目录
[1.0 简介](#1.0 简介)
[1.0 环境](#1.0 环境)
[2.0 服务拆分](#2.0 服务拆分)
[3.0 工程搭建](#3.0 工程搭建)
[4.0 CAP 和 Eurkea](#4.0 CAP 和 Eurkea)
[(5)多机部署 负载均衡-LoadBalance](#(5)多机部署 负载均衡-LoadBalance)
[(6)SpringCloud LoadBalance](#(6)SpringCloud LoadBalance)
[5.0 注册中心的其他实现-Nacos](#5.0 注册中心的其他实现-Nacos)
[1.0 OpenFeign](#1.0 OpenFeign)
[2.0 统一网关介绍](#2.0 统一网关介绍)
[(3)Route Predicate Factories](#(3)Route Predicate Factories)
[(4)Gateway Filter Factories(网关过滤器工厂)](#(4)Gateway Filter Factories(网关过滤器工厂))
[3.0 分布式服务部署](#3.0 分布式服务部署)
一、简介
1.0 简介
(1)引入
认识微服务:
单体架构:
很多创业公司早期会把业务的所有功能实现都打包在一个项目
例如我们之前写项目的时候 一个jar包就是一个项目 里面有前端代码 有后端代码等 这种结构开发简单部署简单 一个项目就包含了所有的功能 省去了多个项目之间的交互和调用
集群和 分布式架构 :
用户量越来越多带来的问题: 后端服务器的压力增大 负载高 业务场景逐渐复杂 各个业务之间的代码耦合度会越来越高 任何一个问题 都需要整个项目重新构建 发布
一个微小的问题 可能导致整个应用挂等等
这个时候解决方案有两种:横向和纵向
横向是添加服务器 相当于增派人手 3x10变成10x10了
纵向是把一整块业务按功能划分为不同的模块
集群和 分布式 :
集群是将⼀个系统完整的部署到多个服务器上, 每个服务器都能提供系统的所有服务, 多个 服务器通过负载均衡调度完成任务. 每个服务器称为集群的节点
例如饭店人手不够了 多招人 这些人干一样的事情
分布式是将⼀个系统拆分为多个⼦系统,多个⼦系统部署在多个服务器上,多个服务器上的⼦系统
协同合作完成⼀个特定任务.
例如饭店给烧烤师傅找个打下手的小徒弟
区别与联系:
多个计算机做同样的事情或者多个计算机做不同的事 但是分布式和集群在实践中很多时候是相互配合使用的 所以不能单独区分 而是统称为分布式架构
微服务架构 :
微服务就是很小的服务 小到一个服务只对应一个单一的功能 只做一件事 这个服务可以单独部署运行 之间采用REST和RPC协议进行通信
微服务是一种经过良好架构设计的分布式架构方案 图片形象化:
微服务的优缺点:
优势:易于开发和维护 每个微服务负责的业务比较清晰 体量小 开发和维护成本降低
容错性高 一个服务发生故障 可以使故障隔离在单个服务器里 不影响整体
扩展性好:每个服务都是独立运行的 我们可以结合项目实际情况进行扩展 按需伸缩
技术选型灵活:每个微服务都是单独的团队来运维 可以选择合适的技术栈
挑战: 服务依赖 一个服务的更改 可能需要考虑对其他服务的影响
运维成本 甚至不同的语言 不同的运行环境 对运维人员来说挑战巨大
开发和测试 服务调用引入网络延迟 不可靠的网络
服务监控:微服务架构下 不仅需要对整个链路进行监控 还需要对每一个服务实施监控
负载均衡:微服务架构中的服务实例数量可能非常庞大 因此需要有效的服务发现和负载均
横机制来管理请求流量和保证高可用性
(2)SpringCloud
微服务的解决方案:SpringCloud
官方文档:Spring Cloud
springcloud提供了一些可以让开发人员快速构建分布式服务的工具,比如配置管理 服务发现 熔断 智能路由等等 它们可以在任何分布式环境中很好的工作
通俗理解就是:springcoloud是 分布式 微服务架构 的一站式解决方案
相当于装修的套餐:电视1 空调2 洗衣机3 冰箱4 小猫4 有不同的套餐 是一个工具包
springCloud 和 springBoot的关系:
SpringBoot是造单个服务的脚手架,让你快速搞出一个能跑的应用 SpringCloud则是管这一堆服务的大管家,帮你解决服务之间怎么发现,怎么通信,怎么容错,怎么配置这些麻烦事
springCloud版本:Spring Cloud
SpringCloud实现方案:
Spring Cloud Netflix = Netflix 家的微服务工具(经过 Spring 改装),装在你的 Spring Boot 应用里,帮你搞定服务发现、熔断、网关、负载均衡这些"分布式麻烦事"。
但是Spring Cloud Netflix里的老组件很多都停止更新了,虽然现在还能用,但以后不安全也不合时宜。Spring官方推荐了新的方案。
Spring Cloud Alibaba :官方网站 Spring Cloud Alibaba 是什么-阿里云Spring Cloud Alibaba官网
二、环境和工程搭建
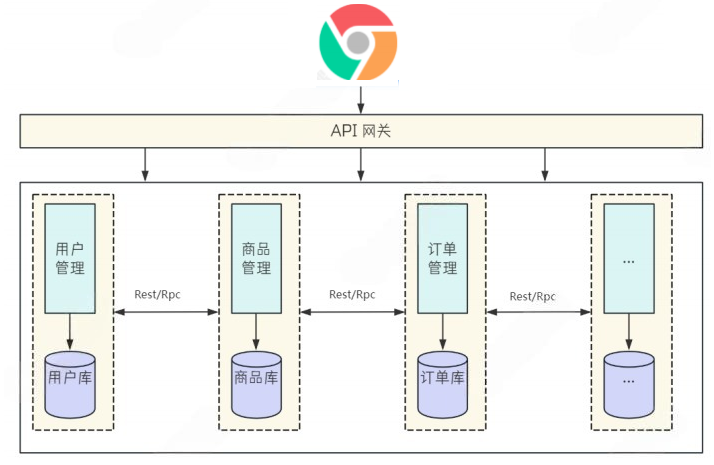
引入:实现一个电商平台
⼀个电商平台包含的内容⾮常多, 以京东为例, 仅从⾸⻚上就可以看到巨多的功能
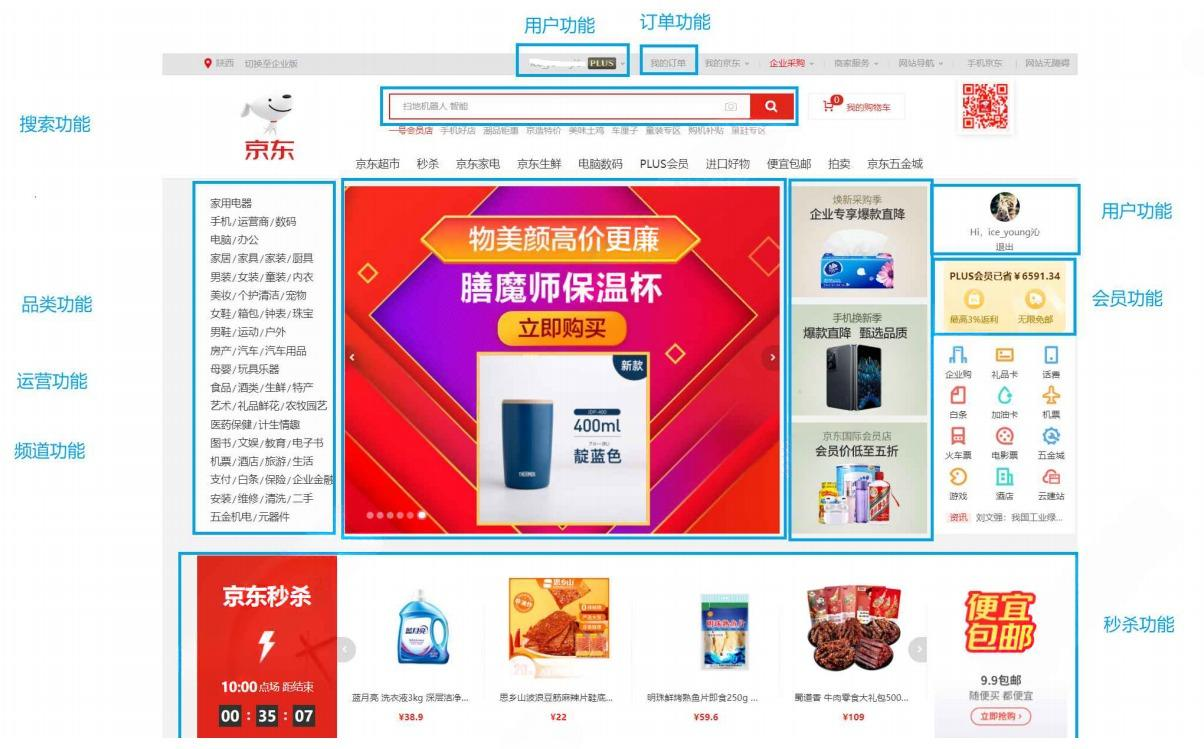
如果把这些功能都写在一个服务里,这个服务将是巨大的
服务拆分:
微服务应⽤开发的第⼀步, 就是服务拆分. 拆分后才能进⾏"各⾃开发"
服务拆分原则:
服务越⼩, 微服务的独⽴性就会越来越⾼, 但同时, 微服务的数量也会越多, 管理这些微服务的难度也会
提⾼. 所以服务拆分也要考虑场景.
