OpenCV-Python实战(28)------OpenCV计算摄影从HDR图像融合到全景拼接
-
- [0. 前言](#0. 前言)
- [1. 规划应用程序](#1. 规划应用程序)
- [2. 图像的 8 位问题](#2. 图像的 8 位问题)
-
- [2.1 RAW 图像](#2.1 RAW 图像)
- [2.2 伽玛校正](#2.2 伽玛校正)
- [3. 高动态范围成像](#3. 高动态范围成像)
-
- [3.1 改变曝光度的方法](#3.1 改变曝光度的方法)
- [3.2 利用多张不同曝光的图像生成 HDR 图像](#3.2 利用多张不同曝光的图像生成 HDR 图像)
- [3.3 使用 OpenCV 编写 HDR 脚本](#3.3 使用 OpenCV 编写 HDR 脚本)
- [3.4 显示 HDR 图像](#3.4 显示 HDR 图像)
- [4. 全景拼接](#4. 全景拼接)
-
- [4.1 编写脚本参数并筛选图像](#4.1 编写脚本参数并筛选图像)
- [4.2 确定相对位置和最终图片尺寸](#4.2 确定相对位置和最终图片尺寸)
- [4.3 改进全景拼接](#4.3 改进全景拼接)
- 小结
- 系列链接
0. 前言
本节的目标是在摄影和图像处理的基础上,深入探讨 OpenCV 提供的一些算法。我们将专注于数字摄影处理,并构建能够充分利用 OpenCV 功能的工具,将其作为编辑照片的工具。
学习数字摄影的基础知识和高动态成像的概念,不仅能更好地理解计算摄影,还能成为更优秀的摄影师。通过本节,将学习如何直接使用数码相机处理 RAW 格式图像,如何使用 OpenCV 的计算摄影工具以及如何使用低级 OpenCV API 来构建全景拼接算法。
1. 规划应用程序
为了构建图像处理工具箱,我们将把要熟悉的算法开发成 Python 脚本,利用 OpenCV 来解决实际问题。
我们将使用 OpenCV 实现以下脚本,以便在需要进行照片处理时能够随时使用它们:
gamma_correct.py:对输入图像应用伽马校正并显示结果图像hdr.py:接收多张图像作为输入并生成高动态范围 (High Dynamic Range,HDR) 图像作为输出panorama.py:接收多张图像作为输入并生成一张大于单张图像的拼接图像
我们首先讨论数字摄影的工作原理,以及为什么我们在不进行后期处理的情况下无法拍出完美的照片。
2. 图像的 8 位问题
我们惯用的典型 JPEG 图像,通过将每个像素编码为 24 位------每个 RGB (红、绿、蓝)颜色分量一个 8 位数------这可以得到一个 0-255 范围内的整数,但它是否包含了足够的信息?为了理解这一点,让我们尝试理解这些数字是如何被记录的,以及这些数字的含义。
目前大多数数码相机使用拜耳滤镜或等效滤镜,其工作原理基于相同的原则。拜耳滤镜是一个由不同颜色传感器组成的阵列,放置在类似于下图的网格上:
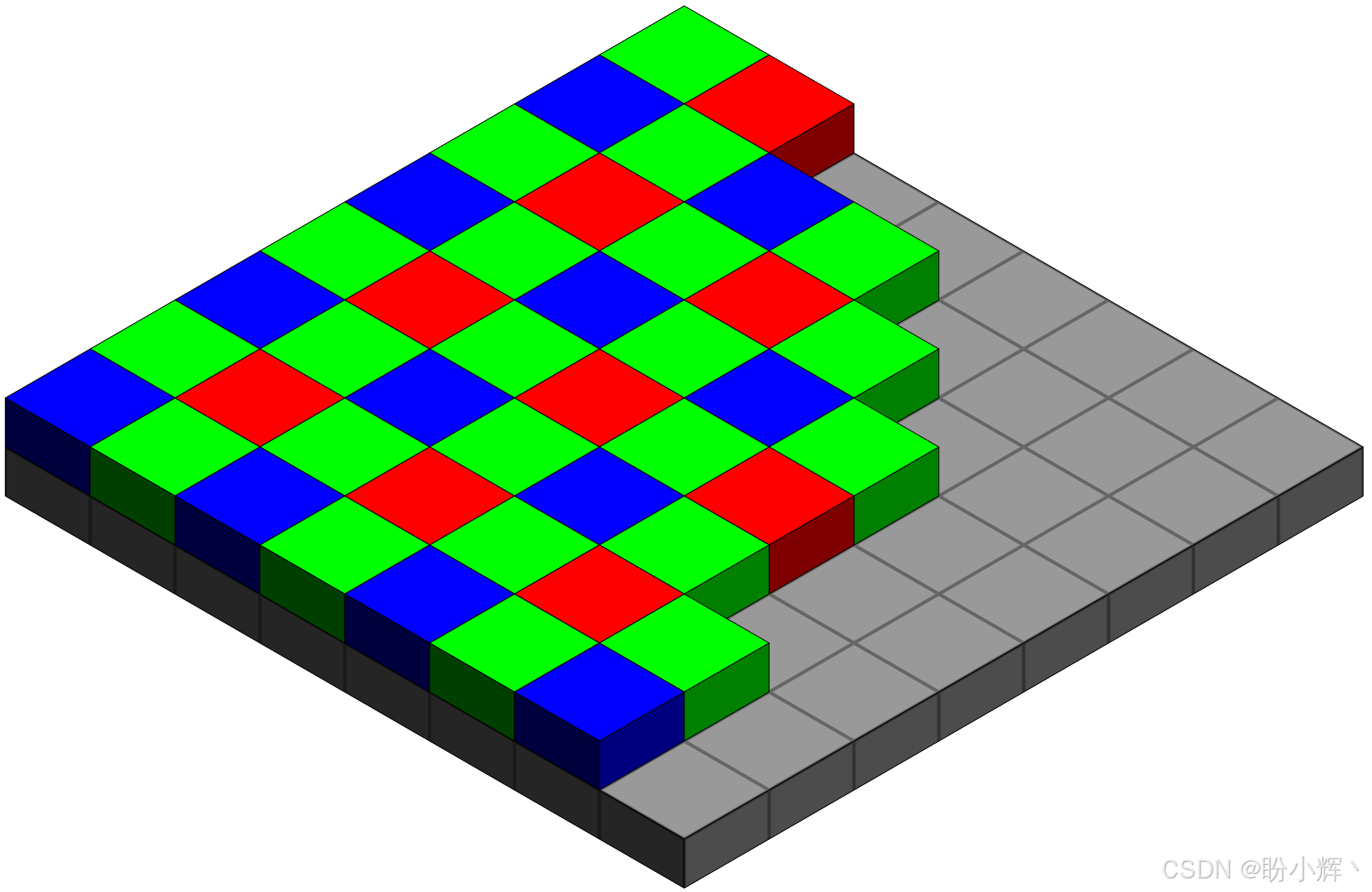
在上图中,每个传感器测量进入它的光线强度,一组四个传感器代表一个像素。来自这四个传感器的数据被组合起来,为我们提供 R、G、B 三个值。
不同的相机可能有略微不同的红、绿、蓝像素布局,但归根结底,它们都使用小型传感器,将接收到的辐射量离散化为 0-255 范围内的单个数值,其中 0 表示完全没有光线,255 表示传感器能记录的最大光线亮度。
可检测到的亮度范围称为动态范围或亮度范围。可以记录的最小光线量与最大光线量之间的比率称为对比度。
如前所述,JPEG 文件的对比度为 255:1。目前大多数液晶显示器对比度高达 1000:1,而人眼的对比度最多可以看到 15000:1。 所以,我们能看到的远比最好的显示器能显示的要多得多,也远比简单的 JPEG 文件存储的要多得多。
动态范围小就是为什么在拍照时,如果背景中有太阳,要么看到太阳而周围一片白茫茫没有任何细节,要么前景中的所有东西都极度黑暗。如下图所示:
