【2026】Datawhale X AMD · Hello ROCm - Part1 - 配置云环境&部署大模型
ROCm(Radeon Open Compute)是AMD公司开发的开源GPU计算平台,类似于NVIDIA的CUDA平台。Part 1主要介绍怎么在云端AMD显卡上用业界主流的vLLM框架,把Google最新开源的Gemma4跑成可对话的推理服务。
资源准备
-
AMD云环境账号注册
进入AMD AI开发者计划页面(https://developer.amd.com.cn/login?source=ifF119ybS),注册账号。
-
AMD云端GPU卡时获取
从AMD AI开发者计划页面进入AMD AI开发者云(https://radeon.anruicloud.com/)页面,然后在页面右上角的头像处选择"Login with ModelScope"使用魔搭登录,首次登录后可以免费获得10个AMD GPU运行时。
如果想要获得更多的AMD GPU运行时,可以在AMD AI开发者计划页面查看经验值获取规则,经验值可以用于兑换AMD GPU运行时,100经验值对应100运行时,每次兑换的运行时在30天内有效。
创建和启动云环境(用时3-6分钟左右)
在AMD AI开发者云页面找到"Hello ROCm Bate",点击"Launch",稍等3秒后按钮变成"Open Notebook",点击该按钮,浏览器会打开jupyter notebook页面。
进入jupyter notebook页面后,看到如下图所示的notebook页面即表示云环境启动成功。该页面展示的就是本次学习的内容。这个notebook里面已经默认配置好了本次学习使用AMD显卡部署运行大模型所需的python环境及一系列库(后面还需要做一些环境的小改动)。
部署&运行Gemma4大模型(用时15-30分钟左右)
在前面已经打开的jupyter notebook中新建终端,执行如下操作:
1. 检查AMD显卡是否可用
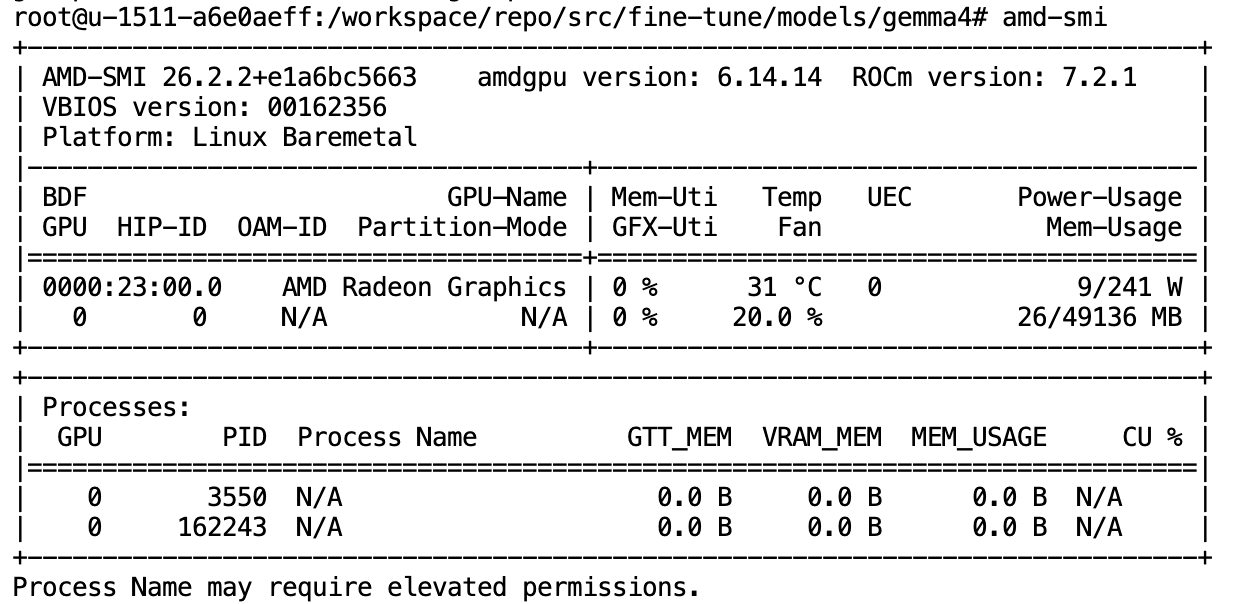
使用下方命令,检查云环境中是否有可用的AMD显卡:
bash
amd-smi| 💡
这个命令跟nvidia显卡查看显卡是否可用的命令nvidia-smi几乎一样,只是刚好换了显卡品牌名称哈哈哈!
