运行在每一个 Pull Request 上的 Agentic Workflow,可能会在不知不觉中累积出高昂的 API 成本。本文将介绍我们如何对生产环境中的工作流进行埋点分析、发现其中存在的低效问题,并构建智能体来自动修复这些问题。
作者:Landon Cox & Mara Kiefer
排版:Alan Wang

GitHub Agentic Workflows 就像一支负责街道清洁的团队,会不断清理代码仓库中的各种"小问题"。这些团队能够显著提升仓库的整洁度和代码质量,但与所有智能体工作一样,成本正逐渐成为开发者关注的重点。而且,由于 Agentic Workflows 这类 CI 作业会被自动调度和自动触发,其产生的成本往往会在不知不觉中持续累积。
幸运的是,相较于优化开发者交互式桌面会话,提高自动化工作流的效率要容易得多。开发者会话中的工作内容通常难以预测,而 Agentic Workflows 的工作则完全由 YAML 文件定义,并且每一次执行都会重复相同的流程。
由于我们既是 GitHub Agentic Workflows 的维护者,也是其在自身 GitHub 仓库中的使用者,因此我们和用户一样,同样关注 Token 的使用效率。正因如此,我们于 2026 年 4 月 开始,系统性地优化许多日常依赖工作流的 Token 消耗。本文将介绍我们进行了哪些埋点监控、采用了哪些优化策略,以及目前取得的初步成果。
记录 Token 使用情况
我们的代码仓库依赖数百个 Agentic Workflow 来完成维护工作和 CI 流程。所有工作流都以 GitHub Actions 的形式运行,并受到真实 API 速率限制的约束。我们一边驾驶着飞机,一边还在建造它;与此同时,也在不断消耗着喷气燃料。
在能够优化 Token 消耗之前,我们首先需要了解 Token 是如何被消耗的。我们遇到的第一个挑战是,不同的智能体框架(Claude CLI、Copilot CLI、Codex CLI)输出的日志格式各不相同,而且历史运行的使用数据可能并不完整。幸运的是,agentic-workflows 的安全架构使用了一个 API 代理,用于防止智能体直接访问认证凭据。这个代理让我们能够以统一、标准化的格式捕获所有运行过程中的 Token 使用情况,而无需关心底层使用的是哪一种智能体框架。
现在,每一个工作流都会输出一个 token-usage.jsonl 工件。其中,每一次 API 调用都会对应一条记录,包含以下信息:
-
输入 Token
-
输出 Token
-
缓存读取 Token
-
缓存写入 Token
-
模型
-
服务提供商
-
时间戳
将这些数据与工作流中的其他日志结合起来,我们便能够获得 Token 通常如何被消耗的历史视图,并据此对未来的运行进行优化。
用工作流优化工作流
有了 Token 数据之后,我们构建了两个每天运行一次的优化工作流。
一个名为 Daily Token Usage Auditor 的工作流,会读取最近工作流运行产生的 Token 使用工件,按照工作流聚合 Token 消耗情况,并生成一份结构化报告。它的职责包括:
-
标记近期 Token 消耗显著增加的工作流;
-
找出成本最高的工作流;
-
记录异常运行情况(例如,一个通常只需要 4 次 LLM 对话即可完成的工作流,这次却执行了 18 次)。
当 Auditor 标记出某个工作流之后,另一个名为 Daily Token Optimizer的工作流,会分析该工作流的源码以及最近的运行日志,自动创建一个 GitHub Issue。Issue 中会描述具体存在的低效问题,并提出针对性的优化建议。Optimizer 已经帮助我们发现了许多原本可能会被忽略的低效点。
当然,Auditor 和 Optimizer 本身也是 Agentic Workflow。它们自己的 Token 消耗同样会出现在每日报告中,从而形成一个小型的正向循环。
