文章目录
-
- 摘要
- [1 研究背景](#1 研究背景)
- [2 系统与优化建模](#2 系统与优化建模)
- [2.1 系统建模](#2.1 系统建模)
- [3 基于监督学习的算法设计](#3 基于监督学习的算法设计)
-
- 3.1、训练数据生成
- [3.2 考虑约束的损失函数设计](#3.2 考虑约束的损失函数设计)
- [4 总结](#4 总结)
摘要
本文针对无人机安全通信场景中的轨迹与功率联合优化问题,提出了一种基于深度监督学习的求解框架。在该场景中,一架固定高度飞行的无人机需在给定起点和终点之间规划水平轨迹,并动态调整发射功率,以在满足最大速度约束的前提下最大化飞行全程的平均保密速率。由于该优化问题具有非凸、高维和约束耦合的特点,本文未直接求解,而是采用数据驱动的监督学习方法:通过利用贝塞尔曲线、正弦谐波扰动、窃听者避让、合法者吸引等规则生成大量"场景--参考轨迹--参考功率"样本,然后送入神经网络中进行训练。实验结果表明方法的有效性。
1 研究背景
-
近年来,无人机(UAV)凭借其高机动性、低成本及灵活部署的优势,在应急通信、环境监测、军事侦察及物联网数据采集等场景中得到广泛应用。无人机常作为空中移动基站或中继节点,为地面用户提供无线连接。然而,无线信道的广播特性使通信极易遭受窃听攻击,特别是在无人值守或敌对环境中,窃听者可能截获机密信息,造成严重的安全威胁。因此,如何在保障通信服务质量的同时,提升物理层安全性,成为无人机通信系统设计的核心问题之一。
-
