JibarOS --- 基于 Android 16 的AICore开源实现方案,将端侧 AI 推理内置为平台级共享服务。麻雀虽小五脏俱全,OEM厂商可以直接拿来做POC了。
1. 问题:端侧 AI 的「应用孤岛」困局
在当前 Android 生态中,每个想用 AI 的应用都在重复同一件事:自带模型 + 运行时。 这种做法带来以下问题:
- 存储浪费 --- 多个应用捆绑功能相近的模型,用户设备上存着大量重复的模型权重文件
- 内存压力 --- 每个应用独立加载模型到内存,中端设备上两个常驻 LLM 就可能触及 OOM
- 调度失控 --- 各应用自行管理模型生命周期和推理调度,彼此互不协调,争抢 GPU/NPU 资源时无法做全局优先级决策
2. 行业背景:Google AICore
Google 在 Android 14 引入了 AICore ,在 I/O 2026 上将 Android 重新定义为 "智能系统(Intelligence System)",AICore 作为底层推理引擎的地位进一步强化。
2.1 AICore 是什么
AICore 是 Google 提供的系统级 AI 服务 ,以 com.google.android.aicore 为包名通过 Play Store 分发,负责 Gemini Nano 模型的下载、版本管理和推理执行。应用不需要自带模型,通过 ML Kit GenAI APIs 调用即可------AICore 在系统侧统一处理模型加载、硬件加速(NPU/GPU/CPU)和内存管理。
AICore 架构 (来源:Android 官方文档)如下,核心设计:
- 模型实例共享 --- 模型在系统进程中仅加载一次,多应用共享,避免每个 App 各自打包数 GB 的模型
- 模型与应用解耦 --- 模型由 AICore 统一管理下载和版本控制,应用 APK 不包含模型文件
- 独立更新 --- AICore 通过 Play Store 分发,模型可独立于系统 OTA 更新
- 统一调度管控 - 官方文档并未提及这部分,但从技术架构角度推测,这部分是必不可少的
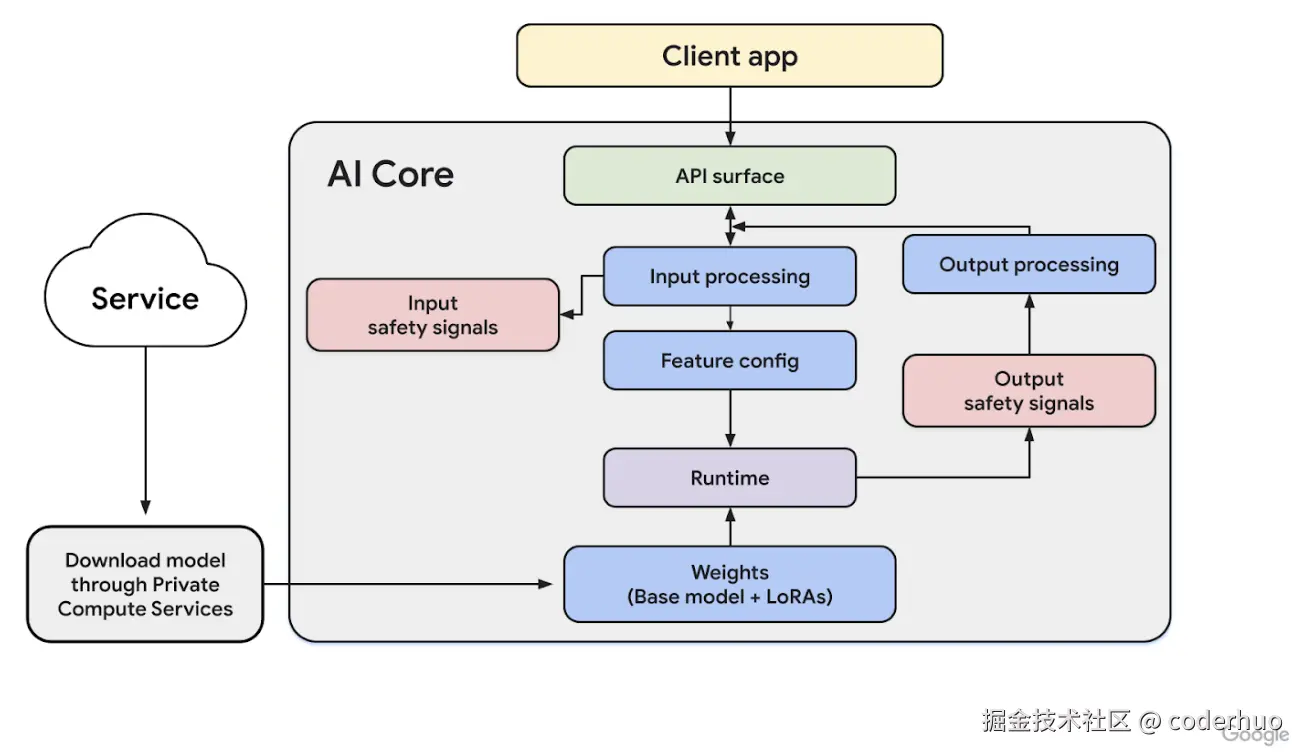
AICore 对外提供通用/专用两类接口(通过 ML Kit GenAI APIs):
