美国文化里有一句家喻户晓的谚语:
"You can't have your cake and eat it too."用中文来讲就是"鱼与熊掌,不可兼得。"
这句话不仅带点生活的哲理,在软件工程和数据科学领域更是被奉为金科玉律。在架构设计中,从来没有所谓的"完美方案"------任何一个惊艳的算法,换个业务场景可能就翻车了。优秀架构的本质,永远是在特定场景下做出的权衡。
拿大家最熟悉的"空间换时间(计算 vs 存储)"来说:
【场景 A】 存储城市间的距离。把大城市之间的距离算好直接存进数据库,是最合理的做法。毕竟城市自己不会长腿跑掉,如果前端每发起一次请求,程序就要重新算一遍纽约到旧金山的距离,那就太低效了。
【场景 B】 智能聊天机器人。你不可能让它提前背下人类的所有提问和标准答案(因为语言组合是无穷的),它必须根据用户的即时输入,进行"在线动态计算"。
场景 A 牺牲了存储,换来的是极致的响应速度;场景 B 消耗了计算性能,却省下了海量的预存空间。你很难做到既不花算力、又不占内存,因为"鱼与熊掌无法兼得"。
不过,今天我们要聊一个更具颠覆性、也更烧钱的话题:大语言模型(LLM)。
大模型是目前地表最强的 AI 武器,几乎吞噬了全人类的知识库。但它们体量太大了,企业一般都是通过 API 远程调用。问题是:API 调用 = 消耗 Token = 疯狂烧钱。
设想一下,你想做一款智能应用,帮用户挑选今晚约会的餐厅。用户输入:"帮我找一家不贵、浪漫、位置好、有情调的意大利餐厅。"
如果让 LLM 跑去遍历全球成千上万家餐厅的数据,再去逐一判断它们是不是意大利菜、价格适不适合、够不够浪漫......最坏的结果是:你还没收到返回结果,公司卡里的 Token 余额就已经被烧光了,而用户可能已经饿得睡着了。
但我们又不想放弃 LLM 强大的自然语言理解能力。怎么破?其实核心思路很简单:我们不能在整个业务链路的每一处,都用最重的模型。
今天,我将带大家用 Python 落地一个实战案例,以"餐厅推荐"系统为例,分享一套"极速与精准兼得"的 LLM 推荐系统架构秘籍。
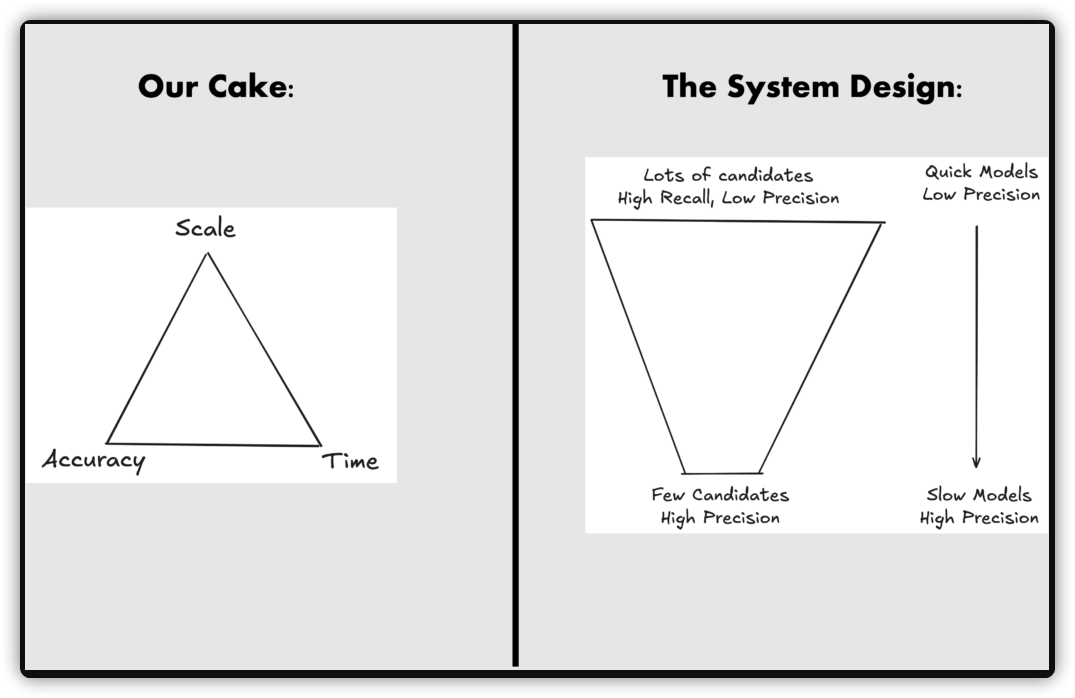
1. 漏斗架构设计:打破"不可能三角"
工程学中有一个著名的"准确度-规模-速度"不可能三角:
1.想在海量数据上做到极度精准?速度就会慢得让人崩溃。
2.想做到既精准又快速?那数据集的规模就不能太大。
3.想做到既快速又能承载海量规模?准确度就必须妥协。
为了打破这个僵局,工业界最主流的做法是"分级漏斗架构":用规则"粗筛"来实现高并发和低延迟,用 AI"精排"来实现高准确度。
阶段 1:位置与规则粗筛 (轻量/高召回/低成本/Hostease服务器) → (从 10,000+ 缩减至 50 个候选) → 阶段 2:LLM 智能重排 (重型/高精准/语义理解) │
第一阶段: 快速、轻量的硬性条件过滤(比如基于地理位置),快速筛选出 Top-K 个最近的餐厅。(高召回率,低精准度)
第二阶段: 指派大语言模型登场,只针对这 Top-K 个候选餐厅进行深度语义匹配,选出最符合用户主观意图的推荐。(高精准度)
通过这种设计,LLM 永远不会看到全量的万级数据库,它只处理粗筛出来的几十个候选者。这样既省下了99% 的 Token 经费,又完美保留了 AI 的智能化体验。
这种双阶段漏斗对底层的硬件响应和网络 I/O 要求极高。第一阶段的万级数据空间计算需要极快的 I/O 吞吐,第二阶段与 LLM API 的握手更需要网络低延迟。在实际商业化落地中,我们团队将此类管线部署在 Hostease 独立服务器 上。其海外本土的高带宽骨干网络以及出色的多核并发处理能力,能确保 Stage 1 的磁盘读写和 Stage 2 的网络中继毫无瓶颈。
2. Python 代码实战
2.1 依赖环境与初始化
为了让项目完全可复用,我们采用面向对象(OOP)的方式编写了核心管线。首先导入基础模块:
Python
from scripts.pipeline import Pipeline
from scripts.dataloader import RestaurantDataLoader
from scripts.datagenerator import RestaurantDataGenerator
from scripts.recommendation import RestaurantRecommender
from scripts.output import OutputGenerator
2.2 模拟数据生成
在生产环境中,这些数据通常存储在自建数据库或云存储中。这里我们先在本地生成 10,000 条包含随机商圈、菜系、价格区间和评分的模拟餐厅数据:
Python
from scripts.datagenerator import RestaurantDataGenerator
生成含有~1万条餐厅数据的测试集,并持久化到本地
generator = RestaurantDataGenerator()
generator.save()
2.3 第一阶段:位置粗筛(生成候选池)
这一步纯粹靠数学计算(大圆距离公式)来过滤城市和距离,完全不消耗任何 AI Token。
我们来测试一个非常刁钻的用户需求:"cheap vegan tacos with a lively atmosphere"(便宜、纯素食、塔可饼、氛围热闹)。
Python
from scripts.dataloader import RestaurantDataLoader
from scripts.recommendation import RestaurantRecommender
from scripts.constants import CITY_COORDINATES
loader = RestaurantDataLoader()
recommender = RestaurantRecommender(loader)
query = "cheap vegan tacos with a lively atmosphere"
columns = "name", "style", "dietary", "avg_score", "n_votes", "price_range", "distance_km"
for city in "New York", "Miami", "Boston":
user_lat, user_lon = CITY_COORDINATEScity
第一阶段:只按地理距离筛选出前 50 个候选者
shortlist = recommender.shortlist_by_distance(city, user_lat, user_lon)
print(f"\n{city}: 距离最近的 50 家候选(展示前5家)")
print(shortlistcolumns.head().round(2).to_string(index=False))
【Stage 1 输出结果】:
Plaintext
New York: 距离最近的 50 家候选(展示前5家)
The Tavern Deluxe Korean omnivore 4.22 1010 0.23
The Harbor Chinese omnivore 3.45 3610 0.41
Urban Grill & Co. French omnivore 4.03 1100 0.63
Urban House Room Japanese vegan 3.13 9911 0.78
Green Bistro Deluxe Indian omnivore 3.82 9510 0.99
结果分析: 可以看到,目前的粗筛列表完全无视了用户想要的"Tacos(塔可)"和"Cheap(便宜)",排在最前面的全是韩国料理和中餐。但这完全符合预期,因为这一步的目的就是把数据范围从 10,000 瞬间压缩到 50,并且保证推荐的餐厅在距离上是绝对靠谱的。
2.4 第二阶段:LLM 精准重排
现在,轮到大模型进行"降维打击"了。我们使用 OpenAI 客户端,并通过 Pydantic 强行约束大模型只输出结构化 JSON 数据,彻底杜绝自由文本解析报错的问题。
Python
from scripts.dataloader import RestaurantDataLoader
from scripts.recommendation import RestaurantRecommender
loader = RestaurantDataLoader()
recommender = RestaurantRecommender(loader)
query = "cheap vegan tacos with a lively atmosphere"
for city in "New York", "Miami", "Boston":
这一步在底层会自动接收 Stage 1 的 50 个候选,并将其喂给 LLM
result = recommender.recommend(query=query, city=city)
print(f"\n===== {city}: 推荐结果 ({len(result.response.picks)} 个精选) =====")
for rank, pick in enumerate(result.response.picks, start=1):
