Qwen3-TTS 模型如何选择:稳定音色、方言支持与克隆服务的工程化取舍
TL;DR
- 场景:在本地搭建机器人/语音助手/客服/内容生成工具的 TTS 服务时,需要同时满足"声音稳定""支持方言""支持克隆"三类需求,单模型无法兼顾。
- 结论:Qwen3-TTS 应按职责拆分为 3--4 个独立服务------主服务用 1.7B-CustomVoice、克隆服务用 1.7B-Base、音色设计用 1.7B-VoiceDesign、低成本兜底用 0.6B-CustomVoice;方言能力分层处理,官方预置的走 CustomVoice,未覆盖的走 Base 克隆。
- 产出:主服务/方言/克隆/音色设计 4 套服务架构 + Speaker 与参数固定化清单 + 文本规范化与切句策略 + 缓存键设计 + 音频质量评估集 + 错误速查卡 + 17 节完整工程化路径。
Qwen3-TTS 模型如何选择:稳定音色、方言支持与克隆服务的工程化取舍
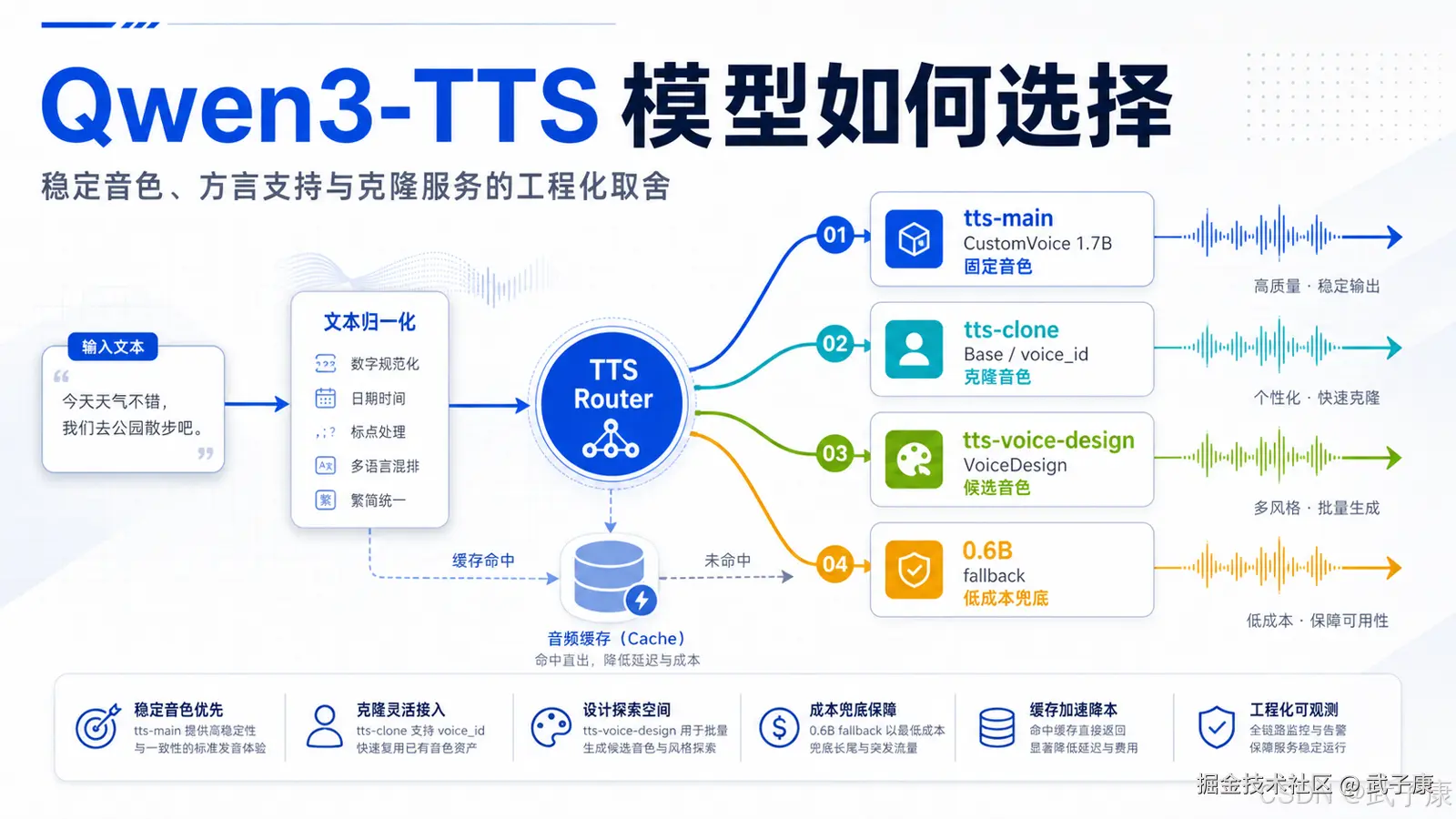
一、问题不是"哪个模型最好",而是"哪个模型适合放在主链路"
很多人在选择 Qwen3-TTS 时,会先看模型参数量、显存占用、是否支持声音克隆、是否支持方言、是否支持 vLLM,然后陷入一个误区:希望一个模型同时承担所有任务。
这是错误的工程思路。
TTS 服务和 LLM 服务不一样。LLM 的核心是文本能力,模型越强,通常综合能力越好。但 TTS 的核心不只是"能不能读出来",而是声音稳定性、音色一致性、语速控制、语气自然度、方言风格、长文本稳定性、首包延迟、并发吞吐、音频质量和服务可控性。
尤其是做机器人语音、语音助手、客服播报、内容生成工具时,真正重要的不是"今天能不能合成一段很好听的声音",而是"明天、后天、一万次请求之后,声音还能不能保持一致"。
所以 Qwen3-TTS 的选型不能只问:
"哪个模型效果最好?"
而应该问:
"哪个模型适合做稳定生产主服务?" "哪个模型适合做克隆服务?" "哪个模型适合做音色探索?" "哪个模型适合做低成本并发兜底?" "方言能力应该放在主链路,还是放在独立服务?"
