1、概念
(1)agent
智能体(agent)是一个能够基于所处环境的观察(感知)而采取行动的实体。
(2)OpenAI Gym
该环境提供了一个简单而通用的Python接口,它在每一步将动作作为输入,基于每个动作给出观察、奖励、完成与否等反馈,并将可选信息对象作为输出。
2、第一个Demo
python
import gymnasium as gym
# 创建环境
env = gym.make('MountainCar-v0', render_mode="human")
# 重置环境,获取初始观测
obs, info = env.reset()
# 循环交互
for step in range(2000):
env.render()
# 随机采样动作
action = env.action_space.sample()
# 执行动作,返回:观测、奖励、终止、截断、额外信息
obs, reward, terminated, truncated, info = env.step(action)
# 打印关键值:步数、动作、当前状态、奖励、是否结束
print(
f"步数: {step:3d} | 动作: {action} | 状态(位置,速度): {obs.round(4)} | 奖励: {reward:.2f} | 终止: {terminated} | 截断: {truncated}")
# 回合结束就重置环境
if terminated or truncated:
print("===== 本回合结束,重置环境 =====")
obs, info = env.reset()
# 关闭环境
env.close()3、安装OpenAI Gym学习环境
通过pip install gym可以完成最小化安装,但是最小安装并不能支持所有环境。
(1)安装MuJoCo
目前是免费不需要授权的。
下载地址:https://github.com/google-deepmind/mujoco/releases
Window电脑中下载:

配置环境变量:
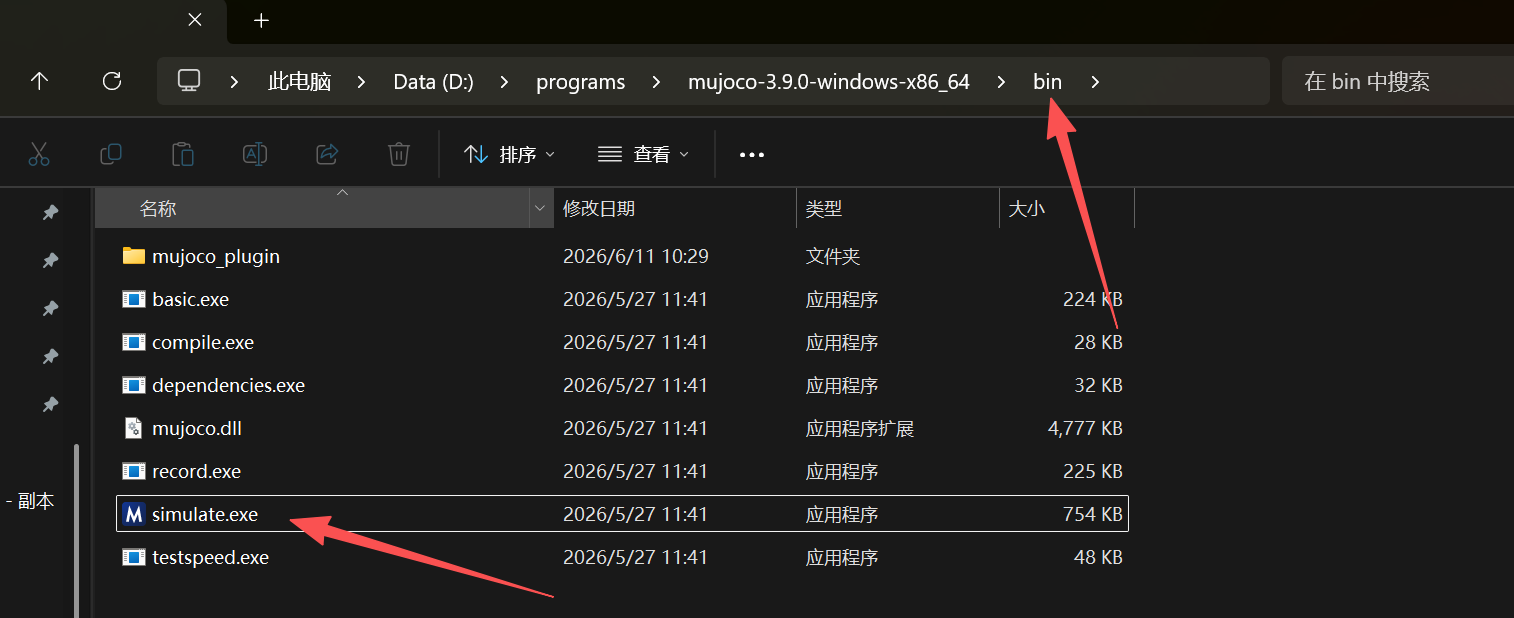
执行命令弹出控制界面说明安装成功。
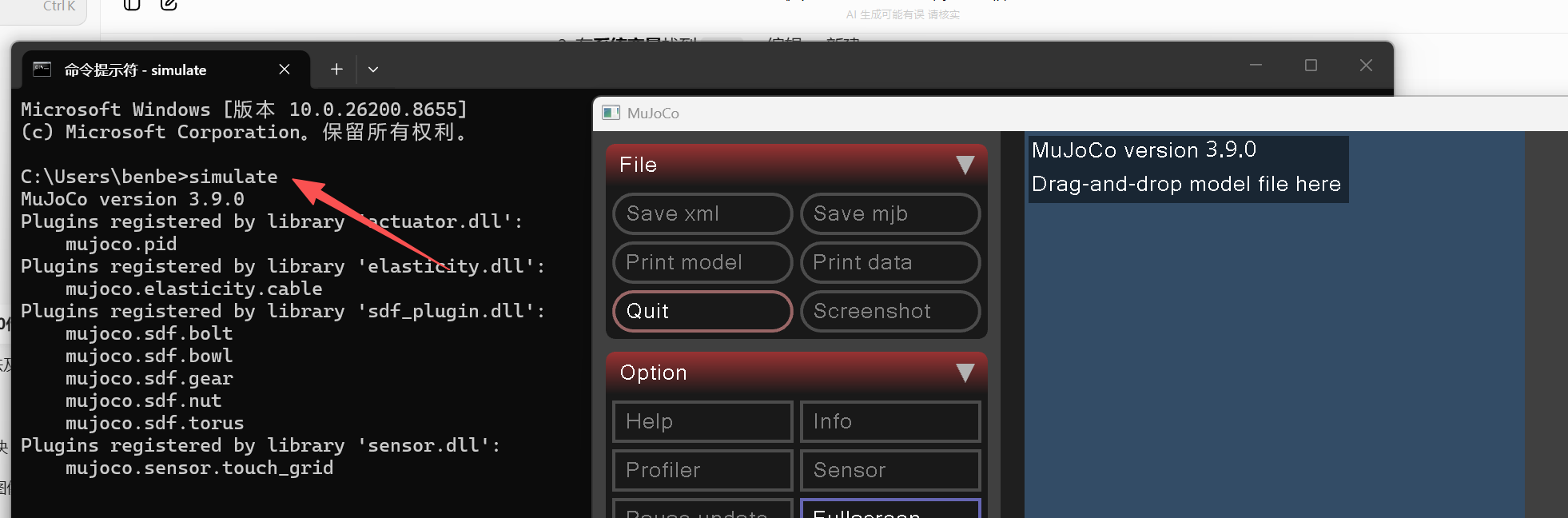
安装 Python 绑定(mujoco)+ Gymnasium 支持:
1.先升级 pip
python
python.exe -m pip install --upgrade pip setuptools wheel2.安装 mujoco
python
pip install mujoco3.安装 gymnasium 的 mujoco 依赖
python
pip install gymnasium[mujoco]4.测试 mujoco
python
(D:\appdata\conda\new_envs\py311) D:\>python -c "import mujoco; print('MuJoCo 版本:', mujoco.__version__)"
MuJoCo 版本: 3.9.0不报错、输出版本号即可。
5.测试 gymnasium + MuJoCo 环境
python
import gymnasium as gym
env = gym.make("Ant-v4", render_mode="human")
