承接上文,在ADM云平台里面进入服务器里面,默认打开就是ModelScope 一键微调 Gemma 4 情绪分类的脚本,如果找不到,去这个路径(/workspace/repo/src/fine-tune/models/gemma4)找
任务简介:模型和数据都从 ModelScope 下载,训练方式用 LoRA,任务是英文六分类情绪识别。整套流程跑通之后,我觉得它很适合写成一篇"可复现、少踩坑"的实战笔记。
这篇文章就基于 gemma4_emotion_lora_modelscope_single_gpu.ipynb 展开,目标很明确:在 AI-ModelScope/emotion 数据集上,对 google/gemma-4-E4B-it 做单卡 LoRA 微调,并完成微调前后对比评估。
一、这份 Notebook 解决了什么问题
如果你之前直接照搬 Hugging Face 版本的教程,通常会遇到几类现实问题:
- 需要登录 Hugging Face,还要处理
HF_TOKEN。 - 数据集和模型分散在不同平台,下载链路不稳定。
MsDataset和datasets某些版本组合下,容易出现兼容性报错。- 原始方案偏多卡,不适合单卡机器快速验证。
- AMD ROCm 环境下,
bitsandbytes的兼容性经常不如 CUDA 稳定。
这份 Notebook 的价值就在于,它把这些问题逐个绕开了:
- 不依赖 Hugging Face 登录。
- 模型从 ModelScope 下载到本地后,再交给
transformers加载。 - 数据集直接下载 parquet 文件,用
datasets.load_dataset("parquet", ...)本地读取。 - 全流程改成单卡训练。
- 保留完整的训练前评估、训练后评估、结果导出和 LoRA 重新加载能力。
换句话说,这不是一份"概念演示代码",而是一份比较贴近真实训练场景的可复用模板。
二、任务设定与整体流程
这次任务使用的是 AI-ModelScope/emotion,它是 dair-ai/emotion 在 ModelScope 上的镜像版本,属于标准的英文情绪分类数据集:
train / validation / test = 16000 / 2000 / 2000- 文本字段:
text - 标签字段:
label - 六个类别:
sadness、joy、love、anger、fear、surprise
Notebook 里的核心配置如下:
MODELSCOPE_MODEL_ID = "google/gemma-4-E4B-it"
MODELSCOPE_DATASET_ID = "AI-ModelScope/emotion"
OUTPUT_DIR = "./gemma4-it-emotion-lora-ms-single-gpu"
TRAIN_LIMIT = 4000
VALIDATION_LIMIT = 400
TEST_LIMIT = 400
EVAL_LIMIT = 400
SEED = 42
MODEL_DTYPE = torch.bfloat16
BF16 = True
FP16 = False这里默认不是全量训练,而是先用较小数据量快速验证流程。做法很务实,因为大模型微调里,先把链路跑通往往比一开始就追求最好指标更重要。
整套流程可以概括成 6 步:
- 安装
modelscope、transformers、datasets、trl、peft等依赖。 - 从 ModelScope 下载 Gemma 4 指令模型。
- 从 ModelScope 下载情绪数据集,并从本地 parquet 读取。
- 把分类样本改造成聊天模型适合的
prompt + completion格式。 - 用
SFTTrainer + LoRA做单卡微调。 - 对比微调前后
accuracy、macro_f1、invalid_predictions等指标,并导出 CSV。
三、依赖与环境
安装命令如下:
uv pip install -U vllm modelscope transformers accelerate datasets trl peft scikit-learn pandas tqdm torchvision --no-cache -i https://mirrors.cloud.tencent.com/pypi/simple/ --extra-index-url https://wheels.vllm.ai/rocm/整套依赖分工很清楚:
modelscope负责模型和数据集下载。transformers负责加载 tokenizer 和基础模型。datasets负责从本地 parquet 读取样本。trl的SFTTrainer负责监督微调。peft负责 LoRA 挂载。scikit-learn负责评估指标。
对应导入如下:
import os
import re
import json
import random
import warnings
import numpy as np
import pandas as pd
import torch
from tqdm.auto import tqdm
from datasets import Dataset, DatasetDict, ClassLabel, load_dataset
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, f1_score
from modelscope import snapshot_download
from modelscope.hub.snapshot_download import dataset_snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