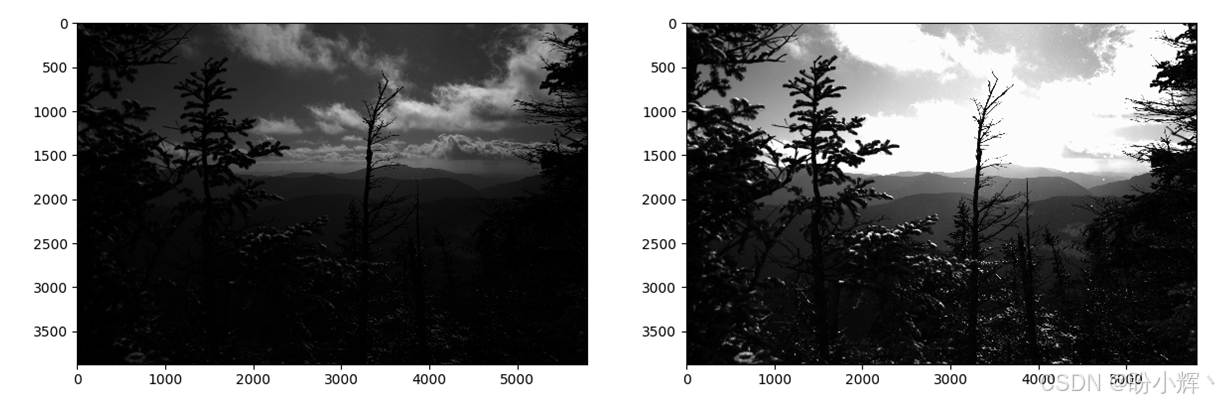
所以,问题在于我们要么显示过亮的东西,要么显示过暗的东西。在继续之前,让我们先看看如何读取超过 8 位的文件并将数据导入 OpenCV。
2.1 RAW 图像
RAW 文件(例如 Nikon Electronic Format (NEF) 或 Canon Raw Version 2 (CR2)) 通常比 JPEG 文件捕获更多的信息(通常每像素更多位数),如果要进行大量的后期处理,这些文件使用起来更方便,因为它们会产生更高质量的最终图像。
那么,让我们看看如何使用 Python 打开一个 CR2 文件并将其加载到 OpenCV 中。为此,我们将使用一个名为 rawpy 的 Python 库。为了方便,我们将编写一个名为 load_image 的函数,它可以处理 RAW 图像和常规 JPEG 文件,这样我们就可以抽象掉这一部分,专注于更有趣的内容:
(1) 首先,导入所需库:
python
import rawpy
import cv2
import numpy as np(2) 定义函数,添加一个可选的 bps 参数,用于控制图像所需的精度,即检查我们是需要完整的 16 位还是 8 位就足够了:
python
def load_image(path, bps=16):(3) 然后,如果文件扩展名是 .CR2,我们使用 rawpy 打开文件并提取图像:
python
def load_image(path, bps=16):
if path.suffix == '.CR2':
with rawpy.imread(str(path)) as raw:
data = raw.postprocess(no_auto_bright=True,
gamma=(1, 1),
output_bps=bps)(4) 由于 .CR2 文件和 OpenCV 使用不同的颜色顺序,我们从 RGB 切换到 BGR (蓝、绿、红),这是 OpenCV 中的默认顺序,并返回结果图像:
python
return cv2.cvtColor(data, cv2.COLOR_RGB2BGR)对于非 .CR2 的文件,我们使用 OpenCV:
python
else:
return cv2.imread(str(path))一旦知道如何加载图片,就可以尝试看看如何在屏幕上更好地显示它们。
2.2 伽玛校正
如果 JPEG 文件只能区分 255 个不同的级别,为什么大家还在使用它们?这是否意味着它只能捕获 1:255 的动态范围?
如前所述,相机传感器捕获的值是线性的,即 4 意味着光线比 1 多 4 倍,80 比 10 多 8 倍。但是 JPEG 文件格式必须使用线性标度吗?事实证明并非如此。因此,如果我们愿意牺牲两个值(例如 100 和 101 )之间的差异,则可以放置另一个值。
为了更好地理解这一点,让我们看一下 RAW 图像灰度像素值的直方图。以下是生成该直方图的代码------只需加载图像,将其转换为灰度,并使用 pyplot 显示直方图:
python
images = [load_14bit_gray(p) for p in args.images]
fig, axes = plt.subplots(2, len(images), sharey=False)
for i, gray in enumerate(images):
axes[0, i].imshow(gray, cmap='gray', vmax=2**14)
axes[1, i].hist(gray.flatten(), bins=256)直方图结果如下所示:
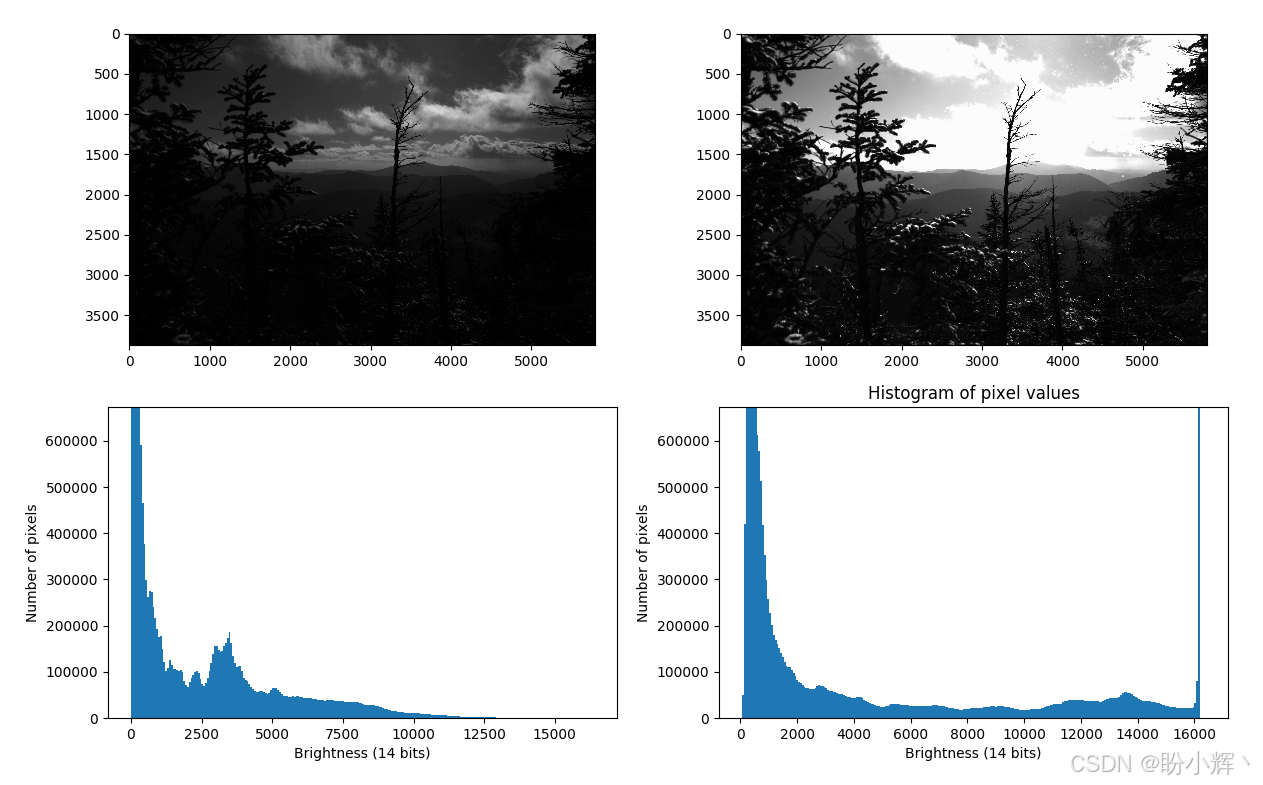
我们有两张图片:左边是一张正常照片,你可以看到一些云,但几乎看不到前景中的任何东西;右边那张试图捕捉树木的一些细节,因此云层完全过曝了。有没有办法将这两张结合起来呢?
