作者: Hao Shen¹²³,Henghui Ding⁴,Yulun Zhang⁵,Zhong-Qiu Zhao³,Xudong Jiang⁶
机构:
¹ School of Public Security and Emergency Management, Anhui University of Science and Technology
² State Key Laboratory of Digital Intelligent Technology for Unmanned Coal Mining, Anhui University of Science and Technology
³ School of Computer Science and Information Engineering, Hefei University of Technology
⁴ Institute of Big Data, Fudan University
⁵ AI Institute, Shanghai Jiao Tong University
⁶ School of Electrical and Electronic Engineering, Nanyang Technological University
来源期刊: IEEE Transactions on Image Processing, TIP 2025
发表时间: 2025年6月19日在线发表
1. 研究目标、过去方法、本文方法、优势及创新点
1.1 研究目标
图像去雾的目标是:给定一张有雾图像,恢复出对应的清晰图像。雾会降低对比度、模糊纹理、改变颜色分布,并且会影响后续目标检测、场景理解等高级视觉任务。论文希望解决两个问题:
第一,如何在不使用高计算量 Transformer 的情况下获得强全局建模能力。传统 CNN 擅长局部细节重建,但长距离依赖建模能力弱;Transformer 虽然能建模全局关系,但计算量和显存成本较高。
第二,如何更好利用频域信息。已有频域去雾方法发现雾退化主要体现在幅度谱中,但很多方法没有重点关注严重雾区、边缘、复杂结构等关键信息。本文希望在空间域和频率域同时建模,提升去雾效果和效率。
1.2 过去方法
1.2.1 基于先验的方法
早期方法主要依赖大气散射模型 ASM 和人工先验,例如:
| 方法 | 思想 | 问题 |
|---|---|---|
| DCP 暗通道先验 | 利用自然图像局部区域中某些通道存在低值的规律估计透射率 | 天空区域、白色物体、强光区域容易失效 |
| CAP 颜色衰减先验 | 根据颜色和深度之间的关系估计雾浓度 | 对复杂真实场景泛化有限 |
| NLP 非局部先验 | 利用颜色簇在空间中的分布规律去雾 | 对噪声、非均匀雾仍不稳定 |
这类方法优点是无需大量训练数据,缺点是先验不一定总成立,容易产生颜色偏移、过增强或残雾。论文也指出,先验估计不准会导致透射图错误,从而产生视觉不自然结果。
1.2.2 CNN 端到端方法
后续 CNN 方法不再显式估计大气散射模型参数
代表方法包括 AOD-Net、FFA-Net、MSBDN、AECR-Net 等。
这些方法的优势是训练稳定、推理速度较快、细节重建能力强。但核心问题是:CNN 卷积核局部性强,难以捕获长距离依赖。对于大面积雾、非均匀雾、远近景混合区域,单纯局部卷积不够。
1.2.3 Transformer 方法
Transformer 类去雾方法,例如 DeHamer、DehazeFormer、Restormer、MBTFormer,利用自注意力或改进注意力机制增强全局建模能力。
它们的问题是:
| 类型 | 问题 |
|---|---|
| 空间自注意力 | 复杂度随图像分辨率平方增长,高分辨率图像很慢 |
| 通道自注意力 | 计算较省,但空间长距离关系建模不够直接 |