from peft import LoraConfig, PeftModel
from trl import SFTConfig, SFTTrainer随机种子与基础目录初始化也做了封装:
def setup_seed(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs("./models", exist_ok=True)
os.makedirs("./datasets", exist_ok=True)Notebook 还会打印当前 GPU 环境:
print("torch version:", torch.__version__)
print("torch.cuda.is_available():", torch.cuda.is_available())
print("torch.cuda.device_count():", torch.cuda.device_count())
if torch.cuda.is_available():
print("current device:", torch.cuda.current_device())
print("device name:", torch.cuda.get_device_name(0))从原始输出看, 实际跑在单卡 AMD GPU 上,虽然使用的是 torch.cuda 接口,但在 ROCm 环境中依然是正常现象。
四、为什么这份实现值得参考
1. 完全绕开 Hugging Face Hub 依赖
Notebook 里把模型源改成了:
MODELSCOPE_MODEL_ID = "google/gemma-4-E4B-it"然后通过 snapshot_download() 拉到本地,再用 AutoTokenizer.from_pretrained() 和 AutoModelForCausalLM.from_pretrained() 从本地目录读取。这样做的好处很直接:训练阶段不再依赖外部在线仓库,环境更稳定,也更方便做缓存复用。
2. 不走 MsDataset.load(),直接读 parquet
这是我认为这份 Notebook 最实用的一个细节。
很多教程会直接调用高层数据集接口,但这类封装一旦和 datasets 版本不匹配,就容易报类似:
as_dataset() got an unexpected keyword argument 'verification_mode'这份实现的思路更稳:先把数据集仓库整体下载到本地,再自己组织 parquet 文件路径:
dataset_dir = dataset_snapshot_download(
MODELSCOPE_DATASET_ID,
cache_dir="./datasets",
)
def _parquet_files_for(split_name: str):
pattern = os.path.join(dataset_dir, "data", f"{split_name}-*.parquet")
files = sorted(glob.glob(pattern))
if not files:
raise FileNotFoundError(
f"No parquet files matched pattern: {pattern}. "
f"Please check the dataset repo layout under {dataset_dir}."
)
return files
raw_dataset = load_dataset(
"parquet",
data_files={
"train": _parquet_files_for("train"),
"validation": _parquet_files_for("validation"),
"test": _parquet_files_for("test"),
},
)这样做虽然更底层一点,但工程上更可控,出了问题也更容易定位。
3. 显式把 label 还原为 ClassLabel
从 parquet 加载数据后,label 往往会退化成普通整数列。Notebook 里额外做了这一步:
for split_name in list(raw_dataset.keys()):
if not isinstance(raw_dataset[split_name].features.get("label"), ClassLabel):
raw_dataset[split_name] = raw_dataset[split_name].cast_column(
"label", ClassLabel(names=EMOTION_LABEL_NAMES)
)之后就可以继续使用:
label_names = dataset["train"].features["label"].names
VALID_LABELS = set(label_names)
ALL_EVAL_LABELS = label_names + ["INVALID"]来直接获取标签名,尽量让后续 prompt 构造、评估逻辑、混淆矩阵生成都保持统一接口。
五、把分类任务改造成聊天微调任务
Gemma 4 E4B-it 是 instruction-tuned 模型,因此最自然的方式不是把它当纯分类器硬喂,而是把任务包装成一轮对话。
Notebook 里的 system prompt 很克制:
SYSTEM_PROMPT = """You are an emotion classification assistant.
Read the user's text and answer with exactly one label.
Only choose from: sadness, joy, love, anger, fear, surprise.
