本文介绍基于脚本,快速、批量下载 Earthdata 中遥感影像数据的方法。
最近,需要下载 MODIS 的 GPP 数据,时间跨度从 2000 年到 2024 年,时间分辨率为 8 天,覆盖全球陆地范围。数据来源选择的是 NASA LP DAAC 提供的 MOD17A2HGF v6.1 产品------这是 MOD17A2H 的 Gap-Filled(间隙填充)版本,在年末阶段对 FPAR/LAI 输入质量较差的像元进行了清洁处理,能有效消除云污染导致的伪异常,适合做长时序分析。
之前的几篇文章中,我们多次介绍过不同的遥感影像批量下载方法,包括基于浏览器插件、本地下载器、谷歌地球引擎GEE平台等;但是,一直都没介绍过基于脚本的下载方法------而基于脚本下载,可能反而是最简单、最快捷的方法。
因此,这篇文章记录一下用 Python 批量下载这批数据的思路和完整代码------只要是需要批量下载 Earthdata 数据的,都可以参考本文思路。大家可以直接将本文发给 Agent,让 AI 一键部署本文所需的环境与脚本,真的就是点点鼠标就能批量下载了。
数据概况
本文以 MOD17A2HGF 数据为例来介绍(但 Earthdata 中的其他数据都可以用本文的方法)。MOD17A2HGF 是 Terra 卫星 MODIS 传感器生产的全球陆地总初级生产力(GPP)产品。
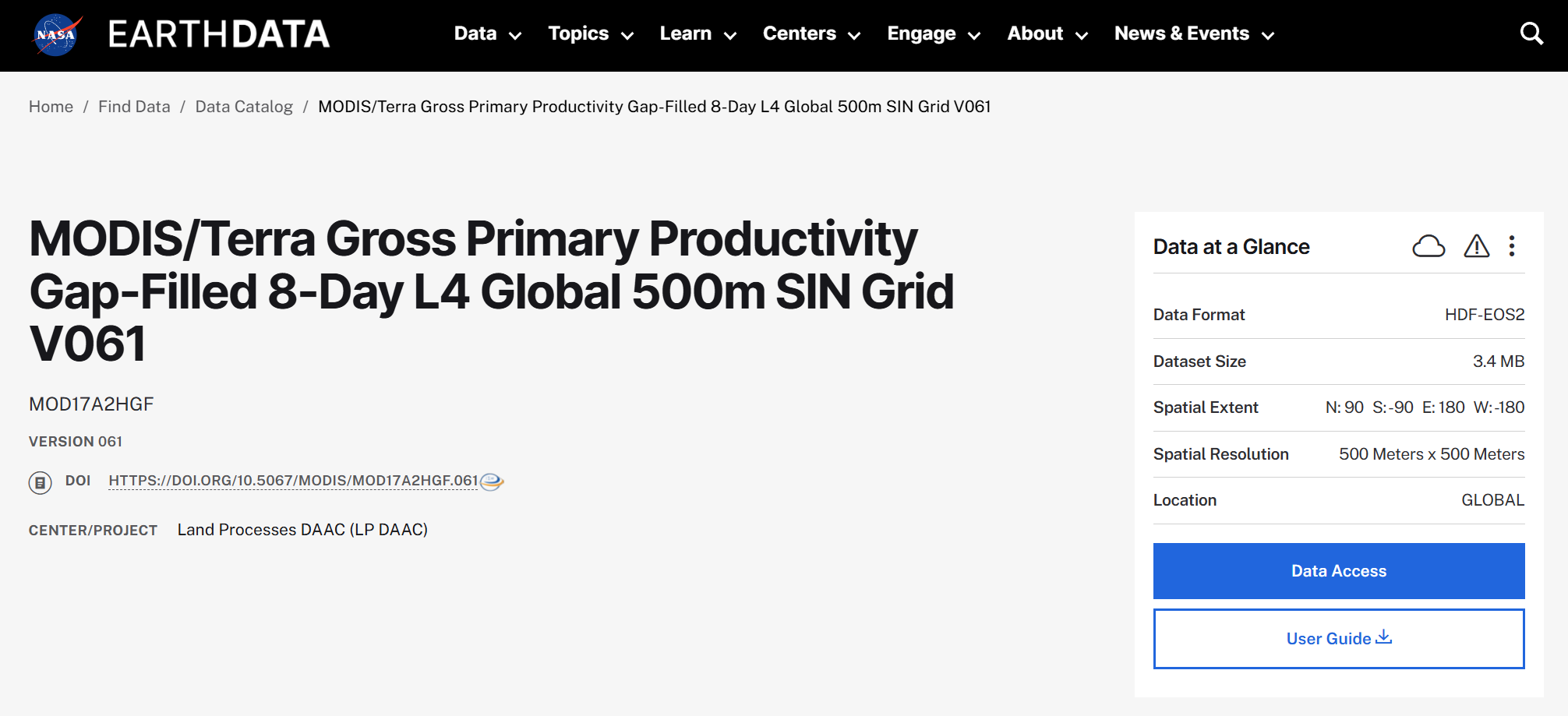
这一产品的主要参数如下:
| 项目 | 内容 |
|---|---|
| 产品名 | MOD17A2HGF v6.1 |
| 时间分辨率 | 8 天合成 |
| 空间分辨率 | 500 m(原生分辨率) |
| 数据格式 | HDF4(.hdf) |
| 空间覆盖 | 全球陆地,约 286~326 个 MODIS 瓦片/周期 |
| 数据时段 | 2000-02-18 至今 |
| 下载来源 | NASA LP DAAC(earthaccess API) |
全球完整下载一套(2000-2024)大约需要 1144 个 8 天周期 (2000 年从 MODIS 数据起始日 2 月 18 日开始共 40 个周期,2001~2024 年每年 46 个),原始 HDF 文件总量约 1100 GB。单靠手动从网页点击下载显然不现实,所以用脚本来做。
环境准备
主要依赖两个库:
bash
pip install earthaccess tqdmearthaccess 是 NASA 官方出品的 Python 库,专门用于搜索和下载 Earthdata(包括 MODIS 在内的所有 NASA 数据)。tqdm 用于显示下载进度条。
另外需要注册一个 NASA Earthdata 账号,地址是 https://urs.earthdata.nasa.gov,注册完成后在账号页面给 LP DAAC Data Pool 这个应用授权,否则下载会报 401 错误。
认证方面,推荐使用 .netrc 文件方式,在 Windows 上对应的文件路径是 C:\Users\<用户名>\_netrc,内容格式如下:
machine urs.earthdata.nasa.gov
login 你的用户名
password 你的密码这种方式最稳定,不依赖 Token API,在有代理软件的 Windows 环境下也能正常工作。如果系统装了 Clash、V2Ray 等工具,即使其是"关闭"状态,Windows 系统代理设置有时仍然生效,会导致 HTTPS 连接被拦截。解决方案是在脚本里显式设置 NO_PROXY="*",让 Python 的请求绕过系统代理。
代码设计思路
下载脚本的整体逻辑不复杂,核心是三步:
第一步,生成 MODIS 8 天周期列表。MODIS 的 8 天合成不是任意的 8 天,而是从每年第 1 天(1 月 1 日)开始,每 8 天一个周期,全年固定 46 个周期(最后一个周期可能不足 8 天)。所以需要先把起止日期对齐到 MODIS 的标准周期边界,再逐一生成周期列表。
第二步,按周期搜索并下载颗粒 。用 earthaccess.search_data() 搜索指定时间范围内的数据颗粒(Granule),每个颗粒对应一个 MODIS 瓦片的 HDF 文件。全球范围每个周期大约有 290 个颗粒。搜索完成后,用多线程并发下载,默认 8 个线程,实测速度稳定在每个周期 3~5 分钟,全部下载完大约需要 3 天左右。
第三步,断点续传与完整性校验 。下载过程中用一个 JSON 文件记录已完成的周期。每次完成一个周期后,会进行三重校验:文件数是否正好 290 个、所有 HDF 文件的 MODIS 周期标签(如 A2001001)是否与目录名完全一致。只有三项全部通过,才标记该周期完成并写入进度文件。下次运行时加 --resume 参数即可从断点继续,不达标的周期会被自动跳过重新下载。
此外,每个颗粒的下载支持最多 3 次指数退避重试,下载时先写入 .tmp 临时文件,完成后重命名,防止意外中断导致的不完整文件被当作有效文件跳过。
