目录
[一、调度诞生的底层根源:硬件矛盾 + 进程两大核心特性](#一、调度诞生的底层根源:硬件矛盾 + 进程两大核心特性)
[1.1 底层硬件核心矛盾](#1.1 底层硬件核心矛盾)
[1.2 进程核心特性一:独立性(系统稳定的基础)](#1.2 进程核心特性一:独立性(系统稳定的基础))
[1.3 进程核心特性二:资源竞争性(调度的核心原因)](#1.3 进程核心特性二:资源竞争性(调度的核心原因))
[1.4 并发与并行(90%初学者混淆核心)](#1.4 并发与并行(90%初学者混淆核心))
[1.4.1 核心定义](#1.4.1 核心定义)
[1.4.2 通俗比喻](#1.4.2 通俗比喻)
[1.4.3 动手实操验证(可直接复制执行)](#1.4.3 动手实操验证(可直接复制执行))
[1.4.4 现代Linux模型](#1.4.4 现代Linux模型)
[1.5 调度基本单位:LWP轻量级进程](#1.5 调度基本单位:LWP轻量级进程)
[二、Linux两大CPU调度模型(核心:分时CPU + 实时CPU)](#二、Linux两大CPU调度模型(核心:分时CPU + 实时CPU))
[2.1 分时CPU调度(SCHED_OTHER / CFS/EEVDF)](#2.1 分时CPU调度(SCHED_OTHER / CFS/EEVDF))
[2.1.1 核心运行规则](#2.1.1 核心运行规则)
[2.1.2 核心特点与适用场景](#2.1.2 核心特点与适用场景)
[2.2 实时CPU调度(SCHED_FIFO / RR / DEADLINE)](#2.2 实时CPU调度(SCHED_FIFO / RR / DEADLINE))
[2.2.1 三大实时CPU调度策略](#2.2.1 三大实时CPU调度策略)
[2.2.2 核心运行规则](#2.2.2 核心运行规则)
[2.2.3 核心特点与适用场景](#2.2.3 核心特点与适用场景)
[2.3 分时CPU vs 实时CPU 终极对比(面试必背)](#2.3 分时CPU vs 实时CPU 终极对比(面试必背))
[3.1 上下文核心组成](#3.1 上下文核心组成)
[3.2 上下文切换完整流程图](#3.2 上下文切换完整流程图)
[3.3 内核汇编源码逐行解析(x86_64 原生代码)](#3.3 内核汇编源码逐行解析(x86_64 原生代码))
[3.4 切换触发场景与开销](#3.4 切换触发场景与开销)
[3.5 实操:查看上下文切换统计](#3.5 实操:查看上下文切换统计)
[四、进程优先级体系(Nice/PR/内核优先级 完整映射)](#四、进程优先级体系(Nice/PR/内核优先级 完整映射))
[4.1 三层优先级层级(从高到低,绝对抢占)](#4.1 三层优先级层级(从高到低,绝对抢占))
[4.2 Nice值、PR值、内核优先级映射(分时CPU专属)](#4.2 Nice值、PR值、内核优先级映射(分时CPU专属))
[4.3 优先级本质:分时CPU权重分配](#4.3 优先级本质:分时CPU权重分配)
[4.4 实操:Top/renice修改分时进程优先级](#4.4 实操:Top/renice修改分时进程优先级)
五、Linux调度器三代演进(O(1)→CFS→EEVDF)
[5.1 第一代:O(1)调度器(Linux2.6.0~2.6.22)](#5.1 第一代:O(1)调度器(Linux2.6.0~2.6.22))
[核心前置:O(1) 优先级位图查找原理(面试核心重点)](#核心前置:O(1) 优先级位图查找原理(面试核心重点))
[1. 位图基础结构](#1. 位图基础结构)
[2. 位图查找核心指令(硬件级 O(1))](#2. 位图查找核心指令(硬件级 O(1)))
[3. 完整查找执行流程](#3. 完整查找执行流程)
[4. 位图核心优势](#4. 位图核心优势)
[5. 关键对比:位图查找 为什么碾压「遍历链表」?(面试高频)](#5. 关键对比:位图查找 为什么碾压「遍历链表」?(面试高频))
[1. 传统链表遍历(O(n) 致命缺陷)](#1. 传统链表遍历(O(n) 致命缺陷))
[2. 位图查找(硬件级 O(1) 降维打击)](#2. 位图查找(硬件级 O(1) 降维打击))
[3. 核心差距总结](#3. 核心差距总结)
[1. 动态修改进程优先级的表现(分时进程专属)](#1. 动态修改进程优先级的表现(分时进程专属))
[2. 新增就绪进程的调度表现](#2. 新增就绪进程的调度表现)
[3. 位图机制导致的致命缺陷:分时进程饥饿根源](#3. 位图机制导致的致命缺陷:分时进程饥饿根源)
[4. O(1) 原生饥饿解决方案(启发式补偿机制)](#4. O(1) 原生饥饿解决方案(启发式补偿机制))
[5. O(1) 整体致命缺陷总结](#5. O(1) 整体致命缺陷总结)
