文章目录
- [1. 哈希的概念](#1. 哈希的概念)
-
- [1.1 直接定址法](#1.1 直接定址法)
- [1.2 哈希冲突](#1.2 哈希冲突)
- [1.3 负载因子](#1.3 负载因子)
- [1.4 将关键字转为整数](#1.4 将关键字转为整数)
- [1.5 哈希函数](#1.5 哈希函数)
-
- [1.5.1 除法散列法/除留余数法](#1.5.1 除法散列法/除留余数法)
- [1.6 处理哈希冲突](#1.6 处理哈希冲突)
-
- [1.6.1 开放地址法](#1.6.1 开放地址法)
- [1.6.2 开放地址法实现](#1.6.2 开放地址法实现)
- [1.6.3 扩容](#1.6.3 扩容)
- [1.6.4 实现字符串储存](#1.6.4 实现字符串储存)
- [1.6.5 链地址法](#1.6.5 链地址法)
- [1.6.6 两种方法代码实现](#1.6.6 两种方法代码实现)

1. 哈希的概念
哈希 (hash) 又称散列,是一种组织数据的方式。从译名来看,有散乱排列的意思。本质就是通过哈希函数把关键字 Key 跟存储位置建立一个映射关系,查找时通过这个哈希函数计算出 Key 存储的位置,进行快速查找。
1.1 直接定址法
直接定址法是最基础的哈希函数实现方式,核心逻辑是:用关键字本身或对关键字做简单的线性运算(比如加减一个固定偏移量),直接算出数组下标,建立关键字和存储位置的一一映射。
它的特点是完全没有哈希冲突、访问效率极高,但仅适用于关键字取值范围连续且集中的场景,不适合范围大、分布零散的数据。
例:比如一组关键字都在 0,99 之间,那么我们开一个 100 个数的数组,每个关键字的值直接就是存储位置的下标。再比如一组关键字值都在 a,z 的小写字母,那么我们开一个 26 个数的数组,每个关键字 ASCII 码 - a 的 ASCII 码就是存储位置的下标。也就是说直接定址法本质就是用关键字计算出一个绝对位置或者相对位置。
cpp
#include <stdio.h>
int main() {
// 关键字范围:0~99,数组长度设为100
int count[100] = {0};
int nums[] = {5, 12, 5, 37, 12, 5, 99};
int n = sizeof(nums) / sizeof(nums[0]);
// 直接定址法:Key直接作为下标
for (int i = 0; i < n; i++) {
int key = nums[i];
count[key]++;
}
// 输出结果
printf("数字出现次数:\n");
for (int i = 0; i < 100; i++) {
if (count[i] > 0) {
printf("%d: %d次\n", i, count[i]);
}
}
return 0;
}1.2 哈希冲突
直接定址法的缺点也非常明显,当关键字的范围比较分散时,就很浪费内存甚至内存不够用。假设我们只有数据范围是0,9999的N个值,我们要映射到一个M个空间的数组中(一般情况下M >= N),那么就要借助哈希函数(hash function)hf,关键字key被放到数组的h(key)位置,这里要注意的是h(key)计算出的值必须在[0, M)之间。
