本项目站内资源源代码下载地址
1. 概述
1.1 说明
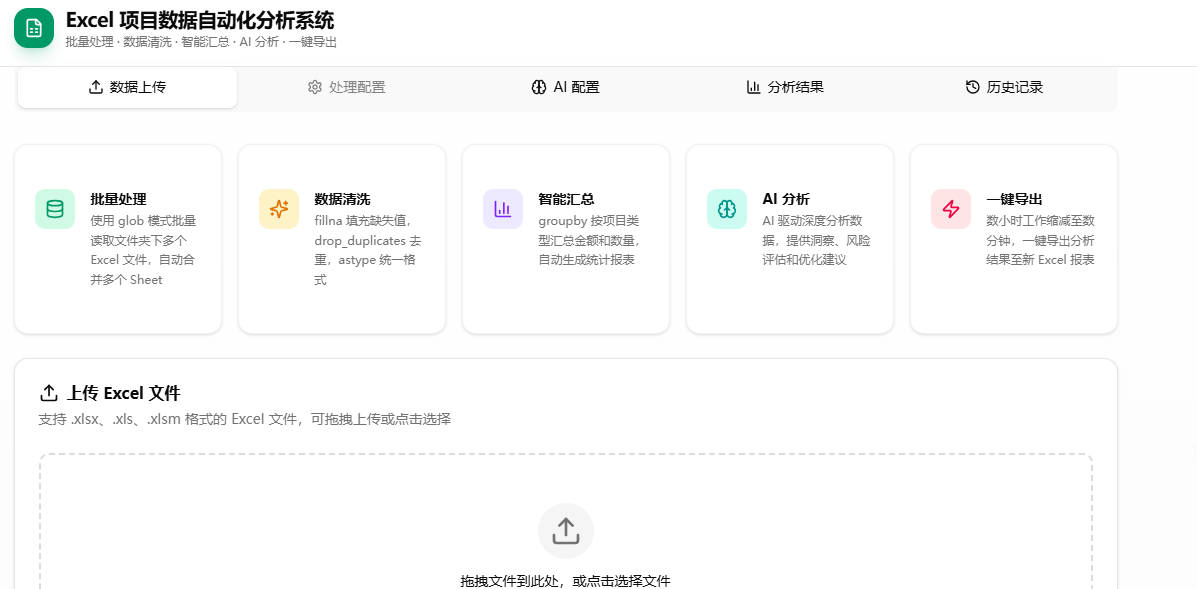
Excel 项目数据自动化分析系统是一套面向企业项目数据处理场景的全栈 Web 应用。用户上传多个 Excel 文件后,系统自动完成数据合并、清洗、去重、类型转换与分组聚合,并支持 AI 驱动的深度数据洞察,最终一键导出格式化 Excel 报表。将数小时的手工处理工作压缩至数分钟。
1.2 核心能力
| 能力模块 | 功能描述 |
|---|---|
| 批量读取 | glob 模式匹配文件夹下 .xlsx / .xls / .xlsm 文件,自动合并多 Sheet |
| 数据清洗 | fillna 缺失值填充、drop_duplicates 去重、astype 类型统一 |
| 分组汇总 | groupby 按指定列分组,支持 sum / count / mean / max / min 聚合 |
| AI 分析 | 接入 LLM 对处理结果进行综合分析、质量评估、趋势预测、风险识别 |
| 结果导出 | 多 Sheet Excel 输出,含格式化表头和冻结首行等美化处理 |
| 配置管理 | 处理规则和 AI 配置的增删改查,支持多套预设与快速切换 |
1.3 系统边界
- 输入: 用户上传的一个或多个 Excel 文件(.xlsx/.xls/.xlsm),或系统自动生成的示例数据
- 处理: 服务端通过 Python 子进程调用 pandas / openpyxl 执行数据管道
- 输出: 清洗后的数据预览、分组聚合图表、AI 分析报告、可下载的 Excel 报表
- 存储: SQLite 数据库(Prisma ORM),本地文件系统存储上传文件和导出结果
2. 架构设计
2.1 整体架构
┌──────────────────────────────────────────────────────────┐
│ 用户浏览器 │
│ ┌──────────┬──────────┬──────────┬──────────┬─────────┐ │
│ │ 上传页面 │ 配置编辑 │ AI 配置 │ 结果展示 │ 历史记录 │ │
│ └──────────┴──────────┴──────────┴──────────┴─────────┘ │
└───────────────────────┬──────────────────────────────────┘
│ HTTP / REST API
┌───────────────────────▼──────────────────────────────────┐
│ Caddy (反向代理 :81) │
│ reverse_proxy → localhost:3000 │
└───────────────────────┬──────────────────────────────────┘
│
┌───────────────────────▼──────────────────────────────────┐
│ Next.js 16 Server (Bun Runtime) │
│ ┌────────────────────────────────────────────────────┐ │
│ │ API Routes │ │
│ │ /api/upload /api/process /api/config │ │
│ │ /api/jobs /api/export /api/ai/config │ │
│ │ /api/ai/analyze │ │
│ └────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌────────────────────▼───────────────────────────────┐ │
│ │ Python Processor │ │
│ │ scripts/processor.py (child_process.execFile) │ │
│ │ pandas + openpyxl 数据处理 │ │
│ └────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌────────────────────▼───────────────────────────────┐ │
│ │ Prisma Client + SQLite │ │
│ │ db/custom.db │ │
│ └────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘2.2 请求处理流程
用户上传 Excel 文件
→ POST /api/upload
→ 保存至 upload/{uuid}/ 目录
→ 前端跳转至「处理配置」页
用户配置处理规则,点击「开始处理」
→ POST /api/process { uploadDir, configOverride }
→ 创建 ProcessingJob (status=processing)
→ 立即返回 jobId
后台异步执行
→ child_process.execFile → python3 scripts/processor.py
→ 输出 JSON 结果
→ 更新 ProcessingJob (status=completed/failed)
→ 写入 ProcessingResult
前端轮询 (2s 间隔)
→ GET /api/jobs?id={jobId}
→ 展示 stats、chart、data tables
用户触发 AI 分析
→ POST /api/ai/analyze { jobId, analysisType }
→ LLM 生成分析报告
→ 写入 ProcessingResult.aiAnalysis
→ 渲染 Markdown
用户点击导出
→ GET /api/export/{jobId}
→ 返回 result_{jobId}.xlsx3. 技术栈
3.1 前端
| 技术 | 版本 | 用途 |
|---|---|---|
| Next.js | 16.1.1 | React 全栈框架,App Router |
| React | 19.0.0 | UI 组件库 |
| TypeScript | 5.x | 类型安全 |
