一、前言
前两篇文章分别建立了 BF16 基线和 AWQ INT4 量化实验,我们发现了一个有趣的现象:AWQ 量化把模型权重从 14 GB 压缩到 4 GB,TPOT 降了 65%,但吞吐却翻了一倍多------这个倍数远超 TPOT 降幅能解释的范围。
吞吐翻倍的另一半原因藏在 KV Cache 里。
本文不做新的优化实验,而是深入理解 LLM 推理中最关键的显存消费者------KV Cache。通过理论推导和实测验证,回答以下问题:
- KV Cache 是什么?为什么它是高并发场景下的显存瓶颈?
- vLLM 的 PagedAttention 是怎么管理 KV Cache 的?
- KV Cache 占用和序列长度、并发数的定量关系是什么?
- AWQ 量化后吞吐翻倍,KV Cache 在其中扮演了什么角色?
先看结论:
| 实验 | 关键发现 |
|---|---|
| 单请求 KV Cache vs 序列长度 | 严格线性关系,实测 ~55 KB/token,与理论值 56 KB 一致 |
| 并发数 vs KV Cache 占用 | 线性增长,BF16 模型在 conc≈88 时 KV Cache 打满 |
| BF16 vs AWQ 的 KV Cache 容量 | AWQ 省出 10 GB 给 KV Cache,容量扩大 3 倍(5306 → 15839 blocks) |
最重要的洞察:AWQ 量化的吞吐翻倍不只是因为 TPOT 降低(带宽收益),更因为模型权重压缩后省出的显存全部给了 KV Cache,系统能同时服务 3 倍数量的请求------这是吞吐翻倍的真正推手。
二、KV Cache 与 PagedAttention
2.1 LLM 推理的两个阶段
LLM 生成文本时,每次只输出一个 token,依赖前面所有 token 的信息,直到达到最大长度或生成结束符(EoS)。整个推理过程分为两个阶段:
Prefill 阶段 :把用户输入(prompt)一次性送进模型,计算出所有输入 token 对应的 Key-Value 对,并生成第一个输出 token。这个阶段是计算密集型的,GPU 算力是瓶颈。
Decode 阶段 :逐个生成后续 token,每一步都需要用到输入和之前所有已生成 token 的 Key-Value 对。这个阶段是访存密集型的,显存带宽是瓶颈。
Prefill 阶段(一次性处理所有输入),以输入"中国首都是"为例:
模型一次性计算 K 1 V 1 , K 2 V 2 , K 3 V 3 , K 4 V 4 , K 5 V 5 K_1 V_1, K_2 V_2, K_3 V_3, K_4 V_4, K_5 V_5 K1V1,K2V2,K3V3,K4V4,K5V5,并生成第一个输出 token:"北"。这一步的耗时就是 TTFT。
Decode 阶段(逐个生成),每步只计算一个新 token 的 KV,并存入 cache:
- 生成"北"时:从 cache 读取 K 1 ... K 5 K_1 \dots K_5 K1...K5,计算新的 K 6 V 6 K_6 V_6 K6V6 存入 cache,输出"京"
- 生成"京"时:从 cache 读取 K 1 ... K 6 K_1 \dots K_6 K1...K6,计算新的 K 7 V 7 K_7 V_7 K7V7 存入 cache,输出"。"
- 生成"。"后触发 EoS,结束。每步耗时就是 TPOT。
2.2 KV Cache------用空间换时间
在 Decode 阶段,每生成一个新 token 都需要与前面所有 token 做 Attention 计算。Attention 的核心公式为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dk QKT)V
其中 Q Q Q 是当前 token 的 Query 向量, K K K 和 V V V 是所有历史 token 的 Key 和 Value 向量。
如果每步都重新计算所有 K K K、 V V V,计算量是 O ( N 2 ) O(N^2) O(N2)。KV Cache 的本质是用显存空间换计算时间 ------把已经计算过的 K K K、 V V V 缓存在显存里,后续直接读取。
没有 KV Cache(每步重算) :生成第 N N N 个 token 时,需要重新计算 K 1 V 1 ... K N − 1 V N − 1 K_1 V_1 \dots K_{N-1} V_{N-1} K1V1...KN−1VN−1,总计算量 O ( N 2 ) O(N^2) O(N2)。
有 KV Cache(缓存复用):
- 生成第 1 个 token:计算 K 1 V 1 K_1 V_1 K1V1,存入 cache
- 生成第 2 个 token:从 cache 读 K 1 V 1 K_1 V_1 K1V1,只算 K 2 V 2 K_2 V_2 K2V2,存入 cache
- 生成第 3 个 token:从 cache 读 K 1 V 1 , K 2 V 2 K_1 V_1, K_2 V_2 K1V1,K2V2,只算 K 3 V 3 K_3 V_3 K3V3,存入 cache
- ......