[5.2 第二代:CFS完全公平调度器(Linux2.6.23~6.5)](#5.2 第二代:CFS完全公平调度器(Linux2.6.23~6.5))
[5.3 第三代:EEVDF调度器(Linux6.6+ 新版默认)](#5.3 第三代:EEVDF调度器(Linux6.6+ 新版默认))
六、实时CPU调度深度详解(FIFO/RR/DEADLINE)
[6.1 软实时 vs 硬实时](#6.1 软实时 vs 硬实时)
[6.2 三大实时CPU调度策略细节](#6.2 三大实时CPU调度策略细节)
[6.3 实时CPU核心防护机制](#6.3 实时CPU核心防护机制)
[7.1 双层调度模型](#7.1 双层调度模型)
[7.2 核心参数详解(生产高频)](#7.2 核心参数详解(生产高频))
[7.3 K8s对应关系](#7.3 K8s对应关系)
[8.1 核心定义(精准无歧义)](#8.1 核心定义(精准无歧义))
[8.2 完整复现场景(三级进程标准模型)](#8.2 完整复现场景(三级进程标准模型))
[8.3 核心危害(生产/工控致命点)](#8.3 核心危害(生产/工控致命点))
[8.4 两大工业级解决方案(Linux RT 标配)](#8.4 两大工业级解决方案(Linux RT 标配))
[8.4.1 方案一:优先级继承协议(PI,Priority Inheritance)](#8.4.1 方案一:优先级继承协议(PI,Priority Inheritance))
[8.4.2 方案二:优先级天花板协议(PCP,Priority Ceiling Protocol)](#8.4.2 方案二:优先级天花板协议(PCP,Priority Ceiling Protocol))
[8.5 PI与PCP 终极对比(面试必背)](#8.5 PI与PCP 终极对比(面试必背))
[8.6 Linux 内核真实支持情况(生产落地重点)](#8.6 Linux 内核真实支持情况(生产落地重点))
[8.7 生产避坑总结](#8.7 生产避坑总结)
[9.1 1个核心本质](#9.1 1个核心本质)
[9.2 2大调度体系(层级永不颠倒)](#9.2 2大调度体系(层级永不颠倒))
[9.3 3代分时调度演进逻辑](#9.3 3代分时调度演进逻辑)
[9.4 1个致命坑点](#9.4 1个致命坑点)
本篇文章先给出全局核心架构链路图,所有调度原理、进程特性、软硬件配合逻辑全部围绕该闭环展开,帮助大家建立整体认知:
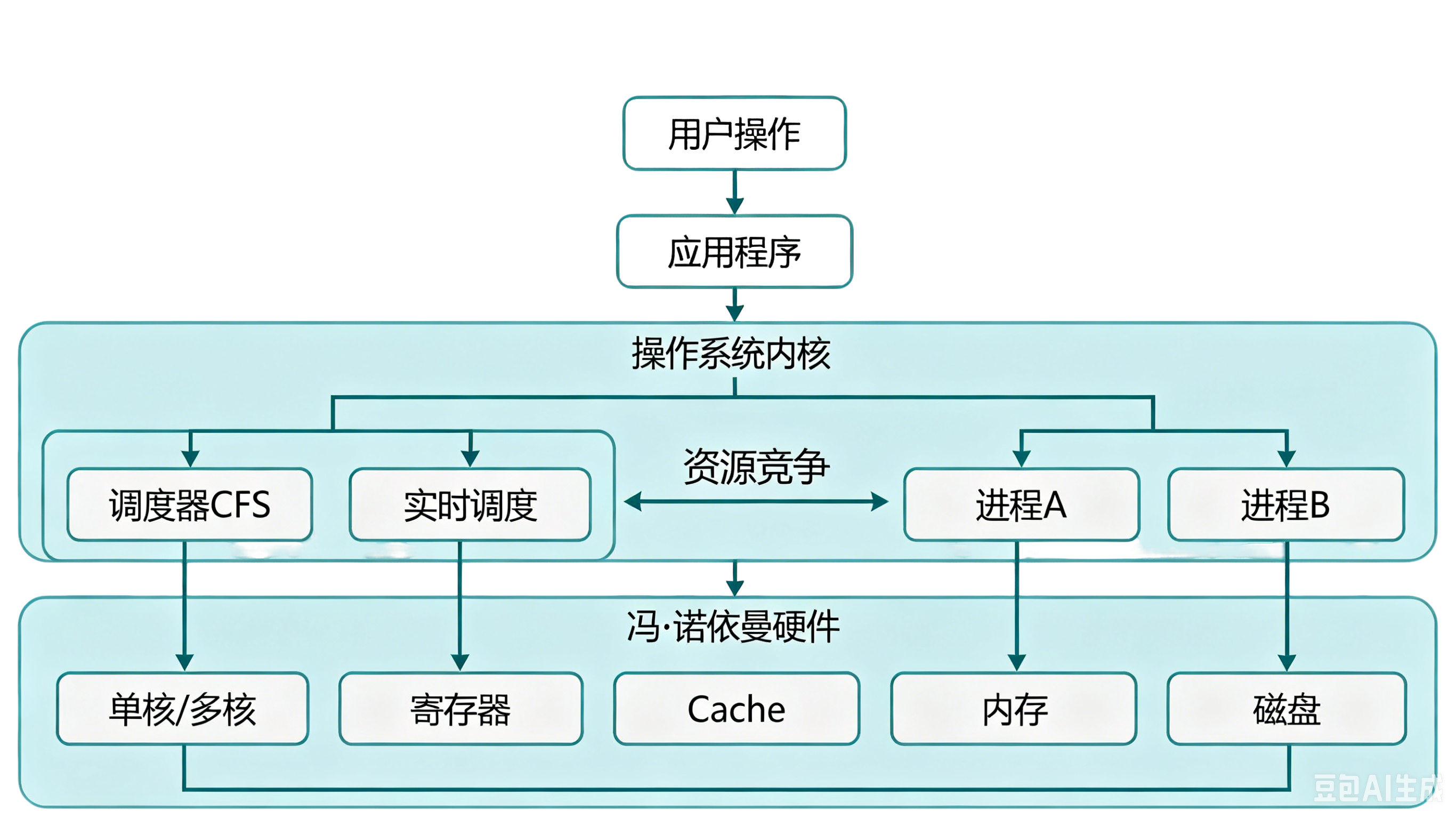
一、调度诞生的底层根源:硬件矛盾 + 进程两大核心特性
1.1 底层硬件核心矛盾
冯·诺依曼架构下,计算机硬件速度层级差距极大,这是调度器诞生的根本原因:
-
CPU 运算速度:<1 纳秒(极速运算)
-
内存读写速度:50~100 纳秒
-
磁盘/网络 I/O:毫秒级(比 CPU 慢上万倍)
如果没有调度机制,CPU 会在进程等待 I/O 时空转,系统资源利用率不足 1%。为了解决该问题,操作系统引入多道程序设计:内存同时加载多个进程,一个进程等待I/O时,CPU立刻切换执行其他进程,拉满系统吞吐量。
1.2 进程核心特性一:独立性(系统稳定的基础)
Linux 进程最核心的设计就是完全隔离独立,每个进程都独占一套私有资源,互不干扰,这是多任务安全运行的前提:
-
独立虚拟地址空间:依托MMU硬件隔离,每个进程拥有独立的"虚拟内存",无法访问其他进程内存,单个进程崩溃不会影响全局
-
独立文件描述符表:进程打开的文件、套接字、管道私有,同文件多进程打开互不冲突
-
独立信号处理机制:每个进程可自定义信号处理逻辑,Ctrl+C等信号仅作用于目标进程
-
独立运行上下文:私有寄存器状态、内核栈、工作目录、用户权限
核心结论:进程独立性保证了多任务的安全性、稳定性,让内核可以放心切换进程,无需担心资源错乱。
1.3 进程核心特性二:资源竞争性(调度的核心原因)
进程软件资源完全独立,但硬件资源全局共享,所有进程天然存在资源竞争:
-
CPU核心:单核同一时刻仅能运行一个进程
-
物理内存:总容量固定,多进程抢占内存空间
-
磁盘I/O带宽、网络带宽:硬件吞吐上限固定
若无调度器仲裁,会出现三大致命问题:
-
进程饥饿:低优先级进程永久抢不到CPU
-
资源耗尽:恶意进程占满CPU/内存,系统卡死
-
执行混乱:多进程无序抢占,数据错乱
调度器的本质定位:硬件资源的公平裁判,决定「谁能上CPU、运行多久、何时切换」。
1.4 并发与并行(90%初学者混淆核心)
1.4.1 核心定义
-
并发(Concurrent):一段时间内多任务交替推进,同一时刻仅一个任务执行。依托单核CPU高速进程切换实现,宏观同时运行,微观串行。
-
并行(Parallel):同一精确时刻多任务真正同时执行,必须依赖多核CPU硬件。
1.4.2 通俗比喻
-
并发:1个人同时做饭、打字、接电话,靠快速切换注意力
