突破纯文字交互:基于魔珐星云端到端技术,赋能国产大模型构建数字人智能体
引言:大模型的"大脑"已就绪,那"肉身"呢?
2026年,以 DeepSeek、Qwen 为代表的国产大模型(LLM)在逻辑推理与文本生成上已经达到了行业顶尖水平。然而,大多数人在体验这些顶尖"大脑"时,界面依然停留在冷冰冰的纯文本聊天框 或简单的语音播报。
大模型的未来不应被局限在方寸之间的输入框内。如何让大模型长出"生动的面孔",实现具备眼神对视、微表情、肢体动作的自然交流?本文将结合实际研发出的 Demo,分享如何依托魔珐星云(Embodia AI)AI 端渲染与端侧解算技术,补齐国产 LLM 具象交互短板的完整实战方案。
切入点:大产达模型:依托魔珐星云 AI 端侧与端侧解算技术 + 参数流,补齐 Qwen/DeepSeek 等国产 LLM 高效互服务,完善国产化 AI 闭环,助力信创项目落地全场景数字人交互应用。
引言:大模型的"大脑"已就绪,那"肉身"呢?
2026年,以 DeepSeek、Qwen 为代表的国产大模型(LLM)在逻辑推理与文本生成上已经达到了行业顶尖水平。然而,大多数人在体验这些顶尖"大脑"时,界面依然停留在冷冰冰的纯文本聊天框 或简单的语音播报。
大模型的未来不应被局限在方寸之间的输入框内。如何让大模型长出"生动的面孔",实现具备眼神对视、微表情、肢体动作的自然交流?本文将结合实际研发出的 Demo,分享如何依托魔珐星云(Embodia AI)AI 端渲染与端侧解算技术,补齐国产 LLM 具象交互短板的完整实战方案。
一、 认知重塑:撕下传统数字人的"流媒体"伪装
大模型的智商在飞速狂飙,但大模型的"长相"却一直卡在瓶颈。
-
第一点,交互行不行?
-
传统方案属于"全链路串行"架构。数据必须按"识别 → 大模型推理 → 语音合成 → 云端视频渲染"的顺序走完流程。
-
层层传递导致产生数秒级的严重延迟,数字人回应太慢,根本无法正常聊天。
-
第二点,为什么难落地?
-