| Tailwind CSS | 4.x | 原子化 CSS 框架 |
| shadcn/ui | --- | Radix UI + Tailwind 组件库 |
| Zustand | 5.0.6 | 轻量级状态管理 |
| Recharts | 2.15.4 | 柱状图可视化 |
| React Markdown | 10.1.0 | Markdown 渲染 AI 分析结果 |
| Framer Motion | 12.23.2 | 动画效果 |
| Sonner | 2.0.6 | Toast 通知 |
3.2 后端(API Routes)
| 技术 | 版本 | 用途 |
|---|---|---|
| Bun | 1.3.x | JavaScript 运行时 |
| Prisma | 6.11.1 | ORM(数据库访问层) |
| SQLite | --- | 嵌入式关系型数据库 |
| z-ai-web-dev-sdk | 0.0.18 | AI LLM 集成 SDK |
| Zod | 4.0.2 | 运行时类型校验 |
| uuid | 11.1.0 | UUID 生成 |
3.3 数据处理管道
| 技术 | 版本 | 用途 |
|---|---|---|
| Python | 3.12 | 数据处理脚本运行环境 |
| pandas | 2.x | 数据读取、合并、清洗、聚合 |
| openpyxl | --- | Excel 读写与格式化美化 |
| NumPy | 2.4.6 | pandas 底层依赖 |
3.4 运行环境
| 组件 | 说明 |
|---|---|
| Caddy | 反向代理网关,监听 81 端口,支持动态端口转发 |
| 虚拟环境 | Python 3.12 venv,位于 .venv/ |
| 构建产物 | Next.js standalone 输出 + 静态资源 + 数据库 |
4. 数据库设计
本系统使用 SQLite 数据库,通过 Prisma ORM 进行访问。数据库文件路径为 db/custom.db。
4.1 ER 图
┌──────────────────┐ ┌──────────────────┐
│ ProcessingConfig │ │ AIConfig │
│──────────────────│ │──────────────────│
│ id (PK) │ │ id (PK) │
│ name │ │ name │
│ fillnaRules │ │ url │
│ dedupColumns │ │ apiKey │
│ typeMappings │ │ modelId │
│ groupbyColumn │ │ enabled │
│ groupbyAgg │ │ systemPrompt │
│ isDefault │ │ isDefault │
│ createdAt │ │ createdAt │
│ updatedAt │ │ updatedAt │
└───────┬──────────┘ └──────────────────┘
│ 1:N
│
┌───────▼──────────┐
│ ProcessingJob │
│──────────────────│
│ id (PK) │
│ configFileId (FK)│
│ status │
│ fileNames │
│ totalRows │
│ totalColumns │
│ cleanedRows │
│ dedupedRows │
│ resultSummary │
│ errorMessage │
│ createdAt │
│ updatedAt │
└───────┬──────────┘
│ 1:N
│
┌───────▼──────────┐
│ ProcessingResult │
│──────────────────│
│ id (PK) │
│ jobId (FK) │
│ sheetName │
│ rawData │
│ cleanedData │
│ aggData │
│ aiAnalysis │
│ createdAt │
└──────────────────┘4.2 模型说明
ProcessingConfig(处理配置)
存储用户自定义的数据处理规则,支持多套配置并存,isDefault 标记默认配置。
| 字段 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| id | String (CUID) | 主键 | 自动生成 |
| name | String | 配置名称 | "默认配置" |
| fillnaRules | String (JSON) | 缺失值填充规则 | {} |
| dedupColumns | String (JSON) | 去重参照列 | [] |
| typeMappings | String (JSON) | 类型转换映射 | {} |
| groupbyColumn | String | 分组列名 | "项目类型" |
| groupbyAgg | String (JSON) | 聚合函数映射 | {} |
| isDefault | Boolean | 是否默认配置 | false |
ProcessingJob(处理任务)
记录每次数据处理任务的执行状态与统计信息。
| 字段 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| id | String (CUID) | 主键 | 自动生成 |
| status | String | pending / processing / completed / failed | "pending" |
| fileNames | String (JSON) | 上传文件名列表 | [] |
| configFileId | String? | 关联配置 ID | null |
| totalRows | Int | 原始数据总行数 | 0 |
| totalColumns | Int | 原始数据列数 | 0 |
| cleanedRows | Int | 清洗后行数 | 0 |
| dedupedRows | Int | 去重删除行数 | 0 |
