一、项目背景:为什么要做恶意 URL 检测?
在网络安全场景中,恶意 URL 是非常常见的一类攻击入口。攻击者往往不会直接把恶意程序摆在用户面前,而是通过邮件、聊天消息、社交平台、论坛链接、搜索结果伪装等方式,将用户引导到钓鱼网站、仿冒登录页、恶意软件下载页或带有脚本攻击的页面。对于普通用户来说,一个 URL 看起来可能只是普通网址,但它背后可能隐藏着账号窃取、隐私泄露、木马下载、恶意跳转等风险。
传统的恶意 URL 检测方式主要依赖黑名单、人工规则、搜索引擎信誉、网站备案信息或安全厂商数据库。这类方法在工程上简单直接,但缺点也比较明显:一是对新出现的恶意 URL 响应慢,二是规则维护成本较高,三是面对变形 URL、短链接、混淆字符和批量生成域名时容易漏检。因此,将机器学习和深度学习引入 URL 检测,是一个比较适合学生项目展示的方向:既有明确的安全应用场景,又能体现数据预处理、特征提取、模型训练、前后端系统集成等完整流程。
本项目的核心目标很清晰:让用户在网页上输入一个或多个 URL,系统自动调用已训练好的检测模型,输出该 URL 属于恶意链接的概率,并给出可视化结果。整体上,它不是只停留在"训练一个模型"的层面,而是进一步封装成了一个 Web 检测系统,更适合作为毕业设计、课程设计或作品集项目进行展示。
二、项目整体思路
项目可以概括为一句话:把 URL 当作一种特殊文本序列,通过深度学习模型学习其中的字符模式、结构特征和上下文表示,最终完成安全/ 恶意 URL 的二分类检测。
从完整流程来看,系统大致包含四个环节:
- 数据获取与清洗:使用公开 URL 数据集,将 good、bad 标签转化为模型可识别的数值标签;
- URL 预处理与特征构造:对 URL 字符串进行分词、编码、填充、截断,同时提取域名、子域名、后缀域、路径长度、特殊字符数量等特征;
- 模型训练与对比:分别实现 CNN、GRU + Self-Attention、BERT 三类模型,比较它们在 URL 检测任务上的表现;
- 系统封装与展示:前端基于 Angular,后端基于 FastAPI,将模型能力封装成接口,支持单 URL 和多 URL 检测。
