一. GPT-2 Decode-Only 架构概览
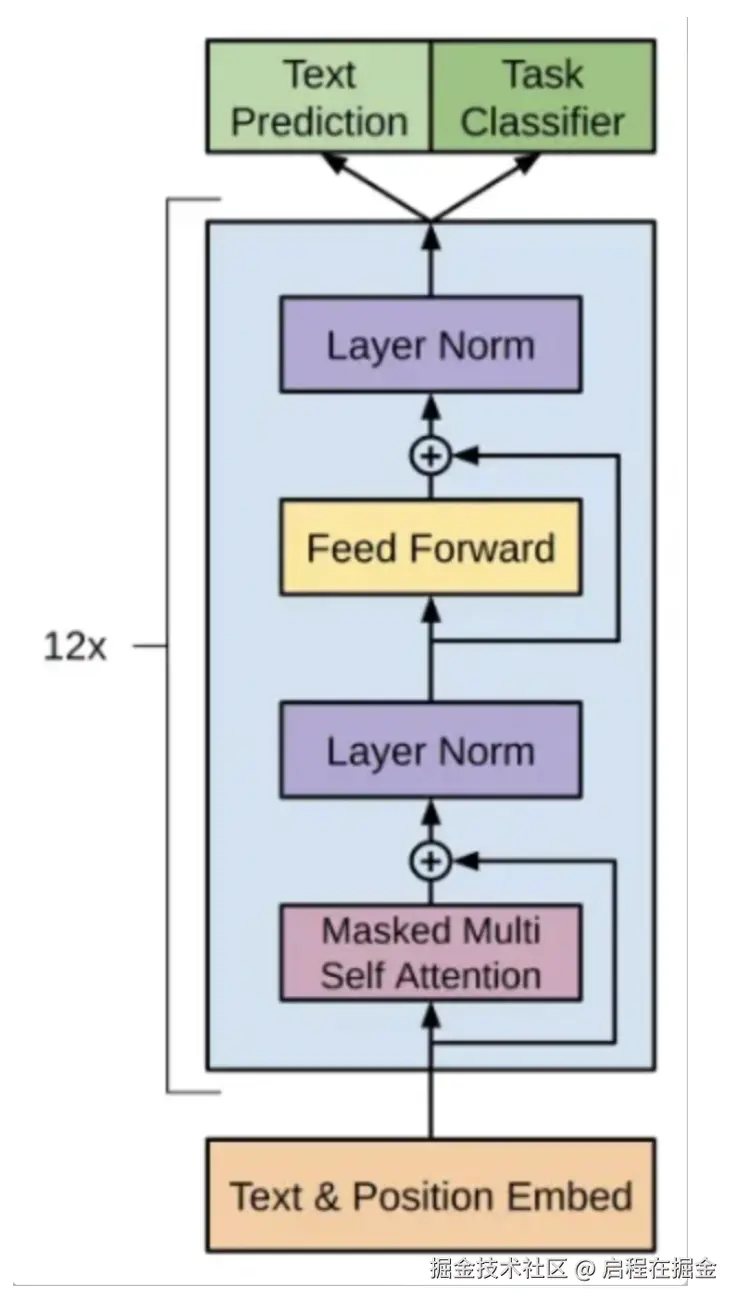
GPT-2 核心特点:
GPT-2 采用纯 Decoder 架构,与 BERT 的 Encoder 架构不同。核心创新在于使用 因果掩码(Causal Masking),确保模型在生成第 t 个词时只能看到前 t-1 个词,从而实现自回归生成。
二. Masked Multi Self Attention QKV计算流程
1. 投影计算 (Q, K, V Projection)
计算步骤:
- 输入嵌入:输入嵌入 X(维度为 Batch × SequenceLength × EmbeddingDimension)
- 权重矩阵:三个可学习的权重矩阵 W^Q、W^K、W^V,维度均为 D × D
- 生成 Q、K、V:输入嵌入分别与三个权重矩阵相乘
ini
Q = X · W^Q
K = X · W^K
V = X · W^V
# W^Q, W^K, W^V: 模型的可学习参数flowchart LR
A[输入 X] --> B[W^Q]
A --> C[W^K]
A --> D[W^V]
B --> E[Q]
C --> F[K]
D --> G[V]
style A fill:#3498db,color:#fff
style B fill:#f39c12,color:#fff
style C fill:#f39c12,color:#fff
style D fill:#f39c12,color:#fff
style E fill:#9b59b6,color:#fff
style F fill:#9b59b6,color:#fff
style G fill:#9b59b6,color:#fff
📊 2. 计算注意力得分 (Attention Scores)
注意力得分的作用:
Scores=dk Q⋅KT
通过点积计算当前词与其他词之间的相关性,值越大表示相关性越强。
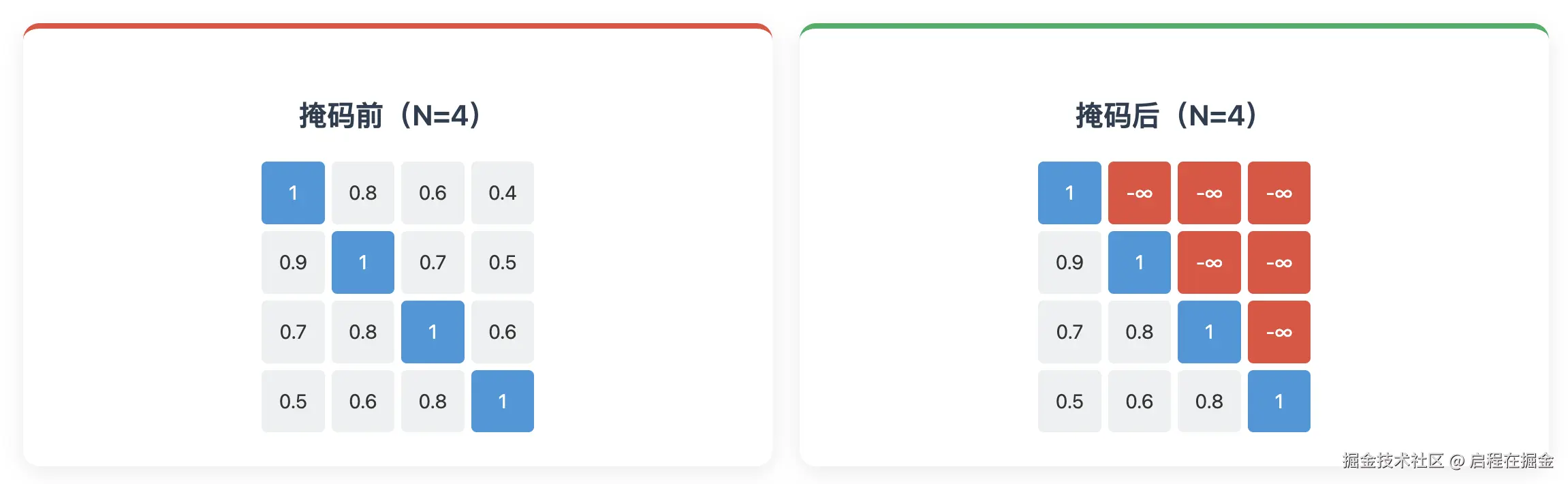
3. 因果掩码 (Causal Masking)
因果掩码的作用:
这是 GPT-2 区别于 BERT 等编码器架构的关键步骤。为了确保模型在预测第 t 个词时只能"看到"前 t-1 个词,需要应用一个 上三角掩码矩阵。
掩码操作:
| 操作 | 说明 |
|---|---|
| 创建掩码矩阵 | 创建一个与 Scores 同尺寸的下三角矩阵 |
| 填充上三角 | 将上三角部分(对角线以上)填充为 -∞ |
| SoftMax | 执行 SoftMax 后,这些位置的概率变为 0 |
scss
AttentionWeights = softmax( (Q · K^T) / sqrt(d_k) + Mask )