这里存在的一个问题就是,两个不同的key可能会映射到同一个位置去,这种问题我们叫做哈希冲突,或者哈希碰撞。理想情况是找出一个好的哈希函数避免冲突,但是实际场景中,冲突是不可避免的,所以我们尽可能设计出优秀的哈希函数,减少冲突的次数,同时也要去设计出解决冲突的方案。
1.3 负载因子
假设哈希表中已经映射存储了N个值,哈希表的大小为M,那么 负载因子 = N / M,负载因子有些地方也翻译为载荷因子/装载因子等,它的英文为load factor。负载因子越大,哈希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;
1.4 将关键字转为整数
我们将关键字映射到数组中位置,一般是整数好做映射计算,如果不是整数,我们要想办法转换成整数,这个细节我们后面代码实现中再进行细节展示。下面哈希函数部分我们讨论时,如果关键字不是整数,那么我们讨论的Key是关键字转换成的整数。
1.5 哈希函数
一个好的哈希函数应该让N个关键字被等概率地均匀地散列分布到哈希表的M个空间中,但是实际中却很难做到,但是我们要尽量往这个方向去考量设计。
1.5.1 除法散列法/除留余数法
除法散列法,又称除留余数法 ,是最经典、最常用的哈希函数构造方法。
其核心公式为:
h ( k e y ) = k e y % M h(key) = key \% M h(key)=key%M
其中:
- k e y key key:待映射的关键字(需为整数)
- M M M:哈希表的长度
- h ( k e y ) h(key) h(key):关键字在哈希表中的映射下标,范围 0 , M − 1 0, M-1 0,M−1
-
M M M 的取值禁忌
应避免将 M M M 设为 2 x 2^x 2x(2的幂)或 10 x 10^x 10x(10的幂):
- 若 M = 2 x M=2^x M=2x,取模运算等价于只保留 k e y key key 的低 x x x 位,高位信息丢失,容易因低 x x x 位相同导致冲突。例如 M = 16 ( 2 4 ) M=16(2^4) M=16(24) 时, 63 ( 00111111 ) 63(00111111) 63(00111111) 和 31 ( 00011111 ) 31(00011111) 31(00011111) 的低4位均为
1111,哈希值均为15。 - 若 M = 10 x M=10^x M=10x,则仅保留 k e y key key 的低 x x x 位十进制数字,同样容易因低位重复引发冲突。例如 M = 100 ( 10 2 ) M=100(10^2) M=100(102) 时, 112 112 112 和 12312 12312 12312 的低2位均为
12,哈希值均为12。
- 若 M = 2 x M=2^x M=2x,取模运算等价于只保留 k e y key key 的低 x x x 位,高位信息丢失,容易因低 x x x 位相同导致冲突。例如 M = 16 ( 2 4 ) M=16(2^4) M=16(24) 时, 63 ( 00111111 ) 63(00111111) 63(00111111) 和 31 ( 00011111 ) 31(00011111) 31(00011111) 的低4位均为
-
推荐取值
多数数据结构教材建议,将 M M M 取为不太接近2的整数次幂的质数,能显著降低冲突概率。
cpp
#include <stdio.h>