下面这张图展示了系统的整体调用流程:用户输入 URL 后,前端将请求提交给后端,后端完成合法性校验、预处理、模型调用和结果返回,最后由网页展示检测分数。
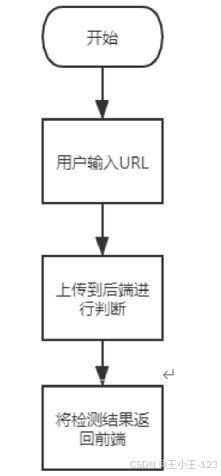
图1 系统流程图
三、技术栈与系统架构
本项目采用典型的 B/S 架构,也就是浏览器端负责交互,服务器端负责模型推理和数据处理。
| 模块 | 技术 / 方法 | 作用 |
|---|---|---|
| 前端 | Angular、TypeScript、HttpClient | 提供 URL 输入、批量检测、结果展示等交互界面 |
| 后端 | Python、FastAPI | 提供检测接口、参数校验、模型调用和结果返回 |
| 深度学习 | Keras、PyTorch | 实现 CNN、GRU、BERT 等模型训练与推理 |
| 数据处理 | Tokenizer、Padding、特征提取 | 将原始 URL 转换为模型可接收的向量或特征矩阵 |
| 模型融合 | 三分类器加权 | 综合 CNN、GRU、BERT 输出,给出最终恶意概率 |
项目中的模型部分主要围绕三条技术路线展开:CNN 用于捕获局部字符模式,GRU 适合处理 URL 的序列结构,BERT 则利用预训练语言模型的上下文建模能力进一步提升识别效果。三种模型既可以单独输出检测结果,也可以在系统中进行融合展示。
四、URL 数据预处理:模型训练前最关键的一步
URL 虽然看起来像普通字符串,但它并不是自然语言句子,而是一种带有协议、域名、路径、参数和特殊符号的结构化文本。例如,一个 URL 可能包含 http/https、主域名、子域名、端口号、路径、查询参数、锚点等信息。恶意 URL 往往会在这些部分做文章,比如使用很长的路径、混入大量数字、添加可疑符号、伪装成知名网站、使用 IP 地址代替域名,或通过短链接隐藏真实跳转目标。
在 CNN 模型中,项目将 URL 字符串转化为固定长度的序列。由于不同 URL 的长度不同,模型无法直接接收不定长输入,因此需要进行统一处理。项目根据数据分布,将 URL 长度统一设置为 161:长度不足的在末尾补 0,长度超过的截取前 161 个字符。同时,系统还额外提取后缀域名、域名和子域名,将它们映射为数值输入,用于辅助模型识别 URL 结构差异。