单一职责原则:单一职责原则本身是面向对象设计中的一个基本原则,它指的是一个类应该专注单一功能,不要存在多于一个导致类变更的原因。在微服务架构中, ⼀个微服务也应该只负责⼀个功能或业务领域, 每个服务应该有清晰的定义和边界, 只关注⾃⼰的特定业务领域。
服务自治:是指每个微服务都应该具备高度自治的能力,即每个服务要能做到独⽴开发, 独⽴测试, 独⽴构建, 独⽴部署, 独⽴运⾏。
单向依赖:微服务之间需要做到单向依赖,严禁循环依赖, 双向依赖
简单说,循环依赖会让微服务之间像你拽我 我拽你,一坏坏一篇,谁也没法独立和升级
单向依赖像树形结构(上层依赖下层,下层不知道上层)。比如:订单 -> 用户 -> 积分。改积分,用户和订单都不用动。
如果⼀些场景确实⽆法避免循环依赖或者双向依赖, 可以考虑使⽤消息队列等其他⽅式来实现
数据准备:根据服务自治原则,每个服务都应有自己独立的数据库
1.0 环境
开发环境安装:jdk17 mysql
windwos安装jdk17 Linux安装jdk:课程中使用的Linux环境为Ubuntu 20.4 后续不再说明
2.0 服务拆分
原则:单一原则 服务自治:自己独立治理 每一个服务都可以独立开发 构建 部署 运行 测试
单项依赖 不能存在循环依赖 双向依赖(A依赖B B依赖A 如果避不开,采用其他方式解决 分布式等)
具体场景具体分析,这里我们拆分为订单服务和商品服务
3.0 数据准备
根据服务自治原则 每个服务器都应有自己独立的数据库
3.0 工程搭建
(1)构建父子工程
创建⼀个空的Maven项⽬, 删除所有代码, 只保留pom.xml
完善pom文件:使用那个properties来进行版本号的统一管理 使⽤dependencyManagement来管理依赖, 声明⽗⼯程的打包⽅式为pom。
这段 pom 配置里,父项目是 spring-boot-starter-parent 3.1.6,统一管理项目基础配置;properties 里指定了 JDK 22 编译版本和 UTF-8 编码;dependencies 里直接引入了 lombok 依赖,用于简化代码生成;dependencyManagement 中管理了 spring-cloud-dependencies、mybatis-spring-boot-starter、mysql-connector-j、mybatis-spring-boot-starter-test 的版本,供子模块按需引用;当前配置中未定义任何插件。
SpringCloud版本:
Spring Cloud 是基于SpringBoot搭建的, 所以Spring Cloud 版本与SpringBoot版本有关
咱们项⽬中使⽤的SpringBoot 版本为 3.1.6, 对应的Spring Cloud版本应该为2022.0.x,
选择任⼀就可以
(2)创建子项目
new一个module 名字叫做:order-service
声明项目依赖和项目构建插件:spring-boot-starter-web mysql-connector-j mybatis-spring-boot-starter
这些依赖都没有写 <version>,是因为它们由父项目(比如 spring-boot-starter-parent)或 BOM 统一管理了版本,所以你可以不用关心具体版本号,Maven 会自动帮你挑一个兼容的。
订单服务:
声明项目依赖和项目构建插件:spring-boot-starter-web mysql-connector-j mybatis-spring-boot-starter依赖 spring-boot-maven-plugin插件
创建包 配置文件里面:端口号 jdbc mysql mybatis
商品服务:
远程调用:
需求是根据订单查询订单信息时,根据订单里面的产品ID 获取产品的详细信息
实现思路:order-service服务向product-service服务发送⼀个http请求, 把得到的返回结果, 和订单结果融合在⼀起, 返回给调⽤⽅.
实现方式:采⽤Spring 提供的RestTemplate RestTemplate类文档:
RestTemplate 最详解 - 程序员自由之路 - 博客园
REST(Representational State Transfer), 表现层资源状态转移. REST 是⼀种设计⻛格, 指资源在⽹络中以某种表现形式进⾏状态转移
RESTful:REST 是⼀种设计⻛格, 并没有⼀个明确的标准. 满⾜这种设计⻛格的程序或接⼝我们称之为RESTful(从单词字⾯来看就是⼀个形容词). 所以RESTful API 就是满⾜REST架构⻛格的接⼝.
RestTemplate 是Spring提供, 封装HTTP调⽤, 并强制使⽤RESTful⻛格. 它会处理HTTP连接和关闭, 只需要使⽤者提供资源的地址和参数即可.
(3)项目存在的问题
远程调⽤时, URL的IP和端⼝号是写死的(http://127.0.0.1:9090/product/), 如果更换IP, 需要修改代码 远程调⽤时, URL⾮常容易写错, ⽽且复⽤性不⾼, 如何优雅的实现远程调
如何使用SpringCloud中的组件来解决这个问题?
生活例子:
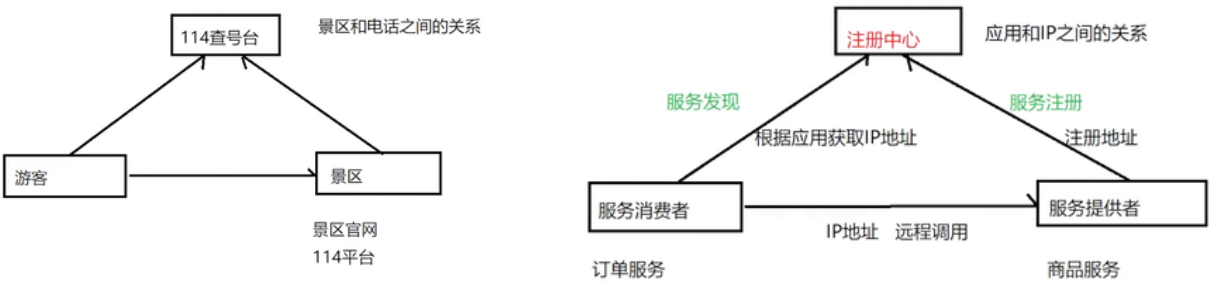
同样的,微服务开发时,也可以采用类似的方案

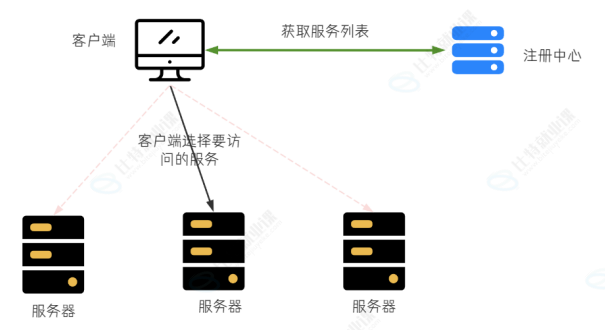
服务注册:服务提供者在启动时, 向 Registry 注册⾃⾝服务, 并向 Registry 定期发送⼼跳汇报存活状态.
服务发现: 服务消费者从注册中⼼查询服务提供者的地址,并通过该地址调⽤服务提供者的接⼝. 服务
发现的⼀个重要作⽤就是提供给服务消费者⼀个可⽤的服务列表.
