从 OpenAI Conversation State 到 Claude Mid-conversation System Messages: 一个负责把上下文接起来,一个负责在会话中途改变高优先级规则。理解这两个概念,才能真正搭好可持续运行的 AI 应用。
先拆开:这两份文档在回答两个不同的问题
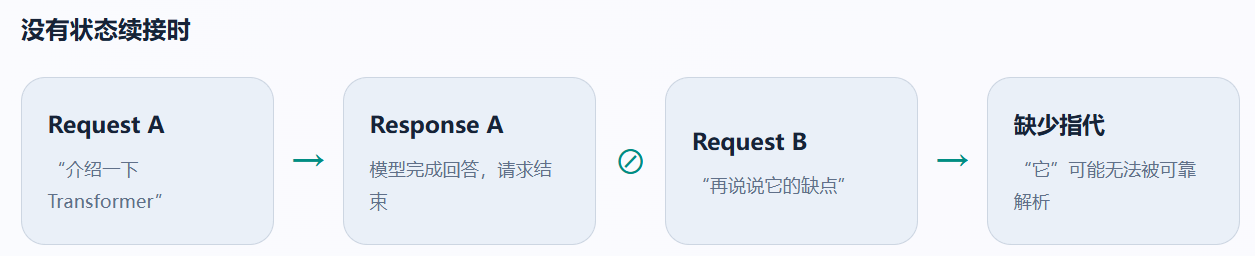
OpenAI 的 Conversation State 关心的是:一次 API 请求结束以后,下一次请求怎样继续理解前文。 例如,用户先说"给我讲个笑话",下一轮只说"解释一下为什么好笑",模型必须能拿到上一轮的内容,否则"这个"没有指向对象。
Claude 的 Mid-conversation System Messages 关心的则是:一段长会话已经进行了很多轮,应用此时才发现需要增加一条更高优先级的规则, 怎样把这条规则插入当前会话,同时避免修改最前面的顶层 system,从而破坏已经建立的 Prompt Cache。

一句话区分: Conversation state 是"把过去带到下一轮";mid-conversation system message 是"从当前节点开始,改变后续应该遵守的规则"。
为什么每次调用默认都像"第一次见面"
大多数文本生成 API 的单次请求本质上是独立的。服务器收到请求中的输入,完成推理,返回结果;下一次调用如果没有提供任何可关联的信息, 模型不会自动知道上一轮聊了什么。这就是常说的 stateless。
stateless 不代表不能做多轮聊天。它只意味着"状态必须被显式带回来"。这个状态可以由应用自己保存并重发,也可以由 API 提供的对象或 ID 帮你关联。
OpenAI 中管理 conversation state 的三条路线
从工程实现看,可以把 OpenAI 的方案分成三类:手动维护完整历史、通过 previous_response_id 串联响应,以及使用 Conversations API 创建长期存在的 conversation object。

OpenAI 官方文档目前更推荐使用 Responses API 管理多轮上下文;使用 Chat Completions 时,通常需要由应用自行维护消息历史。
手动维护 history:最直观,也最容易踩坑
手动方案就是维护一个数组:用户消息加入数组,模型输出也加入数组,下一轮再把整个数组作为 input 或 messages 发出去。 它适合需要自定义删减、摘要、审计或跨供应商兼容的系统。
为什么不能永远无脑追加
history 会持续增长。输入越长,token 成本越高,也更容易触及 context window。实际系统一般需要加入 sliding window、摘要、检索式记忆、compaction 或重要消息保留策略。



previous_response_id:把 response 串成一条链
Responses API 可以通过 previous_response_id 指向上一轮 response。 下一次请求不需要再次手工拼装完整的可见消息列表,就能沿着上一轮继续。
需要注意:"不用手动重发完整 history"不等于"历史 token 不计费"。官方文档明确说明,即使使用 previous_response_id,链中先前输入 token 仍会按 input token 计费。
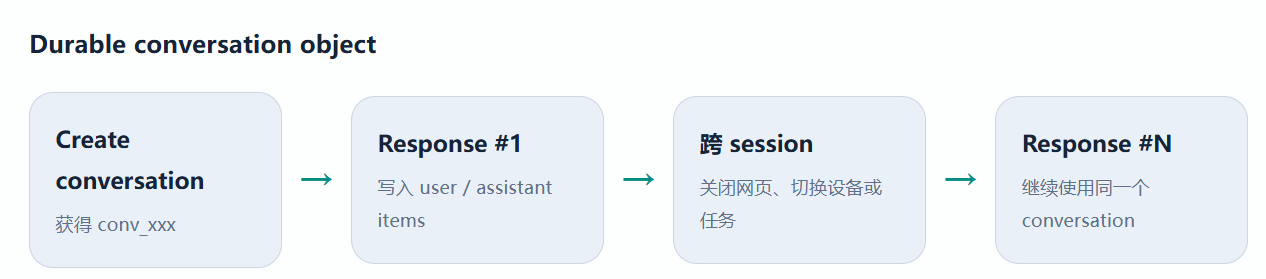
这种方式天然适合线性对话。若系统需要长期存在、跨设备恢复、多人协作或更明确地管理 conversation 中的 item, durable conversation object 通常更合适。
Conversations API:把会话本身变成一个长期对象
Conversations API 与 Responses API 配合使用。应用先创建 conversation,获得 durable identifier; 后续请求持续传入这个 conversation ID。conversation 中不仅可以保存普通 message,也可以保存 tool call、tool output 等 item。

