目录
[四 结合反向代理实现 tomcat 部署](#四 结合反向代理实现 tomcat 部署)
[4.1 常见部署方式介绍](#4.1 常见部署方式介绍)
[企业级生产应用(Enterprise Scenario)](#企业级生产应用(Enterprise Scenario))
[4.2 利用 nginx 反向代理实现](#4.2 利用 nginx 反向代理实现)
[代码逐行解析(Line-by-Line Breakdown)](#代码逐行解析(Line-by-Line Breakdown))
[4.3 实现 tomcat 中的负载均衡](#4.3 实现 tomcat 中的负载均衡)
[4.3.1 HTTP 的无状态,有连接和短连接](#4.3.1 HTTP 的无状态,有连接和短连接)
[4.3.2 tomcat 负载均衡实现](#4.3.2 tomcat 负载均衡实现)
[代码逐行解析(Line-by-Line Breakdown)](#代码逐行解析(Line-by-Line Breakdown))
[五 Memcached](#五 Memcached)
[5.1 Memcached 简介](#5.1 Memcached 简介)
[5.2 memcached 的安装与启动](#5.2 memcached 的安装与启动)
[代码逐行解析(Line-by-Line Breakdown)](#代码逐行解析(Line-by-Line Breakdown))
[5.3 memcached 操作命令](#5.3 memcached 操作命令)
[命令逐行解析(Line-by-Line Breakdown)](#命令逐行解析(Line-by-Line Breakdown))
[六 session 共享服务器](#六 session 共享服务器)
[6.1 msm 介绍](#6.1 msm 介绍)
[6.2 安装](#6.2 安装)
[6.3 配置过程](#6.3 配置过程)
[代码逐行解析(Line-by-Line Breakdown)](#代码逐行解析(Line-by-Line Breakdown))
[Tomcat context.xml 配置解析](#Tomcat context.xml 配置解析)
[Nginx 配置解析](#Nginx 配置解析)
四 结合反向代理实现 tomcat 部署
4.1 常见部署方式介绍
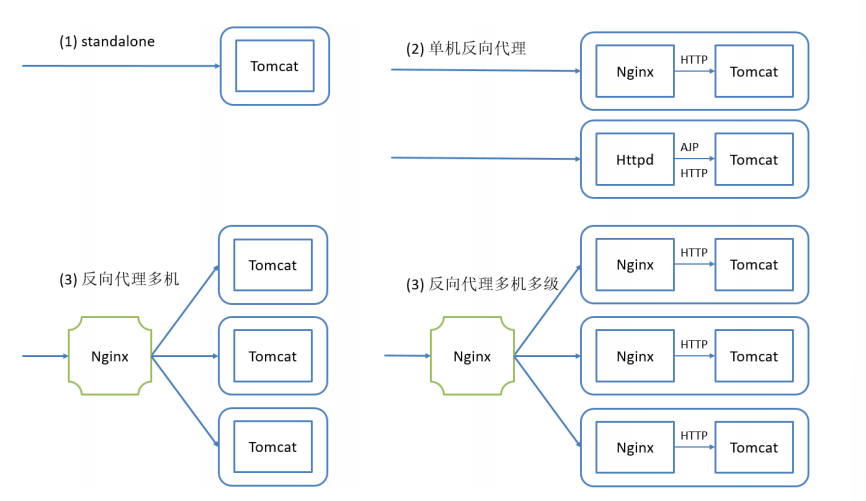
(1) standalone Tomcat (2) 单机反向代理 Nginx HTTP Tomcat Httpd AJP HTTP Tomcat (3) 反向代理多机 Tomcat (3) 反向代理多机多级 Nginx HTTP Tomcat Nginx Tomcat Nginx Nginx HTTP Tomcat Tomcat Nginx HTTP Tomcat
standalone 模式,Tomcat 单独运行,直接接受用户的请求,不推荐。
反向代理,单机运行,提供了一个 Nginx 作为反向代理,可以做到静态由 nginx 提供响应,动态 jsp 代 理给 Tomcat
- LNMT:Linux + Nginx + MySQL + Tomcat
- LAMT:Linux + Apache (Httpd)+ MySQL + Tomcat
前置一台 Nginx, 给多台 Tomcat 实例做反向代理和负载均衡调度,Tomcat 上部署的纯动态页面更 适合
- LNMT:Linux + Nginx + MySQL + Tomcat
多级代理
- LNNMT:Linux + Nginx + Nginx + MySQL + Tomcat
图片备注:此处插入 Tomcat 四种部署架构对比图,从左到右依次为:standalone 单机、Nginx + 单 Tomcat 反向代理、Nginx + 多 Tomcat 负载均衡、Nginx 多级代理集群
板块核心解释
- standalone 模式的致命缺陷:Tomcat 原生处理静态资源的性能仅为 Nginx 的 1/10,且直接暴露 8080 端口存在安全风险,无法实现 SSL 卸载、流量控制等高级功能,生产环境绝对禁止使用。
- 反向代理的核心价值 :实现动静分离------ 静态资源(HTML/CSS/JS/ 图片)由 Nginx 直接返回,动态请求(JSP/Servlet)转发给 Tomcat,充分发挥 Nginx 高并发静态处理能力和 Tomcat 业务逻辑处理能力。
- 多级代理的适用场景:大型互联网公司的边缘节点 + 核心节点架构,边缘 Nginx 负责就近接入和静态缓存,核心 Nginx 负责负载均衡和流量调度,提升系统的整体可用性和响应速度。
生活类比
反向代理就像医院的导诊台:患者(用户请求)进门后不用直接找医生(Tomcat),导诊台(Nginx)先判断患者是需要拿体检报告(静态资源)还是看病(动态请求)。拿报告的直接在导诊台旁边的自助机(Nginx)领取,看病的由导诊台分配到对应的科室(Tomcat),避免所有患者都挤到医生办公室。
坑点(Gotchas)
- AJP 协议弃用风险:Apache Httpd 的 AJP 协议存在多个高危漏洞(如 CVE-2020-1938),且性能不如 HTTP 协议,生产环境应全部使用 HTTP 反向代理,禁用 AJP 连接器。
- 多级代理的 X-Forwarded-For 丢失 :多级代理时如果未配置
proxy_set_header X-Forwarded-For $remote_addr;,后端 Tomcat 无法获取真实的客户端 IP,只能获取到上一级代理的 IP。
企业级生产应用(Enterprise Scenario)
- 千万级并发场景:采用「CDN + 边缘 Nginx + 核心 Nginx 集群 + Tomcat 集群」架构,CDN 缓存所有静态资源,边缘 Nginx 负责 SSL 卸载和静态缓存,核心 Nginx 负责负载均衡和流量控制,Tomcat 集群只处理纯动态请求。
- 进阶优化 :
- 开启 Nginx 的长连接配置
keepalive 1024;,减少 Nginx 与 Tomcat 之间的 TCP 连接建立和销毁开销。 - 配置 Nginx 的缓存