完整代码
python
#!/usr/bin/env python3
"""
MODIS MOD17A2HGF v6.1 GPP 全球下载脚本(纯下载版)
=====================================================
仅从 NASA LP DAAC 下载 HDF 文件,按 MODIS 标准 8 天周期组织目录存储。
下载完成后,使用本地 ArcPy 将 HDF 批量转为 GeoTIFF。
特性:
- 多线程下载:并行下载多个瓦片,大幅提升速度
- 断点续传:记录每个已完成周期的下载状态,可随时恢复
- 完整性校验:文件数 = 290 + 标签一致性双重验证
- 跨年过滤:自动排除跨年日期范围匹配到的非目标周期颗粒
- 交互式/环境变量/ netrc 认证:灵活适配不同运行环境
- 详细日志:同时输出到控制台和日志文件
使用方法:
# 交互式登录(首次需输入用户名密码,自动保存凭据到 ~/.netrc)
python lpdaac_gpp_download_only.py
# 环境变量认证
set EARTHDATA_USERNAME=myuser
set EARTHDATA_PASSWORD=mypass
python lpdaac_gpp_download_only.py
# 恢复中断的下载
python lpdaac_gpp_download_only.py --resume
# 指定日期范围
python lpdaac_gpp_download_only.py --start 2010-01-01 --end 2015-12-31
# 调整并行线程数(默认 8,NASA 限制约 10-15)
python lpdaac_gpp_download_only.py --workers 12
# 只检查哪些周期缺失,不实际下载
python lpdaac_gpp_download_only.py --dry-run
依赖:
pip install earthaccess tqdm
"""
import argparse
import json
import logging
import os
import re
import sys
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime, timedelta
from pathlib import Path
import earthaccess
from tqdm import tqdm
# ============================================================
# 日志配置
# ============================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
handlers=[
logging.StreamHandler(sys.stdout),
],
)
logger = logging.getLogger(__name__)
# ============================================================
# 常量
# ============================================================
MODIS_PRODUCT = "MOD17A2HGF"
MODIS_VERSION = "061"
MODIS_TERRA_START = datetime(2000, 2, 18)
# 默认路径
DEFAULT_RAW_DIR = r"F:\MODIS_GPP\raw_hdf"
PROGRESS_FILE = r"F:\MODIS_GPP\gpp_download_progress.json"
LOG_FILE = r"F:\MODIS_GPP\gpp_download.log"
# 每个 8 天周期预计瓦片数(全球覆盖约 286~326 个)
# MOD17A2HGF 全球陆地范围约 290 个瓦片
EXPECTED_TILES = 290 # 标准瓦片数(MOD17A2HGF 全球陆地覆盖)
# ============================================================
# 辅助函数
# ============================================================
def generate_8day_periods(start_date, end_date):
"""生成 MODIS 标准 8 天合成周期列表,按年对齐。
MODIS 8 天周期每年从 Day 001 开始,周期标签为 YYYYDDD:
- 2000 年首个可用周期 Day 049(2000-02-18)
- 2001 年起首个周期 Day 001(2001-01-01)
