AI Agent 的价值,不只是把大模型接到几个工具上,更关键的是让系统具备可控的推理能力、可追踪的外部行动能力,以及可回滚的错误修正能力。
很多团队在做 Agent 时,第一版通常都能跑通:用户提问,模型理解意图,调用工具,返回结果。但一进入真实业务,就会遇到更复杂的问题:信息不足时如何补全?工具返回异常时如何恢复?多步骤任务如何避免走偏?结果不确定时如何自检?如果涉及退款、封禁、配置变更这类高风险动作,又该如何防止 Agent "自信地犯错"?
这正是 ReAct、CoT 与 Self-Reflection 的工程意义。
- CoT(Chain of Thought):让复杂任务先被拆解,形成目标、约束、缺失信息和执行步骤。
- ReAct(Reasoning + Acting):让 Agent 在"推理---行动---观察"之间循环,用外部事实不断修正路线。
- Self-Reflection:让 Agent 对结果和过程进行复盘,发现证据不足、权限越界、步骤遗漏或成本超预算等问题。
三者不是互斥关系,而是可以组合成一个更可靠的 Agent 工作闭环:先规划,再行动;行动后观察;观察后反思;必要时重新规划或升级人工。
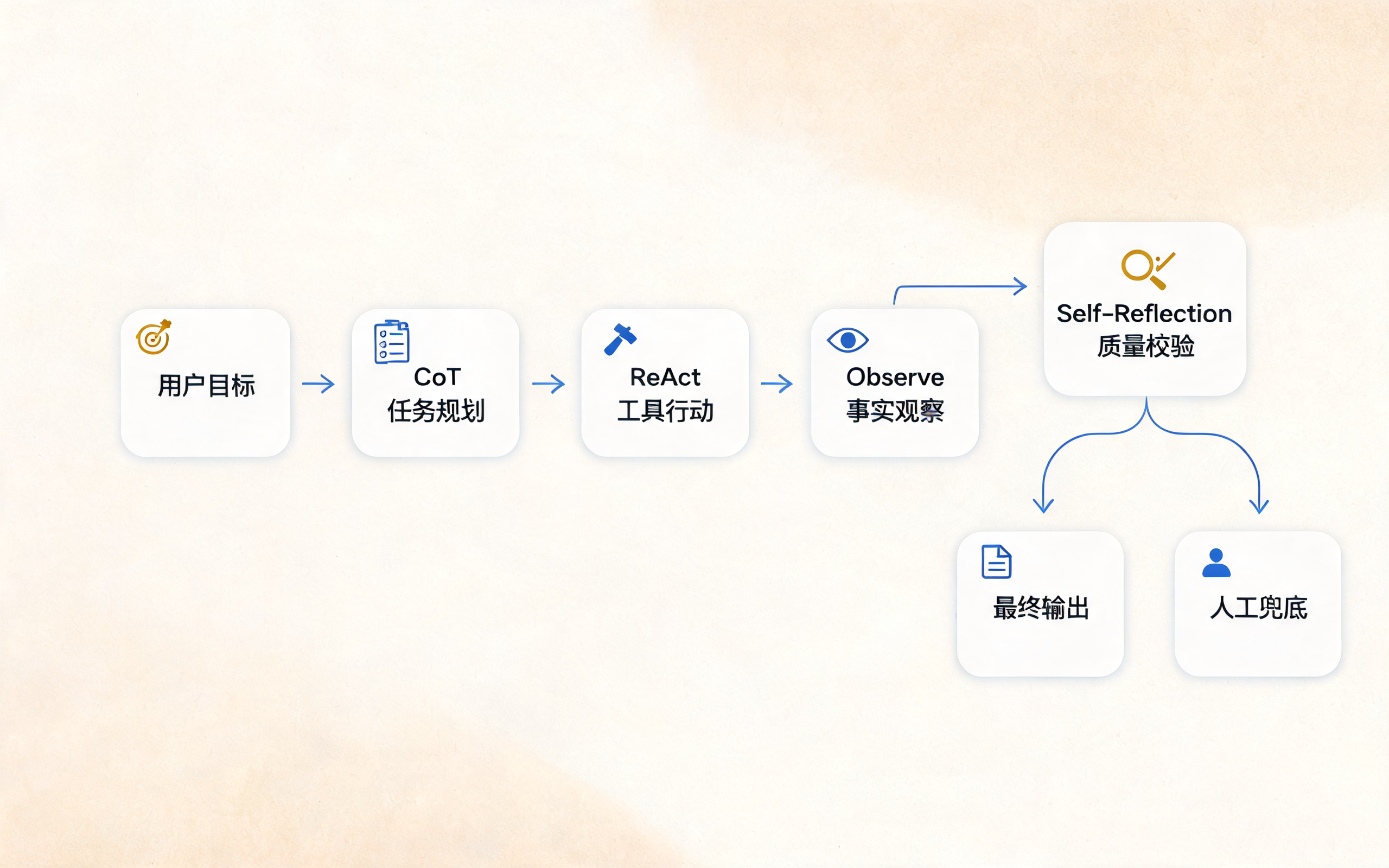
Agent 工程闭环总览:Seedream 单图生成版,展示 CoT、ReAct、Observe 与 Self-Reflection 闭环
文章目录
-
- [一、为什么 Agent 不能只靠一次性回答](#一、为什么 Agent 不能只靠一次性回答)
- 二、CoT:让复杂任务先被拆开
-
- [一个结构化 CoT 计划示例](#一个结构化 CoT 计划示例)
- 三、ReAct:在思考与行动之间循环
-
- [ReAct 执行循环示例](#ReAct 执行循环示例)
- [四、Self-Reflection:让 Agent 有纠错机制](#四、Self-Reflection:让 Agent 有纠错机制)
- [五、用 Mermaid 画出完整工作流](#五、用 Mermaid 画出完整工作流)
- 六、三者如何组合成可落地架构
- 七、工程实践中的关键设计点
-
- [1. 把推理过程结构化,而不是纯文本化](#1. 把推理过程结构化,而不是纯文本化)
- [2. 工具调用必须有边界](#2. 工具调用必须有边界)
- [3. 反思阶段要结合规则与模型](#3. 反思阶段要结合规则与模型)
- [4. 控制循环次数和成本](#4. 控制循环次数和成本)
- [5. 建立评估集](#5. 建立评估集)
- [八、一个通用业务示例:异常订单处理 Agent](#八、一个通用业务示例:异常订单处理 Agent)
- 九、常见误区
- 十、落地建议
- 总结
一、为什么 Agent 不能只靠一次性回答
传统问答系统通常是一次输入、一次输出。用户问一个问题,模型直接给出答案。这种模式适合知识解释、简单分类、文本总结等任务,但不适合真实业务流程。
以运维告警处理为例,用户可能只说:"线上接口异常,帮我看一下。"一个可靠的 Agent 不能立刻给出结论,它至少需要做几件事:
- 判断告警属于哪个业务服务;
- 查询错误率、延迟、QPS、实例状态等监控指标;
- 对比发布时间、配置变更、依赖服务状态;
- 如果某个工具超时,尝试降级到备用数据源;
- 最后给出证据链、可能原因和处置建议。
再看客服场景。用户说"订单没有到账",Agent 需要识别用户身份、查询订单状态、核对支付流水、判断履约节点、确认是否触发补偿策略。这里的每一步都可能影响最终处理方式。如果 Agent 只是凭语言模型猜测,就容易出现错误承诺、越权操作或遗漏关键条件。
所以,Agent 的核心不是"会说",而是"会按步骤解决问题"。
可以把三类能力对应到三个问题:
| 能力 | 解决的问题 | 工程落点 |
|---|---|---|
| CoT | 任务怎么拆 | 计划生成、步骤编排、信息缺口识别 |
| ReAct | 下一步怎么做 | 工具调用、状态更新、动态决策 |
| Self-Reflection | 做得对不对 | 结果校验、过程复盘、失败恢复 |
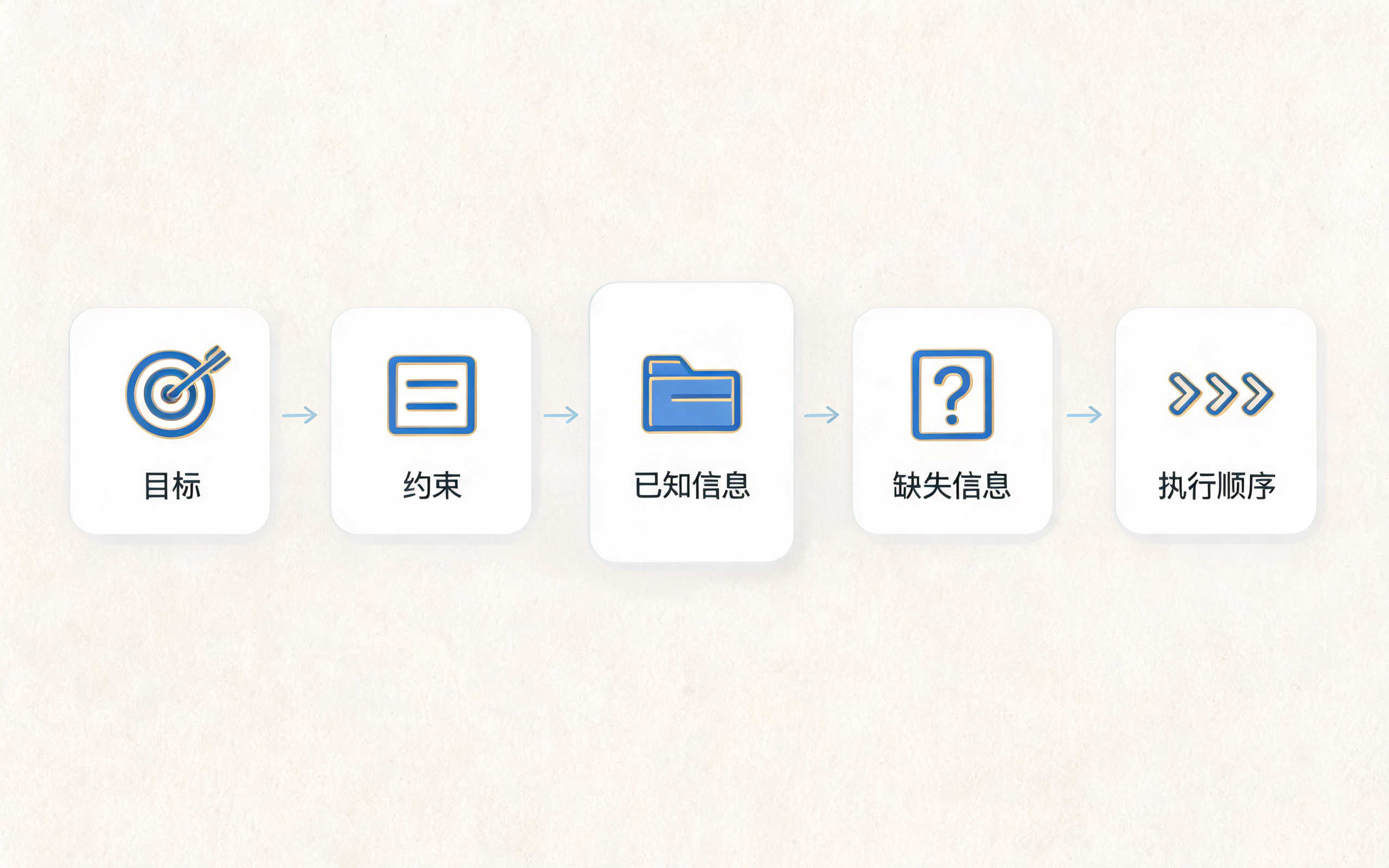
CoT 任务拆解图:Seedream 单图生成版,展示目标、约束、信息与顺序
二、CoT:让复杂任务先被拆开