proxy_cache,缓存热点动态页面,减少 Tomcat 的压力。 - 使用 Nginx 的限流模块
limit_req_zone,防止恶意请求打垮 Tomcat 集群。
- 开启 Nginx 的长连接配置
课后防宕机指南(Troubleshooting)
- 错误现象 :访问静态资源正常,访问 JSP 页面报 404 错误
- 排查思路:检查 Nginx 的 location 正则是否正确匹配.jsp 后缀;检查
proxy_pass地址是否正确;检查 Tomcat 是否部署了对应的应用;检查 Tomcat 的日志是否有异常。
- 排查思路:检查 Nginx 的 location 正则是否正确匹配.jsp 后缀;检查
- 错误现象 :后端 Tomcat 获取的客户端 IP 都是 Nginx 的 IP
- 排查思路:检查 Nginx 是否配置了
proxy_set_header X-Forwarded-For $remote_addr;;检查 Tomcat 的server.xml是否配置了RemoteIpValve来解析 X-Forwarded-For 头。
- 排查思路:检查 Nginx 是否配置了
4.2 利用 nginx 反向代理实现
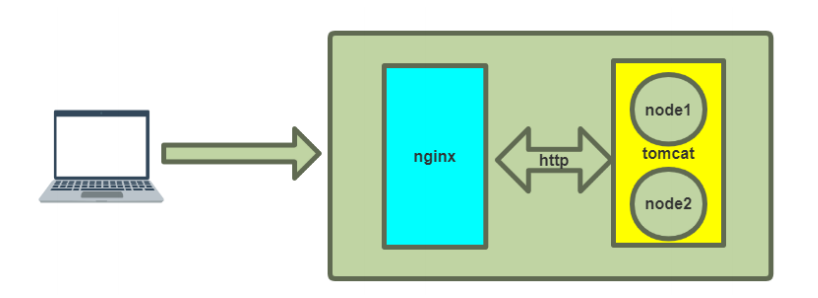
图片备注:此处插入单机 Nginx 反向代理单 Tomcat 拓扑图,左侧为客户端,中间为 Nginx 服务器(node1),右侧为 Tomcat 服务器(node2)
利用 nginx 反向代理功能,实现图中的代理功能,将用户请求全部转发至指定的同一个 tomcat 主机 利用 nginx 指令 proxy_pass 可以向后端服务器转发请求报文,并且在转发时会保留客户端的请求报文中的 host 首部
bash
[root@Nginx ~]# vim /usr/local/nginx/conf.d/vhosts.conf
location ~ \.jsp$ {
proxy_pass http://172.25.254.10:8080;
}测试:
在浏览器中访问信息 lee.timinglee.org/test.jsp
代码逐行解析(Line-by-Line Breakdown)
| 代码行 | 底层触发动作 | 作用 |
|---|---|---|
location ~ \.jsp$ { |
Nginx 启动时预编译正则表达式,当接收到客户端请求时,将请求 URI 与正则表达式进行匹配;~表示区分大小写的正则匹配,\.jsp$表示匹配以.jsp 结尾的 URI |
拦截所有动态 JSP 请求,将其转发给后端 Tomcat 处理 |
proxy_pass http://172.25.254.10:8080; |
Nginx 与后端 Tomcat 建立 TCP 连接,将客户端的请求头(包括 Host、Cookie、User-Agent 等)和请求体完整转发给 Tomcat;接收 Tomcat 返回的响应头和响应体,再转发给客户端 | 将匹配到的 JSP 请求转发到指定的 Tomcat 服务器 |
} |
结束 location 块 | - |
坑点(Gotchas)
- proxy_pass 斜杠陷阱 :如果写成
proxy_pass http://172.25.254.10:8080/;(末尾加斜杠),Nginx 会将请求 URI 中的匹配部分替换为斜杠,导致路径错误。例如请求/test.jsp会被转发为http://172.25.254.10:8080/,而不是http://172.25.254.10:8080/test.jsp。 - 正则匹配优先级问题 :Nginx 的 location 匹配优先级为:精确匹配
=> 前缀匹配^~> 正则匹配~/~*> 普通前缀匹配。如果有其他 location 块的优先级更高,会导致.jsp 请求无法被当前 location 匹配。
企业级生产应用
- 千万级并发场景:生产环境不会直接写死 Tomcat 的 IP 地址,而是使用 upstream 块定义后端服务器组,即使 Tomcat 地址发生变化,也只需要修改 upstream 块,无需修改所有 location 块。
- 进阶优化 :
- 添加
proxy_set_header Host $host;,确保 Tomcat 能获取到正确的 Host 头,避免虚拟主机配置失效。 - 添加
proxy_set_header X-Real-IP $remote_addr;和proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;,让 Tomcat 获取到真实的客户端 IP。 - 配置
proxy_connect_timeout 60s;、proxy_read_timeout 60s;、proxy_send_timeout 60s;,防止慢请求占用连接资源。
- 添加
课后防宕机指南(Troubleshooting)
- 错误现象 :访问 JSP 页面报 502 Bad Gateway 错误
- 排查思路:检查 Tomcat 是否启动;检查 Tomcat 的 8080 端口是否监听;检查 Nginx 服务器能否 ping 通 Tomcat 服务器;检查防火墙是否开放 8080 端口;检查 SELinux 是否阻止 Nginx 转发请求。
- 错误现象 :访问 JSP 页面报 504 Gateway Time-out 错误
- 排查思路:检查 Tomcat 是否处理请求过慢(查看 Tomcat 日志);检查 Nginx 的 proxy_read_timeout 配置是否过短;检查网络是否存在丢包或延迟过高的问题。
4.3 实现 tomcat 中的负载均衡
动态服务器的问题,往往就是并发能力太弱,往往需要多台动态服务器一起提供服务。如何把并发的压 力分摊,这就需要调度,采用一定的调度策略,将请求分发给不同的服务器,这就是 Load Balance 负载 均衡。
当单机 Tomcat, 演化出多机多级部署的时候,一个问题便凸显出来,这就是 Session。而这个问题的由 来,都是由于 HTTP 协议在设计之初没有想到未来的发展。