- 其中 Prompt API 是通用接口,开发者可以发送任意自然语言 prompt 获取自由文本回复,类似云端 Gemini API 的端侧版本
- 其余四个是 Google 基于此预封装的专用接口,针对特定任务做了输入输出格式优化,开箱即用
Prompt API是今年新增的,估计Google也意识到原来的专用接口覆盖的业务面太窄了,限制了AICore的使用场景。
| 能力 | 说明 | 类型 |
|---|---|---|
| Prompt API (Alpha) | 通用推理接口,可发送任意 prompt | 通用接口 |
| Summarization | 文本摘要生成 | 专用接口 |
| Proofreading | 语法校对 | 专用接口 |
| Rewriting | 文本改写 | 专用接口 |
| Image Description | 图像内容描述 | 专用接口 |
2.2 AICore 局限性
- 闭源:源代码不公开,OEM 和开发者无法自行修改或定制
- 能力开放受限:部分 API 仍处于 Alpha/Preview 阶段,能力扩展节奏由 Google 控制
- 模型不可替换:仅支持 Google 提供的 Gemini Nano,OEM 无法更换模型
- 硬件门槛:仅在特定旗舰 SoC 上可用
- 依赖 GMS:AICore 通过 Google Play Services 分发,未预装 GMS 的设备无法使用
上述局限性使得 AICore 的实际应用范围受到较大限制------特别是对于国内厂商,设备普遍不预装 GMS,AICore 方案基本不可用。
3. JibarOS 解决方案
JibarOS 整体思路借鉴 AICore,其核心主张:
端侧 AI 推理应该是操作系统的基础设施,而非应用的私有资产。
简单说:操作系统统一管理 AI 模型,应用只管调接口用 。模型加载、内存分配、推理调度、权限控制全部由系统完成,应用通过 Binder 调用获取 AI 能力,就像调系统服务一样。即一次加载,多方服务(Load once, serve many)。 应用只需调用:
kotlin
OpenIntelligence.text.completeStream("用一句话总结这段文字:...")