在 GRU 模型中,项目重点提取了 URL 的静态特征,包括 URL 总长度、主机长度、路径长度、一级路径长度、特殊符号数量、数字数量、字母数量、域名级数、是否包含 IP 地址、是否为短链接等。这些特征对恶意 URL 判断具有较强参考意义。例如,超长路径、异常多的特殊字符、直接使用 IP 地址、域名层级过深,都可能暗示该 URL 具有较高风险。
在 BERT 模型中,项目使用分词器将 URL 转换为 BERT 输入格式,包括 CLS、SEP、Token ID、Mask 和位置编码等内容。通过这种方式,URL 可以被送入预训练模型进行微调。

图2 BERT 输入表示图
五、模型一:基于 CNN 的恶意 URL 检测
CNN 常见于图像识别任务,但在文本分类中也非常实用。URL 可以看作由字符组成的序列,恶意链接中常常存在某些局部模式,例如可疑路径片段、特殊符号组合、伪装域名、异常参数等。CNN 的卷积核可以在字符序列上滑动,自动捕获这些局部特征。
本项目中的 CNN 模型设计了多个输入:主输入是经过标记化和填充的 URL 序列,辅助输入包括子域名、域名和后缀域名。URL 序列经过 Embedding 层后进入卷积层,卷积窗口分别用于捕获不同长度的局部模式;域名相关输入同样经过 Embedding 处理。随后,多个向量被拼接到一起,再通过 Dropout 和全连接层输出最终概率。
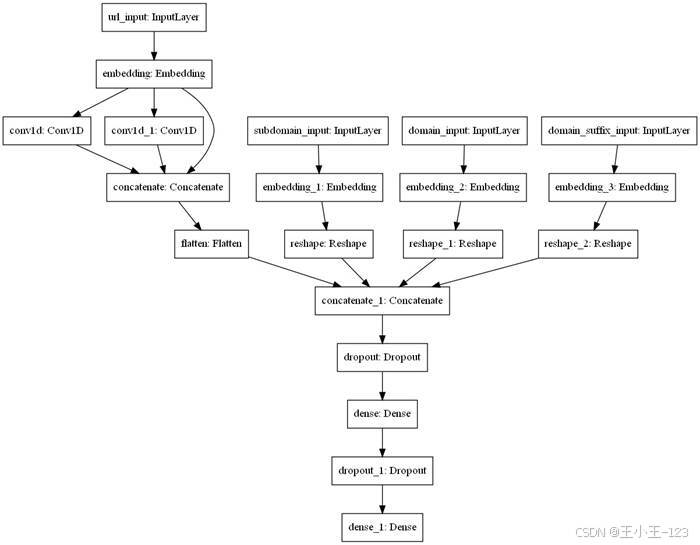
图3 CNN 网络结构示意图
训练方面,CNN 模型使用了 Adam 优化算法,并通过 Dropout 降低过拟合风险。最后一层使用 sigmoid 函数,将输出映射到 0 到 1 之间:数值越高,代表模型认为该 URL 越可能是恶意链接。项目中设置了三段式判断逻辑:小于 0.5 判定为安全,0.5 到 0.75 之间判定为可疑,大于 0.75 判定为恶意。
训练曲线显示,模型在前几轮迭代中快速提升,随后准确率逐渐趋于稳定,说明模型已经学习到较稳定的 URL 字符模式。
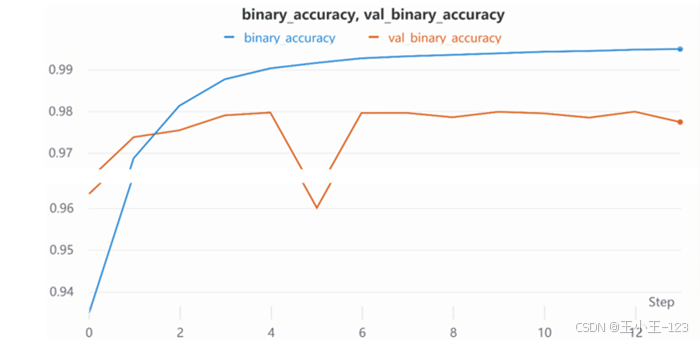