4.3.1 HTTP 的无状态,有连接和短连接
**无状态:**指的是服务器端无法知道 2 次请求之间的联系,即使是前后 2 次请求来自同一个浏览器,也 没有任何数据能够判断出是同一个浏览器的请求。后来可以通过 cookie、session 机制来判断。
- 浏览器端第一次 HTTP 请求服务器端时,在服务器端使用 session 这种技术,就可以在服务器端 产生一个随机值即 SessionID 发给浏览器端,浏览器端收到后会保持这个 SessionID 在 Cookie 当 中,这个 Cookie 值一般不能持久存储,浏览器关闭就消失。浏览器在每一次提交 HTTP 请求的 时候会把这个 SessionID 传给服务器端,服务器端就可以通过比对知道是谁了
- Session 通常会保存在服务器端内存中,如果没有持久化,则易丢失
- Session 会定时过期。过期后浏览器如果再访问,服务端发现没有此 ID, 将给浏览器端重新发 新的 SessionID
- 更换浏览器也将重新获得新的 SessionID
**有连接:**是因为它基于 TCP 协议,是面向连接的,需要 3 次握手、4 次断开。
**短连接:**Http 1.1 之前,都是一个请求一个连接,而 Tcp 的连接创建销毁成本高,对服务器有很大的 影响。所以,自 Http 1.1 开始,支持 keep-alive, 默认也开启,一个连接打开后,会保持一段时间 (可设置), 浏览器再访问该服务器就使用这个 Tcp 连接,减轻了服务器压力,提高了效率。
服务器端如果故障,即使 Session 被持久化了,但是服务没有恢复前都不能使用这些 SessionID。
如果使用 HAProxy 或者 Nginx 等做负载均衡器,调度到了不同的 Tomcat 上,那么也会出现找不到 SessionID 的情况。
板块核心解释
- HTTP 无状态的本质:HTTP 协议本身不保存客户端的状态信息,每个请求都是独立的,服务器无法区分两个请求是否来自同一个客户端。这是 HTTP 协议设计的优点(简单、可扩展),但也是缺点(无法跟踪用户状态)。
- Session 的工作原理:服务器为每个客户端创建一个唯一的 SessionID,通过 Cookie 发送给客户端,客户端后续请求都会携带这个 SessionID,服务器根据 SessionID 找到对应的 Session 对象,从而识别用户身份。
- 负载均衡下的 Session 问题:如果用户的第一次请求被调度到 Tomcat1,Session 保存在 Tomcat1 的内存中;第二次请求被调度到 Tomcat2,Tomcat2 的内存中没有这个 SessionID,就会认为用户未登录,导致用户状态丢失。
生活类比
HTTP 无状态就像一个没有记忆的收银员 :每次你去结账,他都不记得你是谁,也不记得你之前买过什么。Session 就像收银员给你发了一张会员卡,上面有唯一的卡号(SessionID),你每次结账都出示这张卡,收银员就能从系统里查到你的会员信息(Session 对象)。如果有两个收银员(Tomcat 集群),而会员卡信息只存在第一个收银员的电脑里,你去第二个收银员那里结账,他就查不到你的会员信息了。
坑点(Gotchas)
- Session 超时配置错误:Tomcat 默认 Session 超时时间为 30 分钟,如果设置过短,用户会频繁被要求重新登录;如果设置过长,会占用大量服务器内存,导致内存溢出。
- Cookie 禁用导致 Session 失效:如果用户浏览器禁用了 Cookie,SessionID 无法通过 Cookie 传递,需要使用 URL 重写的方式传递 SessionID,但这种方式存在安全风险,且不利于 SEO。
企业级生产应用
- 千万级并发场景:生产环境不会依赖服务器内存存储 Session,而是使用分布式 Session 方案(如 Memcached、Redis),将 Session 统一存储在外部缓存中,所有 Tomcat 实例都可以访问,彻底解决负载均衡下的 Session 丢失问题。
- 进阶优化 :
- 开启 Session 的持久化,避免 Tomcat 重启导致 Session 丢失。
- 配置 Session 的过期时间为 15-30 分钟,平衡用户体验和服务器内存占用。
- 使用 JWT(JSON Web Token)替代 Session,实现无状态认证,彻底解决分布式 Session 问题。
课后防宕机指南(Troubleshooting)
- 错误现象 :用户登录后刷新页面就退出登录
- 排查思路:检查负载均衡算法是否为轮询,导致请求被调度到不同的 Tomcat;检查是否配置了分布式 Session;检查 Tomcat 的 Session 超时时间是否过短;检查 Cookie 的 Domain 和 Path 配置是否正确。
- 错误现象 :部分用户出现 Session 丢失,其他用户正常
- 排查思路:检查用户是否禁用了 Cookie;检查负载均衡器是否开启了会话保持;检查分布式缓存是否正常运行;检查 Tomcat 之间的时间是否同步。
4.3.2 tomcat 负载均衡实现
bash
[root@Nginx ~]# vim /usr/local/nginx/conf.d/vhosts.conf
upstream tomcat {
#ip_bash;
#hash $cookie_JSESSIONID;
server 172.25.254.10:8080;
server 172.25.254.20:8080;
}
server {
listen 80;
server_name lee.timinglee.org;
root /webdataw/nginx/timinglee.org/lee;
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
try_files $uri $uri.html $uri/index.html /error/default.html;
location ~ \.jsp$ {
proxy_pass http://tomcat;
}
}测试:
当使用 ip_bash 的算法时有什么问题?