obs, info = env.reset()
for _ in range(1000):
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
env.reset()
env.close()能弹出蚂蚁模型并动起来,就完全装好了。
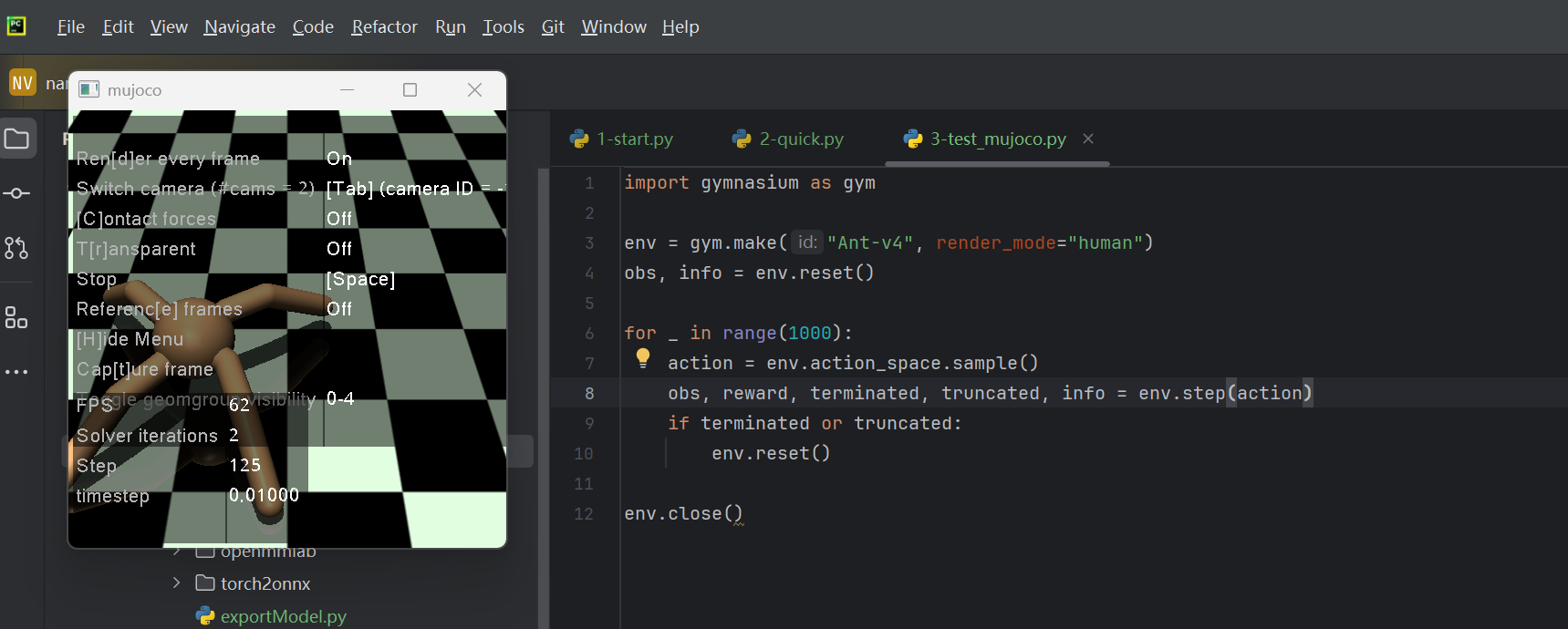
(2)安装其他环境
需要的其他环境包括:Atari、Box2D、Robotics。
1.升级编译依赖工具
python
pip install --upgrade pip setuptools wheel
pip install swig2.安装box2d
python
conda install -c conda-forge box2d-py3.安装atari
python
pip install "gymnasium[atari]" "gymnasium[accept-rom-license]"4.安装robotics
python
pip install gymnasium-robotics5、测试box2d
python
import gymnasium as gym
env = gym.make("LunarLander-v3", render_mode="human")
obs, info = env.reset()
for _ in range(300):
a = env.action_space.sample()
obs, _, ter, tru, _ = env.step(a)
if ter or tru:
env.reset()
env.close()6、测试Atari
python
import gymnasium as gym
# 改用存在的 v4 版本
env = gym.make("Pong-v4", render_mode="human")
obs, info = env.reset()
for _ in range(300):
action = env.action_space.sample()
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
obs, info = env.reset()
env.close()7、测试Robotics
python
import gymnasium as gym
import gymnasium_robotics # 1. 导入机器人环境库
gym.register_envs(gymnasium_robotics) # 2. 注册所有机器人环境{insert\_element\_1\_}
# 3. 直接写 FetchPush-v3(不用加 Fetch/ 前缀){insert\_element\_2\_}
env = gym.make("FetchPush-v4", render_mode="human")
obs, info = env.reset()
for _ in range(300):
a = env.action_space.sample()
obs, _, ter, tru, _ = env.step(a)
if ter or tru:
obs, info = env.reset()
env.close()4、Gym中的空间