图4 CNN 准确率变化曲线
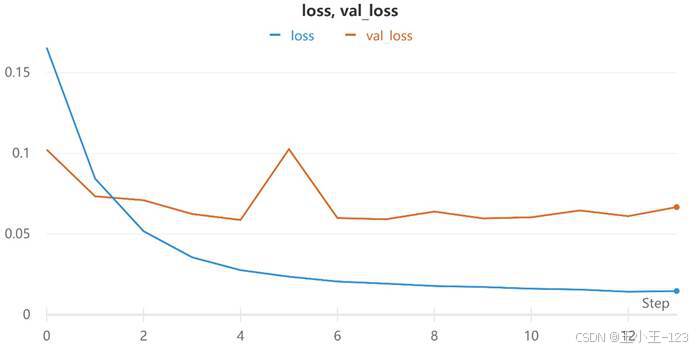
图5 CNN 损失值变化曲线
从实验结果看,CNN 模型在验证集上的准确率约为 97%,说明字符级卷积网络已经能够较好地完成恶意 URL 检测任务。对于学生项目而言,CNN 部分可以作为基础模型,用来展示深度学习在 URL 字符特征学习上的有效性。
六、模型二:GRU + Self-Attention 的序列建模方案
URL 不仅包含局部字符模式,还存在明显的序列关系。例如,协议、域名、路径、参数之间存在前后顺序;某些危险片段出现在不同位置时,含义也可能不同。因此,项目进一步引入了循环神经网络结构。
RNN 可以处理序列数据,但普通 RNN 在长序列中容易出现梯度消失和长期依赖捕获不足的问题。LSTM 和 GRU 都是在 RNN 基础上改进而来的门控结构,其中 GRU 结构相对更简洁,训练速度通常也更快。
图6 RNN 序列建模流程图
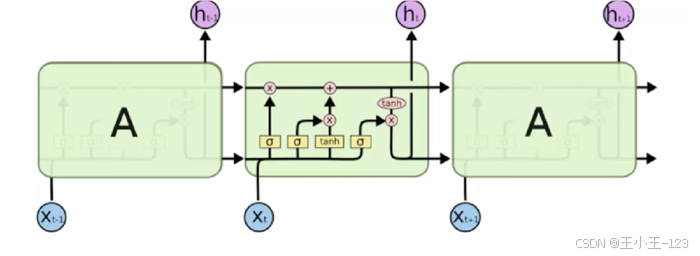
图7 LSTM 模型流程图
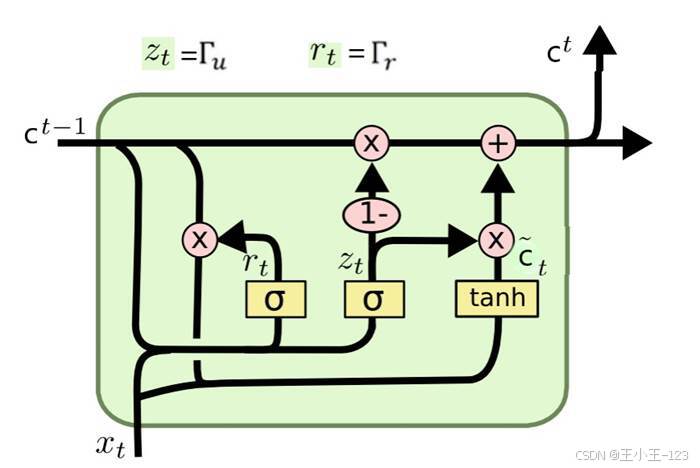
图8 GRU 基本结构图
本项目采用的 GRU 检测模型包括 Embedding 层、双向 GRU 层、Self-Attention 层、单向 GRU 层、Dropout 层和 Dense 输出层。双向 GRU 用于同时学习 URL 序列的前向和后向信息,Self-Attention 则用于自动分配不同特征片段的重要性权重,让模型把注意力集中在更可能影响分类结果的部分。
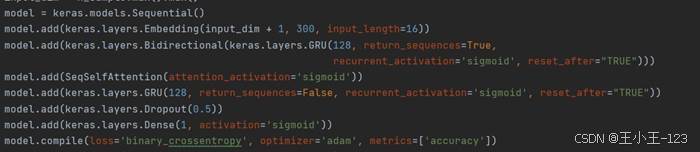
图9 GRU + Self-Attention 模型结构代码
Self-Attention 的作用可以理解为"让模型自己判断哪里更重要"。在 URL 检测中,并不是每一个字符都同等重要。普通路径片段可能价值较低,而异常符号、深层域名、短链接特征、可疑参数等可能更关键。Attention 机制能够提升这些关键信息在分类过程中的权重,从而增强模型判别能力。