不同浏览器里测试http://lee.timinglee.org/test.jsp
代码逐行解析(Line-by-Line Breakdown)
| 代码行 | 底层触发动作 | 作用 |
|---|---|---|
upstream tomcat { |
定义一个名为 tomcat 的后端服务器组,Nginx 启动时初始化该组的服务器列表和负载均衡算法 | 集中管理所有后端 Tomcat 服务器,方便统一配置和维护 |
#ip_bash; |
注释掉 ip_hash 算法,Nginx 默认使用轮询(round-robin)算法 | 轮询算法将请求依次分发到每个后端服务器,适用于所有服务器性能相同的场景 |
#hash $cookie_JSESSIONID; |
注释掉基于 JSESSIONID Cookie 的哈希算法 | 哈希算法根据指定的键计算哈希值,将同一个键的请求始终分发到同一个后端服务器,实现会话保持 |
server 172.25.254.10:8080; |
将 IP 为 172.25.254.10、端口为 8080 的 Tomcat 服务器添加到服务器组 | 定义后端 Tomcat 节点 |
server 172.25.254.20:8080; |
将 IP 为 172.25.254.20、端口为 8080 的 Tomcat 服务器添加到服务器组 | 定义第二个后端 Tomcat 节点 |
} |
结束 upstream 块 | - |
server { |
定义一个虚拟主机 | 配置域名lee.timinglee.org的访问规则 |
listen 80; |
监听 80 端口的 HTTP 请求 | - |
server_name lee.timinglee.org; |
匹配 Host 头为lee.timinglee.org的请求 | - |
root /webdataw/nginx/timinglee.org/lee; |
设置虚拟主机的根目录,静态资源从该目录下查找 | - |
access_log /var/log/nginx/access.log; |
开启访问日志,将所有请求记录到指定文件 | 用于统计访问量和排查问题 |
error_log /var/log/nginx/error.log; |
开启错误日志,将所有错误信息记录到指定文件 | 用于排查 Nginx 的运行错误 |
try_files $uri $uri.html $uri/index.html /error/default.html; |
按顺序查找文件:先查找\(uri对应的文件,再查找\)uri.html,再查找 $uri/index.html,如果都找不到,返回 /error/default.html | 实现静态资源的优雅降级和错误页面跳转 |
location ~ \.jsp$ { |
匹配所有以.jsp 结尾的请求 | - |
proxy_pass http://tomcat; |
将匹配到的请求转发到名为 tomcat 的后端服务器组,Nginx 根据负载均衡算法选择一个后端服务器 | 实现动态请求的负载均衡 |
} |
结束 location 块 | - |
} |
结束 server 块 | - |
坑点(Gotchas)
- ip_hash 算法的缺陷:ip_hash 算法根据客户端 IP 的前三个字节计算哈希值,会导致同一个局域网内的所有用户都被调度到同一个 Tomcat 服务器,如果该局域网用户量很大,会导致负载不均。此外,如果客户端使用代理服务器,会导致多个用户共享同一个 IP,同样会出现负载不均的问题。
- upstream 中 server 的权重配置错误 :如果后端服务器性能不同,需要配置权重
weight,例如server 172.25.254.10:8080 weight=2;表示该服务器接收的请求数是权重为 1 的服务器的 2 倍。如果权重配置不合理,会导致性能好的服务器空闲,性能差的服务器过载。 - server 行末尾忘记加分号 :这是 Nginx 配置最常见的语法错误,会导致 Nginx 启动失败,提示
invalid number of arguments in "server" directive。
企业级生产应用
- 千万级并发场景 :生产环境会使用
least_conn(最少连接)算法替代轮询算法,将请求分发到当前连接数最少的后端服务器,避免某台服务器过载;同时配置健康检查max_fails=3 fail_timeout=30s,自动剔除故障节点,实现高可用。 - 进阶优化 :
- 配置
backup服务器,当所有主服务器都故障时,使用备份服务器提供服务,例如server 172.25.254.30:8080 backup;。 - 开启 Nginx 的被动健康检查,当某台服务器连续 3 次请求失败后,将其标记为不可用,30 秒后再尝试重新连接。
- 使用 Nginx Plus 的主动健康检查功能,定期向后端服务器发送健康检查请求,提前发现故障节点。
- 配置
课后防宕机指南(Troubleshooting)
- 错误现象 :Nginx 启动失败,提示
invalid host in upstream "tomcat"- 排查思路:检查 upstream 块中的 server 地址是否正确;检查 server 行末尾是否加分号;检查 upstream 块的名称是否与 proxy_pass 中的名称一致(区分大小写)。
- 错误现象 :负载不均,某台 Tomcat 服务器的请求数远多于其他服务器
- 排查思路:检查负载均衡算法是否为 ip_hash;检查是否配置了权重;检查是否有长连接配置导致连接数不均;检查后端服务器的性能是否存在差异。
五 Memcached
5.1 Memcached 简介

M
REMCACHED图片备注:此处插入 Memcached 官方 Logo 图
Memcached 只支持能序列化的数据类型,不支持持久化,基于 Key-Value 的内存缓存系统 memcached 虽然没有像 redis 所具备的数据持久化功能,比如 RDB 和 AOF 都没有,但是可以通过做集群同步的方式, 让各 memcached 服务器的数据进行同步,从而实现数据的一致性,即保证各 memcached 的数据是一样 的,即使有任何一台 memcached 发生故障,只要集群中有一台 memcached 可用就不会出现数据丢 失,当其他 memcached 重新加入到集群的时候,可以自动从有数据的 memcached 当中自动获取数据并 提供服务。
Memcached 借助了操作系统的 libevent 工具做高效的读写。libevent 是个程序库,它将 Linux 的 epoll、 BSD 类操作系统的 kqueue 等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥高 性能。memcached 使用这个 libevent 库,因此能在 Linux、BSD、Solaris 等操作系统上发挥其高性能
Memcached 支持最大的内存存储对象为 1M, 超过 1M 的数据可以使用客户端压缩或拆分报包放到多个 key 中,比较大的数据在进行读取的时候需要消耗的时间比较长,memcached 最适合保存用户的 session 实现 session 共享
Memcached 存储数据时,Memcached 会去申请 1MB 的内存,把该块内存称为一个 slab, 也称为一个 page
Memcached 支持多种开发语言,包括:JAVA,C,Python,PHP,C#,Ruby,Perl 等
Memcached 官网:http://memcached.org/
板块核心解释
- Memcached 的核心特性:纯内存、键值对、高性能、分布式、无持久化。所有数据都存储在内存中,读写速度极快(微秒级),但服务器重启后数据会全部丢失。
- Slab 内存分配机制:Memcached 将内存划分为多个 1MB 的 Slab,每个 Slab 又划分为多个相同大小的 Chunk。存储数据时,选择最适合数据大小的 Chunk 进行存储,避免内存碎片。
- libevent 的作用:基于事件驱动的异步 I/O 模型,支持数十万并发连接,是 Memcached 高性能的关键。
