DiCLIP: Diffusion Model Enhances CLIP's Dense Knowledge for Weakly Supervised Semantic Segmentation
• 期刊:IEEE Transactions on Image Processing 2026
• arXiv:2605.04593
• 代码:https://github.com/zwyang6/DiCLIP
一、背景与核心问题
语义分割的目标是对图像中每个像素打上语义标签。全监督方法依赖大量像素级标注,成本极高。弱监督语义分割(WSSS)以图像级标签为监督信号,通过类激活图(CAM)生成伪标签后训练分割网络,显著降低标注成本。
WSSS的核心难点:如何生成高质量的CAM。
近年来,CLIP(对比语言-图像预训练模型)因其在4亿图文对上的预训练能力被引入WSSS,用于辅助生成CAM。然而,本文作者发现了一个被长期忽视的根本性瓶颈:
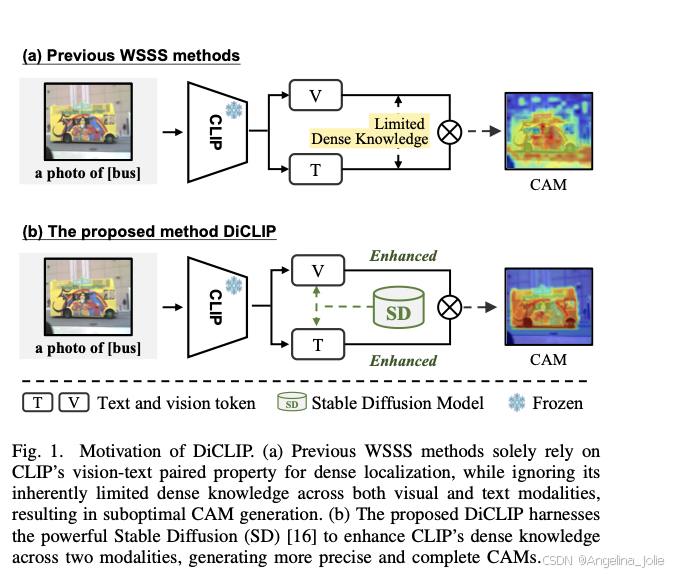
▶ CLIP在视觉和文本两个模态上,都存在固有的密集知识缺陷
具体来说:
• 视觉端:CLIP的自注意力图因全局图文对齐训练范式,呈现"过度平滑"现象------注意力分布散漫,缺乏对目标边界和细节的精准感知,导致CAM质量差。
• 文本端:单一的文本描述(如"a photo of bus")无法涵盖该类别在现实中的外观多样性,patch与文本的匹配精度天然受限。
问题已经找到,怎么解决?作者的方案是:用生成式扩散模型(Stable Diffusion,SD)从外部为CLIP"补充"密集知识,由此提出 DiCLIP 框架。
二、方法:两个核心模块