Return only the label and nothing else."""这个 prompt 的重点不在华丽,而在约束足够强:
- 只做情绪分类。
- 只从 6 个标签中选择。
- 只返回标签,不输出解释。
对应的数据转换逻辑是:
def to_prompt_completion(example):
text = example["text"]
label = label_names[example["label"]]
user_content = f"Classify the emotion of this text:\n\n{text}"
return {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"completion": [
{"role": "assistant", "content": label},
],
}
sft_dataset = dataset.map(
to_prompt_completion,
remove_columns=dataset["train"].column_names,
)这里把普通分类样本改造成了聊天模型适合的 prompt + completion 结构。对于情绪分类这种标准化任务,这种设计通常比"让模型自由发挥解释原因"更稳定。
六、tokenizer、chat template 与基础模型加载
从魔搭下载后的本地路径加载 tokenizer:
tokenizer = AutoTokenizer.from_pretrained(
LOCAL_MODEL_DIR,
use_fast=True,
trust_remote_code=True,
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token这份 Notebook 的一个亮点,是它考虑到了 chat_template 缺失的情况。Gemma 这类 instruction-tuned 模型对消息模板很敏感,如果 tokenizer 内部没有正确的模板,推理和训练格式都会出问题。
所以额外写了一个逻辑,从同一个 ModelScope 仓库读取官方 chat_template.jinja:
TEMPLATE_SOURCE_MODEL_ID = "google/gemma-4-E4B-it"
def _load_official_gemma_chat_template() -> str:
try:
template_dir = snapshot_download(
TEMPLATE_SOURCE_MODEL_ID,
cache_dir="./models",
allow_file_pattern=["chat_template.jinja"],
)
path = os.path.join(template_dir, "chat_template.jinja")
if os.path.exists(path):
with open(path, "r", encoding="utf-8") as f:
return f.read()
except Exception as e:
print("snapshot_download(allow_file_pattern) failed, fallback to HTTP. err =", e)如果 tokenizer 本身没有模板,就手动注入:
if not getattr(tokenizer, "chat_template", None):
tokenizer.chat_template = _load_official_gemma_chat_template()并用一次 apply_chat_template() 做自检:
_probe = tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello"},
],
tokenize=False,
add_generation_prompt=True,
)基础模型的加载方式如下:
base_model = AutoModelForCausalLM.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=MODEL_DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
)
base_model.to(device)
base_model.config.use_cache = False
base_model.config.pad_token_id = tokenizer.pad_token_id
base_model.config.bos_token_id = tokenizer.bos_token_id
base_model.config.eos_token_id = tokenizer.eos_token_id
base_model.generation_config.pad_token_id = tokenizer.pad_token_id
base_model.generation_config.bos_token_id = tokenizer.bos_token_id
base_model.generation_config.eos_token_id = tokenizer.eos_token_id这些 token id 对齐步骤很重要,能减少推理阶段一些边界问题。
七、推理辅助函数与评估设计
微调前后都用同一套推理函数做评估,方便对比模型效果。
首先是标签提取函数:
LABEL_PATTERN = re.compile(r"\b(sadness|joy|love|anger|fear|surprise)\b", re.IGNORECASE)
def extract_label(raw_text: str) -> str:
raw_text = raw_text.strip().lower()
match = LABEL_PATTERN.search(raw_text)
if match:
return match.group(1)
tokens = raw_text.split()
if not tokens:
return "INVALID"
return tokens[0].strip(".,!?:;\"'()[]{}")这段逻辑的价值在于:即使模型没有完全按规范输出,也会尽量从结果中抽取合法标签;实在抽不出来,才判为 INVALID。
实际生成函数如下:
def generate_label(model, tokenizer, user_text: str, system_prompt: str = SYSTEM_PROMPT, max_new_tokens: int = 4) -> str:
user_content = f"Classify the emotion of this text:\n\n{user_text}"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content},
]
device = next(model.parameters()).device
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(device) for k, v in inputs.items()}
input_len = inputs["input_ids"].shape[-1]
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