// 除留余数法哈希函数
int hash(int key, int table_size) {
return key % table_size;
}
int main() {
int table_size = 13; // 选用质数,降低冲突概率
int keys[] = {10, 23, 36, 49, 62};
int n = sizeof(keys) / sizeof(keys[0]);
for (int i = 0; i < n; i++) {
int idx = hash(keys[i], table_size);
printf("key = %d → 下标 = %d\n", keys[i], idx);
}
return 0;
}1.6 处理哈希冲突
这里我们说两种方法:开放定址法,链地址法
1.6.1 开放地址法
这里给张图展示:
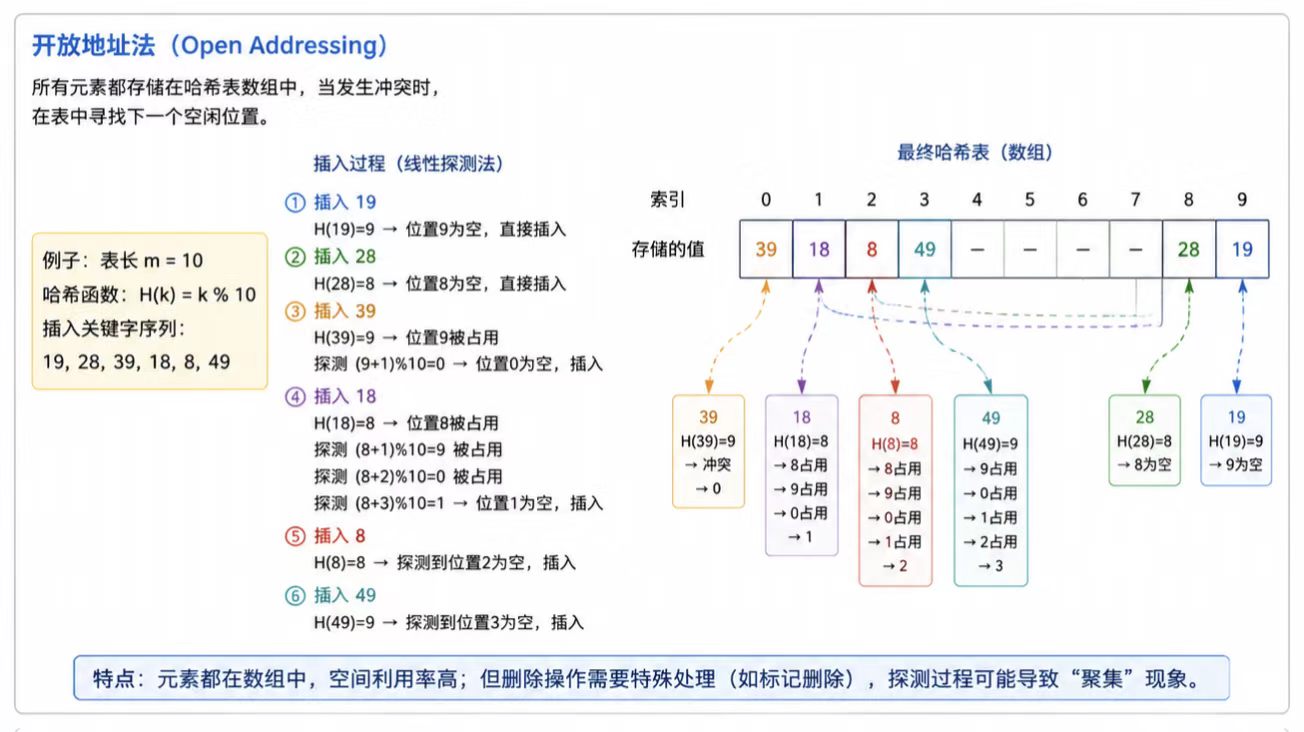
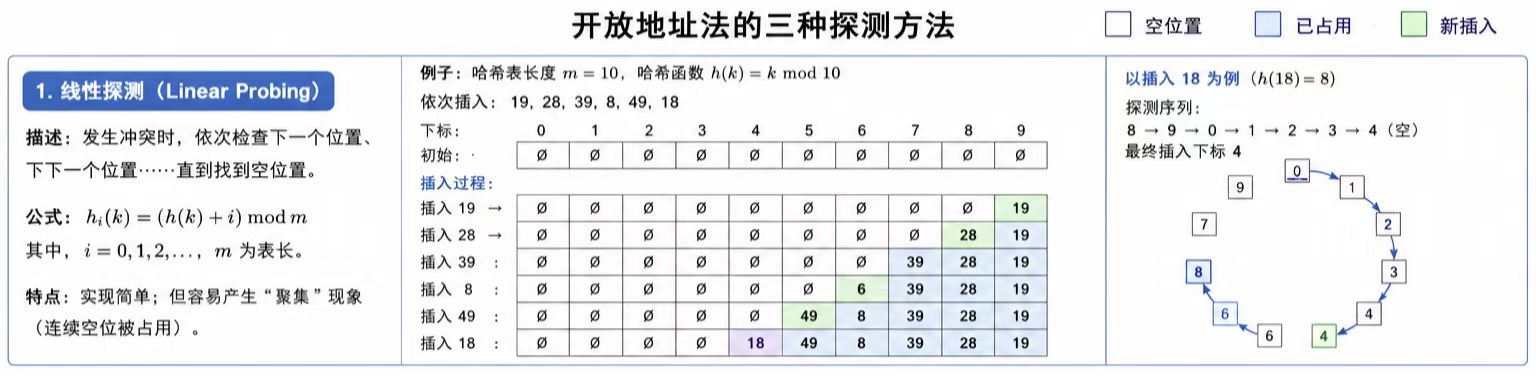
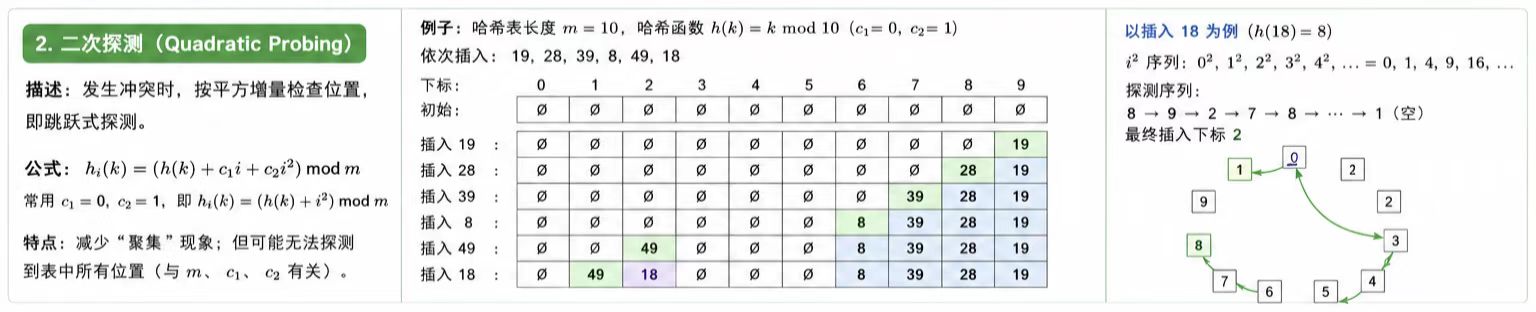
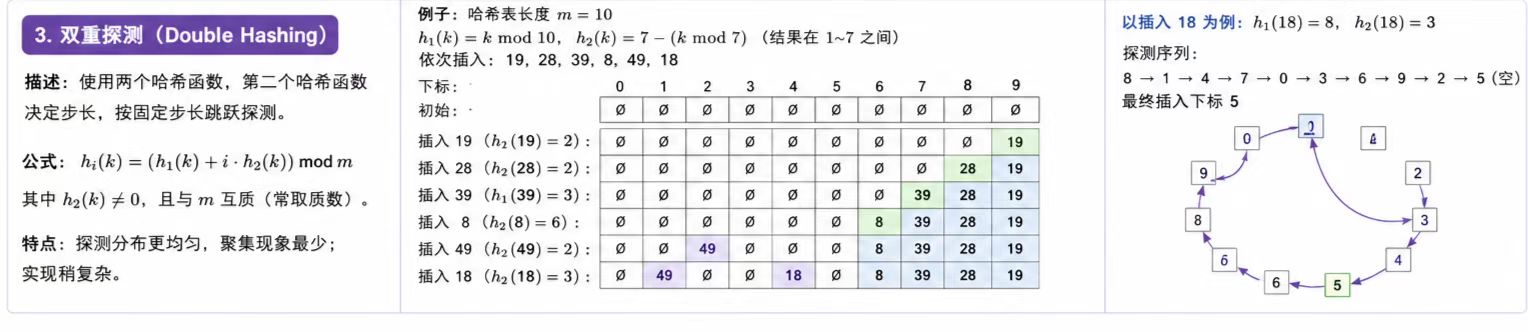
这里的探测主要有三种:
线性探测,二次探测,双重探测
1.6.2 开放地址法实现
先给个哈希表结构:
cpp
enum State
{
EXIST,
EMPTY,
DELETE
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY;
};
template<class K, class V>
class HashTable
{
private:
vector<HashData<K, V>> _tables;
size_t _n = 0; // 表中存储数据个数
};这里给_tables加了个State状态。
便于增删查改。
1.6.3 扩容
扩容 :
先给个函数:
cpp
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}这是 SGI STL 哈希表配套的获取下一个质数函数。哈希表扩容要求容量为质数(减少哈希冲突),此函数专门用来获取大于等于当前容量的最小质数,替代简单的 2 倍扩容。
哈希表负载因子达到 0.7 触发扩容时,调用该函数拿到新质数容量,再将旧表数据重新哈希映射到新表,保证哈希表容量始终为质数,降低冲突概率。
为什么取质数?
哈希表容量选择质数,是因为除留余数法中,合数容量容易与关键字产生公因数,导致哈希结果扎堆、冲突增多、分布不均,而质数仅有1和自身两个因数,能最大程度避免关键字集中映射,让哈希下标均匀分布,从而大幅减少哈希冲突。
1.6.4 实现字符串储存
cpp
#include <string>
#include <vector>
using namespace std;
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
// 字符串哈希函数特化(BKDR哈希)
template<>
struct HashFunc<string>
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto e : key)
{
hash *= 131;//BKDR哈希,感兴趣可以去看看