- 每年 46 个周期(365/8 ≈ 45.6),最后一周期跨年
Returns:
list of (period_start: datetime, period_end: datetime, period_key: str)
period_key 格式为 YYYYDDD,如 "2001001"
"""
periods = []
for year in range(start_date.year, end_date.year + 1):
first_doy = 49 if year == 2000 else 1
for doy_start in range(first_doy, 367, 8):
try:
period_start = datetime(year, 1, 1) + timedelta(days=doy_start - 1)
except (ValueError, OverflowError):
break # 闰年溢出
if period_start.year != year:
break # 已超出当年
if period_start < start_date:
continue
if period_start > end_date:
return periods
period_end = period_start + timedelta(days=7)
period_key = f'{year}{doy_start:03d}'
periods.append((period_start, period_end, period_key))
return periods
def authenticate():
"""使用 earthaccess 进行 NASA Earthdata 认证。
优先级: .netrc 文件 > 环境变量 > 交互式登录
earthaccess v0.18 的 strategy="environment" 会调用 token API(需要 SSL),
在无代理环境下可能失败,因此优先使用 .netrc(直接使用 HTTP Basic Auth 下载)。
同时设置 NO_PROXY 环境变量,防止 Windows 系统代理干扰连接。
"""
# 防止 Windows 系统代理(如 Clash/V2Ray)干扰 HTTPS 连接
os.environ["NO_PROXY"] = "*"
os.environ["no_proxy"] = "*"
# 优先级1: .netrc 文件(最稳定,不依赖 token API)
try:
earthaccess.login(strategy="netrc")
logger.info("[OK] 使用 .netrc 文件认证成功")
return
except Exception as e:
logger.debug(f"netrc 认证失败: {e}")
# 优先级2: 环境变量(EARTHDATA_TOKEN 或 EARTHDATA_USERNAME/PASSWORD)
try:
earthaccess.login(strategy="environment")
logger.info("[OK] 使用环境变量认证成功")
return
except Exception as e:
logger.debug(f"环境变量认证失败: {e}")
# 优先级3: 交互式登录
try:
earthaccess.login(strategy="interactive")
logger.info("[OK] NASA Earthdata 交互式认证成功(凭据已保存到 .netrc)")
except Exception as e:
logger.error(f"[FAIL] 认证失败: {e}")
logger.error("请前往 https://urs.earthdata.nasa.gov 注册 NASA Earthdata 账号")
logger.error("或确认 ~/.netrc(Windows 下为 ~/_netrc)文件配置正确")
sys.exit(1)
def download_single_granule(granule, output_dir, max_retries=3):
"""下载单个数据颗粒,支持重试。
Args:
granule: earthaccess 颗粒对象
output_dir: 输出目录
max_retries: 最大重试次数
Returns:
(granule, local_path, success: bool)
"""
for attempt in range(max_retries):
try:
links = granule.data_links()
if not links:
return (granule, None, False)
url = links[0]
filename = os.path.basename(url)
local_path = os.path.join(output_dir, filename)
