在普通程序里,文字首先只是字符串。字符串可以做精确匹配,却很难直接回答"这两句话是不是在说同一件事"。 例如,"怎样重置登录密码"和"我忘记密码了"几乎没有相同词汇,但人一眼就能看出它们高度相关。
Embedding model 做的事,是把一段文本编码成一组浮点数,也就是一个高维 vector。 这些数字单独看没有直观含义,放到同一个 vector space 中之后,距离较近的文本通常具有更接近的语义。 因此,程序不再只比较字面,而是可以比较"意思"。
Embeddings 的价值不在于生成新文字,而在于把原本难以计算的语义关系,变成可以排序、聚类和检索的数值关系。
文本输入
句子、段落、FAQ、商品说明、代码函数,甚至类别名称。
Embedding model
把输入映射到固定长度的高维 vector,而不是输出自然语言。
数值输出
得到浮点数数组,之后可用于 similarity、nearest neighbor 或 ML feature。
别把 embedding 当成文本摘要。 它不是一段可以还原成人话的压缩文本,也不适合直接展示给用户。它是一种便于机器比较的语义表示。
官方列出的典型用途
OpenAI 文档把常见用途归纳为 Search、Clustering、Recommendations、Anomaly detection、 Diversity measurement 和 Classification。它们的共同点是:先把对象放进同一个 vector space, 再根据距离或相似度作判断。
如何调用 Embeddings API
调用方式并不复杂:向 embeddings endpoint 发送 input 和模型名称, API 返回的 data[0].embedding 就是 vector。API key 应放在服务端环境变量中, 不要写进公开网页或提交到 Git 仓库。
python
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-3-small",
input="肝脏肿瘤分割需要利用器官区域先验",
encoding_format="float"
)
vector = response.data[0].embedding
print(len(vector))
print(vector[:8])返回值里真正需要看的内容
{ "object": "list", "data": { "object": "embedding", "index": 0, "embedding": \[-0.0069, -0.0053, -0.00004, ... }], "model": "text-embedding-3-small", "usage": { "prompt_tokens": 18, "total_tokens": 18 } }