-
并行:3个人同时分别做饭、打字、接电话,真正同步执行
1.4.3 动手实操验证(可直接复制执行)
通过死循环进程,直观区分并发与并行:
现象解读:
-
单核机器:两个进程各占50%CPU,交替执行 → 并发
-
双核机器:两个核心各100%占用,进程独立运行 →并行
1.4.4 现代Linux模型
多核CPU整体并行,单个核心内部永远是并发,是并发+并行的混合架构。
1.5 调度基本单位:LWP轻量级进程
Linux内核不区分进程和线程,统一以 LWP(轻量级进程) 为调度单位:
-
普通进程:独立虚拟地址空间 + 独立CPU上下文
-
线程:共享父进程地址空间,仅拥有独立CPU上下文
核心本质:调度器只识别「寄存器上下文」,谁占用CPU寄存器,谁就是正在运行的任务。
二、Linux两大CPU调度模型(核心:分时CPU + 实时CPU)
Linux CPU调度严格分为分时CPU调度(普通进程) 与**实时CPU调度(实时进程)**两大类,优先级层级完全隔离,实时CPU永远抢占分时CPU,是系统调度的顶层规则。
2.1 分时CPU调度(SCHED_OTHER / CFS/EEVDF)
定位 :系统默认调度模型,负责99%普通业务进程,追求公平性、低卡顿、资源均衡。
对应进程:普通用户进程、后台服务、浏览器、bash、Java/Python业务进程等。
优先级区间:内核优先级 100~139(Nice -20~19),数值越小优先级越高。
2.1.1 核心运行规则
-
无固定时间片,基于权重比例分配CPU时间,Nice值决定权重大小
-
遵循vruntime/vdelay公平机制,绝对不会永久饥饿,仅暂时落后
-
可被实时进程强制抢占,无法抢占任何实时CPU任务
-
交互式进程优先补偿,保障桌面、终端操作流畅
2.1.2 核心特点与适用场景
-
优势:公平均衡、资源利用率高、无永久饥饿、交互体验好
-
劣势:无硬实时保障,极端场景存在轻微调度延迟
-
场景:服务器业务、桌面交互、脚本执行、后台守护进程
2.2 实时CPU调度(SCHED_FIFO / RR / DEADLINE)
定位 :高优先级专属调度模型,追求确定性、低延迟、硬时限保障,牺牲公平性换实时性。
对应进程:音视频采集、工业工控、汽车电子、vCPU虚拟化、精密采集任务。
优先级区间 :内核优先级 0~99,数值越大优先级越高,完全凌驾于分时进程之上。
2.2.1 三大实时CPU调度策略
-
SCHED_FIFO(实时先来先服务):无时间片,一旦占用CPU永久运行,主动sleep/退出或被更高优先级实时进程抢占才释放CPU,实时性最强
-
SCHED_RR(实时时间片轮转):同优先级实时进程拥有固定时间片,时间片耗尽轮转,避免同级独占CPU
-
SCHED_DEADLINE(硬实时截止时间):Linux最高级实时策略,EDF最早截止时间优先,严格保障任务时限,带CPU带宽限流,防止卡死系统
2.2.2 核心运行规则
-
绝对抢占:只要有实时CPU进程就绪,立刻抢占所有分时CPU进程,分时进程直接让出CPU
-
实时内部层级:高优先级实时抢占低优先级实时,同级按策略轮转/排队
-
可配置CPU带宽上限,系统默认保留5%CPU给分时进程,防止实时任务卡死系统
2.2.3 核心特点与适用场景
-
优势:微秒/毫秒级低延迟、执行确定性强、时限保障高
-
劣势:不公平、极易导致低优先级分时进程饥饿,配置不当会卡死系统
-
场景:硬实时工控、音视频实时编解码、高精度采集、虚拟化vCPU
2.3 分时CPU vs 实时CPU 终极对比(面试必背)
| 对比维度 | 分时CPU(普通CFS/EEVDF) | 实时CPU(FIFO/RR/DEADLINE) |
|---|---|---|
| 优先级范围 | 100~139(Nice -20~19) | 0~99(数值越大优先级越高) |
| 核心目标 | 公平调度、资源均衡、高利用率 | 低延迟、确定性、硬实时时限保障 |
| 抢占规则 | 无法抢占实时进程,仅同级/低同级切换 | 可无条件抢占所有分时进程 |
| 时间片机制 | 无固定时间片,权重比例分配 | FIFO无时间片,RR/DEADLINE有固定时间片 |
| 饥饿问题 | 机制级彻底杜绝饥饿 | 极易导致分时进程饥饿,需带宽限制防护 |
| 适用业务 | 99%普通业务、桌面、服务器、脚本 | 实时精密任务、工控、音视频、虚拟化 |
三、调度核心本质:上下文切换(底层硬件全流程)
调度 = 保存旧进程上下文 + 切换地址空间 + 恢复新进程上下文,是操作系统多任务的核心基石,分时/实时进程切换底层逻辑完全一致。
3.1 上下文核心组成
上下文是进程CPU运行的全部状态,保存在 task_struct.thread 中,缺失任意一项都会导致进程崩溃:
| 寄存器/资源 | 核心作用 |
|---|---|
| RIP 程序计数器 | 记录下一条执行指令地址,决定进程恢复执行位置 |