物理层安全技术通过利用信道差异性来防止窃听,无需上层加密,特别适合资源受限的无人机平台。其中,动态调整无人机飞行轨迹和发射功率,可以有效增大合法用户与窃听者之间的信道质量差距,从而提升保密速率。然而,轨迹与功率的联合优化面临严峻挑战:一方面,目标函数(如平均保密速率)非凸、约束条件(最大速度、起点/终点固定、功率限制)耦合性强;另一方面,任务时域长、状态空间连续,传统优化方法(如凸逼近、动态规划)计算复杂,难以满足实时决策需求。
-
已有研究如交替优化、连续凸逼近等,通常将问题分解为轨迹和功率两个子问题迭代求解。虽然能获得较好的局部最优解,但需要大量迭代计算,每次环境变化(如用户位置移动)均需重新求解,无法在线快速响应。此外,模型依赖精确的信道假设,鲁棒性较差。
-
深度学习的兴起为复杂优化问题提供了新的思路。其中,监督学习可以通过模仿专家轨迹实现快速映射,强化学习则通过与环境交互直接优化累积奖励,有望突破传统方法的瓶颈。
2 系统与优化建模
2.1 系统建模
考虑个无人机(UAV)作为空中移动基站,在固定高度飞行,为一组地面合法用户提供下行数据传输服务,同时存在一个地面窃听者试图截获机密信息,UAV飞行区域为二维水平面。令UAV在时隙t的水平位置为
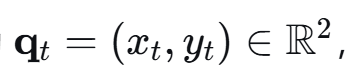
且无人机有最大飞行速率约束,即
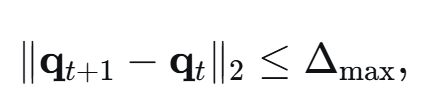
系统包含 N个合法用户和 一个窃听者。所有地面节点位置固定且已知。记第 i个用户的位置的位置为
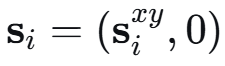
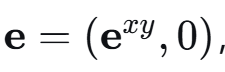
令集合g表示地面用户的集合,包含合法者和窃听者