.collect { chunk -> print(chunk.text) }系统运行时自动处理:选哪个模型、用哪个上下文、请求优先级、内存预算------应用无需关心。
这一思路与 Google AICore 的架构一脉相承,但一个封闭、一个开放。下表展示了两者的异同:
| 维度 | AICore | JibarOS |
|---|---|---|
| 源代码 | 闭源 | Apache 2.0 开源 |
| 模型选择 | Google 精选(Gemini Nano) | 任意 GGUF / ONNX / GGUF mtmd |
| OEM 接入 | 需 Google 审批 | 无门槛 |
| 应用访问 | 依赖 GMS,部分 API 仍为 Alpha | 标准 Android 权限 oir.permission.USE_* |
| 推理引擎 | 单一 Google 运行时 (TFLite),无法定制 | llama.cpp / whisper.cpp / ONNX Runtime 等,可定制 |
| API能力 | 精选集(5 种) | 12 种能力,OEM 可扩展 |
| 硬件要求 | 特定旗舰 SoC | 任意 ARM/x86 设备 |
| 模型更新 | Play System Updates | 构建时预置于系统分区 |
JibarOS不具备模型独立更新能力,这点和AICore相比是个弱项。
4. JibarOS 架构
4.1 整体分层
JibarOS 的 AI 基础设施由三层组成,通过 Binder IPC 连接,各层职责如下:
应用层 --- oir-sdk (Kotlin)
- 提供
OpenIntelligence.text/.audio/.vision顶层 API - 基于 Kotlin 协程,支持流式输出(模型边生成、应用边接收)
OIRService --- system_server 中的 Java 服务
- 随
system_server启动,注册到ServiceManager - 通过 Android 标准权限模型控制访问(
oir.permission.USE_TEXT等) - 每 UID 令牌桶限流,防止单个应用过度消耗推理资源
- 维护能力注册表:解析
capabilities.xml+ OEM 扩展配置 - 将请求通过
IOirWorkerAIDL 接口转发给 oird
oird --- C++ 原生守护进程
- 由
init通过.rc文件启动,SELinux 域u:r:oird:s0 - 持有所有推理引擎实例,管理模型的加载/卸载/驻留
- 预创建推理上下文池(
ContextPool),请求来了直接借用,用完归还,避免重复创建开销 - 内存管理:跟踪每个模型和对话缓存占了多少内存,内存不够时自动释放最久没用的
- 优先级调度:音频请求优先级最高,文本和视觉请求次之
scss
┌─────────────────────────────────────────────────────────────┐
│ 应用层 (any UID) │
│ │
│ OpenIntelligence.text.completeStream(...) │
│ OpenIntelligence.audio.transcribeStream(...) │
│ OpenIntelligence.vision.describe(...) │
│ OpenIntelligence.vision.detect(...) │
│ │ │
│ ▼ Binder IPC │
├─────────────────────────────────────────────────────────────┤
│ OIRService (system_server 进程) │
│ ├─ 权限检查:USE_TEXT / USE_AUDIO / USE_VISION │
│ ├─ Per-UID 令牌桶限流 │
│ ├─ 能力注册表 (capabilities.xml + OEM 扩展配置) │
│ └─ IOirWorker AIDL │
│ │ │
│ ▼ Binder IPC │
├─────────────────────────────────────────────────────────────┤
│ oird (原生守护进程, /system_ext/bin/oird) │
│ ├─ 共享模型驻留 --- 每能力仅加载一次 │
│ ├─ ContextPool / WhisperPool │
│ ├─ KV 缓存 + 内存核算 + LRU 驱逐 │
│ └─ 优先级调度 │
├─────────────────────────────────────────────────────────────┤
│ 推理引擎 │
│ ┌───────────┬──────────────┬───────────────┬──────────┐ │
│ │ llama.cpp │ whisper.cpp │ ONNX Runtime │ libmtmd │ │
│ │ (GGUF) │ (.bin) │ (.onnx) │ (VLMs) │ │
│ └───────────┴──────────────┴───────────────┴──────────┘ │
└─────────────────────────────────────────────────────────────┘4.2 一次推理请求的完整旅程
以 OpenIntelligence.text.completeStream("Hello") 为例:
scss
1. App 调用 oir-sdk API
└─ SDK 通过 Binder 向 OIRService 发起请求
2. OIRService 接收请求
├─ 检查调用方是否持有 oir.permission.USE_TEXT
├─ 令牌桶限流检查
├─ 查询能力注册表:text.complete → 对应后端 + 模型路径
└─ 通过 IOirWorker AIDL 转发到 oird
