零基础入门3D点云深度学习:从PointNet开始,理解3D数据处理
这是一篇写给深度学习新手的文章。上一篇我们学习了从ResNet到YOLOv11的对比,了解了如何处理2D图像。这一篇我们进入3D世界,学习如何处理点云数据。
一、什么是点云?(先搞懂数据)
1.1 从2D到3D
2D图像 :
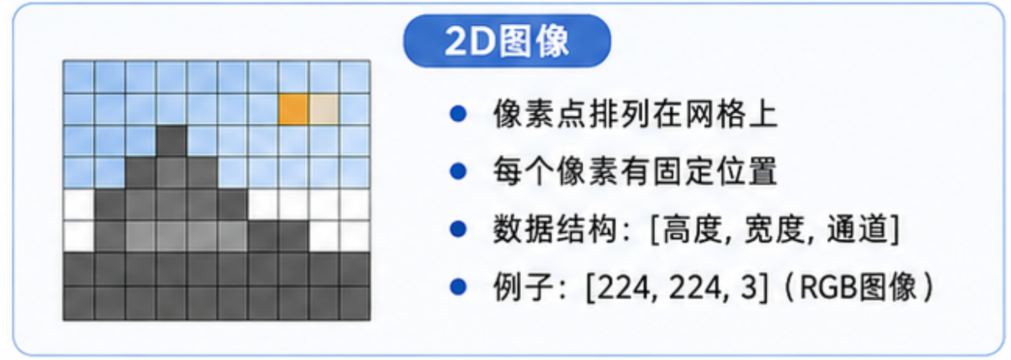
3D点云 :
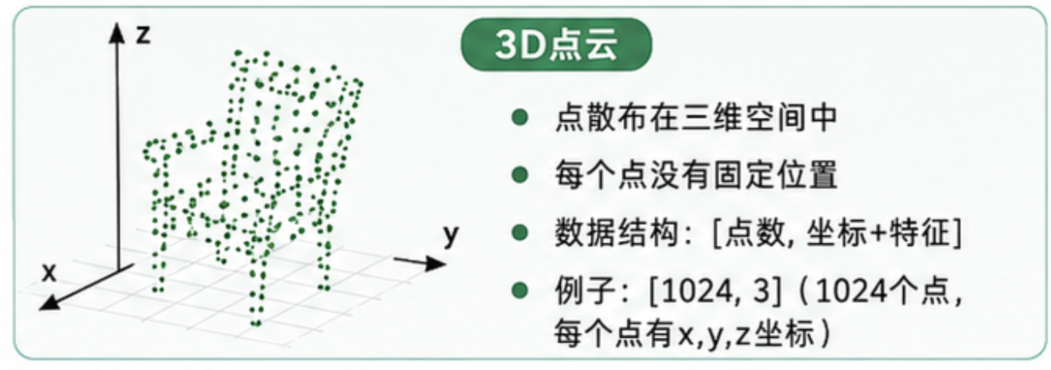
1.2 点云长什么样?
