有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。
电影数据采集、清洗建模、可视化分析与 Flask 平台展示
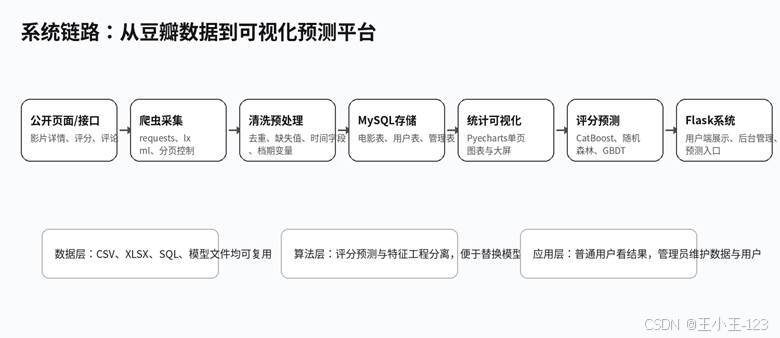
图1-1 系统整体链路示意
1 项目效果速览
这套系统围绕豆瓣电影数据展开,把数据采集、字段清洗、统计分析、可视化页面、评分预测和 Web 系统集成到一条完整链路里。前期通过爬虫获取影片基础信息、评分、评价人数、上映时间、片长、类型、国家、语言等字段,同时额外采集热门影片的长评和短评,用于词云展示和文本侧观察。处理后的数据进入 CSV、XLSX、SQL 和 MySQL 数据库,既方便离线分析,也方便系统端读取。
整体展示不只是单个训练脚本,而是从数据到系统的完整小闭环:一边可以看到评分区间、类型占比、导演数量、国家语言分布、上映时间变化等图表,一边可以将清洗后的特征送入机器学习模型做评分预测。对学生项目来说,这种"爬虫 + 数据分析 + 机器学习 + Flask 系统"的组合更容易体现工程完成度,答辩时也有足够多的图表和页面可以展示。
我在整理资料时重点保留了系统能直接看见的内容:爬虫运行效果、清洗后的数据样例、多维可视化图表、词云图、模型评价指标、预测值与真实值对比、项目目录结构和系统模块。具体的数据集、完整源码、数据库导入命令、模型文件和部署细节没有在这里全部展开,项目资源可以单独沟通。
图1-2 豆瓣影评采集运行效果
2 数据采集与字段设计
数据采集部分主要由三类脚本组成:第一类抓取影片基础数据,第二类抓取指定影片长评,第三类抓取短评。影片数据覆盖 movie_id、movie_name、director、juqing、country、language、push_time、movie_long、pingfen、pingjiarenshu 等字段,后续又从演员字段中提取演员数量,并从上映时间中拆出 year、month、day、week 等时间维度。