传统方案极度依赖"云端网络推流"。所有 3D 渲染都在云端服务器跑,一旦多台设备并发使用,云端 GPU 算力成本会呈指数级飙升。
-
这种架构极度吃带宽,网络稍有波动就会画面卡顿、变马赛克,高昂的服务器和网络成本让批量部署很难落地。
以上就是我认为的传统数字人的痛点,但是现在魔珐星云(Embodia AI) 给了我们很好的答案。
1.传统数字人的本质:基于云端视频流的单向交互方案
传统数字人之所以做不好交互,是因为它们的架构从一开始就不是为了低延迟、高并发设计的。
虽然很多传统数字人确实做到了可交互,但不能简单地把它贬低为"视频播放器"。从技术本质来看,它其实是一套"基于云端视频流的单向交互方案":
- 云端服务器把大模型生成的文本丢给语音合成引擎。
- 渲染引擎在远端的 GPU 服务器上,把 3D 动画实时渲染成一段段视频流。
- 这些视频流通过网络拉下来,实时推流并呈现在前端屏幕上。
这种架构把压力都压在了云端。带来的副作用非常明显:超高延迟、成本高昂、并发能力极低。当面对需要快速响应、多点部署的商用大屏或车机项目时,弊端便暴露无遗。
1.2 星云(Embodia AI)的本质:可开发的 AI 躯干
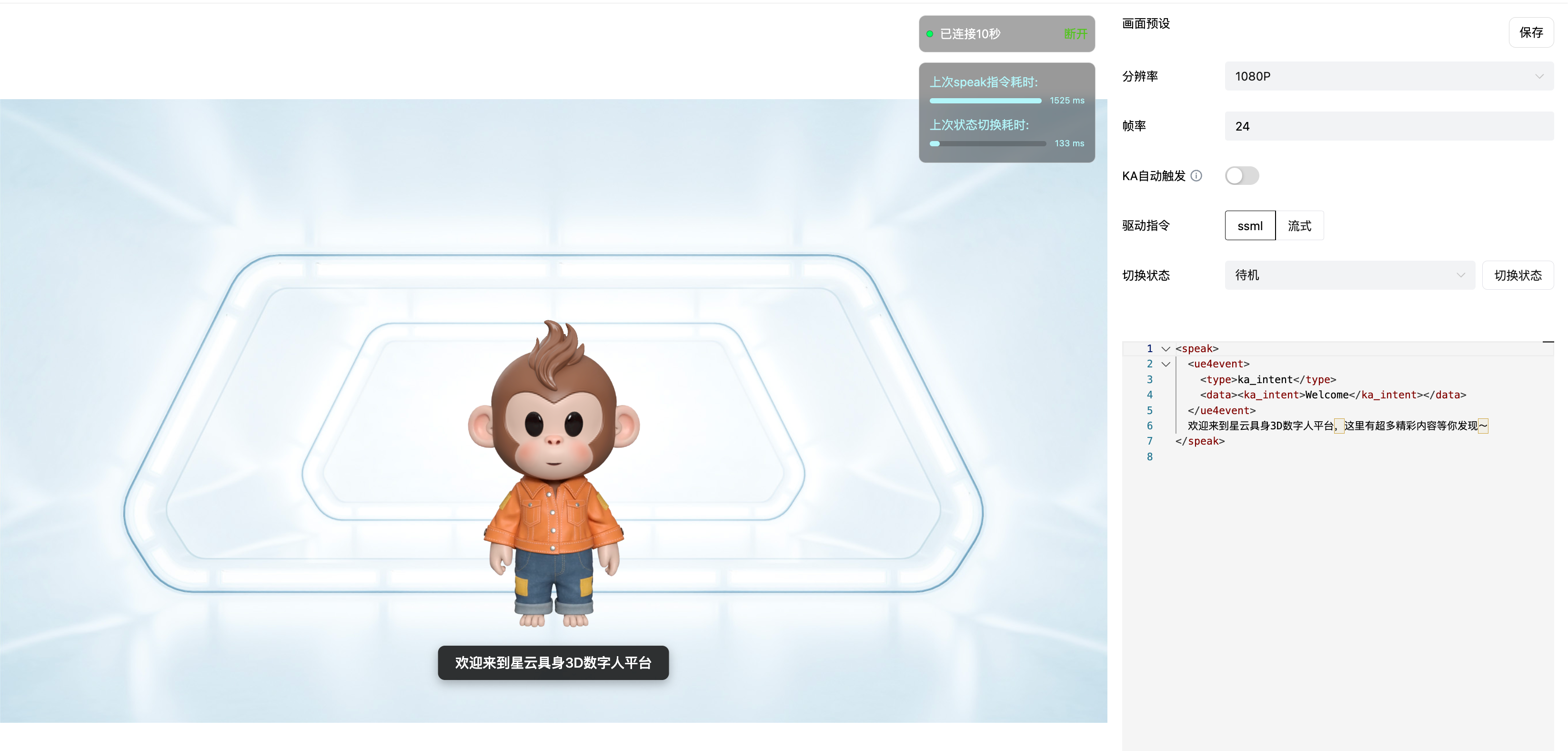
魔珐星云(Embodia AI)换了套思路。在它的架构里,数字人不再是一段被动接收的视频,而是一个真正可开发的 AI 躯干。
- 走参数流,不走视频流: 云端不传输任何高带宽的视频画面,只下发极其轻量化、毫秒级的"动画控制参数"。
- AI端侧解算,本地生成:前端通过星云 SDK,依托自研参数流架构,结合 AI 端渲和解算能力,调用本地算力实时演算 3D 骨骼与面部表情。
依托自研参数流架构,结合 AI 端渲和解算能力,调用本地算力实时演算 3D 骨骼与面部表情。
这样一来,数字人就在本地"活"过来了。接收大模型语义数据,本地实时演算生成对视眼神、微表情与肢体动作;由视频渲染转为参数驱动,是大模型落地具象交互的底层基础。
二、 拼凑的局限:为什么传统单点技术(LLM+TTS+渲染)堆砌做不出好体验?
