拷个 .exe 到新电脑就跑不起来?你缺的不是文件,是对链接的理解
一道让 90% 程序员愣住的问题
先做一个小实验。
你写了一段 C 代码,不到 10 行:
c
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}用 Visual Studio 编译。出来的 hello.exe:
- 用 /MD 编译:8 KB
- 用 /MT 编译:180 KB
同一份源码,体积差了 22 倍。
更魔幻的是------把 8KB 那个 exe 单独拷到一台新电脑上,双击弹窗:
💀 "无法启动此程序,因为计算机中丢失 VCRUNTIME140.dll。"
而 180KB 那个,拷到哪儿都能跑。
一个 10 行的 Hello World,哪来 180KB? 那个弹窗背后的 DLL 又是什么?
答案藏在编译流程最后一步------链接器。它才是决定你的软件是"单枪匹马"还是"拖家带口"的那个人。
今天我们把这事儿彻底聊透。
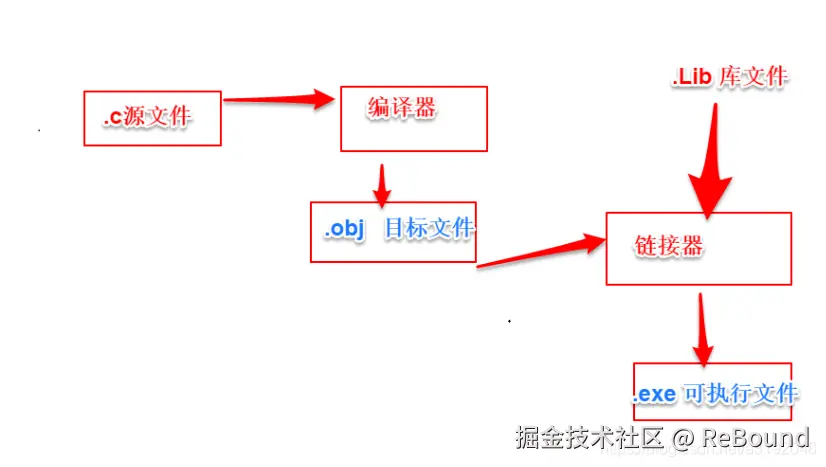
一、你写的代码,到 exe 之前经历了什么?
大部分人对编译的理解止步于"源代码变成机器码"。但真正的流程是这个:
bash
源代码 (.c/.cpp)
│
▼
编译器 → 翻译成机器码,但函数地址全空着
│
▼
目标文件 → "我知道要调 printf,但不知道 printf 在哪"
│
▼
链接器 → 🔥 关键角色:填地址 + 搬代码
│
▼
.exe → 操作系统能直接加载的 PE 格式文件
编译器只负责翻译,链接器负责"缝合"。
而链接器缝合的方式,有两条截然不同的路:
二、一条岔路口:把代码塞进去,还是留张"欠条"?
🅰️ 路线一:静态链接------全塞进去
链接器把所有被调用的库函数的完整机器码 ,直接从 .lib 里抠出来,塞进你的 .exe。
c
你的 hello.c ──────────┐
printf 的完整实现 ─────┤──→ 链接器 ──→ hello.exe (180KB)
malloc/scanf/strlen... ─┘ ↑
"不就是个 Hello World 吗,
我把整个 C 运行时库都打包进来了"运行时简单到令人发指:
OS:加载这个 exe → 映射到内存 → 跳到入口点 → 跑。
没有"找 DLL",因为根本不需要。你要的东西,exe 自己全带了。
打开这个 180KB 的 PE 文件,导入表几乎只有一行:kernel32.dll。其他一切------printf、malloc、strlen------全在 .text 段里躺着。
这就是为什么它拷到哪儿都能跑。
🅱️ 路线二:动态链接------留张"欠条"
链接器不拷贝库代码,只在 exe 里写了一张表:
c
┌─────────────────────┐
│ 导入表 (IAT) │
│ │
│ 我需要: │
│ ┌────────────────┐ │
│ │ VCRUNTIME140 │ │ ← printf 在这个 DLL 里
│ │ ├ printf │ │
│ │ └ scanf │ │
│ │ MSVCRT │ │ ← malloc/free 在这
│ │ ├ malloc │ │
│ │ └ free │ │
│ │ KERNEL32 │ │ ← 创建文件、分配内存
│ │ └ CreateFile │ │
│ └────────────────┘ │
└─────────────────────┘翻译成人话:
"我运行的时候需要
VCRUNTIME140.dll里的printf,你记得帮我找。地址那一栏先空着,等跑起来再填。"
运行时就没那么轻松了:
markdown
1. OS 加载器打开 exe,扫一遍 PE 头
2. 看到导入表:"嚯,你要 5 个 DLL?等着。"
3. 按顺序找每个 DLL:
① 当前目录 → ② System32 → ③ PATH 环境变量
4. 找到了 → 映射到进程的内存空间
5. 找不到 → 💀 "缺少 xxx.dll",程序直接拒绝启动
6. 全部找齐 → 把每个函数的真实内存地址写入 IAT 表
7. 准备就绪 → 跳转到入口点这就是为什么 8KB 的 exe 离了 VC++ 运行库就活不了。
打个比方,秒懂