爬虫脚本使用 requests、urllib、lxml、正则表达式、CSV 写入等常见技术,核心逻辑包括分页访问、链接提取、详情页解析、字段规整和本地落盘。长评和短评部分围绕热门影片《哪吒之魔童闹海》展开,长评数据约 6950 条,短评数据约 400 条,字段包含评论者、星级、时间、IP 属地、有用数和评论正文。文本数据不直接参与所有结构化建模,但非常适合做关键词词云,作为影片口碑展示的补充。
采集后的原始数据不是直接进入模型,而是先经过字段校验和格式统一。比如片长字段需要去掉"分钟",上映时间需要统一成日期格式,导演、国家、语言等类别字段需要保留为后续建模可用的特征。这样处理之后,数据既能支撑统计分析,也能进入数据库和 Web 系统,避免"图表能做、系统不能用"的割裂。
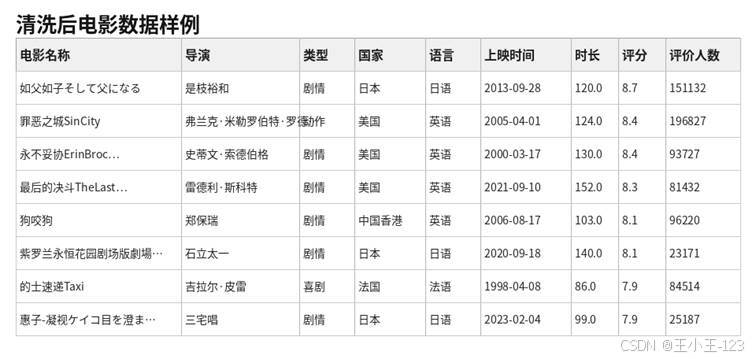
图2-1 清洗后的电影数据样例
3 清洗预处理与特征工程
数据预处理使用 Pandas 和 Numpy 完成,重点解决三类问题。第一类是字段可用性问题,例如去掉不适合建模的封面链接、简介长文本等展示字段,把演员列表转化为演员数量;第二类是数值化问题,例如将片长从字符串转换为分钟数,将评价人数、评分等字段整理成模型能直接读取的格式;第三类是时间特征问题,把上映时间拆成年、月、日、星期,便于观察年度趋势、月份分布和上映节奏。
比较有展示价值的是档期变量设计。项目把元旦、春节、清明、劳动、端午、中秋、国庆、暑期档、圣诞节、白色情人节等时间窗口映射成 period 字段,用来刻画影片上映时点可能带来的关注度差异。这个处理比单纯使用日期更接近真实业务场景,也能让后面的评分预测和可视化分析更有解释空间。
清洗后的主数据表大约保留 13934 条电影记录,字段围绕影片属性、口碑指标和时间属性展开。另有影评、短评、词云文本、SQL 脚本、XLSX 文件和模型文件共同组成项目资源包。这样的资源组织方式比较清楚:原始数据用于追溯,预处理数据用于建模,可视化 HTML 用于展示,Flask 工程用于系统落地。