4.0 CAP 和 Eurkea
CAP理论:谈到注册中心,就避不开CAP理论
CAP 理论是分布式系统设计中最基础, 也是最为关键的理论
C:一致性

强一致性:主库和从库 不论何时 对外提供的服务都是一致的
弱一致性:随着时间的推移 最终达到了一致性
A:可用性
对所有的请求 都有响应 即使这个响应可能是错误的数据
P:分区容错性 在网络分区的情况下 系统依然可以对外提供服务
生活例子:银行 银行利率下调,这个通知需要下发到各个银行工作人员,通知下发需要一定的时间
一致性:所有的银行工作人员 对客户讲的利率都是一样的
可用性:不论何时 银行的工作人员对客户咨询利率的请求 都是有答案的 这个答案可能是旧的
分区容错性:如果其中工作人员请假了,银行依然可以提供对外服务
因为P必须要保证 所以C和A只能二选一 我们的架构就是CP架构或者AP架构
CP架构:为了保证分布式系统对外的数据一致性,于是选择不返回任何数据
AP架构:为了保证分布式系统的可用性,节点2返回V0版本的数据(即使这个数据不正确)
注册中心:Zookeeper Eureka Nacos
搭建 Eureka Server:
Eureka-server是一个独立的微服务
1创建Eureka-server子模块 项目改名工作做好:父项目是eureka 子项目是订单服务和商品服务
2引入eureka-server依赖 spring-cloud-starter-netflix-eureka-server
3配置文件 增加Eureka相关的配置
java
client:
fetch-registry: false # 表⽰是否从Eureka Server获取注册信息,默认为true.因为这是 ⼀个单点的Eureka Server,不需要同步其他的Eureka Server节点的数据,这⾥设置为false
register-with-eureka: false # 表⽰是否将⾃⼰注册到Eureka Server,默认为true.由于
当前应⽤就是Eureka Server,故⽽设置为false.
service-url:
# 设置与Eureka Server的地址,查询服务和注册服务都需要依赖这个地址.
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
简单来说:
登记处本身不需要把自己登记成一个员工 登记处也不需要去另外一个登记处查员工名单 但是它需要一个公开的地址测试:启动服务 访问设置好的端口号 出来页面就可以看到eureka-server已经启动成功了
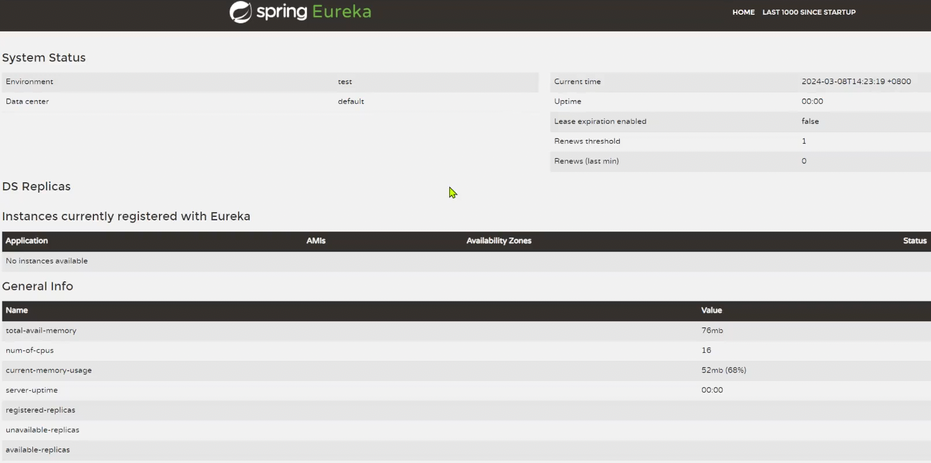
服务注册:
1加入Eureka的依赖 修改配置信息 启动测试
服务发现:
1加入Eureka的依赖 修改配置信息 修改远程调用代码 启动测试
配置信息修改:eureka的相关配置 还有自己本服务的名称
java
@Autowired
private DiscoveryClient discoveryClient;
public OrderInfo selectOrderById(Integer orderId){
OrderInfo orderInfo = orderMapper.selectOrderById(orderId);
//String url = "http://127.0.0.1:9090/product/"+orderInfo.getProductId();
//从Eureka中获取服务列表
List<ServiceInstance> instances = discoveryClient.getInstances("product-service");
String uri = instances.get(0).getUri().toString();
String url = uri+"/product/"+orderInfo.getProductId();
log.info("远程调用url:{}", url);
ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}
这样我们访问端口 就可以实现远程调用的功能咯
(5)多机部署 负载均衡-LoadBalance
上述远程调用代码存在的问题:
思考: 如果⼀个服务对应多个实例呢? 流量是否可以合理的分配到多个实例呢?
之前的代码instances.get(0); // 永远只取列表里的第一个
真正的微服务 我们用负载均衡代替这个get(0) 它会自动从注册中心拿到所有的健康的实例列表 然后按照一定的策略从中选一个去处理当前请求
现象观察:
我们再启动2个product-service实例
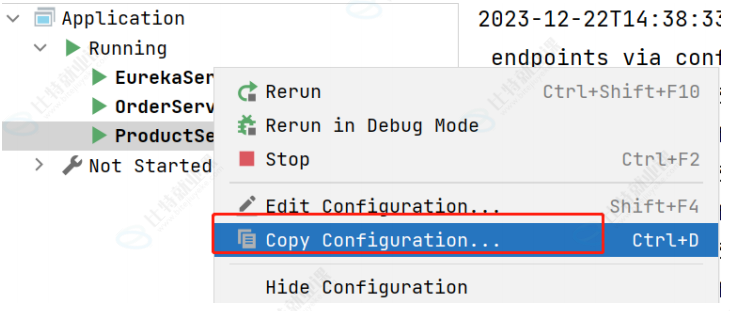
选中要启动的服务, 右键选择 Copy Configuration... 起一个新的名称 端口号重换一个
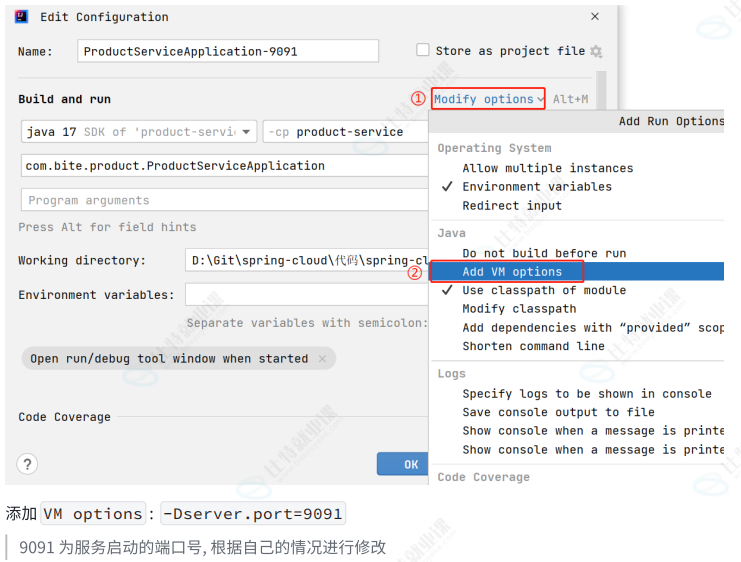
启动之后开始测试

通过⽇志可以观察到, 请求多次访问, 都是同⼀台机器. 没有用上真正的负载均衡
这肯定不是我们想要的结果, 我们启动多个实例, 是希望可以分担其他机器的负荷, 那么如何实现呢?
我们肯定希望均匀的访问到9091 9092 我们希望请求次数和实例对应起来 我们希望是下面这样

负载均衡:负载就是流量、压力 均衡就是均匀合理分配
负载均衡简称LB,是高并发,高可用系统必不可少的关键组件
当服务流量增大时,通常会采用增加机器的方式进行扩容,负载均衡就是用来在多个机器或者其他资源中,按照一定的规则合理分配负载
负载均衡 的一些实现:负载均衡分为服务端负载均衡和客⼾端负载均衡.