| RSP/RBP 栈指针 | 维护函数调用栈,保证局部变量、调用链不混乱 |
| 通用寄存器(RAX/RBX等) | 保存运算中间数据 |
| CR3 页表寄存器 | 存储进程页表基址,实现虚拟内存隔离 |
| EFLAGS 标志寄存器 | 保存运算状态(进位、零值等),影响条件判断 |
3.2 上下文切换完整流程图
旧进程运行 → 触发调度中断/主动阻塞 → 保存寄存器上下文 & 内核栈 → 改写CR3切换进程页表 → 刷新CPU TLB缓存 → 加载新进程上下文 → 恢复执行
3.3 内核汇编源码逐行解析(x86_64 原生代码)
源码路径:arch/x86/kernel/process_64.c,核心函数 __switch_to,是Linux最底层的进程切换实现:
源码核心考点
-
切换最大开销:CR3改写导致TLB缓存失效,需要重新加载页表映射
-
每个进程独有 thread_struct + 内核栈,保证现场可恢复
-
纯汇编实现,零冗余,是内核高性能的核心保障
3.4 切换触发场景与开销
触发场景
-
自愿切换:进程调用 sleep、read、write 阻塞,主动让出CPU
-
非自愿切换:时间片耗尽,时钟中断强制抢占(分时进程高频)
-
抢占切换:高优先级实时进程就绪,强制抢占分时/低优先级实时进程
-
退出切换:进程exit终止,强制切换
切换开销
-
直接开销:寄存器保存/恢复、页表切换、TLB刷新(1~10微秒/次)
-
间接开销:CPU Cache失效,新进程需重新加载缓存,性能损耗极大
3.5 实操:查看上下文切换统计
通过 vmstat、pidstat -w 可实时查看系统全局、单进程上下文切换次数,排查系统卡顿、CPU软中断高负载问题。
四、进程优先级体系(Nice/PR/内核优先级 完整映射)
优先级是调度器选进程的唯一依据,严格区分实时CPU优先级 和分时CPU优先级,层级不可逆。
4.1 三层优先级层级(从高到低,绝对抢占)
-
硬实时优先级(0~99):对应实时CPU调度,数字越大优先级越高,绝对抢占所有分时进程
-
普通分时优先级(100~139):对应分时CFS/EEVDF调度,数字越小优先级越高
-
空闲优先级:系统空闲进程,仅无任何任务时执行
4.2 Nice值、PR值、内核优先级映射(分时CPU专属)
Nice值仅作用于分时普通进程,实时进程不依赖Nice值,直接使用0~99硬性优先级:
-
Nice值范围:-20 ~ 19,值越小优先级越高、CPU权重越大
-
内核优先级 = 120 + Nice
-
Top展示PR值 = 20 + Nice
| Nice值 | 内核优先级 | Top PR值 | 权重 | 优先级等级 |
|---|---|---|---|---|
| -20 | 100 | 0 | 88761 | 最高分时优先级 |
| 0 | 120 | 20 | 1024 | 默认分时优先级 |
| 19 | 139 | 39 | 15 | 最低分时优先级 |
4.3 优先级本质:分时CPU权重分配
分时CPU无固定时间片,优先级仅代表CPU占用权重比例:
进程CPU占比 = 进程权重 / 系统所有就绪分时进程总权重
示例:Nice=0(1024权重)+ Nice=19(15权重)
-
总权重 = 1039
-
Nice0进程占比 = 98.5%
-
Nice19进程占比 = 1.5%
4.4 实操:Top/renice修改分时进程优先级
仅对分时普通进程生效,实时进程无法通过Nice修改优先级:
操作步骤
-
终端输入 top 打开监控面板
-
查看目标进程PID、NI(当前nice)、PR(当前优先级)
-
按键盘 r 键,进入renice修改模式
-
输入目标进程PID,回车
-
输入新的Nice值(-20~19),回车确认
-
面板自动刷新,NI、PR列实时更新,修改生效
权限规则
-
普通用户:仅能增大Nice值(降低分时进程优先级)
-
Root用户:可任意设置-20~19所有分时优先级
命令行快捷修改 :renice -n 5 -p 进程PID
五、Linux调度器三代演进(O(1)→CFS→EEVDF)
三代调度器均为分时CPU调度器,负责普通进程调度;实时CPU调度逻辑独立存在,不随三代调度器迭代改变。
5.1 第一代:O(1)调度器(Linux2.6.0~2.6.22)
核心目标:彻底解决早期调度器 O(n) 遍历卡顿问题,让调度决策耗时与系统进程总数无关,无论系统存在几十、几百甚至上千个进程,单次选程耗时恒定,稳定 O(1) 时间复杂度,大幅提升高并发服务器的调度稳定性,是 Linux 2.6 时代里程碑式优化。
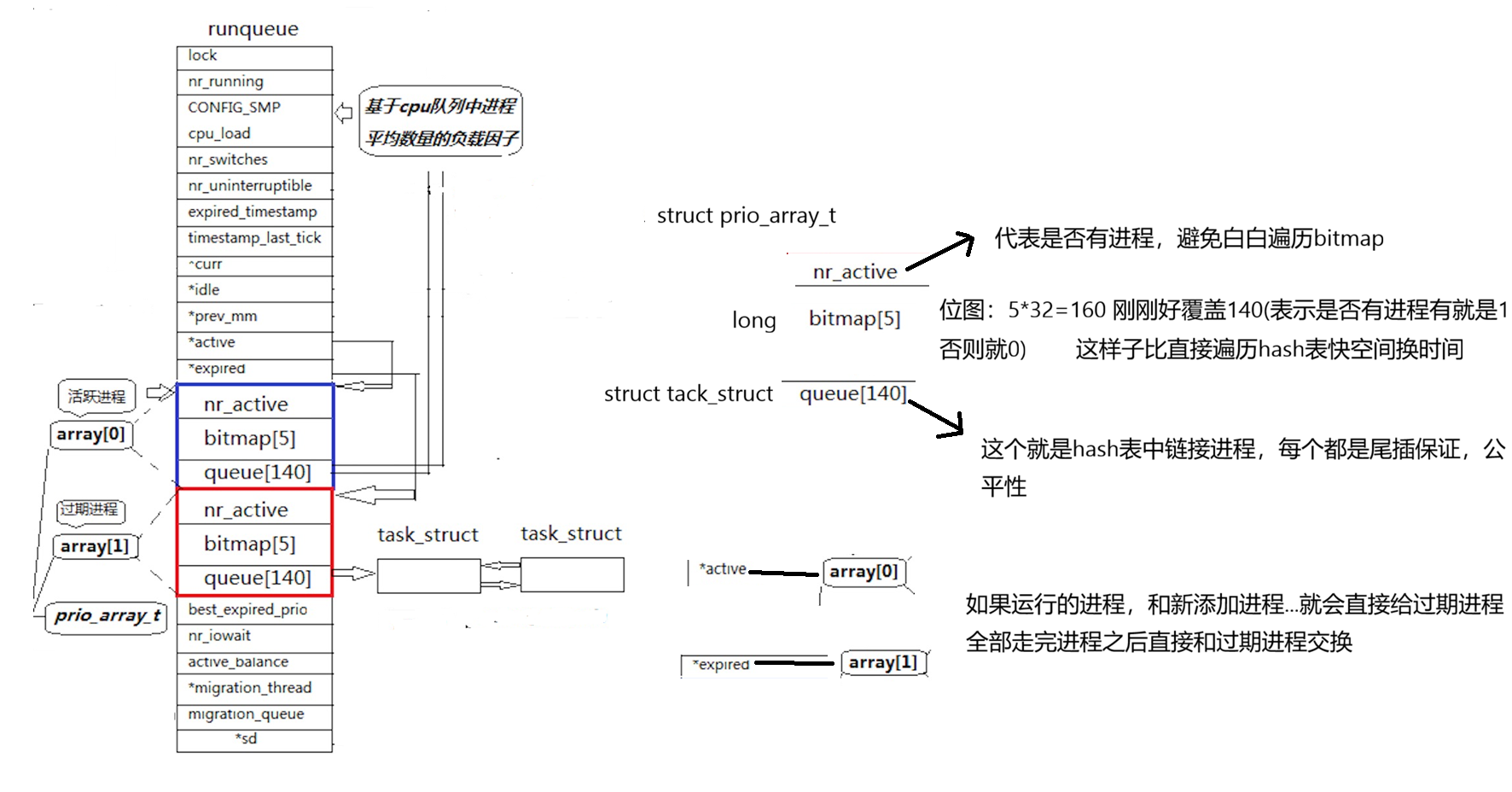
核心结构
-
每CPU独立运行队列 runqueue:CPU 之间调度完全隔离,不跨核抢占,减少多核锁竞争,提升多核并发性能,每个核心独立调度自身就绪进程。