| 静态链接 | 动态链接 | |
|---|---|---|
| 像什么 | 出门把所有行李背身上 | 出门只带一张购物清单 |
| 启动 | 推门就走 | 先按清单去超市采购一圈 |
| 体重 | 沉(180KB) | 轻(8KB) |
| 风险 | 背得累 | 超市缺货就完蛋 |
一个把复杂度放在了编译时,一个把它推迟到了运行时。
三、一张表,看懂两种方案的全部代价
| 维度 | 静态链接 | 动态链接 |
|---|---|---|
| exe 体积 | 大(5~50MB 都正常) | 小(几十 KB) |
| 依赖关系 | 几乎为零(只依赖系统内核) | 导入表里列了一长串 DLL |
| 磁盘占用 | N 个程序 = N 份库代码 | N 个程序共享 1 份 DLL |
| 内存占用 | 每个进程独占代码页 | OS 用 Copy-on-Write 让多个进程共享同一份物理页 |
| 启动速度 | 一次 I/O,干净利落 | 逐个查找、加载、重定位、填 IAT |
| 安全更新 | 库有漏洞 → 重编所有用它的程序 | 换一个 DLL → 全部程序自动修复 |
| 版本冲突 | 不存在 | DLL Hell(下文细说) |
| 插件系统 | 基本做不了 | LoadLibrary 一行搞定 |
这里最反直觉的一条是 "动态链接反而更省内存"。我们来深入看看。
四、三个深度细节,看完才算真正理解
4.1 Copy-on-Write:为什么 10 个程序共享一份 DLL 不打架?
你的电脑上同时开着 Chrome、微信、VS Code------它们全都要用 user32.dll。
如果每个进程都自己存一份,光这一个 DLL 就要吃掉 10 份内存。但实际上,操作系统是这样做的:
css
物理内存里:只有一份 user32.dll 代码页
进程 A 的虚拟地址空间 ──→ 映射到同一份物理页
进程 B 的虚拟地址空间 ──→ 映射到同一份物理页
进程 C 的虚拟地址空间 ──→ 映射到同一份物理页
... ↑
代码段标记为只读,共享完全没问题
对于数据段(全局变量):标记为 Copy-on-Write
→ 任何一个进程尝试写,OS 才复制一份私有页给它
→ 没写过的部分继续共享所以动态链接不止省磁盘,更省物理内存。 这就是为什么 Windows 自己就是一个巨大的动态链接体系------系统 DLL 被成百上千个进程共享,如果每个都静态链接一份,内存早爆了。
4.2 DLL Hell:Windows 开发史上最臭名昭著的问题
故事是这样的:
css
某天,你装了"软件 A",它很贴心地带了 foo.dll v1.0。
过两天,你又装了"软件 B",安装程序二话不说,
把 foo.dll 覆盖成了 v2.0。
然后:
✅ 软件 B 正常------v2.0 就是它带来的
❌ 软件 A 崩溃------它调的函数在 v2.0 里被删了这就是 DLL Hell。 90 年代末到 2000 年代初,这是 Windows 用户的日常噩梦。
微软后来用 WinSxS(Windows Side-by-Side) 来救火------C:\Windows\WinSxS\ 这个目录能膨胀到十几 GB,就是因为它存了同一个 DLL 的 N 个版本,让不同程序各自加载自己需要的那个。
如果你好奇 WinSxS 有多大,打开 PowerShell 跑一句:
powershell
(Get-ChildItem C:\Windows\WinSxS -Recurse | Measure-Object Length -Sum).Sum / 1GB结果可能会让你怀疑人生。
4.3 IAT Hook:动态链接的一个"副作用"
因为函数地址是运行时才填进 IAT 的,这就给了一个天然的拦截点:
正常路径:
你的程序 → IAT 指向 → user32.dll!MessageBoxW → 弹出对话框
Hook 路径:
你的程序 → IAT 被改 → 指向恶意模块 → 先偷数据,再决定要不要真弹框所以杀毒软件、游戏反作弊、输入法注入,底层都离不开 IAT Hook。而静态链接因为函数地址在编译时就写死了,这套玩法对它基本无效------这也是一些安全软件和 DRM 系统倾向静态链接的原因之一。
五、一个"你以为简单、实际复杂"的问题
为什么大型软件一定是多文件的?