服务端负载均衡:就是在服务端进行负载均衡
有个专门的"分发员",所有请求都先找它,它再分给后面的人干活。
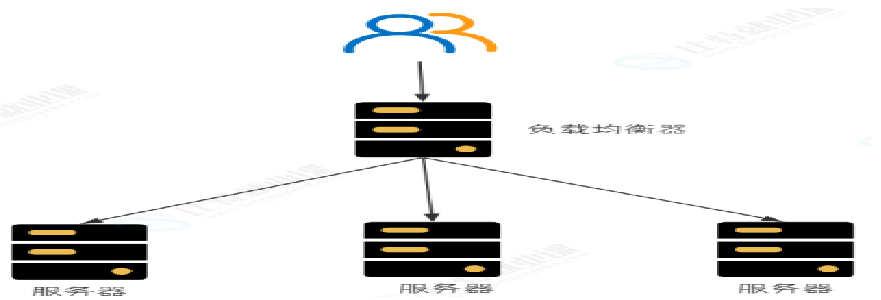
⽐较有名的服务端负载均衡器是Nginx. 请求先到达Nginx负载均衡器, 然后通过负载均衡算法, 在多个服务器之间选择⼀个进⾏访问
客户端负载均衡:在客户端进行负载均衡的算法分配
把负载均衡的功能以库的方式集成到客户端 而不是再由一台指定的负载均衡设备集中提供
//没有这个分发员,每个干活的人自己手里有一份通讯录,自己挑一个同事去帮忙。
(6)SpringCloud LoadBalance
1添加注解@ 2修改远程代码 把IP和端口号改成应用名称
负载均衡 策略:按照什么样的策略进行负载均衡分配
Spring Cloud LoadBalancer 仅⽀持两种负载均衡策略: 轮询策略 和 随机策略
轮询:服务器轮流 默认是轮询 随机:随机选择后端服务器处理请求
自定义:Spring Cloud LoadBalancer :: Spring Cloud Commons
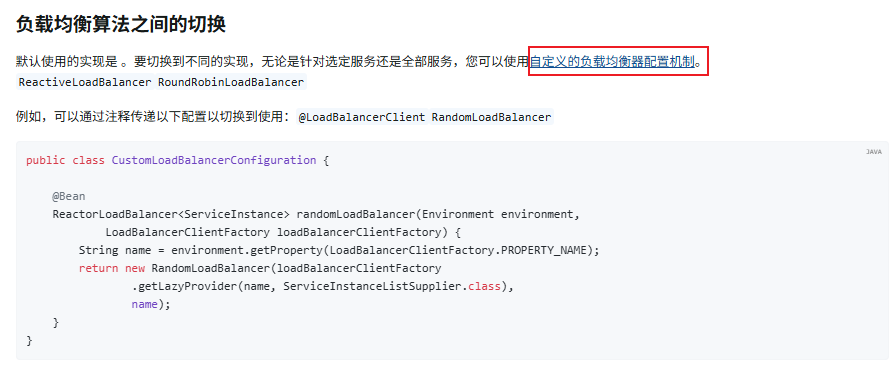
LoadBalancer原理: 通过源码进行分析
拿到URL 从里面取到HOST ....如果服务列表不为空 生成一个随机数
轮询的策略:如果是空 如果是1 拿到坐标 通过类似计数器来拿到实例
服务部署(Linux):
安装好mysql
服务构建打包:采用Maven打包,需要对3个服务分别打包 eureka-server, order-service, product-service 打包⽅式和SpringBoot项⽬⼀致, 依次对三个项⽬打包即可 //maven里面点击名 然后点击package
启动服务:上传Jar包到云服务器 //第一次上传需要安装lrzsz apt install lrzsz 直接拖动文件到xshell窗口
启动服务:
java
# 创建日志目录
mkdir -p logs
# 后台启动 eureka-server
nohup java -jar eureka-server.jar > logs/eureka.log 2>&1 &
# 后台启动 order-service
nohup java -jar order-service.jar > logs/order.log 2>&1 &
# 后台启动 product-service(端口 9090)
nohup java -jar product-service.jar > logs/product-9090.log 2>&1 &开放端口号:根据自己项目的设置情况 在云服务器上开放对应的端口号
不同的服务器⼚商, 开放端⼝号的⼊⼝不同, 需要⾃⾏找⼀找或者咨询对应的客服⼈员.
以腾讯云服务器举例:
1.进⼊防⽕墙管理⻚⾯ 2.添加规则
测试:访问Eureka Server 访问订单服务接⼝: http://110.41.51.65:8080/order/1
远程调用成功
5.0 注册中心的其他实现-Nacos
官网:Nacos官网| Nacos 配置中心 | Nacos 下载| Nacos 官方社区 | Nacos 官网
(1)Nacos安装:
下载安装包:⽬前官⽅推荐的稳定版本为2.2.3, 咱们课程中也是⽤2.2.3
下载地址 :Release 2.2.3 (May 25th, 2023) · alibaba/nacos · GitHub
其他版本下载链接: 下载链接: Releases · alibaba/nacos · GitHub
安装包内容:

logs文件夹里面是日志 可以从里面看错误日志
修改单机模式:Nacos的启动模式默认是集群模式 直接双击cmd会闪退的
使用记事本打开startup.cmd
Line26行左右,修改启动模式 set MODE="cluster"改为 setMODE="standalone"
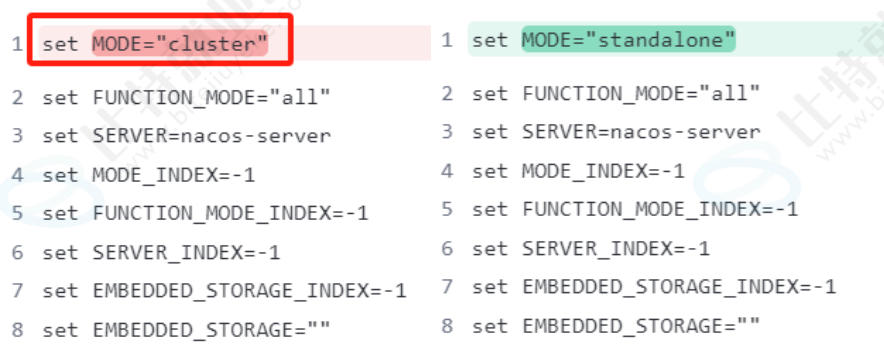
修改之后 双击启动starup.cmd
访问Nacos主⻚, 出现以下界⾯, 表⽰Nacos启动成功
(2)常见问题:
Nacos启动后,目录下会多一个logs的文件夹 报错日志在:logs/nacos.log
1 集群模式启动
报错⽇志:Caused by: java.net.UnknownHostException: jmenv.tbsite.net
Nacos默认是集群(cluster)启动,将其设置为单机(standalone), 设置⽅式参考 上⾯章节
2 端口号冲突
Nacos 默认端⼝号是8848, 如果该端⼝号被其他应⽤占⽤, 启动会报错
Caused by: java.net.BindException: Address already in use: bind
解决方式有两种,二选一:
关闭进程 cmd后输入 netstat -ano|findstr "8848" 然后杀掉进程:taskkill /pid 4968 -f
修改Nacos端口号:修改文件 ${Nacos⽬录}/conf/application.properties 23⾏左右 server.port=8848修改掉
Linux:
准备安装包 上传提前下载好的安装包到服务器上某个⽬录, ⽐如 /usr/local/src 解压安装包unzip nacos-server-2.2.3.zip //如果第⼀次使⽤, 未安装unzip命令, 需要安装⼀下 apt-get install unzip
单机模式启动:进⼊nacos/bin⽬录, 输⼊命令:bash startup.sh -m standalone
启动成功后, 访问Nacos链接: http://IP:port/nacos
(3)Nacos快速上⼿:
Nacos是Spring Cloud Alibaba的组件, Spring Cloud Alibaba遵循Spring Cloud中定义的服务注册, 服务发现规范. 因此使⽤Nacos和使⽤Eureka对于微服务来说,并没有太⼤区别
参考文档:Nacos discovery · alibaba/spring-cloud-alibaba Wiki · GitHub
服务注册和服务发现:
Nacos的服务注册和服务发现代码⼀样
引入SpringCloud Alibaba依赖:在⽗⼯程的pom⽂件中的 <dependencyManagement> 中引⼊Spring Cloud Alibaba的依赖
引入Nacos依赖:
引入LoadBalance依赖:
配置Nacos地址:课堂中直接使用服务器Nacos地址 配置文件的代码可以从AI中获取
远程调用:修改IP为项目名 为restTemplate添加负载均衡注解@LoadBalanced
启动服务:启动两个服务, 观察Nacos的管理界⾯, 发现order-service 和product-service 都注册在Nacos上了
测试接⼝: http://127.0.0.1:8080/order/1
启动多个服务,测试负载均衡:多次访问接⼝, 观察⽇志 http://127.0.0.1:8080/order/1
常见问题:
java.net.UnknownHostException :检查是否添加 LoadBalance 依赖
服务注册失效:检查Spring Cloud Alibaba版本是否正确 参考https://qcnuizt0rgup.feishu.cn/wiki/BqmRwtoxCiOsaekaaAQcq6cUne1#share-JPyedDv5topIKVxGIzHcgTedn3e
(4)Nacos负载均衡
企业中出现问题 不是先去解决 是先止损 然后再解决问题
服务下线:当某个节点上接口的性能比较差时,我们可以第一时间对该节点进行下线
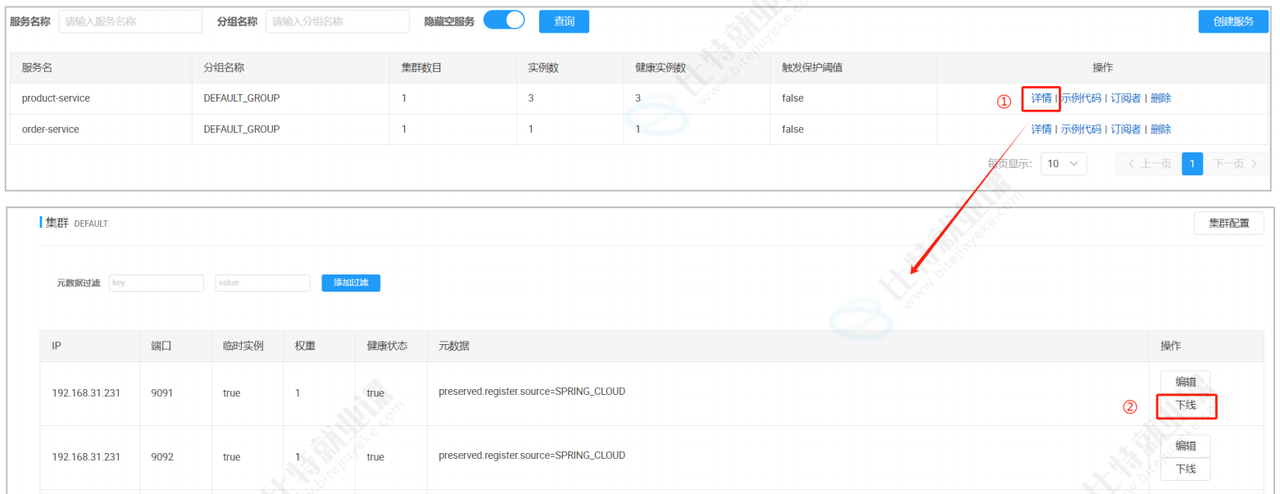
开启Nacos 负载均衡 策略:
由于Spring Cloud LoadBalance组件⾃⾝有负载均衡配置⽅式, 所以不⽀持Nacos的权重属性配置.