| 空间类型 | 核心特点 | 最简单类比 | 典型使用场景 |
|---|---|---|---|
| Discrete | 单选、整数、有限选项 | 单选题、单开关 | 简单动作:左右、启停 |
| Box | 连续小数、区间取值、支持图像 | 滑块、坐标、图片 | 连续控制、传感器、游戏画面 |
| MultiDiscrete | 多组独立单选(多维离散) | 多组档位开关 | 多组独立按键、多档位控制 |
| MultiBinary | 多位 0/1 二进制 | 一排灯开关 | 多传感器、多按键通断 |
| Tuple | 有序组合,按顺序取值 | 有序包裹 | 简单混合状态 |
| Dict | 命名组合,按名字取值(推荐) | 表格 / 表单 / 结构体 | 机器人、机械臂、复杂仿真 |
5、Q-Learning
(1)Q-Learning的公式

(2)Q-Table版本
python
import gymnasium as gym
import numpy as np
import os
# ===================== 超参数 =====================
MAX_NUM_EPISODES = 50000
STEPS_PER_EPISODE = 200
EPSILON_MIN = 0.005
max_num_steps = MAX_NUM_EPISODES * STEPS_PER_EPISODE
EPSILON_DECAY = 500 * EPSILON_MIN / max_num_steps
ALPHA = 0.05
GAMMA = 0.98
NUM_DISCRETE_BINS = 30
# 最终模型保存路径(只存最终文件,不再每轮保存)
Q_TABLE_SAVE_PATH = "./final_q_table.npy"
POLICY_SAVE_PATH = "./final_policy.npy"
# 模式开关:True=训练(支持续训) False=仅测试
TRAIN_MODE = True
# ===================================================
class Q_Learner(object):
def __init__(self, env):
self.obs_shape = env.observation_space.shape
self.obs_high = env.observation_space.high
self.obs_low = env.observation_space.low
self.obs_bins = NUM_DISCRETE_BINS
self.bin_width = (self.obs_high - self.obs_low) / self.obs_bins
self.action_shape = env.action_space.n
# 修复冗余 +1,维度与分箱严格对齐
self.Q = np.zeros((self.obs_bins, self.obs_bins, self.action_shape))
self.alpha = ALPHA
self.gamma = GAMMA
self.epsilon = 1.0
def discretize(self, obs):