如果仔细观察直方图,我们会发现过曝部分在右侧直方图中是可见的,因为有些值为 16000 的像素被编码为 255,即白色像素。但在左侧图片中,没有白色像素。我们将 14 位值编码为 8 位值的方式非常原始:我们只是将值除以 64 ( 2 6 2^6 26),因此 2500、2501 和 2502 之间不再具有区别;取而代之的是,只剩下 39 (在 0-255 范围内),因为 8 位格式的值必须是整数。
这就是伽马校正发挥作用的地方。我们不会简单地将记录的值作为强度显示,而是进行一些校正,使图像在视觉上更吸引人。
我们将使用一个非线性函数来尝试强调我们认为更重要的部分:
O = ( I 255 ) γ × 255 O=(\frac I {255})^\gamma \times 255 O=(255I)γ×255
我们尝试可视化这个公式在两种不同 γ γ γ 值下的情况------ γ = 0.3 γ = 0.3 γ=0.3 和 γ = 3 γ = 3 γ=3:
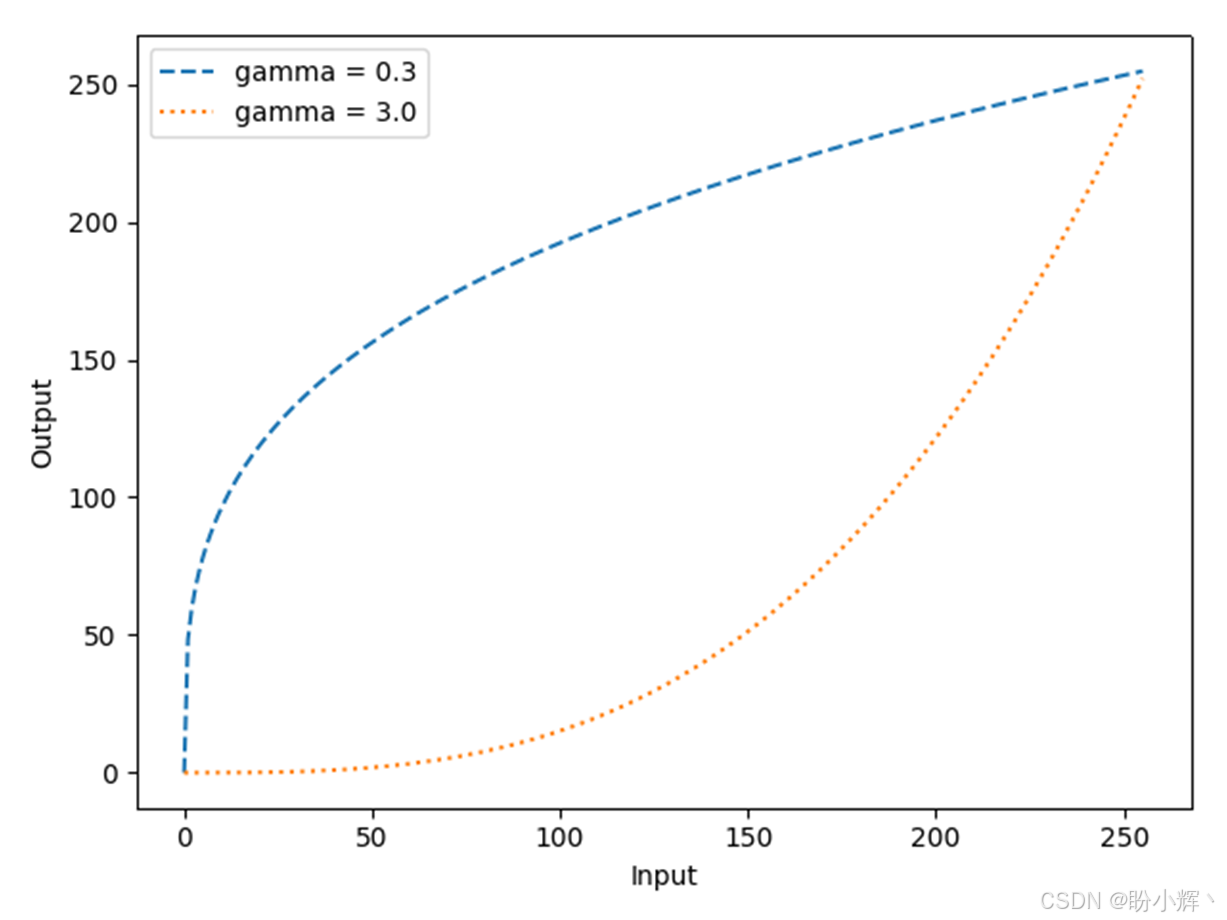
如上所示,较小的伽马值强调较低的值:0-50 的像素值被映射到 0-150 (超过可用值的一半)。较大的伽马值则相反------200-250 的值被映射到 100-250 (也超过可用值的一半)。因此,如果想让照片更亮,应该选择 γ < 1 γ < 1 γ<1 的伽马值,这通常称为伽马压缩。如果想让照片更暗以显示更多细节,应该选择 γ > 1 γ > 1 γ>1 的伽马值,这称为伽马扩展。
我们可以从浮点数开始处理 I I I,得到 O O O,然后将该数字转换为整数,从而比直接使用整数损失更少的信息。让我们编写 Python 代码来实现伽马校正:
(1) 首先,我们编写一个函数来应用我们的公式。由于我们使用的是 14 位图像,我们需要将其修改为:
O = ( I 2 14 ) γ × 255 O=(\frac I {2^{14}})^\gamma \times 255 O=(214I)γ×255
因此,相关代码如下:
python
@functools.lru_cache(maxsize=None)
def gamma_transform(x, gamma, bps=14):
return np.clip(pow(x / 2**bps, gamma) * 255.0, 0, 255)这里,我们使用了 @functools.lru_cache 装饰器来确保不重复计算任何内容。
(2) 然后,我们只需遍历所有像素并应用我们的变换函数:
python
def apply_gamma(img, gamma, bps=14):
corrected = img.copy()
for i, j in itertools.product(range(corrected.shape[0]),
range(corrected.shape[1])):
corrected[i, j] = gamma_transform(corrected[i, j], gamma, bps=bps)
return corrected现在,让我们看看如何使用这个函数,将经过伽马校正的图像与常规变换的 8 位图像并排显示。我们将为此编写一个脚本:
(2.1) 首先,配置一个解析器来加载图像并允许设置伽马值:
python
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('raw_image', type=Path,
help='Location of a .CR2 file.')