hash += e;
}
return hash;
}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
private:
vector<HashData<K, V>> _tables;
size_t _n = 0; // 表中存储数据个数
};字符串、日期等非整型类型无法直接取模,因此引入哈希仿函数统一将关键字转为整型;默认仿函数直接转换整型关键字,针对字符串做模板特化,采用 BKDR 哈希算法,让每个字符都参与运算,降低哈希冲突。
核心要点简释
- 普通整型key:使用默认仿函数,直接强转为
size_t参与取模。 - 字符串key:不能简单累加ASCII码(易冲突),改用BKDR哈希,通过乘以质数131叠加字符值,让不同字符串尽量生成不同整型哈希值。
- 哈希表模板增加哈希仿函数模板参数,支持不同类型key自定义哈希规则。
1.6.5 链地址法
先看图:
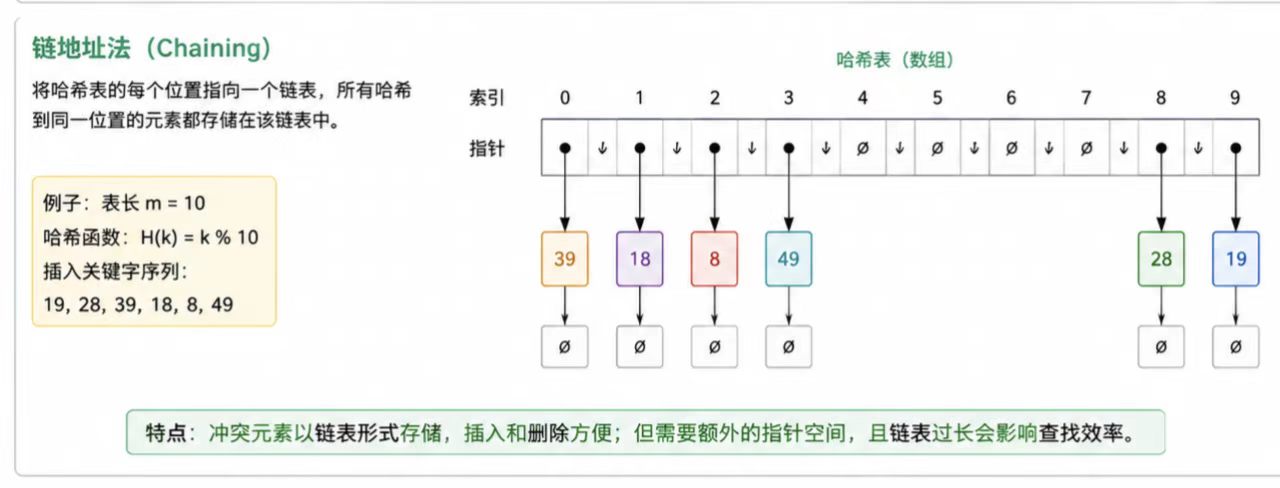
扩容
开放定址法负载因子必须小于 1,链地址法的负载因子就没有限制了,可以大于 1。负载因子越大,哈希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;STL 中unordered_xxx的最大负载因子基本控制在 1,大于 1 就扩容,我们下面实现也使用这个方式。
1.6.6 两种方法代码实现
cpp
#pragma once
#include"HashTable.h"
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
enum State
{
EXIST,
EMPTY,
DELETE
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY;
};
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash += ch;
hash *= 131;
}
return hash;
}
};
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] = {
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
//开放地址法
namespace open_address
{
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
private:
vector<HashData<K, V>> _tables;
size_t _n;
public:
HashTable()
:_tables(__stl_next_prime(0))
, _n(0)
{
}
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first))
return false;
if (_n * 10 / _tables.size() >= 7)
{
HashTable<K, V, Hash> newht;
newht._tables.resize(__stl_next_prime(_tables.size() + 1));
for (auto& data : _tables)
