案。
5.3 支持向量机模型
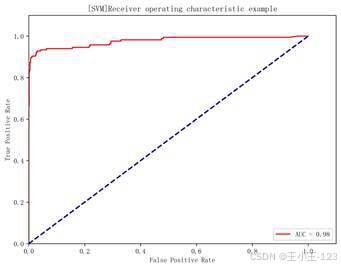
支持向量机在高维文本分类中也很常见,尤其适合特征维度较高、类别边界相对清晰的任务。本项目中 SVM 的准确率为 96.77%,精确率达到 99.24%,说明一旦它判断某条短信为垃圾短信,判断结果较可靠。不过召回率为 78.92%,意味着仍有部分垃圾短信可能被漏掉。
5.4 随机森林与 XGBoost 模型
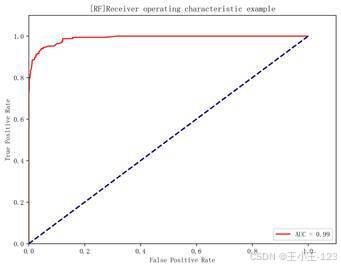
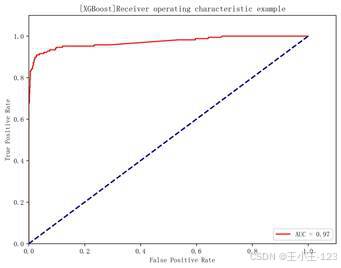
随机森林通过多棵决策树投票得到最终分类结果,稳定性较好。项目中随机森林准确率为 96.77%,AUC 达到 0.99,是所有模型中 AUC 最高的一个。XGBoost 则采用梯度提升思想,不断修正前一轮模型的错误,最终准确率为 96.59%,AUC 为 0.97。两类集成模型都具有较好的分类能力,但在当前数据规模和特征表示方式下,整体并没有超过逻辑回归。
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图6 朴素贝叶斯 ROC 曲线 | 图7 逻辑回归 ROC 曲线 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
| 图8 支持向量机 ROC 曲线 | 图9 随机森林 ROC 曲线 |
|-----------------------------------------------------------------------------|-----------------------------------------------------------------------------|
|  |
|  |
|
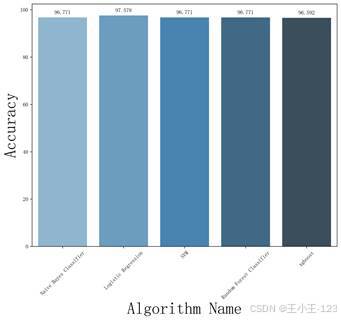
| 图10 XGBoost ROC 曲线 | 图11 不同算法准确率对比 |
6 模型评估与结果对比
从最终结果看,各模型的准确率都保持在较高水平,说明机器学习方法能够较好完成垃圾短信识别任务。逻辑回归在准确率、精确率、F1 分数和 Kappa 系数上表现更优,整体最适合作为当前项目的推荐模型。随机森林的 AUC 值最高,说明它在区分正常短信与垃圾短信方面有较强能力。朴素贝叶斯召回率最高,适合更重视"少漏判"的应用场景。
模型选择不能只看一个指标。如果系统更重视用户体验,希望减少正常短信被误拦截,就应该关注 Precision;如果系统更重视安全拦截,希望尽可能多发现垃圾短信,就应该关注 Recall;如果希望综合平衡,就可以参考 F1 分数和 Kappa 系数。这个项目的价值就在于把多个模型放在同一套指标体系下比较,结果更清楚,也更容易解释。
|---------|---------|---------|---------|---------|---------------|-----------|
| 模型 | 准确率 | AUC | 召回率 | 精确率 | F1 分数 | Kappa |
| 朴素贝叶斯 | 96.77% | 0.98 | 90.36% | 88.24% | 0.8928 | 0.8738 |
| 逻辑回归 | 97.58% | 0.98 | 86.14% | 97.28% | 0.9137 | 0.8997 |
| 支持向量机 | 96.77% | 0.98 | 78.92% | 99.24% | 0.8792 | 0.8608 |
| 随机森林 | 96.77% | 0.99 | 78.92% | 99.24% | 0.8792 | 0.8608 |
| XGBoost | 96.59% | 0.97 | 80.12% | 96.38% | 0.8750 | 0.8555 |
表1 垃圾短信分类模型性能对比
7 项目结构与展示价值
这类项目比较适合做成完整的课程设计或毕业设计,因为它有明确的业务场景,也有清晰的数据处理链路。前半部分可以展示数据来源、样本分布和文本清洗,后半部分可以展示模型训练、ROC 曲线和指标对比。读者不用一下子看完全部代码,也能通过图表快速明白项目做了什么。
从技术点来看,项目覆盖了 Python 数据分析、文本预处理、停用词处理、标签编码、词袋特征、机器学习分类、模型评估和可视化展示。对初学者而言,可以通过这个项目掌握完整的 NLP 文本分类入门流程;对需要交付作品的同学而言,可以继续扩展为 Web 页面、接口服务或短信输入预测工具。
后续还可以继续升级,例如把 CountVectorizer 替换为 TF-IDF,引入中文垃圾短信数据集,加入 TextCNN、BiLSTM、BERT 等深度学习模型,或者将训练好的模型保存为 pkl 文件,封装成 Flask 接口。这样不仅能完成实验分析,还能进一步形成可演示、可部署、可二次开发的项目资源。
8 项目亮点总结
一是场景清晰。项目围绕垃圾短信检测展开,和网络安全、信息过滤、用户体验直接相关,容易说明实际价值。
二是流程完整。从数据读取到文本清洗,再到特征提取和模型评估,关键步骤齐全,不是单纯调用一个算法。
三是模型丰富。朴素贝叶斯、逻辑回归、SVM、随机森林、XGBoost 都进行了对比,能体现不同算法在同一任务上的差异。
四是图表直观。样本分布、长度分布、ROC 曲线、准确率对比图都能直接展示项目效果,适合放在项目说明和成果展示中。
五是可扩展性强。项目可以继续接入中文语料、在线预测页面、模型保存与加载、接口调用等功能,后续升级空间比较大。
9 每文一语
把复杂问题拆成数据、特征和模型,答案就会一步一步清晰起来!