embedding 是需要保存和检索的 vector;usage 反映本次 input 消耗的 token。 Embeddings 按 input token 计费,而不是按输出文字计费。
语义检索是怎么跑起来的
很多人第一次接触 Embeddings,是为了做知识库、站内搜索或 RAG。关键不是每次搜索时把所有文档重新交给模型, 而是把"文档建库"和"用户查询"拆成两个阶段。

文档入库时,每个 chunk 通常会同时保存原文、来源、标题、权限、时间等 metadata。 查询时只需为 query 生成一次 embedding,再到 vector database 中寻找最接近的若干条记录。 这一步拿到的是"相关材料",而不是最终答案。
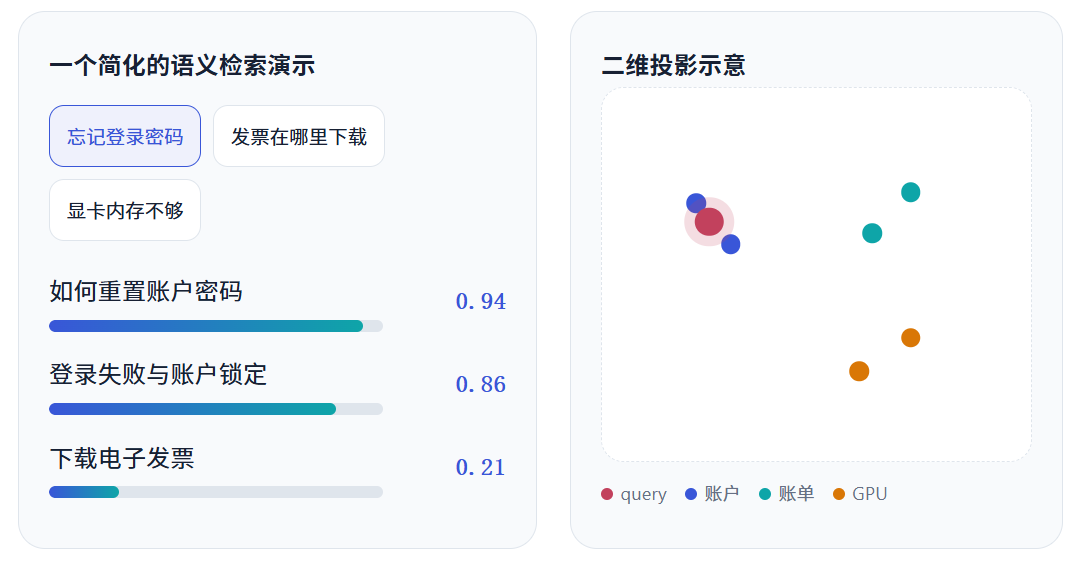
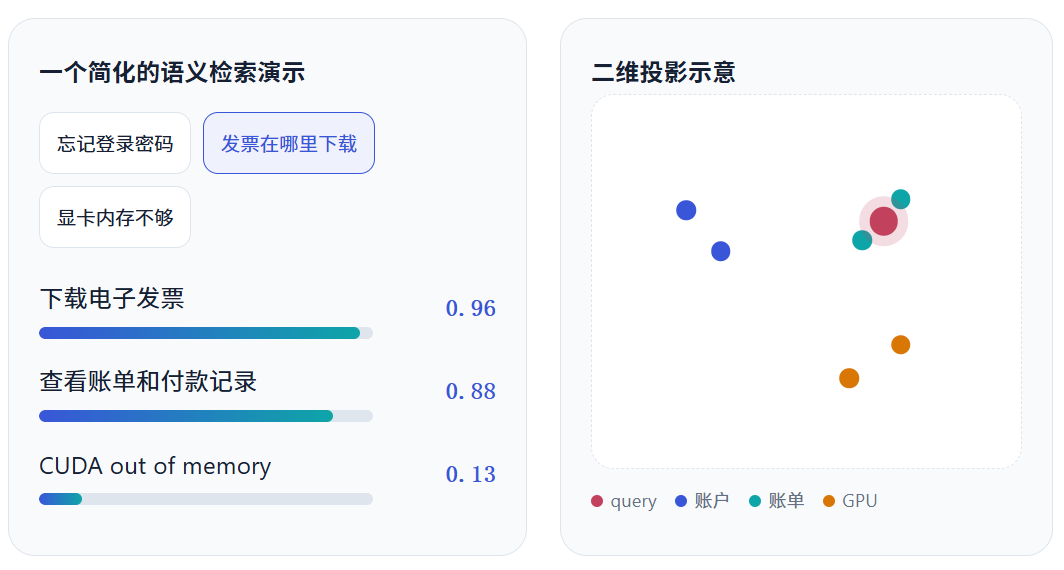
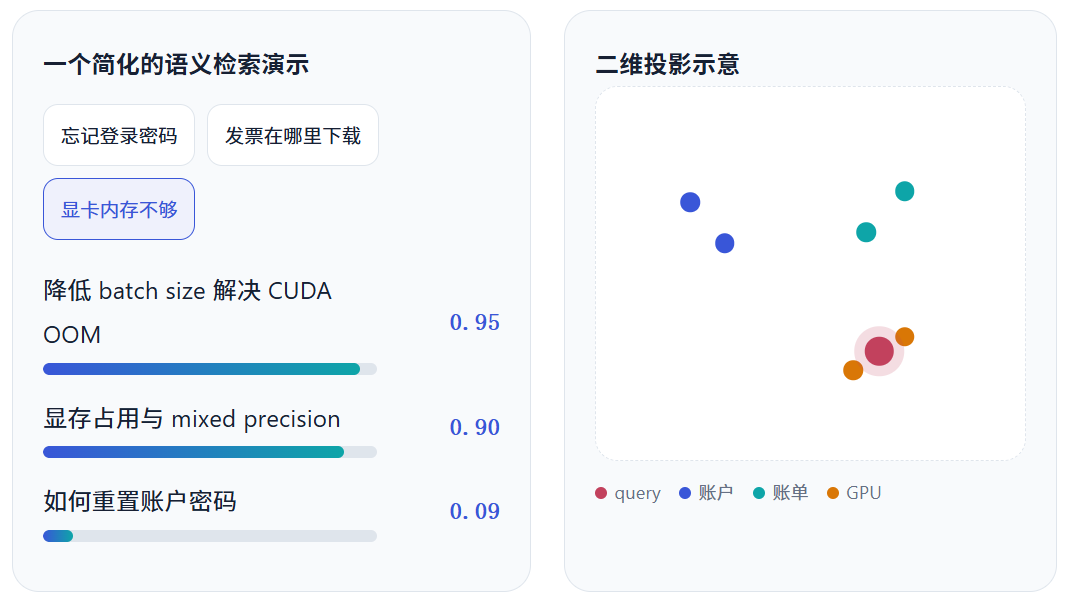
上图只是把高维关系投影成二维后的概念示意。真实 embedding 通常有上千个维度,不能用肉眼直接理解每一维的含义。
为什么经常使用 cosine similarity
得到 vector 后,需要一个函数衡量两个 vector 有多接近。官方文档推荐使用 cosine similarity。它关注两个 vector 的方向是否一致,而不是只看坐标差了多少。
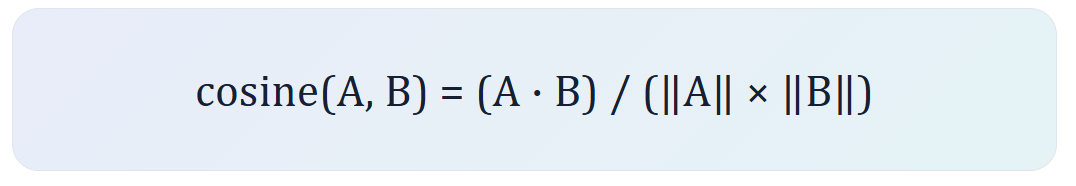
对 OpenAI embeddings 而言,vector 已归一化为长度 1。因此 cosine similarity 可以直接用 dot product(点乘) 计算; 同时,使用 cosine similarity 和 Euclidean distance(欧氏距离) 会得到相同的排序结果。
相似度不是绝对事实。 "多少分算相关"没有一个适用于所有业务的统一阈值。应当拿自己的 query 与文档构造验证集, 观察 Top-K recall、MRR、nDCG 或最终问答正确率,再决定阈值和召回数量。
模型怎么选,dimensions 又是什么
当前官方指南重点介绍两个第三代模型:text-embedding-3-small 和 text-embedding-3-large。前者通常更适合成本敏感、数据量较大的通用检索; 后者提供更强的效果上限,适合对跨语言检索或精度更敏感的场景。
| Model | 默认维度 | 最大 input | 适合场景 |
|---|---|---|---|
| text-embedding-3-small | 1536 | 8192 tokens | 通用检索、FAQ、分类、数据量较大的知识库 |
| text-embedding-3-large | 3072 | 8192 tokens | 更重视检索质量、多语言能力与复杂语义区分 |