生活类比
Memcached 就像超市的临时储物柜:你可以把东西(数据)存在储物柜里,得到一个唯一的取物码(Key),凭取物码可以快速取出东西。储物柜的空间有限(内存),如果储物柜满了,会自动清理最久没人用的柜子(LRU 淘汰算法)。超市关门(服务器重启)后,储物柜里的东西会被全部清空。
坑点(Gotchas)
- 1M 对象大小限制:Memcached 默认最大存储对象为 1MB,超过这个大小的数据无法存储,需要客户端进行拆分或压缩。虽然可以通过修改源码调整这个限制,但不推荐,会影响 Memcached 的性能。
- 无持久化导致的数据丢失:Memcached 没有数据持久化功能,服务器重启或故障会导致所有数据丢失,因此不能用于存储重要数据,只能用于缓存热点数据。
- 集群数据同步问题:原文中提到的 "集群同步" 是错误的,原生 Memcached 没有集群同步功能,也没有主从复制机制,它的分布式是通过客户端实现的(一致性哈希算法)。如果某台 Memcached 节点故障,该节点上的数据会全部丢失。
企业级生产应用
- 千万级并发场景:生产环境使用 Memcached 集群存储用户 Session 和热点数据,客户端使用一致性哈希算法将数据分布到多个 Memcached 节点上,实现水平扩展。同时配置双写机制,将数据同时写入 Memcached 和 Redis,避免 Memcached 节点故障导致的数据丢失。
- 进阶优化 :
- 根据业务数据的大小调整 Slab 的大小,提高内存利用率。
- 开启 Memcached 的压缩功能,减少网络传输和内存占用。
- 使用 mcstat 工具监控 Memcached 的运行状态,包括命中率、内存使用率、连接数等。
课后防宕机指南(Troubleshooting)
- 错误现象 :向 Memcached 写入数据失败,提示
SERVER_ERROR object too large for cache- 排查思路:检查数据大小是否超过 1MB;检查是否开启了客户端压缩;如果数据确实很大,考虑拆分数据存储或使用 Redis 替代。
- 错误现象 :Memcached 命中率过低(低于 90%)
- 排查思路:检查 Memcached 的内存是否足够,是否频繁发生 LRU 淘汰;检查缓存策略是否合理,是否缓存了不常访问的数据;检查一致性哈希算法的实现是否正确,是否存在数据倾斜。
5.2 memcached 的安装与启动
bash
[root@tomcat ~]# yum install memcached -y
[root@tomcat ~]# vim /etc/sysconfig/memcached
PORT="11211"
USER="memcached"
MAXCONN="1024"
CACHESIZE="64"
OPTIONS="-l 0.0.0.0,::1"
[root@tomcat ~]# systemctl enable --now memcached
[root@tomcat ~]# netstat -antlupe | grep memcache
tcp 0 0 0.0.0.0:11211 0.0.0.0:* LISTEN 980 97815 34711/memcached代码逐行解析(Line-by-Line Breakdown)
| 代码行 | 底层触发动作 | 作用 | |
|---|---|---|---|
yum install memcached -y |
yum 从官方仓库下载 Memcached RPM 包,自动解决依赖关系,安装到系统默认路径;创建 memcached 用户和组;生成默认配置文件/etc/sysconfig/memcached和 systemd 服务文件/usr/lib/systemd/system/memcached.service |
安装 Memcached 服务 | |
PORT="11211" |
设置 Memcached 监听的端口为 11211,这是 Memcached 的默认端口 | 定义 Memcached 的服务端口 | |
USER="memcached" |
设置 Memcached 服务运行的用户为 memcached,避免使用 root 用户运行,提升安全性 | 控制 Memcached 的运行权限 | |
MAXCONN="1024" |
设置 Memcached 的最大并发连接数为 1024 | 限制 Memcached 的连接数,防止连接数过多导致服务器过载 | |
CACHESIZE="64" |
设置 Memcached 使用的最大内存为 64MB | 限制 Memcached 的内存使用量,防止占用过多服务器内存 | |
OPTIONS="-l 0.0.0.0,::1" |
设置 Memcached 监听的地址为 0.0.0.0(所有 IPv4 地址)和::1(IPv6 本地回环地址) | 允许外部服务器访问 Memcached(默认只监听 127.0.0.1,只能本地访问) | |
systemctl enable --now memcached |
设置 Memcached 服务开机自启,并立即启动服务 | 启动 Memcached 服务并实现开机自启 | |
| `netstat -antlupe | grep memcache` | 查看系统中所有 TCP 和 UDP 连接,过滤出 memcached 进程监听的端口 | 验证 Memcached 是否成功启动并监听 11211 端口 |
坑点(Gotchas)
- 监听地址配置错误 :如果写成
OPTIONS="-l 127.0.0.1",Memcached 只会监听本地回环地址,外部服务器无法访问,导致 Tomcat 无法连接到 Memcached。 - 内存配置过小:默认 64MB 的内存对于生产环境来说太小,会导致频繁的 LRU 淘汰,命中率下降。生产环境应根据服务器配置和业务需求调整 CACHESIZE,一般为服务器内存的 50%-70%。
- 最大连接数配置过小:默认 1024 的最大连接数在高并发场景下会不够用,导致新连接被拒绝,生产环境应调整为 10240 或更高。
企业级生产应用
- 千万级并发场景:生产环境不会使用 yum 安装 Memcached,而是手动编译安装最新版本,开启大页内存支持,提升性能;同时配置多实例 Memcached,每个实例绑定不同的 CPU 核心,充分利用多核 CPU 的性能。
- 进阶优化 :
- 添加
-m 4096参数,将 Memcached 的内存设置为 4GB。 - 添加
-c 20480参数,将最大连接数设置为 20480。 - 添加
-t 8参数,启动 8 个工作线程,每个线程绑定一个 CPU 核心。 - 配置防火墙,只允许 Tomcat 服务器访问 11211 端口,防止未授权访问。
- 添加
课后防宕机指南(Troubleshooting)
- 错误现象 :Tomcat 无法连接到 Memcached,提示
Connection refused- 排查思路:检查 Memcached 是否启动;检查 Memcached 的监听地址是否为 0.0.0.0;检查防火墙是否开放 11211 端口;检查 SELinux 是否阻止 Memcached 绑定端口。
- 错误现象 :Memcached 运行一段时间后自动退出
- 排查思路:检查系统日志
/var/log/messages是否有 OOM(内存溢出)错误;检查 Memcached 的 CACHESIZE 配置是否过大,导致系统内存不足;检查是否有其他进程占用了大量内存。
- 排查思路:检查系统日志
5.3 memcached 操作命令
五种基本 memcached 命令执行最简单的操作。这些命令和操作包括:
- set
- add
- replace
- get
- delete
前三个命令是用于操作存储在 memcached 中的键值对的标准修改命令,都使用如下所示的语法: command <key> <flags> <bytes>
<value>
参数说明如下: command set/add/replace
key key 用于查找缓存值
flags 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息