CoT,即 Chain of Thought,可以理解为链式思考。它的核心不是让模型啰嗦地展示所有思考过程,而是让系统在内部形成可执行、可检查的推理结构。
在工程里,CoT 更适合作为任务规划与中间状态管理机制,而不是简单把提示词改成"请一步步思考"。一个成熟的 Agent 应该能把用户请求拆成:
- 目标:用户真正想完成什么;
- 约束:权限、时间、成本、合规边界是什么;
- 已知信息:用户已经提供了哪些字段;
- 缺失信息:还需要查什么、问什么;
- 候选路径:有哪些可能的解决路线;
- 执行顺序:先做什么,失败后怎么降级。
例如在订单异常处理场景中,用户输入:"客户反馈扣款成功但订单显示未支付。"Agent 可以拆解为:
- 确认订单号和用户身份是否匹配;
- 查询订单系统中的支付状态;
- 查询支付通道流水状态;
- 判断是否存在回调延迟、回调失败或状态同步失败;
- 根据业务规则给出处理动作,例如重试回调、创建人工工单或提示等待。
这种拆解带来的好处很直接:第一,降低遗漏步骤的概率;第二,让系统更容易审计;第三,便于在不同步骤插入权限控制、异常处理和人工确认。
一个结构化 CoT 计划示例
不要只让模型输出一段自然语言计划,更推荐让它输出结构化对象。下面是一个简化的 Python 示例:
python
from dataclasses import dataclass, field
from typing import Literal
RiskLevel = Literal["low", "medium", "high"]
@dataclass
class PlanStep:
name: str
goal: str
tool: str | None = None
required_inputs: list[str] = field(default_factory=list)
success_criteria: list[str] = field(default_factory=list)
fallback: str | None = None
@dataclass
class AgentPlan:
task: str
risk_level: RiskLevel
missing_info: list[str]
steps: list[PlanStep]
def build_order_plan(user_request: str) -> AgentPlan:
return AgentPlan(
task="排查已扣款但订单待支付的问题",
risk_level="medium",
missing_info=["order_id", "user_id"],
steps=[
PlanStep(
name="校验订单归属",
goal="确认订单属于当前用户,避免越权查询",
tool="order.query",
required_inputs=["order_id", "user_id"],
success_criteria=["订单存在", "订单用户匹配"],
fallback="要求用户补充订单号或转人工核验",
),
PlanStep(
name="查询支付流水",
goal="确认支付通道是否真的扣款成功",
tool="payment.query",
required_inputs=["order_id"],
success_criteria=["流水存在", "支付状态为 SUCCESS 或明确失败"],
fallback="切换备用支付查询接口或提示稍后重试",
),
PlanStep(
name="判断异常类型",
goal="区分回调延迟、回调失败、状态同步失败",
tool="callback.query",
required_inputs=["order_id"],
success_criteria=["找到回调记录或明确无回调"],
fallback="创建人工工单并附带已查证据",
),
],
)这个结构可以被后续的执行器读取,也可以被日志系统记录、被评估系统回放。相比纯文本计划,它更适合做权限校验、步骤跳过检查和失败恢复。
但 CoT 也有边界。它擅长规划和推理,却不能替代事实查询。如果 Agent 没有读取真实订单数据,仅靠推理给出结论,风险仍然很高。因此 CoT 必须和工具调用结合,这就进入 ReAct 的范围。
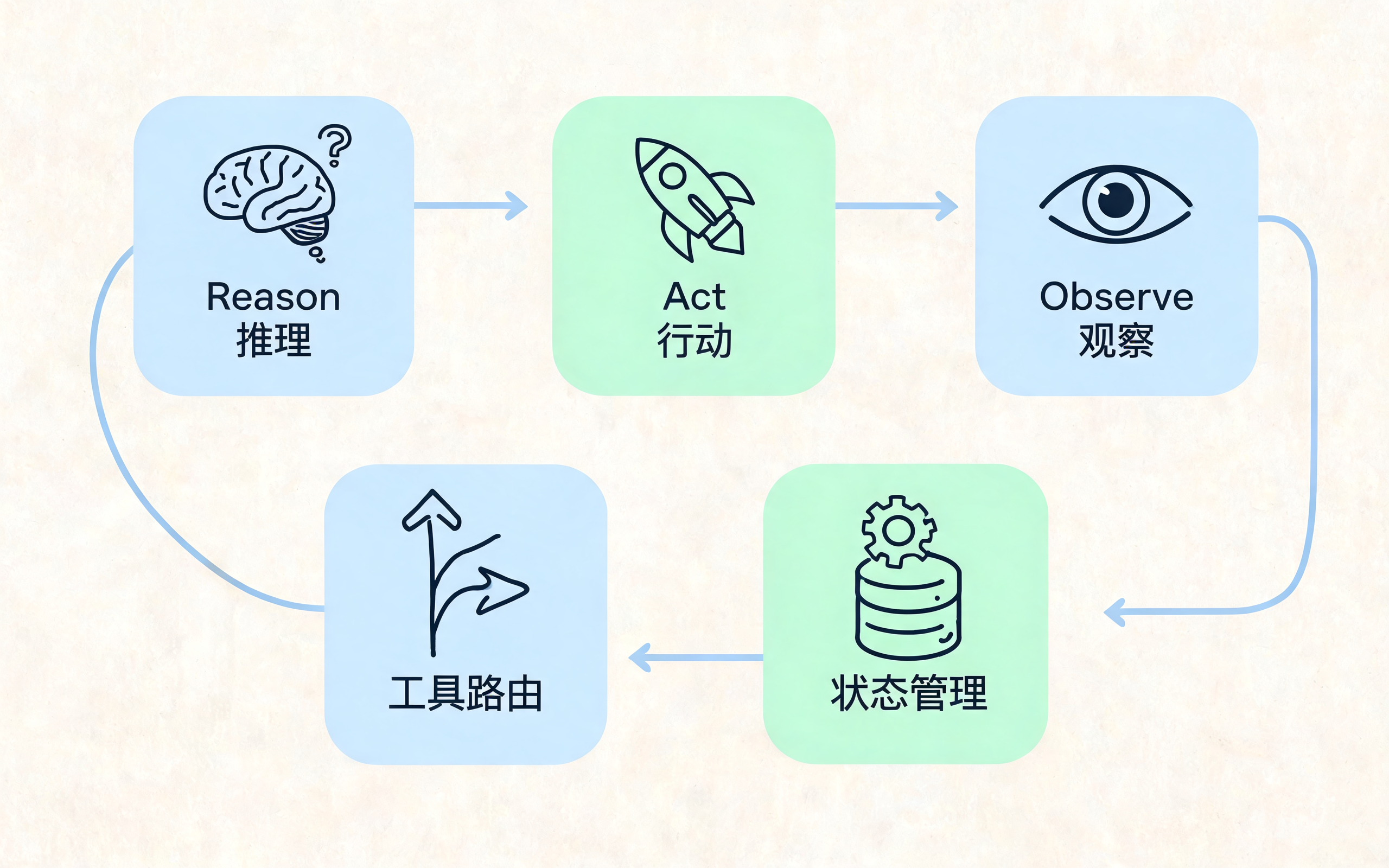