# Mask: 上三角掩码矩阵,对角线以上填充为 -∞掩码可视化(N=4):
4. 输出生成
最终,利用注意力权重对 Value 进行加权求和:
ini
Output = AttentionWeights · V三. Attention QKV 计算流程总结
完整六步流程:
- 定义 Q、K、V 权重矩阵:三个矩阵是可学习的权重参数,维度是 D × D(D 等于向量维度)
- 输入向量 X:输入维度为 N × D(N 等于输入序列长度,D 等于向量维度)
- 计算 Q、K、V 矩阵:输入向量 X 分别与 Q、K、V 权重矩阵相乘,得到新的 Q、K、V 矩阵,维度均为 N × D
- 计算 Attention 得分矩阵:Q 与 K 的转置相乘,生成得分矩阵,维度为 N × N,表示每个位置对其他位置的关注度
- 归一化处理(含掩码):除以 sqrt(d_k),添加因果掩码,然后进行 SoftMax
- 融合上下文信息:归一化后的注意力得分矩阵与 V 矩阵相乘,输出融合了上下文信息的新矩阵,维度为 N × D
📈 矩阵维度变化表
| 步骤 | 操作 | 矩阵名称 | 维度 |
|---|---|---|---|
| 1 | 输入 | X | N×D |
| 2 | 投影 | Qw、Kw、Vw | D×D |
| 3 | 计算 Q, K, V | Q, K, V | N×D |
| 4 | 计算得分 | Q×KT | N×N |
| 5 | 注意力加权(含掩码) | Softmax(Score+Mask) | N×N |
| 6 | 融合输出 | Attention×V | N×D |
四. 核心要点总结
Decode-Only 架构特点
- 纯 Decoder:只使用解码器结构,不使用编码器
- 因果掩码:确保自回归生成,防止信息泄露
- 自回归生成:逐词生成,每个词依赖于之前生成的词
- KV 缓存:优化生成效率,避免重复计算
注意力机制的核心
| 概念 | 作用 |
|---|---|
| Q(Query) | 当前词要"找什么" |
| K(Key) | 其他词"有什么" |
| V(Value) | 其他词的"具体内容" |
| 因果掩码 | 只允许关注前面的词 |
📚 关键概念
| 概念 | 英文 | 作用 |
|---|---|---|
| 因果掩码 | Causal Masking | 防止模型看到未来的词 |
| 自回归 | Autoregressive | 逐词生成,依赖之前的输出 |
| KV 缓存 | KV Cache | 缓存中间结果,提升生成效率 |
| 缩放因子 | Scaling Factor | 防止点积过大导致梯度消失 |
| 注意力头 | Attention Head | 并行计算不同的注意力模式 |