expiration time 在缓存中保存键值对的时间长度 (以秒为单位,0 表示永远)
bytes 在缓存中存储的字节数
value 存储的值 (始终位于第二行)
#增加 key, 过期时间为秒,bytes 为存储数据的字节数
add key flags exptime bytes
示例:
bash
[root@tomcat ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
#增加
add leekey 0 60 4
test
STORED
add leekey1 0 60 3
lee
STORED
#查看
get leekey
VALUE leekey 0 4
test
END
get leekey1
VALUE leekey1 0 3
lee
END
#改
set leekey 0 60 5
test1
STORED
get leekey
VALUE leekey 0 5
test1
END
add leekey1 0 60 4
test
NOT_STORED
#删除
delete leekey
DELETED
get leekey
END
get leekey1
VALUE leekey1 0 3
lee
END
#清空
flush_all
OK
get leekey1
END命令逐行解析(Line-by-Line Breakdown)
| 命令 | 底层触发动作 | 作用 |
|---|---|---|
telnet localhost 11211 |
与本地 Memcached 服务器的 11211 端口建立 TCP 连接,进入 Memcached 的命令行交互界面 | 用于手动测试 Memcached 的基本操作 |
add leekey 0 60 4 |
向 Memcached 发送 add 命令,参数为:key=leekey,flags=0,expiration time=60 秒,bytes=4 字节。如果 key 不存在,则存储数据;如果 key 已存在,则返回 NOT_STORED | 添加一个新的键值对,仅当 key 不存在时成功 |
test |
输入要存储的值,长度为 4 字节("test" 正好 4 个字符) | 指定键对应的值 |
STORED |
Memcached 返回的成功响应,表示数据已成功存储 | - |
get leekey |
向 Memcached 发送 get 命令,查询 key=leekey 的值。如果 key 存在,则返回 VALUE 响应和对应的值;如果 key 不存在,则返回 END | 根据 key 查询对应的值 |
set leekey 0 60 5 |
向 Memcached 发送 set 命令,参数为:key=leekey,flags=0,expiration time=60 秒,bytes=5 字节。无论 key 是否存在,都会覆盖原有数据 | 设置一个键值对,key 存在则覆盖,不存在则添加 |
replace leekey 0 60 5 |
向 Memcached 发送 replace 命令,参数同上。只有当 key 存在时,才会替换原有数据;如果 key 不存在,则返回 NOT_STORED | 替换已存在的键值对 |
delete leekey |
向 Memcached 发送 delete 命令,删除 key=leekey 的键值对。如果 key 存在,则返回 DELETED;如果 key 不存在,则返回 NOT_FOUND | 删除指定的键值对 |
flush_all |
向 Memcached 发送 flush_all 命令,清空所有存储的数据。注意:该命令不会立即释放内存,只是将所有数据标记为过期,后续新数据会覆盖这些内存 | 清空 Memcached 中的所有数据 |
坑点(Gotchas)
- bytes 参数错误 :bytes 参数必须与第二行输入的值的字节数完全一致,否则会导致命令执行失败,提示
CLIENT_ERROR bad data chunk。例如,如果 bytes=4,但输入的值是 "test1"(5 个字节),就会报错。 - 过期时间单位混淆:expiration time 参数的单位是秒,最大值为 30 天(2592000 秒)。如果超过 30 天,Memcached 会将其视为 Unix 时间戳,表示数据在该时间点过期。如果设置为 0,表示数据永不过期,直到被 LRU 淘汰或手动删除。
- add 和 set 命令混淆:add 命令仅当 key 不存在时成功,set 命令无论 key 是否存在都会覆盖。如果使用 add 命令更新已存在的 key,会返回 NOT_STORED,导致数据更新失败。
企业级生产应用
- 千万级并发场景:生产环境不会使用 telnet 操作 Memcached,而是使用编程语言的客户端库(如 Java 的 spymemcached、Python 的 pymemcache)进行操作。同时会对 Memcached 的操作进行封装,添加重试机制、超时控制和异常处理,提高系统的稳定性。
- 进阶优化 :
- 使用批量操作命令(getMulti、setMulti)减少网络往返次数,提升性能。
- 合理设置过期时间,避免缓存雪崩(大量数据同时过期导致数据库压力骤增)。
- 使用缓存预热机制,在系统启动时将热点数据加载到 Memcached 中,提升用户体验。
课后防宕机指南(Troubleshooting)
- 错误现象 :执行 add 命令返回 NOT_STORED
- 排查思路:检查 key 是否已存在;检查 bytes 参数是否与值的字节数一致;检查 Memcached 是否已满,是否发生了 LRU 淘汰。
- 错误现象 :执行 get 命令返回 END,但数据确实应该存在
- 排查思路:检查数据是否已过期;检查是否执行了 flush_all 命令;检查 Memcached 节点是否故障,数据是否丢失;检查一致性哈希算法是否正确,是否查询了错误的节点。
六 session 共享服务器
6.1 msm 介绍
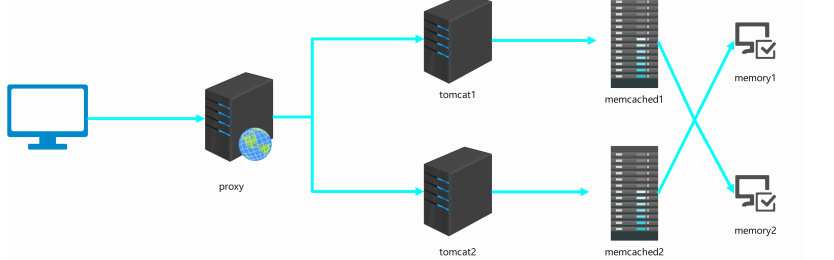
图片备注:此处插入 MSM Session 共享架构图,左侧为 Nginx 代理,中间为 Tomcat1 和 Tomcat2,右侧为 Memcached1 和 Memcached2,Tomcat1 的 Session 主备份在 Memcached2,Tomcat2 的 Session 主备份在 Memcached1
msm (memcached session manager) 提供将 Tomcat 的 session 保持到 memcached 可以实现高可用。 项目早期托管在 google code, 目前在 Github github
网站链接: https://github.com/magro/memcached-session-manager
支持 Tomcat 的 6.x、7.x、8.x、9.x
Tomcat 的 Session 管理类,Tomcat 版本不同
- memcached-session-manager-2.3.2.jar
- memcached-session-manager-tc9-2.3.2.jar
Session 数据的序列化、反序列化类
- 官方推荐 kyro
- 在 webapp 中 WEB-INF/lib/ 下
驱动类
- memcached (spymemcached.jar)
- Redis (jedis.jar)
板块核心解释
- MSM 的工作原理:MSM 是一个 Tomcat 的 Session 管理器插件,它替换了 Tomcat 默认的内存 Session 管理器。当 Tomcat 创建一个新的 Session 时,MSM 会将 Session 序列化后存储到 Memcached 中;当用户请求到来时,MSM 会从 Memcached 中读取 Session 并反序列化,提供给 Tomcat 使用。
- 主备备份机制:MSM 支持主备备份模式,每个 Tomcat 节点的 Session 会同时存储到两个 Memcached 节点中,一个作为主节点,一个作为备用节点。如果主 Memcached 节点故障,MSM 会自动切换到备用节点,保证 Session 不丢失。