4 多维可视化展示
可视化部分使用 Pyecharts 生成单页 HTML 图表和大屏页面。图表维度比较完整,既有评分区间分布、类型占比、导演数量 Top20,也有 9 分以上电影的国家占比、不同类型平均分、国家评分趋势、中国/日本/美国电影 Top10、电影时长占比、语言分布、年份片量、月份上映占比、评价人数 Top10 等内容。
从展示效果看,评分主要集中在 6 到 9 分之间,低分影片占比相对较少;类型上剧情片数量明显更多,喜剧、动作、动画、爱情等类型也有较高占比;国家和语言维度可以直观看到不同地区影片数量和口碑差异;时间维度则适合展示电影产量变化、档期分布和上映节奏。
这些图表的作用不只是"好看"。在建模之前,它们可以帮助判断哪些字段可能与评分、热度相关;在系统展示时,它们可以让用户直接看到数据规律;在答辩或项目演示时,多图组合也能快速体现工作量和完成度。
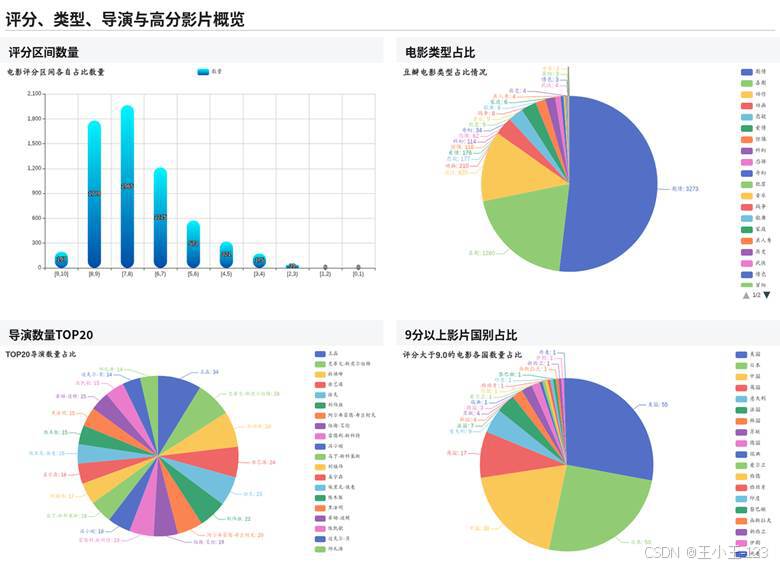
图4-1 评分、类型、导演与高分影片概览
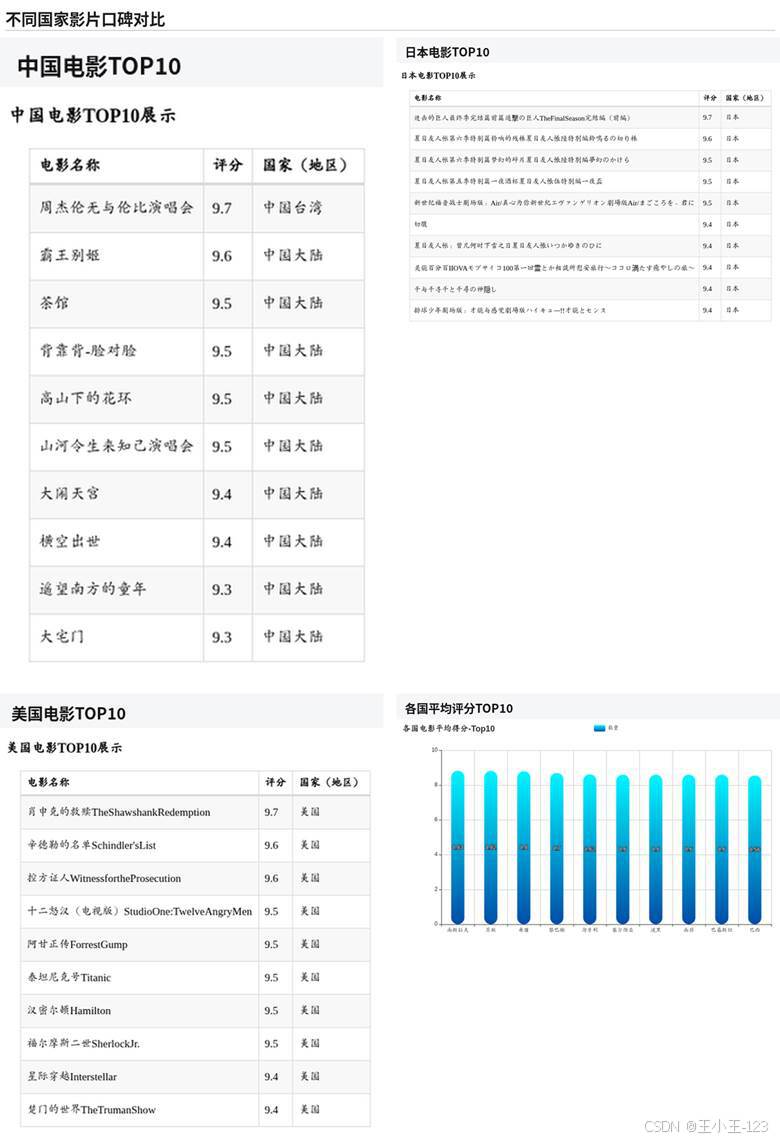
图4-2 不同国家影片口碑对比
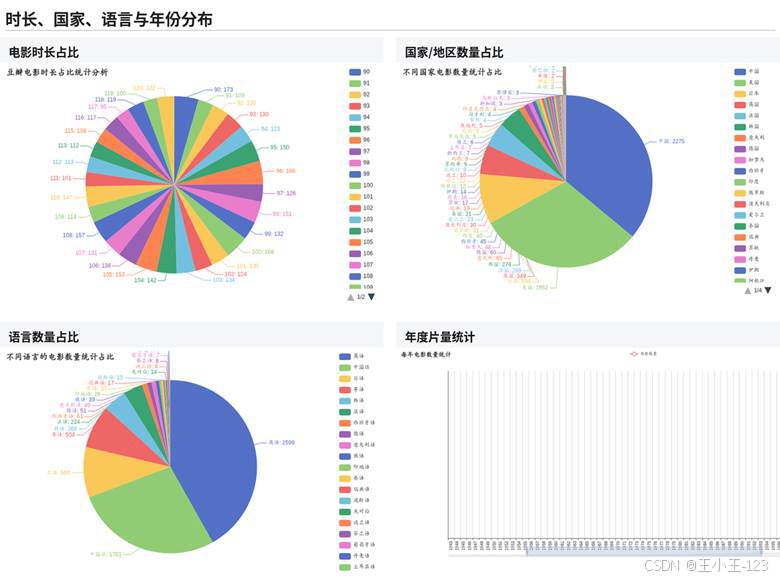
图4-3 时长、国家、语言与年份分布
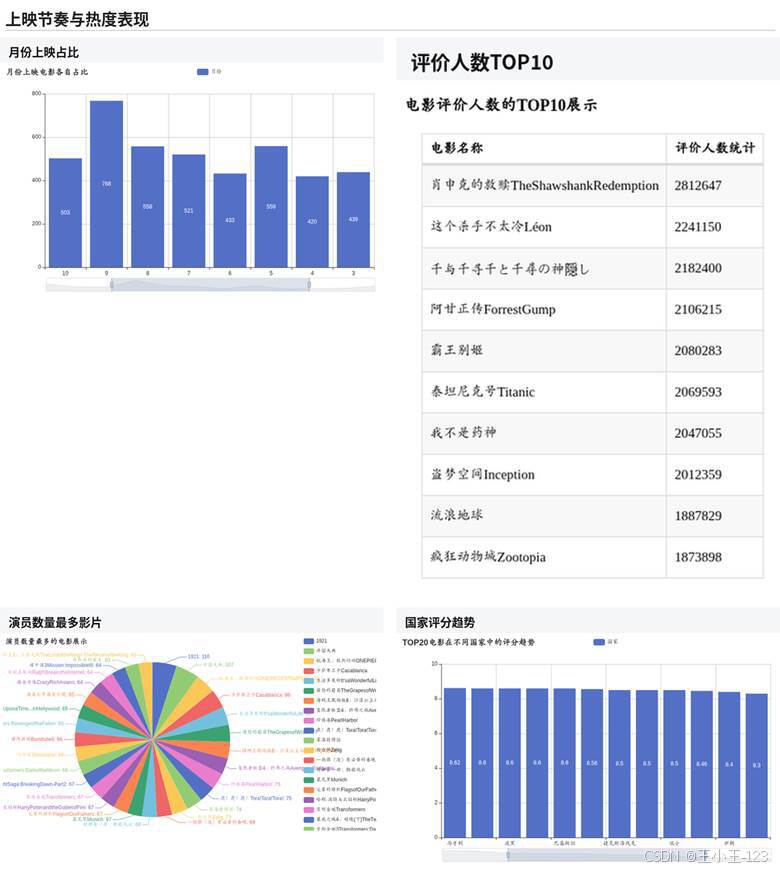
图4-4 上映节奏与评价热度分析
5 评论文本与词云分析
除了结构化电影数据,项目还加入了影评和短评文本。处理流程是先把评论文本单独导出,再结合停用词库进行分词和高频词统计,最后用词云图展示观众讨论重点。长评更偏观点展开,短评更偏即时反馈,两类文本放在一起看,可以对影片口碑形成补充判断。