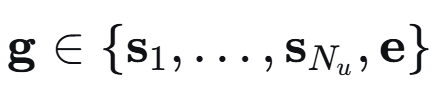

简单点,假设合法用户之间的接收信号正交,则接收信号的SINR为
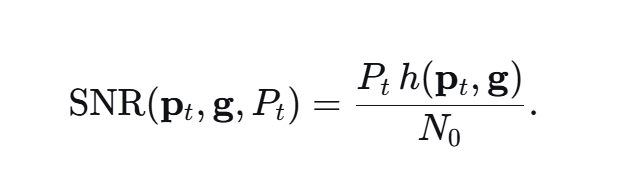
合法用户的可达速率为
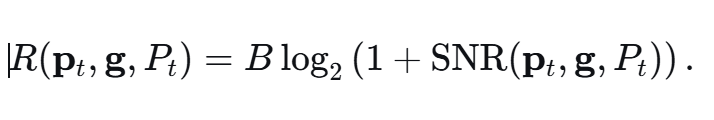
系统的保密和速率为
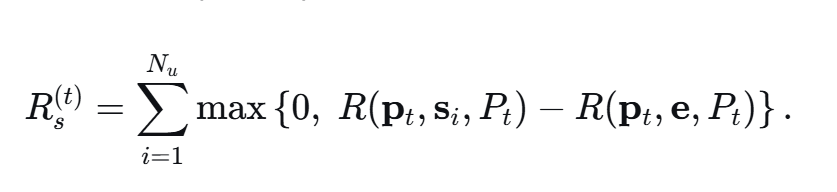
则整个飞行任务期间,系统的平均保密速率为
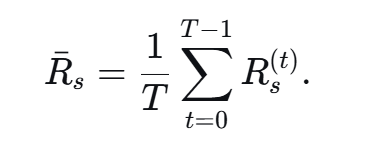
本项目旨在通过联合优化UAV的轨迹和功率分配,最大化UAV飞行期间的系统的平均保密速率,考虑UAV的飞行范围约束,飞行速率约束以及基站功率约束。
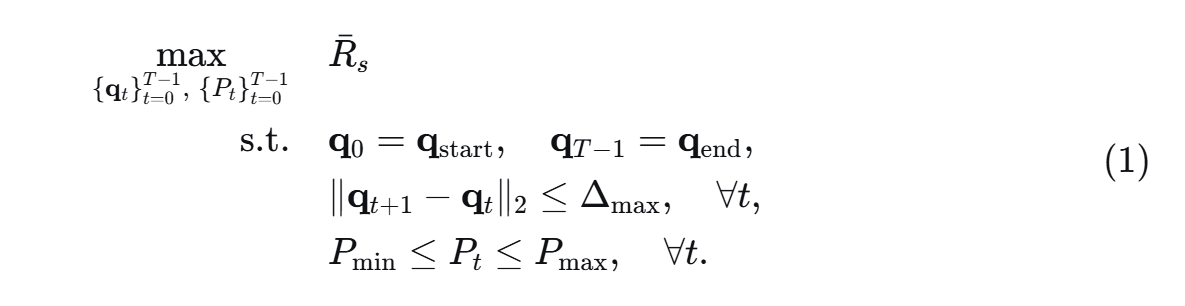
该优化问题具有非凸、高维、约束耦合的特点,难以直接求解全局最优。因此采用将其转化为有监督回归问题,预先生成的启发式专的轨迹与功率作为标签,训练神经网络去模仿那些高保密速率且满足约束的轨迹。
3 基于监督学习的算法设计
3.1、训练数据生成
基于启发式算法生成满足物理约束、且体现安全与性能折衷的参考轨迹和参考功率(可以理解为局部最优解或者可行解),同时计算该参考解对应的保密速率 ,然后将场景中的特征(起点、终点、传感器/窃听者位置、轨迹特征)拼接为输入特征向量,与参考轨迹、参考功率、保密速率一起存储,重复多次生成数据集。


3.2 考虑约束的损失函数设计
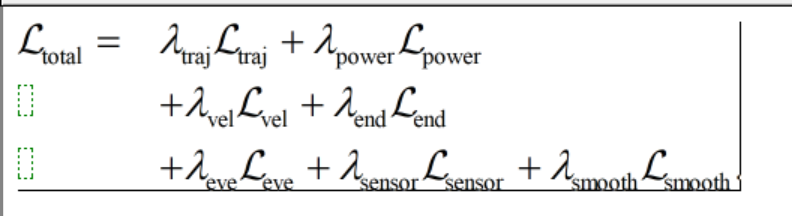
-
轨迹监督损失 L t r a j L_{traj} Ltraj为