parser.add_argument('--gamma', type=float, default=0.3)
args = parser.parse_args()(2.2) 将灰度图像作为 14 位图像加载:
python
gray = load_14bit_gray(args.raw_image)(2.3) 使用线性变换,将输出值作为 [0-255] 范围内的整数:
python
normal = np.clip(gray / 64, 0, 255).astype(np.uint8)(2.4) 使用 apply_gamma 函数获得伽马校正后的图像:
python
corrected = apply_gamma(gray, args.gamma)(2.5) 然后,将这两幅图像连同它们的直方图一起绘制出来:
python
fig, axes = plt.subplots(2, 2, sharey=False)(2.6) 最后,显示图像:
python
for i, img in enumerate([normal, corrected]):
axes[1, i].hist(img.flatten(), bins=256)
axes[1, i].set_ylim(top=1.5e-2 * len(img.flatten()))
axes[1, i].set_xlabel('Brightness (8 bits)')
axes[1, i].set_ylabel('Number of pixels')
axes[0, i].imshow(img, cmap='gray', vmax=255)
plt.title('Histogram of pixel values')
plt.savefig('histogram.png')
plt.show()现在我们已经绘制了直方图,接下来查看以下两幅图像及其直方图:
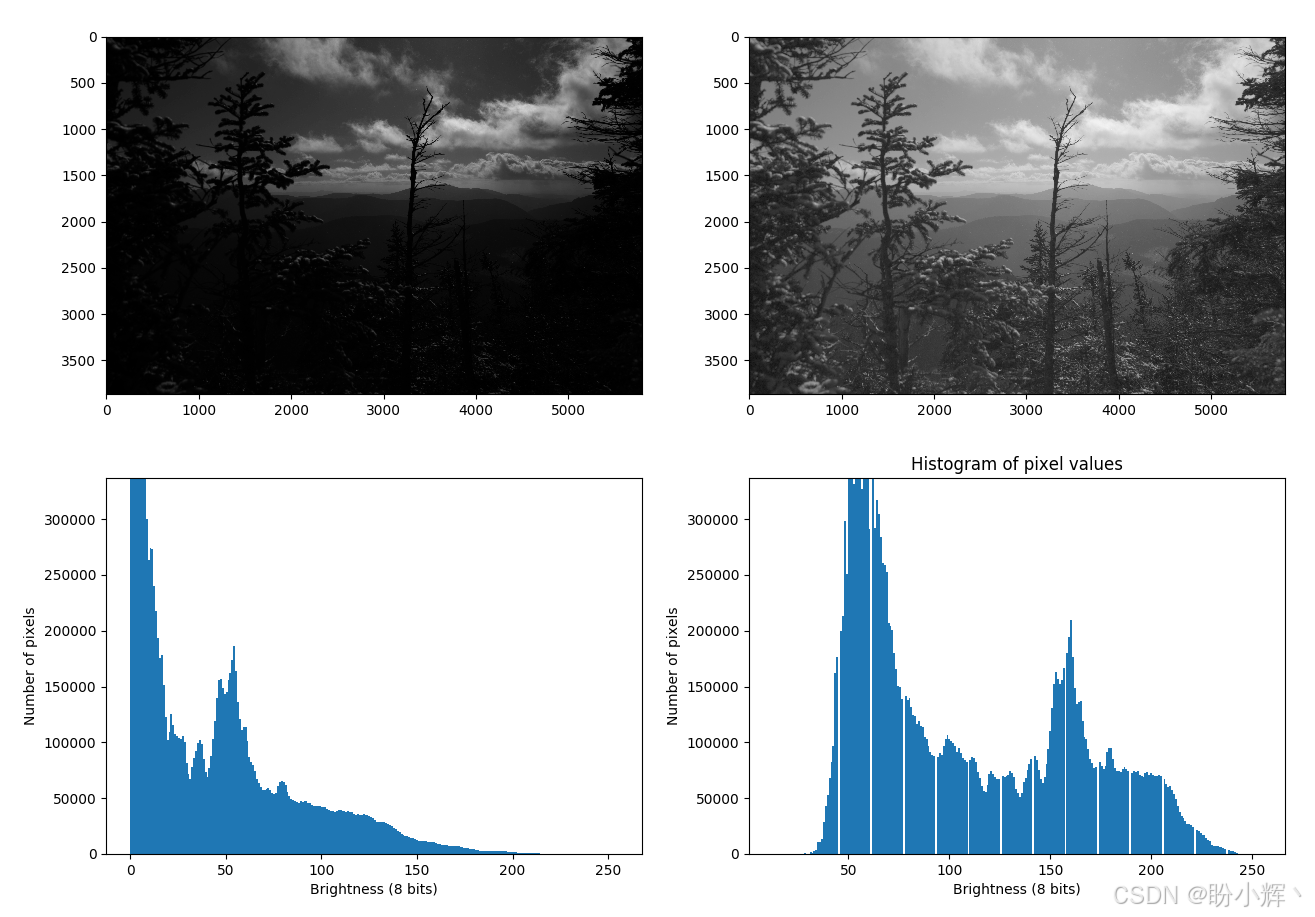
事实证明,伽马校正对于黑白图像效果很好,但它并非万能,它要么校正亮度而失去大部分颜色信息,要么校正颜色信息而失去亮度信息。因此,我们需要使用一个新的方法------那就是 HDRI。
3. 高动态范围成像
高动态范围成像 (High Dynamic Range, HDR)是一种技术,用于生成比显示介质所能显示的或相机单次拍摄所能捕获的具有更大亮度动态范围(即对比度)的图像。创建此类图像主要有两种方式------使用特殊的图像传感器(例如过采样二值图像传感器),或者通过组合多张标准动态范围 (Standard Dynamic Range, SDR)图像来生成一张合成的 HDR 图像,这也是我们在本节将重点关注的方式。
HDR 成像处理的是每通道使用超过 8 位(通常为 32 位浮点值)的图像,从而实现更宽的动态范围。正如我们所知,场景的动态范围是其最亮部分和最暗部分之间的对比度。
我们仔细看看一些常见事物的亮度值。下表显示了从黑暗天空(约 10⁻⁴ cd/m² )到日落时的太阳 (10⁵ cd/m²) 之间的数值:

我们能看到的比这些值更多。因为人类可以调节眼睛适应更暗的地方,而太阳的亮度值可能高达 10⁸ cd/m²,这个范围已经相当大了。作为比较,通常的 8 位图像对比度为 256:1,人眼一次可以看到的对比度约百万比一,而 14 位 RAW 格式为 2¹⁴:1。
显示介质也有局限性;例如,典型的 IPS 显示器对比度约为 1000:1,而 VA 显示器的对比度可高达 6000:1。我们将这些值放在光谱上,比较结果如下所示:
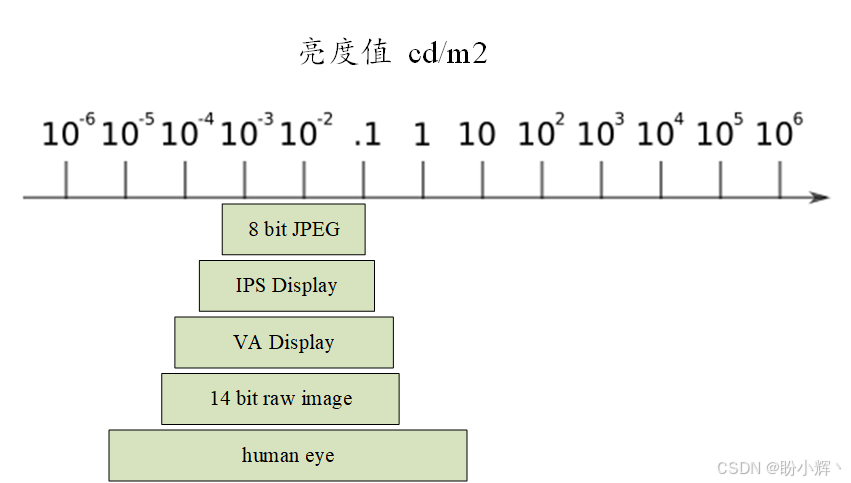
现在,这看起来好像我们看不到太多东西,这确实是真的,因为我们需要时间来适应不同的光照条件。相机也是如此。但仅仅一瞥之间,我们的肉眼就能比最好的相机看到更多的东西。那么我们该如何弥补这一点呢?
诀窍是快速连续拍摄多张照片,大多数相机都能轻松做到这一点。如果我们快速连续拍摄能够互补的照片,仅用五张 JPEG 图像就可以覆盖光谱的相当大一部分:
这看起来非常简单,拍摄五张照片是相当容易的。但是,我们需要的是一张拥有全部动态范围的图片,而不是五张独立的图片。HDR 图像存在两个大问题:
- 我们如何将多张图像合并为一张图像?
- 我们如何显示一张动态范围高于显示介质的图像?
然而,在我们能够合并这些图像之前,我们学习如何改变相机的曝光度,即它对光的敏感度。
3.1 改变曝光度的方法
现代数码单反相机以及其他数码相机都有一个固定的传感器网格(通常以拜耳滤镜的形式放置),它仅仅测量相机接收到的光强度。
同一台相机能够拍摄出美丽的夜景照片,水面像丝滑的云彩,也能够拍摄出运动员全力伸展的静态照片。那么,如何使用同一台相机适应如此不同的设置,并拍出我们在屏幕上看到的结果?
在测量曝光时,测量被捕获的亮度确实非常困难。测量相对速度比测量 10 的幂次方的亮度要容易得多,后者可能很难调整。我们以 2 的幂次方来测量速度;这称为一档。
诀窍在于,尽管相机受到限制,它必须能够每张照片捕获有限的亮度范围。这个范围本身可以沿着亮度光谱移动。为了克服这一点,让我们研究相机的快门速度、光圈和 ISO 速度参数。