出现如下图所示的输出,说明AMD显卡可用:
2. 检查PyTorch是否可以识别AMD显卡
使用下方命令,检查云环境中的PyTorch是否可以识别AMD显卡:
bash
python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"这条命令的内容是:
1️⃣print('PyTorch:', torch.__version__)-》输出PyTorch版本;
2️⃣print('ROCm available:', torch.cuda.is_available())-》输出当前环境是否能使用AMD的ROCm框架进行GPU加速的检查结果(在PyTorch中,这个函数原本是检测NVIDIA CUDA是否可用。但当安装了ROCm版PyTorch时,PyTorch会通过兼容层把ROCm接口模拟成CUDA API。torch.cuda.is_available() 在ROCm环境下返回True的前提是:
- 正确安装了ROCm版PyTorch(云环境已自带)
- AMD GPU驱动正常(云环境已自带)
- 系统能识别AMD GPU(云环境已自带)
3️⃣print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')-》输出显卡设备名称
终端出现如下输出说明云环境可以运行大模型:

3. 使用ModelScope下载Gemma4模型
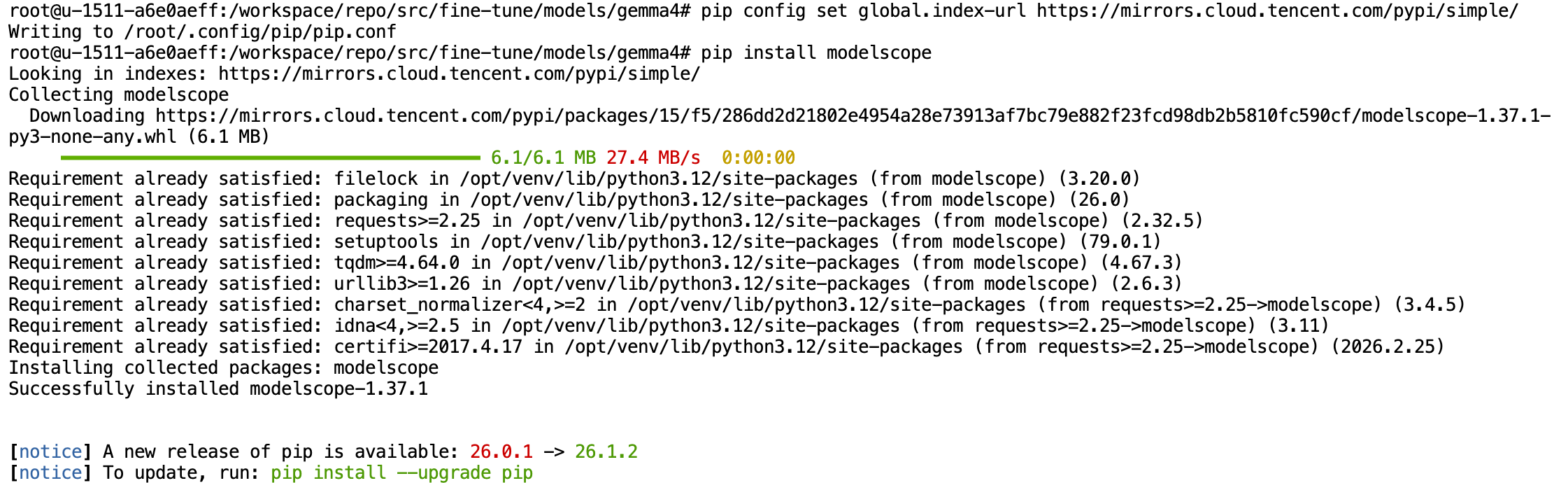
Gemma 4是Google推出的一款大语言模型。在安装Gemma4模型前,为了提升国内环境下的依赖下载速度,先使用如下命令把pip源切换到腾讯云镜像:
bash
pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/随后,安装ModelScope第三方库。ModelScope它是由阿里达摩院主导的国内开源模型社区,是国内的"AI 模型应用商店",其服务器在国内,能帮我们高速、稳定地把大模型拉到本地。安装命令如下:
bash
pip install modelscope完成这两个设置安装时,终端会输出如下页面内容:
然后正式开始使用ModelScope安装Gemma4,安装命令如下:
bash
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"这条命令表示将ModelScope平台上的google/gemma-4-E4B-it(https://www.modelscope.cn/models/google/gemma-4-E4B-it)模型权重下载到云服务器的路径`./models` ,下载时间大概需要8-10分钟。下载完成后终端会输出Successfully Downloaded from model google/gemma-4-E4B-it.的提示:
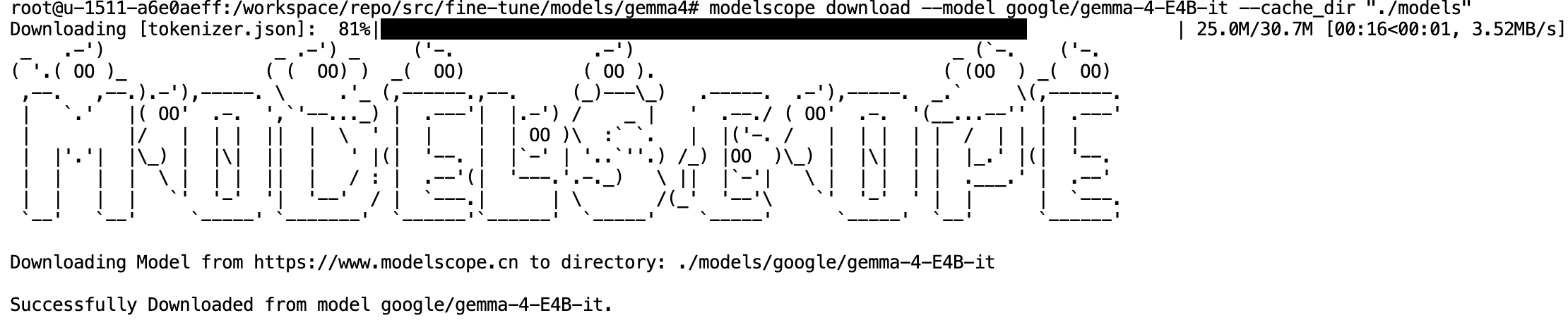
(因为我是二次执行上一条命令,而模型已经安装完成了,所以显示的进度条很少,但实际上安装过程会显示好几条进度条,对应模型的不同文件)
完成Gemma4安装后,可以通过下方命令检查是否真的安装成功了:
bash
ls -lh ./models/google/gemma-4-E4B-it/终端输出如下内容就表示安装成功,其中15G大的 model.safetensors 是模型权重:

4. 使用vllm框架运行Gemma4大模型
vLLM 是一个本地高效推理大模型的项目,这里使用vLLM来测试刚才下载的模型能否正常使用。在使用 vLLM 前,需更新云环境中的 vLLM 版本才能运行 Gemma4 模型。更新命令如下:
bash