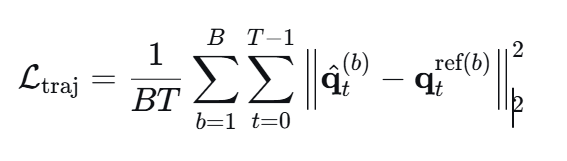
用于迫使网络预测的无人机水平位置 尽可能接近由启发式专家生成的参考轨迹
-
功率监督损失 L p o w e r L_{power} Lpower
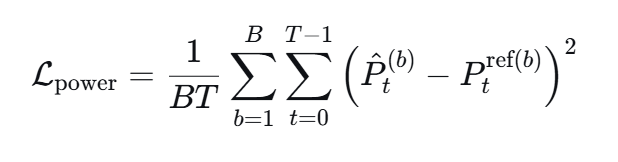
用于让预测的发射功率贴近参考功率
-
速度约束惩罚 L v e l L_{vel} Lvel
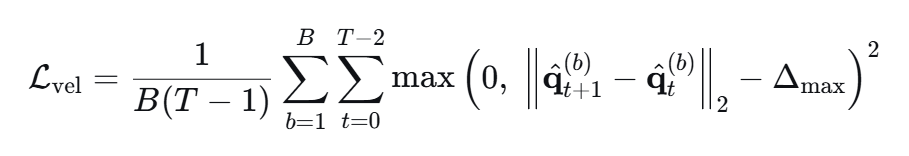
如果相邻时隙的步长超过了最大允许位移 Δmax则施加平方惩罚;否则惩罚为0;
-
端点约束损失 L e n d L_{end} Lend
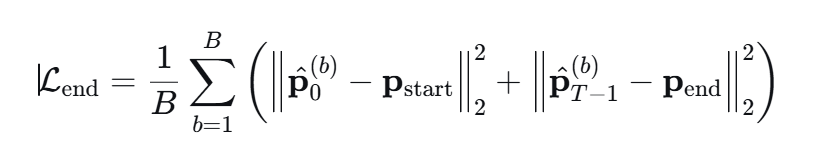
用于惩罚预测轨迹的起始点和终点与固定起点、终点的偏差。确保无人机从规定位置起飞并在任务结束时精确到达终点。该项权重很大,用来确保无人机能够飞到终点;
-
窃听者避让惩罚 L e v e L_{eve} Leve
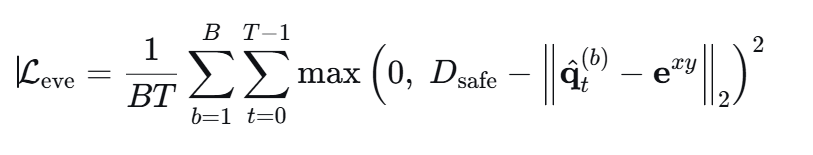
当预测的无人机位置与窃听者的水平距离小于安全阈值 D_safe,惩罚该距离与安全阈值的差的平方;否则为0。
-
接近合法惩罚用户 L s e n s o r L_{sensor} Lsensor
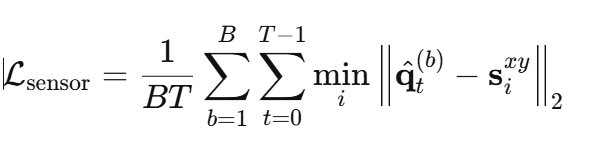
计算每个时刻无人机到最近用户的水平距离,促使无人机尽可能靠近用户,从而增强合法用户的信道质量,提高用户速率。
-
轨迹平滑损失 L s m o o t h L_{smooth} Lsmooth