3.1.1 快门速度
快门速度实际上并不是快门移动的速度,而是拍摄照片时相机快门打开的时间长度。因此,它是相机内部的数字传感器暴露在光线下收集信息的时间长度。它是所有相机控制中最直观的,因为我们可以感觉到它的发生。
快门速度通常以秒的分数来衡量。例如,当快门速度为 1/1000s,在手持相机拍摄时晃动相机时,照片中并不会出现模糊的情况。
3.1.2 光圈
光圈是光学镜头中光线进入相机的孔的直径。下图展示了光圈设置为不同数值时的开口示例:

光圈通常用 f f f 来衡量, f f f 是系统焦距与开口直径(入瞳)的比值。我们不需要关心镜头的焦距;我们唯一需要知道的是,只有变焦镜头具有可变焦距,因此如果我们不改变镜头上的放大倍率,焦距将保持不变。所以我们可以通过计算 f f f 倒数的平方来衡量入瞳的面积:
area ∝ 1 f − number 2 \text{area} \propto \frac 1 {f-\text{number}^2} area∝f−number21
而且,我们知道面积越大,我们照片中获得的光线就越多。因此,如果我们增加 f f f ,这将对应于入瞳尺寸的减小,我们的照片会变得更暗。
3.1.3 ISO 感光度
ISO 感光度指的是相机中传感器的感光能力。它的数值标定方式,是将数字传感器的感光特性映射到计算机尚未普及时所用的化学胶卷上。
ISO 感光度通常由两个数值表示,例如 100/21°:第一个数字是算术标度下的感光度,第二个数字是对数标度下的数值。由于这两个数值一一对应,通常省略第二个数字,只写作 ISO 100。ISO 100 的感光能力是 ISO 200 的一半,两者相差 1 档。
用 2 的幂次来讨论比用 10 的幂次更简便,因此摄影师引入了"档"的概念。1 档表示相差 2 倍,2 档表示相差 4 倍,依此类推, n n n 档表示相差 2 n 2^n 2n 倍。
理解了如何控制曝光之后,我们来看看如何将多张不同曝光的照片合成为一张图像。
3.2 利用多张不同曝光的图像生成 HDR 图像
既然知道了如何获取更多照片,我们就可以拍摄多张动态范围几乎没有重叠的图片。来看一下最流行的 HDR 算法,该算法由 Paul E. Debevec 和 Jitendra Malik 于 2008 年首次发表。
事实证明,要想获得理想的效果,照片之间需要有一定的动态范围重叠,以确保精度,同时还要考虑照片中的噪声。通常,相邻照片之间相差 1 档、2 档或最多 3 档是比较常见的做法。如果我们拍摄五张 8 位照片,每张之间相差 3 档,那么就能覆盖人眼一百万比一的感光比范围。
接下来,我们详细看一下 Debevec HDR 算法的工作原理。
首先,假设相机看到的记录值是场景光照强度的某个函数。我们之前讨论过这可能是线性的,但现实生活中没有什么是真正线性的。让记录值矩阵为 Z Z Z,光照强度矩阵为 X X X:
Z = f ( E Δ t ) Z=f(E\Delta t) Z=f(EΔt)
其中,我们用 Δ t Δt Δt 表示曝光时间,函数 f f f 称为相机的响应函数。同时,我们假设:如果将曝光时间加倍、光照强度减半,得到的输出不变,反之亦然。这个假设对所有图像都应成立,并且光照强度 E E E 在不同照片之间不应改变,只有记录值 Z Z Z 和曝光时间 Δ t Δt Δt 可以变化。对两边应用响应函数的反函数 f − 1 f^{−1} f−1,再取对数,则对于所有照片 i i i,有:
l n f − 1 ( Z i ) = l n E + l n Δ t i lnf^{−1}(Z_i)=lnE+ln\Delta t_i lnf−1(Zi)=lnE+lnΔti
关键在于设计一个能够计算出 f − 1 f^{−1} f−1 的算法,而 Debevec 等人正是完成了这一工作。
当然,我们的像素值并不会完全遵循这一规则,我们需要拟合一个近似解。但在此之前,我们先更详细地了解这些数值的含义。
在继续之前,下一小节我们将研究如何从图像文件中恢复出 Δ t i Δt_i Δti 的值。
3.2.1 从图像中提取曝光强度
假设我们之前讨论的所有相机参数都满足互易律,让我们尝试设计一个函数 exposure_strength,返回与曝光等效的时间:
(1) 首先,我们为 ISO 速度和 f f f 值设定一个参考值:
python
def exposure_strength(path, iso_ref=100, f_stop_ref=6.375):(2) 然后,使用 exifread 包,该包可以轻松读取图像中的元数据。大多数现代相机都以这种标准格式记录元数据:
python
with open(path, 'rb') as infile:
tags = exifread.process_file(infile)(3) 然后,我们提取 f f f 值,并查看入瞳面积比参考值大了多少:
python
[f_stop] = tags['EXIF ApertureValue'].values