我们需要开启Nacos的负载均衡策略, 让权重配置⽣效
//默认的负载均衡器是个"瞎子",看不到Nacos给的权重分数。你需要换一个"明眼"的裁判(Nacos的规则),才能让权重配置真正生效。
Nacos服务实例权重不影响流量分配的原因-微服务引擎-阿里云
解决方式是通过下面的代码开启负载均衡策略:
java
# 开启nacos的负载均衡策略
spring.cloud.loadbalancer.nacos.enabled=true
# 开启nacos的负载均衡策略
spring:
cloud:
loadbalancer:
nacos:
enabled: true测试权重配置:
启动服务, 访问多次接⼝, 观察结果, 会发现9091端⼝号的实例接收的请求明显⽐另外两个实例少
整体流量⽣效, 局部流量不是严格按照设置的⽐例进⾏分配的
修改权重的时候,可能会报错 解决办法: 删除 Nacos 根⽬录下 data ⽂件夹下的 protocol ⽂件夹即可

(5)同集群优先访问
简单来说就是: 能找邻居就别跑外地 也可以叫做同机房优先访问
微服务架构中,一个服务通常有多个实例共同提供服务,这些实例可以部署在不同的机器上,这些机器可以分布在不同的机房
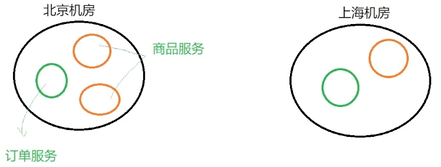
北京挂了上海的还活着哈哈
给实例配置集群名称:配置文件里面修改:cluster-name:SH 集群名称,上海集群
重启服务,观察Nacos控制台,SH集群下就多了一个实例
开启Nacos 负载均衡 策略:同时 权重配置也生效了
(6)健康检查
Nacos作为注册中⼼, 需要感知服务的健康状态, 才能为服务调⽤⽅提供良好的服务
健康机制保证注册中心里的名单是活的 挂了的人也会被自动剔除 不会把请求发给一个已经死了的服务实例
提供的两种健康检查机制:

1客户端主动上报机制:
• 客⼾端通过⼼跳上报⽅式告知服务端(nacos注册中⼼)健康状态, 默认⼼跳间隔5秒;
• nacos会在超过15秒未收到⼼跳后将实例设置为不健康状态, 超过30秒将实例删除
2服务器端反向探测机制:
• nacos主动探知客⼾端健康状态, 默认间隔为20秒.
• 健康检查失败后实例会被标记为不健康, 不会被⽴即删除.
员工每天汇报和领导每天检查
(7)Nacos服务实例类型
Nacos的服务实例分为临时实例和非临时实例
实例就是一个具体的、正在运行的服务进程,是被注册、被发现被调用、被检查的最小单位
Nacos对临时实例,采取的是 客户端主动上报机制,对非临时实例,采取服务器端反向探测机制 临时工正式工
把一个实例修改为非临时实例: //配置文件里面放入代码
java
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例临时实例和非临时实例不能相互转化,Nacos规定,你注册时签的什么合同,就是什么合同 不能中途修改 如果需要修改 需要停掉服务 删除nacos目录下 /data/protocol/raft信息 //里面会保存应用实例的元数据信息
修改配置文件, 重新启动注册
重启服务,观察Nacos控制台 停止服务,再观察控制台
(8)环境隔离
开发环境 测试环境 预发布环境 发布环境
预发、发布环境在通常情况下,配置、数据库都是一样的,区别就是预发布环境不对外
Nacos提供了namespace来实现环境的隔离,不同的namespace服务不可见
创建Namespace:
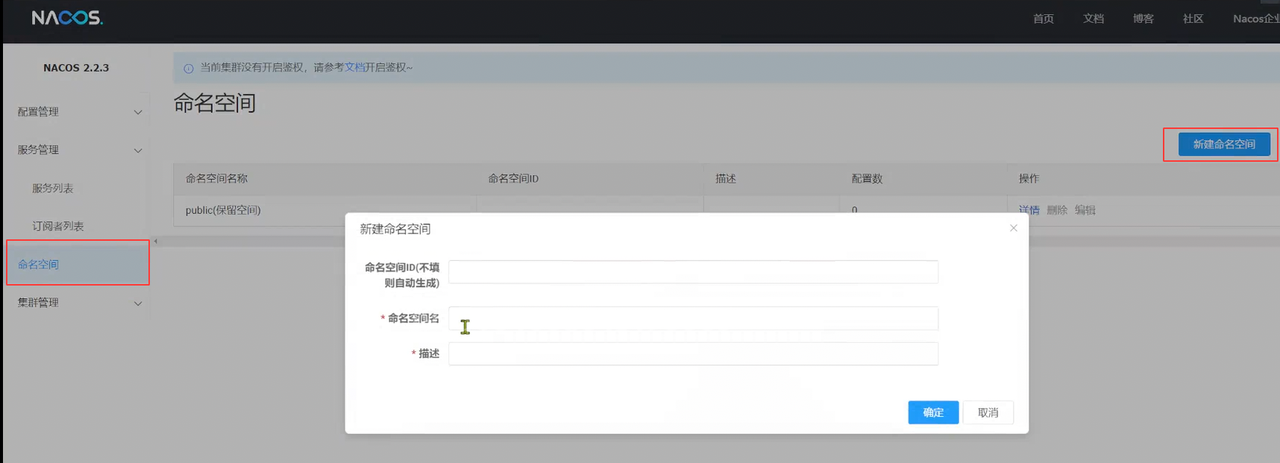
配置Namespqce:
在网站命名空间里面新建一个命名空间 复制命名空间ID
namespace创建完成后,对服务进行配置 方式就是修改配置文件
添加以下代码
java
spring:
cloud:
nacos:
discovery:
namespace: 51152a13-7911-49e3-bbdc-16fd5670a257 //命名空间(9)Nacos配置中心
Nacos还是一个配置中心 具备配置管理的功能
Namespace的常用场景之一是不同的环境配置区分隔离
开发环境走开发环境的配置 测试环境走测试环境的配置 预发布环境走预发布环境的配置
为什么需要配置中心:当前应用实例太多了 每个都需要配置文件 很容易出现问题 漏掉其中一个
这个过程没有技术含量 但是我们不得不做
配置中心就是对这些配置项进行统一管理,通过配置中心,可以集中查看,修改和删除配置,无修改配置文件,提高效率的同时,也降低了出错风险
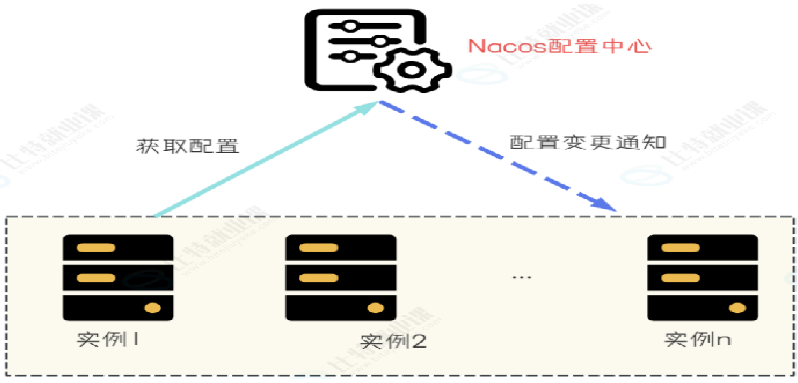
-
服务启动时, 从配置中⼼读取配置项的内容, 进⾏初始化.
-
配置项修改时, 通知微服务, 实现配置的更新加载.