生活中的例子:
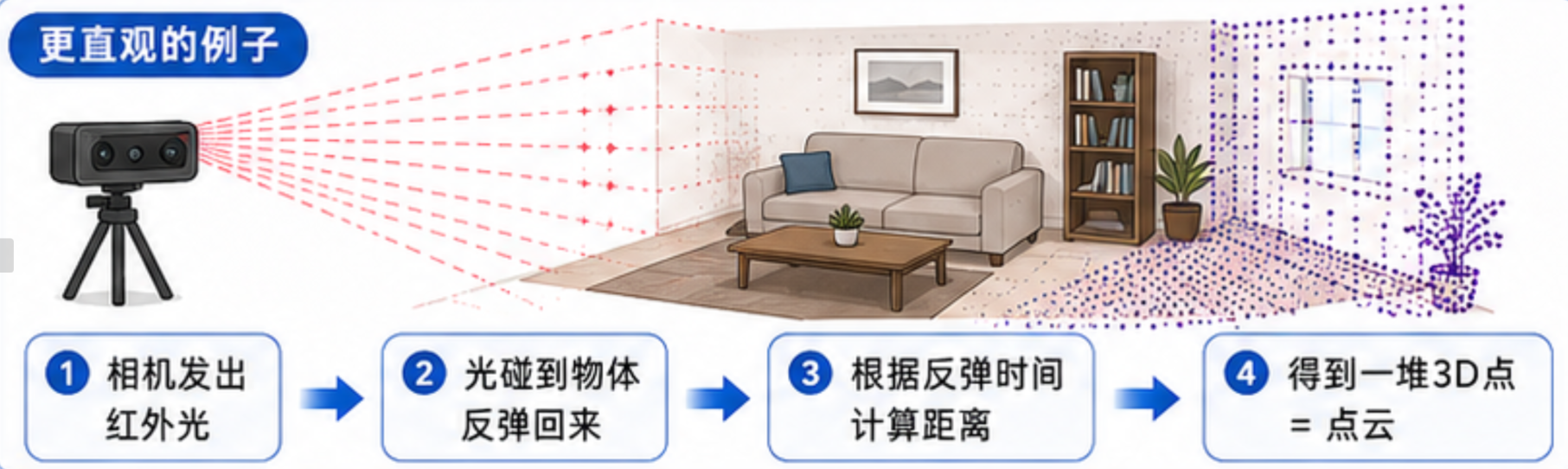
1.3 点云数据的特点
| 特点 | 说明 | 挑战 |
|---|---|---|
| 无序性 | 点的顺序无关紧要 | 网络必须对顺序不敏感 |
| 稀疏性 | 点分布不均匀 | 有些区域密,有些区域稀 |
| 不规则性 | 不像图像那样整齐 | 不能直接用卷积 |
| 点数不固定 | 不同场景点数不同 | 网络必须能处理任意点数 |
最关键的问题:无序性

1.4 点云的应用场景
| 领域 | 应用 | 例子 |
|---|---|---|
| 自动驾驶 | 3D目标检测 | 检测周围的车、行人 |
| 机器人 | 抓取规划 | 识别物体形状,规划抓取 |
| AR/VR | 场景重建 | 把真实世界搬到虚拟世界 |
| 医学 | 器官建模 | 3D重建CT/MRI数据 |
| 建筑 | BIM建模 | 建筑信息模型 |
二、处理点云的传统方法(为什么需要PointNet?)
2.1 传统方法1:体素化(Voxelization)
思路:把点云转换成3D网格(体素)
点云(不规则)→ 体素网格(规则)→ 3D卷积
原始点云: 体素化后:
* ┌───┬───┬───┐
* * │ 0 │ 1 │ 0 │
* * ├───┼───┼───┤
* * │ 1 │ 1 │ 1 │
* ├───┼───┼───┤
│ 0 │ 1 │ 0 │
└───┴───┴───┘优点:
- 可以用3D卷积处理
- 结构规则,易于处理
缺点:
- 计算量大:32×32×32 = 32768个体素
- 信息损失:体素化会丢失细节
- 稀疏性:大部分体素是空的
2.2 传统方法2:投影法(Projection)
思路:把3D点云投影到2D图像
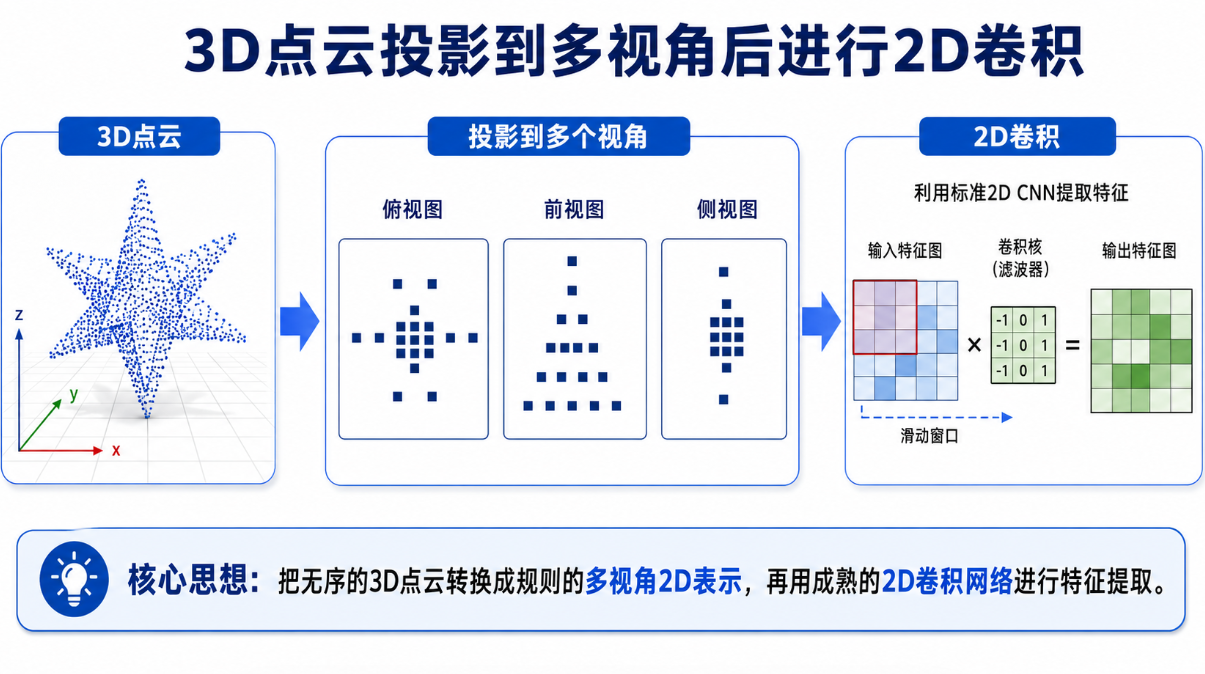
优点:
- 可以用成熟的2D卷积网络
- 计算效率高
缺点:
- 3D信息损失严重
- 视角选择影响性能
2.3 传统方法3:特征工程
思路:手工设计点云特征
对每个点计算:
- 法向量(表面朝向)
- 曲率(弯曲程度)
- 密度(周围点的多少)
- 局部特征(FPFH等)
然后用传统机器学习分类优点:
- 可解释性强
- 不需要大量数据
缺点
- 特征设计困难
- 泛化能力差
- 无法端到端学习
2.4 PointNet的突破