| Transformer 去雾网络 | 参数、FLOPs、推理时间通常较高 |
论文的目标不是继续堆 Transformer,而是构建一个 纯 CNN 形式但具备类似全局建模能力的高效网络。
1.2.4 频域方法
已有频域图像复原方法利用傅里叶变换,把图像从空间域转到频率域。论文提到,频域有天然的全局性质,并且已有研究发现:
雾退化主要体现在幅度谱 amplitude spectrum
纹理结构更多保存在相位谱 phase spectrum
但是已有方法通常只做整体频域学习,没有重点关注严重雾区、边缘和复杂结构区域。本文的 FM 模块就是为了解决这个问题。
1.3 本文方法:SFMN
本文提出 Spatial Frequency Modulation Network,SFMN 。整体是一个 两阶段 U-Net ,基本模块是 Spatial Frequency Modulator,SFM。SFM 里面又包括:
| 模块 | 中文理解 | 作用 |
|---|---|---|
| CSM | Cross-Scale Modulator,跨尺度调制器 | 在空间域聚合不同尺度上下文 |
| FM | Frequency Modulator,频率调制器 | 在频域建模雾退化和复杂结构 |
| CLM | Cross-Level Modulator,跨层调制器 | 让 encoder/decoder 不同层级特征互相调制 |
它的核心设计可以概括为:
空间域:CSM + CLM 解决跨尺度、跨层上下文建模
频率域:FM 解决全局雾退化建模和关键区域增强
整体结构:两阶段 U-Net 分别处理幅度谱和相位谱论文明确指出,SFMN 将上述模块整合进 U-Net,形成两阶段空间-频率调制网络,并在多个去雾 benchmark 上取得优于现有 SOTA 的效果。
1.4 创新点总结
这篇论文的创新点主要有四个:
创新点 1
提出空间频率调制视角
不是只在空间域做卷积或注意力,也不是只在频域做傅里叶处理,而是将:
空间上下文建模 + 频率全局建模 结合起来。创新点 2
CSM 跨尺度空间调制
CSM 用多分支结构逐步聚合不同尺度的上下文信息。雾在图像中往往不是均匀分布的,有些地方轻雾,有些地方浓雾,所以跨尺度建模比单尺度调制更适合去雾。
创新点 3
FM 双分支频域调制
FM 不是简单做 FFT,而是设计了两个频域分支:
分支 1:学习通道相关的全局频域特征
分支 2:学习通道无关的关键区域频域特征
然后用分支 2 去调制分支 1这样可以让网络更关注严重雾区、边缘和复杂结构区域。
创新点 4
CLM 跨层调制
普通 U-Net 只是把 encoder 和 decoder 的特征 concat 起来,但本文认为简单拼接不能充分利用不同层级的互补信息。因此设计 CLM,让高分辨率细节特征和低分辨率语义上下文特征互相调制。
2. 文中算法主要思想与专业名词解释
2.1 整体网络结构
SFMN 是一个两阶段网络,每个阶段都是 U-Net 结构。论文图 3 展示了整体流程。第一阶段输入原始有雾图像,经过 3×3 卷积提取浅层特征,然后进入四层 encoder-decoder,每一层都使用 SFM 模块。第一阶段最后通过 SAM 生成中间去雾结果 O1O_1O1。第二阶段并不是简单再次输入原图,而是把输入图像的相位谱和第一阶段输出图像的幅度谱结合起来作为输入,再生成最终结果 O2O_2O2。
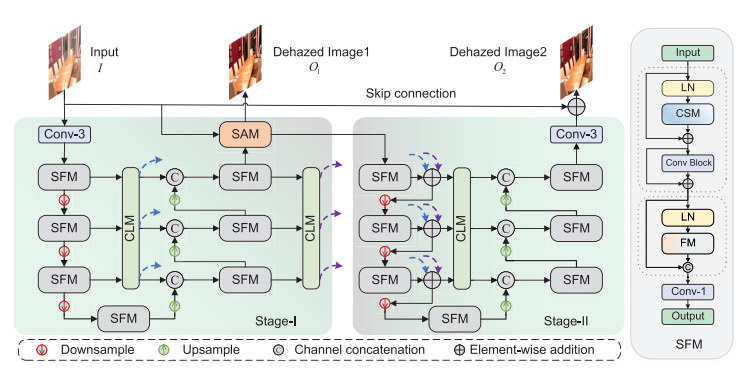 空间频率调制网络(SFMN)的整体架构采用两阶段U-Net设计构建整个网络,其中所提出的空间频率调制器(SFM)作为各层的基本构建单元。第二阶段的编码器融合了第一阶段网络中编码器(蓝色虚线)与解码器(紫色虚线)输出的对应层级 CLM 结果