快速上手:
参考文档:Nacos 融合 Spring Cloud,成为注册配置中心 | Nacos 官网
1添加配置
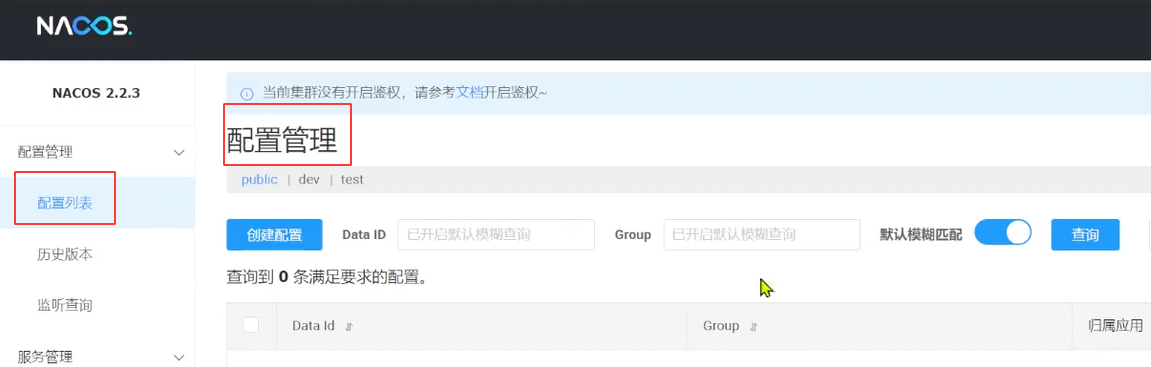
注意:服务管理的命名空间 不等于 配置管理的命名空间
2引入依赖
一个是nacos的config依赖 一个是starter bootstrap依赖
3修改配置文件
nacos配置文件:bootstrap.properties
微服务启动前,需要先获取nacos中配置,并与application.yml配置合并
在微服务运行前,Nacos要求必须使用bootstrap.properties配置文件来配置Nacos Server地址
java
spring.application.name=product-service
spring.cloud.nacos.config.server-addr=110.41.51.65:10020
第一行代码是给微服务起名
第二行代码是告诉微服务,去110.41.51.65:10020这个地址的Nacos拉取你这个服务专属的配置文件用@Value读取配置
java
@Value("${nacos.test.num:0}")
$就是去配置文件里面找 还需要加入一个注解:@RefreshScope 对配置进行热更新 热更新:不用重启,就能立刻读到新值
配置中心详解:
dataId说明:
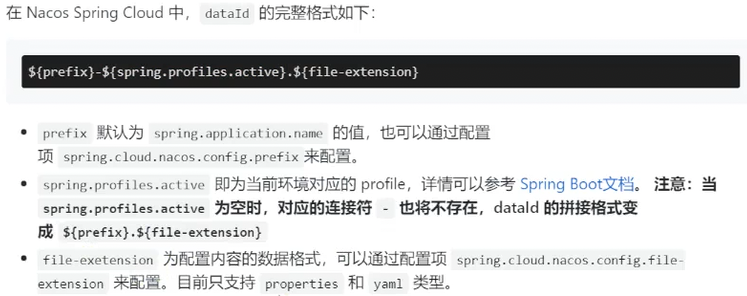
常见的问题:
1读取不到配置项
可能原因:配置错误 检查DataID 配置格式 配置空间等
未引入依赖
2 No spring.config.import property has been defined 启动报错日志
原因: bootstrap.properties 是系统级的资源配置文件,用于程序执行更加早期配置信息读取。但SpringCloud 2020.* 之后的版本把 bootstrap 禁用了,导致在读取文件的时候读取不到而报错,所以需要重新导入bootstrap 包进来就可以了
3NacosServer配置中心错误
(10)Nacos服务部署
1修改配置文件 2 对两个服务进行打包
3上传jar到Linux服务器 4启动Nacos 启动前最好把data数据删除掉 5启动服务 观察Nacos控制台
6测试:访问接口 观察远程调用的结果
三、SpringCloud组件
1.0 OpenFeign
优雅实现远程调用
观察远程调用的代码,看看RestTemplate存在的问题:
java
public OrderInfo selectOrderById(Integer orderId) {
OrderInfo orderInfo = orderMapper.selectOrderById(orderId);
String url = "http://product-service/product/" + orderInfo.getProductId();
ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);
orderInfo.setProductInfo(productInfo);
return orderInfo;
}需要拼接URL 灵活性高 但是封装臃肿 URL复杂时,容易出错
代码可读性差,风格不统一
微服务通信 RPC和HTTP 微服务采用的是HTTP RPC就是让你调用别人服务器上的方法,跟调用自己电脑上的方法一样简单
在SpringCloud中, 默认是使⽤HTTP来进⾏微服务的通信, 最常⽤的实现形式有两种:
• RestTemplate • OpenFeign
(1)OpenFeign介绍
OpenFegin是一个声明式的Web Service客户端,它让微服务之间的调用变得更简单,类似controller调用service只需要创建一个接口,然后添加注解即可使用OpenFeign
//调用远程方法就像是调用本地方法,底层帮你搞定URL拼接,HTTP请求,结果解析
OpenFeign是Feign的一个更强大更灵活的实现 Feign就是帮你把"调远程接口"变成"调用本地方法"的一个工具
Spring Cloud Feign 是 Spring 对 Feign 的封装, 将 Feign 项⽬集成到 Spring Cloud ⽣态系统中.
受 Feign 更名影响,Spring Cloud Feign 也有两个 starter
• spring-cloud-starter-feign
• spring-cloud-starter-openfeign 由于Feign的停更维护,我们使用的是这个依赖
OpenFeign官方文档:https://github.com/OpenFeign/feign
SpringCloudFeign文档:https://spring.io/projects/spring-cloud-openfeign/
(2)快速上手
1引入依赖:spring-cloud-starter-openfeign
2添加注解:在order-service的启动类添加注解 @EnableFeignClients , 开启OpenFeign的功能
3编写OpenFeign的客户端:
java
基于SpringMVC的注解来声明远程调⽤的信息
@FeignClient(value = "product-service", path = "/product")
public interface ProductApi {
@RequestMapping("/{productId}")
ProductInfo getProductById(@PathVariable("productId") Integer productId);
}name/value:指定FeignClient的名称 也就是微服务的名称 用于服务发现
Feign底层会使用SpringCloudLoadBanlance进行负载郡城 也可以使用url属性指定一个具体的url
path:定义当前FeignClient的统一前缀
//name管找谁 path管去哪里 后面的@RequestMapping管具体办什么事
4远程调用:
java
@Autowired
private ProductApi productApi;
/**
* Feign实现远程调用
* @param orderId
*/
public OrderInfo selectOrderById(Integer orderId) {
OrderInfo orderInfo = orderMapper.selectOrderById(orderId);
ProductInfo productInfo = productApi.getProductById(orderInfo.getProductId());
orderInfo.setProductInfo(productInfo);
return orderInfo;
}5测试:启动服务 访问接口 测试远程调用
(3)OpenFeign参数传递
通过观察,我们也可以发现 Feign的客户端和服务提供者的接口声明非常相似
上面的例子中,演示了Feign从URL中获取参数,接下来演示下Feign参数传递的其他方式
1传递单个参数
服务提供方 product-service
java
商品服务自己写了一个接口
访问路径:/product/p1
功能:接收一个id 返回一句话 再看Feign客户端(你要调别人接口的地方)
java
@FeignClient(value = "product-service", path = "/product")
public interface ProductApi {
@RequestMapping("/p1")
String p1(@RequestParam("id") Integer id);
}
这个接口就是在抄对方的接口签名
为什么叫约定暗号?服务提供方说:你要调用我,就得这样调 请求路径请求参数返回值
Feign客户端说:好的 我抄下来 你等着我调你服务消费方order-service
java
就是你自己的服务 你要用别人的东西 你就是"消费者"
// ========== 服务消费方 order-service ==========
@RequestMapping("/feign")
@RestController
public class TestFeignController {
@Autowired
private ProductApi productApi;
@RequestMapping("/o1")
public String o1(Integer id){
return productApi.p1(id);
}
}测试远程调用:http://127.0.0.1:8080/feign/o1?id=5
2传递多个参数
使⽤多个@RequestParam 进⾏参数绑定即可
服务提供方product-service
java
@RequestMapping("/p2")
public String p2(Integer id, String name){
return "p2接收到参数,id:" + id + ",name:" + name;
}Feign客户端
java
@RequestMapping("/p2")
String p2(@RequestParam("id")Integer id,@RequestParam("name")String name);服务消费方order-service
java
@RequestMapping("/o2")
public String o2(@RequestParam("id") Integer id, @RequestParam("name") String name){
return productApi.p2(id, name);
}测试远程调用
http://127.0.0.1:8080/feign/o2?id=5\&name=zhangsan
3传递对象
4传递 JSON
(4)最佳实践
其实就是经过历史的迭代,在项目实践过程中,总结出来的最好的使用方式 就是现实洪流里面时代的选择
通过观察,我们也能看出来,Fegin的客户端与服务提供者的controller代码非常相似
把各个方法相似的部分抽取出来共性 化为一个接口 写其他方法的时候继承就行
Feign继承方式:定义好一个接口,服务提供方(做菜餐馆)实现这个接口 服务消费方(点菜的人)编写Feign接口的时候,直接继承这个接口