DiCLIP整体分为离线阶段(构建知识缓存)和在线阶段(训练分割),包含两个关键模块:视觉相关增强(VCE)和文本语义增强(TSA)。
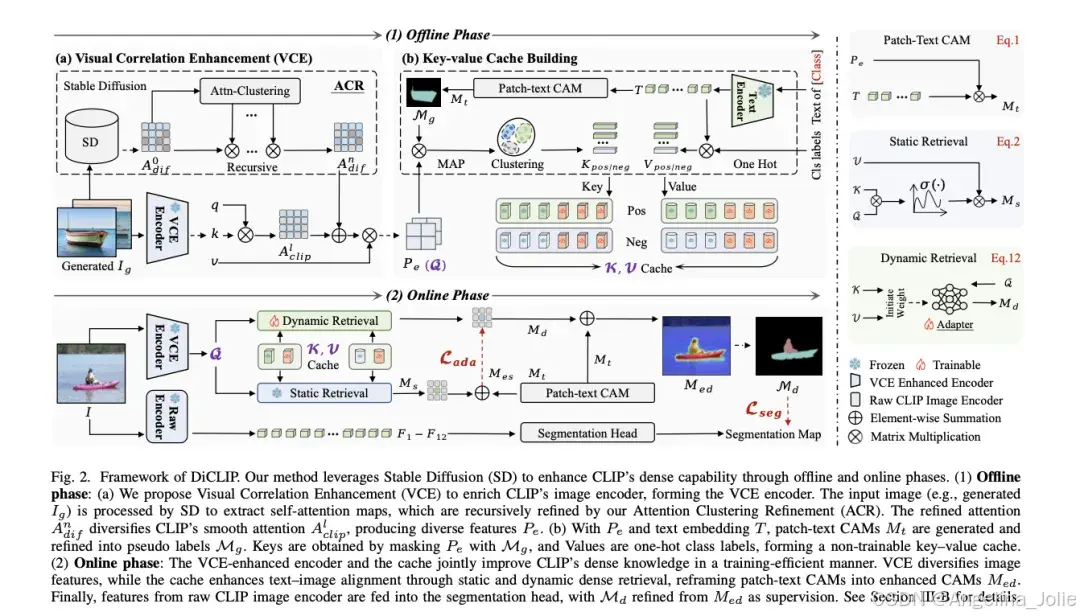
模块一:视觉相关增强(VCE)
▶ 问题根源
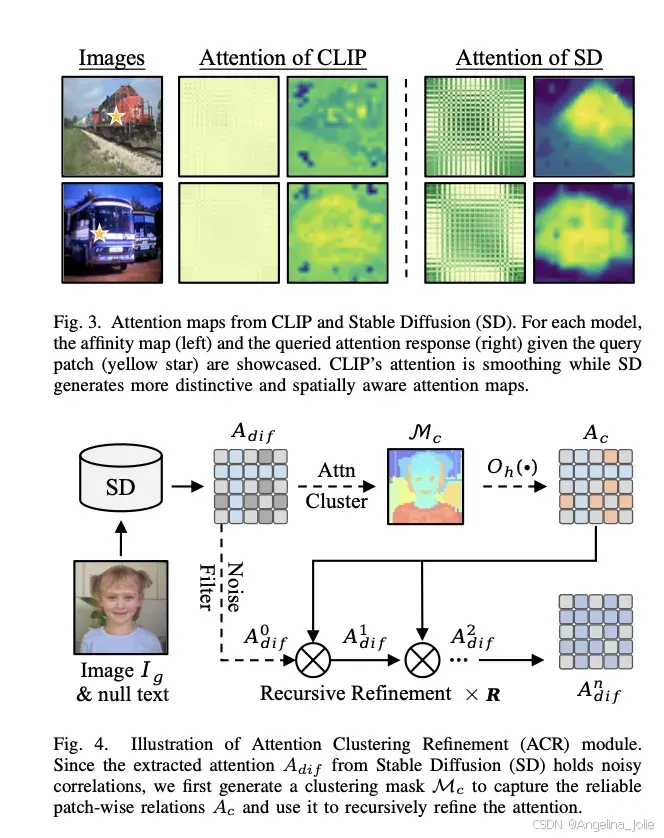
CLIP自注意力的计算逻辑是:每个patch的查询向量与所有patch的键向量计算相似度,再对值向量加权聚合。由于训练时追求全局图文对齐,最终的注意力图高度平滑,缺乏细粒度的空间区分能力。
而SD中的UNet去噪网络需要从噪声中逐步还原图像,其自注意力图天然保留了丰富的空间上下文和多样化语义区域------正好是CLIP所缺少的。
▶ 注意力聚类精炼(ACR)
直接拿SD的原始注意力图用于增强CLIP效果不佳(存在噪声)。作者设计了ACR模块进行精炼:
① 将图像送入SD(配合空文本提示),提取UNet解码器中的自注意力图; ② 用在线聚类算法将注意力图划分为若干个语义群组,生成聚类掩码; ③ 利用聚类掩码构造patch间亲和力矩阵,对SD注意力图进行递归精炼:每次迭代都增强同语义区域内的关联,抑制跨语义噪声。实验表明3次迭代效果最优,迭代过多会导致相关性过于刚性。
▶ LoRA式加性融合
精炼后的SD注意力图以"加法"方式注入CLIP的注意力层(类比LoRA低秩更新的设计思路):
CLIP增强注意力 = 原始CLIP注意力 + 权重系数 × 精炼后的SD注意力
这种设计的关键优势:在增强空间多样性的同时,完整保留了CLIP的跨模态对齐能力。作者对比了归一化、缩放、门控等多种融合方式,加性融合效果最佳。
效果:VCE模块零训练参数,将patch-text CAM的mIoU从12.1%提升至72.2%,接近多数需要训练的WSSS方法!