GRU 模型训练时设置 batch size 为 64,初始迭代轮数为 10。训练曲线显示,模型准确率随着迭代逐步上升,但在若干轮之后验证集效果开始波动,说明模型可能已经接近最优点,再继续训练可能带来过拟合。
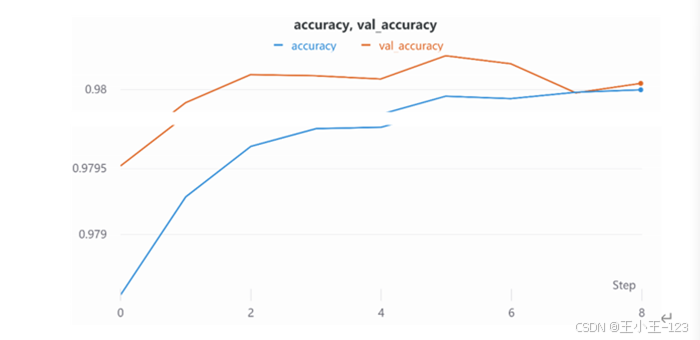
图10 GRU 准确率变化曲线
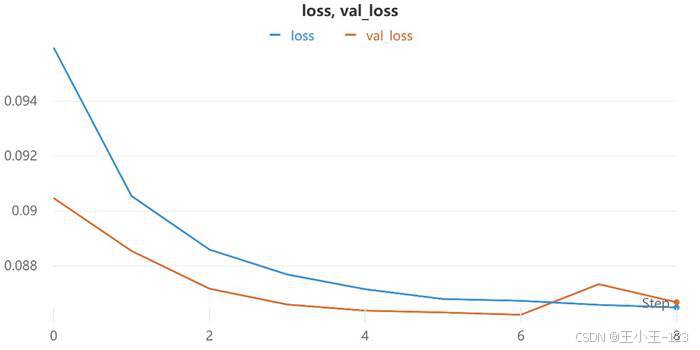
图11 GRU 损失值变化曲线
最终,GRU + Self-Attention 模型的准确率约为 98%。相比 CNN,它更强调序列结构和全局依赖,对复杂 URL 的表达能力更强。
七、模型三:基于 BERT 的 URL 检测
第三个模型采用 BERT。BERT 原本是自然语言处理领域的预训练模型,核心结构基于 Transformer,可以通过 Self-Attention 同时关注序列中不同位置的信息。虽然 URL 不是标准自然语言,但它仍然可以作为一种特殊文本输入模型,由 BERT 学习其中的字符、片段和上下文关系。
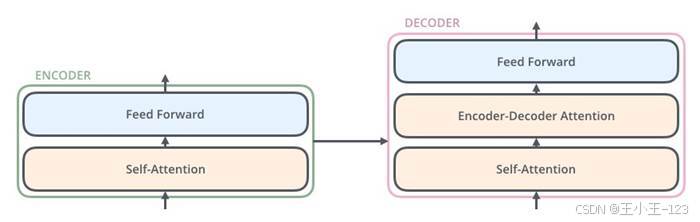
图12 Transformer 编码器与解码器结构图
本项目采用 bert-base-uncased 预训练模型进行微调。URL 输入首先经过分词器处理,然后在开头加入 CLS,在结尾加入 SEP,再转换为 Token ID,并通过 Padding 或截断统一长度。随后,模型在二分类任务上进行微调,输出 URL 为恶意链接的概率。
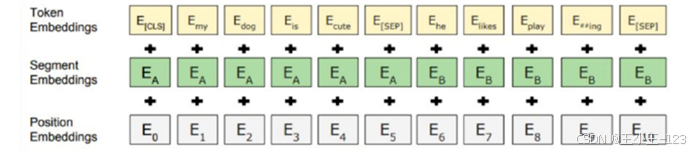
图13 BERT 微调相关代码
由于 BERT 参数量较大,对硬件资源要求更高,项目中 batch size 设置为 8,学习率设置为 2e-5,训练轮数设置为 4。实验曲线显示,模型在 3 轮左右准确率基本趋于稳定。最终,BERT 模型准确率约为 99%,是三类模型中表现最好的一个。
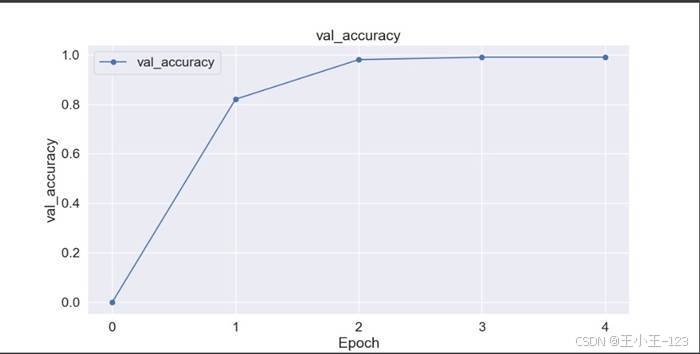
图14 BERT 模型准确率变化曲线