| resultSummary | String (JSON) | 聚合摘要 | {} |
| errorMessage | String? | 错误信息 | null |
ProcessingResult(处理结果)
保存单次处理的数据预览和 AI 分析内容,最多存储 200 行预览数据。
| 字段 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| id | String (CUID) | 主键 | 自动生成 |
| jobId | String (FK) | 关联任务 ID | --- |
| sheetName | String | Sheet 名称 | "合并数据" |
| rawData | String (JSON) | 原始数据预览 | [] |
| cleanedData | String (JSON) | 清洗后数据预览 | [] |
| aggData | String (JSON) | 聚合数据 | [] |
| aiAnalysis | String | AI 分析 Markdown 内容 | "" |
AIConfig(AI 配置)
存储 AI 服务的连接信息和行为参数。
| 字段 | 类型 | 说明 | 默认值 |
|---|---|---|---|
| id | String (CUID) | 主键 | 自动生成 |
| name | String | 配置名称 | "默认AI配置" |
| url | String | API 端点地址 | "" |
| apiKey | String | API 密钥 | "" |
| modelId | String | 模型标识符 | "" |
| enabled | Boolean | 是否启用 | true |
| systemPrompt | String | 系统提示词 | "" |
| isDefault | Boolean | 是否默认配置 | true |
JSON 字段采用 String 存储,在 API 层通过
JSON.parse/JSON.stringify进行转换。这种设计兼容了 SQLite 对 JSON 的原生支持和 Prisma 的序列化需求。
5. API 接口设计
所有接口均位于 Next.js App Router 的 /src/app/api/ 目录下,遵循 RESTful 风格。
5.1 文件上传
POST /api/upload
- Content-Type:
multipart/form-data - 参数:
files(File\[\], 必填),支持 .xlsx / .xls / .xlsm - 逻辑: 生成 UUID 子目录 → 写入文件 → 返回目录路径
- 返回:
{ success: true, uploadDir, fileNames, message }
POST /api/upload?generate-sample=true
- 参数: 无 Body
- 逻辑: 调用 Python
processor.py --generate-sample生成演示数据 - 返回:
{ success: true, uploadDir, fileNames, message }
5.2 数据处理
POST /api/process
- Content-Type:
application/json - 请求体:
json
{
"uploadDir": "string (必填)",
"configId": "string?",
"configOverride": {
"fillnaRules": { "列名": "填充值" },
"dedupColumns": ["列名"],
"typeMappings": { "列名": "float64|int64|str" },
"groupbyColumn": "分组列",
"groupbyAgg": { "列名": "sum|count|mean|max|min" }
}
}- 逻辑:
- 解析配置(DB 配置 > configOverride > 内置默认值)
- 创建 ProcessingJob(status=processing)
- 异步启动 Python 子进程(timeout 120s, maxBuffer 10MB)
- 解析 Python 输出的 JSON 结果
- 更新 Job 状态和 Result
- 返回:
{ success: true, jobId, status: "processing", message }
5.3 处理配置
GET /api/config --- 获取所有配置列表,含 jobCount
POST /api/config --- 创建新配置(支持 isDefault 互斥)
PUT /api/config?id=xxx --- 更新指定配置
DELETE /api/config?id=xxx --- 删除指定配置
5.4 任务管理
GET /api/jobs --- 获取最近任务列表(含结果和配置摘要)
GET /api/jobs?id=xxx --- 获取单个任务详情(含完整数据和 AI 分析)
5.5 结果导出
GET /api/export/{jobId}
- 校验:任务存在且 status=completed
- 返回: Excel 二进制流,Content-Type:
application/vnd.openxmlformats-officedocument.spreadsheetml.sheet - 文件名:
分析结果_{原文件名}_{日期}.xlsx
5.6 AI 配置
GET /api/ai/config --- 获取 AI 配置列表或指定配置(?id=xxx)
POST /api/ai/config --- 创建 AI 配置
PUT /api/ai/config?id=xxx --- 更新 AI 配置
DELETE /api/ai/config?id=xxx --- 删除 AI 配置
5.7 AI 分析
POST /api/ai/analyze
- 请求体:
json
{
"jobId": "string (必填)",
"analysisType": "comprehensive|quality|trend|risk|suggestion|custom",
"customQuestion": "string?"
