Google DeepMind 于2026 年 6 月 10 日正式开源实验性文本扩散大模型 DiffusionGemma,主打极速并行文本生成。
(图源网络,侵删)
2026 年 6 月,Google DeepMind 正式对外开源实验性大模型DiffusionGemma,首次把成熟离散文本扩散方案以 Apache 2.0 协议完整开放权重,打破长久以来 LLM 依赖逐 Token 自回归生成的固有模式,凭借并行去噪机制实现最高 4 倍的推理提速,成为本地低延迟 AI 赛道的重磅技术突破。
告别 "打字机",用扩散印刷整段文本
(图源网络,侵删)
市面上绝大多数大模型(Gemma 标准版、GPT 系列等)都是自回归架构:像打字机一样,一次只输出一个 Token,写完一个才能预测下一个,早期文字出错还会一路传导、污染全文,GPU 算力也常因串行等待闲置,单用户本地运行效率很低。
DiffusionGemma 移植了图像生成成熟的扩散逻辑,思路如同批量印刷排版:
1、先铺开一张256 Token 的空白噪声画布;
2、多轮全局并行迭代去噪,用双向注意力同步修正画布内所有文字,高置信度内容先行锁定,反向优化模糊语句;
3、画布收敛后一次性输出完整段落,全程并行计算最大化压榨 GPU 算力。
编码器依旧采用自回归缓存用户提示词,兼顾上下文理解,解码器全权负责扩散生成,兼顾理解速度与输出效率。
核心硬件与架构参数
1、MoE 稀疏专家架构
整体总参数量 26B,内置 128 个专家模块,推理时仅激活 8 个、有效运算参数仅 3.8B,大参数量保障基础理解力,稀疏设计压低内存占用,平衡性能与部署门槛。
2、显存适配门槛友好
4bit 量化版本仅需 18GB 显存,RTX 4090、5090 这类消费级显卡即可本地完整运行;企业级 H100、DGX 工作站、RTX PRO 专业卡均完成全栈优化,原生支持 NVFP4 压缩加速。
3、炸裂的生成速度
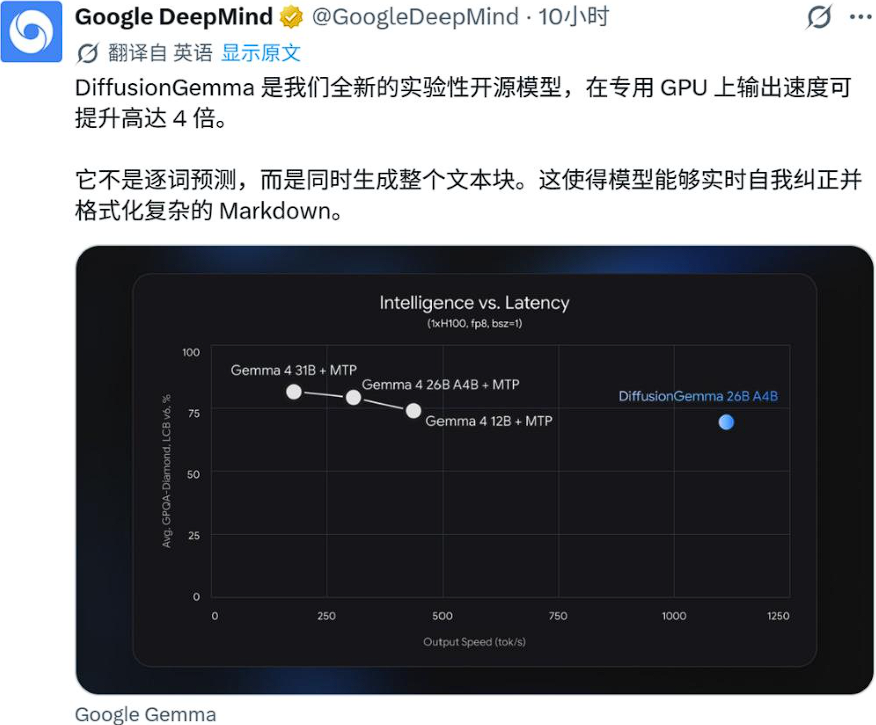
H100 单卡:1000+ token/s
RTX 5090 消费卡:700+ token/s
同等硬件条件下,吞吐速度稳定达到传统自回归 Gemma 模型的 4 倍,延迟大幅降低,完美适配单人实时交互场景。
4、附加能力
支持文本、图片、短视频多模态输入统一输出文本;上下文窗口最高拓展至 256K Token,依靠块自回归技术突破单块 256Token 画布限制;HumanEval 代码得分 89.6%,代码填空、Markdown 排版、表格生成等结构化任务表现突出。
清晰的优劣取舍与适用场景

(图源网络,侵删)
谷歌官方明确定位 DiffusionGemma 为实验提速型模型,存在明确能力取舍:
1、优势场景
低延迟本地工具、代码实时补全、快速文案草稿、即时翻译、表格 / 公式结构化填充、离线桌面 AI 助手;并行全局纠错的特性,很适合需要整体排版修正的内容创作。
2、短板局限
长文深度叙事、复杂数理推理、高精度专业论文写作能力弱于标准版自回归 Gemma 4;高并发云端批量服务场景中,速度优势会被批量调度抵消,此时传统自回归模型性价比更高。
算力支撑决定运行体验
想要流畅跑满 DiffusionGemma 的极速性能,充足稳定的 GPU 算力是核心前提。个人设备显卡显存、算力有限,多卡集群搭建又存在极高硬件与运维成本。
算家云提供高性价比 RTX 5090、RTX 4090、A100 等弹性算力租赁服务,一键开通即用,无需自备硬件、省去环境配置调试,自有镜像社区一键轻松部署各类 AI 模型,无论是开发者调试验证、批量量化微调,还是长时间离线推理运行,都能稳定释放模型并行生成速度,大幅降低文本扩散大模型的上手门槛。
行业价值与开源意义
**1、谷歌首个商用友好开源文本扩散大模型:**Apache 2.0 协议允许企业自由修改、商用分发,给全球学术界、开发者一套可复现、可落地的非自回归 LLM 基线;
**2、开辟 LLM 双线发展格局:**自回归主打高精长文本,扩散架构主打极速低延迟,补齐本地离线 AI 的性能短板;
**3、验证扩散文本生成规模化可行性:**后续有望带动更多开源模型跟进并行生成路线,推动端侧、边缘 AI 整体体验升级。
简单来说,DiffusionGemma 并非用来替代高精度自回归大模型,而是补齐高速实时 AI 的重要拼图。