- 序列化方式:MSM 支持多种序列化方式,包括 Java 原生序列化、Kryo、Jackson 等。官方推荐使用 Kryo 序列化,因为它的性能更高,序列化后的字节数更少。
生活类比
MSM 就像银行的异地备份系统:你在银行 A(Tomcat1)开了一个账户(Session),银行 A 会把你的账户信息同时备份到本地服务器(Tomcat1 内存)和异地银行 B 的服务器(Memcached2)。如果银行 A 的服务器故障了,你可以去银行 B(Tomcat2)办理业务,银行 B 会从异地备份服务器(Memcached2)获取你的账户信息,你不会感觉到任何差异。
坑点(Gotchas)
- 版本兼容性问题:MSM 的版本必须与 Tomcat 的版本严格对应,例如 memcached-session-manager-tc9-2.3.2.jar 只能用于 Tomcat 9.x,不能用于 Tomcat 8.x 或 10.x,否则会导致 Tomcat 启动失败。
- 序列化问题:Session 中存储的所有对象都必须实现 Serializable 接口(Java 原生序列化)或支持 Kryo 序列化,否则会导致序列化失败,Session 无法存储到 Memcached 中。
- Jar 包冲突:MSM 依赖的 Jar 包(如 spymemcached、kryo)如果与 web 应用中已有的 Jar 包版本不一致,会导致类加载冲突,出现 NoClassDefFoundError 或 ClassCastException 异常。
企业级生产应用
- 千万级并发场景:生产环境使用 MSM+Memcached 集群实现分布式 Session 共享,同时配置 Session 的过期时间和 Memcached 的内存大小,保证系统的性能和稳定性。对于高可用要求更高的场景,可以使用 Redis 替代 Memcached,利用 Redis 的主从复制和哨兵机制实现 Session 的高可用。
- 进阶优化 :
- 开启 MSM 的异步备份模式,将 Session 备份到 Memcached 的操作异步执行,减少请求响应时间。
- 配置 Session 的属性过滤,只序列化需要的属性,减少序列化后的字节数和网络传输开销。
- 使用连接池管理 Memcached 连接,提高连接的复用率和性能。
课后防宕机指南(Troubleshooting)
- 错误现象 :Tomcat 启动失败,日志提示
ClassNotFoundException: de.javakaffee.web.msm.MemcachedBackupSessionManager- 排查思路:检查 MSM 的 Jar 包是否放在 Tomcat 的 lib 目录下;检查 Jar 包版本是否与 Tomcat 版本对应;检查是否缺少依赖的 Jar 包。
- 错误现象 :Session 无法存储到 Memcached 中,日志提示
java.io.NotSerializableException- 排查思路:检查 Session 中存储的对象是否实现了 Serializable 接口;检查是否有对象的属性没有实现 Serializable 接口;如果使用 Kryo 序列化,检查是否注册了自定义的序列化器。
6.2 安装
参考链接: https://github.com/magro/memcached-session-manager/wiki/SetupAndConfiguration 将 spymemcached.jar、memcached-session-manage、kyro 相关的 jar 文件都放到 Tomcat 的 lib 目录 中,这个目录是 $CATALINA_HOME/lib/ , 对应本次安装就是 /usr/local/tomcat/lib。
kryo-3.0.3.jar
asm-5.2.jar objenesis-2.6.jar
reflectasm-1.11.9.jar
minlog-1.3.1.jar
kryo-serializers-0.45.jar
msm-kryo-serializer-2.3.2.jar
memcached-session-manager-tc9-2.3.2.jar
spymemcached-2.12.3.jar
memcached-session-manager-2.3.2.jar
t1 和 m1 部署可以在一台主机上,t2 和 m2 部署也可以在同一台。
当新用户发请求到 Tomcat1 时,Tomcat1 生成 session 返回给用户的同时,也会同时发给 memcached2 备 份。即 Tomcat1 session 为主 session,memcached2 session 为备用 session, 使用 memcached 相当于 备份了一份 Session
如果 Tomcat1 发现 memcached2 失败,无法备份 Session 到 memcached2, 则将 Sessoin 备份存放在 memcached1 中
板块核心解释
- Jar 包分类及作用 :
- 核心 MSM Jar 包:memcached-session-manager-2.3.2.jar(MSM 核心类库)、memcached-session-manager-tc9-2.3.2.jar(Tomcat 9 适配包)
- Memcached 客户端 Jar 包:spymemcached-2.12.3.jar(Memcached Java 客户端)
- Kryo 序列化相关 Jar 包:kryo-3.0.3.jar(Kryo 核心类库)、asm-5.2.jar(字节码操作库)、objenesis-2.6.jar(对象实例化库)、reflectasm-1.11.9.jar(反射优化库)、minlog-1.3.1.jar(日志库)、kryo-serializers-0.45.jar(Kryo 额外序列化器)、msm-kryo-serializer-2.3.2.jar(MSM Kryo 序列化适配包)
- 主备备份机制的优势:每个 Tomcat 节点的 Session 备份到不同的 Memcached 节点,避免单点故障。如果 Memcached2 故障,Tomcat1 会自动切换到 Memcached1 备份,保证 Session 的高可用。
坑点(Gotchas)
- Jar 包放置位置错误:所有 Jar 包必须放在 Tomcat 的全局 lib 目录($CATALINA_HOME/lib)下,不能放在 web 应用的 WEB-INF/lib 目录下,否则会导致类加载失败。
- Jar 包版本不匹配:Kryo 的版本必须与 msm-kryo-serializer 的版本对应,例如 msm-kryo-serializer-2.3.2.jar 需要搭配 kryo-3.0.3.jar 使用,不能使用更高或更低版本的 Kryo。
- 主备节点配置错误:如果 Tomcat1 和 Tomcat2 都将 Session 备份到同一个 Memcached 节点,当该节点故障时,所有 Session 都会丢失。
企业级生产应用
- 千万级并发场景:生产环境会将 Tomcat 和 Memcached 部署在不同的服务器上,避免资源竞争;同时部署至少 3 个 Memcached 节点,实现更高的可用性。使用自动化工具(如 Ansible、SaltStack)统一部署和管理所有 Jar 包和配置文件,避免人为错误。
- 进阶优化 :
- 使用 Docker 容器化部署 Tomcat 和 Memcached,实现快速部署和扩容。
- 配置 Memcached 的主从复制和哨兵机制,实现 Memcached 的高可用。
- 监控 MSM 的运行状态,包括 Session 的创建、读取、备份次数,以及序列化和反序列化的时间。
6.3 配置过程
下载相关 jar 包 下载相关 jar 包,参考下面官方说明的下载链接 https://github.com/magro/memcached-session-manager/wiki/SetupAndConfiguration
修改 tomcat 配置
bash