}- 逻辑:
- 校验 job 状态(仅 completed 可分析)
- 读取启用的 AI 配置
- 构建分析上下文(数据概况 + 清洗结果 + 聚合摘要)
- 根据 analysisType 生成 system prompt + user prompt
- 调用
z-ai-web-dev-sdk获取 LLM 响应 - 写入
ProcessingResult.aiAnalysis
- 返回:
{ success: true, analysis: "...", analysisType }
分析类型
| 类型 | 英文标识 | 描述 |
|---|---|---|
| 综合分析 | comprehensive | 全面分析数据特征和规律 |
| 数据质量评估 | quality | 评估数据完整性和准确性 |
| 趋势分析 | trend | 识别变化趋势和模式 |
| 风险提示 | risk | 识别潜在风险和异常 |
| 优化建议 | suggestion | 提供配置调整和优化建议 |
| 自定义提问 | custom | 用户自定义问题 |
6. 前端设计
6.1 页面结构
系统采用单页应用(SPA)布局,顶部固定导航栏,通过 shadcn/ui Tabs 组件切换 5 个功能面板:
┌─────────────────────────────────────────────┐
│ Header: Logo + 系统标题 + 状态徽章 │
│ [上传] [处理配置] [AI配置] [分析结果] [历史]│
├─────────────────────────────────────────────┤
│ │
│ Tab 内容区(max-w-6xl, 居中) │
│ │
├─────────────────────────────────────────────┤
│ Footer: 系统信息 + 技术栈标识 │
└─────────────────────────────────────────────┘6.2 组件树
page.tsx (主页面)
├── FileUpload (上传组件)
│ ├── 拖拽上传区域 (Drag & Drop)
│ ├── 待上传文件列表 (含大小/格式/删除)
│ ├── 上传进度条
│ ├── 已上传文件列表
│ └── 操作按钮(上传/生成示例/开始分析)
├── ConfigEditor (处理配置编辑器)
│ ├── 配置名称 + 保存/加载/开始处理
│ ├── 填充缺失值编辑器(动态 key-value)
│ ├── 去重规则编辑器(动态列表)
│ ├── 类型转换编辑器(列→类型下拉)
│ └── 分组汇总编辑器(分组列 + 聚合规则)
├── AIConfigEditor (AI 配置编辑器)
│ ├── 启用/禁用状态横幅
│ ├── 连接设置(URL + API Key + Model ID)
│ ├── 系统提示词编辑
│ └── 默认配置开关 + 连接测试
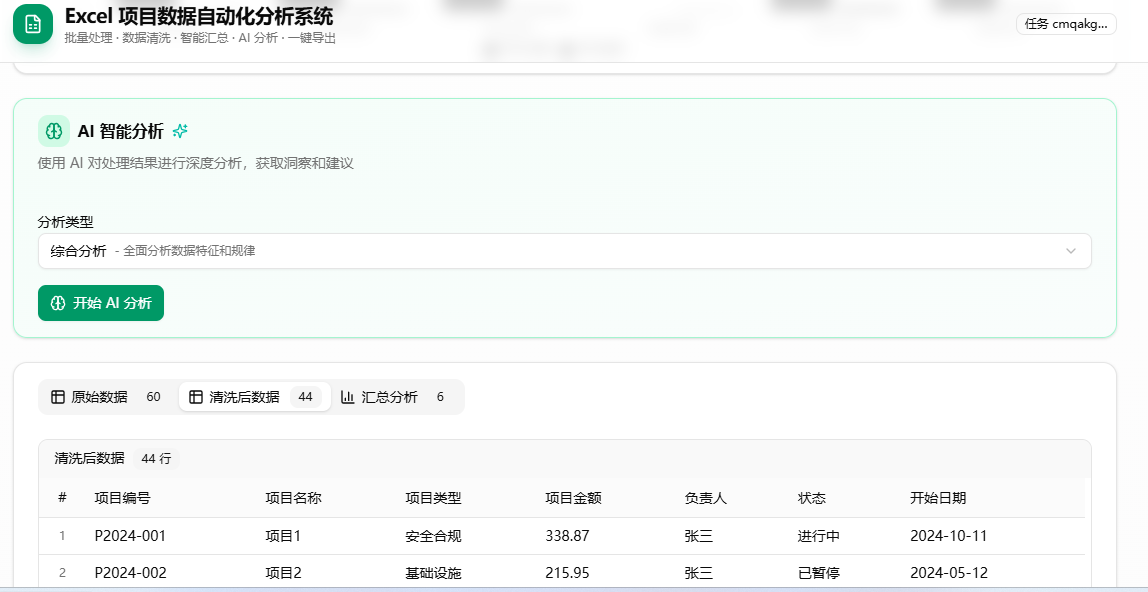
├── ResultsViewer (结果查看器)
│ ├── 处理状态展示
│ │ ├── Loading 动画 (处理中)
│ │ ├── Error 展示 (失败)
│ │ └── Empty 状态 (未选择)
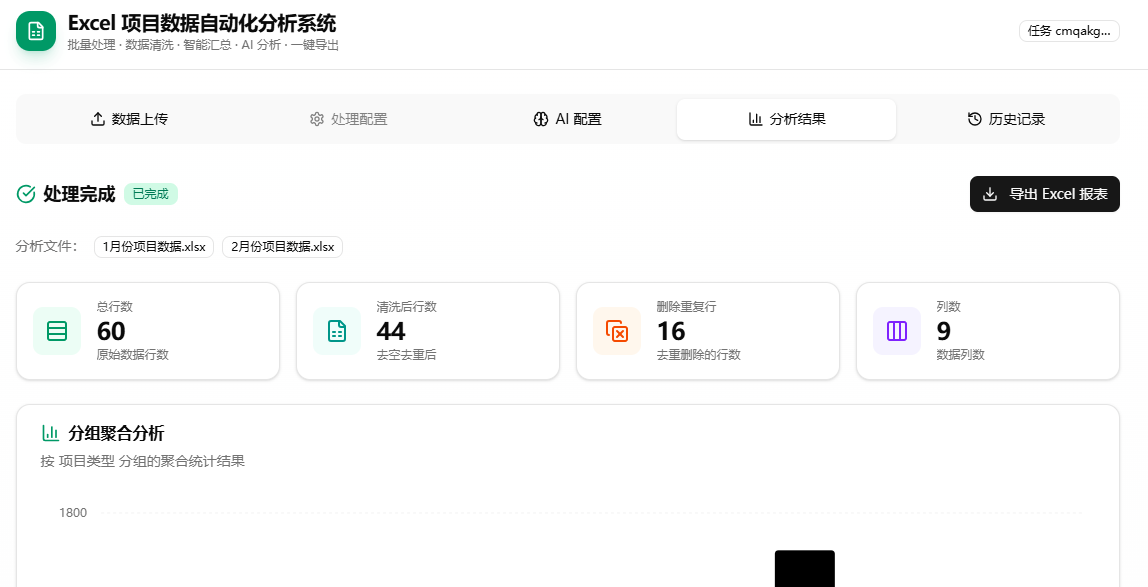
│ ├── 统计卡片 (总行数/清洗后/去重/列数)
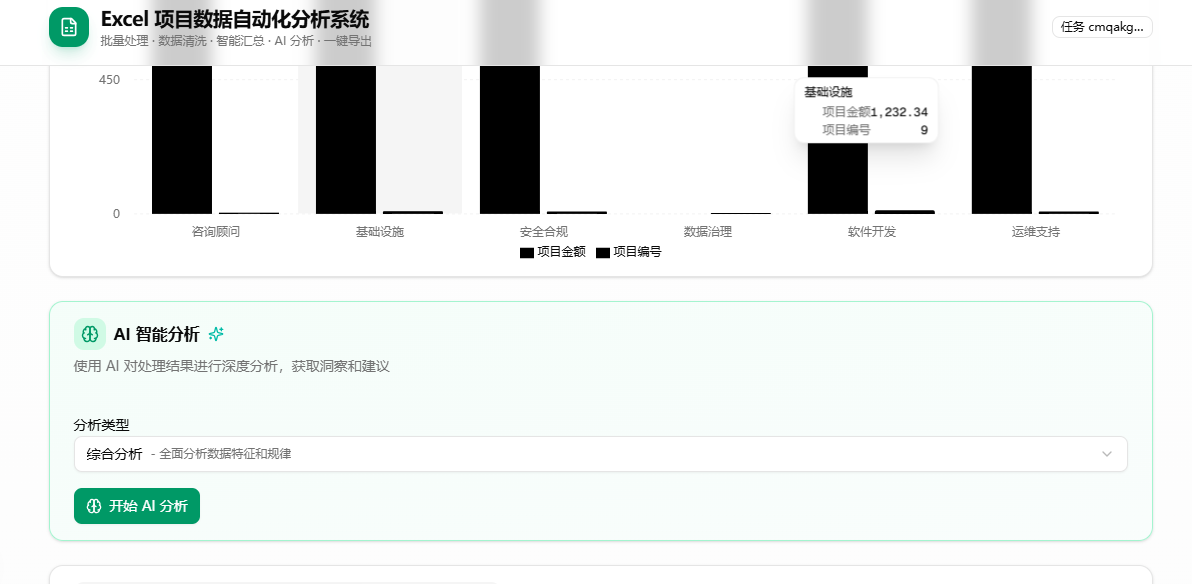
│ ├── 柱状图 (Recharts BarChart)
│ ├── AIAnalysisPanel (AI 分析面板)
│ │ ├── 分析类型选择(6 种)
│ │ ├── 自定义问题输入
│ │ ├── 分析结果 Markdown 渲染
│ │ └── 加载/重新分析状态
│ └── 数据表 Tabs (原始/清洗/汇总)
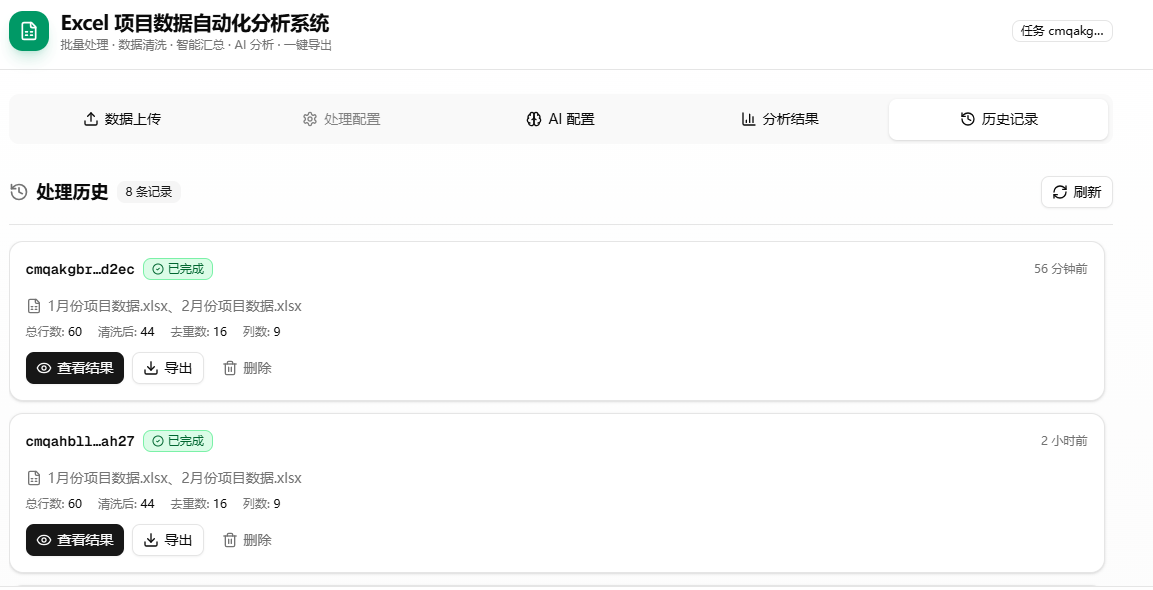
└── HistoryList (历史记录列表)
├── 任务卡片列表
├── 状态徽章 (pending/processing/completed/failed)
├── 时间戳(相对时间格式)
└── 操作按钮(查看结果/导出)6.3 状态管理(Zustand Store)
使用 Zustand 实现全局状态管理,/src/lib/store.ts 包含以下核心状态:
| 状态域 | 字段 | 类型 | 说明 |