-
双队列设计:每个 runqueue 包含 active 活跃队列、expired 过期队列
-
active:存放已经分配时间片、正在/等待运行的就绪进程
-
expired:存放时间片耗尽、暂时让出 CPU 的进程,等待新一轮时间片分配
-
-
140 级优先级映射结构:对应 Linux 完整优先级区间(0~139),内置 140 条进程链表 + 140 位优先级位图,每一条链表对应一个固定优先级,同优先级进程挂在同一条链表上。
核心逻辑
O(1) 调度器的核心调度逻辑极简且高效,全程无全局遍历,完全靠位图+双队列指针切换实现恒定耗时调度,完整流程如下:
-
选程逻辑:通过优先级位图快速扫描置位的最高优先级位,直接定位系统当前最高优先级就绪进程,从对应链表头部取出进程投入 CPU 运行。位图查询是硬件级位运算,耗时恒定。
-
时间片耗尽处理:进程时间片用完后,调度器不会丢弃进程,而是将其移出 active 队列,移入 expired 队列尾部,等待新一轮时间片重置。
-
队列切换机制:当 active 活跃队列中所有优先级进程全部耗尽时间片后,内核直接指针交换 active 与 expired 队列,无需迁移任何进程数据,瞬间完成新一轮调度周期切换,这也是 O(1) 复杂度的核心关键。
核心前置:O(1) 优先级位图查找原理(面试核心重点)
位图是 O(1) 调度器实现恒定耗时选程的核心,彻底抛弃传统 O(n) 遍历进程的低效逻辑,是 O(1) 复杂度的根本保障。
1. 位图基础结构
Linux O(1) 为每个 CPU 的 runqueue 维护一张 140 位优先级位图,对应普通进程 100~139、实时进程 0~99 的完整 140 级优先级:
-
位图每 1 个 bit 位,对应 1 个优先级等级
-
bit = 1:代表该优先级有就绪进程,可调度
-
bit = 0:代表该优先级无就绪进程,跳过
-
位图高位 = 高优先级(实时进程),低位 = 低优先级(普通分时进程)
2. 位图查找核心指令(硬件级 O(1))
内核依靠 CPU 硬件指令 find_first_bit(查找第一个置1位) 完成选程,单次查询仅需 1 个时钟周期,和进程数量无关:
查找铁律:永远从最高位向低位扫描,找到第一个 bit=1 的优先级,就是当前系统最高优先级就绪任务。
3. 完整查找执行流程
-
系统所有就绪进程,按自身优先级挂载到对应链表,并自动置位对应位图bit;进程休眠/退出时,自动清零对应bit
-
调度触发时,CPU 硬件扫描整张 140 位位图,快速定位最靠前的置1位
-
通过bit位编号,精准匹配对应优先级的进程链表
-
取出链表头部进程,投入 CPU 运行
4. 位图核心优势
-
无论系统有 10 个进程还是 1000 个进程,查找耗时完全一致,严格 O(1)
-
天然保证「高优先级优先执行」,无需排序、无需遍历
-
硬件指令执行,速度远超软件遍历算法
5. 关键对比:位图查找 为什么碾压「遍历链表」?(面试高频)
在 O(1) 调度器诞生前,早期 Linux 调度器采用纯链表遍历选程,存在严重性能瓶颈,这也是位图结构必须存在的核心原因,两者效率差距本质如下:
1. 传统链表遍历(O(n) 致命缺陷)
如果不使用位图,内核想要找到「系统最高优先级就绪进程」,必须执行以下操作:
-
从最高优先级链表开始,逐个判断链表是否为空;
-
如果为空,继续向下遍历次一级优先级链表;
-
直到找到第一个非空链表,取出进程执行。
时间复杂度:O(n)
系统优先级共 140 级,最坏情况(所有高优先级均为空,仅有最低优先级进程就绪)需要遍历 139 次空链表才能找到目标进程。系统进程越多、优先级越分散,遍历耗时越长,高并发场景下调度延迟急剧飙升。
2. 位图查找(硬件级 O(1) 降维打击)
位图彻底规避了「逐一遍历」的低效逻辑,将软件循环遍历转化为硬件位运算:
-
位图是一张 140bit 的标记表,每一位提前标记对应优先级「是否有就绪进程」;
-
无需循环判断,直接调用 CPU 专属硬件指令 find_first_bit;
-
硬件一次性扫描所有 bit,单个时钟周期直接返回最高置1位的下标;
-
通过下标直接定位对应链表,零遍历、零冗余判断。
时间复杂度:严格 O(1)
3. 核心差距总结
| 对比维度 | 链表遍历(旧调度器) | 位图查找(O(1)调度器) |
|---|---|---|
| 算法复杂度 | O(n),随优先级层级递增耗时 | O(1),耗时恒定不随进程数变化 |
| 执行方式 | 软件循环判断,多次内存读取 | 硬件位运算,单时钟周期完成 |
| 最坏场景耗时 | 遍历全部140级优先级,耗时极高 | 无论任何场景,耗时完全一致 |
| 高并发表现 | 进程越多,调度卡顿越严重 | 高负载下调度延迟极度稳定 |