在这个思路下,Qwen3-TTS 的选择会变得很清晰。
主服务应该选 Qwen3-TTS-12Hz-1.7B-CustomVoice。
克隆服务应该选 Qwen3-TTS-12Hz-1.7B-Base。
音色设计服务可以选 Qwen3-TTS-12Hz-1.7B-VoiceDesign。
0.6B 版本不应该作为首选主服务,除非你的目标是低资源、低成本、高并发,而不是音色质量和稳定性。
二、先理解 Qwen3-TTS 的几个版本
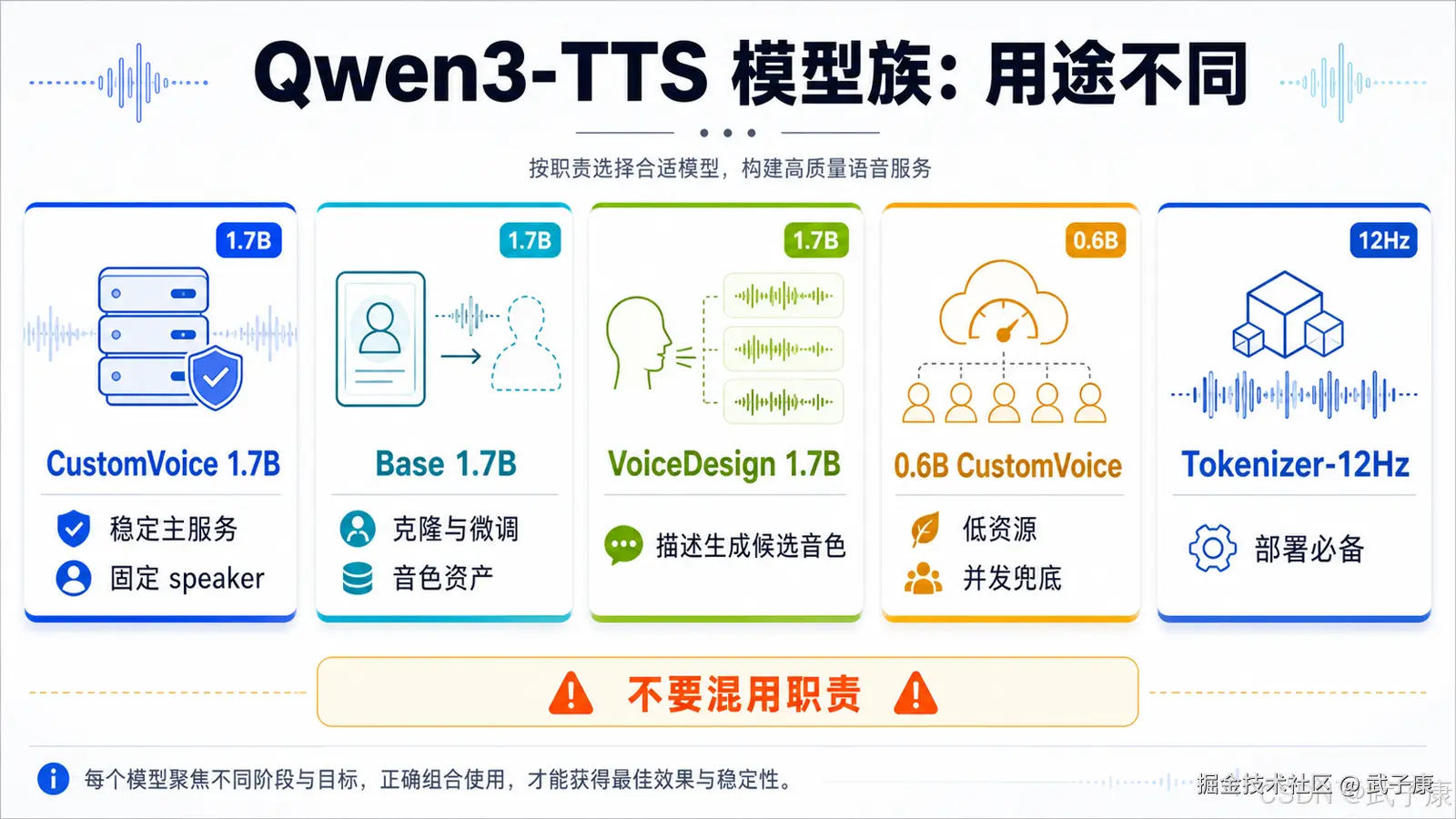
Qwen3-TTS 不是单个模型,而是一组模型。它们的用途不同,不能混着理解。
目前最关键的几个版本是:
Qwen3-TTS-12Hz-1.7B-CustomVoice
这是最适合做稳定 TTS 主服务的版本。它的核心能力是使用官方预置的高质量音色进行语音合成。你只需要指定语言、speaker 和可选的 instruct,就可以输出对应音色的语音。
它适合的场景是:
机器人固定声音; 语音助手固定声音; 播报系统; 客服系统; 内容生成工具; 产品默认 TTS; 需要每次声音一致的业务。
它不适合的场景是:
临时克隆某个人的声音; 根据一句话自由设计新音色; 大量探索不同角色声音。
原因很简单:它的优势是稳定,不是自由。
Qwen3-TTS-12Hz-1.7B-Base
这是声音克隆和微调路线的核心模型。它可以基于参考音频做快速声音克隆,也可以用于后续微调。
它适合的场景是:
用户上传参考音频生成自己的声音; 品牌音色训练; 角色音色复用; 山东话、地方口音等官方预置音色没有覆盖的场景; 后续构建独立的声音资产库。
它不适合直接作为默认主服务。因为克隆链路天然比固定音色链路更复杂,涉及参考音频质量、文本标注、speaker prompt 复用、版权授权、音色一致性测试、音频缓存和用户隔离。
Qwen3-TTS-12Hz-1.7B-VoiceDesign
这是音色设计模型。它的作用不是"稳定复用一个固定声音",而是根据自然语言描述生成某种声音。例如:
"年轻男声,普通话,声音清晰,略带山东口音,适合机器人助手。" "成熟女声,语速偏慢,温柔但不做作,适合知识类播报。" "中年男声,低沉稳重,像纪录片旁白。"
这个模型很适合做音色探索,但不适合作为生产主链路。因为用户描述天然具有不确定性,同样一句描述在不同输入文本、不同采样参数、不同上下文下,可能得到细节不同的声音表现。
更合理的用法是:
先用 VoiceDesign 生成候选音色; 人工筛选出满意的声音; 再用 Base 构建可复用的 clone prompt; 最后把这个声音沉淀成固定音色资产。
也就是说,VoiceDesign 是设计工具,不是主服务。
Qwen3-TTS-12Hz-0.6B-CustomVoice
这是轻量版固定音色模型。它的用途是降低资源占用,提高部署灵活性。适合显存紧张、并发压力较大、对音质要求没那么高的场景。
如果你只有消费级显卡,或者只想在边缘设备上跑一个能用的 TTS,0.6B 可以考虑。
但如果你有 A6000 48GB 这类显卡,第一选择就不应该是 0.6B,而应该先上 1.7B。TTS 的质量差距最终会体现在声音质感、稳定性、长文本自然度和产品感上。主服务不应该一开始就为了省一点显存牺牲体验。