|---|---|---|---|
| 上传 | uploadedFiles | string\[\] | 已上传文件名列表 |
| 上传 | uploadDir | string? | 文件存储目录 |
| 上传 | isUploading | boolean | 上传进行中 |
| 配置 | currentConfig | ProcessingConfigType? | 当前处理配置 |
| AI 配置 | aiConfig | AIConfigType? | 当前 AI 配置 |
| 处理 | isProcessing | boolean | 处理进行中 |
| 处理 | currentJobId | string? | 当前任务 ID |
| AI 分析 | aiAnalysis | string? | AI 分析内容 |
| AI 分析 | isAnalyzing | boolean | AI 分析进行中 |
| 导航 | activeTab | string | 当前活动标签 |
6.4 UI 设计要点
- 配色: 以 Emerald(翠绿)为主色调,Teal 为 AI 相关辅色,各功能区使用差异化色系(Amber=清洗、Violet=转换、Blue=去重、Rose=导出)
- 响应式 : 所有组件支持移动端,通过
sm:/lg:断点适配 - 暗色模式 : 全面支持 Tailwind
dark:类 - 交互反馈: Sonner Toast 通知所有操作结果,处理中显示动画加载状态
- 轮询机制: 结果页 2s 间隔轮询,历史页 10s 间隔轮询(仅在有活跃任务时)
7. 数据处理管道
7.1 Python 脚本结构
scripts/processor.py 是实现核心数据逻辑的独立 Python 脚本,通过 child_process.execFile 由 Node.js 端调用。脚本采用命令行参数驱动设计:
python3 processor.py
--input-dir ./upload/{uuid}/
--output ./download/result_{jobId}.xlsx
--config '{"fillnaRules":{"项目金额":0},"dedupColumns":["项目编号"],...}'7.2 处理管道步骤
┌─────────────────────────────────────────────┐
│ Step 1: batch_read_excel(input_dir) │
│ - glob 扫描 *.xlsx, *.xls, *.xlsm │
│ - 逐文件读取所有 Sheet │
│ - 添加 __来源文件__, __来源Sheet__ 标记列 │
│ - pd.concat 合并 │
├─────────────────────────────────────────────┤
│ Step 2: clean_data(df, config) │
│ - fillna: 按 fillnaRules 填充指定列缺失值 │
│ - drop_duplicates: 按 dedupColumns 去重 │
│ - astype: 按 typeMappings 转换列类型 │
│ - 返回 (cleaned_df, stats) │
├─────────────────────────────────────────────┤
│ Step 3: aggregate_data(df, config) │
│ - groupby(groupbyColumn) │
│ - agg(groupbyAgg) │
│ - 生成分组摘要 │
├─────────────────────────────────────────────┤
│ Step 4: export_to_excel(output_path, ...) │
│ - Sheet 1: 清洗后数据 │
│ - Sheet 2: 汇总分析 │
│ - Sheet 3: 处理统计 │
│ - openpyxl 美化:表头字体/颜色/边框/冻结/列宽 │
├─────────────────────────────────────────────┤
│ 输出: JSON 结果到 stdout │
│ { success, stats, summary, preview, columns }│
└─────────────────────────────────────────────┘7.3 数据转换规则
| 配置项 | Python 实现 | 说明 |
|---|---|---|