以热门影片评论为例,词云中可以看到观众围绕人物、剧情、价值表达、观影感受等关键词展开讨论。这部分不需要把每一条评论逐字列出来,只要把高频词、情绪倾向和典型关注点展示出来,就能让读者快速理解"大家在讨论什么"。对于电影评分预测系统而言,文本侧展示也能弥补单纯数值分析的不足。
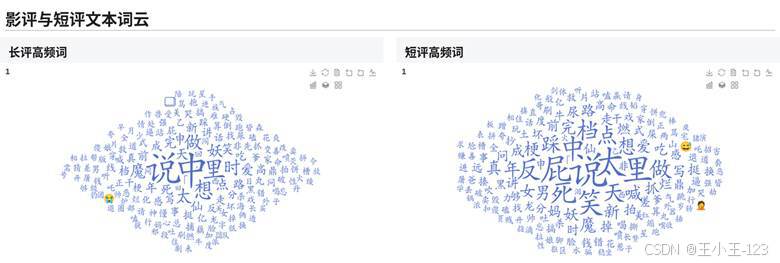
图5-1 影评与短评词云展示
6 评分预测模型
模型部分主要围绕电影评分预测展开。处理后的数据以 pingfen 作为目标值,其他字段作为输入特征。项目先使用 CatBoost 建立基线预测模型,再对线性回归、决策树、随机森林、梯度提升回归等模型进行统一训练和对比,评价指标包括 MSE、MAE、RMSE 和 R²。
从结果看,线性回归的 R² 约为 0.4388,说明电影评分与特征之间并不是简单线性关系;决策树能够捕捉非线性模式,但稳定性不足;随机森林在优化后表现更好,R² 约为 0.8708,RMSE 约为 0.4848;梯度提升回归优化后 R² 约为 0.7905。整体上,集成学习模型更适合处理这种多类别、多时间维度、多属性交互的数据。
CatBoost 的优势在于对类别特征较友好,不需要做过多手工编码,适合电影类型、国家、语言、档期等字段较多的场景。预测值与真实值对比图显示,大部分样本能较好贴合评分变化,但极端低分或高分影片仍然存在一定误差,这也符合电影口碑数据主观性强、影响因素复杂的特点。
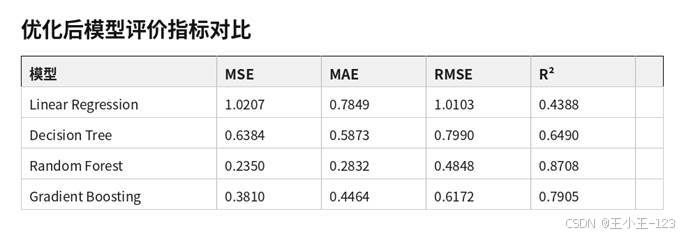
图6-1 不同模型评价指标对比
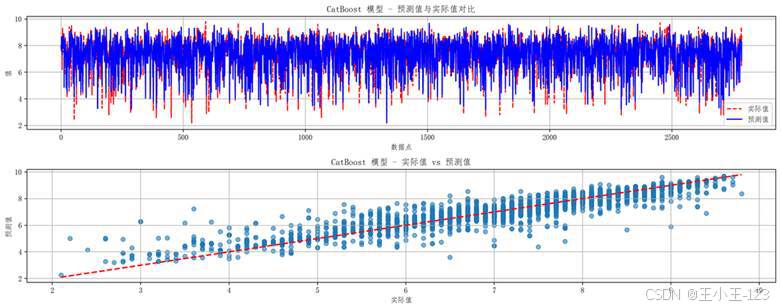
图6-2 CatBoost 模型预测值与真实值对比
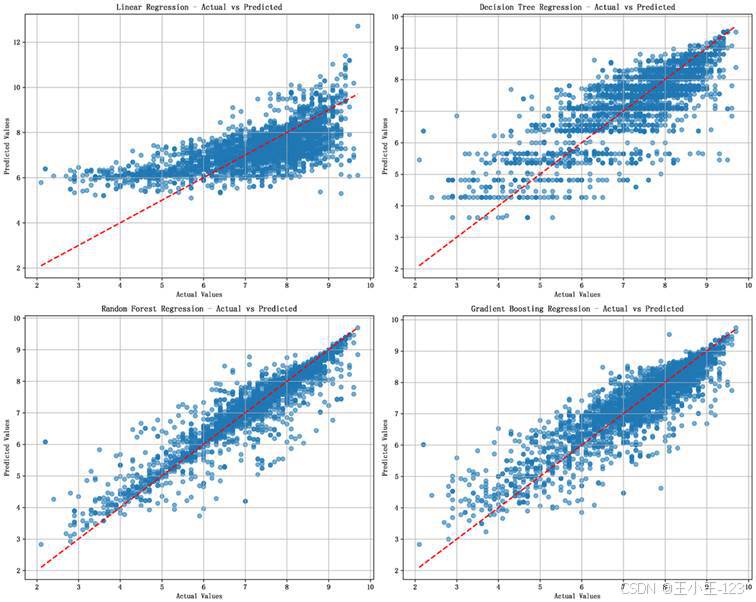
图6-3 多模型真实值与预测值散点对比
7 Flask 系统实现