Qwen3-TTS-Tokenizer-12Hz
这个不是主模型,而是语音 tokenizer。Qwen3-TTS 依赖它完成音频编码和解码相关能力。部署时不能只下载 TTS 模型,还要把 tokenizer 一起准备好。
三、你的需求应该怎么拆
你的需求可以概括为三句话:
第一,希望声音稳定,每次生成效果一致。
第二,希望支持方言。
第三,后续克隆语音可以独立成一个服务。
这三个需求不能用一个模型硬塞。正确架构应该拆成两到三个服务。
第一层是主 TTS 服务。
它负责普通话、固定音色、稳定播报、机器人日常回答、语音助手输出。这个服务应该使用 Qwen3-TTS-12Hz-1.7B-CustomVoice。
它的要求是:
固定 speaker; 固定 language; 固定 instruct; 固定采样参数; 固定文本清洗规则; 固定音频后处理; 固定缓存策略。
这个服务追求的是一致性,不追求每次都有新鲜感。
第二层是方言服务。
如果只是北京话、四川话这类官方预置音色可以覆盖的方言,可以直接放在 CustomVoice 主服务里,通过固定 speaker 实现。
但如果目标是山东话,尤其是青岛、胶东、鲁西南这类更细分的口音,不能指望 CustomVoice 直接稳定完成。官方预置音色没有明确覆盖山东话。此时应该把山东话放进独立克隆或微调链路。
第三层是克隆服务。
克隆服务应该独立部署 Qwen3-TTS-12Hz-1.7B-Base。它负责上传参考音频、生成 speaker prompt、保存音色资产、后续复用声音。
这个服务不能和主服务混在一起。原因有四个。
第一,克隆服务的输入更复杂。主服务只需要 text、language、speaker。克隆服务需要 ref_audio、ref_text、voice_clone_prompt,甚至还要做音频质量检测。
第二,克隆服务有更高的合规风险。用户上传的声音可能不是自己的。生产系统必须考虑授权、留存、删除、审核和水印策略。
第三,克隆服务的结果更不稳定。参考音频噪声、口音、录音设备、说话情绪都会影响输出。
第四,克隆服务更适合异步化。主 TTS 服务要低延迟返回;克隆音色构建可以慢一点,但要保证质量。
所以最合理的设计是:
tts-main 负责稳定固定音色。
tts-clone 负责克隆和个性化音色。
tts-voice-design 负责音色探索和候选音色生成。
四、为什么主服务应该选择 CustomVoice
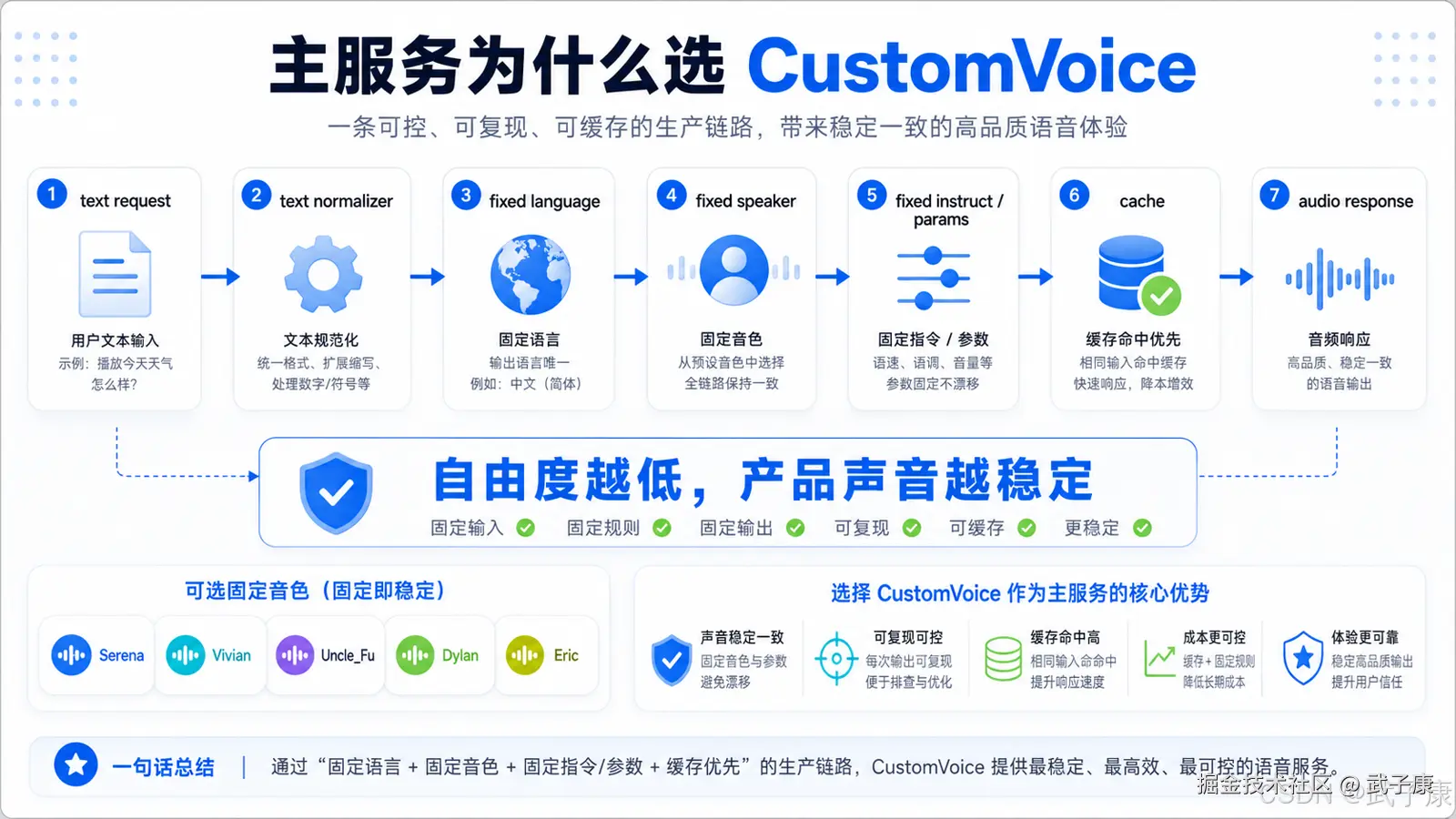
稳定声音的关键不是"模型能力最自由",而是"模型自由度最低且质量足够高"。
这句话很重要。
声音生成越自由,输出越不稳定。你让模型根据自然语言描述"生成一个温柔的年轻女声",它每次都可能在音高、气息、情绪、语速、年龄感上产生细节差异。对于创作,这是优点;对于产品,这是缺点。
产品语音最怕三件事:
第一,同一个助手今天像 25 岁,明天像 35 岁。
第二,同一段开场白每次语速和情绪不同。
第三,用户刚适应一个声音,下一次又变了。
这会破坏产品人格的一致性。
CustomVoice 的价值就在于它提供了固定 speaker。你不需要每次重新描述声音,不需要每次上传参考音频,不需要每次让模型自由设计。你只需要指定:
language = Chinese speaker = Vivian / Serena / Uncle_Fu / Dylan / Eric instruct = 固定值或空字符串
这样输出的声音才更接近稳定生产服务。
对于你的场景,默认可以这样选:
女声助手:Vivian 或 Serena。
男声助手:Uncle_Fu。
北京话风格:Dylan。
四川话风格:Eric。
如果做机器人助手,我更倾向于 Uncle_Fu 或 Serena。Uncle_Fu 更稳重,适合解释、播报、设备反馈、系统提示。Serena 更温和,适合陪伴、助手、长时间对话。Vivian 更年轻、更亮,适合更活泼的产品风格。
Dylan 和 Eric 可以作为"方言模式",但不应该作为默认普通话主音色。方言音色适合特定功能入口,不适合所有场景。
五、方言支持要分清"能说"和"稳定可用"
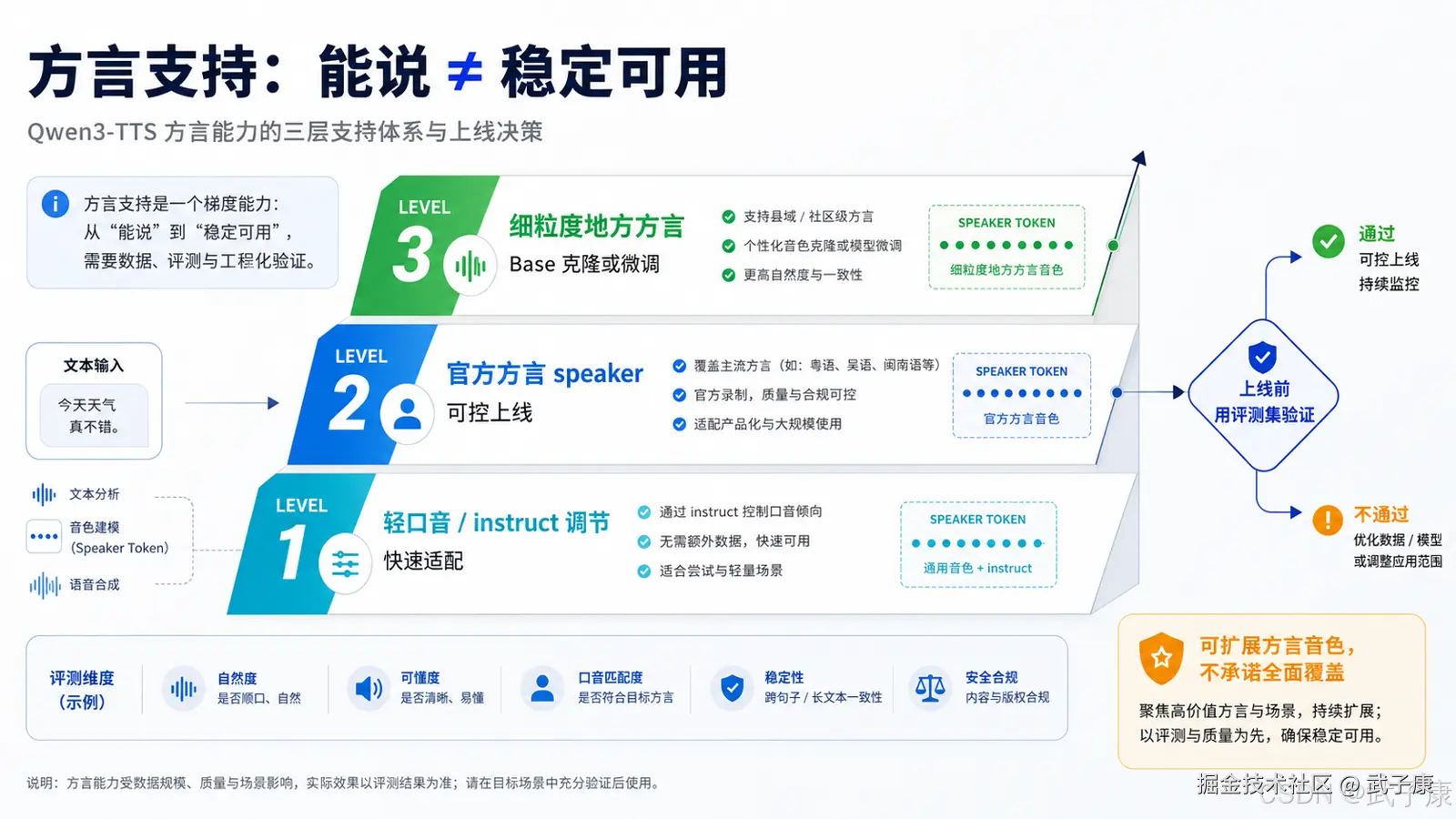
方言支持有三个层次。
第一层是普通话带一点地方口音。
这类需求比较容易。你可以通过 speaker 或 instruct 控制一些语音风格,例如"自然一点""更像口语""稍微带地方口音"。但这种方式不保证强一致性。
第二层是明确方言音色。
例如北京话、四川话。官方预置 speaker 如果本身就是对应方言,那么稳定性会更高。因为模型不是每次临时理解"请说四川话",而是使用一个固定的方言 speaker。
第三层是真正的地方方言能力。
例如山东话、青岛话、胶东方言。这类方言通常需要更具体的训练数据、发音规律、语料标注和目标音色。单靠 prompt 很难稳定解决。
所以你的方言策略应该是:
北京话、四川话:直接使用 CustomVoice 的方言 speaker。
山东话:不要放在第一阶段主服务里,后续用 Base 做独立克隆或微调。
普通话轻微地方感:可以通过 instruct 测试,但不能承诺稳定。
这也是产品设计上的边界。不要在产品上写"全面支持山东话",除非你真的做了专项测试。更稳妥的说法是:
"支持普通话、英语等多语言语音合成,并可扩展方言音色。当前内置部分方言风格音色,更多地方音色可通过克隆或定制服务实现。"
这句话更准确,也更安全。
六、为什么克隆语音必须独立服务
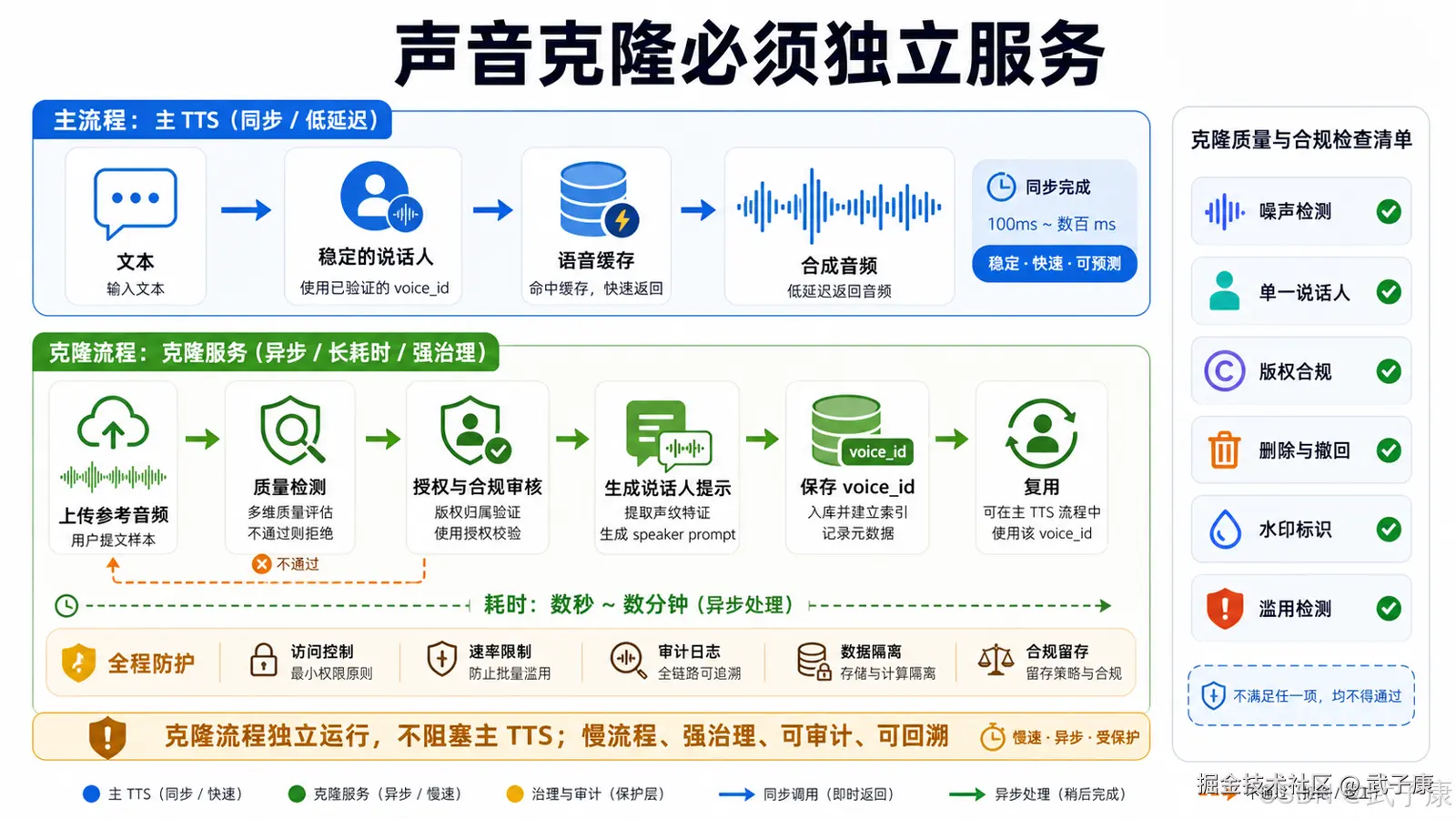
声音克隆很吸引人,但它不应该和主 TTS 服务混在一起。
主 TTS 服务是确定性的产品能力。它应该像一个基础设施:稳定、可监控、可缓存、可扩容、可回滚。
克隆服务是个性化能力。它的不确定性更高,风险更高,流程更复杂。
一个成熟的克隆服务至少要处理这些问题:
参考音频质量检测; 参考音频降噪; 说话人是否单一; 是否包含背景音乐; 是否有版权授权; 是否需要用户声明; 是否允许公开生成; 是否保存原始音频; 是否保存 speaker embedding; 是否支持用户删除; 是否支持批量生成; 是否允许第三方调用; 是否做内容审核; 是否做音频水印; 是否做滥用检测。
这些问题和普通 TTS 服务不是一个复杂度。
从架构上,主 TTS 服务可以是同步 API:
请求文本,返回音频。
克隆服务应该更像任务系统:
上传音频; 检测质量; 生成音色; 试听; 确认保存; 生成 speaker_id; 后续通过 speaker_id 调用。