return tuple(((obs - self.obs_low) / self.bin_width).astype(int))
def get_action(self, obs):
discretized_obs = self.discretize(obs)
# ε 线性衰减
if self.epsilon > EPSILON_MIN:
self.epsilon -= EPSILON_DECAY
if np.random.random() > self.epsilon:
return np.argmax(self.Q[discretized_obs])
else:
# 优化:直接生成随机动作,不构造列表
return np.random.randint(0, self.action_shape)
def learn(self, obs, action, reward, next_obs):
discretized_obs = self.discretize(obs)
discretized_next_obs = self.discretize(next_obs)
td_target = reward + self.gamma * np.max(self.Q[discretized_next_obs])
td_error = td_target - self.Q[discretized_obs][action]
self.Q[discretized_obs][action] += self.alpha * td_error
def load_last_q_table():
"""加载上一次训练完成的Q表,用于断点续训"""
if os.path.exists(Q_TABLE_SAVE_PATH):
return np.load(Q_TABLE_SAVE_PATH)
return None
def train(agent, env):
best_reward = -float('inf')
for episode in range(MAX_NUM_EPISODES):
done = False
obs, _ = env.reset()
total_reward = 0.0
while not done:
action = agent.get_action(obs)
next_obs, reward, done, truncated, info = env.step(action)
agent.learn(obs, action, reward, next_obs)
obs = next_obs
total_reward += reward
if total_reward > best_reward:
best_reward = total_reward
print(f"Episode#:{episode} reward:{total_reward} best_reward:{best_reward} eps:{agent.epsilon}")
# 全部训练完成后,统一保存 Q表 + 策略
final_policy = np.argmax(agent.Q, axis=2)
np.save(Q_TABLE_SAVE_PATH, agent.Q)
np.save(POLICY_SAVE_PATH, final_policy)
print(f"\n训练完成!")