ReAct 执行循环图:Seedream 单图生成版,展示 Reason、Act、Observe 与状态管理
三、ReAct:在思考与行动之间循环
ReAct 是 Reasoning and Acting 的组合。它强调 Agent 不应一次性完成全部推理,而应在推理、行动和观察之间循环。
一个典型 ReAct 循环包括三步:
- Reason:判断当前要解决什么问题;
- Act:调用工具、查询系统或执行动作;
- Observe:读取工具结果,并更新下一步计划。
以运维故障排查为例,Agent 的执行过程可能是:先判断异常接口属于哪个服务;调用监控工具查看 QPS、错误率和延迟;观察到错误率从某次发布后升高;继续查询发布记录;发现某依赖配置变更;再查询下游服务状态;最后给出处置建议。
这个循环的价值在于动态性。真实世界不是静态题目,工具结果会不断改变 Agent 的判断。ReAct 让 Agent 不再只是凭空推理,而是用外部事实校正自己的路线。
从架构角度看,ReAct 至少需要四个组件:
- Planner:负责根据目标生成下一步行动;
- Tool Router:负责选择合适的工具并组装参数;
- Observation Parser:负责解析工具返回结果;
- State Manager:负责维护任务状态和历史轨迹。
很多失败的 Agent 项目,不是模型能力不够,而是状态管理过于粗糙。比如多轮工具调用后,系统没有保存已查询的数据,导致重复调用;或者工具失败后没有记录失败原因,导致反复走同一条坏路径。ReAct 要落地,必须把每一次行动和观察都结构化保存,而不是只塞进一段长上下文。
ReAct 执行循环示例
下面的示例展示一个最小化 ReAct Loop。它没有绑定具体 LLM SDK,但保留了工程上最关键的结构:状态、预算、工具结果和退出条件。
python
from dataclasses import dataclass, field
from typing import Any, Callable
@dataclass
class Observation:
step: str
tool: str
ok: bool
data: dict[str, Any]
error: str | None = None
@dataclass
class AgentState:
task: str
plan: list[str]
observations: list[Observation] = field(default_factory=list)
final_answer: str | None = None
risk_flags: list[str] = field(default_factory=list)
Tool = Callable[[dict[str, Any]], dict[str, Any]]
def choose_next_action(state: AgentState) -> dict[str, Any]:
"""真实系统里这里通常由 LLM + 规则共同决定。"""
done_steps = {obs.step for obs in state.observations if obs.ok}
if "query_order" not in done_steps:
return {"step": "query_order", "tool": "order.query", "args": {"order_id": "O123"}}
if "query_payment" not in done_steps:
return {"step": "query_payment", "tool": "payment.query", "args": {"order_id": "O123"}}
if "query_callback" not in done_steps:
return {"step": "query_callback", "tool": "callback.query", "args": {"order_id": "O123"}}
return {"step": "finish", "tool": None, "args": {}}
def run_react_loop(state: AgentState, tools: dict[str, Tool], max_steps: int = 8) -> AgentState:
for _ in range(max_steps):