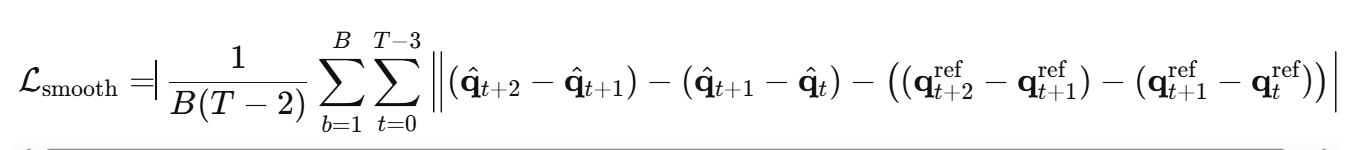
强制无人机预测轨迹的加速度(即相邻位移的变化率)与参考轨迹的加速度保持一致,从而抑制网络输出中出现剧烈抖动或不连续的航点。
即 回归任务为:

| 模块 | 层名称 | 输入维度 | 输出维度 | 激活函数 | 备注 |
|---|---|---|---|---|---|
| 输入层 | 特征拼接 | - | 20 | - | 起点(3)+终点(3)+3个传感器(9)+1个窃听者(3)+曲线尺度(1)+横向偏置(1) = 20 |
| 编码器 | Linear | 20 | 192 | GELU | 全连接 |
| Dropout | 192 | 192 | - | 概率 0.1 | |
| ResidualBlock ×2 | 192 | 192 | GELU | 每个残差块包含:LayerNorm → Linear(192→192) → GELU → Dropout → Linear(192→192) → 残差加和 | |
| LayerNorm | 192 | 192 | - | 最终编码器输出 | |
| 轨迹头 | Linear | 192 | 192 | GELU | - |
| Linear | 192 | 202 | - | 输出 2×101 个值(每个时隙的 x, y) | |
| Reshape | 202 | (101, 2) | - | 变为时隙数×2 | |
| 功率头 | Linear | 192 | 96 | GELU | - |
| Linear | 96 | 101 | Sigmoid | 输出归一化功率(0~1) | |
