这是驭缰工程里房间里的大象------所有人都在谈论怎么让 AI 写代码,没人知道怎么验证它写对了。
一个不舒服的事实
Martin Fowler 在他(与 Birgitta Böckeler 合作的)驭缰工程专题文章里做了一个诚实的分类:
| 规制维度 | 成熟度 | 现状 |
|---|---|---|
| 可维护性 Harness | 最成熟 | lint、类型检查、覆盖率------工具链完善 |
| 架构适应度 Harness | 中等 | Fitness Functions 能检测漂移 |
| 行为 Harness | 最弱 | 功能正确性验证------"目前还不够好" |

Fowler 用的原话是:"This is the elephant in the room."(这是房间里的大象。) AI 能编译、能通过测试、能覆盖 90% 的代码行------但它做的是不是你想要的?没人有可靠答案。
为什么评估这么难?
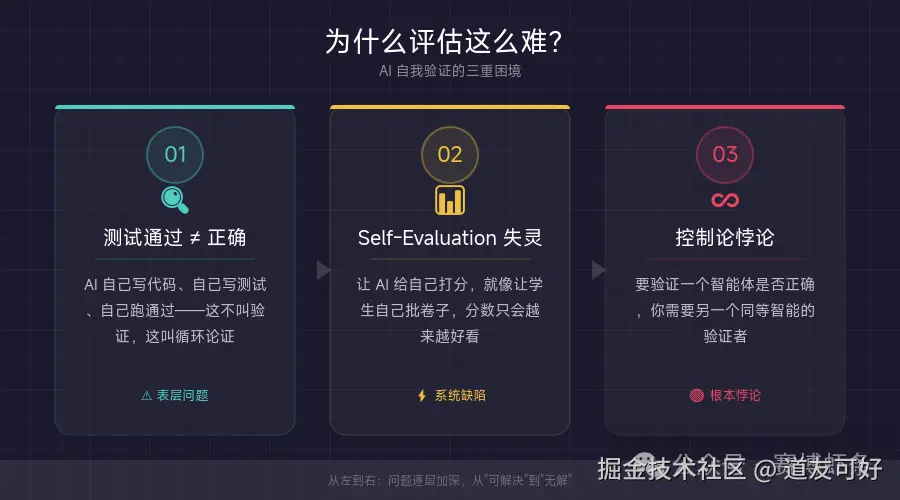
问题一:测试通过 ≠ 正确
AI 生成的测试天然有一个问题:代码、测试、执行者全是 AI 自己,绿灯能绿出花来。
测试全绿,但代码做的是不是你想要的?根本没人知道。
你让它实现 A 功能,它实现了 B 功能,然后它为 B 功能写了完美的测试。全绿。但它做的是错的。
问题二:Self-Evaluation 不可靠
Anthropic 的三智能体实验直接验证了这一点。
他们发现:智能体评估自己的工作时,倾向于过度称赞。 即使质量平庸,它也会给自己打高分。
这就像让学生自己批自己的卷子------分数肯定不低,但你不敢信。
问题三:控制论的悖论
Ashby 必要多样性定律说:调节器必须至少拥有与被调节系统同等的多样性。
换句话说:你需要一个和 LLM 一样聪明的系统来验证 LLM 的输出。但如果你有这么聪明的系统,为什么不直接用它来生成?
这是一个根本性的困境。目前没有完美解法。
目前的三种应对策略
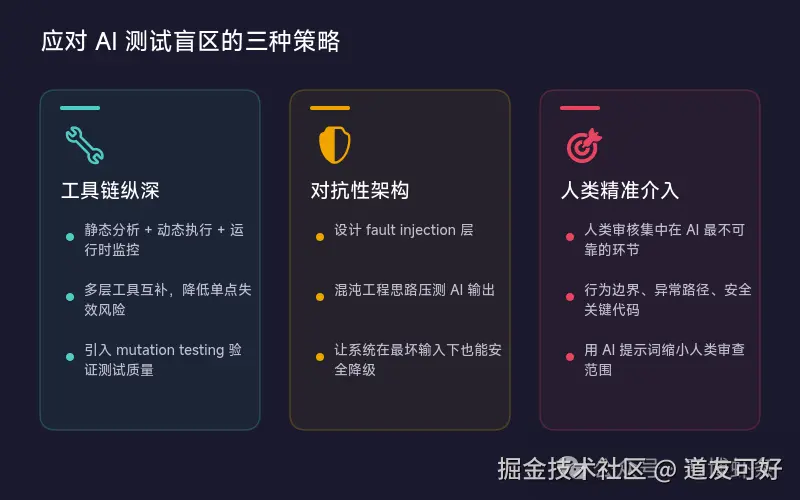
策略一:工具链纵深(计算性验证)
这是最成熟的路径------用确定性的工具链构建多层防线:
bash
第 1 层:类型检查(编译时)
第 2 层:Lint 规则(提交时)
第 3 层:单元测试(CI 时)
第 4 层:集成测试(CI 时)
第 5 层:结构测试(CI 时)
第 6 层:覆盖率检查(CI 时)优点: 快速、确定性、成本低。 局限: 只能捕获结构性和回归性错误,无法判断"代码做了对的事"。
策略二:对抗性架构(AI 审核 AI)
Anthropic 的三智能体实验给出的方案------用 AI 监督 AI 。
Planner(规划者)→ 生成规格
Generator(实现者)→ 按规格编码
Evaluator(评估者)→ 用 Playwright 实际操作应用,逐条验证
关键设计:Evaluator 不是 Generator 的自我评价,而是一个独立的智能体,有自己的判断标准。
这和 GAN(生成对抗网络)的思路一样------通过对抗来提升质量。 Sprint 合同机制让这个体系更可靠:
- 编码前,Generator 和 Evaluator 协商"done 长什么样"
- 双方达成一致后才开始
- 编码后,Evaluator 逐条验证 优点: 能捕获语义层面的错误 局限: Evaluator 本身也是 AI,也有评估偏差;成本高(Anthropic 的 Full Harness 跑一次花了 $200,是单智能体的 20 多倍)。
策略三:人类精准介入
Fowler 的核心观点:好的 Harness 不以消除人类输入为目标,而应将人类输入引导到最重要的地方。
Fowler 说得明白:好的 Harness 应该把人类的注意力集中到刀刃上。
AI 处理 95% 的结构性验证(lint/测试/类型检查)
→ 人类只看 AI 无法判断的 5%
→ 这 5% 是:需求理解、业务逻辑正确性、用户体验判断 人类的隐性 Harness: 社会问责感、对复杂性的审美痛感、组织记忆、"我们这里不这么做"的直觉。智能体没有这些。
评估的适用性矩阵