action = choose_next_action(state)
if action["step"] == "finish":
state.final_answer = "已完成必要查询,可以进入反思校验阶段。"
return state
tool_name = action["tool"]
try:
result = tools[tool_name](action["args"])
state.observations.append(
Observation(step=action["step"], tool=tool_name, ok=True, data=result)
)
except Exception as exc:
state.observations.append(
Observation(step=action["step"], tool=tool_name, ok=False, data={}, error=str(exc))
)
state.risk_flags.append(f"工具调用失败:{tool_name}")
state.risk_flags.append("达到最大执行步数,停止自动循环")
return state这个循环里有几个值得注意的点:
max_steps是预算控制,避免无限循环;- 每次工具调用都生成
Observation,便于后续复盘; - 工具失败不会被吞掉,而是写入
risk_flags; - "下一步做什么"可以由规则、模型或二者共同决定。
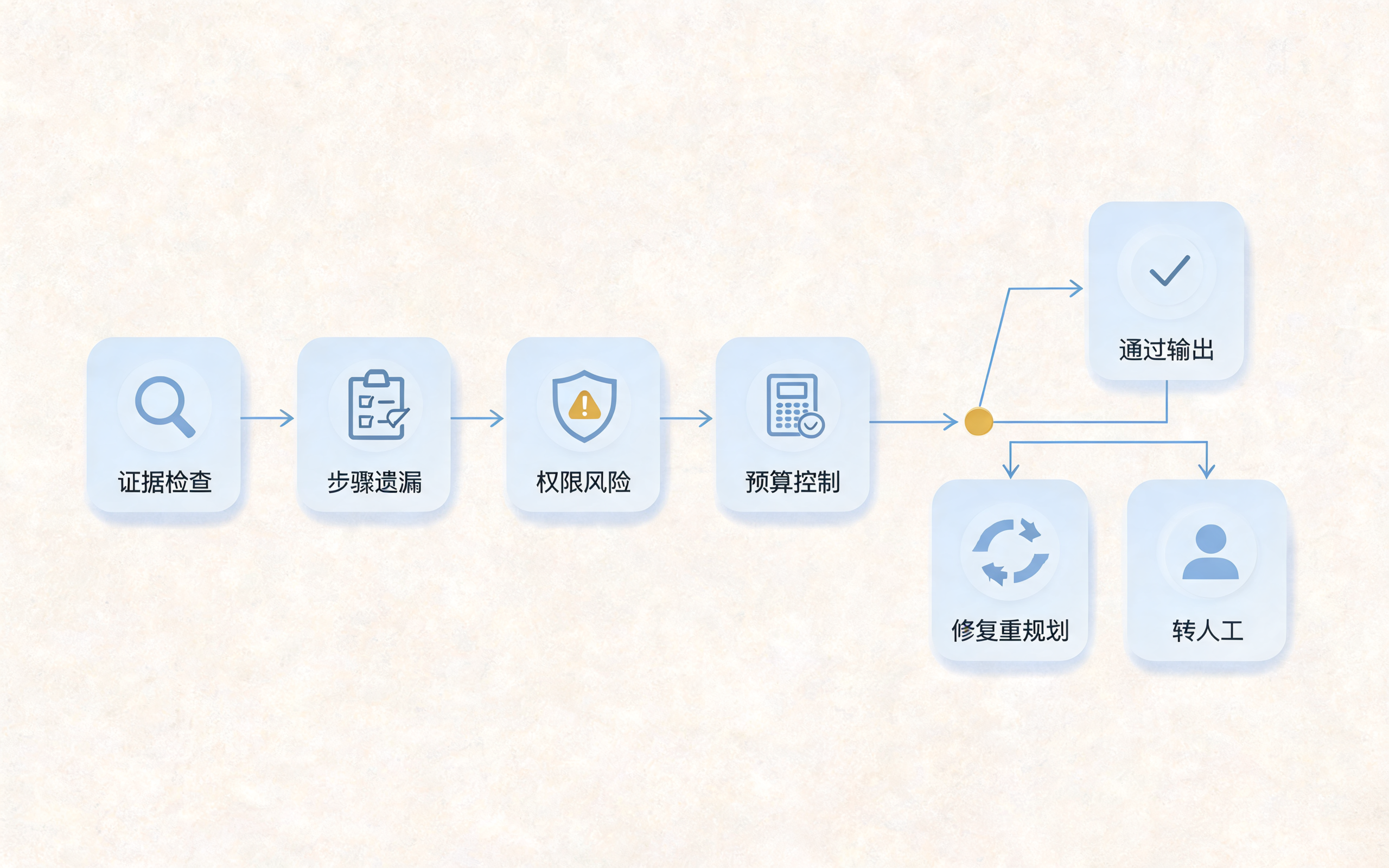
Self-Reflection 质量护栏图:Seedream 单图生成版,展示校验、修复与人工兜底
四、Self-Reflection:让 Agent 有纠错机制
Self-Reflection 可以理解为自我反思或自我评估。它的目标不是让 Agent 变得像人一样内省,而是在工程上建立质量检查和修正回路。
在客服退款场景中,Agent 初步判断某订单符合退款条件,但在反思阶段,它应再次检查:用户身份是否已验证?订单是否已发货?退款金额是否超过权限阈值?是否需要人工确认?如果任何条件不满足,Agent 就不能直接执行,而应转为询问补充信息或提交人工处理。
Self-Reflection 常见的落地方式有三类。
第一类是结果校验。Agent 完成任务后,用规则或模型检查结果是否满足要求。例如风控场景中,输出处置建议前必须检查是否引用了真实交易记录、是否给出了风险等级、是否包含下一步动作。
第二类是过程复盘。Agent 检查自己的工具调用轨迹是否合理。例如是否跳过必要查询、是否重复调用同一接口、是否在数据不足时做了确定性判断。
第三类是失败恢复。当工具异常、结果冲突或置信度不足时,Agent 应生成修正计划。例如切换数据源、缩小查询范围、请求用户补充字段,或转交人工。
需要注意的是,Self-Reflection 不等于无限重试。工程系统必须设置最大反思次数、超时阈值和人工兜底策略。否则 Agent 可能在低质量循环中消耗大量资源,却无法真正解决问题。
反思校验器示例
下面是一个偏工程化的反思函数:规则先行,模型补充。真实生产中,可以把硬规则放在代码里,把语义判断交给 LLM 或评估模型。
python
def reflect(state: AgentState) -> dict[str, Any]:
issues: list[str] = []
suggestions: list[str] = []
successful_steps = {obs.step for obs in state.observations if obs.ok}
failed_tools = [obs.tool for obs in state.observations if not obs.ok]
# 1. 检查必要步骤是否缺失
required_steps = {"query_order", "query_payment", "query_callback"}
missing = required_steps - successful_steps
if missing:
issues.append(f"缺少必要查询步骤:{', '.join(sorted(missing))}")
suggestions.append("补齐查询,或在输出中明确说明证据不足")