| fillnaRules | df[col].fillna(value) |
支持数值和字符串填充 |
| dedupColumns | df.drop_duplicates(subset=cols) |
keep='first' |
| typeMappings (float64) | pd.to_numeric(col, errors='coerce') |
失败值用 fillna 规则填充 |
| typeMappings (int64) | pd.to_numeric(col).astype('Int64') |
支持空值 Integer |
| typeMappings (str) | df[col].astype(str) |
--- |
| groupbyAgg | df.groupby(col).agg(dict) |
支持 sum/count/mean/max/min |
7.4 错误处理
- 文件读取异常: 打印警告至 stderr,跳过该文件继续处理
- 类型转换异常: 打印警告,继续执行
- 配置 JSON 解析失败: 退出并返回 error 信息
- 整体异常: 通过 traceback 捕获,以结构化 JSON 返回
8. AI 智能分析模块
8.1 集成架构
ResultsViewer (前端)
→ POST /api/ai/analyze { jobId, analysisType, customQuestion }
→ 读取 AIConfig (默认/enabled)
→ 构建分析上下文 (data_stats + config + preview_data)
→ 构建 Prompt (system + user)
→ ZAI SDK → LLM API
← Markdown 分析结果
→ 写入 ProcessingResult.aiAnalysis
→ 前端 ReactMarkdown 渲染8.2 Prompt 设计
System Prompt(用户可自定义覆盖):
你是一位资深的项目数据分析师,专注于 Excel 项目数据的分析与优化建议。你需要基于提供的数据处理结果,给出专业、可操作的分析结论和调整建议。
分析应包含:
- 数据质量评估
- 关键发现
- 趋势分析
- 风险提示
- 优化建议
分析上下文 (由 buildAnalysisContext 构建):
## 数据处理概况
- 分析文件: [文件名列表]
- 原始数据总行数/列数/清洗后行数/删除重复行数
## 处理配置
{ fillnaRules, dedupColumns, typeMappings, groupbyColumn, groupbyAgg }
## 清洗后数据预览 (前10行)
[JSON 数据]
## 汇总分析结果
[JSON 聚合数据]
## 处理统计摘要
[JSON 统计信息]8.3 分析类型 Prompt 映射
| 类型 | User Prompt 前缀 |
|---|---|
| comprehensive | 请对以下项目数据进行全面深入的分析... |
| quality | 请重点分析数据质量,评估完整性和可靠性... |
| trend | 请重点分析数据趋势和模式... |
| risk | 请重点识别风险和异常... |
| suggestion | 请重点给出处理配置的优化建议... |
| custom | 用户自定义问题 |
9. 构建与部署
9.1 开发环境
前置要求:
- Bun >= 1.3.x
- Python 3.12 + venv
- 系统依赖: 无额外要求
启动步骤:
bash
# 1. 安装 Node.js 依赖
bun install
# 2. 生成 Prisma Client 并推送数据库
bun run db:push
bun run db:generate
# 3. 安装 Python 依赖(如首次运行)
python3 -m venv .venv
source .venv/bin/activate
pip install pandas openpyxl --break-system-packages
# 4. 启动开发服务器
bun run dev
# 访问 http://localhost:30009.2 生产构建
bash
# 方式一:标准化构建脚本
sh .zscripts/build.sh
# 方式二:手动构建
bun run build构建脚本流程:
bun install--- 安装依赖bun run build--- Next.js standalone 构建- 复制