# 检查文件是否已存在且大小合理(> 100KB 认为有效)
if os.path.exists(local_path) and os.path.getsize(local_path) > 102400:
return (granule, local_path, True)
# 下载
session = earthaccess.get_requests_https_session()
response = session.get(url, stream=True, timeout=120)
response.raise_for_status()
# 写入临时文件,完成后重命名(防止部分写入)
temp_path = local_path + ".tmp"
with open(temp_path, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
os.rename(temp_path, local_path)
return (granule, local_path, True)
except Exception as e:
if attempt < max_retries - 1:
wait = 2 ** attempt
logger.debug(f" 下载重试 {attempt+1}/{max_retries} (等待{wait}s): {e}")
time.sleep(wait)
else:
logger.warning(f" 下载失败 {filename}: {e}")
return (granule, None, False)
return (granule, None, False)
def download_granules_parallel(granules, output_dir, max_workers=8):
"""多线程下载颗粒。
Args:
granules: earthaccess 颗粒列表
output_dir: 输出目录
max_workers: 最大线程数
Returns:
(downloaded_list, failed_count)
"""
os.makedirs(output_dir, exist_ok=True)
downloaded = []
failed = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {
executor.submit(download_single_granule, g, output_dir): g
for g in granules
}
with tqdm(total=len(futures), desc=" 下载瓦片", unit="瓦片",
ncols=80, leave=False) as pbar:
for future in as_completed(futures):
granule, path, success = future.result()
if success and path:
downloaded.append(path)
else:
failed += 1
pbar.update(1)
pbar.set_postfix(ok=len(downloaded), fail=failed)
logger.info(f" 下载完成: {len(downloaded)} 成功, {failed} 失败")
return downloaded, failed
def count_hdf_files(directory):
"""统计目录中 .hdf 文件数量。"""
if not os.path.exists(directory):
return 0
return len([f for f in os.listdir(directory) if f.lower().endswith(".hdf")])
def validate_period_dir(directory, expected_key):
"""验证目录中的 HDF 文件是否完整且标签一致。
Args:
directory: 目录路径
expected_key: 期望的 MODIS 周期标签(如 "2001001")
Returns:
(is_valid: bool, total_count: int, mismatch_count: int)
"""
if not os.path.exists(directory):
return False, 0, 0
files = [f for f in os.listdir(directory) if f.lower().endswith(".hdf")]
total = len(files)
if total != EXPECTED_TILES:
return False, total, 0
# 检查每个文件的 MODIS 标签是否与目录一致
pattern = f"A{expected_key}."