2017年,斯坦福大学的Charles Qi等人提出了PointNet:
直接在原始点云上进行深度学习,不需要体素化或投影。
核心创新:
- 直接处理无序点集
- 对点的顺序不敏感
- 可以学习全局特征
三、PointNet的核心思想(最重要的部分)
3.1 关键问题:如何处理无序数据?
问题:
输入:[点1, 点2, 点3] 和 [点3, 点1, 点2]
期望:相同的输出(因为是同一个物体)
传统网络:
- 全连接网络:对顺序敏感,输出不同
- 卷积网络:需要规则网格,无法直接处理
怎么办?3.2 解决方案:对称函数
什么是对称函数?
对称函数:输入顺序不影响输出
例子:
- 求和:1+2+3 = 3+1+2 = 6
- 求最大值:max(1,2,3) = max(3,1,2) = 3
- 求平均:avg(1,2,3) = avg(3,1,2) = 2
这些函数对输入顺序不敏感!PointNet的核心思想:
1. 对每个点独立处理(共享权重)
2. 用对称函数聚合所有点的信息
具体步骤:
[点1, 点2, 点3, ..., 点N]
↓
[特征1, 特征2, 特征3, ..., 特征N] ← 对每个点提取特征
↓
max(特征1, 特征2, ..., 特征N) ← 用最大值聚合
↓
全局特征 ← 对顺序不敏感3.3 图解PointNet的核心流程
输入点云 [N×3]
(N个点,每个点有x,y,z坐标)
│
↓
┌─────────────────────────────────────┐
│ 对每个点独立处理(共享权重) │
│ │
│ 点1 → MLP → 特征1 │
│ 点2 → MLP → 特征2 │
│ 点3 → MLP → 特征3 │
│ ... │
│ 点N → MLP → 特征N │
└─────────────────────────────────────┘
│
↓
[N×D] 特征矩阵
(N个点,每个点D维特征)
│
↓
┌─────────────────────────────────────┐
│ 对称函数:最大值池化 │
│ │
│ max(特征1, 特征2, ..., 特征N) │
│ │
│ = 全局特征 [1×D] │
└─────────────────────────────────────┘
│
↓
分类头(MLP)
│
↓
输出:类别概率3.4 为什么这样有效?