# 2. 检查工具失败是否被处理
if failed_tools:
issues.append(f"存在失败工具调用:{', '.join(failed_tools)}")
suggestions.append("尝试备用数据源,或转人工处理")
# 3. 检查风险动作是否需要确认
if "refund.execute" in [obs.tool for obs in state.observations]:
issues.append("检测到高风险动作:退款执行")
suggestions.append("确认用户身份、金额阈值和审批状态后再执行")
# 4. 给出最终判定
passed = not issues
return {
"passed": passed,
"issues": issues,
"suggestions": suggestions,
"next_action": "answer" if passed else "repair_or_escalate",
}反思阶段最好输出明确的结构化结论,而不是一句"我检查过了"。例如:
json
{
"passed": false,
"issues": ["缺少支付流水查询", "回调服务查询失败"],
"suggestions": ["切换备用支付接口", "将结论降级为可能原因"],
"next_action": "repair_or_escalate"
}这类结构能直接驱动后续状态机:继续补查、降级回答、请求用户补充信息,或者转人工处理。
五、用 Mermaid 画出完整工作流
下面是一个可直接放进技术文档的流程图,展示 CoT、ReAct 和 Self-Reflection 如何组合成一个闭环。
#mermaid-svg-9cxTRMwiNTA4K0Zp{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-9cxTRMwiNTA4K0Zp .error-icon{fill:#552222;}#mermaid-svg-9cxTRMwiNTA4K0Zp .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-9cxTRMwiNTA4K0Zp .marker{fill:#333333;stroke:#333333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .marker.cross{stroke:#333333;}#mermaid-svg-9cxTRMwiNTA4K0Zp svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-9cxTRMwiNTA4K0Zp p{margin:0;}#mermaid-svg-9cxTRMwiNTA4K0Zp .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .cluster-label text{fill:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .cluster-label span{color:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .cluster-label span p{background-color:transparent;}#mermaid-svg-9cxTRMwiNTA4K0Zp .label text,#mermaid-svg-9cxTRMwiNTA4K0Zp span{fill:#333;color:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .node rect,#mermaid-svg-9cxTRMwiNTA4K0Zp .node circle,#mermaid-svg-9cxTRMwiNTA4K0Zp .node ellipse,#mermaid-svg-9cxTRMwiNTA4K0Zp .node polygon,#mermaid-svg-9cxTRMwiNTA4K0Zp .