mismatches = 0
for f in files:
if pattern not in f:
mismatches += 1
return (mismatches == 0), total, mismatches
def load_progress(progress_file):
"""加载下载进度。"""
if os.path.exists(progress_file):
with open(progress_file, "r") as f:
return json.load(f)
return {"completed_periods": [], "start_time": datetime.now().isoformat()}
def save_progress(progress, progress_file):
"""保存下载进度。"""
os.makedirs(os.path.dirname(progress_file), exist_ok=True)
with open(progress_file, "w") as f:
json.dump(progress, f, indent=2)
def estimate_total_size(periods, granules_per_period=290, mb_per_granule=2.2):
"""估算总下载量。"""
total_mb = len(periods) * granules_per_period * mb_per_granule
return total_mb / 1024 # GB
# ============================================================
# 主流程
# ============================================================
def main():
parser = argparse.ArgumentParser(
description="MODIS MOD17A2HGF v6.1 GPP 全球 HDF 下载脚本(纯下载版)",
formatter_class=argparse.RawDescriptionHelpFormatter,
)
parser.add_argument("--start", default="2000-02-18",
help="起始日期 (YYYY-MM-DD), 默认 2000-02-18")
parser.add_argument("--end", default="2024-12-31",
help="结束日期 (YYYY-MM-DD), 默认 2024-12-31")
parser.add_argument("--raw-dir", default=DEFAULT_RAW_DIR,
help=f"HDF 文件存储目录, 默认 {DEFAULT_RAW_DIR}")
parser.add_argument("--workers", type=int, default=8,
help="并行下载线程数, 默认 8(NASA 限制约 10-15)")
parser.add_argument("--resume", action="store_true",
help="从上次中断处恢复下载")
parser.add_argument("--dry-run", action="store_true",
help="仅统计周期数和预估数据量,不实际下载")
parser.add_argument("--force", action="store_true",
help="强制重新下载已完成的周期(补全缺失文件)")
args = parser.parse_args()
# 初始化目录
os.makedirs(args.raw_dir, exist_ok=True)
# 配置文件日志
os.makedirs(os.path.dirname(LOG_FILE), exist_ok=True)
file_handler = logging.FileHandler(LOG_FILE, encoding="utf-8")
file_handler.setFormatter(logging.Formatter("%(asctime)s [%(levelname)s] %(message)s"))
logger.addHandler(file_handler)
start_date = datetime.strptime(args.start, "%Y-%m-%d")
end_date = datetime.strptime(args.end, "%Y-%m-%d")
# 认证
logger.info("=" * 60)
logger.info("MODIS MOD17A2HGF v6.1 GPP 全球 HDF 下载(纯下载版)")
logger.info("=" * 60)
authenticate()
# 生成周期列表
periods = generate_8day_periods(start_date, end_date)
logger.info(f"总 8 天周期数: {len(periods)}")
logger.info(f"时间范围: {periods[0][0].strftime('%Y-%m-%d')} ~ "
f"{periods[-1][1].strftime('%Y-%m-%d')}")
logger.info(f"并行线程数: {args.workers}")
logger.info(f"HDF 存储目录: {args.raw_dir}")
# 预估数据量
total_gb = estimate_total_size(periods)
logger.info(f"预估下载总量: ~{total_gb:.0f} GB({len(periods)} 周期 × ~290 瓦片/周期)")
logger.info(f"预计存储占用: ~{total_gb:.0f} GB(HDF 原始文件)")
if args.dry_run:
logger.info("=== Dry Run 模式,不实际下载 ===")
for i, (ps, pe, pk) in enumerate(periods[:8]):
logger.info(f" 周期 {i+1}: {ps.strftime('%Y-%m-%d')} ~ {pe.strftime('%Y-%m-%d')} [{pk}]")
if len(periods) > 8:
logger.info(f" ... 共 {len(periods)} 个周期")
# 检查已有文件
completed = 0
for ps, pe, pk in periods:
period_dir = os.path.join(args.raw_dir, pk)
is_valid, n, mismatches = validate_period_dir(period_dir, pk)
if is_valid:
completed += 1
logger.info(f"本地已有完整周期: {completed}/{len(periods)}")
return
# 加载进度
progress = load_progress(PROGRESS_FILE) if args.resume else {
"completed_periods": [], "start_time": datetime.now().isoformat()
}
completed = set(progress.get("completed_periods", []))
if completed and args.resume:
logger.info(f"恢复模式: 已完成 {len(completed)}/{len(periods)} 个周期")
# 统计
total_downloaded = 0
total_failed = 0
start_time = time.time()