- 生成第 N N N 个 token:从 cache 读 K 1 ... K N − 1 K_1 \dots K_{N-1} K1...KN−1,只算 K N V N K_N V_N KNVN,总计算量 O ( N ) O(N) O(N)
每步只需计算一个新 token 的 KV 并存入 cache,其余全部从 cache 读取。代价是 KV Cache 会持续占用显存,并且随着序列长度和并发数线性增长。
2.3 KV Cache 大小与序列长度的关系
KV Cache 的大小和输入长度 + 输出长度成正比:
KV Cache = n l a y e r s × 2 × n k v h e a d s × d h e a d × b d t y p e × L \text{KV Cache} = n_{layers} \times 2 \times n_{kvheads} \times d_{head} \times b_{dtype} \times L KV Cache=nlayers×2×nkvheads×dhead×bdtype×L
其中 L L L 为序列总长度(输入 + 已生成 token 数), b d t y p e b_{dtype} bdtype 为数据类型的字节数。以 Qwen2.5-7B 为例:
单 token KV = 28 × 2 × 4 × 128 × 2 = 57344 bytes ≈ 56 KB \text{单 token KV} = 28 \times 2 \times 4 \times 128 \times 2 = 57344 \text{ bytes} \approx 56 \text{ KB} 单 token KV=28×2×4×128×2=57344 bytes≈56 KB
随着序列长度和并发数增长,KV Cache 线性增长:
| 序列长度 | 单请求 KV Cache | 32 并发总占用 |
|---|---|---|
| 512 token | 28 MB | 896 MB |
| 2048 token | 112 MB | 3.6 GB |
| 4096 token | 224 MB | 7.2 GB |
| 8192 token | 448 MB | 14.3 GB |
对比 AWQ INT4 模型权重(约 4 GB),KV Cache 在高并发 + 长序列场景下占用的显存远超模型本身。这就是上一篇实验里 conc=128 时吞吐开始饱和的根本原因。
2.4 传统 KV Cache 管理的问题
在 vLLM 之前,KV Cache 的分配方式是按最大序列长度预分配连续内存。比如请求 A 实际只用了 200 个 token,但系统会按 max_seq_len=4096 预分配一整块连续显存,剩余 3896 个 token 的空间全部浪费。
这种方式存在三个严重问题:
内部碎片(Internal Fragmentation) :预分配按最大长度,但实际生成长度无法预知,大量预留空间被浪费。论文统计实际浪费比例高达 60~80%。
外部碎片(External Fragmentation):要求连续内存块,即使剩余显存足够,也可能因为碎片化而无法分配给新请求。
无法共享:不同请求即使有相同的 system prompt(prefill 部分 KV 完全一样),也要各自存一份,造成冗余。
2.5 PagedAttention------像操作系统管理内存一样管理 KV Cache
vLLM 的核心创新是 PagedAttention,灵感来自操作系统的虚拟内存和分页机制------vLLM 的 "v" 就是 virtual 的意思。
核心思路:把 KV Cache 拆成固定大小的 Block(页),不要求物理连续,按需动态分配。
以序列 "I love cats so much . Do you love me who" 为例,block_size=4:
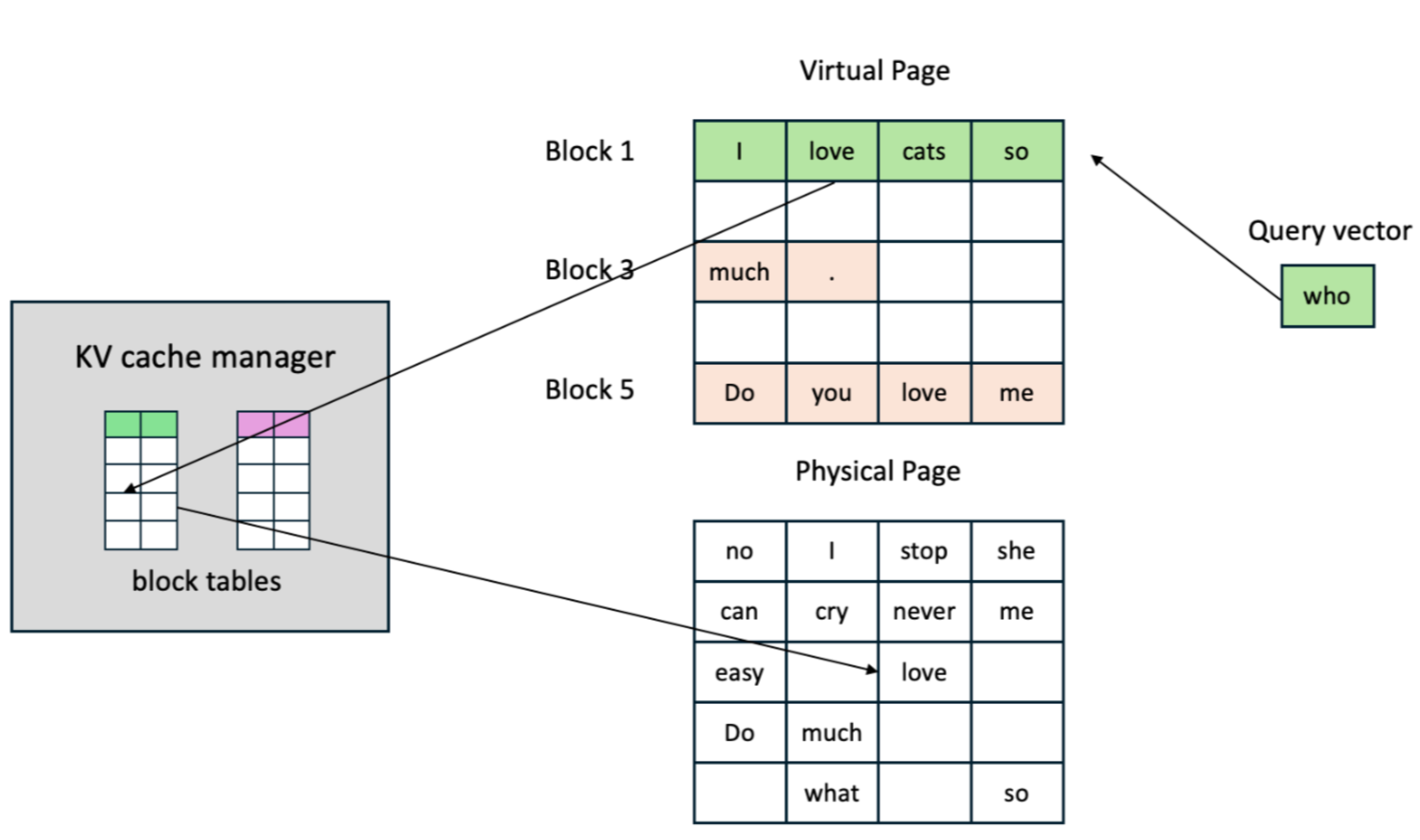
这些 Block 在物理显存(Physical Page)上不需要连续存放 ,通过 KV Cache Manager 中的 Block Table(类似 OS 的页表)做映射:
Block Table(逻辑 → 物理映射):
Block 1 → 物理页 3
Block 3 → 物理页 1
Block 5 → 物理页 4Attention 计算时,Query vector "who" 按照 Block Table 的映射,依次从物理上不连续的 Block 中读取 K、V,分块计算 Attention 分数,最后汇总得到最终输出。因为每次只有一小部分 KV Cache 需要加载到 GPU 片上缓存,访存局部性反而更好。
2.6 PagedAttention 的三大收益
收益 1:几乎零浪费
不再按最大长度预分配,而是生成多少 token 就分配多少 Block,序列结束立即回收:
传统:请求用 200 token,预分配 4096 token → 浪费 95%
vLLM:请求用 200 token,分配 13 个 Block(13 × 16 = 208)→ 浪费 4%收益 2:消除外部碎片
Block 不需要连续,任何空闲 Block 都能被任何请求使用,就像 OS 的分页消除了外部碎片一样。
收益 3:跨请求共享
多个请求如果有相同的 prefix(比如同样的 system prompt),可以共享同一组 Block,通过引用计数管理,只在写入时复制(Copy-on-Write):
请求 A:system prompt [Block 0][Block 1] → 用户问题 [Block 5][Block 6]
↑ ↑
请求 B:system prompt [Block 0][Block 1] → 用户问题 [Block 8][Block 9]
共享同一份!不重复存储这就是第一篇基线文章里 vLLM metrics 中 enable_prefix_caching=True 的基础。
三、KV Cache 占用实测
3.1 实验设计
前面从理论上推导了单个 token 的 KV Cache 大小为 56 KB(BF16),现在通过实验来验证。
实验思路:固定输入内容,改变 max_tokens 控制输出长度,通过 vLLM 的 /metrics 接口实时采集 KV Cache 峰值占用,与理论值对比。
vLLM 启动配置(BF16 基线模型,无量化):
bash
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/qwen2.5-7b-instruct \
--served-model-name qwen2.5-7b \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096测试脚本的核心逻辑是:在后台线程发送请求,主线程每 50ms 采样一次 kv_cache_usage_perc,记录整个生成过程中的峰值使用率,再乘以 KV Cache 总容量换算成 MB:
python
# kv_cache_experiment.py
import requests
import time
import re
import threading
def get_kv_cache_usage():
r = requests.get("http://localhost:8000/metrics")
for line in r.text.split("\n"):
if "kv_cache_usage_perc" in line and not line.startswith("#"):
return float(line.split()[-1])
return None
def get_total_kv_cache_info():
r = requests.get("http://localhost:8000/metrics")
for line in r.text.split("\n"):
if "cache_config_info" in line and not line.startswith("#"):
m1 = re.search(r'num_gpu_blocks="(\d+)"', line)
m2 = re.search(r'block_size="(\d+)"', line)
if m1 and m2:
return int(m1.group(1)), int(m2.group(1))
return None, None
result = {}
def send_request_async(max_tokens):
r = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "qwen2.5-7b",
"messages": [{"role": "user", "content": "请详细介绍一下中国的历史,从远古时代开始讲起,讲1万字"}],
"max_tokens": max_tokens,
"temperature": 0.7
},
stream=False
)
data = r.json()
usage = data["usage"]
result["prompt"] = usage["prompt_tokens"]
result["completion"] = usage["completion_tokens"]
# 获取 KV Cache 配置
token_kv_bytes = 28 * 2 * 4 * 128 * 2 # Qwen2.5-7B BF16
num_blocks, block_size = get_total_kv_cache_info()
total_tokens_capacity = num_blocks * block_size
total_kv_mb = total_tokens_capacity * token_kv_bytes / 1024 / 1024
print(f"KV Cache 配置: {num_blocks} blocks × {block_size} tokens/block")
print(f"KV Cache 总容量: {total_kv_mb:.1f} MB")
print()
for max_tokens in [32, 64, 128, 256, 512, 1024, 2048]:
result.clear()
t = threading.Thread(target=send_request_async, args=(max_tokens,))
t.start()
peak_kv = 0.0
while t.is_alive():
kv = get_kv_cache_usage()
if kv is not None and kv > peak_kv:
peak_kv = kv
time.sleep(0.05)
t.join()
prompt_tokens = result.get("prompt", 0)
completion_tokens = result.get("completion", 0)
total_tokens = prompt_tokens + completion_tokens
theory_mb = total_tokens * token_kv_bytes / 1024 / 1024
actual_mb = peak_kv * total_kv_mb
print(f"max_tokens={max_tokens:>5} 输入={prompt_tokens} 输出={completion_tokens} "
f"总tokens={total_tokens} 理论={theory_mb:.2f}MB 实测={actual_mb:.2f}MB")
time.sleep(3)3.2 实验结果
KV Cache 配置: 5306 blocks × 16 tokens/block
KV Cache 总容量: 4641.3 MB| max_tokens | 输入 | 输出 | 总 tokens | 理论 KV (MB) | 实测 KV (MB) | 峰值占用率 |
|---|---|---|---|---|---|---|
| 32 | 47 | 32 | 79 | 4.32 | 4.38 | 0.09% |
| 64 | 47 | 64 | 111 | 6.07 | 6.13 | 0.13% |
| 128 | 47 | 128 | 175 | 9.57 | 9.63 | 0.21% |
| 256 | 47 | 256 | 303 | 16.57 | 16.63 | 0.36% |