空间频率调制网络(SFMN)的整体架构采用两阶段U-Net设计构建整个网络,其中所提出的空间频率调制器(SFM)作为各层的基本构建单元。第二阶段的编码器融合了第一阶段网络中编码器(蓝色虚线)与解码器(紫色虚线)输出的对应层级 CLM 结果
为什么要两阶段?因为论文认为:
幅度谱 amplitude 更偏向雾退化、亮度、全局能量分布;
相位谱 phase 更偏向纹理、边缘、结构。
如果把幅度和相位混在一起学,优化难度更高。所以第一阶段主要学习幅度相关信息,第二阶段进一步学习相位结构信息。
2.2 SFM:Spatial Frequency Modulator
SFM 是本文最核心的基础模块。
它与 Transformer 的区别是:Transformer 通常通过 attention 做 token 之间的两两关系建模,而 SFM 用 特征调制 的方式实现上下文交互,计算量更低。论文强调 SFM 不是传统 Transformer,而是在空间域和频率域同时进行调制。
2.3 Feature Modulation,特征调制
特征调制可以理解为:
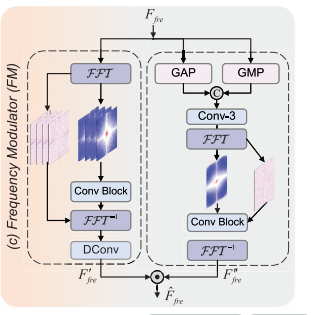 频率调制器(FM)的架构
频率调制器(FM)的架构
数学上通常是逐元素乘法:
先生成一个“调制器” M,
再用 M 去控制原始特征 Q。
Output = Q ⊙ M其中 ⊙表示 element-wise multiplication,也就是对应位置相乘。
直观理解:
Q 是原始特征;
M 是注意力/门控/上下文引导;
Q ⊙ M 表示:哪些区域重要就增强,哪些区域不重要就压制。
这和 attention 的目标类似,都是为了让特征之间产生交互。但相比 self-attention,逐元素乘法更便宜,适合构建高效网络。
2.4 Cross-Scale Modulator,跨尺度调制器
CSM 的作用是解决一个问题:
不同区域的雾浓度不同,需要不同尺度的感受野来处理。
| 场景 | 需要的信息 |
|---|---|
| 大面积天空雾 | 大感受野、全局上下文 |
| 建筑边缘、树枝 | 小感受野、细节纹理 |
| 远景浓雾 | 中远距离上下文 |
| 近景轻雾 | 局部细节恢复 |
CSM 的做法是:
- 对输入特征做不同倍率的平均池化,得到不同尺度空间。
- 每个尺度分支使用 HFE 提取特征。
- 从粗尺度到细尺度逐步上采样并融合。
- 用门控机制选择不同粒度的信息。
- 最后用聚合后的跨尺度特征去调制 query 特征。
论文中 CSM 采用多分支结构,并通过平均池化、上采样、HFE 和逐元素乘法实现 coarse-to-fine 的跨尺度建模。
2.5 Hierarchical Feature Extractor
HFE 是 CSM 里面的层次特征提取器。它使用多个 depth-wise convolution,并逐步增大卷积核大小。
论文最终采用的卷积核设置是:
k = 3, 5, 7
这表示:
| 卷积核 | 作用 |
|---|---|
| 3×3 | 捕获局部细节 |
| 5×5 | 捕获中等范围结构 |
| 7×7 | 捕获更大范围上下文 |
这就是从局部到全局的层次建模。
2.6 Depth-wise Convolution,深度可分离卷积中的逐通道卷积
普通卷积会同时混合空间信息和通道信息,计算量较大。Depth-wise convolution 是每个通道单独卷积,不直接跨通道混合,因此更轻量。
直观理解:
普通卷积:所有通道一起卷,计算量大;
Depth-wise Conv:每个通道自己卷,计算量小;
后面再用 1×1 Conv 做通道融合。
本文大量使用 depth-wise convolution,是其高效性的来源之一。
2.7 Frequency Modulator,频率调制器
FM 是论文另一个核心模块。它利用傅里叶变换将特征从空间域转到频率域。
2.7.1 为什么用频域?