# 逐周期下载
for i, (period_start, period_end, period_key) in enumerate(periods):
period_dir = os.path.join(args.raw_dir, period_key)
# 检查是否已下载完成(目录存在、290 文件、标签全部一致)
if not args.force:
if period_key in completed or os.path.exists(period_dir):
is_valid, total, mismatches = validate_period_dir(period_dir, period_key)
if is_valid:
if period_key not in completed:
completed.add(period_key)
progress["completed_periods"] = sorted(completed)
save_progress(progress, PROGRESS_FILE)
logger.info(f" 周期 {period_key} 已完成 ✓ (290 文件, 标签一致),跳过")
continue
elif total > 0:
# 有文件但不达标:显示详情
if mismatches > 0:
logger.warning(f" 周期 {period_key} 已有 {total} 个文件但 {mismatches} 个标签不一致,重新下载")
else:
logger.warning(f" 周期 {period_key} 仅 {total} 个文件(需 290),重新下载")
completed.discard(period_key)
progress["completed_periods"] = sorted(completed)
save_progress(progress, PROGRESS_FILE)
# 预估剩余时间
elapsed = time.time() - start_time
if total_downloaded > 0:
avg_time = elapsed / total_downloaded
remaining = avg_time * (len(periods) - len(completed))
eta_str = f" (ETA: {remaining/3600:.1f}h)"
else:
eta_str = ""
logger.info(f"\n--- 周期 {i+1}/{len(periods)}: "
f"{period_start.strftime('%Y-%m-%d')} ~ "
f"{period_end.strftime('%Y-%m-%d')}{eta_str} ---")
# Step 1: 搜索颗粒
try:
granules = earthaccess.search_data(
short_name=MODIS_PRODUCT,
version=MODIS_VERSION,
temporal=(period_start, period_end),
)
except Exception as e:
logger.error(f" 搜索颗粒失败: {e}")
total_failed += 1
continue
if not granules:
logger.warning(f" 未找到颗粒,跳过此周期")
completed.add(period_key)
progress["completed_periods"] = sorted(completed)
save_progress(progress, PROGRESS_FILE)
continue
logger.info(f" 搜索到 {len(granules)} 个颗粒")
# 关键步骤:按 MODIS 周期标签 A{YYYYDDD} 过滤
# 跨年日期范围(如 12-27 ~ 01-03)可能匹配到多个 MODIS 周期,
# 必须只保留文件名含 "A{period_key}." 的颗粒
pattern = f"A{period_key}."
filtered = []
for g in granules:
try:
links = g.data_links()
if links and pattern in links[0]:
filtered.append(g)
except Exception:
pass
if len(filtered) != len(granules):
logger.info(f" 过滤后保留 {len(filtered)} 个(排除 {len(granules) - len(filtered)} 个非同周期颗粒)")
else:
logger.info(f" 全部 {len(filtered)} 个颗粒均为目标周期")
if not filtered:
logger.warning(f" 过滤后无颗粒,跳过此周期")
completed.add(period_key)
progress["completed_periods"] = sorted(completed)
save_progress(progress, PROGRESS_FILE)
continue
granules = filtered
logger.info(f" 开始 {args.workers} 线程下载...")
# Step 2: 多线程下载
os.makedirs(period_dir, exist_ok=True)
downloaded, failed_count = download_granules_parallel(
granules, period_dir, max_workers=args.workers
)
# Step 3: 校验下载完整性(文件数 = 290 且标签全部一致)
is_valid, total, mismatches = validate_period_dir(period_dir, period_key)
if is_valid:
logger.info(f" [OK] 周期 {period_key} 下载完成且验证通过 "
f"({total} 文件, 标签一致)")
completed.add(period_key)
progress["completed_periods"] = sorted(completed)
save_progress(progress, PROGRESS_FILE)
total_downloaded += 1
elif total > 0:
mismatch_info = f", {mismatches} 标签不一致" if mismatches > 0 else ""
logger.warning(f" [WARN] 周期 {period_key} 下载不完整 "
f"({total}/290 文件{mismatch_info}),下次运行将自动补全")
total_failed += 1
else:
logger.warning(f" [WARN] 周期 {period_key} 下载失败 (0 文件)")
total_failed += 1
# 每 10 个周期输出一次汇总
if (i + 1) % 10 == 0:
elapsed = time.time() - start_time
speed = total_downloaded / (elapsed / 3600) if elapsed > 0 else 0
logger.info(f" >>> 进度: {len(completed)}/{len(periods)} 完成, "
f"速度: {speed:.1f} 周期/小时")
# 最终汇总
total_time = (time.time() - start_time) / 3600 if start_time else 0
logger.info("\n" + "=" * 60)
logger.info("下载完成!")