关键洞察1:每个点独立处理
python
# 对每个点用相同的MLP
for point in point_cloud:
feature = MLP(point) # 共享权重!好处:
- 不依赖点的顺序
- 可以处理任意数量的点
- 参数量固定
关键洞察2:最大值池化是对称函数
python
# 最大值池化
global_feature = torch.max(all_features, dim=0)好处:
- 对顺序不敏感
- 保留最显著的特征
- 计算简单高效
关键洞察3:MLP可以学习复杂特征
python
# 多层感知机
feature = MLP(point)
# 可以学习:法向量、曲率、局部结构等四、PointNet的网络结构详解
4.1 整体架构
输入:点云 [N×3]
│
↓
┌─────────────────────────────────────┐
│ 输入变换网络(T-Net) │
│ 学习一个3×3变换矩阵 │
│ 对齐输入点云 │
└─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────┐
│ 共享MLP(64, 64) │
│ 对每个点提取特征 │
└─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────┐
│ 特征变换网络(T-Net) │
│ 学习一个64×64变换矩阵 │
│ 对齐特征空间 │
└─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────┐
│ 共享MLP(64, 128, 1024) │
│ 提取更高维特征 │
└─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────┐
│ 最大值池化 │
│ 得到全局特征 [1×1024] │
└─────────────────────────────────────┘
│
↓
┌─────────────────────────────────────┐
│ 分类MLP(512, 256, K) │
│ K = 类别数 │
└─────────────────────────────────────┘
│
↓
输出:类别概率 [1×K]4.2 T-Net:输入变换网络
问题:点云可能有不同的旋转、平移
同一个物体:
- 位置不同(平移)
- 朝向不同(旋转)
网络应该识别出它们是同一个物体解决方案:学习一个变换矩阵,对齐点云
python
class TNet(nn.Module):
"""变换网络,学习3×3或64×64的变换矩阵"""
def __init__(self, dim=3):
super().__init__()
self.dim = dim
# 共享MLP
self.mlp = nn.Sequential(
nn.Linear(dim, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
)
# 最大值池化后的全连接层
self.fc = nn.Sequential(
nn.Linear(1024, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, dim * dim),
)
# 初始化为单位矩阵
self.fc[-1].weight.data.zero_()
self.fc[-1].bias.data.copy_(torch.eye(dim).flatten())
def forward(self, x):
"""
x: [B, N, D] - batch×点数×维度
返回: [B, D, D] - 变换矩阵
"""
B, N, D = x.shape
# 对每个点提取特征
x = x.view(B * N, D)
x = self.mlp(x)
x = x.view(B, N, -1)
# 最大值池化
x = torch.max(x, dim=1)[0] # [B, 1024]
# 生成变换矩阵
x = self.fc(x) # [B, D*D]
x = x.view(B, self.dim, self.dim) # [B, D, D]
return x为什么初始化为单位矩阵?
python
# 初始化时:
# 变换矩阵 = 单位矩阵
# 变换后:x' = x × I = x
# 即:不做任何变换
# 训练后:
# 网络学习到最优的变换
# 对齐不同姿态的点云4.3 共享MLP:逐点特征提取
什么是共享MLP?