rel_aperture_area = 1 / (f_stop.num / f_stop.den / f_stop_ref) ** 2(4) 然后,计算当前 ISO 设置相对于参考基准的感光度提高了多少倍:
python
[iso_speed] = tags['EXIF ISOSpeedRatings'].values
iso_multiplier = iso_speed / iso_ref(5) 最后,将所有值与快门速度结合起来,返回等效的曝光时间 exposure_time:
python
[exposure_time] = tags['EXIF ExposureTime'].values
exposure_time_float = exposure_time.num / exposure_time.den
return rel_aperture_area * exposure_time_float * iso_multipli使用以下照片进行演示,该照片取自 Frozen River 照片集:
| 照片 | 光圈 | ISO速度 | 快门速度 |
|---|---|---|---|
| AM5D5669.CR2 | 6 3/8 | 100 | 1/60 |
| AM5D5670.CR2 | 6 3/8 | 100 | 1/250 |
| AM5D5671.CR2 | 6 3/8 | 100 | 1/160 |
| AM5D5672.CR2 | 6 3/8 | 100 | 1/100 |
| AM5D5673.CR2 | 6 3/8 | 100 | 1/40 |
| AM5D5674.CR2 | 6 3/8 | 160 | 1/40 |
| AM5D5676.CR2 | 6 3/8 | 250 | 1/40 |
使用 exposure_strength 函数对这些照片进行时间估计的输出如下所示:
shell
[0.016666666666666666, 0.004, 0.00625, 0.01, 0.025, 0.04, 0.0625现在,我们有了曝光时间,接下来看看如何利用它来获取相机响应函数。
3.2.2 估算相机响应函数
在 y y y 轴上绘制 l n Δ t i ln\Delta t_i lnΔti,在 x x x 轴上绘制 Z i Z_i Zi:
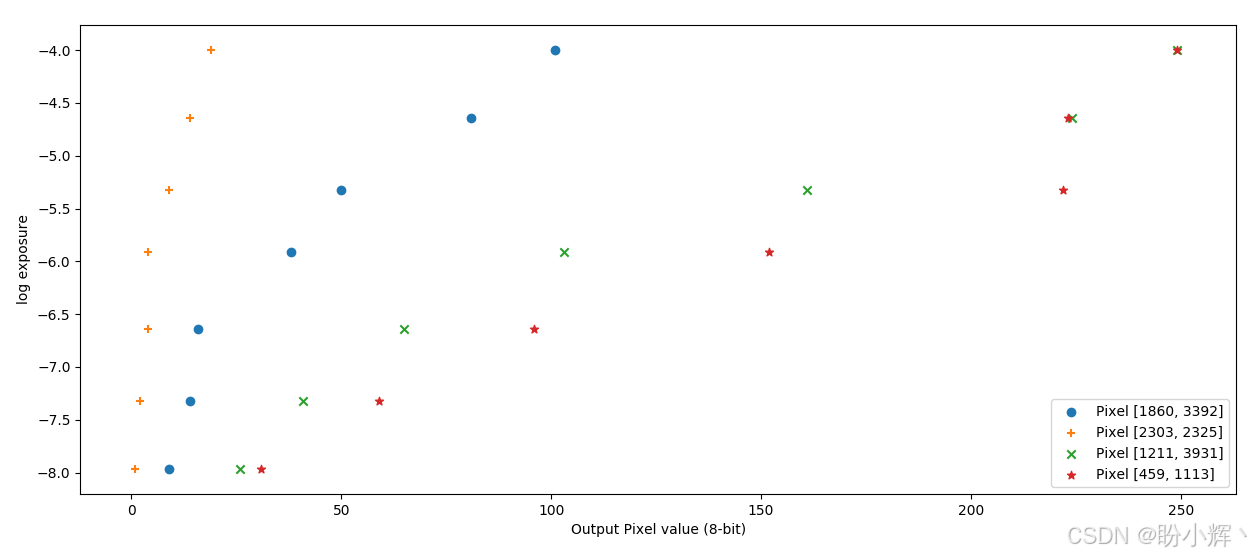
我们试图找到一个 f − 1 f^{−1} f−1,更重要的是,找到所有照片的 l n E lnE lnE,使得当我们把 l o g ( E ) log(E) log(E) 加到曝光时间的对数上时,所有像素都落在同一个函数曲线上。下图展示了 Debevec 算法的运行结果:
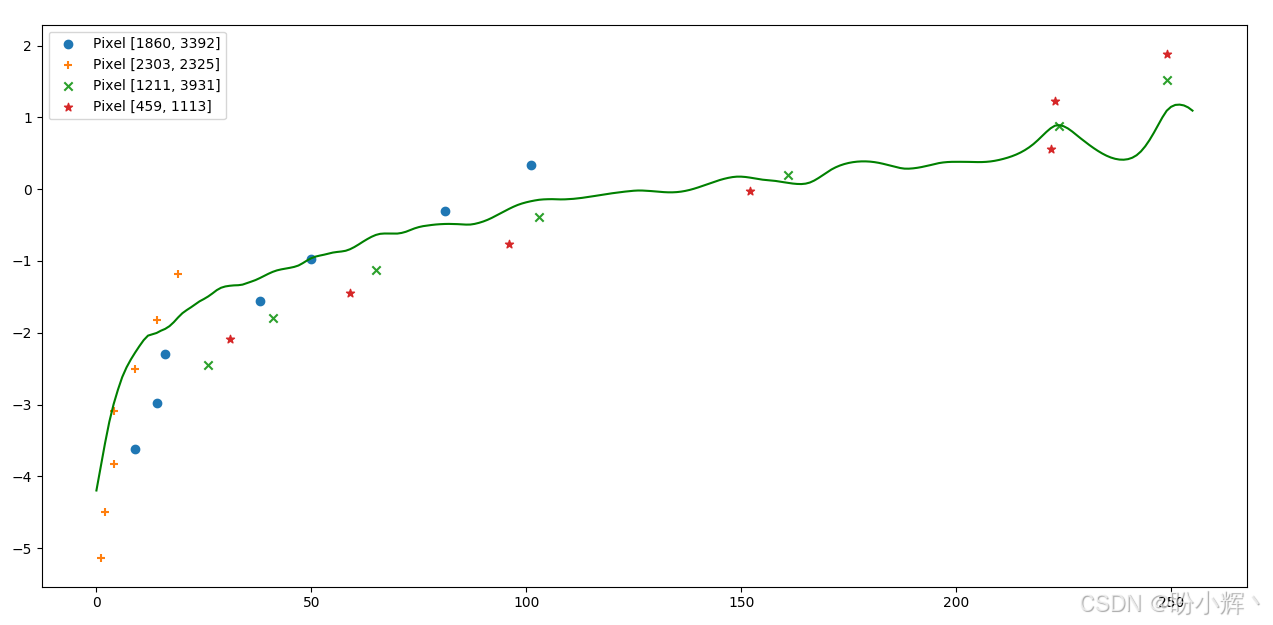
Debevec 算法同时估算出 f − 1 f^{−1} f−1 (它近似穿过所有像素点)和 l n E lnE lnE。其中, E E E 矩阵就是我们恢复出的 HDR 图像矩阵。
现在,我们来看看如何使用 OpenCV 实现这一算法。
3.3 使用 OpenCV 编写 HDR 脚本
脚本的第一步是使用 Python 内置的 argparse 模块来设置脚本参数:
python
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser()
img_group = parser.add_mutually_exclusive_group(required=True)
img_group.add_argument('--image-dir', type=Path)
img_group.add_argument('--images', type=Path, nargs='+')
args = parser.parse_args()
if args.image_dir:
args.images = sorted(args.image_dir.iterdir())可以看到,我们设置了两个互斥的参数:--image-dir (包含所有图像的目录)和 --images (我们将使用的图像列表)。我们需要确保 args.images 中填充了所有图像的列表,这样脚本的其他部分就不必关心用户选择了哪个选项。
设置完所有命令行参数后,后续流程如下:
(1) 将所有图像读入内存:
python
images = [load_image(p, bps=8) for p in args.images](2) 读取元数据,并使用 exposure_strength 估算曝光时间:
python
times = [exposure_strength(p)[0] for p in args.images]
times_array = np.array(times, dtype=np.float32)(3) 计算相机响应函数------crf_debevec:
python
cal_debevec = cv2.createCalibrateDebevec(samples=200)