模块二:文本语义增强(TSA)
▶ 核心洞察
"a photo of cat"这一句话无法覆盖猫在现实图像中的姿态、光照、背景的全部多样性。为此,TSA利用SD的生成能力,构建一个视觉键值缓存(Key-Value Cache),将CAM生成从"patch与文本直接匹配"转变为"视觉知识检索"的新范式。
▶ 缓存构建(离线,无需训练)
键(Keys)的构建: ① 用SD为每个类别生成若干单类别图像(只含单一目标,保证语义纯洁性,规避共现干扰); ② 用VCE增强的CLIP编码器提取特征; ③ 用伪掩码进行掩码均值池化,分别获取前景和背景特征; ④ 对每类前景特征做K-means聚类,聚类中心作为键存入缓存。
值(Values)的构建: 作者的一个创新点是用文本嵌入对类别标签加权,而非直接使用one-hot标签。具体做法:计算文本嵌入与各类键的相似度,将相似度权重分配给one-hot类别标签形成值向量。这样构造的值能够捕获类内差异和类间差异,使检索更加可靠。
▶ 静态知识检索(训练无关)
以每个图像patch的视觉特征作为查询,计算与所有键的相似度,加权聚合对应的值,得到基于缓存的CAM。前景缓存和背景缓存各自检索,再用背景响应对前景进行过滤,进一步去噪。
结果:仅通过静态检索(无需任何训练),mIoU从72.0%提升至74.0%,超越了大多数需要训练的方法!
▶ 动态知识检索(轻量微调)