你打开 Chrome 的安装目录看看,或者 Photoshop,或者 VS Code。没有一个是你想象中的"单个 exe"。原因很硬核:
① 增量更新
Chrome 每 6 周一个大版本。如果每次更新都要下载 200MB 的单一 exe,用户和带宽成本都受不了。实际做法是只替换变化了的几个 DLL。
② 插件生态
IDE、浏览器、PS 的核心竞争力就是插件。底层机制 LoadLibrary("plugin.dll") + GetProcAddress 决定了功能模块必须在外部 DLL 中。静态链接的程序做插件系统?基本不可能。
③ 几百人同时开发一个产品
团队 A 负责渲染,产出 rendering.dll。团队 B 负责网络,产出 networking.dll。各自独立编译、测试、部署------这才是现代软件工程的节奏。
④ Windows 本身就是一个庞大的动态链接体系
kernel32.dll、user32.dll、gdi32.dll、ntdll.dll......你写的任何一个 Windows 程序,都不可能完全不碰这些系统 DLL。动态链接不是你要不要选的问题,而是你打算在系统 DLL 之上,再多链接多少的问题。
六、那些"看起来像单文件"的软件,在骗你
有意思的是,近年很多软件"看起来"是单文件,但它们本质上是多文件的伪装:
| 方案 | 障眼法原理 | 案例 |
|---|---|---|
| 自解压打包 | exe = 解压程序头 + 压缩的完整安装目录,运行时解压到 %TEMP% 偷偷跑 |
很多安装包 |
| .NET 单文件发布 | dotnet publish -p:PublishSingleFile=true 把运行时+全部 DLL 打进一个 exe |
.NET 6+ 桌面应用 |
| PyInstaller | Python 解释器 + .pyc + .dll 揉成一团 | 各种 Python 写的 GUI 工具 |
| Go 静态编译 | 真正干净的单文件,语言层面原生支持 | Docker CLI、Hugo、Caddy |
| AppImage | Linux 上运行时 FUSE 挂载为虚拟文件系统 | Kdenlive、Krita |
真相是:除了 Go/Rust 这种原生静态编译,其余的全是"看起来像单文件"的障眼法。运行时该解压的解压,该加载的加载,一个没少。
七、给你的决策清单
下次你要开一个新项目,这样选:
markdown
你的场景?
├── CLI 工具 / 便携小软件
│ └── 静态链接,Go/Rust 一步到位
│ 理由:用户拷走就能用,心智负担为零
│
├── GUI 桌面应用(需要频繁更新)
│ └── 多文件 + 增量更新机制
│ 理由:别让用户每次更新都重下整个包
│
├── 企业级系统 / 多人协作项目
│ └── 必须多文件 + 模块化拆分
│ 理由:独立编译、按需加载、安全审计
│
└── 插件/扩展
└── 你没得选------宿主程序的架构已经定死了八、亲手验证
如果你装了 Visual Studio,花 5 分钟跑一遍:
静态链接版本:
powershell
cl /MT hello.c
dumpbin /imports hello.exe
# 导入表:几乎只有 kernel32.dll
# 文件大小:~180KB动态链接版本:
powershell
cl /MD hello.c
dumpbin /imports hello.exe
# 导入表:VCRUNTIME140.dll、MSVCRT.dll、KERNEL32.dll...
# 文件大小:~8KB把 /MD 版本单独拷到一台没装 VC++ 运行库的机器上------你会亲眼看到所有 Windows 用户都见过的那个弹窗:
"无法启动此程序,因为计算机中丢失 VCRUNTIME140.dll。"
一个 Hello World,把你拉回了现实世界。
最后一句话
每次有人问起"为什么有的 exe 只有一个、有的一堆",说到底就一句:
你愿意把复杂度放在编译时------那就扛着一个大胖子到处跑,但随时能干活。
你愿意把复杂度放在运行时------那就轻装上阵,但到了现场得先找到你欠的那些"债"。
没有谁高谁低。工程上的选择,从来都只是在哪个阶段支付复杂度的区别。
延伸阅读
如果这篇文章让你对链接器产生了兴趣,推荐继续深入:
- 📖 《程序员的自我修养------链接、装载与库》------俞甲子 / 石凡 / 潘爱民 著,豆瓣 8.9 分,系统讲解链接、装载与库的底层原理
- 📖 《Linkers and Loaders》------John Levine 著,链接器领域的经典著作
觉得有收获?点个赞👍收藏⭐关注👆,后续会分享更多操作系统底层原理的硬核解读!