crf_debevec = cal_debevec.process(images, times=times_array)(4) 使用相机响应函数计算 HDR 图像:
python
merge_debevec = cv2.createMergeDebevec()
hdr_debevec = merge_debevec.process(images, times=times_array.copy(), response=crf_debevec)需要注意的是,HDR 图像的类型是 float32 而非 uint8,因为它包含了所有曝光图像的全部动态范围。
现在我们得到了 HDR 图像,接下来进入另一个重要环节。让我们看看如何利用 8 位图像表示来显示 HDR 图像。
3.4 显示 HDR 图像
显示 HDR 图像并非易事,HDR 图像包含的数值范围远超普通相机所能记录的范围,因此我们需要找到一种方法来显示它。在 OpenCV 中,我们可以使用伽马校正,将所有不同的数值映射到一个较小的、范围在 0 到 255 之间的范围中,这个过程称为色调映射。
OpenCV 提供了一个方法,该方法将伽马值作为参数:
python
tonemap1 = cv2.createTonemap(gamma=2.2)
res_debevec = tonemap1.process(hdr_debevec.copy())然后,我们需要将所有数值裁剪并转换为整数:
python
res_8bit = np.clip(res_debevec * 255, 0, 255).astype('uint8')之后,我们可以使用 pyplot 显示生成的 HDR 图像:
python
plt.imshow(x)
plt.show()结果如下图所示:

现在,让我们来看看如何扩展相机的视野------甚至可能扩展到 360 度!
4. 全景拼接
计算摄影中另一个非常有趣的主题是全景拼接。本节将重点介绍全景拼接背后的思想,我们不会仅仅调用一个函数就完事,而是会完整地走一遍从一组独立照片创建全景图所涉及的所有步骤。
4.1 编写脚本参数并筛选图像
我们希望编写一个脚本,该脚本接收一组图像列表,并生成一张全景图。因此,让我们为脚本设置 ArgumentParser:
python
def parse_args():
parser = argparse.ArgumentParser()
img_group = parser.add_mutually_exclusive_group(required=True)
img_group.add_argument('--image-dir', type=Path)
img_group.add_argument('--images', type=Path, nargs='+')
parser.add_argument('--show-steps', action='store_true')
args = parser.parse_args()
if args.image_dir:
args.images = sorted(args.image_dir.iterdir())
return args在这里,我们创建了一个 ArgumentParser 实例,并添加了参数,以便可以传入一个包含图像的目录或一个图像列表。然后,如果传入的是图像目录,我们会确保从该目录中获取所有图像,而不是直接使用传入的图像列表。
下一步是使用特征提取器,找出图像之间共同的特征。这与《通过特征匹配和透视变换寻找物体》以及第《基于运动恢复结构的 3D 场景重建》的内容非常相似。我们还将编写一个函数来筛选那些具有共同特征的图像,从而使脚本更加通用。让我们逐步分析这个函数:
(1) 创建 SURF 特征提取器,并计算所有图像的所有特征:
python
def largest_connected_subset(images):
finder = cv2.xfeatures2d_SURF.create()
all_img_features = [cv2.detail.computeImageFeatures2(finder, img)
for img in images](2) 创建一个匹配器类,用于将一张图像匹配到与其共享最多特征的最近邻图像:
python
matcher = cv2.detail.BestOf2NearestMatcher_create(False, 0.6)
pair_matches = matcher.apply2(all_img_features)
matcher.collectGarbage()(3) 筛选图像,确保至少有两张图像共享特征,这样我们才能继续执行算法:
python
_conn_indices = cv2.detail.leaveBiggestComponent(all_img_features, pair_matches, 0.4)
conn_indices = [i for [i] in _conn_indices]
if len(conn_indices) < 2:
raise RuntimeError("Need 2 or more connected images.")