.next/standalone+.next/static+public→next-service-dist/ - 复制并推送数据库至构建产物
- 打包为
.tar.gz
构建产物结构:
/tmp/build_fullstack_{BUILD_ID}/
├── next-service-dist/ # Next.js standalone 输出
│ ├── server.js
│ ├── .next/static/
│ └── public/
├── db/
│ └── custom.db # 生产数据库
├── Caddyfile # 反向代理配置
├── start.sh # 启动脚本
└── mini-services-start.sh (可选)9.3 生产部署
启动服务:
bash
# 解压构建包
tar xzf build_fullstack_{BUILD_ID}.tar.gz -C /app/
cd /app
# 启动所有服务(Next.js + Caddy)
sh start.shstart.sh 行为:
- 设置环境变量
NODE_ENV=production,PORT=3000,DATABASE_URL - 后台启动
bun server.js(Next.js standalone) - 前台启动
caddy run --config Caddyfile(作为主进程)
9.4 反向代理配置(Caddyfile)
:81 {
@transform_port_query { query XTransformPort=* }
handle @transform_port_query {
reverse_proxy localhost:{query.XTransformPort}
}
handle {
reverse_proxy localhost:3000
}
}- 默认将 81 端口请求代理到 localhost:3000
- 支持通过
?XTransformPort=xxxx动态转发至其他端口,便于与其他微服务共存
9.5 环境变量
| 变量 | 说明 | 默认值 |
|---|---|---|
| DATABASE_URL | SQLite 数据库路径 | file:/home/z/my-project/db/custom.db |
| PORT | Next.js 服务端口 | 3000 |
| HOSTNAME | 绑定地址 | 0.0.0.0 |
| NODE_ENV | 运行环境 | production(生产) |
9.6 目录权限与数据持久化
upload/: 上传文件临时存储,按 UUID 子目录隔离download/: 导出 Excel 结果存储,按 jobId 命名db/custom.db: SQLite 数据库,需确保读写权限- 生产部署时
upload/和download/建议挂载持久化存储或定期清理
10. 目录结构
project-root/
├── .env # 环境变量(DATABASE_URL)
├── .gitignore # Git 忽略规则
├── .zscripts/ # 构建与启动脚本
│ ├── build.sh # 生产构建脚本
│ ├── start.sh # 生产启动脚本
│ ├── dev.sh # 开发环境启动
│ ├── mini-services-build.sh # 微服务构建
│ ├── mini-services-install.sh # 微服务依赖安装
│ └── mini-services-start.sh # 微服务启动
├── Caddyfile # Caddy 反向代理配置
├── next.config.ts # Next.js 配置(standalone 输出)
├── package.json # 项目依赖与脚本
├── tsconfig.json # TypeScript 配置
├── tailwind.config.ts # Tailwind CSS 配置
├── components.json # shadcn/ui 配置
├── bun.lock # Bun 依赖锁文件
├── eslint.config.mjs # ESLint 配置
├── postcss.config.mjs # PostCSS 配置
├── prisma/
│ └── schema.prisma # Prisma 数据模型定义
├── scripts/
│ └── processor.py # Python 数据处理管道
├── db/
│ └── custom.db # SQLite 数据库文件
