对应教材:陈封能《数据挖掘导论》第2章
核心问题:数据长什么样?每个特征是什么类型?如何度量两个样本之间的"像"与"不像"?
一、数据的基本构成:对象与属性
1.1 什么是数据对象(样本)?
-
数据对象 = 一条记录、一个样本、一个实例。
比如:一个患者、一笔订单、一张图片、一个用户。
-
在表格中,一行就是一个数据对象。
1.2 什么是属性(特征)?
-
属性 = 一个特征、一个字段、一个维度。
比如:年龄、性别、血型、收入、评分。
-
在表格中,一列就是一个属性。
1.3 举个订单的例子
| 订单ID | 商品类目 | 用户评分(1-5星) | 下单时间 | 金额(元) | 是否退款 |
|---|---|---|---|---|---|
| 1001 | 手机 | 4 | 2023-01-01 10:00 | 2999 | 否 |
| 1002 | 图书 | 5 | 2023-01-01 10:05 | 89 | 否 |
-
对象:每一行订单。
-
属性:订单ID、商品类目、评分、下单时间、金额、是否退款。
✅ 同一张表中,不同列可以有不同的属性类型。下面我们就来学习这四种类型。
二、四种属性类型(核心重点)
根据统计学家 Stevens(1946)的测量尺度理论 ,属性分为四种,从低到高:标称 → 序数 → 区间 → 比率。
层次越高,能做的数学运算越多。
2.1 标称属性(Nominal)------ 只分类,不排序
-
特点 :值只是类别标签,没有顺序,不能比大小。
即使写成数字(如1=男,2=女),数字也没有数学意义。
-
允许的操作:判断相等(==)或不相等(!=)。
-
不允许的操作:比大小、加减乘除、求均值。
-
常用统计:频数、众数、卡方检验。
-
例子:
-
血型(A、B、O、AB)
-
性别(男、女)
-
邮政编码(100010并不比100009"大")
-
学号(20230001并不比20230002"小")
-
💡 小贴士:如果你对一列"标称"属性求平均值,会得到毫无意义的数字。比如性别平均值=1.3,没有任何含义。
2.2 二元属性(Binary)------ 标称的特殊情况
二元属性只有两个取值,比如:是/否、男/女、0/1。
根据两个值是否"平等",分为两种:
| 类型 | 含义 | 例子 | 常用相似度度量 |
|---|---|---|---|
| 对称二元 | 两个值地位相同,都重要 | 性别(男/女)、抛硬币(正/反) | SMC(简单匹配系数) |
| 非对称二元 | 其中一个值更重要(通常为1) | 患病(1=患病,0=健康)、购买(1=买了,0=没买) | Jaccard |
为什么区分?
在非对称场景中,两个人都"没患病"或都"没购买"并不能说明相似(因为大量未发生的事件没有信息量),所以要忽略"双0"匹配。
2.3 序数属性(Ordinal)------ 有顺序,但间距未知
-
特点 :值之间有大小顺序,但无法确定"差值"的绝对大小。
比如:优、良、中、差 -- 我们知道优 > 良 > 中 > 差,但优比良好多少?不知道。
-
允许的操作:比较大小、排序。
-
不允许的操作:加减(因为间距不等)。
-
常用统计:中位数、百分位数、秩相关系数。
-
处理方法 :常常将序数值转换为秩(rank),再归一化到 0,1 区间。
-
例子:
-
成绩等级(A、B、C、D)
-
满意度评分(1=很不满意,2=不太满意,3=一般,4=满意,5=很满意)
→ 严格来说,我们不知道"满意"比"一般"具体多多少,所以不应该直接计算平均值。
-
⚠️ 常见误用:把问卷调查的1-5分直接当数值做平均。虽然很多论文这么做,但严格意义上属于序数,平均值可能没有实际意义。
2.4 区间属性(Interval)------ 差值有意义,但没有"真零点"
-
特点:可以比较差值(等距),但零点是人造的,倍数无意义。
-
允许的操作:加减(因为差值有意义)、均值。
-
不允许的操作:乘除(因为倍数无意义)。
-
常用统计:均值、标准差、Pearson相关系数。
-
例子:
-