终极结论:位图的核心价值不是「优化代码」,而是用空间换时间,彻底消灭遍历开销,让 Linux 在高并发服务器场景下,调度性能彻底脱胎换骨。
关键场景表现(优先级修改/新增进程/饥饿问题)
1. 动态修改进程优先级的表现(分时进程专属)
O(1) 调度器优先级、位图bit、时间片三者强绑定,修改优先级会联动「位图置位、进程链表迁移、时间片大小」同步变化,前台表现极其直观:
-
调高优先级(Nice 减小):内核自动清零旧优先级位图bit,置位新的高优先级bit,将进程迁移到高位优先级链表,分配更长固定时间片;位图扫描会优先命中该高位,进程抢占能力拉满,直接抢占低优先级分时进程CPU,CPU占有率大幅飙升。
-
调低优先级(Nice 增大):内核清零旧高位bit,置位低位bit,进程迁移至低优先级链表,分配更短时间片;位图扫描最后才会命中该优先级,调度权重大幅后置,CPU占有率显著下降。
核心特点:O(1) 是「固定时间片模型」,优先级对应固定时长时间片,无动态权重比例分配,优先级差距带来的性能差距是阶梯式、固定化的,不够平滑。
2. 新增就绪进程的调度表现
-
新进程创建/唤醒后,内核根据其优先级自动置位对应位图bit,挂载到 active 队列对应链表尾部。
-
高优先级新进程:位图高位被置1,硬件扫描优先命中,直接抢占当前低优先级运行进程,立刻获取CPU执行权,响应极速。
-
同优先级新进程:遵循 FIFO 先进先出规则,排队执行,时间片轮流分配。
-
低优先级新进程:无法抢占高优先级进程,只能等待当前 active 高优先级队列全部跑完,才会被调度。
3. 位图机制导致的致命缺陷:分时进程饥饿根源
O(1) 调度器天生存在低优先级分时进程饥饿漏洞,也是被 CFS 淘汰的核心原因:
饥饿本质(位图机制原生漏洞):只要系统持续存在高优先级就绪进程(分时+实时),位图高位永远为1,CPU 每次扫描都会优先命中高位,低位低优先级分时进程bit永远无法被遍历到,长期得不到CPU,形成永久饥饿。
4. O(1) 原生饥饿解决方案(启发式补偿机制)
内核为解决分时进程饥饿,强行加入一套复杂的启发式补偿逻辑,也是 O(1) 代码臃肿的根源:
-
饥饿检测:内核统计低优先级分时进程的「等待时长」,如果进程等待超时、长期未被调度,判定为饥饿进程。
-
临时升权补偿:临时抬高饥饿进程的优先级、赠送额外时间片,强制让其获得 CPU 执行机会,打破永久饥饿。
-
交互式进程优待:主动识别休眠频繁的交互式分时进程(终端、桌面),额外奖励时间片、提升优先级,避免操作卡顿。
补偿机制弊端:启发式规则全是硬编码特例,逻辑极其臃肿、难以维护,且补偿精度差、公平性弱,经常出现「过度补偿」或「补偿失效」,无法从根本上解决调度不公平问题。
5. O(1) 整体致命缺陷总结
-
公平性极差:基于固定优先级+固定时间片,无动态权重,高低优先级分时进程资源分配极端不均衡。
-
交互式体验差:单纯靠启发式补偿,无法稳定保障前台分时进程响应,容易出现鼠标卡顿、终端延迟。
-
内核代码臃肿:大量补丁式启发逻辑,维护成本极高,扩展性差。
-
无法彻底解决饥饿:补偿只是事后补救,而非机制级公平,高负载下分时进程饥饿依旧频发。
公平性差、交互式进程卡顿、启发式逻辑臃肿难维护,最终被CFS替代
5.2 第二代:CFS完全公平调度器(Linux2.6.23~6.5)
核心目标 :针对分时CPU进程实现权重比例公平,彻底解决O(1)的调度不公平、饥饿问题
核心核心:vruntime虚拟运行时间
vruntime += 实际运行时间 × (1024 / 进程权重)
-
权重大的分时进程,vruntime增长慢,优先被调度
-
调度铁律:永远选择vruntime最小的分时进程执行
核心数据结构:红黑树
CFS运行队列基于红黑树实现,按vruntime排序,左小右大,支持O(logN)增删查,完美适配分时进程频繁唤醒/休眠场景
核心价值 :从机制层面彻底杜绝分时进程永久饥饿,低权重进程只要持续就绪,vruntime最终一定会最小,必然能抢到CPU时间片。
5.3 第三代:EEVDF调度器(Linux6.6+ 新版默认)
优化对象 :依旧是分时CPU进程,解决CFS累积vruntime误差导致的交互式卡顿、长尾延迟高问题
核心改进:虚拟截止时间vdelay
vdelay = vruntime + (1024/权重) × 时间增量
调度规则:优先选择vdelay最小的分时任务,彻底消除历史运行误差干扰
核心优势
-
更低的交互式分时进程延迟,桌面/微服务体验更好
-
代码精简,移除CFS冗余启发式逻辑
-
SLO稳定性更强,适合云原生生产环境
六、实时CPU调度深度详解(FIFO/RR/DEADLINE)
6.1 软实时 vs 硬实时
-
软实时(FIFO/RR):尽力执行,偶尔超时可接受,适用于音视频、桌面交互等非严苛场景
-
硬实时(SCHED_DEADLINE):严格时限,超时即故障,适用于工控、汽车电子、精密控制场景
6.2 三大实时CPU调度策略细节