把一些常用的操作封装到接口里面
具体参考:Spring Cloud OpenFeign Features :: Spring Cloud Openfeign
可以把一些公用的代码集中写在一个模块里,打包成jar包放到maven仓库中
1创建一个Moudle 接口可以放在一个公共的Jar包里,供服务提供方和服务消费方使用
2引入依赖 3编写接口 4打Jar包 5服务提供方实现接口ProductInterface 6服务消费方继承ProductInterface
7测试 试试远程调用
最佳实践 2:
官方推荐Feign的使用方式为 继承 的方式
但是企业开发中,更多是把Feign接口抽取为一个独立的模块
操作方法:将Feign的Client抽取为一个独立的模块 并把涉及到的实体类等都放到这个模块中 打成Jar
服务消费方只需要依赖Jar包即可
Jar包通常由服务提供方来实现
提供方最懂自己的接口,所以由它来编写 Feign 接口和实体类,打成 jar 包发布出去。消费方只负责引入 jar 包、直接调用,自己不写 Feign 接口。谁提供谁维护,职责清晰。
1创建一个module 2引入依赖 3编写API 复制 ProductApi, ProductInfo 到product-api模块中 4打Jar包
5服务消费方使用product-api:
删除 ProductApi, ProductInfo
引⼊依赖 修改项⽬中ProductApi, ProductInfo的路径为product-api中的路径
指定扫描类: ProductApi 在启动类添加扫描路径
6测试:测试远程调用 http://127.0.0.1:8080/order/1
(5)服务部署
1修改数据库,Nacos等相关配置: 云服务器的配置和我们本地的配置是不一样的
2对两个服务进行打包: 3启动服务 4测试
问题:
Maven打包默认是从远程仓库下载的, product-api 这个包在本地, 有以下解决⽅案:
搭建Maven私服, 上传Jar包到私服企业推荐
从本地读取Jar包个⼈学习阶段推荐
java
从本地读取Jar包:
<scope>system</scope>
<systemPath>D:/Maven/.m2/repository/org/example/product-api/1.0-SNAPSHOT/product-api-1.0-SNAPSHOT.jar</systemPath>
相当于: 你告诉 Maven,"别去网上下载了,jar 包就在我电脑 D 盘这个位置,直接拿"
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
默认情况下,Spring Boot 打包插件会忽略 system 范围的依赖,不把它打进最终的 jar 包。
加上 true,就是告诉插件:"这个本地的 jar 也给我打进去,不然部署到服务器上找不到。"2.0 统一网关介绍
(1)网关介绍
前面的课程 通过Eureka Nacos解决了服务注册 服务发现的问题
使用SpringCloudLoadBalance解决了负载均衡的问题
使用OpenFeign解决了远程调用的问题
由于使用了微服务,原本一个应用的多个模块拆分成了多个应用,我们不得不是多次实现校验逻辑,当这套逻辑需要修改时,我们需要修改多个应用,这样加重了开发人员的负担。
对于以上的问题,一个常用的解决方案是:使用 API网关 //类似前台
什么是 API网关:
API网关也是一个服务,通常是后端服务的唯一入口。
它就类似整个微服务架构的门面,所有的外部客户端访问,都需要经过它来进行调度和过滤
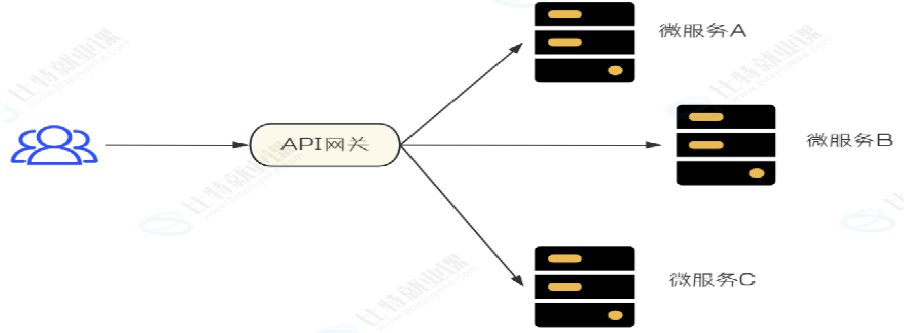
网关的核心功能:
权限控制:作为微服务的入口,对用户进行权限校验,如果校验失败则进行拦截
动态路由:一切请求先经过网关,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务
负载均衡:当路由的目标服务有多个时,还需要做负载均衡
限流:请求流量过高时,按照网关中配置微服务能够接受的流量进行放行,避免服务压力过大
(2)常见的网关实现
业界常用的网关方式有很多 技术方案也比较成熟 其中不乏很多开源产品
Zuul SpringCloudGateway等
SpringCloudGateway快速上手:
1创建网关项目:API网关也是一个服务 项目名称改为:gateway
2引入网关依赖:
java
网关:spring-cloud-starter-gateway
基于nacos实现服务发现依赖:spring-cloud-starter-alibaba-nacos-discovery
负载均衡:spring-cloud-starter-loadbalancer3编写启动类
4添加Gateway的路由配置: 创建application.yml文件 添加如下配置
java
server:
port: 10030 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
discovery:
server-addr: 110.41.51.65:10020
gateway:
routes: # 网关路由配置
- id: product-service # 路由ID, 自定义, 唯一即可
uri: lb://product-service # 目标服务地址
predicates: # 路由条件
- Path=/product/**
- id: order-service
uri: lb://order-service
predicates:
- Path=/order/**5测试
启动API网关服务 通过网关服务访问product-service
访问时,观察网关日志,可以看到网关服务从Nacos时获取服务列表
(3)Route Predicate Factories
Predicate就是网关的 "安检规则" ,用来判断一个请求能不能走这条路
它就是一个只干一件事的接口,你给我个东西,我告诉你行不行
Predicate是Java 8提供的⼀个函数式编程接⼝
它接收⼀个参数并返回⼀个布尔值, ⽤于条件过滤, 请求参数的校验
java
@FunctionalInterface//这个注解表示这是一个函数式接口,里面只能有一个抽象方法
public interface Predicate<T> {
boolean test(T t);
//...
}代码演示:
1定义一个Predicate //路由条件
java
class StringPredicate implements Predicate<String>{
@Override
public boolean test(String str){
return str.isEmpty();
}
}2使用这个Predicate
java
public class PredicTest{
public static void main(String[] args){
Predicate<String> predicate = new StringPredicate();
System.out.println(predicate.test(""));
System.out.println(predicate.test("xiyu520"));
}
}3运行结果
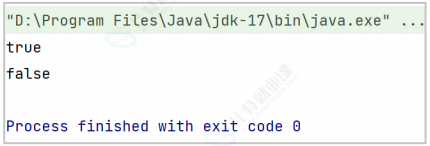
4Predicate的其他写法
java
内置函数
lambad写法
isEqual(Object targetRef) :⽐较两个对象是否相等,参数可以为Null
and(Predicate other): 短路与操作,返回⼀个组成Predicate
or(Predicate other) :短路或操作,返回⼀个组成Predicate
test(T t) :传⼊⼀个Predicate参数,⽤来做判断
negate() : 返回表⽰此Predicate逻辑否定的PredicateRoute Predicate Factories:
我们在配置⽂件中写的断⾔规则只是字符串, 这些字符串会被Route Predicate Factory读取并处理, 转变为路由判断的条件. ⽐如前⾯章节配置的 Path=/product/** , 就是通过Path属性来匹配URL前缀是 /product 的请求.
Route predicate factories是 一个能生产路由匹配条件的工厂,像是一个智能门卫
Spring Cloud Gateway 默认提供了很多Route Predicate Factory, 这些Predicate会分别匹配HTTP请求的不同属性, 并且多个Predicate可以通过and逻辑进⾏组合.
官方文档:Route Predicate Factories :: Spring Cloud Gateway
After: 几点之后才开门 Before:几点之前才开门
Between:仅在营业时间段内开门 Cookie:认准暗号(并且暗号要对)
Header:检查请求头里的工作证 Host:用哪个门牌号访问的 Method:看你是什么动作
.....
代码演示:
当存在多个路由条件时,关系是and
在application.yml中添加如下规则:
java
predicates: #路由条件
- Path=/product/**
- After=2025-01-01T00:00:00.000+08:00[Asia/Shanghai]
//增加限制路由规则:请求时间为2025年1月1日之后测试:http://127.0.0.1:10030/product/1001 返回404
修改时间为2024-01-01 再访问
After=2024-01-01T00:00:00.000+08:00Asia/Shanghai
http://127.0.0.1:10030/product/1001
(4)Gateway Filter Factories(网关过滤器工厂)
Predicate决定了请求由哪一个路由处理 如果在请求处理前后需要加一些逻辑这就是Filter(过滤器)的作用范围了
它就是你在 办事前 和 办完事后 可以插入的一些 额外小手续,或者小动作
Filter分为两种类型:Pre类型和Post类型
Pre类型过滤器:路由处理之前执⾏(请求转发到后端服务之前执⾏), 在Pre 类型过滤器中可以做鉴权, 限流等
//安检 验票
Post类型过滤器:请求执⾏完成后, 将结果返回给客⼾端之前执⾏.