print(f"Q表已保存至: {Q_TABLE_SAVE_PATH}")
print(f"最优策略已保存至: {POLICY_SAVE_PATH}")
return final_policy
def load_policy_only():
"""仅加载最终策略,用于测试"""
if os.path.exists(POLICY_SAVE_PATH):
policy = np.load(POLICY_SAVE_PATH)
print(f"成功加载训练好的策略: {POLICY_SAVE_PATH}")
return policy
else:
print("未找到策略文件,请先执行训练!")
return None
def test(agent, env, policy):
done = False
obs, _ = env.reset()
total_reward = 0.0
while not done:
action = policy[agent.discretize(obs)]
next_obs, reward, done, truncated, info = env.step(action)
obs = next_obs
total_reward += reward
return total_reward
if __name__ == "__main__":
# 训练关闭渲染,测试开启渲染
if TRAIN_MODE:
env = gym.make('MountainCar-v0', render_mode=None)
else:
env = gym.make('MountainCar-v0', render_mode="human")
agent = Q_Learner(env)
if TRAIN_MODE:
# 断点续训:加载上次训练的Q表
old_q = load_last_q_table()
if old_q is not None:
agent.Q = old_q
print("检测到历史Q表,继续训练...\n")
else:
print("无历史模型,开始全新训练...\n")
learned_policy = train(agent, env)
else:
learned_policy = load_policy_only()
if learned_policy is None:
exit()
# 测试环节
print("\n开始测试策略...")
for _ in range(10):
test(agent, env, learned_policy)
env.close()注意:在训练时不render图像,可以极大提升训练的速度。
(3)DQN版本
python
import torch
import torch.nn as nn
import torch.optim as optim
import gymnasium as gym
import numpy as np
import os
# ===================== 全局配置 & 超参数 =====================
# 设备自动适配
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {DEVICE}")
MAX_NUM_EPISODES = 10000
STEPS_PER_EPISODE = 300
EPSILON_MIN = 0.005
max_num_steps = MAX_NUM_EPISODES * STEPS_PER_EPISODE
EPSILON_DECAY = 500 * EPSILON_MIN / max_num_steps
ALPHA = 0.05
GAMMA = 0.98
# DQN 关键:目标网络同步间隔(每多少步同步一次权重)
TARGET_UPDATE_STEP = 100
# 模型保存路径
MODEL_SAVE_PATH = "./policy/dqn_net.pth"
# 模式开关:True=训练(支持续训) False=仅测试
TRAIN_MODE = False
# ===================== 浅层神经网络 Q网络 =====================
class SLP(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.hidden_dim = 40
self.linear1 = nn.Linear(input_dim, self.hidden_dim)
self.out = nn.Linear(self.hidden_dim, output_dim)
def forward(self, x):
if isinstance(x, np.ndarray):
x = torch.tensor(x, dtype=torch.float32).to(DEVICE)
x = torch.relu(self.linear1(x))
q_vals = self.out(x)
return q_vals
# ===================== DQN 智能体(双网络:Online + Target) =====================
class Shallow_Q_Learner(object):
def __init__(self, env):
self.obs_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.n
# 1. 在线网络(实时更新,选动作、算当前Q)
self.online_net = SLP(self.obs_dim, self.action_dim).to(DEVICE)
# 2. 目标网络(延迟更新,只算目标Q值)
self.target_net = SLP(self.obs_dim, self.action_dim).to(DEVICE)
# 初始化时,目标网络和在线网络权重完全一致
self.target_net.load_state_dict(self.online_net.state_dict())
# 目标网络设置为评估模式,关闭梯度
self.target_net.eval()
self.optimizer = optim.Adam(self.online_net.parameters(), lr=1e-5)
self.alpha = ALPHA
self.gamma = GAMMA
self.epsilon = 1.0