消除未使用的 MCP 工具
根据 Auditor 和 Optimizer 的初步分析结果,最常见的一类低效问题就是:注册了未使用的 MCP 工具。
由于 LLM API 是无状态的,智能体运行时通常会在每一次请求中附带 MCP 工具的函数名称以及对应的 JSON Schema。实际上,这意味着:完整的工具集合都会成为每一次调用上下文的一部分。
以一个拥有 40 个工具的 GitHub MCP Server 为例,每一次对话都会额外增加约 10--15 KB 的 Schema 数据。如果智能体实际上只使用了其中两个工具,那么剩下的 38 个工具就完全属于每一次请求都会携带的额外开销。
工作流作者通常会直接启用完整工具集,因为这是阻力最小的方式,而智能体可以自行判断需要使用哪些工具。但是随着时间推移,大多数工作流最终都会稳定依赖于一小部分固定工具。Optimizer 会通过对比工具清单与实际工具调用记录,识别出这种模式,并建议从配置中移除那些未使用的工具。
在我们的 Smoke Test 工作流中,从 MCP 配置中移除未使用工具之后,每次调用的上下文大小减少了 8--12 KB,每次运行节省了数千个 Token,而工作流的行为完全没有发生变化。
使用 GitHub CLI 替代 GitHub MCP
移除未使用的 MCP 工具,是一种相对简单的优化收益。而更大的结构性优化机会,则来自于:将获取 Pull Request Diff、文件内容以及 Review 评论等数据获取操作,从 GitHub MCP 调用替换为 GitHub CLI 调用。
这种改动带来的收益,并不仅仅是减少了未使用工具带来的额外开销。原因在于,一次 MCP 工具调用不仅仅是一次数据获取操作,它本身还是一次推理步骤。智能体必须决定是否调用这个工具,构造调用参数,并将工具返回结果作为上下文的一部分接收回来。这意味着一次完整的 MCP 工具调用,本质上就是一次完整的 LLM API 往返调用。它会消耗工具调用 JSON Schema 对应的 Token,参数块对应的 Token,返回结果对应的 Token。相比之下,执行 gh pr diff 则只是一次确定性的 HTTP 请求,直接调用 GitHub REST API,整个过程完全不需要 LLM 参与。
为了完成这一迁移,我们采用了两种策略。
Agent 运行前的数据预下载 。对于智能体一定会使用到的数据,例如 Pull Request Diff 或变更文件列表,我们在工作流中增加了初始化步骤。在智能体启动之前,先执行 gh 命令,并将获取到的数据写入工作区文件。随后,智能体直接读取这些文件,而不是发起 MCP 调用。这种方式既消除了工具调用的额外开销,又能够充分利用智能体在 Bash 脚本方面的大量训练经验,高效处理这些数据。
Agent 内部 CLI 代理替换。 对于那些需要智能体在运行时自行决定获取哪些数据的场景,预下载并不可行。在这种情况下,我们采用了一个轻量级透明 HTTP 代理。它负责将 CLI 请求转发到 GitHub API 服务器,同时不会向智能体暴露认证 Token。智能体执行 gh pr view --json即可像开发者在终端中操作一样,获得结构化的数据返回结果。这种方式在不破坏智能体无密钥安全要求的前提下,降低了 Token 消耗。
综合来看,这两种技术将绝大多数 GitHub 数据获取操作,从 LLM 推理循环中移了出来。
衡量效率提升并非易事
当我们开始优化工作流之后,很快遇到了一个更加微妙的问题:如何判断一次改动究竟让工作流变得更高效了,还是仅仅让它完成了更少(甚至可能更差)的工作?
这里存在三个容易混淆判断的因素。
并不是所有 Token 都是等价的。 在 Claude Haiku 和 Claude Sonnet 上运行同一个工作流,产生的 Token 数量可能非常接近,但成本却相差很大。Haiku 的单 Token 成本大约只有 Sonnet 的 1/4,因此,一个切换模型的工作流,在原始 Token 数量上看起来几乎没有变化,却可能已经实现了显著的成本降低。为了消除这种影响,我们引入了 Effective Tokens(ET,有效 Token) 指标,对不同类型的 Token 应用模型成本系数:
plain
ET = m × (1.0 × I + 0.1 × C + 4.0 × O)其中:
-
m 表示模型成本系数(Haiku = 0.25×,Sonnet = 1.0×,Opus = 5.0×);
-
I 表示新处理的输入 Token;
-
C 表示缓存读取 Token;
-
O 表示输出 Token。
输出 Token 被赋予 4 倍权重,因为在所有主流模型提供商中,它们都是成本最高的一类 Token。缓存读取 Token 则只赋予 0.1 倍权重,因为它们来自缓存,其成本仅为重新处理输入的一小部分。通过这一公式,我们能够对不同模型层级之间的 Token 消耗进行归一化。因此,无论使用哪一种模型,ET 降低 10% 都意味着真实成本降低了 10%。
我们的工作负载来自一个持续演进的真实代码仓库。 据我们所知,目前并不存在一个可用于优化 Token 使用情况的 Agentic Workflow 基准测试。当我们开始分析工作流的 Token 消耗时,发现一次运行可能只处理一个五行代码的修复,而下一次运行则可能处理一个包含 200 行改动的 Pull Request。前者自然会消耗更少的 Token,但这种差异并不是效率突然提高造成的。原始 Token 数量很容易将工作负载变化与效率波动混淆在一起。因此,我们尝试同时跟踪 LLM API 调用次数 和 Token 数量 来进行归一化分析:如果每次运行的 LLM 对话轮数保持稳定,而每次调用消耗的 Token 数下降,则说明效率确实得到了提升。如果两者同时下降,则可能意味着工作流只是完成了更少的工作。
质量是否发生了变化? 这是最难评估的问题。采用更轻量级的模型,并运行一个约束更多的工作流,可能会导致输出质量下降。因此,我们使用流程层面的信号来近似衡量质量,包括:每次 LLM 调用产生的输出 Token 数,每次运行的对话轮数,工具调用完成率。对于我们优化后的 Smoke Copilot 工作流而言,即使 Token 消耗持续下降,上述三个指标在整个优化期间都保持稳定。无论优化前还是优化后,该工作流每次运行大约都会完成 5 次 LLM 对话。当然,这些都是流程信号,而不是结果信号。由于不存在一个可以作为标准答案的"正确性",我们无法直接观察输出质量究竟是提升了、下降了,还是保持不变。要衡量"每单位正确工作所消耗的 Token 数",还需要更多的埋点能力和进一步的研究。
初步结果
在 gh-aw 和 gh-aw-firewall 两个代码仓库中的十几个生产工作流部署 Auditor 和 Optimizer 之后,我们下载了每个工作流优化前后的 token-usage 工件,并计算了每次运行对应的 ET 值。12 个工作流中,有 9 个采纳了 Optimizer 推荐的优化方案。本文仅展示那些在优化前后阶段都至少运行了 8 次的工作流结果。它们包括:
-
Auto-Triage Issues
-
Daily Compiler Quality
-
Community Attribution
-
Security Guard
-
Smoke Claude
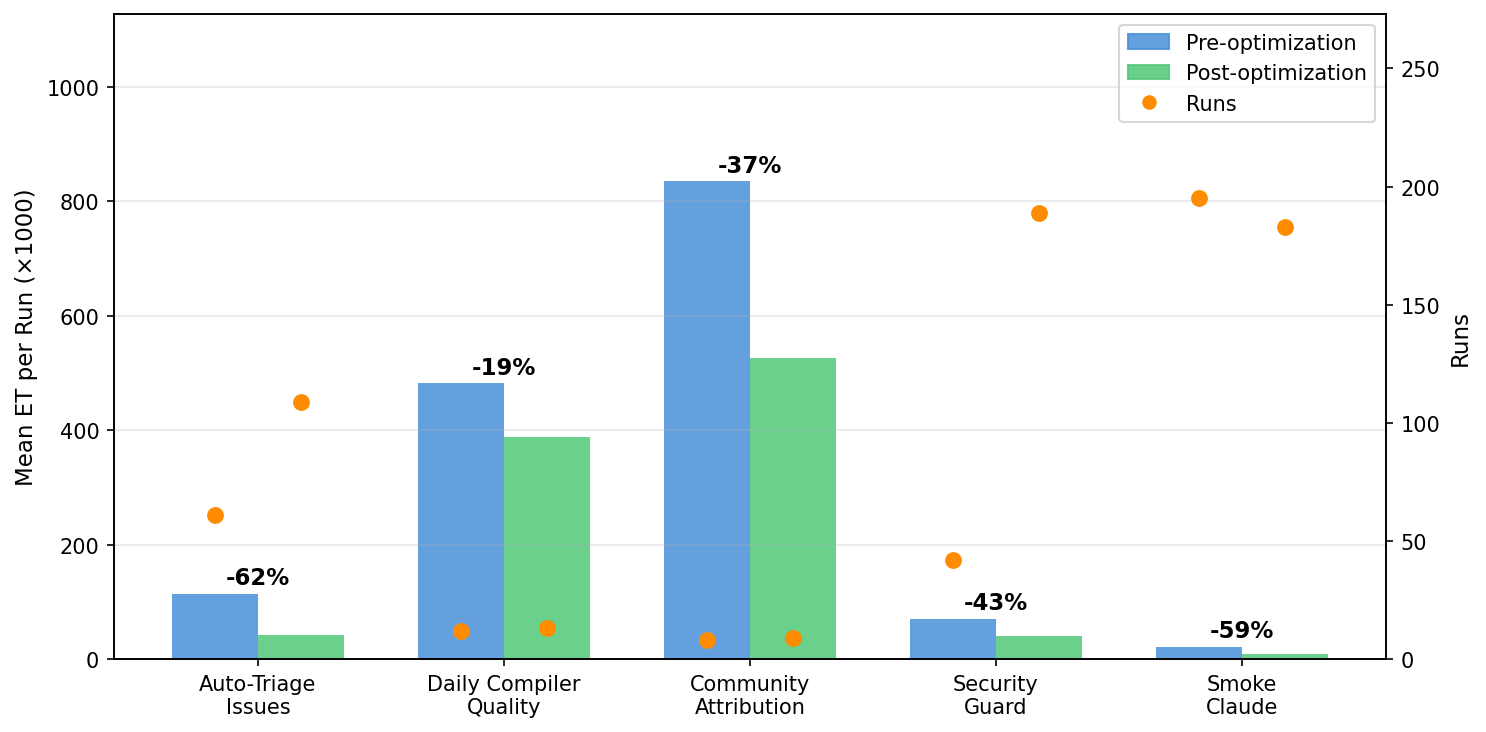
Auto-Triage Issues 在修复后的 109 次运行 中,实现了持续且明显的 62% 降幅。Daily Compiler Quality 在修复后的 12 次运行 中,实现了 19% 的提升。