raw_pred = tokenizer.decode(outputs[0][input_len:], skip_special_tokens=True).strip()
return extract_label(raw_pred)这里使用 do_sample=False,本质上是在把生成式模型尽量拉回分类任务的稳定范式。
评估函数则会输出:
accuracymacro_f1invalid_predictionsclassification_reportconfusion_matrix
核心实现如下:
def evaluate_model(model, tokenizer, split="test", limit=EVAL_LIMIT):
y_true, y_pred, rows = [], [], []
raw_source = dataset[split]
if limit is not None:
raw_source = raw_source.select(range(min(limit, len(raw_source))))
model.eval()
for ex in tqdm(raw_source, desc=f"Evaluating {split}", leave=False):
true_label = label_names[ex["label"]]
raw_pred_label = generate_label(model, tokenizer, ex["text"], SYSTEM_PROMPT)
pred_label = raw_pred_label if raw_pred_label in VALID_LABELS else "INVALID"
y_true.append(true_label)
y_pred.append(pred_label)
rows.append({
"text": ex["text"],
"true_label": true_label,
"pred_label": pred_label,
"raw_pred_label": raw_pred_label,
"correct": true_label == pred_label,
})
metrics = {
"accuracy": accuracy_score(y_true, y_pred),
"macro_f1": f1_score(y_true, y_pred, labels=label_names, average="macro", zero_division=0),
"invalid_predictions": sum(1 for p in y_pred if p == "INVALID"),
"evaluated_examples": len(y_true),
}其中 invalid_predictions 这个指标尤其值得保留。因为在生成式分类任务里,模型"有没有答对"和"有没有按格式答"其实是两个问题,而这份 Notebook 把它们拆开看了。
八、微调前评估:先做基线,再谈提升
这份 Notebook 没有一上来就训练,而是先评估基础模型:
pre_metrics, pre_report, pre_preds = evaluate_model(base_model, tokenizer, split="test", limit=EVAL_LIMIT)这一步非常必要。很多教程训练完就说"效果不错",但没有基线就没有对比,也很难说明 LoRA 到底带来了多少收益。保留微调前评估,后面做结果表格、错误分析和参数对比时都会轻松很多。
九、LoRA 配置与训练参数
LoRA 配置如下:
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)这里 target_modules="all-linear" 是一种先跑通的务实策略,优先保证大部分线性层都能挂上 LoRA。如果你后续要进一步控制显存和训练成本,可以改成更细粒度的模块名。"q_proj", "v_proj"等等
训练参数则是:
training_args = SFTConfig(
output_dir=OUTPUT_DIR,
per_device_train_batch_size=4,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=1e-4,
weight_decay=0.01,
lr_scheduler_type="linear",
warmup_steps=50,
num_train_epochs=1,
logging_steps=5,
eval_strategy="steps",
eval_steps=25,
save_strategy="steps",
save_steps=25,
save_total_limit=2,
metric_for_best_model="eval_loss",
greater_is_better=False,
gradient_checkpointing=True,
bf16=BF16,
fp16=FP16,
tf32=False,
max_length=256,
packing=False,
completion_only_loss=True,
remove_unused_columns=False,
dataloader_num_workers=2,
optim="adamw_torch",
report_to="none",
seed=SEED,
data_seed=SEED,
)几个参数可以重点理解:
per_device_train_batch_size=4配合gradient_accumulation_steps=4,等效 batch size 为 16。gradient_checkpointing=True能明显缓解显存压力。max_length=256对短文本分类一般足够。completion_only_loss=True很适合这种"提示词固定、答案极短"的任务。optim="adamw_torch"避开了 ROCm 环境下一些优化器兼容问题。
如果显存不够,优先调整:
TRAIN_LIMIT = 1000
EVAL_LIMIT = 50
per_device_train_batch_size = 1
max_length = 128十、开始训练前,先检查 LoRA 是否真的挂上了
这里会创建 SFTTrainer:
trainer = SFTTrainer(
model=base_model,
train_dataset=sft_dataset["train"],
eval_dataset=sft_dataset["validation"],
peft_config=lora_config,
args=training_args,
processing_class=tokenizer,
)但 Notebook 没有直接 trainer.train(),而是先做了一层检查:
trainable_params = 0
total_params = 0
trainable_param_names = []
for name, param in trainer.model.named_parameters():
total_params += param.numel()
if param.requires_grad:
trainable_params += param.numel()
trainable_param_names.append(name)
if trainable_params == 0:
raise RuntimeError("No trainable LoRA parameters were attached. Check target_modules before training.")这是一个很好的工程防呆设计。因为不少人以为自己在做 LoRA,实际上配置没匹配到任何层,最后等于白跑。
确认无误后再开始训练:
train_result = trainer.train()
trainer.model.eval()
trainer.model.config.use_cache = True十一、保存 adapter 与微调后评估
训练完成后保存的是 LoRA adapter,不是完整大模型权重:
python
trainer.model.save_pretrained(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
with open(os.path.join(OUTPUT_DIR, "train_metrics.json"), "w", encoding="utf-8") as f:
json.dump(train_result.metrics, f, ensure_ascii=False, indent=2)接着直接复用内存中的模型做评估,避免重新加载造成额外显存压力:
ft_model = trainer.model
ft_model.eval()
ft_model.config.use_cache = True
post_metrics, post_report, post_preds = evaluate_model(ft_model, tokenizer, split="test", limit=EVAL_LIMIT)这里把微调前后的核心指标合并成一个表:
comparison_df = pd.DataFrame([
{"stage": "pre_finetuning", **pre_metrics},
{"stage": "post_finetuning", **post_metrics},
])
这个表就是后面写实验结论时最核心的内容。
十二、手动测试与结果落盘
除了自动评估,这份 Notebook 还准备了一组人工样例:
test_texts = [
"I feel completely heartbroken and alone.",
"This is the best day of my life!",
"I am really scared about what might happen tomorrow.",
"I can't believe they remembered my birthday!",
"I am so angry that nobody listened to me.",
"I really love spending time with my family.",
]
for text in test_texts:
print(text, "=>", predict_emotion_ft(text))这部分虽然不是严格评测,但很适合直观展示"模型已经能稳定输出合法标签"。
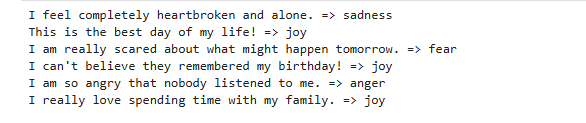
最后,Notebook 会把多个评估结果统一保存到 OUTPUT_DIR:
comparison_df.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_before_after_metrics.csv"), index=False)
merged_examples.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_prediction_examples.csv"), index=False)
changed_predictions.to_csv(os.path.join(OUTPUT_DIR, "gemma4_emotion_changed_predictions.csv"), index=False)
pre_preds.to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_predictions.csv"), index=False)
post_preds.to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_predictions.csv"), index=False)
pd.DataFrame(pre_report).transpose().to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_classification_report.csv"))
pd.DataFrame(post_report).transpose().to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_classification_report.csv"))
confusion_matrix_df(pre_preds).to_csv(os.path.join(OUTPUT_DIR, "pre_finetuning_confusion_matrix.csv"))
confusion_matrix_df(post_preds).to_csv(os.path.join(OUTPUT_DIR, "post_finetuning_confusion_matrix.csv"))这一步很重要,因为真正有价值的训练,不只是保存权重,而是把结果证据也一并保留下来,方便后续画图、分析和复现实验。
十三、这份方案适合哪些人直接复用
如果你符合下面几种情况,这份 Notebook 基本可以直接作为模板:
- 你想在国内环境下跑 Gemma 微调,不想处理 Hugging Face 登录问题。
- 你只有单卡设备,先想快速验证流程。
- 你做的是短文本分类,但希望沿用聊天模型微调范式。
- 你希望代码除了能训练,还能输出评估结论。
尤其是第三点。现在很多分类任务都在尝试直接迁移到 instruction-tuned LLM 上,这份实现给出了一个比较稳的最小闭环。
十四、几个最值得带走的工程经验
读完整份 Notebook,我觉得有 6 个经验最值得朋友们学习:
- 能从本地加载的资源,就尽量不要把训练过程绑死在在线服务上。
- 数据集兼容性出问题时,直接回到 parquet 这类底层格式,往往比继续绕高层接口更高效。
- 分类任务做生成式微调时,提示词约束要足够严格。
- 微调前评估一定要保留,否则训练效果没有基线。
- LoRA 训练前要显式检查可训练参数是否真的挂载成功。
- 结果文件一定要结构化保存,否则后续分析几乎都会返工。
十五、实战的边界与后续优化方向
当然,这份 Notebook 也不是没有边界:
- 默认
TRAIN_LIMIT=4000、EVAL_LIMIT=400,更偏向"先跑通"而不是"追求最优指标"。 num_train_epochs=1较为保守,适合快速实验,不一定是最佳收敛点。target_modules="all-linear"虽然省事,但未必是最优 LoRA 注入策略。
如果后续要继续优化,可以优先尝试这些方向:
- 把
TRAIN_LIMIT放开,使用更多训练样本。 - 对比
r=8/16/32、lora_alpha=16/32/64的效果差异。 - 把
num_train_epochs提高到2或3,观察macro_f1变化。 - 基于导出的预测 CSV 做更细的错误案例分析。