| 512 | 47 | 512 | 559 | 30.57 | 30.63 | 0.66% |
| 1024 | 47 | 1024 | 1071 | 58.57 | 58.64 | 1.26% |
| 2048 | 47 | 1857 | 1904 | 104.12 | 104.14 | 2.24% |
3.3 结果分析
发现 1:理论公式与实测高度吻合
实测值比理论值一致地多出约 0.06~0.28 MB,原因是 PagedAttention 按 block_size=16 分配,实际分配的 token 数会向上取整到 16 的倍数:
实际分配 blocks = ⌈ 总 tokens block size ⌉ \text{实际分配 blocks} = \left\lceil \frac{\text{总 tokens}}{\text{block size}} \right\rceil 实际分配 blocks=⌈block size总 tokens⌉
以 79 tokens 为例:
⌈ 79 / 16 ⌉ = 5 blocks = 80 tokens × 56 KB = 4.38 MB ✓ \lceil 79 / 16 \rceil = 5 \text{ blocks} = 80 \text{ tokens} \times 56 \text{ KB} = 4.38 \text{ MB} \quad \checkmark ⌈79/16⌉=5 blocks=80 tokens×56 KB=4.38 MB✓
每一行都能精确对上,2.3 节推导的理论公式完全正确。
发现 2:KV Cache 与序列长度严格线性
从实测数据中反推每 token 实际占用:
| 总 tokens | 实测 KV (MB) | 每 token 占用 |
|---|---|---|
| 79 | 4.38 | 55.4 KB |
| 303 | 16.63 | 54.9 KB |
| 1071 | 58.64 | 54.8 KB |
| 1904 | 104.14 | 54.7 KB |
每 token 实际占用稳定在约 55 KB,与理论值 56 KB 几乎一致(微小差异来自 Block 对齐的分母效应)。KV Cache 占用与序列长度呈严格线性关系,没有任何隐藏的额外开销。
发现 3:单请求占用很小,并发才是瓶颈
单个 2048 token 的请求只占 KV Cache 总容量的 2.24%,看起来微不足道。但如果 32 个这样的请求同时在飞:
104.14 MB × 32 = 3332 MB ≈ 3.3 GB 104.14 \text{ MB} \times 32 = 3332 \text{ MB} \approx 3.3 \text{ GB} 104.14 MB×32=3332 MB≈3.3 GB
占 KV Cache 总容量(4641 MB)的 72%。这也解释了上一篇实验中的两个现象:
第一,BF16 基线在 conc=128 时吞吐开始饱和,因为 104 MB × 128 = 13.3 GB 104 \text{ MB} \times 128 = 13.3 \text{ GB} 104 MB×128=13.3 GB 已经远超 KV Cache 总容量,大量请求被排队等待。
第二,AWQ INT4 量化后吞吐翻倍,不只是因为 TPOT 降低,更因为模型权重从 14 GB 压缩到 4 GB,省出的 ~10 GB 显存全部给了 KV Cache 池,总容量从 4641 MB 扩大到约 13000 MB,能同时服务的请求数大幅增加。
💡 启示
KV Cache 的占用取决于实际生成长度,不是设置的 max_tokens------这正是 PagedAttention 按需分配的优势。max_tokens=2048 时模型只生成了 1857 个 token(提前遇到 EoS 结束),KV Cache 只分配了 1904 token 的空间,而不是 2048,浪费极小。
3.4 并发数 vs KV Cache 占用实测
上一节验证了单请求的 KV Cache 与序列长度成线性关系,本节进一步测试:多个请求同时在飞时,KV Cache 占用如何变化,什么时候会被打满?