Daily Community Attribution 在修复后的 8 次运行 中,实现了 37% 的提升。在 gh-aw-firewall 仓库中,负责审计每一个 Pull Request 是否包含安全敏感修改的 Security Guard,以及用于验证 Firewall Claude CLI 路径的集成测试 Smoke Claude,拥有最多的修复后运行次数,分别实现了 43% 和 59% 的优化效果。
运行频率的重要性,与单次运行节省的成本同样重要。Auto-Triage Issues 会在每一个新 Issue 创建时触发,平均每天运行 6.8 次,最高可达 15 次。而 Daily Compiler Quality 最多每天只运行一次。62% 的节省 配合 每天 6.8 次运行 的频率,会快速形成累计效应。按照优化前的消耗水平计算,在整个观察期间,Auto-Triage 的优化累计节省了约 780 万 ET(7.8 M ET)。而 Security Guard 和 Smoke Claude 的运行频率甚至更高。因此,在决定优先优化哪些工作流时,运行频率与单次运行消耗同样重要。
需要特别说明的是,智能体提出的每一项优化建议,并不一定都会转化为可测量的 ET 节省。尤其是在真实代码仓库中,工作负载每天都在变化,而观察窗口又较短的情况下,这一点更加明显。例如,Contribution Check 工作流的 ET 实际增加了 5%,我们将在后文对这一现象进行更详细的讨论。
总结
基于这些结果,我们总结出了三个规律。
许多智能体执行轮次实际上都是确定性的数据获取过程。 Auto-Triage Issues 在 gh-aw 中取得了最显著且持续的优化效果(修复后的 109 次运行中降低了 62%),因为这次优化消除了结构性的低效问题:大量智能体执行轮次都花费在无需推理的数据读取上,例如获取 Issue 元数据和扫描标签。将这些读取操作移动到智能体启动之前,由预处理 CLI 步骤完成,使它们完全脱离了 LLM 推理循环。同样的模式也带来了 gh-aw-firewall 中 Security Guard 工作流 43% 的成本下降:现在,一个相关性判断会先进行筛选,对于那些没有涉及安全敏感文件的 Pull Request,直接跳过 LLM。最便宜的 LLM 调用,就是根本不发生的调用。
Contribution Check 展示了一个容易混淆判断的因素:其中 82%--83% 的输入 Token 都来自缓存读取,也就是数据获取过程,但平均 ET 却增加了 5%。造成这一现象的原因并不是优化失败,而是工作负载发生了变化:在优化之前,有 41% 的运行处理的是小型 Pull Request(ET < 100K),有 39% 的运行处理的是大型 Pull Request(ET > 300K);而优化之后恰逢一次开发活动高峰,工作流处理的 Pull Request 中只有 9% 属于小型 Pull Request,却有 65% 属于大型 Pull Request。由于 ET 公式中输出 Token 具有 4 倍权重,随着智能体需要审查更大的 Diff,输出 Token 增加了 14%。优化很可能确实提升了每一次执行轮次的效率,只是工作负载整体变重,掩盖了这种提升在总体数据中的表现。
未使用的工具,会带来昂贵的成本。 在未纳入统计结果的 gh-aw 工作流中,Glossary Maintainer 是一个很有代表性的案例。一个名为 search_repositories 的工具,在一次运行中被调用了 342 次,占全部工具调用次数的 58%,然而对于一个只需要扫描本地文件变更的工作流来说,它其实完全没有必要。Optimizer 给出的建议就是将它从工具集中移除。在 gh-aw-firewall 中,Smoke Claude 实现了 59% 的成本下降,其中部分原因正是对 MCP 工具进行了大幅裁剪,并同时切换到了 Haiku 模型层级。Daily Community Attribution 工作流则说明了这种优化方式的局限性:它配置了 8 个 GitHub MCP 工具,但整个运行过程中一次都没有调用这些工具,然而将它们移除之后,ET 并没有下降。这是因为工具清单只占整个工作流上下文的一小部分。