logger.info(f"总耗时: {total_time:.1f} 小时")
logger.info(f"成功: {len(completed)}/{len(periods)} 个周期")
logger.info(f"失败/不完整: {total_failed}")
logger.info(f"HDF 文件存储: {os.path.abspath(args.raw_dir)}")
# 统计本地文件
total_hdf = 0
for d in os.listdir(args.raw_dir):
dpath = os.path.join(args.raw_dir, d)
if os.path.isdir(dpath):
n = len([f for f in os.listdir(dpath) if f.lower().endswith(".hdf")])
total_hdf += n
total_size_mb = sum(
os.path.getsize(os.path.join(root, f))
for root, _, files in os.walk(args.raw_dir)
for f in files if f.lower().endswith(".hdf")
) / (1024 * 1024)
logger.info(f"本地 HDF 文件总数: {total_hdf}")
logger.info(f"本地 HDF 文件总大小: {total_size_mb:.0f} MB ({total_size_mb/1024:.1f} GB)")
# 列出未完成的周期
incomplete = []
for ps, pe, pk in periods:
if pk not in completed:
incomplete.append(pk)
if incomplete:
logger.info(f"未完成周期 ({len(incomplete)}):")
for pk in incomplete[:10]:
logger.info(f" {pk}")
if len(incomplete) > 10:
logger.info(f" ... 还有 {len(incomplete)-10} 个")
logger.info("=" * 60)
logger.info("下一步: 使用 hdf2tif 脚本将 HDF 批量转为 GeoTIFF")
if __name__ == "__main__":
main()关键参数说明
脚本中几个容易需要根据实际情况调整的变量如下:
| 参数 | 默认值 | 说明 |
|---|---|---|
DEFAULT_RAW_DIR |
F:\MODIS_GPP\raw_hdf |
HDF 文件存储目录,按需修改到有足够空间的磁盘 |
--start / --end |
2000-02-18 / 2024-12-31 | 下载的时间范围 |
--workers |
8 | 并行下载线程数,NASA 服务器一般限制约 10~15 个并发,不建议超过 15 |
EXPECTED_TILES |
290 | 认为一个周期"下载完整"所需的标准文件数,MOD17A2HGF 全球陆地覆盖约为 290 个瓦片 |
命令行用法如下:
bash
# 完整下载 2000-2024(首次运行)
python lpdaac_gpp_download_only.py
# 断点续传(中途中断后恢复)
python lpdaac_gpp_download_only.py --resume
# 先检查本地已有多少,不实际下载
python lpdaac_gpp_download_only.py --dry-run
# 调整线程数为 12,加快下载
python lpdaac_gpp_download_only.py --workers 12
# 自定义时间范围
python lpdaac_gpp_download_only.py --start 2010-01-01 --end 2020-12-31几个踩坑记录
关于 MOD17A2HGF 与 MOD17A2H 的选择:如果做长时序分析,建议优先选 GF 版本。标准版 MOD17A2H 在年末几个周期会因为 FPAR/LAI 质量差而出现明显的低估异常,在时序曲线上表现为突然的负值或极低值,用 GF 版本可以规避这个问题。
关于 Windows 代理干扰问题 :这个问题比较隐蔽。即便在 Clash 或 V2Ray 里点击了"关闭系统代理",Windows 注册表里的代理设置有时候不会立即清除,导致 Python 的 requests 库仍然走代理,在代理不稳定或没有开启 TUN 模式时会出现 SSL 握手失败(SSLEOFError)。解决方法是在脚本里显式设置 os.environ["NO_PROXY"] = "*" 和 os.environ["no_proxy"] = "*",强制让所有请求绕过代理直连。
关于 earthaccess v0.18 认证接口变更 :早期版本的 earthaccess.login() 支持 strategy="password" 直接传用户名密码,v0.18 之后这个策略被移除,改成了 strategy="netrc"(读取 .netrc 文件)、strategy="environment"(读取环境变量)和 strategy="interactive"(交互式引导)三种方式。如果用老版本代码会报 ValueError: Invalid strategy,换用上面的方式就好。
至此,大功告成。
欢迎关注:疯狂学习GIS