Claude 的 mid-conversation system message 到底做了什么
Claude Messages API 通常把全局系统指令放在顶层 system 字段中。 但在长会话中,应用可能到第 20 轮才知道一条新要求,例如"从现在开始,所有 SQL 必须参数化"。
传统做法是修改顶层 system prompt,然后把整段会话重新发出。问题在于:顶层 system 位于 prompt 前缀的前部, 一旦改变,后续已经缓存的前缀很可能无法继续命中。mid-conversation system message 则允许在 messages 数组的当前节点追加 {"role":"system"}, 让新规则从这里开始生效。
为什么"中途加 system message"会和缓存强绑定
Prompt Caching 的关键不是"这几句话意思差不多",而是前缀要能精确匹配。Claude 文档给出的顺序是: tools → system → messages。缓存命中要求到 cache breakpoint 为止的前缀与近期请求逐字节一致。

这项功能并不会自动让所有请求产生缓存收益。Claude 的 Prompt Caching 是 opt-in: 请求必须配置 cache_control 或显式 cache breakpoint, 并且内容需要达到最低可缓存长度。短示例即使写了缓存配置,也可能仍显示缓存 token 为 0。
不是想插哪就插哪:消息放置规则
mid-conversation system message 必须处在合法位置。按照当前 Claude 文档,它需要紧跟在 user turn 之后, 或紧跟在"以 server tool use 结束的 assistant turn"之后;它应当是 messages 中最后一项,或者后面立刻接一个 assistant turn。
User → System:用户消息之后追加新的系统级上下文。
Tool result → System:工具结果由 user message 交回后,再加入 system message。
禁止:Tool use → System → Tool result。不能把 system message 插在工具调用与对应工具结果之间。
OpenAI Conversation State 与 Claude Mid-conversation System Messages 对比
| 维度 | OpenAI Conversation State | Claude Mid-conversation System Message |
|---|---|---|
| 解决的问题 | 让下一轮请求获得此前的消息、输出和工具上下文。 | 在会话中途追加或更新 system-level 指令。 |
| 核心对象 | history、response ID、conversation object。 | messages 数组中的 role: system。 |
| 是否负责"记住前文" | 是,这是主要目标。 | 不是独立的状态存储方案;它建立在已提交的会话历史之上。 |
| 是否改变指令优先级 | 状态续接本身不等于新增 system-level 规则。 | 是,新增内容作为系统指令而不是普通 user text 处理。 |
| 缓存关系 | 主要讨论状态的保存和续接;token 与 context 仍需管理。 | 核心价值之一就是不改动既有前缀,从而尽量保持 Prompt Cache 命中。 |
| 典型场景 | 聊天机器人、跨 session 助手、持续工具调用、项目型 Agent。 | 中途政策变化、工具可用性变化、剩余预算变化、用户执行期间补充要求。 |
| 常见误解 | 用了 ID 就完全不再计算历史 token。 | 可以随意插在任何消息之间,或可用于覆盖用户意图。 |
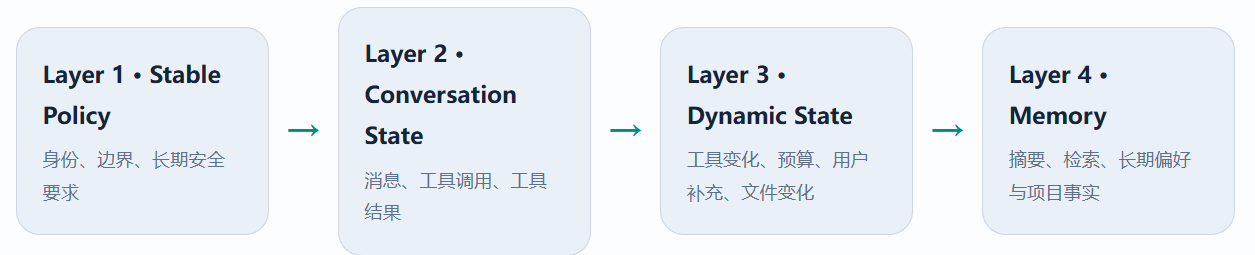
推荐的分层状态设计
最常见的六个误区
把网页聊天界面当成 API 自动记忆。 产品界面可以在后台维护状态,但底层 API 仍需要明确的状态管理机制。
只保存最终文本。 工具型或 reasoning 型工作流可能还需要保存完整 output items,而不只是 output_text。
认为 previous_response_id 可以免除历史 token 成本。 它简化了关联方式,不代表历史上下文免费。
不断改写顶层 system。 在依赖 Prompt Caching 的长会话中,这可能让原有缓存前缀失效。
把 system message 当作强制覆盖用户意图的后门。 更合理的做法是描述事实、状态或约束发生了什么变化。
忽略 context window。 无论状态怎样保存,最终送入模型的有效上下文仍然受到 token 上限约束。