一个配置错误的规则,就可能导致失控的循环。 同样是在未纳入统计结果的工作流中,Daily Syntax Error Quality 在优化之前是整个项目 ET 最高的工作流。问题的根源只是一个一行代码的配置错误:该工作流会先将测试文件复制到 /tmp/,然后调用 gh aw compile*,但沙箱环境中的 Bash Allowlist 只允许使用相对路径的 Glob 模式,因此每一次编译尝试都会被阻止。由于无法使用自己所需的工具,智能体陷入了一个持续 64 个执行轮次 的回退循环,在这个循环中,它只能手动读取源代码来重建编译器原本会告诉它的信息。只需修改 Allowlist 中允许的 Bash Pattern,这个循环便被彻底消除。虽然我们没有足够的优化前基线运行数据来精确量化改进幅度,但这种异常模式十分明显,而修复方案也毫无歧义。
接下来是什么?
我们目前用于优化工作流的工具,包括 API 级可观测性、自动化审计工作流、MCP 工具裁剪以及 CLI 替代方案,如今都已经集成在 GitHub Agentic Workflows 框架中。另一个即将推出的优化方向,是将单体智能体重构为由多个子智能体组成的团队,并采用规模更小、成本更低的模型。
下一步,我们希望从工作流级优化迈向系统级优化。一次工作流运行实际上并不是一条平坦的 API 调用序列,而是由多个不同的阶段组成,例如收集上下文、读取工件、失败后的重试,或者生成最终答案。当你能够清晰地识别这些阶段之后,就能够提出更有价值的问题:究竟是哪一个阶段导致了成本过高?哪些阶段主要是在重复工作、阻塞等待或者失败重试?哪些阶段根本不应该由智能体完成,而应该改造成确定性的预处理步骤?
同样的逻辑也适用于整个工作流组合层面。一个代码仓库并不是只运行一个工作流,而是运行着一整套 Agentic Automation,它们往往会响应同样的事件、检查相同的 Diff 和日志,并得出相互关联的判断。这意味着,成本不仅仅是单个工作流的属性,也来自整个工作流组合中的重复工作。因此,我们下一步希望开展的是组合层面的分析:哪些工作流在重复读取相同的数据,哪些工作流应该合并,哪些共享的中间结果应该被缓存,而不是由每一次运行重新发现。
这些开放问题确实非常困难。对于 Agentic CI Workflow 来说,要衡量 Goodput,仍然需要目前尚未大规模存在的结果级埋点;而要理解阶段效率和组合效率,也需要比当前大多数系统所采集到的更丰富的谱系数据。但这正是未来最重要的发展方向。代理层可观测性和优化器工作流已经改变了我们开发和部署新的 Agentic Automation 的方式。现在,我们从第一天开始就加入 Token 监控,而不是事后再补充;同时,我们越来越多地从整个自动化工作流组合的角度思考哪些工作可以避免,而不仅仅关注某一次运行是否成本过高。
如果你正在 CI 中运行 Agentic Workflow,并且想知道自己是否花费了超过实际需要的成本,那么第一步与我们完全相同:添加 API Proxy,开启日志记录,让数据告诉你应该从哪里开始优化。
如果你希望使用本文介绍的这些工作流,只需要通过 gh-aw CLI 将它们添加到自己的代码仓库即可:
plain
gh extensions install github/gh-aw
gh aw add githubnext/agentic-ops/copilot-token-audit githubnext/agentic-ops/copilot-token-optimizer将它们与现有 CI 一起运行,可以立即获得 Token 使用情况的可见性,并帮助你持续优化工作流。
我们也非常希望了解其他团队是如何解决这一问题的。欢迎在社区讨论中分享你的想法,或者加入 GitHub Next Discord 的 #agentic-workflows 频道参与交流。