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .rough-node .label text,#mermaid-svg-9cxTRMwiNTA4K0Zp .node .label text,#mermaid-svg-9cxTRMwiNTA4K0Zp .image-shape .label,#mermaid-svg-9cxTRMwiNTA4K0Zp .icon-shape .label{text-anchor:middle;}#mermaid-svg-9cxTRMwiNTA4K0Zp .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .rough-node .label,#mermaid-svg-9cxTRMwiNTA4K0Zp .node .label,#mermaid-svg-9cxTRMwiNTA4K0Zp .image-shape .label,#mermaid-svg-9cxTRMwiNTA4K0Zp .icon-shape .label{text-align:center;}#mermaid-svg-9cxTRMwiNTA4K0Zp .node.clickable{cursor:pointer;}#mermaid-svg-9cxTRMwiNTA4K0Zp .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .arrowheadPath{fill:#333333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-9cxTRMwiNTA4K0Zp .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-9cxTRMwiNTA4K0Zp .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-9cxTRMwiNTA4K0Zp .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-9cxTRMwiNTA4K0Zp .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .cluster text{fill:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp .cluster span{color:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-9cxTRMwiNTA4K0Zp .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-9cxTRMwiNTA4K0Zp rect.text{fill:none;stroke-width:0;}#mermaid-svg-9cxTRMwiNTA4K0Zp .icon-shape,#mermaid-svg-9cxTRMwiNTA4K0Zp .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-9cxTRMwiNTA4K0Zp .icon-shape p,#mermaid-svg-9cxTRMwiNTA4K0Zp .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-9cxTRMwiNTA4K0Zp .icon-shape .label rect,#mermaid-svg-9cxTRMwiNTA4K0Zp .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-9cxTRMwiNTA4K0Zp .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-9cxTRMwiNTA4K0Zp .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-9cxTRMwiNTA4K0Zp :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 否
是
是
否
是
否
ReAct Loop
Reason
判断下一步
Act
调用工具/执行动作
Observe
解析结果
更新状态与证据
用户目标
任务解析
识别目标/约束/风险
CoT 规划
拆解子目标/缺失信息/执行顺序
是否信息充足?