-
SCHED_FIFO:无时间片、无轮转。高优先级实时进程就绪即抢占,一旦运行持续占用CPU,主动sleep/退出或被更高优先级实时进程抢占才释放CPU,实时性最强
-
SCHED_RR:同优先级实时进程固定时间片轮转,避免单个实时任务独占CPU,平衡实时性与稳定性
-
SCHED_DEADLINE:EDF最早截止时间优先,Linux最高优先级硬实时策略,自带CPU带宽限流,防止实时任务卡死系统
6.3 实时CPU核心防护机制
为防止实时CPU无限抢占导致所有分时进程饿死、系统卡死 ,内核默认限制:实时任务总CPU带宽≤95%,永久保留5%CPU带宽给分时进程,保障系统基础服务不挂。
七、CFS组调度:容器CPU资源隔离底层原理
Docker/K8s的CPU限制,完全基于分时CFS组调度实现,仅作用于普通分时进程,不限制实时进程。
7.1 双层调度模型
-
组间公平:不同cgroup进程组按权重分配分时CPU资源
-
组内公平:同一容器内的分时进程,再按Nice值二次分配CPU
7.2 核心参数详解(生产高频)
| 参数 | 作用 | 常见误区 |
|---|---|---|
| cpu.shares | 组间相对权重,默认1024,仅竞争分时CPU资源时生效,用于容器/进程组之间的CPU比例分配 | 仅限制分时进程,CPU空闲时不会硬性限制容器占用多余算力,无法做硬限流 |
| cpu.cfs_period_us | 分时调度统计周期,系统默认100ms,是CPU配额统计的时间基准 | 通用场景无需手动修改,擅自调整会导致调度精度异常 |
| cpu.cfs_quota_us | 分时CPU硬限制上限,限定单个调度周期内可使用的CPU最大时长 | 真正限制容器CPU使用率的核心参数,仅对普通分时进程生效,对实时进程无效 |
7.3 K8s对应关系
-
resources.requests.cpu → cpu.shares(分时CPU相对权重)
-
resources.limits.cpu → cfs_quota + cfs_period(分时CPU硬上限)
八、核心坑点:优先级倒置(实时CPU致命BUG)
优先级倒置是实时调度体系下最经典、最致命、面试必考的底层漏洞,仅存在于多优先级抢占式调度场景,普通分时CFS/EEVDF调度几乎不会触发。该问题会直接打破实时任务的确定性低延迟特性,导致高优先级核心实时任务卡顿、超时、业务故障,最知名案例是美国火星探测器因优先级倒置导致系统任务卡死、重启故障。
8.1 核心定义(精准无歧义)
优先级倒置(优先级反转) :在抢占式实时调度系统中,高优先级实时进程 因等待低优先级实时进程 持有的共享资源(互斥锁、信号量)被阻塞,无法执行;同时系统内中等优先级实时进程持续抢占CPU运行,最终出现「低、中优先级进程持续占用CPU,高优先级核心任务长期饥饿阻塞」的反常调度现象,彻底违背实时系统"高优先级优先执行"的核心规则。
关键区分
-
有限优先级倒置:仅高优先级等待低优先级释放资源,无中等优先级干扰,阻塞时间固定、可控,无致命危害
-
无限优先级倒置(致命):中等优先级任务持续抢占CPU,低优先级任务迟迟无法释放锁,高优先级任务阻塞时间无上限、不可预测,这是生产环境需要彻底规避的核心问题
8.2 完整复现场景(三级进程标准模型)
设定三个不同优先级的实时进程(优先级:高A > 中B > 低C),共享一把互斥锁mutex,完整复现致命优先级倒置流程:
-
初始状态:系统仅有低优先级进程C运行,C成功抢占并持有共享mutex锁,进入临界区执行业务逻辑
-
高优先级任务就绪:核心实时任务A唤醒,凭借高优先级直接抢占CPU,但A需要获取mutex锁才能执行,而锁被C持有,A被迫阻塞等待
-
中等优先级任务抢占:进程B就绪,B优先级高于C、低于A,此时A已阻塞,B顺利抢占CPU持续运行
-
死锁式阻塞形成:B持续占用CPU,导致持有锁的低优先级进程C无法被调度、无法退出临界区、无法释放mutex锁;C不释放锁,高优先级A就永远无法唤醒执行
最终诡异结果:最高优先级核心任务A < 中等优先级任务B < 低优先级任务C,调度优先级完全颠倒,高优先级核心业务被低优先级业务无限阻塞。
8.3 核心危害(生产/工控致命点)
-
实时超时故障:硬实时工控、汽车电子、精密采集任务错过执行时限,引发设备异常、业务报错
-
系统卡顿雪崩:核心服务长期阻塞,叠加任务堆积,最终导致系统负载飙升、卡死重启
-
延迟不可控:实时系统核心价值是确定性低延迟,优先级倒置导致调度延迟随机、无上限,彻底破坏实时性
-
排查难度极高:问题偶发、无固定报错日志,仅表现为核心任务偶尔卡顿,常规监控无法定位根因
8.4 两大工业级解决方案(Linux RT 标配)
Linux 主线非实时内核仅基础规避,PREEMPT-RT实时补丁内核完整实现两套标准解决方案:优先级继承(PI)、优先级天花板(PCP),彻底解决无限优先级倒置问题。