这样主服务不会被克隆链路拖慢,也不会因为用户上传音频导致整个 TTS 系统变复杂。
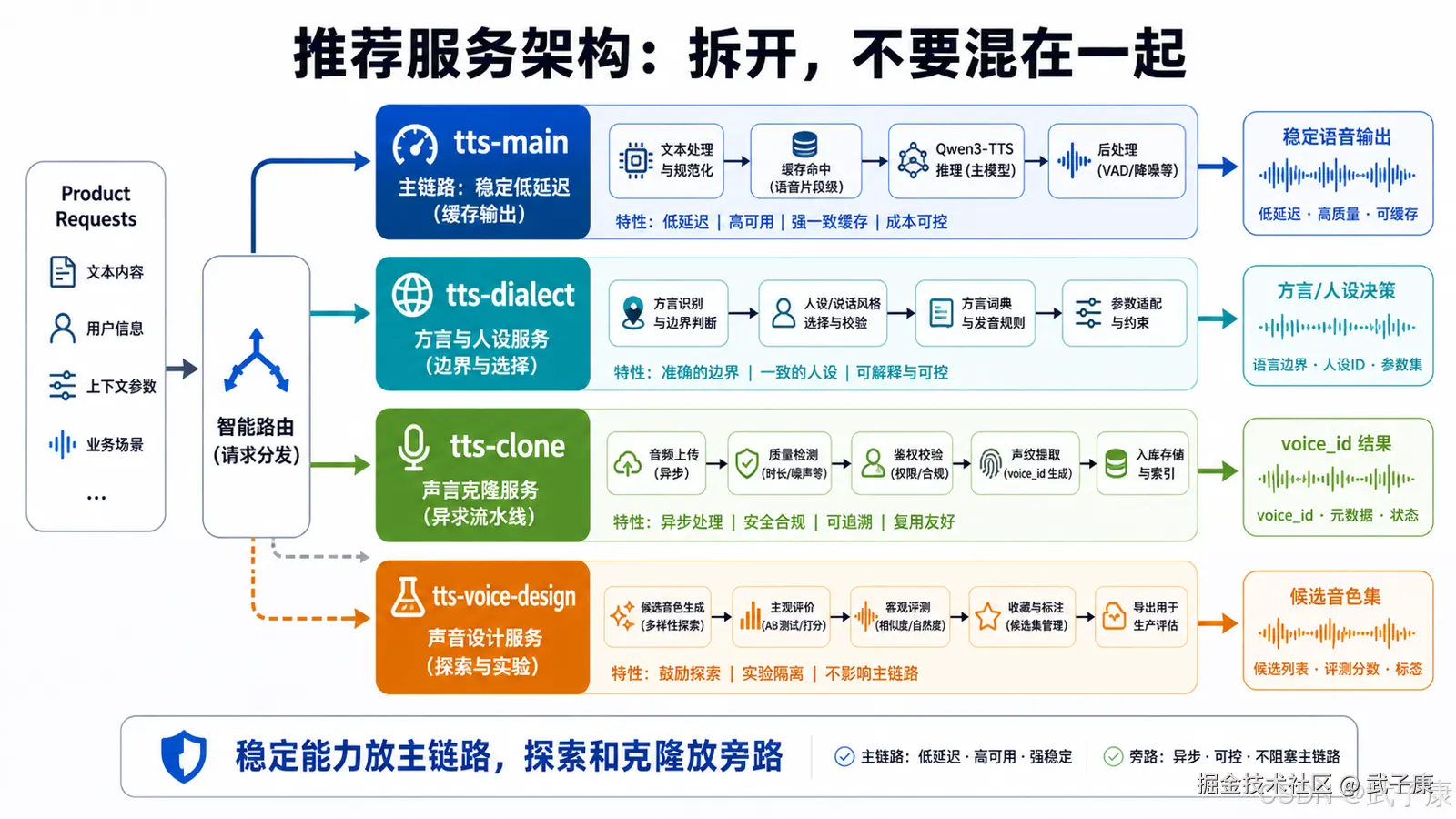
七、推荐的服务架构
推荐架构如下:
text
tts-main
模型:Qwen3-TTS-12Hz-1.7B-CustomVoice
职责:稳定普通话、英语、固定音色、产品默认播报
特点:低延迟、固定 speaker、固定参数、强缓存
tts-dialect
模型:Qwen3-TTS-12Hz-1.7B-CustomVoice / Qwen3-TTS-12Hz-1.7B-Base
职责:北京话、四川话、后续山东话
特点:官方方言 speaker 直接走 CustomVoice;非官方方言走 Base 克隆或微调
tts-clone
模型:Qwen3-TTS-12Hz-1.7B-Base
职责:用户上传参考音频、声音克隆、品牌音色、角色音色
特点:异步任务、音频质检、授权管理、speaker profile 持久化
tts-voice-design
模型:Qwen3-TTS-12Hz-1.7B-VoiceDesign
职责:根据自然语言描述设计候选音色
特点:内部工具或高级功能,不作为主生产链路这套架构的核心原则是:
稳定能力放主链路。 探索能力放旁路。 克隆能力独立化。 方言能力分阶段。 低成本模型做兜底,不做默认。
八、参数固定比换模型更重要
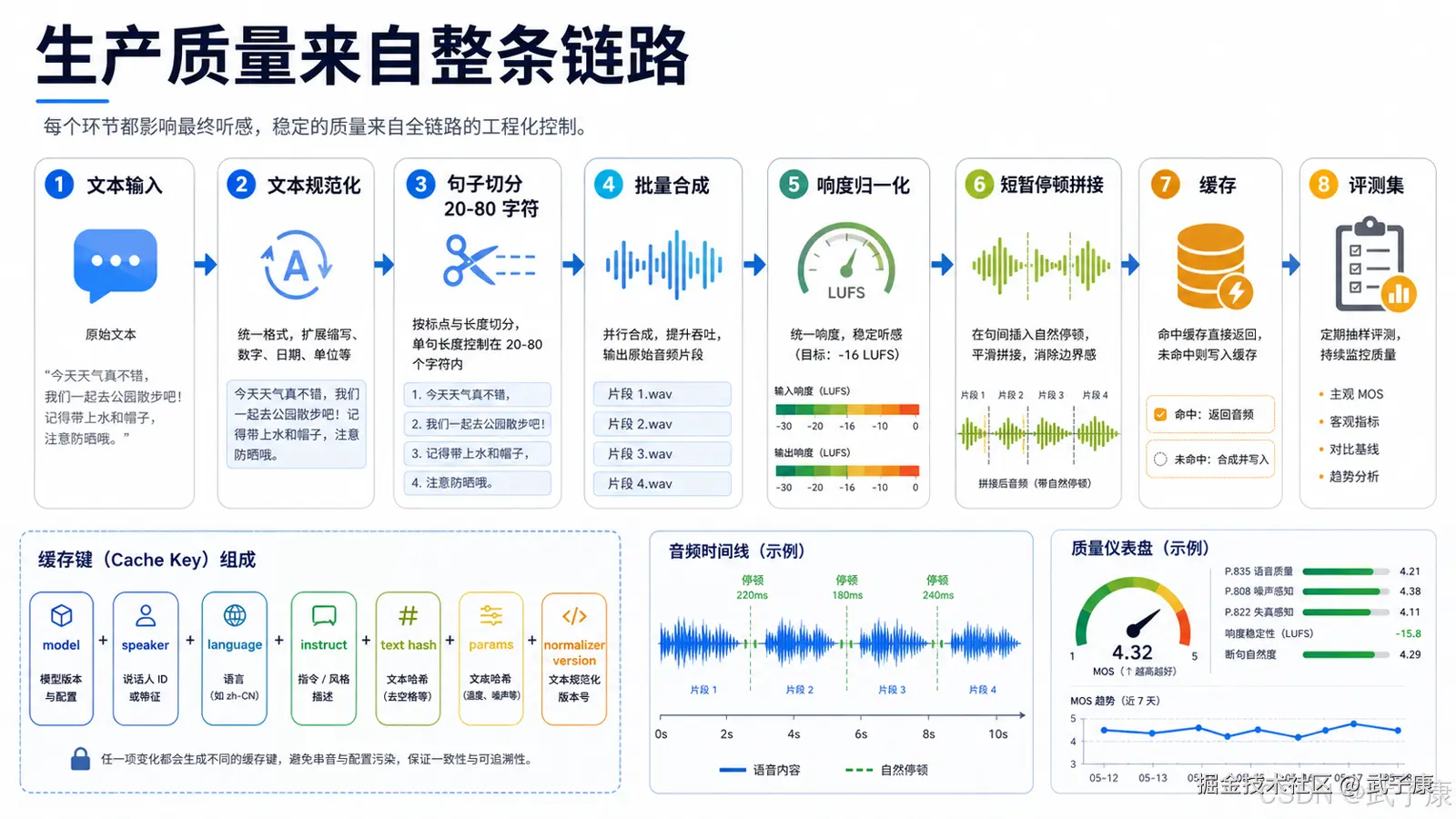
很多人在 TTS 选型里只关心模型,却忽略参数控制。
实际上,稳定声音的关键是:
固定模型版本; 固定 speaker; 固定 language; 固定 instruct; 固定采样参数; 固定文本规范化; 固定标点处理; 固定数字读法; 固定中英文混读规则; 固定缓存策略。
例如同一段文本:
"今天 18:30 开会,GPU 使用率 92%,请提前 5 分钟准备。"
如果文本规范化不一致,TTS 可能出现不同读法:
18:30 读作"十八点三十"; 18:30 读作"下午六点半"; GPU 读作"居皮优"; GPU 读作"G P U"; 92% 读作"百分之九十二"; 92% 读作"九十二 percent"。
这不是模型问题,而是前处理问题。
所以你要做一个稳定 TTS 服务,必须加一层 text normalizer。
它负责:
数字转中文读法; 时间转中文读法; 百分比转中文读法; 英文缩写保留或拆读; URL、代码、符号特殊处理; emoji 删除或替换; Markdown 清洗; 多余空格清理; 标点统一; 长文本分句。
TTS 不是把文本直接丢给模型就完事。真正的生产质量来自模型、前处理、后处理、缓存、监控共同作用。
九、长文本要切句,不要一口气生成
长文本 TTS 的稳定性比短文本更难。
如果一次性输入很长的博客、文章、说明书,可能出现以下问题:
语速漂移; 情绪漂移; 停顿异常; 音色轻微变化; 末尾吞字; 生成时间过长; 失败重试成本高; 缓存命中率低。
正确做法是先切句,再逐段生成,最后拼接音频。
切句规则不能太粗暴。不能只按句号切,也要考虑逗号、分号、冒号、换行、Markdown 标题和列表。
推荐策略:
单段长度控制在 20 到 80 个中文字符; 太短的句子合并; 太长的句子拆分; 标题单独处理; 列表项单独处理; 代码块不读或转为解释文本; 每段生成后统一音量; 拼接处加入短暂停顿。
这比单次生成长文本更稳定。
十、缓存是 TTS 服务的关键优化
TTS 很适合做缓存。
因为很多文本是重复的:
系统提示音; 机器人固定回复; 欢迎语; 错误提示; 菜单播报; 常见问答; 固定说明; 导航指令; 状态提示。
这些内容不应该每次都重新生成。
缓存 key 应该包括:
模型版本; speaker; language; instruct; 文本 hash; 采样参数; 文本规范化版本; 音频后处理版本。
只用文本 hash 不够。因为同一段文本,不同 speaker、不同 instruct、不同 language,输出都不同。
缓存命中后直接返回音频文件,可以显著降低延迟和 GPU 压力。
对于机器人或语音助手,可以提前生成一批高频语音:
"好的。" "我明白了。" "正在处理。" "请稍等。" "已经完成。" "没有找到相关结果。" "网络连接失败。" "请重新说一遍。"
这些固定语音甚至可以离线预生成,直接放 CDN 或对象存储。
这样 TTS 主服务只处理真正动态的内容。
十一、为什么 1.7B 比 0.6B 更适合作为第一选择
0.6B 的价值是轻量,但你的场景不是极限轻量部署。
你有 A6000 48GB,做本地模型服务时,1.7B 并不是大模型。相比 LLM,TTS 1.7B 的资源压力很小。真正需要关注的是工程效率和音频稳定性,而不是盲目省显存。
主服务一开始应该选择质量更稳的路线。后续真的遇到并发压力,再把 0.6B 加进来做分层。
例如:
高质量模式:1.7B-CustomVoice。 极速模式:0.6B-CustomVoice。 克隆模式:1.7B-Base。 批量生成模式:根据队列压力选择 1.7B 或 0.6B。
这样更合理。
不要一开始就为了"以后可能并发高"而牺牲默认体验。产品早期最重要的是声音质量、稳定性和可用性。并发是后续压测和调度问题。
十二、vLLM 目前不能按 LLM 服务的成熟度来预期
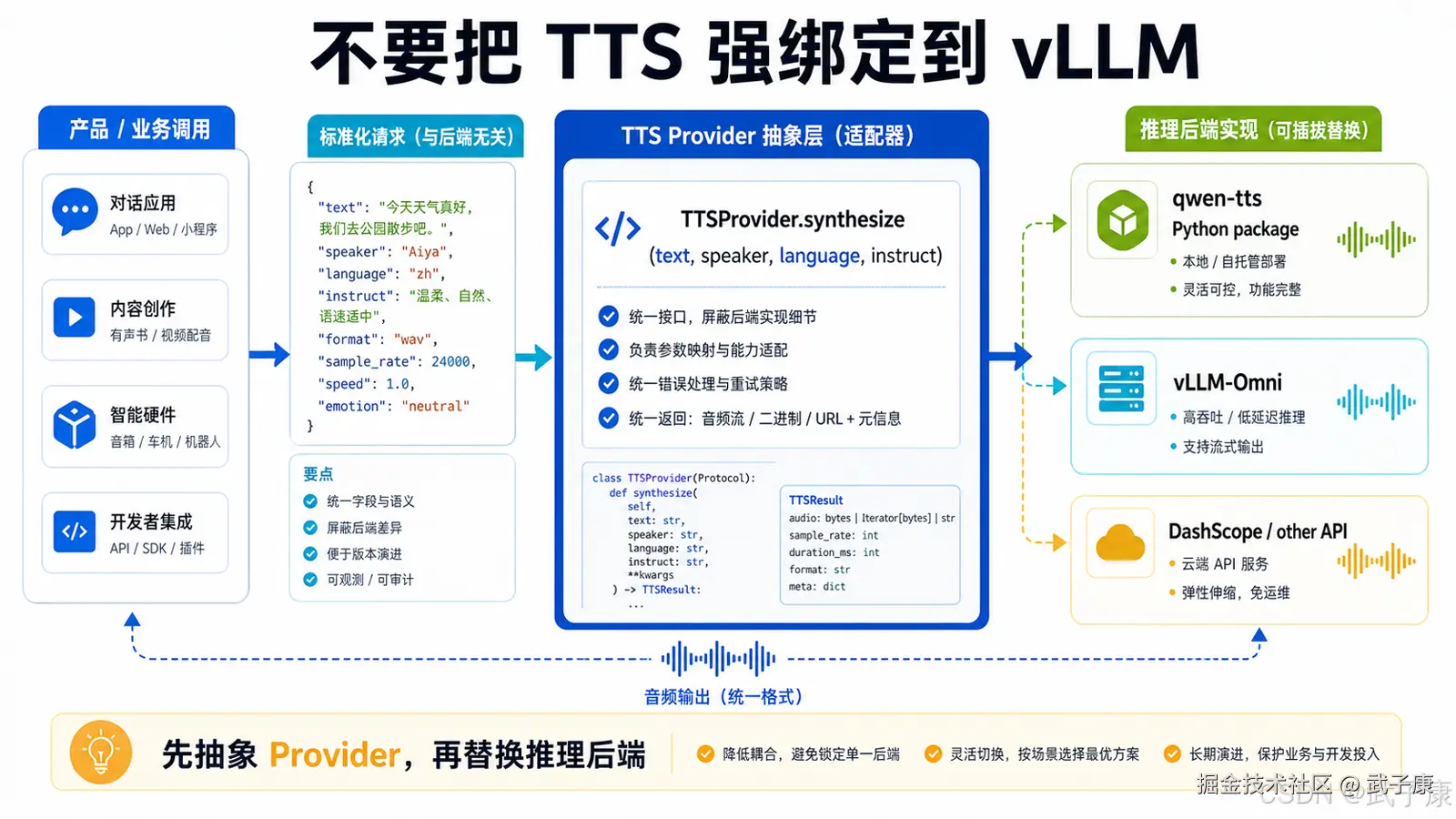
你已经在 LLM 上用 vLLM,并且体验很好。自然会想把 STT、TTS 也统一进 vLLM。
这个方向是对的,但当前阶段要区分"方向正确"和"现在能不能生产落地"。
Qwen3-TTS 官方提到 vLLM-Omni 支持 Qwen3-TTS,但当前主要是 offline inference,online serving 后续支持。这意味着它还不能完全等同于你现在使用的 vllm-openai LLM 服务。
短期生产落地更现实的路线是:
用 qwen-tts Python 包加载模型; 自己封装 FastAPI; 内部实现文本清洗、切句、缓存、队列、音频拼接; 等 vLLM-Omni online serving 成熟后再迁移。
不要把 TTS 服务设计成强依赖 vLLM。现在应该抽象一层 TTS Provider 接口。
例如:
python
class TTSProvider:
def synthesize(self, text, speaker, language, instruct):