├── upload/ # 上传文件存储(按 UUID 子目录)
├── download/ # 导出 Excel 结果存储
├── public/ # 静态资源
│ ├── logo.svg
│ └── robots.txt
├── agent-ctx/ # AI Agent 上下文文件
│ ├── 5-backend-api-builder.md
│ ├── 7-a-file-upload-component-builder.md
│ ├── 7-c-results-viewer-builder.md
│ ├── 7-d-history-list-builder.md
│ └── 8-ai-config-editor-builder.md
├── src/
│ ├── app/
│ │ ├── layout.tsx # 根布局
│ │ ├── page.tsx # 主页面
│ │ ├── globals.css # 全局样式
│ │ └── api/
│ │ ├── route.ts # 健康检查
│ │ ├── upload/route.ts # 文件上传 API
│ │ ├── process/route.ts # 数据处理 API
│ │ ├── config/route.ts # 配置 CRUD API
│ │ ├── jobs/route.ts # 任务查询 API
│ │ ├── export/
│ │ │ └── [jobId]/
│ │ │ └── route.ts # 结果导出 API
│ │ └── ai/
│ │ ├── config/
│ │ │ └── route.ts # AI 配置 CRUD API
│ │ └── analyze/
│ │ └── route.ts # AI 分析 API
│ ├── components/
│ │ ├── file-upload.tsx # 文件上传组件
│ │ ├── config-editor.tsx # 处理配置编辑器
│ │ ├── ai-config-editor.tsx # AI 配置编辑器
│ │ ├── results-viewer.tsx # 结果查看器(含 AI 面板)
│ │ ├── history-list.tsx # 历史记录列表
│ │ └── ui/ # shadcn/ui 组件库
│ │ ├── button.tsx, card.tsx, table.tsx, tabs.tsx
│ │ ├── input.tsx, select.tsx, textarea.tsx
│ │ ├── badge.tsx, progress.tsx, separator.tsx
│ │ ├── dialog.tsx, dropdown-menu.tsx
│ │ ├── switch.tsx, toggle.tsx
│ │ ├── chart.tsx, scroll-area.tsx, accordion.tsx
│ │ └── ... (40+ 组件)
│ ├── lib/
│ │ ├── db.ts # Prisma Client 单例
│ │ ├── store.ts # Zustand 全局状态
│ │ └── utils.ts # 工具函数
│ └── hooks/
│ ├── use-mobile.ts # 移动端检测
│ └── use-toast.ts # Toast Hook
├── examples/
│ └── websocket/ # WebSocket 示例
│ ├── frontend.tsx
│ └── server.ts
├── tool-results/ # 构建工具输出
└── worklog.md # 开发工作记录附录
A. Python 脚本命令行参考
bash
# 生成示例数据
python3 scripts/processor.py --generate-sample --sample-dir ./upload/demo/
# 执行数据处理
python3 scripts/processor.py \
--input-dir ./upload/demo/ \
--output ./download/result.xlsx \
--config '{"fillnaRules":{"项目金额":0},"dedupColumns":["项目编号"],"typeMappings":{"项目金额":"float64"},"groupbyColumn":"项目类型","groupbyAgg":{"项目金额":"sum","项目编号":"count"}}'