实验设计:使用 threading.Barrier 让 N 个请求同时发出,在生成过程中每 100ms 采样一次 KV Cache 使用率,记录整个过程中的峰值。
python
# kv_cache_concurrency.py
import requests
import time
import re
import threading
def get_kv_cache_usage():
r = requests.get("http://localhost:8000/metrics")
for line in r.text.split("\n"):
if "kv_cache_usage_perc" in line and not line.startswith("#"):
return float(line.split()[-1])
return None
def get_total_kv_cache_info():
r = requests.get("http://localhost:8000/metrics")
for line in r.text.split("\n"):
if "cache_config_info" in line and not line.startswith("#"):
m1 = re.search(r'num_gpu_blocks="(\d+)"', line)
m2 = re.search(r'block_size="(\d+)"', line)
if m1 and m2:
return int(m1.group(1)), int(m2.group(1))
return None, None
def get_running():
r = requests.get("http://localhost:8000/metrics")
for line in r.text.split("\n"):
if "num_requests_running" in line and not line.startswith("#"):
return int(float(line.split()[-1]))
return 0
def send_request(barrier):
barrier.wait()
try:
requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "qwen2.5-7b",
"messages": [{"role": "user", "content": "请详细介绍一下中国的历史,从远古时代开始讲起,讲1万字"}],
"max_tokens": 2048,
"temperature": 0.7
},
timeout=300
)
except:
pass
token_kv_bytes = 28 * 2 * 4 * 128 * 2
num_blocks, block_size = get_total_kv_cache_info()
total_kv_mb = num_blocks * block_size * token_kv_bytes / 1024 / 1024
for concurrency in [1, 4, 8, 16, 32, 48, 64, 80, 96, 128]:
barrier = threading.Barrier(concurrency + 1)
threads = [threading.Thread(target=send_request, args=(barrier,)) for _ in range(concurrency)]
for t in threads:
t.start()
barrier.wait()
peak_kv, peak_running = 0.0, 0
while any(t.is_alive() for t in threads):
kv = get_kv_cache_usage()
running = get_running()
if kv is not None and kv > peak_kv:
peak_kv = kv
peak_running = running
time.sleep(0.1)
for t in threads:
t.join()
actual_mb = peak_kv * total_kv_mb
print(f"conc={concurrency:>3} KV={peak_kv*100:.2f}% {actual_mb:.1f}MB running={peak_running}")
time.sleep(5)指标含义说明:
- 峰值 KV%:整个实验过程中 KV Cache 使用率的最高值。KV Cache 总量在 vLLM 启动时预分配固定,这个百分比表示"已用 / 总量"的峰值。100% 表示 KV Cache 被完全占满,新请求无法分配到 KV Cache 空间。
- 峰值 KV (MB):峰值百分比 × KV Cache 总容量(4642.8 MB),换算成绝对值。
- 实际运行中 :峰值采样时刻 GPU 上正在同时生成 token 的请求数。当 KV Cache 打满时,这个值会小于发送的并发数------差额就是因为 KV Cache 空间不足而无法同时运行的请求数,这些请求需要等前面的请求完成释放 KV Cache 后才能开始。
实验结果:
| 并发数 | 峰值 KV% | 峰值 KV (MB) | 实际运行中 |
|---|---|---|---|
| 1 | 1.26% | 58.6 | 1 |
| 4 | 4.26% | 197.8 | 4 |
| 8 | 9.84% | 456.8 | 8 |
| 16 | 19.64% | 911.9 | 16 |
| 32 | 38.02% | 1765.2 | 31 |
| 48 | 48.73% | 2262.3 | 41 |
| 64 | 72.61% | 3371.1 | 60 |
| 80 | 88.65% | 4115.9 | 74 |
| 96 | 99.96% | 4641.0 | 82 |
| 128 | 100.00% | 4642.8 | 104 |
3.5 并发实验分析
发现 1:KV Cache 占用与并发数线性增长
从 conc=1 到 conc=64,KV Cache 占用率几乎完美线性增长,每增加一个并发约占用 1.13% 的 KV Cache(约 52 MB),与单请求实测值(~58 MB/请求)基本吻合。
发现 2:三个阶段清晰可见
阶段一(conc=1~64):线性增长区
KV Cache 有余量,所有请求都能同时运行
实际运行中 ≈ 发送并发数
阶段二(conc=80~96):接近饱和区
KV Cache 即将打满,开始出现"实际运行 < 发送并发"
conc=96 时 KV Cache 已用 99.96%,但只有 82 个请求同时运行
阶段三(conc=128):完全饱和区
KV Cache 100% 打满
128 个请求只有 104 个同时运行,24 个请求需要等待发现 3:KV Cache 打满的临界并发数
临界并发 = KV Cache 总容量 单请求峰值 KV = 4642.8 MB 58.6 MB ≈ 79 \text{临界并发} = \frac{\text{KV Cache 总容量}}{\text{单请求峰值 KV}} = \frac{4642.8 \text{ MB}}{58.6 \text{ MB}} \approx 79 临界并发=单请求峰值 KVKV Cache 总容量=58.6 MB4642.8 MB≈79
实测 conc=80 时 KV Cache 使用率 88.65%,conc=96 时 99.96%,与理论推算的临界点 ~79 基本吻合。超过这个点,新请求必须等待前面的请求释放 KV Cache。
💡 为什么 conc=128 时运行中是 104 而不是 79?
因为 128 个请求不是同时处于"最长"状态。有的请求已经快生成完了(KV Cache 即将释放),有的刚开始(KV Cache 还很小),vLLM 的 continuous batching 机制会"边完成边调度"------一个请求结束释放 KV Cache 后,排队的请求立即填入。所以任意时刻实际运行中的请求数可以超过理论临界值。
发现 4:回看前两篇实验的吞吐瓶颈
这个数据直接解释了前两篇文章的实验现象:
BF16 基线(KV Cache 总容量 4.6 GB):conc=32 时 KV Cache 用了 38%,还有余量;conc=64 时用了 73%,开始吃紧;conc=128 时完全打满。这正是基线实验中 conc=64→128 时 TPOT P99 从 165ms 暴涨到 387ms 的根本原因------不是 GPU 算力不够,而是 KV Cache 塞满了,请求被迫排队。
AWQ INT4(KV Cache 总容量 13.9 GB,是 BF16 的 3 倍):同样 conc=128 时 KV Cache 才用到约 33%,远未饱和。这就是 AWQ 吞吐翻倍的第二重原因------除了 TPOT 降低(带宽收益),KV Cache 扩容让系统能同时服务 3 倍的请求。
四、总结
4.1 本文完成的工作
本文从原理到实测,完整解析了 KV Cache 在 LLM 推理中的角色:
| 内容 | 结果 |
|---|---|
| KV Cache 原理与公式推导 | ✅ 完成 |
| PagedAttention 机制解析 | ✅ 完成 |