简单的总结为一些几点:👇
2.1 延迟太高,像跟木头人聊天
传统链路是完全串行的:用户说话 → 语音识别 → 大模型思考 → 语音合成 → 驱动数字人。 每个模块都是独立的,数据传一圈、网络握手好几次,延迟全部叠加在一起。结果就是用户问完一句话,数字人要在屏幕前傻站好几秒才回应,根本没办法正常交流。
2.2 音画不同步,像看配音粗糙的译制片
人说话时,表情和声音是同步的。 但在拼凑方案里,末端的 3D 渲染器根本不理解大模型的语义,也拿不到声音里的情感细节。它只能机械地根据音频去对口型,导致数字人口型对不上、表情僵硬,充斥着严重的违和感。
2.3 太吃配置和带宽,成本顶不住
传统方案需要把所有的 3D 渲染工作都放在云端服务器上,渲染出视频画面再推给用户。 这不仅极度压榨云端 GPU 算力,还特别耗带宽。一旦想部署在普通的办事大厅大屏、前台 PC 或者车载终端上,高昂的硬件和网络成本直接劝退,更别提满足信创项目轻量化、国产化闭环的要求了。
2.4 破坏实时对话体验
传统"云端视频流"架构下,前端设备没有控制权,只能被动接收视频并播放。这种方式根本没办法做"随时打断"。比如当数字人在说话时,用户一旦想插嘴打断,系统需要重新在云端切断老视频、渲染新视频再推流下来。这导致画面切换极度生硬、卡顿,甚至出现短暂黑屏,直接把实时对话的连贯性给毁了。
三、 破局:魔珐星云(Embodia AI)端到端打通的"参数流革命"
流通法则:AI 端渲染与端侧解算技术 + 参数流(端到端≈500ms 毫秒级响应)。
plain
[用户输入/语音]
│
▼
[DeepSeek / 国产LLM(demo:deepseek)] (语义生成)
│
▼ (流式文本/参数)
[魔珐星云 Embodia AI SDK] (AI端渲和解算驱动)
│
▼
[前端 Web 渲染 (IP:port)] ────► 呈现 3D 具象交互数字人四、 当"潮玩小悟空"接入魔珐星云 SDK:从呆萌模型到傲娇智能体
针对这套方案,我写了一个完整的 Demo 并开源在了 Gitee 上,感兴趣的朋友可以点击 [项目链接](https://gitee.com/chian-ocean/eai) 查看完整源码,官方去拿APP_ID,请点击[魔珐星云官方](https://xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc151&utm_medium=&utm_term=&utm_content=)
4.1 场景定格:不仅仅是吉祥物
在界面视觉和人设打造上,我们定制了一个 3D 潮玩风格的小悟空模型,并利用前端 demo.css 为其量身定做了 UI 面板:
- 视觉容器 :通过
#sdk样式将数字人画布铺满屏幕,背景采用深色径向渐变,烘托出富有科技感的空间展厅氛围。 - 毛玻璃控制台 :右侧的
#sidebar侧边栏采用backdrop-filter: blur(15px)实现了半透明的毛玻璃质感,并在头部用亮绿色的呼吸灯标识(#00e5ff)作为智能体在线状态提示。
这种高颜值的潮玩风格在商用大屏或前台落地时,能大大降低人机交互的冰冷感,让它从一个没有温度的吉祥物变成一个时刻保持就绪、极具亲和力的傲娇智能体。
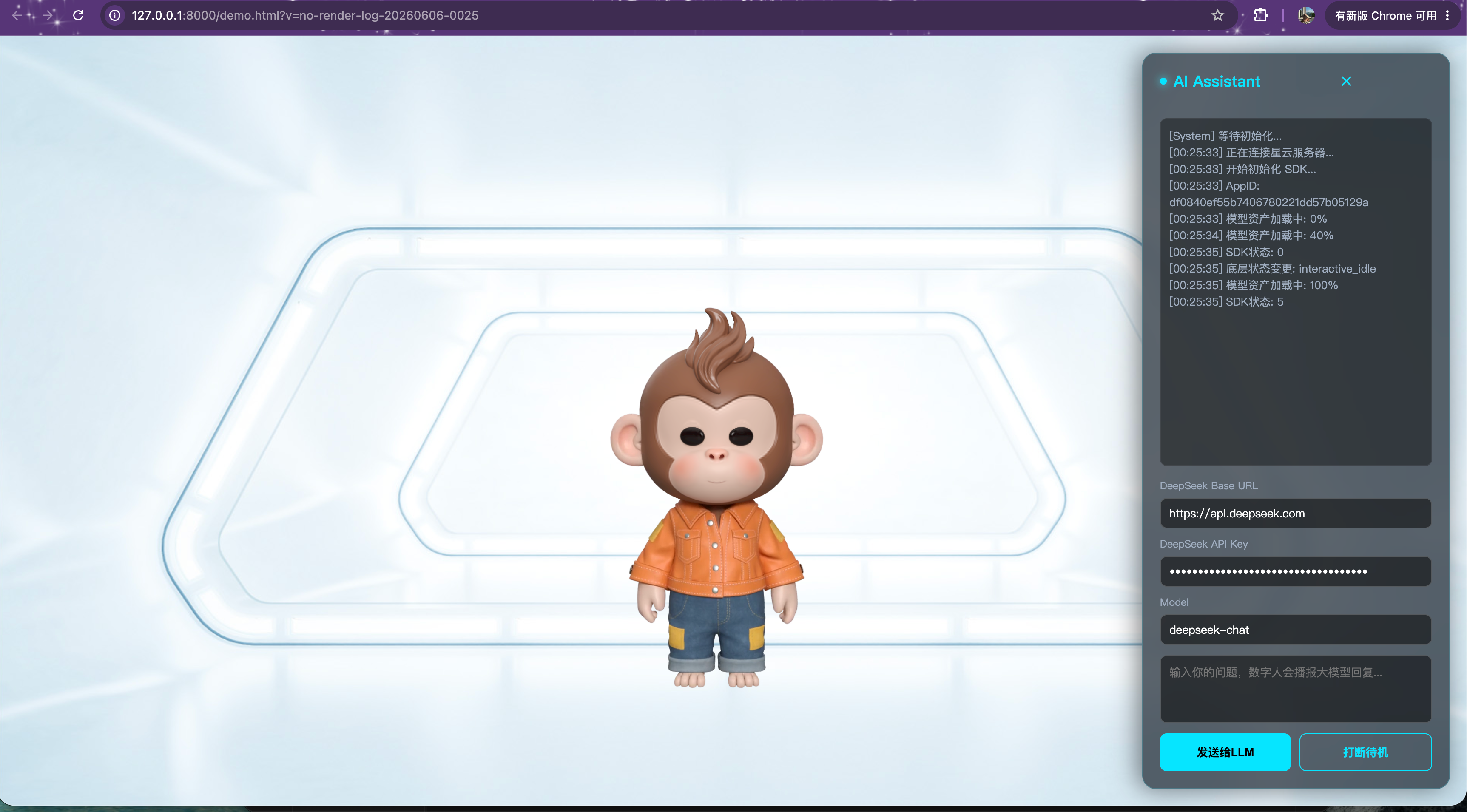
4.2 交互剧本:高燃朗诵时刻