系统端使用 Flask 搭建,前端页面包含登录、注册、普通用户主页、管理员主页、数据列表、用户管理、个人中心、可视化单页、大屏页面和评分预测入口。数据库使用 MySQL,封装 MysqlHelper 负责查询和执行 SQL。普通用户进入系统后可以查看可视化结果和预测页面,管理员可以维护电影数据、用户信息和后台功能。
Flask 路由中包含登录校验、用户信息查询、个人资料修改、管理员信息查询、电影数据管理、用户管理和预测相关接口。前端使用 HTML、CSS、JavaScript 和 Layui 风格组件组织页面,Pyecharts 生成的图表 HTML 被整合到系统菜单中,形成"单页图表 + 大屏展示 + 后台管理"的结构。
这种设计对部署比较友好:数据导入 MySQL 后,Flask 负责路由和页面渲染,静态图表和大屏页面可以直接作为展示资源,模型文件可以通过接口读取。后续如果要升级,也可以继续增加推荐模块、评论情感分析、票房特征、电影海报特征或在线模型预测服务。

图7-1 系统端功能模块整理

图7-2 项目目录与资源结构
8 技术亮点与适用场景
第一,链路完整。项目不是只做一张图,也不是只训练一个模型,而是把爬虫、清洗、可视化、模型和系统端串起来,最后能够形成可展示、可运行、可扩展的工程包。
第二,展示维度丰富。评分、类型、导演、国家、语言、时长、年份、月份、评价人数、文本词云都有对应图表,适合在答辩、课程设计、毕设演示和项目论坛中展示。
第三,模型对比清楚。项目没有只给出一个模型结果,而是把线性模型、树模型和集成学习模型放到同一评价口径下对比,再通过可视化图展示预测效果,能体现基本的数据挖掘流程。
第四,系统落地感强。Flask、MySQL、Pyecharts、模型文件、静态页面和后台管理同时出现,让项目不止停留在 Notebook 阶段,也具备继续包装成完整应用的基础。
适用场景上,这套系统可以用于数据分析课程设计、Python 爬虫综合实训、机器学习回归预测、电影数据可视化展示、Web 可视化平台开发、毕业设计选题包装等方向。如果后续继续扩展,可以加入票房、宣发热度、演员影响力、评论情感、海报特征和推荐算法,让系统从"评分预测"进一步走向"电影决策辅助"。