uv pip uninstall torchvision # 经测试,在该云环境中,需卸载重新安装这个库才能正常使用
uv pip install vllm torchvision \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U更新云环境后,在一个终端中使用vllm框架启动gemma-4模型,命令如下:
bash
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it这条命令用于启动一个兼容 OpenAI API 格式的模型服务,后续可以通过网络接口来调用指定的大语言模型(serve后面紧跟的是本地的Google Gemma-4模型文件夹,--served-model-name参数用于自定义服务对外暴露的模型名称,API 调用时使用这个名字来指定模型)。
运行成功后,vLLM 会从本地路径 ./models/google/gemma-4-E4B-it/ 读取模型文件(包括 config.json、模型权重等),然后默认在 http://localhost:8000 上启动一个兼容 OpenAI API 的服务器,后续可以通过标准的 OpenAI API 方式调用模型。
| 💡
注意:运行这个命令后,这个终端窗口就会 被大模型服务"死死占满" 。请 保持运行,绝对不要关闭它 ,也不要按 Ctrl+C ,否则大模型服务就会立刻停止。
出现如下输出表示vllm启动成功:
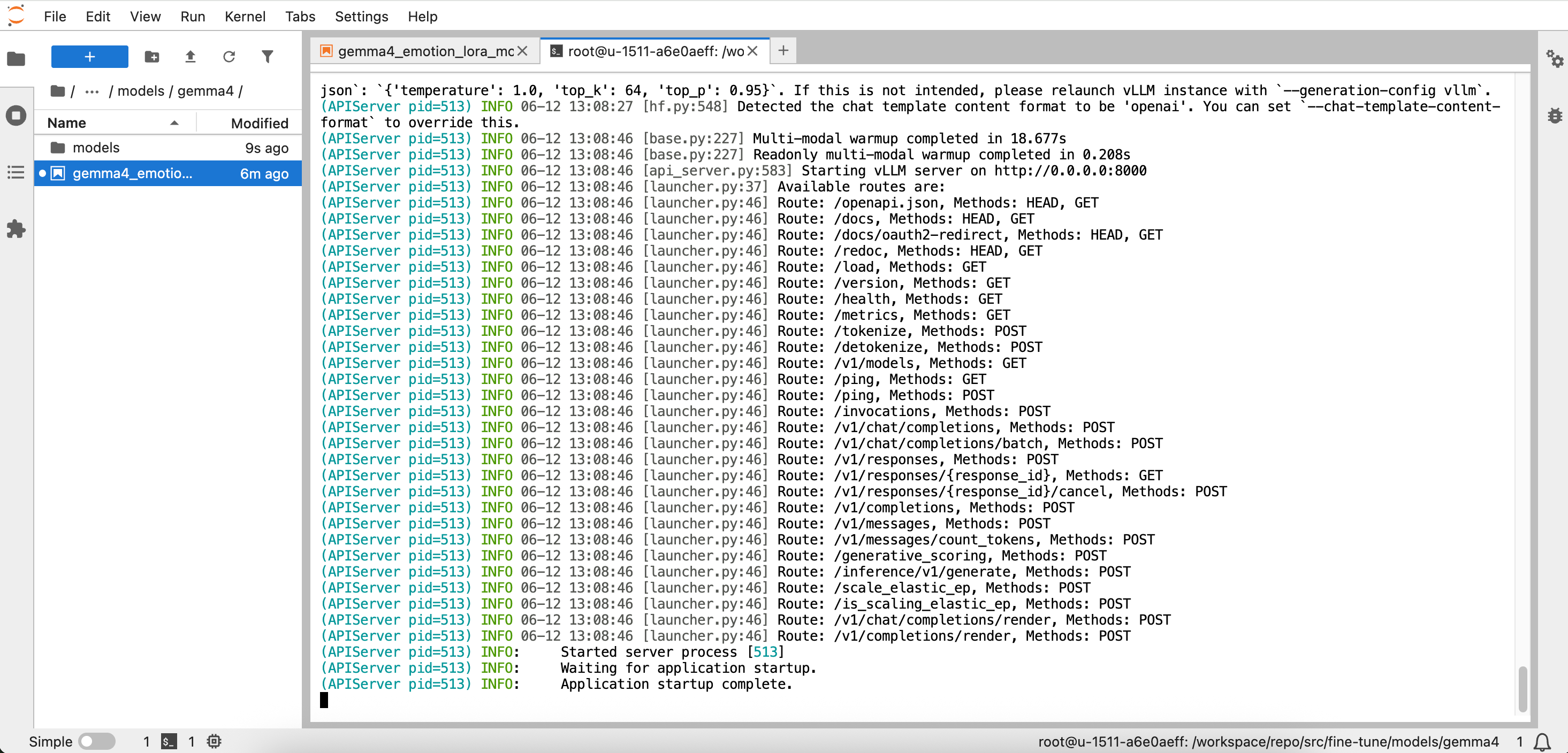
启动这个Gemma4大模型服务后,新开一个终端(前面的一个终端专门用于监视大模型服务日志信息,不能再接收命令),和Gemma4对话,测试它的推理服务是否正常。启动Gemma 4对话的命令如下:
bash