摄氏温度(℃):20℃ 比 10℃ 热10℃,但 20℃ 不是 10℃ 的"两倍热"。因为 0℃ 不是没有温度。
-
年份:公元2024年 - 公元2000年 = 24年,但不能说公元1000年是公元500年的两倍。
-
-
线性变换 :
y = a*x + b(例如摄氏转华氏)。
2.5 比率属性(Ratio)------ 有绝对零点,可乘除
-
特点:存在真正的零点,所有算术运算(加减乘除)都有意义。
-
允许的操作:加减乘除、比较、均值等所有运算。
-
常用统计:几何平均数、变异系数等。
-
例子:
-
开尔文温度(K):0K = 绝对零度,300K 是 150K 的两倍热。
-
身高:180cm 是 90cm 的两倍。
-
收入、年龄、重量、长度。
-
-
变换 :
y = a*x(仅缩放,不能加常数,否则破坏零点)。
🧠 对比记忆:
摄氏20℃是10℃的两倍吗?不是。
300K是150K的两倍吗?是的。
三、数据集的类型
除了属性类型,数据集整体也有不同的"形态":
| 类型 | 说明 | 例子 |
|---|---|---|
| 记录数据 | 最常见的表格形式,每行一个记录,每列一个属性 | Excel表格、数据库表 |
| 基于图的数据 | 节点和边的关系结构,关系本身是信息 | 社交网络、网页链接、交通网络 |
| 有序数据 | 顺序不能打乱,否则信息丢失 | 时间序列(股票价格)、DNA序列、空间轨迹 |
一个实际系统可能同时包含多种类型,例如外卖订单:表格数据(记录)+ 骑手-商家-用户网络(图)+ 订单时间戳(时序)。
维度灾难(Curse of Dimensionality)
-
当属性(维度)非常多时,样本在高维空间中会变得极其稀疏,所有点之间的距离几乎相等,导致很多算法失效。
-
解决:降维(PCA、t-SNE)、特征选择、正则化。
四、数据质量与预处理("垃圾进,垃圾出")
数据挖掘中,80%的时间花在数据预处理上。
| 质量问题 | 含义 | 常见处理方法 |
|---|---|---|
| 噪声 | 随机误差,比如传感器错误 | 平滑、滤波、离群点检测 |
| 异常值 | 合法但与大部分数据差异很大 | 根据情况:可能删除,也可能是挖掘目标(欺诈) |
| 缺失值 | 某些属性值为空 | 删除行/列、填充(均值/中位数/众数/插值)、用模型预测 |
| 重复数据 | 完全相同的记录 | 去重 |
其他预处理操作:
-
聚集:把细粒度数据汇总成粗粒度(例如:日销售额→月销售额)。
-
抽样:从大数据集中随机选子集,减少计算量。
-
离散化:将连续数值变成区间(年龄→年龄段)。
-
标准化 :让不同量纲的特征具有可比性。常用公式:
x' = (x - μ) / σ(Z-score)。 -
降维:减少特征数量。
五、相似性与相异性("有多像" vs "有多远")
这是数据挖掘中最核心的基础概念,几乎所有算法(聚类、分类、推荐等)都要用到。
| 概念 | 值域 | 含义 | 越大表示 |
|---|---|---|---|
| 相似性 (Similarity) | 0, 1 | 两个对象有多像 | 越像 |
| 相异性 (Dissimilarity) | [0, +∞) | 两个对象有多不同 | 越不同(也叫距离) |
转换关系(当相异性归一化到0,1时):
相似性 = 1 - 相异性
万能判断法则:
-
叫"距离" → 相异性
-
叫"系数/相似度/相关系数" → 相似性
六、必背的9大度量归类表(考试常考)
| 类别 | 度量名称 | 适用数据类型 | 简要说明 |
|---|---|---|---|
| 相异性 | 欧氏距离 | 连续型(区间/比率) | 几何直线距离,最常用 |
| 曼哈顿距离 | 连续型 | 城市街区距离,对异常值更稳健 | |
| 切比雪夫距离 | 连续型 | 各维度最大差值,适合瓶颈分析 | |
| 汉明距离 | 标称/二元 | 不同属性的个数 | |
| 相似性 | 余弦相似度 | 连续向量(常为正) | 只看方向,不看长度 |
| Jaccard系数 | 集合/非对称二元 | 交集/并集,忽略双0 | |