从结果上看,BERT 的优势主要体现在更强的上下文建模能力。CNN 更擅长局部字符模式,GRU 更擅长顺序依赖,而 BERT 可以通过 Transformer 结构直接建立序列中不同位置之间的联系,因此对复杂变形 URL 具有更强的表达能力。
八、三类模型效果对比
为了方便展示,可以将三个模型的效果总结如下:
| 模型 | 核心思路 | 主要优势 | 项目准确率 |
|---|---|---|---|
| CNN | 字符级卷积特征提取 | 结构简单、训练速度较快、适合捕获局部模式 | 约 97% |
| GRU + Self-Attention | 序列建模 + 注意力加权 | 能处理 URL 顺序关系,能突出关键特征 | 约 98% |
| BERT | 预训练模型微调 | 上下文表达能力强,整体效果最好 | 约 99% |
可以看到,项目并不是只训练了单一模型,而是采用了由浅入深的模型路线:先用 CNN 建立基础检测能力,再使用 GRU 捕获序列特征,最后用 BERT 提升上下文建模能力。这种设计非常适合写成论文或博客,因为逻辑上有递进关系,实验结果也比较直观。
九、系统实现:从模型到 Web 检测平台
一个完整项目不能只停留在 notebook 或训练脚本中,还需要让用户能够真正使用。因此,本项目将三个模型封装到了 Web 系统中,前端提供输入界面,后端提供检测接口。
系统首先支持单 URL 检测。用户在网页输入待检测 URL 后,前端通过表单将数据提交给后端。后端会先进行合法性校验,如果输入不是合法 URL,则直接返回错误提示;如果格式合法,则继续进入预处理和模型检测流程。
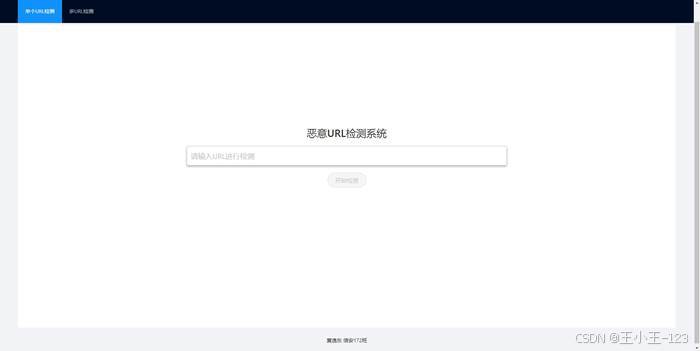
图15 单 URL 检测界面
后端使用 FastAPI 实现接口服务,并通过中间件和装饰器完成请求校验、路径分发和检测调用。FastAPI 的优势是轻量、接口文档友好、类型提示清晰,比较适合这类算法服务封装。
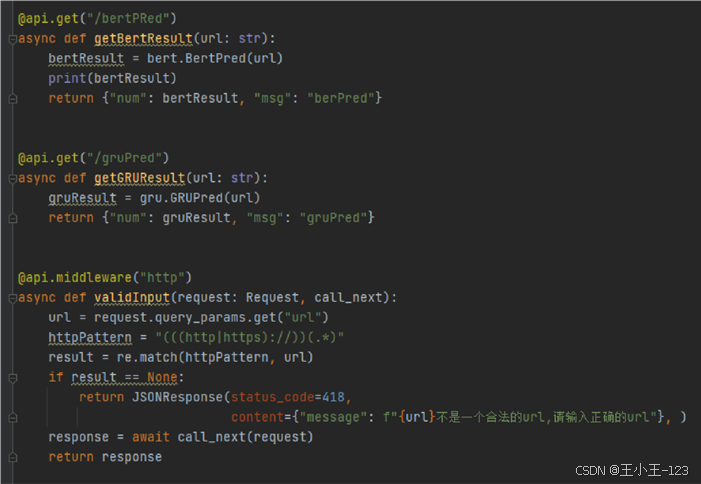
图16 后端中间件与装饰器代码
除了单条检测,项目还提供多 URL 检测功能。用户可以动态添加多个输入框,将多个待检测 URL 一次性提交给系统。后端遍历输入列表,依次调用对应的检测函数,再将多个结果统一返回给前端。对于真实使用场景来说,批量检测比单条检测更实用,尤其适合安全运维、链接巡检或数据集快速筛查。