维度越大,不等于项目一定越好
更长的 vector 往往意味着更高的存储占用、内存开销和相似度计算成本。 第三代模型支持 dimensions 参数,可以在生成 embedding 时直接缩短 vector。 这不是简单粗暴地"随便删数字",而是模型训练时就考虑了这种可缩短能力。

一个实际项目里,不妨先用 text-embedding-3-small 建立 baseline。 当评估表明召回不足,再比较 larger model、不同 dimensions、chunk 策略、hybrid search 与 reranker。 很多时候,切分方式和数据清洗比单纯换大模型更影响最终体验。
Embeddings 能做什么
代码搜索为什么也能用
可以先提取仓库中的 function,为每个 function 的源码或说明生成 embedding; 用户再用自然语言描述需求,例如"查找验证 JWT 的函数"。query 与代码虽然形式不同, 但处于同一语义空间后,仍然可以通过 similarity 排序。
Embeddings 在 RAG 中处于什么位置
RAG 并不是"让 embedding model 回答问题"。Embedding model 负责找材料, language model 负责阅读材料并组织答案。把这两个角色分开,很多概念会立刻清楚。

一个最小 RAG 流程通常是:离线切分资料并生成 embeddings;在线为 query 生成 embedding; 取回 Top-K chunks;把 chunks 连同问题放进 prompt;最后要求模型只根据材料回答并标注来源。
几个常见误区
误区一:Embedding 能保存完整原文
Vector 不能可靠地反向还原为原文。工程上应同时保存 chunk text 和 embedding, 其中 embedding 用来检索,原文用来展示、引用或交给 language model。
误区二:相似度高就代表答案正确
相似只说明语义接近,不代表事实正确,也不代表能够回答 query。 "苹果公司的财报"和"苹果手机新品"可能很接近,但前者不一定包含新品发布时间。
误区三:整本 PDF 一次性生成一个 vector
这样会把多个主题压在同一个表示里,检索定位会很粗。通常应该按标题、段落或 token 长度切成 chunks, 并保留一定 overlap,具体长度需要通过数据评估。
误区四:换成更大的 embedding model 就能解决所有问题
如果原始数据混乱、chunk 缺少上下文、查询语言与资料类型差异过大,单纯换模型未必有效。 先检查数据质量、召回失败样例和索引逻辑。
误区五:只把 vector 存下来,不记录版本
同一索引内应保持 model 与 dimensions 一致。更换 embedding model 后,旧 vector 与新 vector 不应直接混用;通常需要重新生成并建立新索引。