为进一步突破静态检索的上限,TSA将键值缓存的权重用于初始化一个两层MLP适配器,将静态检索过程转化为可学习的动态过程。同时引入少量可学习的键值提示(learnable prompts)进一步提升灵活性。
结果:动态检索将CAM mIoU进一步提升至78.2%,超越CLIP-based SOTA至少2.8%。
▶ 推理时无SD依赖
值得注意的是,训练/推理阶段完全不依赖SD------SD仅在离线构建缓存时使用,正式推理只用原始CLIP编码器和轻量级分割头。
三、实验结果
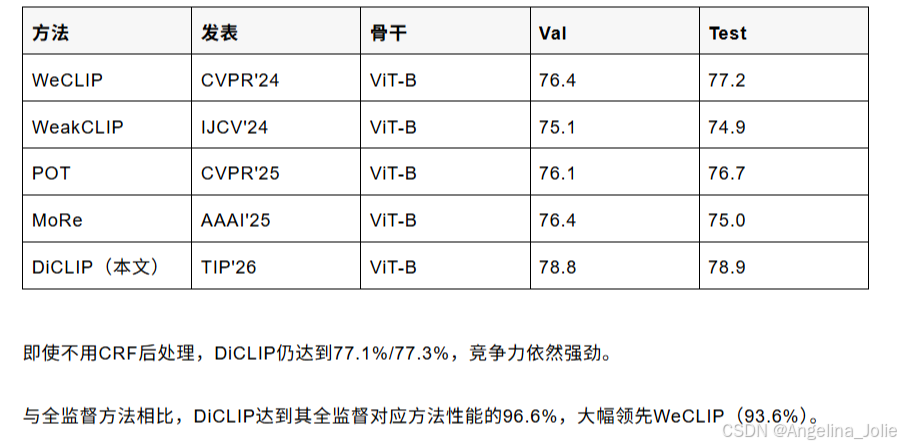
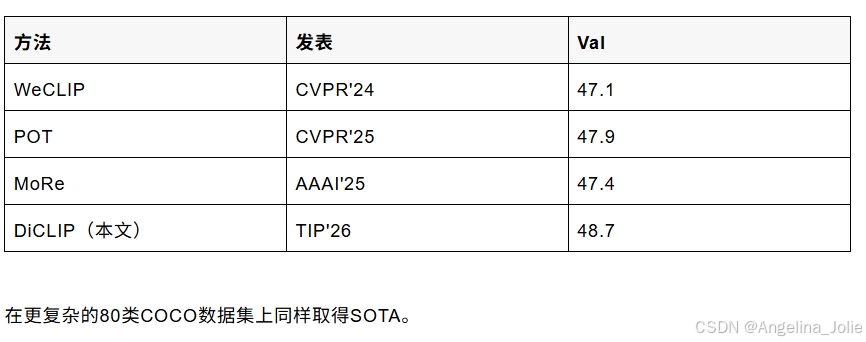
▶ PASCAL VOC 2012
▶ MS COCO 2014
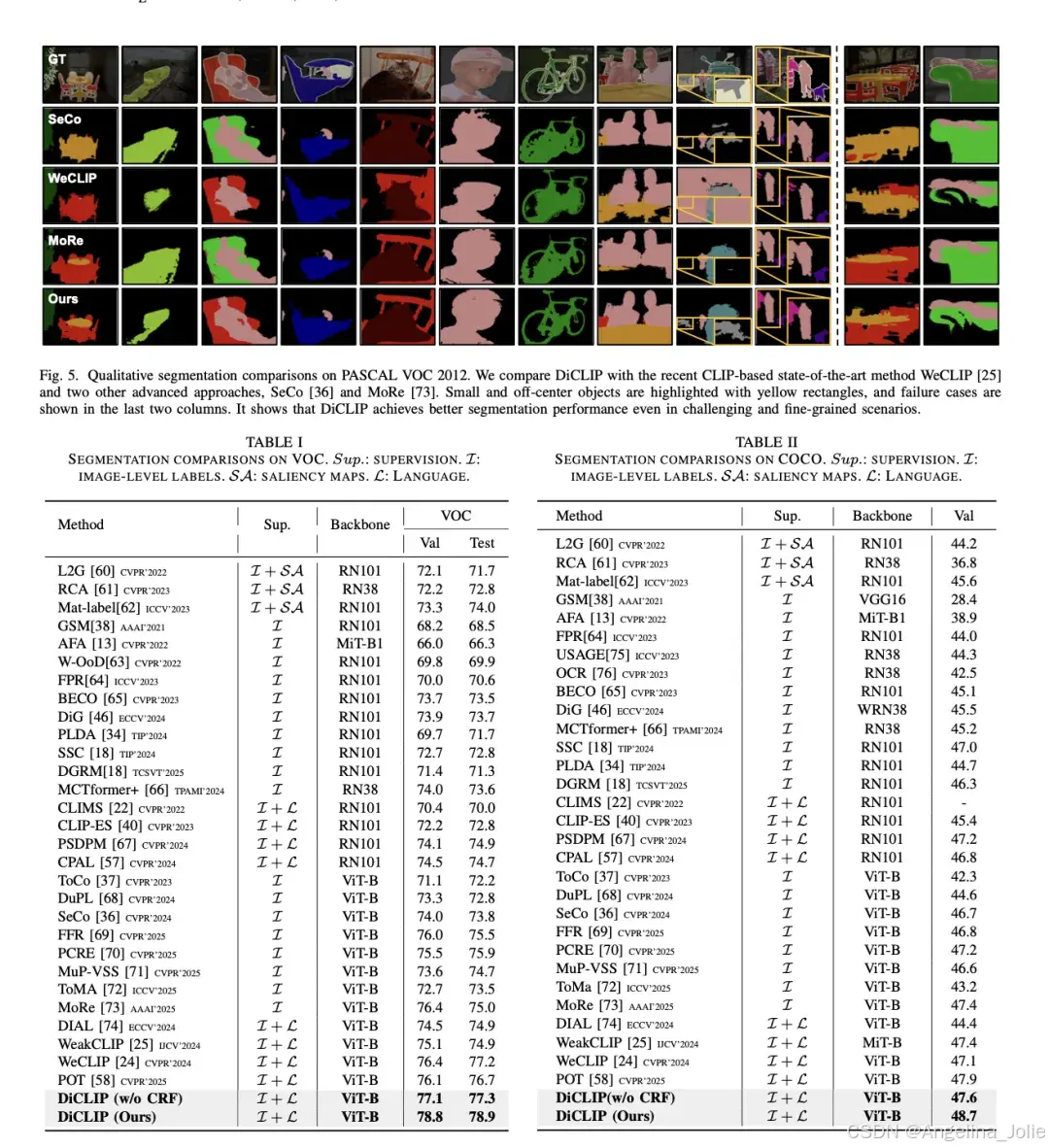
▶ CAM种子质量(无后处理)

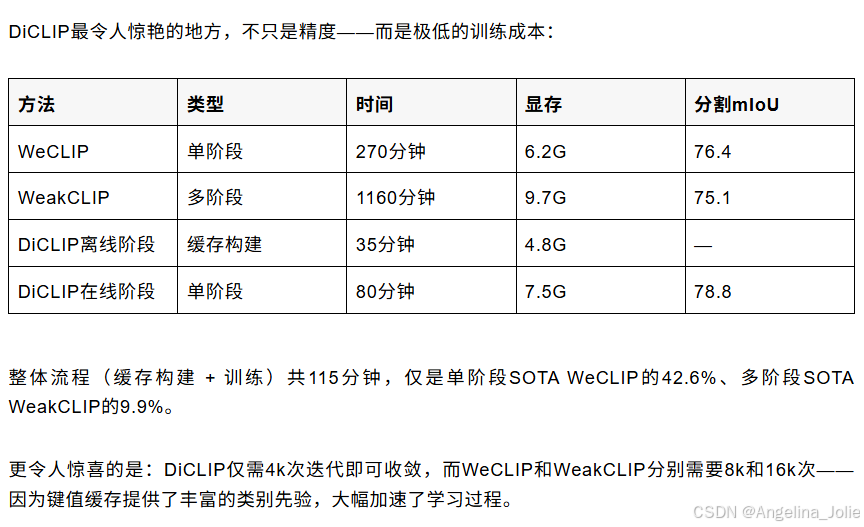
四、训练效率
五、进一步分析
▶ 共现场景下的鲁棒性
WSSS的老大难问题之一是"共现"------图像中同时出现多个类别时,CAM容易产生混淆。在VOC验证集的多类别共现子集上,DiCLIP的平均混淆率(FP/TP)为0.19,优于WeCLIP的0.26。随着共现类别数增加,其他方法的混淆率急剧攀升,而DiCLIP始终保持稳定------语义纯洁的缓存原型在检索时天然过滤了背景噪声。