空间域看到的是像素位置:
哪里亮、哪里暗、哪里有边缘
频域看到的是图像的整体频率组成:
低频:整体亮度、颜色、平滑区域、雾幕感
高频:边缘、纹理、细节
论文引用已有研究认为,雾退化主要反映在 幅度谱 中,而图像结构和纹理更多由 相位谱 表示。
2.7.2 专业名词
FFT、幅度谱、相位谱
对图像或特征做 FFT 后,会得到复数形式:
F = Real + i Imag
其中:Real:实部 Imag:虚部
由实部和虚部可以计算:Amplitude 幅度谱:表示频率能量强弱
Phase 相位谱:表示结构位置和纹理排列
直观理解:
| 频域成分 | 对图像的意义 |
|---|---|
| 幅度谱 | 决定整体强度、对比度、雾感、亮度分布 |
| 相位谱 | 决定结构、边缘、纹理、物体轮廓 |
所以本文两阶段处理:
Stage-I:重点学习 amplitude,去除全局雾退化;
Stage-II:重点学习 phase,恢复纹理和结构。
2.7.3 FM 的双分支结构
FM 包含两个分支
分支 1:通道相关频域分支
这个分支对完整特征图做 FFT,在频域中用 1×1 卷积处理幅度或相位,然后 IFFT 回到空间域。
作用是:学习每个通道自己的全局频率特征。
分支 2:关键区域频域分支
这个分支先用 GAP 和 GMP 压缩通道,得到单通道内容图。
| 操作 | 含义 |
|---|---|
| GAP | Global Average Pooling,全局平均池化,捕获整体响应 |
| GMP | Global Max Pooling,全局最大池化,突出强响应区域 |
然后这个单通道内容图也进入频域学习。它的作用是找出:
严重雾区、边缘、复杂结构区域。
最后,分支 2 的结果会通过广播机制去调制分支 1:
Final FM output = Branch1 feature ⊙ Branch2 feature
这相当于让网络在全局频域建模时,额外关注关键区域。
2.8 Cross-Level Modulator,跨层调制器
普通 U-Net 的 skip connection 通常是:
encoder feature concat decoder feature
但论文认为这样太粗糙,因为不同层级的信息有明显差异:
| 层级 | 特征特点 |
|---|---|
| 高分辨率浅层 | 细节多、边缘多、纹理多,但上下文弱 |
| 低分辨率深层 | 上下文强、语义强,但细节少 |
CLM 的目标是让不同层级之间互相补充:
浅层补细节;
深层补上下文;
跨层之间通过门控和逐元素乘法互相调制。
论文图 5 中,CLM 通过上采样、下采样、特征拼接、1×1 卷积、通道 split、门控聚合、逐元素乘法完成跨层交互。
2.9 损失函数
SFMN 是两阶段网络,所以损失也分两部分:
Ltotal = Lstage1 + Lstage2
Stage-I:
空间 L1 损失 + 幅度谱 L1 损失
Stage-II:
空间 L1 损失 + 相位谱 L1 损失