询问用户或补查上下文
ReAct 执行循环
Self-Reflection
结果校验/过程复盘/风险检查
校验通过?
输出结论与证据
可自动修复?
降级回答或转人工
如果把它落成代码,通常会拆成三个层次:
- Orchestrator:负责任务生命周期和状态机;
- Agent Core:负责规划、工具选择和反思判断;
- Tool Layer:负责具体业务系统调用,并提供权限、超时、幂等和审计。
六、三者如何组合成可落地架构
在实际系统中,可以把 CoT、ReAct 和 Self-Reflection 放进一个统一执行框架。
第一步,任务理解。系统识别用户目标、业务类型、权限边界和风险等级。如果任务涉及高风险动作,例如退款、封禁、配置变更,需要预先标记为需确认流程。
第二步,CoT 规划。Agent 把任务拆成若干子目标,并生成初始执行计划。这里的输出最好是结构化对象,例如任务阶段、所需工具、预期结果、失败处理方式。
第三步,ReAct 执行。Agent 根据计划逐步调用工具,每一步都记录输入、输出、状态和异常。观察结果会反过来影响下一步行动。
第四步,Self-Reflection 校验。Agent 对最终结果和过程轨迹进行检查,判断是否满足业务规则、权限约束和质量标准。
第五步,输出或升级。如果结果可靠,就返回用户可执行的结论;如果存在缺口,就询问补充信息、降级为建议,或转人工处理。
一个简化的伪代码如下:
python
def run_agent(user_request: str, tools: dict[str, Tool]) -> str:
plan = build_order_plan(user_request)
if plan.risk_level == "high":
return "该任务涉及高风险动作,需要人工确认后继续。"
state = AgentState(
task=plan.task,
plan=[step.name for step in plan.steps],
)
state = run_react_loop(state, tools, max_steps=8)
review = reflect(state)
if review["passed"]:
return format_answer_with_evidence(state)
if review["next_action"] == "repair_or_escalate":
return format_degraded_answer(state, review)
return "当前证据不足,建议转人工处理。"这里最重要的工程原则是:不要把所有能力都压进一个提示词。提示词可以引导行为,但真正的可靠性来自状态机、工具协议、权限系统、审计日志和异常处理。
七、工程实践中的关键设计点
1. 把推理过程结构化,而不是纯文本化
如果 Agent 的中间步骤只是自然语言,后续很难审计和控制。更好的方式是把步骤拆成结构化字段,例如:当前目标、所需信息、工具名称、参数、返回摘要、置信度、下一步动作。
这能让系统做到可观测、可回放、可评估。出现错误时,团队可以定位是规划问题、工具选择问题、参数问题,还是结果判断问题。
2. 工具调用必须有边界
ReAct 让 Agent 能行动,但行动能力越强,风险越高。每个工具都应定义清楚输入约束、输出格式、权限范围、超时策略和幂等机制。
例如订单系统查询可以自动执行,但退款操作必须经过权限校验和用户确认;运维指标查询可以自动执行,但生产配置变更应进入审批流程。
3. 反思阶段要结合规则与模型
完全依赖模型反思并不稳定。更可靠的方式是规则优先、模型补充。业务硬约束用规则,例如金额阈值、身份校验、字段完整性;语义类质量判断用模型,例如解释是否清楚、建议是否与证据一致。
4. 控制循环次数和成本
CoT、ReAct、Self-Reflection 都会增加 token 与工具调用成本。系统需要设置预算,例如最多执行多少步、最多调用多少次外部工具、单任务最长运行多久。当预算耗尽时,应给出当前进展和可选下一步,而不是假装已经完成。
一个简单的预算对象可以这样设计:
python
@dataclass
class Budget:
max_steps: int = 8
max_tool_calls: int = 12
max_reflections: int = 2
max_tokens: int = 12000