print(f"{rank}. {pick.name} 匹配度: {pick.fit_score:.0f}/100")
print(f" 推荐理由: {pick.reason}")
print(f"小结: {result.response.summary}")
【Stage 2 输出结果】:
Plaintext
===== New York: 5 个精选 (基于 50 个候选重排) =====
- Golden Spoon 匹配度: 90/100
推荐理由: 这是一家纯素食(Vegan)餐厅,评分高达 4.9 且评价数极多,完美契合"氛围热闹"的需求。虽然主营不是 Taco,但素食菜单完全过关。
- Maison Fork 匹配度: 85/100
推荐理由: 墨西哥菜系(Mexican),绝对有塔可。4.5 的高分且在预算内,是性价比极高的塔可选择。
小结: 针对"便宜、纯素食、氛围热闹的塔可饼"需求,纽约的 Golden Spoon 和 Maison Fork 是首选。
Plaintext
===== Boston: 5 个精选 (基于 50 个候选重排) =====
- Urban Spoon 匹配度: 90/100
推荐理由: 墨西哥菜,完美对齐 Taco 需求;价格极低,符合 Cheap 标签;高评价数暗示其店里氛围非常火爆。
- Little House 匹配度: 85/100
推荐理由: 传统墨西哥风味,非常适合吃 Taco。价格低廉且人气很高。
小结: 波士顿地区首推 Urban Spoon 和 Little House,它们在完美符合墨西哥菜系的同时,极具性价比。
3. 架构收益对比
如果我们将这套"双阶段漏斗架构"与传统的"直接用 LLM 检索全表"方案进行对比,你会发现它在工程落地上的优势是压倒性的:
(1)Token 成本暴降 99%
传统全表方案:每次用户发起请求,你都需要把万级餐厅的全部描述都塞进 Prompt 的上下文中,Token 消耗量呈爆炸式增长,财务成本根本无法承受。
双阶段漏斗方案:每次喂给大模型的数据,仅仅是 Stage 1 粗筛出来的 50 个候选描述。你只为最精准的"精排"买单,直接砍掉了 99% 的无效 Token 支出。
(2)响应延迟从"分钟级"缩短至"秒级"
传统全表方案:让大模型在单次长文本中处理数万条数据,API 的推理和响应时间通常长达数十秒甚至几分钟,用户体验极差。
双阶段漏斗方案:得益于底层的硬核优化,第一阶段的规则粗筛在毫秒内即可完成。大模型只需要并行处理极小的上下文,1 秒左右就能给出最终的精准重排结果。
(3)硬件门槛全面平民化
传统全表方案:如果要走本地私有化部署,海量的上下文需要极其恐怖的显存支持,对算力资源要求极高。
双阶段漏斗方案:由于核心的计算压力被分散到了基础过滤和轻量级推理上,普通的云服务器、或者标准的 Hostease 独立服务器 就能轻松跑满高并发,大幅降低了企业的基建成本。
(4)彻底根除 AI 幻觉
传统全表方案:大模型在面对海量、冗长的文本输入时,极容易产生语义混淆,甚至"胡编乱造"出一些根本不存在的餐厅地址。
双阶段漏斗方案:大模型的所有推荐结果,都只能在 Stage 1 框定的 50 家真实存在的本地数据库候选池中进行挑选。这就等于给 AI 扣上了安全带,确保了结果 100% 真实可靠。
不得不承认,大模型在 Stage 2 中展现出了让人惊艳的语义理解力:它能敏锐地识别出"墨西哥菜(Mexican) = 塔可饼(Tacos)"的内在联系,还能通过评价数(n_votes)去侧面推导"氛围是否热闹"。当数据无法完美匹配时,它还会"傲娇"地扣除一部分匹配分,并在 reason 字段里诚实地说明原因。
4. 结语与生产环境避坑指南
把这套方案从 Demo 搬到真实的生产环境时,有两点需要特别注意:
第一阶段的算力瓶颈: 如果你的应用日活(UV)非常高,Stage 1 的地理围栏计算(Geofencing)和硬性规则过滤会在瞬间吃满 CPU。你需要通过建立空间索引(如 H3 或 S2)或使用高性能的缓存数据库(如 Redis)来加速这个过程。
高并发下的网络延迟: Stage 2 需要频繁地向大模型中继数据。一旦网络出现抖动或 API 响应超时,整个推荐链路就会面临雪崩的风险。在架构设计上,必须引入完备的超时重试机制和降级兜底方案(例如在大模型接口超时时,直接将 Stage 1 按照评分排序的结果返回给用户)。
总的来说,推荐系统的本质就是一场关于"权衡"的艺术。大模型的出现并没有让传统的架构设计过时,反而对我们调度算力的智慧提出了更高的要求。通过将轻量级的传统过滤与重量级的语义理解相结合,我们不仅能帮公司守住 Token 账单的底线,更能为用户交出一份兼顾速度与智能的完美答卷。