//评价 好评坏评
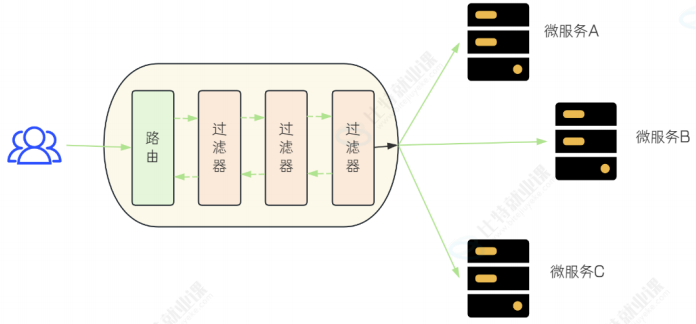
SpringCloudGateway从作用范围上,把Filter可分为GatewayFilter 和 GlobalFilter
GatewayFilter: 应⽤到单个路由或者⼀个分组的路由上. 默认就有的,全自动的 私人助理
GlobalFilter: 应⽤到所有的路由上, 也就是对所有的请求⽣效. 手动添加的 定制化的 公司前台 来者不拒
GatewayFilter:
GatewayFilter 同 Predicate 类似, 都是在配置⽂件 application.yml 中配置,每个过滤
器的逻辑都是固定的
1快速上手:
java
filters:
- AddRequestParameter=userName, bite2接受参数并打印
在product-service服务中接受请求的参数 并打印出来
java
System.out.println("收到请求,Id:"+productId);
System.out.println("userName:"+userName);3测试
重启gateway和product-service服务 访问请求 观察日志
控制台打印日志:收到请求,Id:1001 userName:bite
GatewayFilter说明:
Spring Cloud Gateway提供了的Filter⾮常多, 下⾯列出⼀些常⻅过滤器的说明..
好多好多中 简单看几个
AddRequestHead 为当前请求添加Header -AddRequestHeader=X-Request-red ,blue
AddRequestParameter 为当前请求添加请求参数 就是为请求 加个后缀
AddResponseHeader 为响应结果添加Header 为响应 贴个回执
RequestRateLimiter:限流
限流的算法有三个:假设 流量限制:每分钟一千次
固定窗口 :
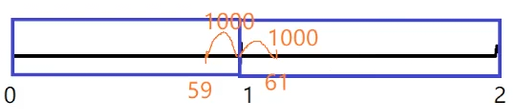
如果卡在一分钟最后一秒发来了1000次请求 接着在一分钟第一秒发来1000次请求
滑动窗口:

问题是 多长时间进行滑动一次?
漏桶算法:
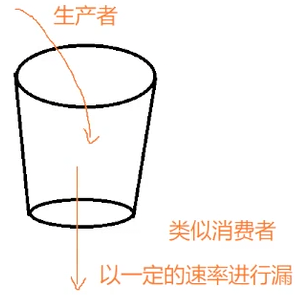
把请求看作水滴 水滴以一定的速率进行漏
但是存在问题:桶里面是空的 新来的请求也只能按固定的慢速一个一个处理 浪费时间 对应激流量也处理不好
令牌桶算法:
和漏桶有相似的地方 这就是令牌桶:食堂老板=系统,饭票=令牌,学生=请求,盒子容量=桶的容量
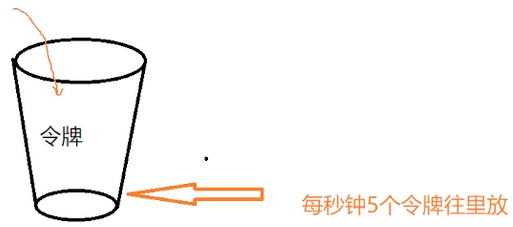
令牌桶的逻辑是闲时 系统生产令牌的速度不变 用不掉就存起来 忙时可以一下子把存货拿走 行成一个小高峰 忙完后,处理速度又回落到均匀生产令牌的节奏
RequestRateLimiter限流采用的就是令牌桶的算法
配置的三个参数:令牌填充速度 令牌桶的容量 每个请求消耗多少令牌
GlobalFilter:
是SpringCloudGateway中的全局过滤器,它和GatewayFilter的作用是相同的
它会应用到所有的路由请求上,全局过滤器通常用于实现与安全性,性能监控和日志记录等相关的全局功能
Spring Cloud Gateway 内置的全局过滤器也有很多 参考官方文档:Spring Cloud Gateway
比如:
Gateway Metrics Filter: ⽹关指标, 提供监控指标
Forward Routing Filter: ⽤于本地forword, 请求不转发到下游服务器
LoadBalancer Client Filter: 针对下游服务, 实现负载均衡
快速上手:添加依赖 添加配置 测试:http://127.0.0.1:10030/actuator, 显⽰所有监控的信息链接
(5)过滤器执行顺序
⼀个项⽬中, 既有GatewayFilter, ⼜有 GlobalFilter时, 执⾏的先后顺序是什么呢?
请求路由后, ⽹关会把当前项⽬中的GatewayFilter和GlobalFilter合并到⼀个过滤器链(集合)中, 并进⾏排序, 依次执⾏过滤器.
每一个过滤器都必须指定一个int类型的order值,默认值为0,表示该过滤的优先级,order值越小,优先级越高,执行顺序越靠前
(6)自定义过滤器
SpringCloudGateway提供了过滤器的扩展功能,开发者可以根据实际业务来自定义过滤器,同样自定义过滤器也可以支持GatewayFilter和GlobalFilter两种
1自定义GatewayFilter
⾃定义GatewayFilter, 需要去实现对应的接⼝ GatewayFilterFactory , Spring Boot 默认帮我们
实现的抽象类是 AbstractGatewayFilterFactory , 我们可以直接使⽤.
方法:定义GatewayFilter 配置过滤器 测试:重启服务 访问接口 观察日志
2自定义GlobalFilter
GlobalFilter的实现比较简单 它不需要额外的配置 只需要实现GlobalFilter接口,自动会过滤所有Filter
GlobalFilter的实现⽐较简单, 它不需要额外的配置, 只需要实现GlobalFilter接⼝, ⾃动会过滤所有的Filter.
(7)服务部署
修改数据库,Nacos等相关配置 对三个服务进行打包:product-service order-service gateway
上传jar到Linux服务器 启动Nacos:启动前最好把其他数据删除掉
启动服务 测试
3.0 分布式服务部署
(1)需要部署的服务
Nacos MySQL 网关服务 订单服务 商品服务
环境要求:机器个数1-N台均可 机器环境:Linux环境(Centos Ubuntu均可)
本课程机器情况说明:机器个数 4台
服务部署分配如下:
服务器1:MySQL Nacos 服务器2:产品服务实例1 订单服务实例1 服务器3:产品服务实例2,订单服务实例2 服务器4:网关服务
(2)部署操作
MySQL 安装 :安装好之后 对其他服务器授权
MySQL默认情况下, 只允许本地连接, 即localhost, 如果其他服务器需要连接到MySQL, 需要MySQL对这个服务器授权
java
grant 权限 on 数据库对象 to ⽤⼾1使用下面SQL 创建用户 并授权
java
-- 创建⽤⼾bite, 并设置密码, 此步可省略
CREATE USER 'bite'@'%' IDENTIFIED BY 'BITE@yyds.666';
-- 对bite⽤⼾授权
-- *.* 表⽰所有库的所有表, 也可以指定库和表
-- %表⽰IP, %表⽰允许所有IP访问, 也可以指定IP
GRANT ALL ON *.* TO 'bite'@'%';
-- 让修改⽣效
FLUSH PRIVILEGES;2修改bind-address
修改文件路径: /etc/mysql/mysql.conf.d/mysqld.cnf
把bind-address = 127.0.0.1改为 bind-address = 0.0.0.0
java
#bind-address = 127.0.0.1
bind-address = 0.0.0.03重启MySQL服务器
java
sudo systemctl restart mysql4开放3306端口
5测试授权结果
使⽤CMD客⼾端, 连接服务器MySQL, 如果可以正确连接, 则授权成功
java
#把110.41.51.65改成⾃⼰服务器的IP -u改成设置的账号名 -p后是对应的密码
2 mysql -h110.41.51.65 -P3306 -ubite -pBITE@yyds.666使⽤CMD客⼾端, 连接服务器MySQL, 如果可以正确连接, 则授权成功
java
#把110.41.51.65改成⾃⼰服务器的IP -u改成设置的账号名 -p后是对应的密码
2 mysql -h110.41.51.65 -P3306 -ubite -pBITE@yyds.666Nacos安装:
安装JDK 安装登录服务器,上传Jar包 启动服务
开放对应的端口号 测试
网关 服务部署:
安装JDK 登录服务器,上传Jar包 启动服务
开放对应的端口号 测试