3. oird 处理请求
├─ 检查模型是否已加载(共享驻留)
│ ├─ 未加载 → 加载模型,检查内存预算,必要时 LRU 驱逐
│ └─ 已加载 → 复用
├─ 从 ContextPool 获取可用 slot
│ ├─ 有空闲 slot → 分配
│ └─ 无空闲 → 按优先级排队等待
├─ 在 slot 的独立 KV 缓存中执行推理
└─ 逐 token 通过 Binder 流式回传
4. App 接收 TokenStream
└─ SDK 的 Flow<OirChunk> 逐 chunk emit(流式输出)5. 能力配置
JibarOS 定义了 12 种标准化的端侧 AI 能力,覆盖文本、音频、视觉三大模态。应用面向能力编程,不关心底层用了什么模型或后端。
这里估计还是follow AICore去年的设计思路,提供的都是专用接口,没有提供通用推理接口,
5.1 文本能力 (Text)
| 能力 | 说明 | 参考推理后端 | 输出类型 | 权限 |
|---|---|---|---|---|
text.complete |
通用文本生成,流式输出 | Qwen 2.5 0.5B Q4_K_M (llama.cpp) | TokenStream | USE_TEXT |
text.translate |
翻译,复用同一 LLM | 与 text.complete 共享模型 | TokenStream | USE_TEXT |
text.embed |
文本嵌入向量 | all-MiniLM-L6-v2 Q8_0 (llama.cpp) | Vector | USE_TEXT |
text.classify |
文本分类 | OEM 提供 ONNX 分类器 | Vector | USE_TEXT |
text.rerank |
检索结果重排序 | OEM 提供 (ms-marco-MiniLM 风格) | Vector | USE_TEXT |
5.2 音频能力 (Audio)
| 能力 | 说明 | 参考推理后端 | 输出类型 | 权限 |
|---|---|---|---|---|
audio.transcribe |
语音转文字 | whisper-tiny.en Q5 (whisper.cpp) | TokenStream | USE_AUDIO |
audio.synthesize |
文字转语音 | OEM 提供 Piper voice + G2P (ONNX) | AudioStream | USE_AUDIO |
audio.vad |
语音活动检测 | Silero VAD (ONNX Runtime) | RealtimeBoolean | USE_AUDIO |
5.3 视觉能力 (Vision)
| 能力 | 说明 | 参考推理后端 | 输出类型 | 权限 |
|---|---|---|---|---|
vision.embed |
图像嵌入向量 | SigLIP-base-patch16-224 (ONNX) | Vector | USE_VISION |
vision.describe |
图像内容描述 | OEM VLM via libmtmd (LLaVA/SmolVLM) | TokenStream | USE_VISION |
vision.detect |
目标检测 | RT-DETR-R50vd-COCO (ONNX) | BoundingBoxes | USE_VISION |
vision.ocr |
OCR 文字识别 | OEM 提供 det+rec pair (ONNX) | BoundingBoxes | USE_VISION |
5.4 参考模型预装情况
系统构建时 oir-vendor-models 预装了 4 个宽松许可模型,覆盖 5/12 种能力:
| 模型 | 许可证 | 覆盖能力 |
|---|---|---|
| Qwen 2.5 0.5B Q4_K_M | Apache 2.0 | text.complete, text.translate |
| all-MiniLM-L6-v2 Q8_0 | MIT | text.embed |
| whisper-tiny.en Q5 | MIT | audio.transcribe |
| SigLIP-base-patch16-224 | Apache 2.0 | vision.embed |
为了在中低端设备运行,这些预装的模型有些能力很弱,OEM可根据后面的章节按需替换。
其余 7 种能力(text.classify、text.rerank、audio.synthesize、audio.vad、vision.describe、vision.detect、vision.ocr)需 OEM 提供对应模型。
5.5 capabilities.xml --- 能力声明文件
上述 12 种能力在系统中通过 /system_ext/etc/oir/capabilities.xml 声明。每个 <capability> 条目定义了能力名称、输入输出类型、所需权限和默认模型路径、推理引擎。下面是几个示例条目:
xml
<capabilities>
<!-- 文本补全:未指定推理引擎 backend,系统根据 text.* 前缀自动选择 llama -->
<capability name="text.complete"
shape="TokenStream"
required-permission="oir.permission.USE_TEXT"
default-model="/product/etc/oir/qwen2.5-3b-instruct-q4_k_m.gguf" />
<!-- 语音转文字:显式指定 whisper 后端 -->
<capability name="audio.transcribe"
shape="TokenStream"
required-permission="oir.permission.USE_AUDIO"