| 反归一化 | 101 | 101 | - | P_min + output*(P_max-P_min)保证约束满足 |
测试随机产生合法者和窃听者的位置,可以观测到无人机的轨迹为
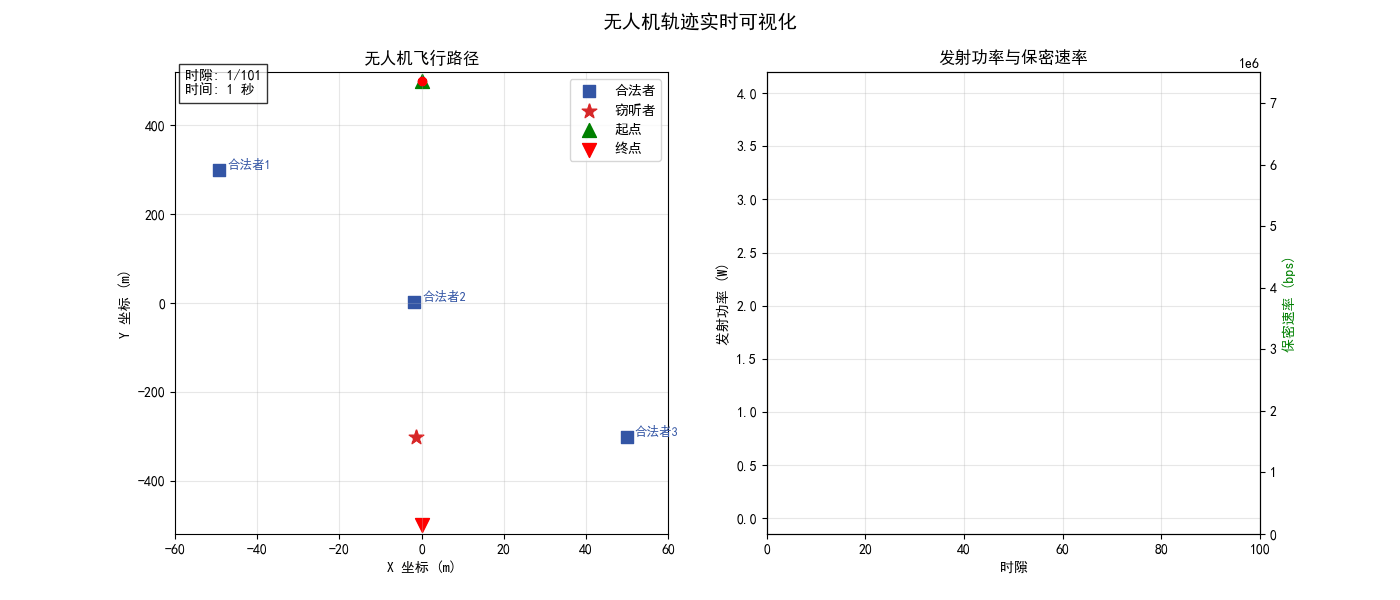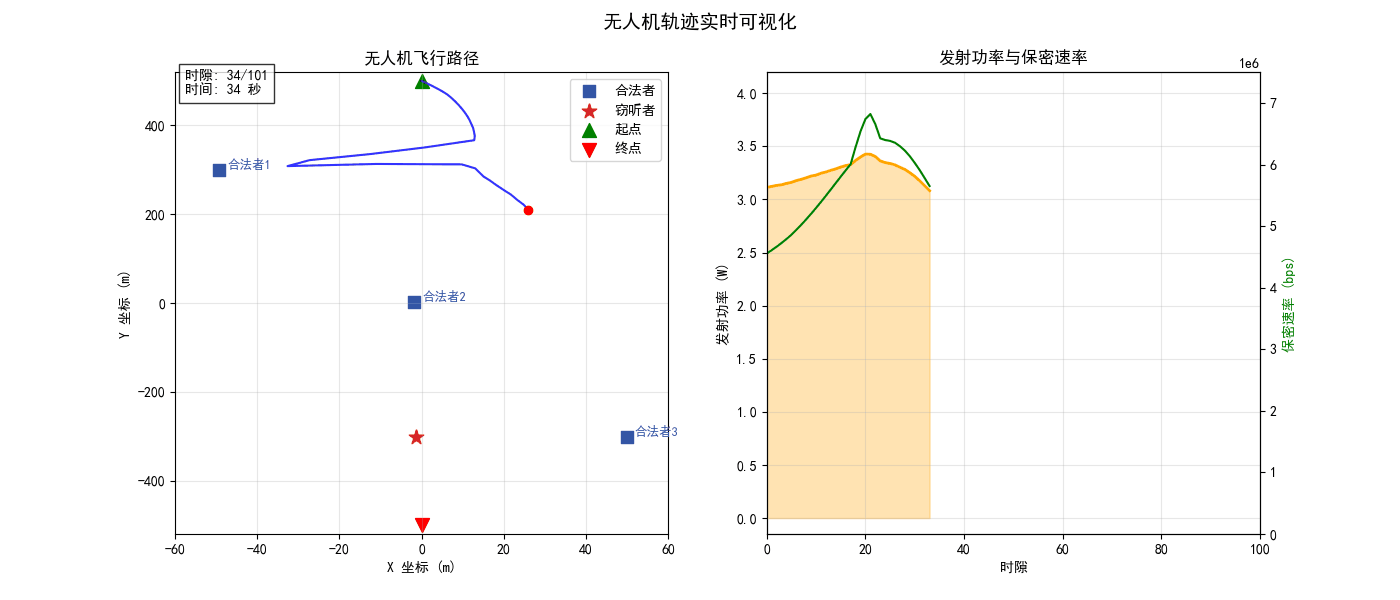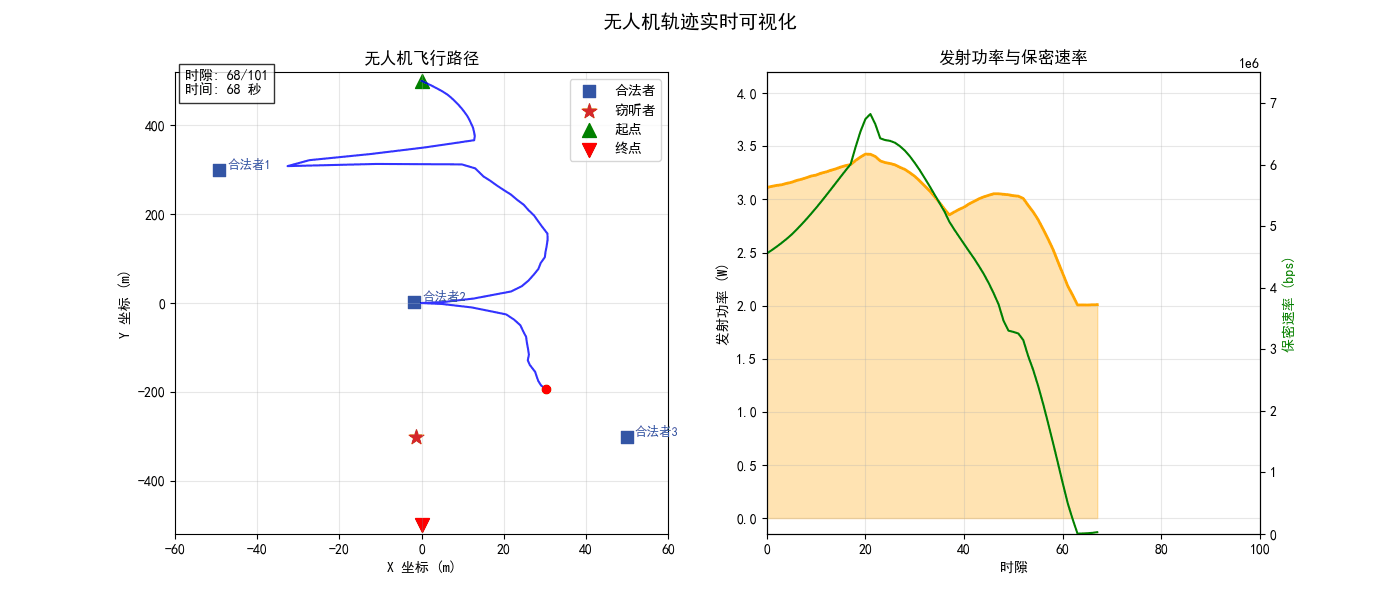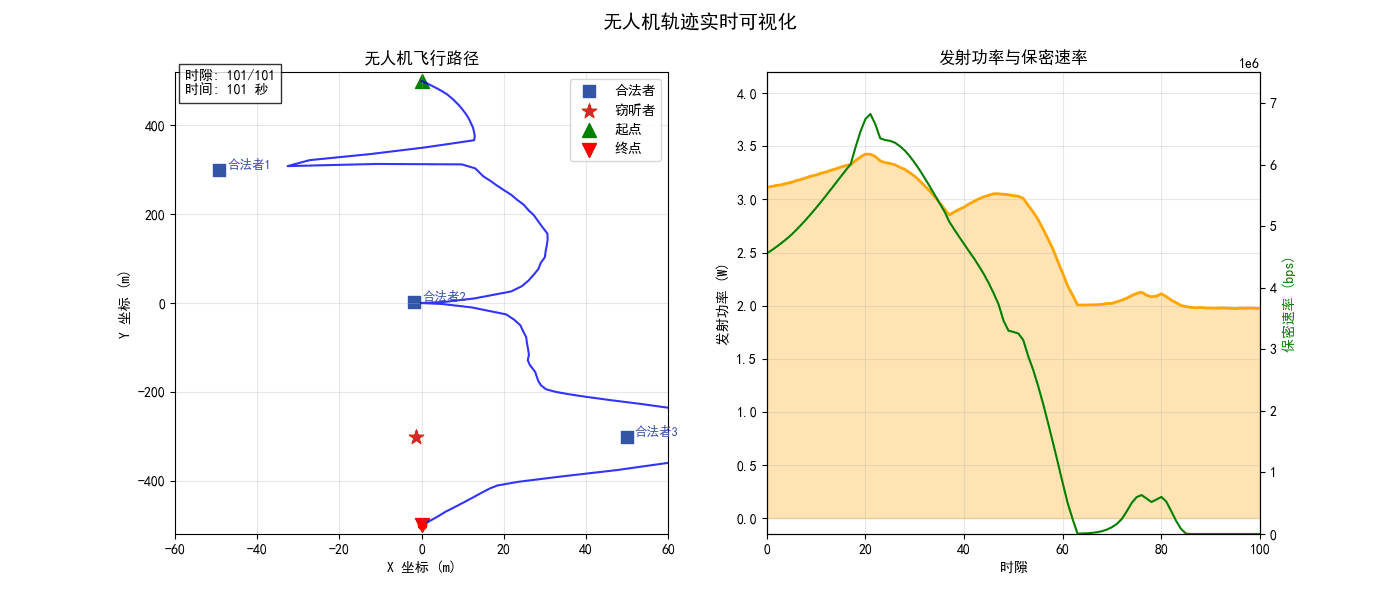
可看到轨迹形状与安全目标的一致性,轨迹会主动接近合法者,偏离窃听者,并最终到达目标。
4 总结
本文通过于将复杂的无人机安全通信优化问题转化为一个有监督的回归任务,并通过启发式数据生成和精心设计的损失函数,使神经网络能够学习到兼顾物理可行性、安全性与通信性能的轨迹‑功率联合策略。然而,该方法也存在内在局限性:参考轨迹的质量直接决定了模型的上限,而启发式规则仅能产生局部次优解。无法保证全局最优;此外,监督学习属于开环映射,缺乏与环境的在线交互,难以适应动态信道变化或未建模的干扰。
后续工作可以从如下角度出发:
- 强化学习替代:将问题建模为马尔可夫决策过程,设计以保密速率为主体的奖励函数,采用SAC等深度强化学习算法直接优化累积奖励,有潜力发现超越启发式专家的策略。
- 不确定性建模:考虑信道估计误差或无人机定位噪声,训练鲁棒性更强的模型,例如在数据生成阶段注入更大的随机扰动或引入对抗训练。
- 在线自适应:结合元学习或模型预测控制,使无人机在飞行中能够根据实时观测调整剩余轨迹,应对突发威胁或环境变化。