要让小悟空开口说话并动起来,整个底层的逻辑链路非常清晰。首先,在 config.js 中配置好魔珐星云的鉴权服务凭证和大模型的默认请求参数:
plain
// config.js - 核心配置项
export const AVATAR_CONFIG = {
appId: 'df0840ef55b7406780221dd57******',
appSecret: '85dcd160c012******cd49****c6c5d',
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
containerId: '#sdk'
};
export const LLM_DEFAULTS = {
baseUrl: 'https://api.deepseek.com',
apiKey: 'sk-1d953876d5*****0befab5e329b4ee',
model: 'deepseek-chat',
temperature: 0.7,
stream: false // 可以修改为true会更加快
};
export const SYSTEM_PROMPT = '你是一个正在由数字人播报的中文AI助理。回答要自然、简洁,适合直接口播。';当用户在界面输入文本并点击【发送给LLM】按钮时,main.js 会触发 handleSend 逻辑:
- 提取输入框中的文本,调用
llm.js向 DeepSeek 发起标准的POST请求。 - 大模型接收到我们预设的
SYSTEM_PROMPT,吐出适合口播的流式文本。 - 文本秒级返回后,直接投喂给星云 SDK 的驱动接口。
plain
// llm.js - 大模型交互驱动
export async function requestLlmReply({ baseUrl, apiKey, model, userText }) {
const response = await fetch(`${baseUrl.trim()}/chat/completions`, {
method: 'POST',
headers: {
Authorization: `Bearer ${apiKey.trim()}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: model.trim(),
messages: [
{ role: 'system', content: SYSTEM_PROMPT },
{ role: 'user', content: userText }
],
temperature: LLM_DEFAULTS.temperature,
stream: LLM_DEFAULTS.stream
})
});
if (!response.ok) throw new Error(`LLM请求失败 ${response.status}`);
// 解析返回的文本内容并交由前端播报
const reply = parseLlmContent(await response.json());
return reply;
}传统的流媒体方案此时要在云端花几秒钟渲染视频,但在星云架构下,文字传回的瞬间,avatar.js 内部直接调用本地解算控制:
plain
// avatar.js - 驱动小悟空说话
export function speak(avatar, text) {