backend="whisper"
default-model="/product/etc/oir/whisper-tiny-en.Q5.bin" />
<!-- 图像描述:显式指定 mtmd 后端,需要 OEM 提供 VLM 模型 -->
<capability name="vision.describe"
shape="TokenStream"
required-permission="oir.permission.USE_VISION"
backend="mtmd" />
</capabilities>6. 运行时机制
6.1 共享模型驻留
- 每个能力对应的模型仅加载一次
ContextPool维护 N 个 slot(text.complete默认 4 个)- 每个 slot 是独立的
llama_context,拥有自己的 KV 缓存(以llama.cpp推理引擎为例) - 并发请求在 slot 级别交错执行
scss
请求 A (App 1: text.complete) ──┐
请求 B (App 2: text.complete) ──┤──→ 同一个 Qwen 2.5 模型实例
请求 C (App 3: text.translate) ──┘ ├─ Slot 0 (KV Cache A)
├─ Slot 1 (KV Cache B)
├─ Slot 2 (KV Cache C)
└─ Slot 3 (空闲)6.2 内存预算与 LRU 驱逐
- oird 会统计每个模型实际占用多少内存(模型权重 + 所有上下文的 KV 缓存)
- 新加载超出预算时触发 LRU 驱逐
- 驱逐保护:正在处理请求的模型、以及刚用过还在"保温期"内的模型不会被回收
ini
内存预算(可配置)
│
├─ 模型 A: 权重 300MB + KV 缓存 4×50MB = 500MB [in-flight, 不可驱逐]
├─ 模型 B: 权重 150MB + KV 缓存 2×30MB = 210MB [warm TTL 内, 不可驱逐]
├─ 模型 C: 权重 80MB + KV 缓存 1×20MB = 100MB [空闲, LRU 候选]
└─ 新模型 D 需要 200MB → 驱逐模型 C,腾出空间6.3 优先级调度
- 音频请求优先级高于文本和视觉请求
- 排队时音频请求自动排到文本/视觉请求前面
- 非抢占式------正在执行的推理会完整跑完,不会被打断
7. OEM 适配指南
JibarOS 定义了"设备支持哪些 AI 能力",OEM 只需选好对应的模型放进去就行,不用改框架或应用代码。
7.1 平台预置
系统构建时通过 oir-vendor-models 模块将模型预置到 /product/etc/oir/ 目录:
makefile
# device.mk
PRODUCT_PACKAGES += \
oir_default_model \
oir_minilm_model \
oir_whisper_tiny_en_model \
oir_siglip_model \
oir_voice_sample_wav7.2 OEM 定制
OEM 只需在 /vendor/etc/oir/oir_config.xml 中指定自己的模型,即可替换默认模型:
xml
<oir_config>
<!-- 全局配置 -->
<memory_budget_mb>1024</memory_budget_mb>
<warm_ttl_seconds>300</warm_ttl_seconds>
<inference_timeout_seconds>30</inference_timeout_seconds>
<!-- 按能力调优 -->
<capability_tuning>
<!-- 为 vision.describe 指定 VLM 模型 -->
<capability name="vision.describe">
<default_model>/product/etc/oir/mmproj.gguf|/product/etc/oir/llm.gguf</default_model>
<n_ctx>512</n_ctx>
</capability>
<capability name="text.complete">
<default_model>/product/etc/oir/qwen-0.5b-q4.gguf</default_model>
<n_ctx>2048</n_ctx>
</capability>
</capability_tuning>
</oir_config>全局配置:
| 配置 | 说明 |
|---|---|
memory_budget_mb |
所有模型的总内存预算(MB) |
warm_ttl_seconds |
模型用完后在内存中保留的时间(秒) |
inference_timeout_seconds |
单次推理超时(秒) |
rate_limit_per_minute |
每 UID 每分钟最大请求数 |
rate_limit_burst |
每 UID 瞬时突发请求上限 |
模块配置 (<capability_tuning> 部分):
| 配置 | 说明 |
|---|---|
default_model |
覆盖该能力的默认模型路径 |
n_ctx |
上下文窗口大小(token 数) |
以上仅列出当前代码中已生效的配置项。更多调优参数(如
max_tokens、temperature、top_p、contexts_per_model等)参见 KNOBS.md。
8. SDK 开发指南
应用通过 oir-sdk Kotlin 库接入 JibarOS 的 AI 能力。完整的开发指南请参考 SDK 文档。
8.1 快速示例
kotlin
import com.oir.OpenIntelligence
// --------- 文本生成(流式)---------
OpenIntelligence.text.completeStream("用一句话总结这段文字:...")