| 单请求 KV Cache vs 序列长度实测 | ✅ 理论与实测高度吻合 |
| 并发数 vs KV Cache 占用实测 | ✅ 找到 KV Cache 打满临界点 |
| BF16 vs AWQ 的 KV Cache 容量对比 | ✅ 量化了 AWQ 吞吐翻倍的 KV Cache 因素 |
4.2 关键结论
结论 1:KV Cache 占用与序列长度和并发数严格线性
总 KV Cache = N r e q u e s t s × L t o k e n s × 56 KB/token \text{总 KV Cache} = N_{requests} \times L_{tokens} \times 56 \text{ KB/token} 总 KV Cache=Nrequests×Ltokens×56 KB/token
实测每 token 占用稳定在 ~55 KB,与理论值 56 KB 几乎完全一致,偏差仅来自 PagedAttention 的 Block 对齐(block_size=16)。
结论 2:KV Cache 是高并发场景下的真正瓶颈
BF16 模型下 KV Cache 总容量为 4.6 GB,临界并发约 88 个请求。超过后 KV Cache 打满,新请求被迫等待:
conc=64: KV Cache 72.6%,所有请求正常运行
conc=96: KV Cache 99.96%,只有 82 个请求能同时运行
conc=128: KV Cache 100%,只有 104 个请求能同时运行结论 3:AWQ 吞吐翻倍 = TPOT 收益 + KV Cache 扩容收益
BF16:权重 14 GB,KV Cache 容量 5306 blocks(4.6 GB)
AWQ: 权重 4 GB, KV Cache 容量 15839 blocks(13.9 GB)
↑ 3 倍!AWQ 把权重从 14 GB 压到 4 GB,省出的 ~10 GB 全部给了 KV Cache,容量扩大 3 倍。这意味着同样的显存条件下能同时服务 3 倍的请求,这是 AWQ 吞吐翻倍中被忽视但更重要的一半原因。
4.3 未完成的实验
本文原计划测试 FP8/INT8 KV Cache 量化以进一步压缩 KV Cache,但 RTX 3090(Ampere 架构,SM 8.6)不支持原生 FP8 计算,INT8 KV Cache 的精度损失也超出可接受范围(HellaSwag 从 80.5% 降至 65.5%)。KV Cache 量化需要 Ada Lovelace(RTX 4090)或 Hopper(H100)架构的硬件支持,在 RTX 3090 上不可行。
4.4 三篇文章的完整对照表
=== 完整实验记录 ===
基线 v0 (BF16) 实验 1 (AWQ INT4)
硬件: RTX 3090 24GB RTX 3090 24GB
模型权重: ~14 GB ~4 GB
KV Cache 容量: 5306 blocks (4.6GB) 15839 blocks (13.9GB)
KV Cache 临界并发: ~88 ~265(推算)
精度:
HellaSwag: 80.5% 79.6% (-0.9%)
ARC-Easy: 81.0% 78.8% (-2.2%)
ARC-Challenge: 55.5% 54.5% (-1.0%)
GSM8K: 71.3% 69.2% (-2.1%)
性能:
TPOT P50 (conc=1): 19.7 ms 6.84 ms (-65%)
Out_TPS (conc=32): 978 tok/s 2126 tok/s (+117%)
严格 SLO Goodput: 826 tok/s 4547 tok/s (+450%)
生产甜点区: conc=8~16 conc=16~324.5 下一步计划
| 实验 | 方法 | 预期收益 |
|---|---|---|
| Prefix Caching 效果验证 | 测试相同 system prompt 下的 TTFT 变化和 KV Cache 复用率 | TTFT 降低、KV Cache 节省 |
| 投机采样(Speculative Decoding) | 用小模型草稿 + 大模型验证,加速 decode | 低并发 TPOT 降 30~50%,精度零损失 |
本系列下一篇:投机采样实验:精度零损失的加速方案(待更新)
参考资料:
- Efficient Memory Management for Large Language Model Serving with PagedAttention(SOSP 2023)
- vLLM 官方文档
- AWQ: Activation-aware Weight Quantization(MLSys 2024 Best Paper)