def exceeded(self, steps: int, tool_calls: int, reflections: int, tokens: int) -> bool:
return (
steps > self.max_steps
or tool_calls > self.max_tool_calls
or reflections > self.max_reflections
or tokens > self.max_tokens
)5. 建立评估集
Agent 的评估不能只看回答是否流畅,而要看任务完成率、工具选择准确率、错误恢复率、越权拦截率和人工升级合理性。建议为客服、运维、风控等高频场景建立标准用例,持续回归测试。
评估指标可以包含:
| 指标 | 说明 |
|---|---|
| Task Success Rate | 是否完成用户目标 |
| Tool Accuracy | 工具选择和参数是否正确 |
| Evidence Coverage | 结论是否有足够证据支撑 |
| Recovery Rate | 工具失败后是否能恢复 |
| Policy Violation Rate | 是否发生越权、错误承诺、违规动作 |
| Escalation Quality | 需要人工时是否说明清楚原因 |
八、一个通用业务示例:异常订单处理 Agent
假设某平台有一个异常订单处理 Agent,目标是协助一线人员判断订单异常原因并给出处置建议。
用户输入:客户反馈已付款,但订单仍显示待支付。
CoT 阶段,Agent 先拆解任务:需要验证订单归属、查询订单状态、查询支付流水、比对支付时间和回调状态、判断异常类型。
ReAct 阶段,Agent 开始行动。第一步调用订单查询工具,发现订单状态为待支付;第二步调用支付流水工具,发现支付通道显示成功;第三步查询回调记录,发现回调接口返回 500;第四步查询近半小时接口错误率,发现回调服务在某个时间窗口异常升高。
Self-Reflection 阶段,Agent 检查结论是否有证据支撑:订单状态、流水状态、回调失败记录、服务异常指标均存在。因此它可以给出较高置信度判断:该问题可能由支付回调处理失败导致。然后根据业务规则,它建议重试回调,并提示如果重试失败则转人工处理。若重试回调属于高风险动作,系统应要求操作人员确认后再执行。
这个例子体现了三者的分工:CoT 负责拆问题,ReAct 负责查事实,Self-Reflection 负责防止错误结论和越权动作。
九、常见误区
第一个误区是把 CoT 当成万能提示词。复杂任务需要真实数据和流程控制,不能只靠模型内部推理。
第二个误区是让 ReAct 无限调用工具。没有预算和状态管理的 Agent,很容易陷入重复查询和无效尝试。
第三个误区是把 Self-Reflection 做成形式化复述。反思阶段必须有可检查的标准,否则只是多消耗一次模型调用。
第四个误区是忽略权限和审计。Agent 一旦接入业务工具,就必须遵守最小权限原则,并保留完整执行轨迹。
第五个误区是把中间推理原样暴露给用户。工程系统应该展示关键步骤、证据和结论,而不是把模型的全部隐式推理链直接输出。这样既能提升透明度,也能减少提示词泄露和不必要的误导。
十、落地建议
如果团队刚开始建设 Agent,不建议一上来追求完全自治。更稳妥的路径是分三步走。
第一阶段,先做只读型 Agent,让它能查询数据、汇总信息、给出建议,但不直接执行高风险动作。
第二阶段,引入受控行动能力,对低风险、可回滚、幂等的动作开放自动执行,对高风险动作保留确认机制。
第三阶段,引入系统化反思和评估,让 Agent 能根据规则和历史轨迹自检,并在不确定时主动降级。
从产品角度看,Agent 不一定要表现得像一个全能助手。更重要的是让用户知道它当前完成了哪些步骤、依据是什么、哪里不确定、下一步需要谁确认。透明度本身就是可靠性的一部分。
总结
CoT、ReAct 与 Self-Reflection 分别解决 Agent 落地中的三个核心问题:如何拆解复杂任务,如何基于真实世界行动,如何发现并修正错误。它们组合起来,才能让 Agent 从简单问答系统升级为可执行、可审计、可控的业务协作系统。
真正可用的 Agent,不是永远回答得很自信,而是在信息不足时会补查,在行动受限时会确认,在结果可疑时会复盘,在风险过高时会升级。对应用开发者、产品经理和架构师来说,建设 Agent 的关键不是追逐某个单点技巧,而是把推理、行动、反思和治理放进同一个工程闭环。