共享MLP = 所有点用相同的权重
点1 → MLP(权重W) → 特征1
点2 → MLP(权重W) → 特征2
点3 → MLP(权重W) → 特征3
权重W是共享的,不依赖于点的顺序代码实现:
python
class SharedMLP(nn.Module):
"""共享MLP,对每个点独立处理"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(in_channels, out_channels),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
)
def forward(self, x):
"""
x: [B, N, C] - batch×点数×通道
返回: [B, N, out_channels]
"""
B, N, C = x.shape
# 展平处理
x = x.view(B * N, C) # [B*N, C]
x = self.mlp(x) # [B*N, out_channels]
x = x.view(B, N, -1) # [B, N, out_channels]
return x为什么用BatchNorm?
python
# 点云数据的特点:
# - 不同点的坐标范围可能差异大
# - 需要规范化处理
# BatchNorm的作用:
# - 稳定训练
# - 加速收敛
# - 允许更大的学习率4.4 最大值池化:聚合全局信息
为什么用最大值池化而不是平均池化?
最大值池化:保留最显著的特征
平均池化:平滑所有特征
对于分类任务:
- 我们关心"有没有某个特征"
- 而不是"平均有多少"
例子:
- 检测"有没有轮子"
- 最大值池化:只要有轮子特征就行
- 平均池化:可能被其他点稀释代码实现:
python
def max_pool(x):
"""
x: [B, N, D] - batch×点数×特征维度
返回: [B, D] - 全局特征
"""
# 对点维度取最大值
global_feature = torch.max(x, dim=1)[0] # [B, D]
return global_feature4.5 完整的PointNet代码
python
import torch
import torch.nn as nn
class PointNet(nn.Module):
"""完整的PointNet网络"""
def __init__(self, num_classes=40):
"""
num_classes: 分类类别数
默认40是ModelNet40数据集的类别数
"""
super().__init__()
# 输入变换网络(3×3)
self.input_transform = TNet(dim=3)
# 第一组共享MLP
self.mlp1 = nn.Sequential(
nn.Linear(3, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
)
# 特征变换网络(64×64)
self.feature_transform = TNet(dim=64)
# 第二组共享MLP
self.mlp2 = nn.Sequential(
nn.Linear(64, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
)
# 分类头
self.classifier = nn.Sequential(
nn.Linear(1024, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, num_classes),
)
def forward(self, x):
"""
x: [B, N, 3] - batch×点数×坐标
返回: [B, num_classes] - 分类logits
"""
B, N, _ = x.shape
# 1. 输入变换
trans_input = self.input_transform(x) # [B, 3, 3]
x = torch.bmm(x, trans_input) # [B, N, 3]
# 2. 第一组MLP
x = self.mlp1(x.view(B * N, -1)).view(B, N, -1) # [B, N, 64]
# 3. 特征变换
trans_feat = self.feature_transform(x) # [B, 64, 64]
x = torch.bmm(x, trans_feat) # [B, N, 64]
# 4. 第二组MLP
x = self.mlp2(x.view(B * N, -1)).view(B, N, -1) # [B, N, 1024]
# 5. 最大值池化
x = torch.max(x, dim=1)[0] # [B, 1024]
# 6. 分类
x = self.classifier(x) # [B, num_classes]
return x, trans_input, trans_feat4.6 代码逐行解释
输入变换:
python
# 学习一个3×3变换矩阵
trans_input = self.input_transform(x) # [B, 3, 3]
# 应用变换:对每个点进行旋转/平移
x = torch.bmm(x, trans_input) # [B, N, 3]
# bmm = batch matrix multiplication
# 对batch中的每个样本分别做矩阵乘法第一组MLP:
python
# 对每个点提取64维特征
x = self.mlp1(x.view(B * N, -1)).view(B, N, -1)