| SMC(简单匹配系数) | 对称二元 | (匹配数)/总属性数,包含双0 | |
| Pearson相关系数 | 连续型(线性) | 线性相关强度,范围-1,1 | |
| 互信息 | 任何类型 | 捕捉任何(包括非线性)依赖关系 |
七、距离度量详解(相异性)
7.1 Minkowski 距离族(一个公式,三种距离)
公式:
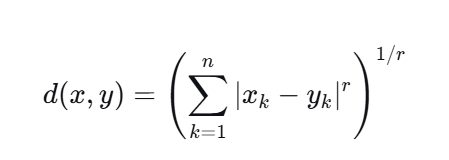

例子:x=(3,0,5,1,2), y=(2,1,5,3,0)
-
欧氏距离 = √((3-2)²+(0-1)²+(5-5)²+(1-3)²+(2-0)²) = √(1+1+0+4+4)=√10≈3.16
-
曼哈顿距离 = |1|+| -1|+|0|+| -2|+|2| = 1+1+0+2+2=6
-
切比雪夫距离 = max(1,1,0,2,2)=2
⚠️ 重要提醒 :欧氏距离受量纲影响!如果身高(cm)和体重(kg)混在一起直接算,会完全被数值大的特征主导。必须先标准化(减去均值除以标准差)。
7.2 汉明距离

-
适用于标称属性 或二元属性。
-
定义:两个向量对应位置不同的个数。
-
归一化版本:不同个数 / 总长度。
例子 :
x = 1,0,1,1,0,0,1
y = 1,1,0,1,0,1,1
对应位置不同:第2、3、6位 → 3个不同。汉明距离=3,归一化=3/7≈0.43。
与SMC的关系:对于二元数据,归一化汉明距离 = 1 - SMC。
7.3 余弦相似度
-
公式:
-
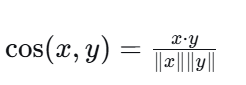
-
范围:-1, 1(通常用于非负数据时0,1)。
-
只看方向,不看长度。
典型例子 :
用户A对两个物品的评分:2,4
用户B的评分:4,8
欧氏距离 ≈ 4.5,看起来不相似。
但余弦相似度 = (2×4+4×8)/(√(4+16)×√(16+64)) = (8+32)/(√20×√80)=40/(4.472×8.944)=40/40=1.0 → 完全相似!
因为他们偏好的比例完全一致(B始终是A的两倍评分)。
适用场景:
-
文本相似度(TF-IDF向量)
-
推荐系统(用户评分向量)
-
不适合:需要考虑量级(如消费金额)的场景。
⚠️ 注意:
scipy.spatial.distance.cosine返回的是余弦距离 (=1-余弦相似度),要得到相似度需用1 - cosine(x,y)。
八、相似性度量详解
8.1 Jaccard 系数
-
适用于集合 或非对称二元属性。
-

例子 :
A = {牛奶, 面包, 黄油, 咖啡}
B = {牛奶, 饼干, 咖啡, 果汁}
交集={牛奶,咖啡} → 大小2,并集大小6 → J=2/6≈0.333。
特点:忽略"双0"(即两个集合都没有的元素),适合购物篮分析、文档去重。
8.2 SMC(简单匹配系数)
-
适用于对称二元属性。
-
公式:
-
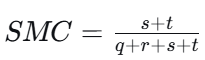 ,t = 双0匹配数。
,t = 双0匹配数。
例子 (10个二元属性):
x = 1,0,0,0,0,0,0,0,0,0
y = 0,0,0,0,0,0,1,0,0,1
s=0(没有同时为1),t=7(同时为0的位置有7个),q=1(x=1,y=0只有一个位置),r=2(x=0,y=1有两个位置)
SMC = (0+7)/10 = 0.7
Jaccard = 0/(1+2+0)=0 → 差异巨大!
何时用哪个?
-
对称(性别)→ SMC
-
非对称(疾病检测)→ Jaccard
九、相关系数与互信息(捕捉变量间的关系)
9.1 Pearson 相关系数
-
适用:连续型(区间/比率),线性关系,大致正态分布。
-
公式:
-
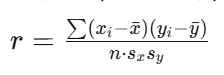
-
范围:-1, 1
-
|r|>0.7:强相关
-
0.3~0.7:中等
-
<0.3:弱相关
-
-
局限性 :只能检测线性关系。如果 y = x²(完全确定但非线性),Pearson r = 0!