▶ 合成数据偏差的应对
SD生成的图像可能与真实图像存在领域偏差。作者通过t-SNE可视化证明,合成数据与真实VOC数据的特征分布高度一致。此外,动态知识检索的自适应微调能进一步弥补偏差。实验对比表明:使用VOC真实图像建缓存与使用SD生成图像建缓存,最终性能差距极小。
使用SD生成图像还有一个实际优势:真实图像中单类别图片极少(如VOC训练集的DiningTable类只有17张单类图像),SD可以按需生成任意数量,极大提升了实用性。
▶ 消融研究核心结论
各模块有效性(VOC val,mIoU): • 基线(裸CLIP):12.1% • +VCE(无训练):72.2%(验证空间一致性假设) • +正缓存(P.C.):73.6%(验证生成有效性假设) • +负缓存(N.C.):74.4%(对比式检索的价值) • +动态适配器:77.1%(动态学习的提升)
六、局限性与未来展望
作者坦率指出:当前键值缓存完全由SD生成,对SD表达不足的类别或极复杂场景,性能可能有所下滑(论文Fig.5展示了若干失败案例)。未来方向是构建在线缓存(Online Cache):在训练过程中渐进式融入真实查询图像的特征,实现先验知识与真实领域知识的动态融合,进一步提升性能与泛化能力。