# x.view(B * N, -1): 展平成[B*N, 3]
# mlp1: 提取特征 -> [B*N, 64]
# .view(B, N, -1): 恢复形状 -> [B, N, 64]特征变换:
python
# 学习一个64×64变换矩阵
trans_feat = self.feature_transform(x) # [B, 64, 64]
# 应用变换
x = torch.bmm(x, trans_feat) # [B, N, 64]最大值池化:
python
# 对点维度取最大值
x = torch.max(x, dim=1)[0] # [B, 1024]
# [0]是因为torch.max返回(values, indices)五、PointNet的变体和改进
5.1 PointNet++:层次化特征学习
PointNet的问题:
- 没有局部特征
- 对噪声敏感
- 无法处理密度不均匀的点云
PointNet++的改进:
PointNet:
点云 → 全局特征
PointNet++:
点云 → 局部特征 → 全局特征
↓
层次化聚合核心思想:
1. 将点云分成多个局部区域
2. 对每个局部区域用PointNet
3. 逐层聚合,从小局部到大局部
就像CNN:
- 浅层:小感受野,提取边缘
- 深层:大感受野,提取整体5.2 点云分割任务
分类 vs 分割:
分类:整个点云 → 一个类别
分割:每个点 → 一个类别
分类:这是什么?→ 椅子
分割:哪些点是椅腿?哪些点是椅面?PointNet用于分割:
python
class PointNetSeg(nn.Module):
"""PointNet分割网络"""
def __init__(self, num_classes=50):
super().__init__()
# 编码器(和分类一样)
self.input_transform = TNet(dim=3)
self.mlp1 = nn.Sequential(
nn.Linear(3, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
)
self.feature_transform = TNet(dim=64)
self.mlp2 = nn.Sequential(
nn.Linear(64, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
)
# 分割头
self.seg_head = nn.Sequential(
nn.Linear(1024 + 64, 512), # 全局特征+局部特征
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, num_classes),
)
def forward(self, x):
B, N, _ = x.shape
# 编码器
trans_input = self.input_transform(x)
x = torch.bmm(x, trans_input)
x = self.mlp1(x.view(B * N, -1)).view(B, N, -1)
local_features = x # 保存局部特征
trans_feat = self.feature_transform(x)
x = torch.bmm(x, trans_feat)
x = self.mlp2(x.view(B * N, -1)).view(B, N, -1)
# 全局特征
global_feature = torch.max(x, dim=1)[0] # [B, 1024]
# 拼接全局和局部特征
global_feature = global_feature.unsqueeze(1).repeat(1, N, 1) # [B, N, 1024]
x = torch.cat([local_features, global_feature], dim=-1) # [B, N, 1024+64]
# 分割
x = self.seg_head(x.view(B * N, -1)).view(B, N, -1) # [B, N, num_classes]
return x关键点:
- 分割需要局部特征
- 拼接全局和局部特征
- 对每个点独立分类
六、PointNet的优缺点分析
6.1 优点
| 优点 | 说明 |
|---|---|
| 端到端学习 | 直接从原始点云学习特征 |
| 对顺序不敏感 | 通过最大值池化实现 |
| 参数效率高 | 共享权重,参数量小 |
| 可处理任意点数 | 不需要固定输入大小 |
| 理论优雅 | 有严格的数学证明 |
6.2 缺点
| 缺点 | 说明 |
|---|---|
| 缺乏局部特征 | 只有全局特征 |
| 对噪声敏感 | 没有局部平滑 |
| 密度不敏感 | 不同密度区域同等对待 |
| 特征表达能力有限 | 1024维可能不够 |
6.3 PointNet++的改进
PointNet:
点 → 全局特征 → 分类
PointNet++:
点 → 局部特征 → 全局特征 → 分类
↑
层次化聚合
密度自适应七、常见问题解答(FAQ)
Q1: 为什么用最大值池化而不是平均池化?
答:
最大值池化:保留最显著的特征
- "有没有轮子?" 有就行,不需要知道有多少
- 对噪声更鲁棒
平均池化:平滑所有特征
- "平均有多少轮子?" 可能被稀释
- 对噪声更敏感
实验表明:最大值池化效果更好Q2: T-Net的作用是什么?
答:
T-Net学习一个变换矩阵,对齐点云
作用:
1. 解决旋转不变性
- 同一个物体,不同朝向
- T-Net旋转到标准姿态
2. 解决平移不变性
- 同一个物体,不同位置
- T-Net平移到原点
3. 提高泛化能力
- 减少数据增强的需求Q3: PointNet能处理多少个点?