论文中频域损失权重 α 和 β 都设为 0.05。这样做的好处是:网络不仅在 RGB 空间接近 GT,也要在频域上接近 GT,从而更好去除雾幕并恢复结构。
3. 实验结果
3.1 数据集
论文实验数据集比较丰富,不只是 ITS 和 OTS。
3.1.1 合成去雾数据集
| 训练集 | 测试集 | 说明 |
|---|---|---|
| RESIDE-ITS | SOTS-Indoor | 室内合成去雾 |
| RESIDE-OTS | SOTS-Outdoor | 室外合成去雾 |
论文按照近期方法使用 ITS 和 OTS 作为自然白天图像去雾训练数据,并在 SOTS-Indoor 和 SOTS-Outdoor 上测试。
这也解释了你前面问的代码问题:论文实验数据集很多,但公开训练代码主要只有 ITS/OTS 两个训练入口;其他数据集更多用于评测或需要自行补训练配置。
3.1.2 真实成对去雾数据集
| 数据集 | 特点 |
|---|---|
| O-HAZE | 真实室外雾图像,有 GT |
| Dense-Haze | 浓雾、非均匀雾,更难 |
| NH-HAZE | 非均匀雾,真实采集 |
这些数据集用于验证模型在真实雾场景中的鲁棒性。
3.1.3 无 GT 真实雾图像
论文还使用 29 张真实有雾图像做无参考质量评估。因为没有清晰 GT,所以不能用 PSNR/SSIM,只能用 NIQE 和 FADE。
3.1.4 扩展任务:图像去雪
为了验证方法泛化性,论文还在去雪数据集上实验:
| 数据集 | 任务 |
|---|---|
| CSD | 去雪 |
| SRRS | 去雪 |
| Snow100K | 去雪 |
这说明作者想证明 SFMN 的空间-频率调制不只对去雾有效,也对其他低级视觉复原任务有效。
3.2 评价指标
论文使用的评价指标包括:
| 指标 | 越大/越小越好 | 含义 |
|---|---|---|
| PSNR | 越大越好 | 像素级重建误差,常用于有 GT 图像复原 |
| SSIM | 越大越好 | 结构相似性,衡量结构恢复 |
| NIQE | 越小越好 | 无参考图像质量评价 |
| FADE | 越小越好 | 无参考去雾质量评价,衡量雾残留程度 |
| Params | 越小越轻量 | 参数量 |
| FLOPs | 越小越高效 | 计算量 |
| Time | 越小越快 | 推理时间 |
其中 FLOPs 是在 3×256×256 图像 patch 上计算的,推理时间是在 1600×1200 的 Dense-Haze 图像上评估的。
3.3 定量实验结果
3.3.1 合成与真实成对去雾结果
论文表 I 中,SFMN 在多个数据集上取得了很强的结果:
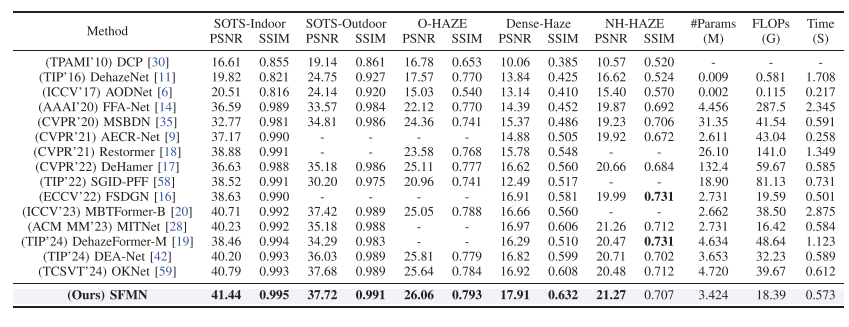 图像去灰度化现有方法的定量比较
图像去灰度化现有方法的定量比较