pass底层可以先接 qwen-tts,后续再接 vLLM-Omni、DashScope API 或其他推理后端。这样不会被某一个框架锁死。
十三、生产 API 应该怎么设计
主服务 API 可以设计得简单一点。
请求示例:
json
{
"text": "你好,我是你的语音助手。",
"language": "Chinese",
"speaker": "Serena",
"style": "default",
"stream": true
}服务端不要直接把用户传入的 style 原样塞给 instruct。应该做白名单映射。
例如:
json
{
"default": "",
"calm": "用平静自然的语气说",
"happy": "用轻松愉快的语气说",
"serious": "用正式稳重的语气说"
}这样用户只能选择预设风格,不能随便写一段 prompt 影响稳定性。
对于主服务,instruct 最好为空或非常稳定。只有当你确实需要情绪控制时,才使用固定模板。
克隆服务 API 应该分两步。
第一步创建音色:
json
{
"ref_audio": "xxx.wav",
"ref_text": "参考音频对应文本",
"voice_name": "my_voice"
}返回:
json
{
"voice_id": "voice_xxx",
"status": "ready"
}第二步使用音色:
json
{
"text": "这是一段用克隆音色生成的语音。",
"language": "Chinese",
"voice_id": "voice_xxx"
}这样能把昂贵的参考音频处理和普通生成请求分开。
十四、音频质量评估不能只靠主观听感
TTS 评估很容易变成"我感觉还不错"。这不够。
至少要建立一套小型测试集。
测试集应该包括:
短句; 长句; 数字; 日期; 时间; 英文缩写; 中英文混合; 技术名词; 口语句子; 问句; 感叹句; 多标点句; 方言测试句; 机器人常用回复; 异常输入。
例如:
"今天下午 3 点 30 分开会。" "GPU 使用率是 92%,显存占用 38GB。" "请打开客厅灯,然后把音量调到 30%。" "这个 API 返回了 500 错误。" "我没听清,请你再说一遍。" "你现在要去哪里?" "这个问题我暂时无法处理。"
每个 speaker 都跑一遍,保存音频,人工打分。
评分维度包括:
音色一致性; 发音准确性; 数字读法; 停顿自然度; 情绪稳定性; 是否吞字; 是否有噪声; 是否有机械感; 长文本是否漂移; 方言是否自然。
先做 50 条测试句就够。不要一开始追求复杂评测系统。早期最重要的是快速发现明显问题。
十五、最终选型结论
按照你的需求,最终选择非常明确。
主服务:
Qwen3-TTS-12Hz-1.7B-CustomVoice
用途:
稳定普通话; 固定产品声音; 机器人语音助手; 日常播报; 低延迟交互; 可缓存高频语音。
默认 speaker:
男声可以优先试 Uncle_Fu。 女声可以优先试 Serena。 更年轻明亮的女声可以试 Vivian。 北京话可以试 Dylan。 四川话可以试 Eric。
克隆服务:
Qwen3-TTS-12Hz-1.7B-Base
用途:
上传参考音频; 构建用户声音; 品牌音色; 角色音色; 山东话等官方预置没有覆盖的口音; 后续微调。