8.4.1 方案一:优先级继承协议(PI,Priority Inheritance)
核心原理 :当高优先级进程A因等待低优先级进程C持有的锁而阻塞时,内核临时将低优先级C的优先级提升至高优先级A的层级,C继承A的优先级,直至C释放所持有的共享锁。锁释放后,C优先级自动恢复原值。
完整执行优化流程
-
低优先级C持有mutex锁正常运行
-
高优先级A就绪,抢占CPU后因无锁阻塞
-
内核触发PI机制,C优先级临时抬升至A的高优先级
-
中等优先级B就绪后,因优先级低于升级后的C,无法抢占CPU
-
C无干扰快速执行完临界区,立刻释放mutex锁
-
A获取锁,抢占CPU优先执行核心任务;C优先级恢复原值
优缺点总结
-
优势:彻底杜绝无限优先级倒置、无需提前配置、动态适配、资源开销小、落地简单
-
劣势:存在链式阻塞、嵌套优先级继承冗余问题,极端场景会轻微增加调度延迟,无法规避所有死锁风险
适用场景:绝大多数实时业务、音视频编解码、常规工控系统,是Linux RT默认首选方案。
8.4.2 方案二:优先级天花板协议(PCP,Priority Ceiling Protocol)
核心原理 :提前为每一把共享锁预设一个最高优先级(天花板优先级) ,该优先级等于所有可能竞争此锁的进程中的最高优先级。任意进程获取该锁时,会无条件临时抬升至天花板优先级,提前阻断中等优先级进程的抢占可能。
核心逻辑:从源头杜绝"中等优先级进程抢占持锁低优先级任务"的可能,无需等待高优先级阻塞后再补救,属于预防性优化,而非事后补偿。
优缺点总结
-
优势:延迟更稳定、确定性更强、彻底规避链式继承问题、可预防部分死锁,硬实时场景适配性更好
-
劣势:需要提前梳理所有锁与进程优先级、配置繁琐、会小幅抬高系统整体调度优先级,资源开销略大
适用场景 :汽车电子、航空航天、高精度工控等硬实时、高安全等级场景。
8.5 PI与PCP 终极对比(面试必背)
| 对比维度 | 优先级继承 PI | 优先级天花板 PCP |
|---|---|---|
| 优化时机 | 被动补救:高优先级阻塞后触发 | 主动预防:加锁瞬间直接抬升优先级 |
| 配置难度 | 低,动态自适应,无需人工配置 | 高,需提前定义每把锁的天花板优先级 |
| 延迟确定性 | 一般,存在轻微链式延迟 | 极强,延迟边界固定可控 |
| 死锁规避 | 无法完全规避 | 可预防大部分锁嵌套死锁 |
| 系统开销 | 小 | 略大 |
| 主流应用 | 通用实时系统、业务实时服务 | 高可靠硬实时、安全关键场景 |
8.6 Linux 内核真实支持情况(生产落地重点)
-
普通Linux内核(默认):无PI/PCP机制,实时进程存在原生优先级倒置漏洞,不适合生产实时业务
-
PREEMPT-RT 实时补丁内核:完整实现 RT-Mutex,原生支持优先级继承PI,工业级实时系统标配
-
SCHED_DEADLINE:硬实时调度策略自带带宽隔离与优先级保护,天然规避大部分优先级倒置问题
8.7 生产避坑总结
-
普通分时业务(CFS/EEVDF)无需关注优先级倒置,权重公平机制天然规避该问题
-
所有自定义FIFO/RR实时业务,必须部署RT内核+PI锁机制,否则大概率出现偶发核心任务卡顿
-
硬实时高可靠场景,优先使用PCP机制或DEADLINE调度,保障延迟绝对可控
-
禁止大量嵌套实时锁,避免优先级继承链式叠加,导致调度延迟恶化
九、全文终极总结(知识闭环)
整篇Linux进程调度核心知识,可归纳为1个本质、2大体系、3代演进、1个致命坑点,彻底覆盖底层原理、面试考点、生产落地:
9.1 1个核心本质
进程调度的本质是硬件资源仲裁+上下文切换:解决进程独立性与硬件资源竞争性的矛盾,在公平性与实时性之间做取舍,最大化系统资源利用率与任务执行确定性。
9.2 2大调度体系(层级永不颠倒)
-
分时CPU体系(100~139):CFS/EEVDF调度,权重公平、无永久饥饿、适配99%普通业务、容器CPU隔离底层依赖
-
实时CPU体系(0~99):FIFO/RR/DEADLINE调度、高优先级抢占、低延迟确定性、存在优先级倒置坑点,需RT机制修复
9.3 3代分时调度演进逻辑
-
O(1):解决并发卡顿,实现恒定耗时调度,但公平性差、分时进程饥饿、代码臃肿
-
CFS:基于vruntime实现权重公平,彻底杜绝分时饥饿,成为Linux数十年主流调度方案
-
EEVDF:基于vdelay优化历史误差,更低交互式延迟、更高稳定性,新版Linux默认调度器
9.4 1个致命坑点
实时调度原生优先级倒置漏洞,需PI/PCP协议修复,是实时Linux生产故障、面试高频核心难点。
最终知识闭环:从硬件速度矛盾→进程两大特性→并发并行→上下文切换→优先级体系→三代调度演进→实时调度原理→容器隔离底层→优先级倒置坑点,完整覆盖Linux进程调度从底层硬件到上层业务的全链路核心原理,适配面试、内核学习、生产调优全场景。