不是所有代码的评估难度都一样:
| 条件 | 可靠度 | 例子 |
|---|---|---|
| 需求明确 + 可测试 | 高 ✅ | API 实现、数据管道、CRUD |
| 需求明确 + 不可测试 | 中 ⚠️ | UI 设计、用户体验 |
| 需求模糊 + 可测试 | 中 ⚠️ | 探索性原型 |
| 需求模糊 + 不可测试 | 低 ❌ | 架构设计、产品决策、安全审计 |
一个实用的评估框架

根据 Fowler 的 Guides × Sensors 框架,加上三个规制维度,我们可以得到一个实用的评估 checklist:
可维护性评估(最成熟)
- 类型检查全过
- Lint 规则全过
- 测试覆盖率达标
- 无死代码
- 命名一致
架构适应度评估(中等)
- 依赖方向正确
- 模块边界未被突破
- 性能指标未退化
- 可观测性规范满足
行为正确性评估(最难)
- 功能规格清晰定义了"完成"标准
- 有独立的验证手段(不只是 AI 生成的测试)
- 关键路径有人工确认
- 有可运行的 demo/截图/录屏证明
写在最后
评估问题是驭缰工程最难啃的骨头。
但难啃不代表啃不动。
"测试全绿"不代表"做对了"------先接受这个前提。然后分层来:工具链兜底结构问题,对抗性架构兜语义问题,人类兜核心决策。别让人看所有代码,只看那 5% AI 确实判断不了的。
评估工具在快速进步,今天的盲区明天可能就补上了。
这是驭缰工程系列的第四篇。上一篇:《用 Linter 驾驭 AI》
下一篇:《Ralph 循环:让 AI 自己干活、自己查、自己改》
觉得有用?转发给正在纠结 AI 代码质量的同事。
有不同看法?评论区聊聊。