# 全局步数计数器,用于控制目标网络同步
self.global_step = 0
self.target_update_step = TARGET_UPDATE_STEP
def get_action(self, obs):
"""ε-贪心选择动作,只用在线网络"""
if self.epsilon > EPSILON_MIN:
self.epsilon -= EPSILON_DECAY
if np.random.random() > self.epsilon:
with torch.no_grad():
q_pred = self.online_net(obs)
action = torch.argmax(q_pred).item()
else:
action = np.random.randint(0, self.action_dim)
return action
def learn(self, obs, action, reward, next_obs):
"""DQN 双网络更新逻辑"""
self.optimizer.zero_grad()
self.global_step += 1
# 1. 在线网络计算当前Q值
q_current = self.online_net(obs)[action]
# 2. 目标网络计算目标Q值,全程阻断梯度
with torch.no_grad():
q_next_max = torch.max(self.target_net(next_obs))
td_target = reward + self.gamma * q_next_max
# 3. 计算损失 & 反向传播(只更新在线网络)
loss = nn.functional.mse_loss(q_current, td_target)
loss.backward()
self.optimizer.step()
# 4. 达到指定间隔,同步在线网络权重到目标网络
if self.global_step % self.target_update_step == 0:
self.target_net.load_state_dict(self.online_net.state_dict())
print(f"【同步】第 {self.global_step} 步:在线网络权重 -> 目标网络")
# ===================== 模型加载/保存工具函数 =====================
def load_pretrained_model(agent):
"""加载预训练权重,在线/目标网络同时恢复"""
if os.path.exists(MODEL_SAVE_PATH):
checkpoint = torch.load(MODEL_SAVE_PATH, map_location=DEVICE)
agent.online_net.load_state_dict(checkpoint)
agent.target_net.load_state_dict(checkpoint)
print("检测到预训练模型,加载权重成功,继续训练...\n")
return True
print("未检测到预训练模型,开始全新训练...\n")
return False
def save_model(agent):
"""训练结束保存在线网络权重(目标网络由在线同步而来,无需单独存)"""
torch.save(agent.online_net.state_dict(), MODEL_SAVE_PATH)
print(f"\n模型训练完成!权重已保存至: {MODEL_SAVE_PATH}")
# ===================== 训练函数 =====================
def train(agent, env):
best_reward = -float('inf')
for episode in range(MAX_NUM_EPISODES):
done = False
obs, _ = env.reset()
total_reward = 0.0
while not done:
action = agent.get_action(obs)
next_obs, reward, done, truncated, info = env.step(action)
agent.learn(obs, action, reward, next_obs)
obs = next_obs
total_reward += reward
if total_reward > best_reward:
best_reward = total_reward
print(f"Episode#:{episode} reward:{total_reward} best_reward:{best_reward} eps:{agent.epsilon}")
# 训练全部结束,保存模型
save_model(agent)
# ===================== 测试函数 =====================
def test(agent, env):
done = False
obs, _ = env.reset()
total_reward = 0.0
while not done:
action = agent.get_action(obs)
next_obs, reward, done, truncated, info = env.step(action)
obs = next_obs
total_reward += reward
return total_reward
# ===================== 主函数 =====================
if __name__ == "__main__":
if TRAIN_MODE:
env = gym.make('CartPole-v0', render_mode=None)
else:
env = gym.make('CartPole-v0', render_mode="human")
agent = Shallow_Q_Learner(env)
if TRAIN_MODE:
load_pretrained_model(agent)
train(agent, env)
else:
if not load_pretrained_model(agent):
print("请先执行训练,再进行测试!")
env.close()
exit()
print("\n开始测试策略...")