{
if (data._state == EXIST)
newht.Insert(data._kv);
}
_tables.swap(newht._tables);
}
Hash hash;
size_t hash0 = hash(kv.first) % _tables.size();
size_t hashi = hash0;
size_t i = 1;
while (_tables[hashi]._state == EXIST)
{
hashi = (hash0 + i) % _tables.size();
i++;
}
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
++_n;
return true;
}
HashData<K, V>* Find(const K& key)
{
Hash hash;
size_t hash0 = hash(key) % _tables.size();
size_t hashi = hash0;
size_t i = 1;
while (_tables[hashi]._state != EMPTY)
{
if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key)
{
return &_tables[hashi];
}
hashi = (hash0 + i) % _tables.size();
++i;
}
return nullptr;
}
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret)
{
ret->_state = DELETE;
return true;
}
return false;
}
};
}
//链地址法
namespace hash_bucket
{
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K, V>& kv)
:_kv(kv)
, _next(nullptr)
{
}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
HashTable()
:_tables(11)
, _n(0)
{
}
bool Insert(const pair<K, V>& kv)
{
if (_n == _tables.size())
{
vector<Node*> newTable(_tables.size() * 2);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = cur->_kv.first % newTable.size();
cur->_next = newTable[hashi];
newTable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTable);
}
size_t hashi = kv.first % _tables.size();
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return true;
}
private:
vector<Node*> _tables;
size_t _n;
};
}