答:
理论上:任意数量
实际上:受GPU内存限制
通常:
- 训练:1024或2048个点
- 推理:可以更多,但计算量增加
如果点数太多:
- 随机采样
- 最远点采样(FPS)Q4: PointNet和CNN有什么区别?
答:
CNN:
- 处理规则网格数据(图像)
- 卷积核提取局部特征
- 对位置敏感
PointNet:
- 处理无序点集
- 共享MLP提取逐点特征
- 对位置不敏感
关键区别:
CNN利用了数据的规则结构
PointNet没有这个假设,更通用Q5: 如何提高PointNet的性能?
答:
1. 数据增强
- 随机旋转
- 随机平移
- 随机缩放
- 随机丢点
2. 使用PointNet++
- 层次化特征
- 密度自适应
3. 增加点数
- 更多点 = 更多细节
4. 后处理
- 投票机制
- 集成学习八、PointNet在3D占用感知中的应用
8.1 什么是3D占用感知?
3D占用感知:预测3D空间中每个体素是否被占用
输入:点云或图像
输出:3D占用网格
应用:
- 自动驾驶:检测周围的障碍物
- 机器人:规划避障路径8.2 PointNet如何用于占用感知?
python
class OccupancyPointNet(nn.Module):
"""用于占用预测的PointNet变体"""
def __init__(self, num_classes=2): # 空/占用
super().__init__()
# PointNet编码器
self.encoder = PointNetEncoder()
# 3D解码器
self.decoder = nn.Sequential(
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, num_classes),
)
def forward(self, points, query_points):
"""
points: [B, N, 3] - 输入点云
query_points: [B, M, 3] - 查询点
返回: [B, M, num_classes] - 占用预测
"""
# 提取全局特征
global_feature = self.encoder(points) # [B, 1024]
# 对每个查询点预测
B, M, _ = query_points.shape
global_feature = global_feature.unsqueeze(1).repeat(1, M, 1) # [B, M, 1024]
# 拼接
x = torch.cat([query_points, global_feature], dim=-1) # [B, M, 1024+3]
# 解码
occupancy = self.decoder(x) # [B, M, num_classes]
return occupancy8.3 从PointNet到PointPillars
PointNet:通用点云特征提取
↓
改进1:局部特征聚合(PointNet++)
↓
改进2:实时性优化(PointPillars)
↓
应用:自动驾驶3D检测九、总结:PointNet的精髓
9.1 核心思想
- 直接处理原始点云:不需要体素化或投影
- 对称函数:用最大值池化处理无序性
- 共享权重:对每个点独立处理
- 端到端学习:自动学习特征
9.2 一句话总结
PointNet通过共享MLP和最大值池化,让深度学习直接在无序点云上工作。
9.3 关键创新
| 创新 | 作用 |
|---|---|
| 共享MLP | 逐点特征提取 |
| 最大值池化 | 聚合全局特征,处理无序性 |
| T-Net | 学习变换矩阵,对齐点云 |
| 端到端训练 | 自动学习最优特征 |
9.4 下一步学习
- PointNet++:层次化特征学习
- VoxelNet:体素化点云处理
- PointPillars:实时3D检测
附录:关键术语表
| 术语 | 英文 | 含义 |
|---|---|---|
| 点云 | Point Cloud | 3D空间中的点集合 |
| 体素 | Voxel | 3D像素,体积元素 |
| 对称函数 | Symmetric Function | 输入顺序不影响输出 |
| 共享权重 | Shared Weights | 所有点用相同的参数 |
| 最大值池化 | Max Pooling | 取最大值作为输出 |
| T-Net | Transformation Network | 学习变换矩阵 |
| 局部特征 | Local Feature | 单个点或邻域的特征 |
| 全局特征 | Global Feature | 整个点云的特征 |
下期预告:《从PointPillars入门3D目标检测------如何实时检测周围的车辆?》
转载请注明出处