conn_features = np.array([all_img_features[i] for i in conn_indices])
conn_images = [images[i] for i in conn_indices](4) 再次运行匹配器,检查是否有图像被移除,并返回将来需要用到的变量:
python
if len(conn_images) < len(images):
pair_matches = matcher.apply2(conn_features)
matcher.collectGarbage()
return conn_images, conn_features, pair_matches在筛选完图像并获取所有特征之后,我们进入下一步,即为全景拼接创建一个空白画布。
4.2 确定相对位置和最终图片尺寸
当我们分离出所有相连的图片并获知所有特征后,接下来就需要确定合并后的全景图有多大,并创建空白画布以便开始向其中添加图片。首先,我们需要找到图片的参数。
4.2.1 查找相机参数
为了能够合并图像,我们需要计算所有图像的单应性矩阵,然后利用这些矩阵对图像进行调整,使它们能够拼接在一起。我们将编写一个函数来完成这项工作:
(1) 首先,创建 HomographyBasedEstimator() 函数:
python
def find_camera_parameters(features, pair_matches):
estimator = cv2.detail_HomographyBasedEstimator()(2) 有了估计器之后,为了提取所有相机参数,我们使用来自不同图像的匹配特征:
python
success, cameras = estimator.apply(features, pair_matches, None)
if not success:
raise RuntimeError("Homography estimation failed.")(3) 确保旋转矩阵 R 具有正确的类型:
python
for cam in cameras:
cam.R = cam.R.astype(np.float32)(4) 然后,返回所有参数:
python
return cameras使用优化器(例如 cv2.detail_BundleAdjusterRay )可以进一步优化这些参数,但为了简单起见,我们暂时保持现状。
4.2.2 为全景图创建画布
为了创建画布,我们基于所需的旋转模式创建一个扭曲器 (warper) 对象。为简单起见,假设我们使用平面模型:
python
warper = cv2.PyRotationWarper('plane', 1)然后,遍历所有相连的图像,获取每张图像中的所有感兴趣区域:
python
stitch_sizes, stitch_corners = [], []
warper = cv2.PyRotationWarper('plane', warped_image_scale)
for i, img in enumerate(conn_images):
sz = img.shape[1], img.shape[0]
K = cameras[i].K().astype(np.float32)
roi = warper.warpRoi(sz, K, cameras[i].R)
stitch_corners.append(roi[0:2])
stitch_sizes.append(roi[2:4])最后,我们根据所有感兴趣区域估算出最终的画布尺寸 canvas_size:
python
canvas_size = cv2.detail.resultRoi(corners=stitch_corners,
sizes=stitch_sizes)现在,让我们看看如何利用画布尺寸将所有图像融合在一起。
4.2.3 将图像融合在一起
首先,我们创建一个 MultiBandBlender 对象,它将帮助我们合并图像。融合器不会简单地从某一张图像中选取像素值,而是会在可用数值之间进行插值:
python
blender = cv2.detail_MultiBandBlender()
blend_width = np.sqrt(canvas_size[2] * canvas_size[3]) * 5 / 100
blender.setNumBands((np.log(blend_width) / np.log(2.) - 1.).astype(np.int))
blender.prepare(canvas_size)然后,对于每一张相连的图像,我们执行以下步骤:
(1) 对图像进行扭曲 (warp),并获取其角点位置:
python
for i, img in enumerate(conn_images):
K = cameras[i].K().astype(np.float32)
corner, image_wp = warper.warp(img, K, cameras[i].R,
cv2.INTER_LINEAR, cv2.BORDER_REFLECT)(2) 接着,计算该图像在画布上的掩模:
python
mask = 255 * np.ones((img.shape[0], img.shape[1]), np.uint8)
_, mask_wp = warper.warp(mask, K, cameras[i].R,
cv2.INTER_NEAREST, cv2.BORDER_CONSTANT)(3) 之后,将数值转换为 np.int16 类型,并输入到融合器中:
python
image_warped_s = image_wp.astype(np.int16)
blender.feed(cv2.UMat(image_warped_s), mask_wp, stitch_corners[i])(4) 最后,对融合器调用 blend 函数,得到最终结果并保存:
python
result, result_mask = blender.blend(None, None)
cv2.imwrite('result.jpg', result)(5) 我们还可以将图像缩小到 600 像素宽并进行显示:
python
zoomx = 600.0 / result.shape[1]
dst = cv2.normalize(src=result, dst=None, alpha=255.,
norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
dst = cv2.resize(dst, dsize=None, fx=zoomx, fy=zoomx)
cv2.imwrite('dst.png', dst)
cv2.imwrite('dst.jpeg', dst)
cv2.imshow('panorama', dst)
cv2.waitKey()最终得到的全景照片如下所示:

可以看到,效果并不完美,白平衡在不同照片之间需要校正,但这已经是一个很好的起点了。在下一小节中,我们将进一步优化拼接输出。
4.3 改进全景拼接
我们可以继续调整我们已经写好的脚本,添加或移除某些功能(例如,添加白平衡补偿器,以确保从一张图片到另一张图片的过渡更加平滑),或者调整其他参数来进行学习。
但当我们需要快速生成全景图时,OpenCV 还提供了一个便捷的 Stitcher 类,它完成了我们上面讨论的大部分工作:
python
images = [load_image(p, bps=8) for p in args.images]
stitcher = cv2.Stitcher_create()
(status, stitched) = stitcher.stitch(images)为了获取更好的观感,需要添加一些代码来裁剪全景图,以去除黑边像素。
小结
在本节中,我们学习了如何利用普通相机拍摄的能力有限(无论是动态范围有限还是视野有限)的简单图像,并使用 OpenCV 将多张图像合并成一张优于原始图像的单张图像。
系列链接
OpenCV-Python实战(1)------OpenCV简介与图像处理基础
OpenCV-Python实战(2)------图像与视频文件的处理
OpenCV-Python实战(3)------OpenCV中绘制图形与文本
OpenCV-Python实战(4)------OpenCV常见图像处理技术
OpenCV-Python实战(5)------OpenCV图像运算
OpenCV-Python实战(6)------OpenCV中的色彩空间和色彩映射
OpenCV-Python实战(8)------直方图均衡化
OpenCV-Python实战(9)------OpenCV用于图像分割的阈值技术
OpenCV-Python实战(10)------OpenCV轮廓检测
OpenCV-Python实战(11)------OpenCV轮廓检测相关应用
OpenCV-Python实战(12)------一文详解AR增强现实
OpenCV-Python实战(13)------OpenCV与机器学习的碰撞
OpenCV-Python实战(14)------人脸检测详解
OpenCV-Python实战(15)------面部特征点检测详解
OpenCV-Python实战(16)------人脸追踪详解
OpenCV-Python实战(17)------人脸识别详解
OpenCV-Python实战(18)------深度学习简介与入门示例
OpenCV-Python实战(19)------OpenCV与深度学习的碰撞
OpenCV-Python实战(20)------OpenCV计算机视觉项目在Web端的部署
OpenCV-Python实战(21)------OpenCV人脸检测项目在Web端的部署
OpenCV-Python实战(22)------使用Keras和Flask在Web端部署图像识别应用
OpenCV-Python实战(23)------将OpenCV计算机视觉项目部署到云端
OpenCV-Python实战(24)------打造实时图像滤镜系统
OpenCV-Python实战(25)------基于深度传感器与凸性分析打造实时手势识别系统