9.2 Spearman 秩相关系数
-
适用:序数数据,或者不满足正态性的连续数据。
-
方法:先将数值转换为秩(排序位置),再计算Pearson。
-
优点:对离群值稳健,可以捕捉单调非线性关系(比如指数、对数)。
-
仍有限制:如果 y = x²(对称的抛物线),不是单调函数,Spearman ρ = 0。
9.3 信息熵与互信息(捕捉任意关系)
熵(Entropy)表示随机变量的不确定性:
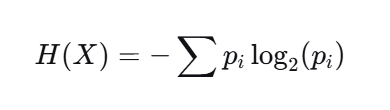
-
单位:比特(bit)。
-
范围:0, log₂(n),n为取值个数。
-
概率分布越均匀,熵越大;越集中,熵越小。
互信息(Mutual Information)度量知道X后,对Y的不确定性减少多少:
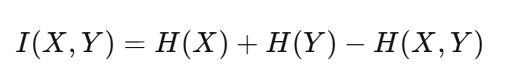
-
范围:0, min(H(X),H(Y)),归一化后0,1。
-
若X和Y独立,I=0;完全依赖,I达到最大值。
-
强大之处 :可以捕捉任何依赖关系(线性、非线性、甚至周期关系)。
经典案例 :
y = x²
x = -3,-2,-1,0,1,2,3
y = 9,4,1,0,1,4,9
-
Pearson r = 0(检测不到)
-
Spearman ρ = 0(检测不到,因为不是单调)
-
互信息 ≈ 1.85 bits(成功检测!)
互信息在特征选择中非常有用:选择与目标变量互信息最大的特征。
十、属性类型如何决定预处理与算法选择
| 属性类型 | 典型预处理 | 适用的算法或距离 |
|---|---|---|
| 标称 | One-Hot编码(将每个类别转为0/1列) | 汉明距离、Jaccard、SMC |
| 序数 | 标签编码(1,2,3)或秩变换 | 曼哈顿距离、Spearman |
| 区间/比率 | 标准化、归一化 | 欧氏距离、余弦、Pearson |
Titanic案例:
-
sex(标称)→ One-Hot编码 -
pclass(1/2/3,序数)→ 标签编码(保留顺序) -
age(比率)→ 填充中位数 + 标准化 -
ticket(标称,高基数)→ 删除或频次编码 -
embarked(标称3类)→ One-Hot编码
十一、课堂练习(带答案解析)
Q1:判断以下属性类型
-
微博粉丝数 → 比率(有绝对零点0粉丝)
-
成绩等级优/良/中/差 → 序数
-
地理经度 → 区间(-180°到180°,0是人为选择)
-
年龄 → 比率(0岁绝对零点)
-
学号 → 标称(数字只是代号)
Q2:A=3,0,5,1,2,B=2,1,5,3,0
欧氏距离 ≈ 3.74
余弦相似度 = 0.8528
哪个度量认为他们更相似? → 余弦相似度(0.85更接近1)
Q3:顾客P:{矿泉水,零食,啤酒,薯片} Q:{矿泉水,面包,薯片,牛奶}
Jaccard = 交集{矿泉水,薯片}大小2 / 并集大小6 = 0.333。
加上"饮料杯"(都没买)→ 交集并集都不变,Jaccard不变(因为Jaccard忽略双0)。
Q4:医院数据
-
年龄(比率)→ 可算均值
-
血型(标称)→ 不能算均值
-
BMI(比率)→ 可算均值
-
疼痛等级1-10(序数)→ 最好不用均值,用中位数
-
过敏史(二元标称)→ 不能算均值(但可算患病比例)
-
住院天数(比率)→ 可算均值
十二、本章核心总结(考试重点)
-
四种属性:标称(只分类)、序数(有序)、区间(差值有意义)、比率(有真零点)。
-
属性决定统计方法:标称用众数,序数用中位数,区间/比率用均值。
-
维度灾难:高维空间距离失效 → 降维或特征选择。
-
三种主要距离:欧氏(直线)、曼哈顿(稳健)、余弦(方向)。
-
Jaccard vs SMC:Jaccard忽略双0(非对称),SMC包含双0(对称)。
-
互信息:比Pearson/Spearman更强,能捕捉任意非线性关系。