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-itvllm chat这条命令用于通过命令行与已部署的 vLLM 服务进行交互对话(这里是使用刚才开放的OpenAI API的接口来做交互),就像在终端里使用一个聊天客户端一样。--url参数指定 vLLM 服务的 API 地址,/v1 表示使用 OpenAI API v1 兼容的端点。--model参数指定要调用的模型名称,必须与之前 vllm serve 命令中 --served-model-name 设置的名称完全一致。
随便输入一些内容与Gemma4对话,Gemma4有内容输出就表示可以正常推理,已经在 AMD ROCm 云环境中正常运行:
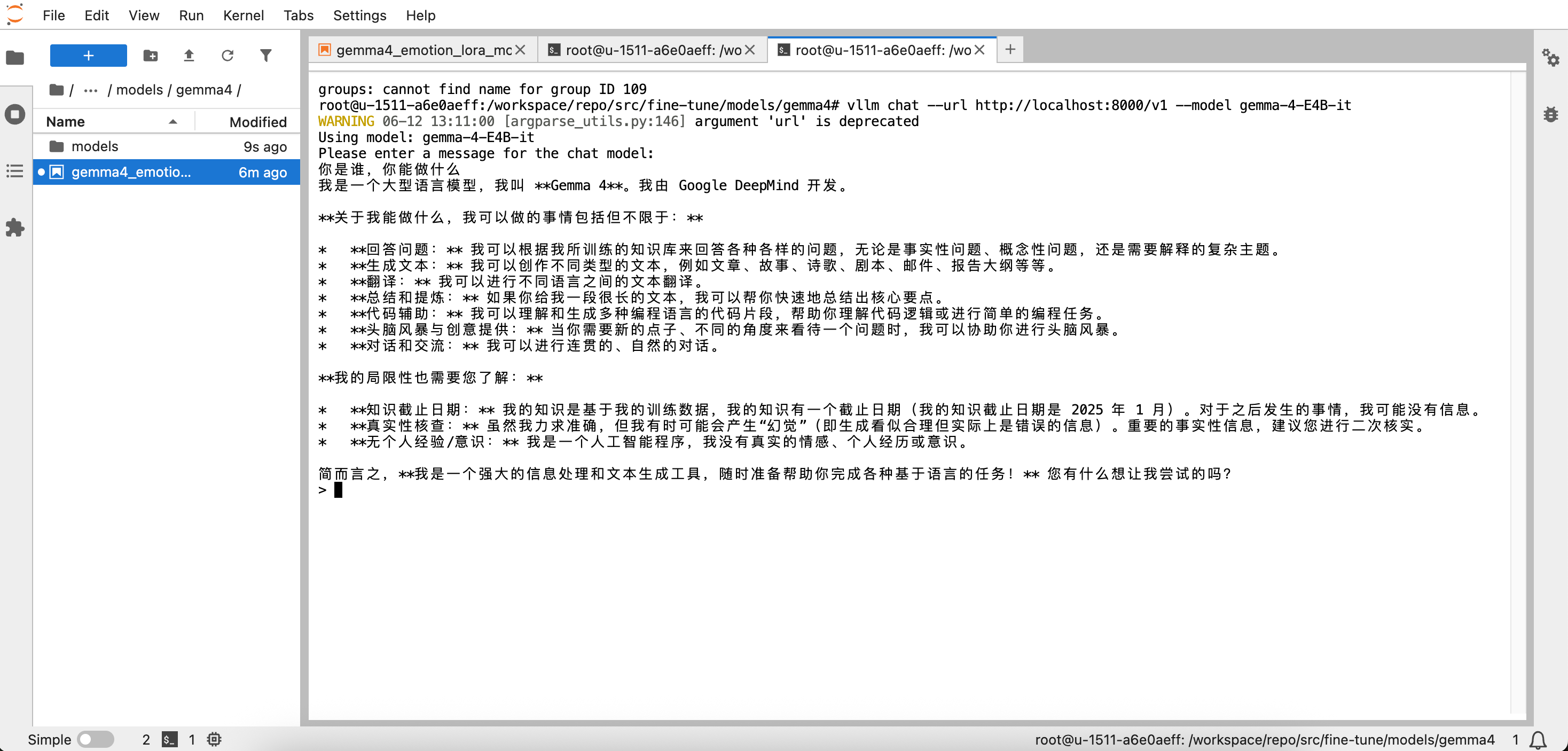
不想继续对话时,Mac电脑按 Control+C 、Windows电脑按 Ctrl +C 即可退出聊天。
关闭vllm服务和云环境
这个部分执行完上述操作就告一段落了,不再使用时需要关闭vllm服务和云环境,避免浪费卡时。
想关闭vllm服务时,在启动vllm服务的终端窗口,Mac电脑按 Control+C 、Windows电脑按 Ctrl +C 即可结束vllm服务,结束后不能再跟Gemma4对话。
想关闭云环境时,回到AMD AI开发者云页面的Profile(个人主页) ,找到 Active Instance 区域,点击红色的Destroy Instance按钮即可。
参考教程
https://ailc.datawhale.cn/hall/group/100000144/task/100000148
https://ailc.datawhale.cn/hall/group/100000144/task/100000035
https://ailc.datawhale.cn/hall/group/100000144/task/100000036