9 环境与运行说明
开发环境建议使用 Python 3.8,配合 Anaconda 管理依赖,常用库包括 pandas、numpy、requests、lxml、jieba、pyecharts、scikit-learn、catboost、flask、pymysql 等。数据库使用 MySQL,先导入 SQL 数据,再修改 Flask 工程中的数据库连接参数。
运行顺序可以概括为:先准备数据库和数据文件,再运行或检查预处理 Notebook,然后查看可视化 HTML 页面,最后启动 Flask 工程进入系统界面。模型文件 model.pkl 和训练数据 model.csv 已经在工程目录中保留,适合后续直接接入预测接口。
如果只做展示,可以直接使用已生成的 HTML 图表、大屏页面和模型效果图;如果需要完整复现,则需要重新配置数据库、依赖库和爬虫参数。因为完整代码、数据、模型和部署命令较多,这里只展示主体效果和技术路线,具体资源可以按需单独获取。
10 总结
这个项目把电影数据分析中最常见的几个方向都串了起来:从公开数据采集开始,到字段清洗、时间变量处理、档期变量构造、多维可视化、评论词云、评分预测,再到 Flask 系统展示,整体结构比较完整。它的优势不在于某一个模型有多复杂,而在于工程链路比较齐全,展示材料多,答辩时能讲清楚数据从哪里来、怎么处理、怎么分析、怎么预测、怎么落地到系统。
后续优化方向可以继续放在三点:一是扩充多平台数据,把票房、宣发、演员热度等变量加入模型;二是强化文本分析,引入情感分类、主题模型或预训练语言模型;三是完善系统交互,把预测、筛选、下载、权限管理和可视化配置做得更灵活。这样一来,项目会从课程展示型系统,逐步接近一个更完整的电影数据分析平台。
每文一语
真正能拉开差距的,从来不是灵感一闪,而是把每一步都做完整、做扎实、做成结果。