可以看出,SFMN 的参数量不大,FLOPs 明显低于多数 Transformer 方法,同时性能更高。论文也特别指出,SFMN 在 SOTS-Indoor 和 SOTS-Outdoor 上分别达到 41.44 dB 和 37.72 dB,相比 MBTFormer-B 分别提升 0.73 dB 和 0.30 dB。
3.3.2 无参考指标结果
表 II 使用 NIQE 和 FADE 评估近三年方法。SFMN 的结果是:
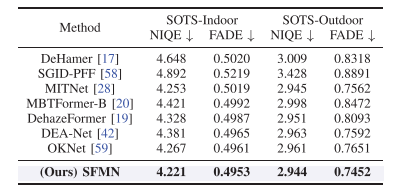 NQE与FADE除锈方法的比较
NQE与FADE除锈方法的比较
这两个指标都是越低越好,SFMN 在两个数据集上都是最低,说明它不仅 PSNR/SSIM 高,感知质量和去雾程度也较好。
3.3.3 无 GT 真实雾图像结果
表 III 中,在 29 张真实无 GT 雾图像上:
 对真实雨天图像的定量结果进行比
对真实雨天图像的定量结果进行比
这里有一个重要现象:传统先验方法 DCP/DDAP 在真实无 GT 图像上仍然很强,因为它们不依赖合成数据训练,受 domain gap 影响较小。但 SFMN-Mix 使用 OTS、Dense-Haze、NH-HAZE 混合训练后,明显接近先验方法,并优于大多数纯数据驱动方法。
3.3.4 去雪泛化实验
表 IV 显示,SFMN 在去雪任务上也表现很强:

这说明空间-频率调制的设计不只是针对雾,也能迁移到其他天气退化任务。
3.4 定性实验结果
3.4.1 SOTS 可视化
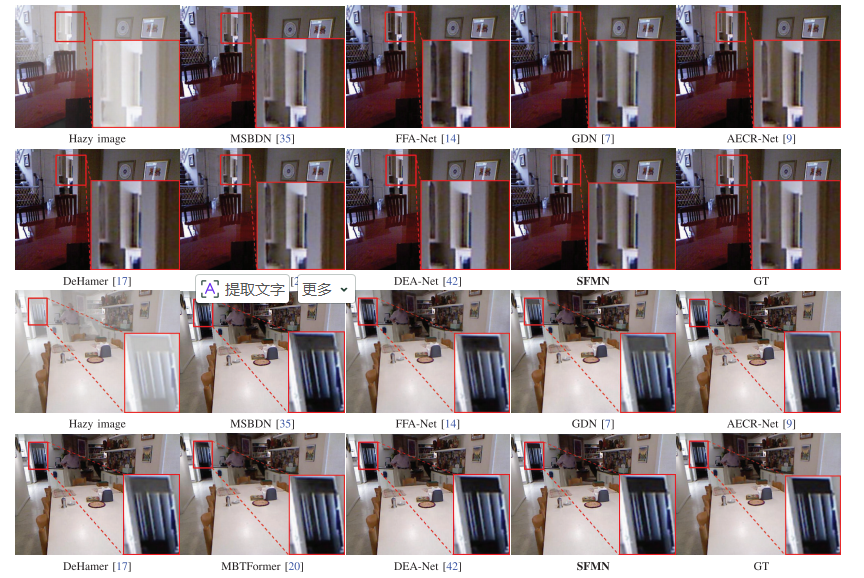 在SOTS21数据集上进行的视觉比
在SOTS21数据集上进行的视觉比
图 6 展示了 SOTS 数据集上的视觉对比。论文指出,其他方法虽然可以去掉大部分雾,但容易出现:
颜色失真;
纹理丢失;
细节模糊;
局部残雾。
SFMN 的结果更接近 GT,能够去除均匀雾,同时保留更清晰的纹理和细节。
3.4.2 Dense-Haze 和 NH-HAZE 可视化
 密集雾61与NH-HAZE62数据集的视觉对比
密集雾61与NH-HAZE62数据集的视觉对比
图 7 展示了 Dense-Haze 和 NH-HAZE 的结果。这两个数据集由专业雾机生成,雾更浓、更不均匀,因此比 RESIDE 更难。
论文观察到,多数方法在这些数据集上难以恢复接近 GT 的结果,并会产生颜色偏移。相比之下,SFMN 的残雾更少,伪影更轻,整体视觉效果更好。
3.4.3 真实无 GT 图像可视化
 针对实际场景中的雾化图像(无法获取无雾图像时),展示多种方法的视觉效果。请放大以获得更清晰的视图
针对实际场景中的雾化图像(无法获取无雾图像时),展示多种方法的视觉效果。请放大以获得更清晰的视图
图 8 展示了真实雾图像,没有 GT。先验方法 DCP/DDAP 在某些场景下看起来更自然,但天空区域可能产生伪影。SFMN 输出相对平衡;SFMN-Mix 由于混合真实风格数据训练,视觉结果更自然。
3.5 消融实验
3.5.1 CSM 分支数消融
论文发现:
| 数据类型 | 最佳分支数 |