音色设计服务:
Qwen3-TTS-12Hz-1.7B-VoiceDesign
用途:
探索新声音; 生成候选音色; 设计人设声音; 内部调音工具; 不作为稳定生产主链路。
兜底服务:
Qwen3-TTS-12Hz-0.6B-CustomVoice
用途:
显存紧张时使用; 高并发低成本模式; 边缘部署; 非核心场景; 批量低质量预览。
不推荐的做法:
不要用 VoiceDesign 直接做主服务。 不要用 Base 即时克隆承担所有请求。 不要靠自由 prompt 实现稳定方言。 不要一开始就选 0.6B 作为默认主音色。 不要把主服务和克隆服务混在一起。 不要没有文本规范化就直接生成音频。 不要没有缓存就上生产。 不要承诺官方没有明确覆盖的方言能力。
十六、一个更实际的落地路线
第一阶段,只做稳定主服务。
部署:
Qwen3-TTS-12Hz-1.7B-CustomVoice Qwen3-TTS-Tokenizer-12Hz
完成:
FastAPI 封装; 固定 speaker; 文本清洗; 短句生成; 音频返回; 高频语音缓存; 基础日志; 错误重试; 并发测试。
目标:
先让机器人或产品拥有一个稳定、可复用、质量足够好的默认声音。
第二阶段,做方言模式。
加入:
Dylan; Eric; 方言测试集; 方言入口; 方言缓存。
目标:
支持明确可控的方言风格,但不夸大能力边界。
第三阶段,做克隆服务。
部署:
Qwen3-TTS-12Hz-1.7B-Base
完成:
上传参考音频; 音频质量检测; 创建 voice_id; 保存 speaker prompt; 复用克隆音色; 权限隔离; 用户删除; 音频审核。
目标:
让克隆成为独立能力,而不是污染主服务。
第四阶段,做 VoiceDesign。
部署:
Qwen3-TTS-12Hz-1.7B-VoiceDesign
完成:
用自然语言描述生成候选声音; 人工试听; 选中后沉淀为 voice_id; 接入 Base 复用。
目标:
把 VoiceDesign 变成"设计音色的工具",而不是"每次在线生成的不稳定入口"。
十七、总结
Qwen3-TTS 的模型选择,本质上是工程边界选择。
你要稳定声音,就选 CustomVoice。
你要克隆声音,就选 Base。
你要设计声音,就选 VoiceDesign。
你要低成本部署,就选 0.6B。
你要产品主服务,就不要把所有能力混在一起。
对于你的需求,最优方案是:
主服务使用 Qwen3-TTS-12Hz-1.7B-CustomVoice,固定 speaker,固定参数,固定文本规范化和缓存策略,优先保证声音一致性。
克隆服务使用 Qwen3-TTS-12Hz-1.7B-Base,独立处理用户参考音频、音色生成、voice_id 保存和复用。
VoiceDesign 只作为音色探索工具,用来设计候选声音,不承担生产主链路。
方言能力分层处理。官方已有的方言 speaker 可以直接用 CustomVoice;山东话这类未明确预置的方言,不要靠 prompt 硬控,而应该进入克隆或微调路线。
这套架构不会最花哨,但最稳。TTS 产品最终拼的不是"某一次生成有多惊艳",而是"一千次、一万次生成后,声音仍然像同一个人"。
作者:武子康的个人博客