for _ in range(100):
test(agent, env)
env.close()(4)ε 衰减

(5)DQN目标Q网络

6、自定义Atari Gym环境
目的:通过修改环境返回的观测结果、调整奖励大小,或是在智能体接收信息前进行筛选,也可以改变环境的屏幕渲染方式,从而让智能体更高效、更稳定地学习,提升策略的泛化能力与鲁棒性。
(1)随机空操作重置(NoopResetEnv)
作用:通过随机次数的空操作,打破游戏固定开局,避免智能体过拟合初始状态,提升泛化能力。
核心逻辑:
1.解决痛点:普通Gym环境重置时,智能体每次从完全相同的初始状态开局,容易死记硬背开局套路,状态稍有变化就表现崩盘。
2.实现方式:游戏重置后,先执行1~noop_max次随机数量的action=0(空操作),再把状态交给智能体
3.关键原理:游戏即使不操作,画面/物体也会随时间(帧数)变化;不同次数的空操作,对应不同帧的游戏状态,实现初始状态随机化
4.最终效果:每次开局状态有微小差异,智能体无法死记硬背,只能学到通用策略,鲁棒性显著提升。
(2)开始键重置
很多 Atari 游戏(比如《Space Invaders》《Qbert》)有个特殊设定:
游戏重置后,并不会自动开始,必须按下 "开始键(Fire,通常是动作 1)",游戏才会正式启动。
角色每失去一条命后,也需要按一次 Fire 键才能重新开始。
如果不处理这个问题,智能体重置后啥也不做,游戏永远停在 "等待开始" 的界面,没法真正玩起来。
所以它的作用是:在游戏重置后,自动帮智能体按下"开始键",让游戏正式启动,同时保证后续游戏能正常继续。
(3)回合生命
在 Atari 游戏中,把 "失去一条命" 当作 "一局游戏结束",提前触发 done 信号,强化死亡的惩罚信号,让智能体更快学会规避危险,提升训练效率。
(4)最大化和略过帧
每执行 1 次动作,连续跳过(重复执行)skip-1帧,累加所有奖励,并取最近几帧的像素最大值作为观测,以此降低计算量、解决画面闪烁问题,让训练更高效稳定。
解决的痛点:
- 帧率太高,没必要逐帧处理Atari 游戏每秒 60 帧,动作变化没那么快,智能体完全不需要每帧都做决策,逐帧处理会浪费大量算力。
- 部分游戏存在 "闪烁问题"有些 Atari 游戏的物体(比如敌人、子弹)会交替在不同帧出现,单看某一帧可能看不到关键物体,导致智能体误判。取连续几帧的最大值,就能保证这些物体始终在画面里,不会消失。
- 统一采样间隔Gym 部分 Atari 环境默认会随机跳帧(n 从 2/3/4 中采样),动作执行间隔不稳定;而NoFrameskip环境可以通过MaxAndSkipEnv自定义固定跳帧间隔(比如每 4 帧执行一次动作),让训练更可控。
(5)Atari环境封装
1)三类Gym Wrapper区别
gym.Wrapper:通用环境包装,改写reset/step,处理动作、生命周期、跳帧、空操作等整体逻辑。
gym.ObservationWrapper:仅改写观测值,重写observation(),做画面裁剪、缩放、归一化。
gym.RewardWrapper:仅改写奖励,重写reward(),常用奖励裁剪。
2)各自定义包装功能(单项目的,不通用)
NoopResetEnv(Wrapper):开局随机空操作,增强初始状态随机性。
MaxAndSkipEnv(Wrapper):多帧跳步执行动作,取帧最大值、累加奖励,降计算量。
FireResetEnv(Wrapper):部分 Atari 游戏开局自动触发开火动作。
EpisodicLifeEnv(Wrapper):损失生命即判定回合结束,拆分多条命为多轮训练。
AtariRescale(ObservationWrapper):画面裁剪、灰度化、缩放到 84×84 标准尺寸。
NormalizedEnv(ObservationWrapper):滑动均值 / 方差,对观测做归一化。
FrameStack(Wrapper):堆叠连续多帧,补充运动时序信息;LazyFrames延迟拼接,省内存。
ClipRewardEnv(RewardWrapper):奖励取符号函数,统一奖励范围。
3)整体流程
make_env按顺序嵌套多层Wrapper,完成Atari游戏预处理流水线,输出标准格式观测与奖励。