// 文本流即时转化为参数流,本地显卡直接渲染动画和语音
avatar.speak(text, true, true);
}依托端到端≤500ms毫秒级响应能力,文本传输完成的同时,动作、口型同步生成。。小悟空瞬间进入"高燃朗诵"状态,彻底告别了尴尬的停顿等待。
4.3 开发者实战:如何玩转"打断机制"?
人机交互中最核心的指标就是"打断能力"。如果数字人只能像复读机一样单向灌输、不能听人插嘴,体验就会大打折扣。
魔珐星云依托自研参数流架构与 AI 端渲和解算能力,赋予了前端绝对的控制权。要实现真正的"即时打断待机",只需要在 avatar.js 中调用底层的 interactiveidle() 状态重置函数:
plain
// avatar.js - 封装打断核心指令
export function interrupt(avatar, logger) {
if (typeof avatar.interactiveidle === 'function') {
// 瞬间切断当前正在执行的动作流与语音播报,让数字人回归待机
avatar.interactiveidle();
return;
}
logger.error('当前 SDK 版本可能不支持直接打断');
}在前端控制逻辑 main.js 中,我们为界面上的【打断待机】(停止按钮)绑定了对应的点击事件监听:
plain
// main.js - 打断事件的控制闭环
function handleStop() {
if (!state.avatar) return;
logger.info('>> 触发打断待机指令'); // 记录日志
try {
// 执行打断,动作流和声音戛然而止
interrupt(state.avatar, logger);
} catch (error) {
logger.error(`打断异常: ${error.message}`);
}
}
// 绑定页面 DOM 事件
els.stopBtn.addEventListener('click', handleStop);有了这几行关键代码,当小悟空在滔滔不绝播报长文本时,用户只要点击打断,或者在后续扩展中触发 ASR 语音插话,小悟空就能做到声音和动作瞬间停滞,并在毫秒级内优雅地恢复到眼神对视、微微晃动的自然待机状态。
4.4 大放异彩: demo展示环节
- 反应快:看日志时间,大模型刚回完,小悟空立马开播。本地解算参数流确实比等云端视频快太多。
- 同步准:说话的同时,底下字幕刚好同步刷出来,说明时间戳卡得准,以后加功能很省心。
- 逻辑闭环:资源加载到对话日志都清清楚楚。

五、结语:具象交互,拉开 AI 2.0 时代的大幕
说到底,AI 的未来绝对不该只是个一成不变的文本聊天框。
这次通过将魔珐星云自研参数流架构、AI 端渲和解算技术和 DeepSeek 这类国产大模型结合,我们算是给纯文本的 AI "大脑"安上了一个生动的"肉身"。这种低延迟、音画字同步的具象交互,让智能体有了温度,不再像个冰冷的查资料工具。随着技术的普及,这种面对面的自然交流,很快就会真正走进各种线下大屏、车载和我们的日常生活中。
欢迎大家前往使用哦----请点击[魔珐星云](https://xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc151&utm_medium=&utm_term=&utm_content=)