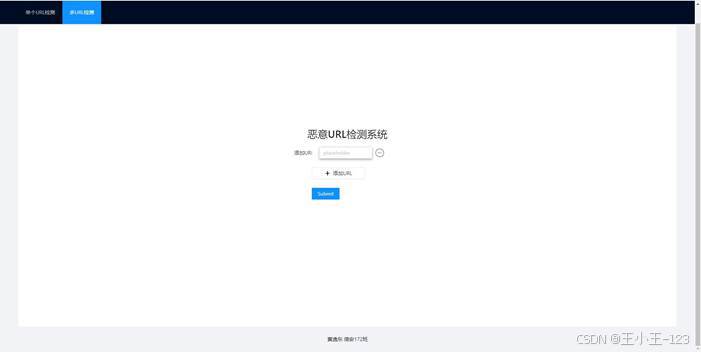
图17 多 URL 检测界面
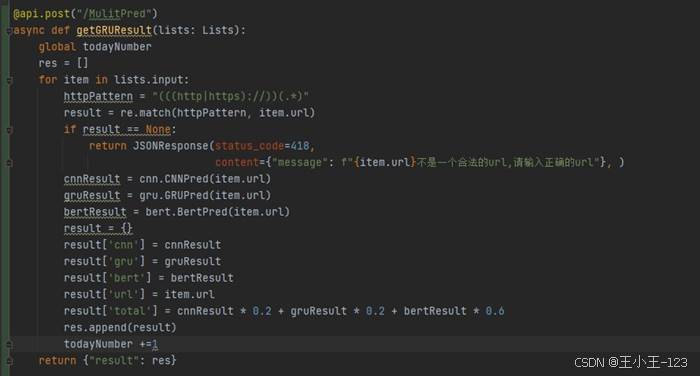
图18 多 URL 检测后端处理代码
在结果展示部分,系统会分别显示 CNN、GRU 和 BERT 对同一 URL 的预测概率,也会通过三分类器加权得到一个综合风险分数。这样的设计有两个好处:一是用户可以看到不同模型的判断差异,二是综合分数比单一模型更稳定,更适合做最终展示。
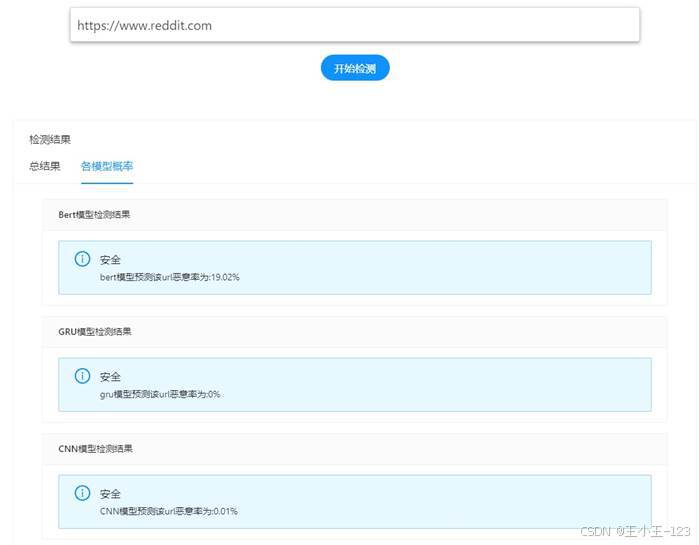
图19 各模型检测结果展示
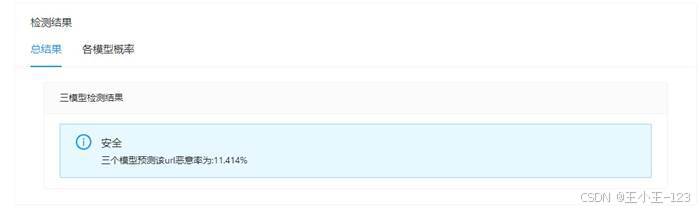
图20 三分类器加权检测结果
十、系统统计与工程细节
除了核心检测功能,项目还加入了检测次数统计和定时任务。系统会记录当天已检测次数,服务器启动时读取已保存的统计文件;每次前端请求 API 时更新统计数;服务器关闭时保存当前状态,避免数据丢失。每天接近结束时,定时任务会判断日期变化并进行清零。
这个功能虽然不是算法核心,但对项目展示非常有价值。很多学生项目容易只有"能跑通"的功能,而缺少服务状态管理、数据保存、定时任务等工程细节。本项目加入这些内容后,更像一个真实的 Web 服务。
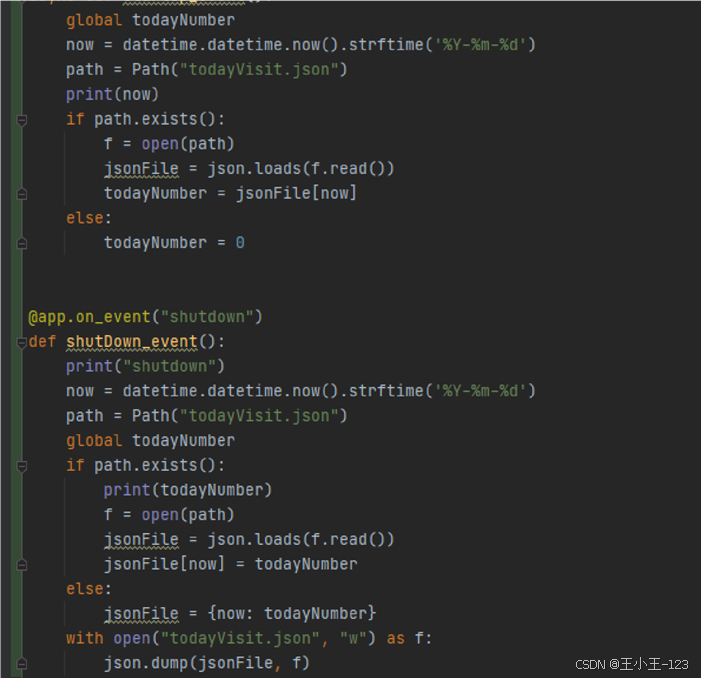
图21 检测次数统计与服务状态保存代码
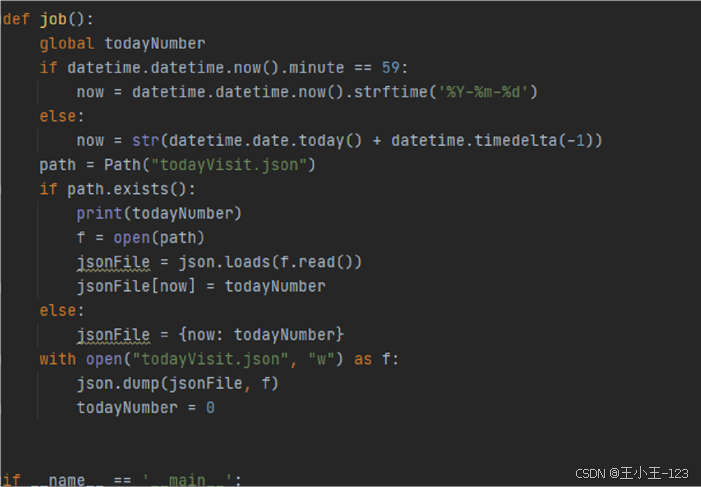
图22 定时任务代码
十一、项目亮点总结
整体来看,这个恶意 URL 检测系统可以总结出以下几个亮点:
第一,选题具有实际应用价值。 恶意 URL 是网络攻击中非常常见的入口,检测系统可以服务于钓鱼识别、链接安全检查、企业安全网关、浏览器插件、安全教育平台等场景。
第二,技术路线完整。 项目不仅介绍了 URL 结构、Web 系统和深度学习基础,还实现了 CNN、GRU、BERT 三类模型,具有较完整的算法对比逻辑。