|---|---|
| ITS / OTS 低分辨率数据 | 2 个分支最好 |
| Dense-Haze / NH-HAZE 高分辨率数据 | 3 个分支最好 |
原因是:高分辨率图像需要更大尺度上下文;但低分辨率图像如果下采样过多,会丢失空间细节。因此最终为了效率统一采用 2 个分支。
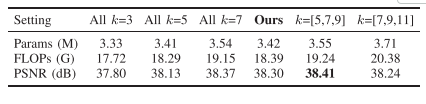
3.5.2 CSM 卷积核大小消融
表 V 显示:
 CSM 中颗粒尺寸的消融研究
CSM 中颗粒尺寸的消融研究
虽然 k=5,7,9 的 PSNR 略高,但计算成本更大,所以最终选择 k=3,5,7,更符合效率和性能平衡。
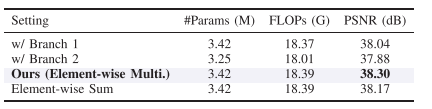
3.5.3 FM 消融
表 VI 显示:
 FM的消融研究
FM的消融研究
这说明:
两个分支都需要;
关键区域分支调制全局频域分支是有效的;
逐元素乘法比简单相加更好。
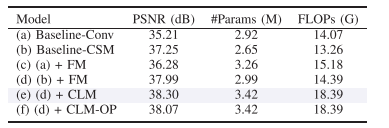
3.5.4 组件消融
表 VII 中:
 用于更好评估所提组件(包括CSM和FM)的拆解消融研究
用于更好评估所提组件(包括CSM和FM)的拆解消融研究
可以看出:
CSM 提升最大;
FM 可以进一步增强;
CLM 带来最终最佳结果。
这说明空间跨尺度、频域调制、跨层交互三者是互补的。
3.5.5 SFM 组合方式消融
表 IX 比较了 SFM 中 CSM 和 FM 的排列方式:
 SFM设计的消融研究
SFM设计的消融研究
最终采用:先 CSM,后 FM
原因是:频域信息虽然能提供全局先验,但需要强空间特征作为基础。先做空间跨尺度建模,再做频率调制,效果最好。
3.5.6 两阶段设计消融
图 14 对比单阶段和两阶段网络。论文认为两阶段设计可以产生更小误差图,说明结构和细节恢复更准确;同时两阶段训练收敛略快。
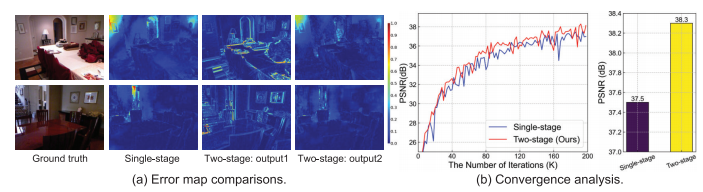 两阶段设计的消融研究
两阶段设计的消融研究
4. 结论
这篇论文的核心贡献是提出了一个高效去雾网络 SFMN。它的关键不是单纯堆深网络,而是围绕"调制"设计了三个核心机制:
CSM:跨尺度空间调制,解决不同雾浓度和不同感受野需求;
FM:频域调制,利用幅度谱和相位谱分别建模雾退化和结构纹理;
CLM:跨层调制,让浅层细节和深层上下文互相补充。
整体上,SFMN 具有几个明显优势:
| 方面 | 优势 |
|---|---|
| 性能 | SOTS-Indoor、SOTS-Outdoor、O-HAZE、Dense-Haze 等多个数据集达到 SOTA 或接近 SOTA |
| 效率 | FLOPs 只有 18.39G,低于多数 Transformer 方法 |
| 结构合理性 | 消融实验充分证明 CSM、FM、CLM 都有效 |
| 泛化性 | 在去雪任务上也有较好结果 |
| 视觉质量 | 定性结果中残雾更少、纹理更清晰、颜色更自然 |