.collect { chunk -> print(chunk.text) }
// --------- 文本嵌入 ---------
val vector: FloatArray = OpenIntelligence.text.embed("把我变成向量")
// --------- 语音转写(流式)---------
OpenIntelligence.audio.transcribeStream("/sdcard/voice.wav")
.collect { chunk -> println(chunk.text) }
// --------- 目标检测 ---------
val boxes = OpenIntelligence.vision.detect("/sdcard/photo.jpg")
boxes.forEach { box ->
println("${box.label}: ${box.confidence} at ${box.rect}")
}8.2 权限声明
应用需要在 AndroidManifest.xml 中声明对应权限:
xml
<manifest>
<!-- 文本能力 -->
<uses-permission android:name="oir.permission.USE_TEXT" />
<!-- 音频能力 -->
<uses-permission android:name="oir.permission.USE_AUDIO" />
<!-- 视觉能力 -->
<uses-permission android:name="oir.permission.USE_VISION" />
</manifest>9. 构建系统与项目结构
9.1 项目仓库组织
JibarOS 基于 AOSP 构建,在纯净 AOSP 基础上叠加自己的改动,使用 repo 工具管理多个 Git 仓库,仓库清单定义如下:
| 仓库 | 职责 |
|---|---|
| JibarOS | 主仓库:repo manifest + 文档 + 构建工具 |
| oird | C++ 原生推理守护进程 |
| oir-framework-addons | OIRService Java 服务 + AIDL 接口定义 |
| oir-patches | 5 个对 AOSP 上游的最小补丁 |
| oir-sdk | 应用端 Kotlin SDK |
| oir-demo | OirDemo Mission Control 演示应用 |
| oir-vendor-models | 参考模型包 + 拉取脚本 |
| device_google_cuttlefish | 参考设备树(Cuttlefish 虚拟设备) |
外部推理引擎相关仓库 :(为了锁定版本保证构建稳定性,以及添加 Android.bp 构建规则接入 AOSP,下面几个仓库是fork出来的)
| 仓库 | 上游 |
|---|---|
| platform_external_llamacpp | llama.cpp |
| platform_external_whispercpp | whisper.cpp |
| platform_external_onnxruntime | ONNX Runtime |
9.2 构建流程
JibarOS 使用标准 AOSP 构建流程,并提供 jibar-os-bake.sh 脚本一键集成 OIR 组件。
完整构建步骤:
bash
# 1. 初始化 repo 工作区
mkdir jibar-os && cd jibar-os
repo init -u https://github.com/Jibar-OS/JibarOS -b main
repo sync -c -j8
# 2. 运行 JibarOS 脚本(集成 OIR 组件到 AOSP )
./.repo/manifests/tools/jibar-os-bake.sh
# 3. 拉取参考模型
cd vendor/oir-models && ./tools/fetch-models.sh
cd ../..
# 4. 标准 AOSP 构建
source build/envsetup.sh
lunch aosp_cf_x86_64_phone-trunk_staging-userdebug
m
# 5. 启动 Cuttlefish 模拟器
launch_cvd --start_webrtcjibar-os-bake.sh 做了什么:
这个脚本做的事情就是把 OIR 相关组件"注入"到 AOSP 构建树中,具体包括:
- 应用 AOSP 补丁 --- 将
oir-patches中的 5 个补丁应用到对应的 AOSP 仓库 - 注入 OIR 组件 --- 将 oird、OIRService、oir-sdk 等组件链接到 AOSP 构建树的正确位置
- 配置设备树 --- 在 Cuttlefish 设备树中添加 OIR 相关的产品配置
- 设置 SELinux 策略 --- 为 oird 守护进程创建
u:r:oird:s0安全域
9.3 构建产物
| 产物 | 说明 | 路径 |
|---|---|---|
| oird 守护进程 | C++ native daemon | /system_ext/bin/oird |
| oird 启动配置 | init 启动脚本 | /system_ext/etc/init/oird.rc |
| OIRService | Java 系统服务 | 内嵌 system_server |
| 能力注册表 | 能力 → 后端映射 | /system_ext/etc/oir/capabilities.xml |
| 参考模型 | 预装模型文件 | /product/etc/oir/*.gguf / *.onnx |
| oir-sdk | 应用端 SDK | APK 依赖 |
| OirDemo | 演示/调试工具 | 预装应用 |
10. 参考资料
- JibarOS GitHub :github.com/Jibar-OS/Ji...
- JibarOS 官方文档 :github.com/Jibar-OS/Ji...
- Android AICore :developer.android.com/ai/gemini-n...
- ML Kit GenAI APIs :developers.google.com/ml-kit/gena...