[root@tomcat-1 ~]# vim /usr/local/tomcat/conf/context.xml
@@@@内容省略@@@@
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="n1:172.25.254.10:11211,n2:172.25.254.20:11211"
failoverNodes="n1"
requestUriIgnorePattern=".*\.(ico|png|gif|jpg|css|js)$"
transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory"
/>
bash
[root@tomcat-2 tomcat]# vim /usr/local/tomcat/conf/context.xml
@@@@内容省略@@@@
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="n1:172.25.254.10:11211,n2:172.25.254.20:11211"
failoverNodes="n2"
requestUriIgnorePattern=".*\.(ico|png|gif|jpg|css|js)$"
transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory"
/>修改 nginx 配置
bash
[root@Nginx ~]# vim /usr/local/nginx/conf.d/vhosts.conf
upstream tomcat {
hash $cookie_JSESSIONID;
server 172.25.254.10:8080;
server 172.25.254.20:8080;
}
server {
listen 80;
server_name lee.timinglee.org;
root /webdataw/nginx/timinglee.org/lee;
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
try_files $uri $uri.html $uri/index.html /error/default.html;
location ~ \.jsp$ {
proxy_pass http://tomcat;
}
}测试:
-
在两台 tomcat 都开启的情况下: http://lee.timinglee.org/test.jsp
-
在 n1 被停止后继续提交信息看是否可以读取到之前的会话信息
代码逐行解析(Line-by-Line Breakdown)
Tomcat context.xml 配置解析
表格
| 代码行 | 底层触发动作 | 作用 | |||||
|---|---|---|---|---|---|---|---|
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager" |
替换 Tomcat 默认的 StandardManager 为 MSM 的 MemcachedBackupSessionManager,所有 Session 的创建、读取、销毁操作都由这个类处理 | 启用 MSM 分布式 Session 管理器 | |||||
memcachedNodes="n1:172.25.254.10:11211,n2:172.25.254.20:11211" |
定义 Memcached 集群的节点列表,格式为节点名称:IP:端口,多个节点用逗号分隔 |
指定 MSM 要连接的 Memcached 节点 | |||||
failoverNodes="n1" |
定义故障转移节点,Tomcat1 的主备份节点是 n2(Memcached2),故障转移节点是 n1(Memcached1)。当主备份节点故障时,自动切换到故障转移节点 | 实现 Session 备份的高可用 | |||||
| `requestUriIgnorePattern=".*.(ico | png | gif | jpg | css | js)$"` | 定义不需要更新 Session 的请求 URI 正则表达式,匹配静态资源的请求不会触发 Session 的备份操作 | 减少不必要的 Session 备份,提升性能 |
transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory" |
指定使用 Kryo 序列化器对 Session 数据进行序列化和反序列化 | 提升序列化性能,减少序列化后的字节数 | |||||
/> |
结束 Manager 标签 | - |
Nginx 配置解析
表格
| 代码行 | 底层触发动作 | 作用 |
|---|---|---|
hash $cookie_JSESSIONID; |
配置 Nginx 使用基于 JSESSIONID Cookie 的哈希负载均衡算法,将同一个 JSESSIONID 的请求始终分发到同一个 Tomcat 服务器 | 实现会话粘性,减少 MSM 从 Memcached 中读取 Session 的次数,提升性能 |
| 其他配置 | 与 4.3.2 节的负载均衡配置相同 | - |
坑点(Gotchas)
- failoverNodes 配置错误:Tomcat1 的 failoverNodes 应该设置为 n1,Tomcat2 的 failoverNodes 应该设置为 n2,这样才能实现交叉备份。如果两个 Tomcat 的 failoverNodes 设置相同,会导致备份节点集中在同一个 Memcached 节点上,存在单点故障风险。
- requestUriIgnorePattern 正则错误:如果正则表达式写错,会导致静态资源请求也触发 Session 备份,增加 Memcached 的压力;或者导致动态请求不触发 Session 备份,导致 Session 数据不一致。
- Nginx 哈希算法的问题 :如果用户浏览器禁用了 Cookie,JSESSIONID 会通过 URL 重写传递,此时
$cookie_JSESSIONID变量为空,哈希算法会失效,导致请求被随机分发到不同的 Tomcat 服务器。
企业级生产应用
- 千万级并发场景 :生产环境会移除 Nginx 的会话粘性配置,让请求可以分发到任意 Tomcat 服务器,实现真正的负载均衡。因为 MSM 已经实现了分布式 Session 共享,即使请求被分发到不同的 Tomcat,也能获取到正确的 Session 数据。同时配置 MSM 的
sticky=false参数,禁用 MSM 的会话粘性,提升系统的可扩展性。 - 进阶优化 :
- 配置
sessionBackupAsync="true",开启异步 Session 备份,减少请求响应时间。 - 配置
sessionBackupTimeout="1000",设置 Session 备份的超时时间为 1 秒,避免备份操作阻塞请求。 - 配置
copyCollectionsForSerialization="true",解决集合类序列化的问题。 - 使用 Redis 替代 Memcached,利用 Redis 的持久化功能和主从复制机制,实现更高的 Session 可用性。
- 配置
课后防宕机指南(Troubleshooting)
- 错误现象 :停止其中一台 Tomcat 后,用户 Session 丢失
- 排查思路:检查 MSM 的配置是否正确,memcachedNodes 和 failoverNodes 是否配置正确;检查 Memcached 集群是否正常运行;检查 Session 是否成功备份到 Memcached 中(使用 telnet 查看 Memcached 中的数据);检查 Nginx 的负载均衡算法是否为轮询。
- 错误现象 :Session 备份到 Memcached 的时间过长,导致请求响应缓慢
- 排查思路:检查是否开启了异步备份;检查 Session 中存储的数据是否过大;检查 Kryo 序列化是否正常;检查 Memcached 的性能是否存在瓶颈(如内存不足、网络延迟过高)。