第三,数据处理过程清晰。 不同模型采用不同的数据表示方式:CNN 使用字符序列与域名结构输入,GRU 使用静态特征与序列建模,BERT 使用分词器和预训练输入格式,能够体现机器学习项目中"数据表示决定模型效果"的思想。
第四,系统落地效果较好。 项目最终实现了 Angular + FastAPI 的可视化检测平台,支持单 URL、多 URL、模型分数展示和综合加权结果,便于博客展示和答辩演示。
第五,实验结果有层次。 CNN 达到约 97%,GRU + Self-Attention 达到约 98%,BERT 达到约 99%,模型效果呈现递进趋势,便于在论文和项目介绍中展开分析。
十二、后续可优化方向
如果后续要继续完善这个项目,可以从三个方向扩展。
首先是数据集扩展。目前模型主要依赖 URL 字符串和标签,如果能够进一步加入 WHOIS 信息、域名注册时间、DNS 解析信息、页面跳转链、网页内容摘要、证书信息等特征,模型对复杂攻击的识别能力会更强。
其次是系统功能扩展。当前系统已经支持基础检测,但还可以加入历史检测记录、风险解释、批量文件上传、检测报告导出、模型版本管理和后台管理模块。这样项目会更接近真实安全产品。
最后是模型更新机制。目前模型属于离线训练,更新需要重新训练并部署。后续可以探索增量学习、在线学习或定期训练机制,让模型能够随着新的恶意 URL 数据持续迭代。
十三、总结
本文介绍了一个基于机器学习和深度学习的恶意 URL 检测系统。项目从网络安全中的恶意链接识别需求出发,完成了数据预处理、CNN 模型、GRU + Self-Attention 模型、BERT 微调模型以及 Web 检测系统的实现。最终系统能够对用户输入的 URL 输出不同模型的风险概率,并通过三分类器加权给出综合判断。
对于学生论文和项目展示来说,这个项目的优势在于结构完整、图文材料丰富、技术链路清楚,既能体现网络安全应用价值,也能展示深度学习模型的训练与部署过程。将它整理成博客后,可以突出"项目能做什么、用了什么技术、模型效果如何、系统界面长什么样"这几个重点,既适合放在 CSDN、博客园、个人网站,也适合作为作品集中的项目说明。
每文一语
善于利用工具,事情会变得简单起来!