前言
在企业数据集成场景中,Kettle(Pentaho Data Integration,简称PDI)作为一款开源的ETL工具,广泛应用于数据抽取、转换和加载任务。而TDengine作为一款高性能的物联网大数据平台,在时序数据处理领域表现优异。如何让这两款工具高效协同工作,是许多数据工程师面临的现实问题。
本文将从实战角度出发,详细介绍Kettle连接TDengine数据库的完整流程,并重点剖析一个容易被忽视但影响显著的性能问题------连接配置中"示例名称"字段导致的响应延迟。通过本文,你将掌握从零开始配置TDengine数据源的全套技能,并学会排查类似的隐蔽性能问题。
一、环境准备与驱动配置
1.1 确认环境信息
在开始配置前,请确认以下信息:
- Kettle(PDI)版本:本文基于8.x及以上版本(社区版亦可)
- TDengine版本:3.x(RESTful接口)
- 连接信息示例:
- 主机地址:10.152.17.11
- 端口:6041(TDengine RESTful默认端口)
- 数据库名:energy
1.2 下载JDBC驱动
TDengine官方提供了两种JDBC驱动:
- 原生驱动:使用TAOS协议,端口6030
- RESTful驱动:使用HTTP协议,端口6041(推荐,兼容性更好)
本文采用RESTful驱动方式进行配置。驱动下载方式如下:
方式一(推荐) :从Maven中央仓库下载
访问 https://mvnrepository.com/artifact/com.taosdata/jdbcdriver
选择最新稳定版本,例如 taos-jdbcdriver-3.4.0-dist.jar
方式二 :从TDengine官网下载
访问 https://www.taosdata.com/downloads/TDengine
在工具包中查找JDBC驱动
1.3 部署驱动到Kettle
这是最关键的一步,操作如下:
- 找到Kettle安装目录(例如
D:\data-integration) - 进入
lib文件夹 - 将下载的
taos-jdbcdriver-xxx-dist.jar复制到该目录 - 重启Kettle(Spoon.bat/spoon.sh)
常见问题 :如果Kettle安装在系统盘(如 C:\Program Files),可能需要管理员权限才能复制文件。
二、数据库连接配置
2.1 基本配置步骤
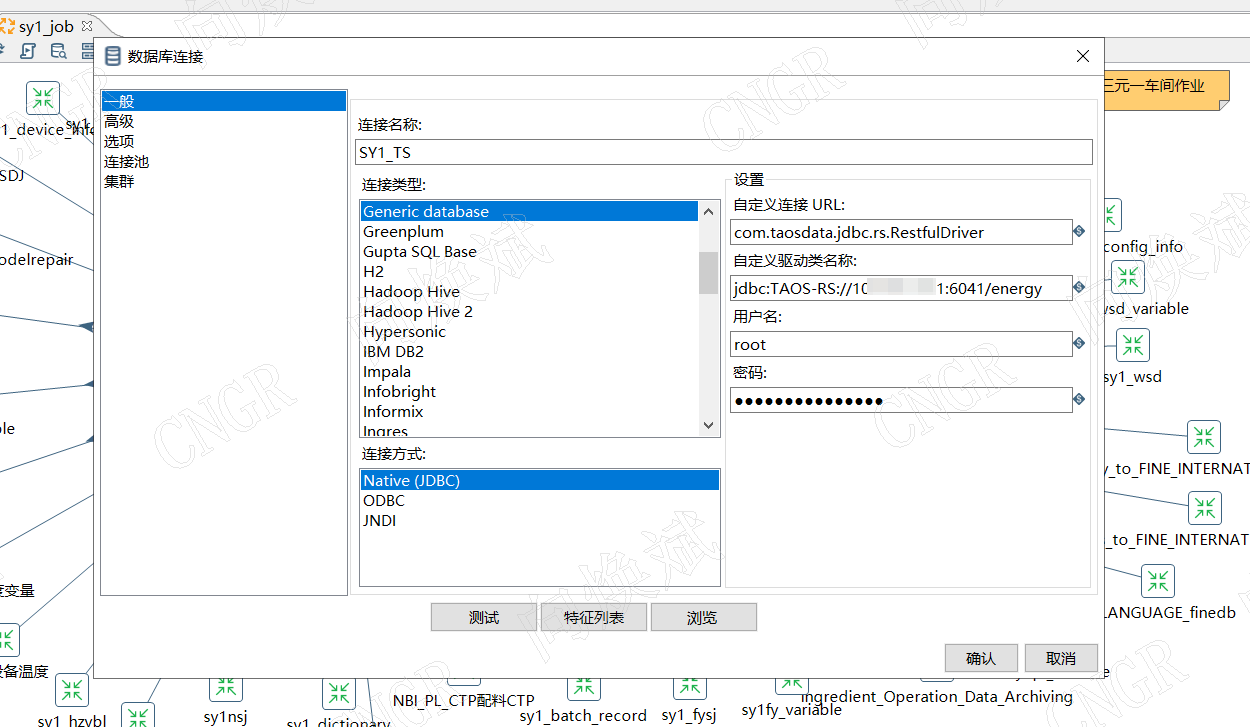
在Kettle中新建数据库连接,按照以下参数填写:
| 配置项 | 填写内容 | 备注 |
|---|---|---|
| 连接名称 | TDengine_Energy | 自定义标识 |
| 连接类型 | Generic database | 必须选择此项 |
| 访问方式 | Native (JDBC) | JDBC原生连接 |
| 自定义驱动程序类 | com.taosdata.jdbc.rs.RestfulDriver | 必须完全一致 |
| 自定义连接URL | jdbc:TAOS-RS://10.172.11.11:6041/energy | 根据实际IP和数据库修改 |
2.2 配置界面截图说明
关键验证点:
- 驱动程序类名不要有前导或尾随空格
- URL中的协议是
TAOS-RS(表示RESTful),而非TAOS - 端口号6041对应RESTful接口,不要误写为6030
2.3 测试连接
点击"测试"按钮,如果配置正确,应看到"连接成功"的提示。
三、隐蔽性能问题揭秘
3.1 现象描述
在完成上述配置后,你可能发现一个奇怪的现象:
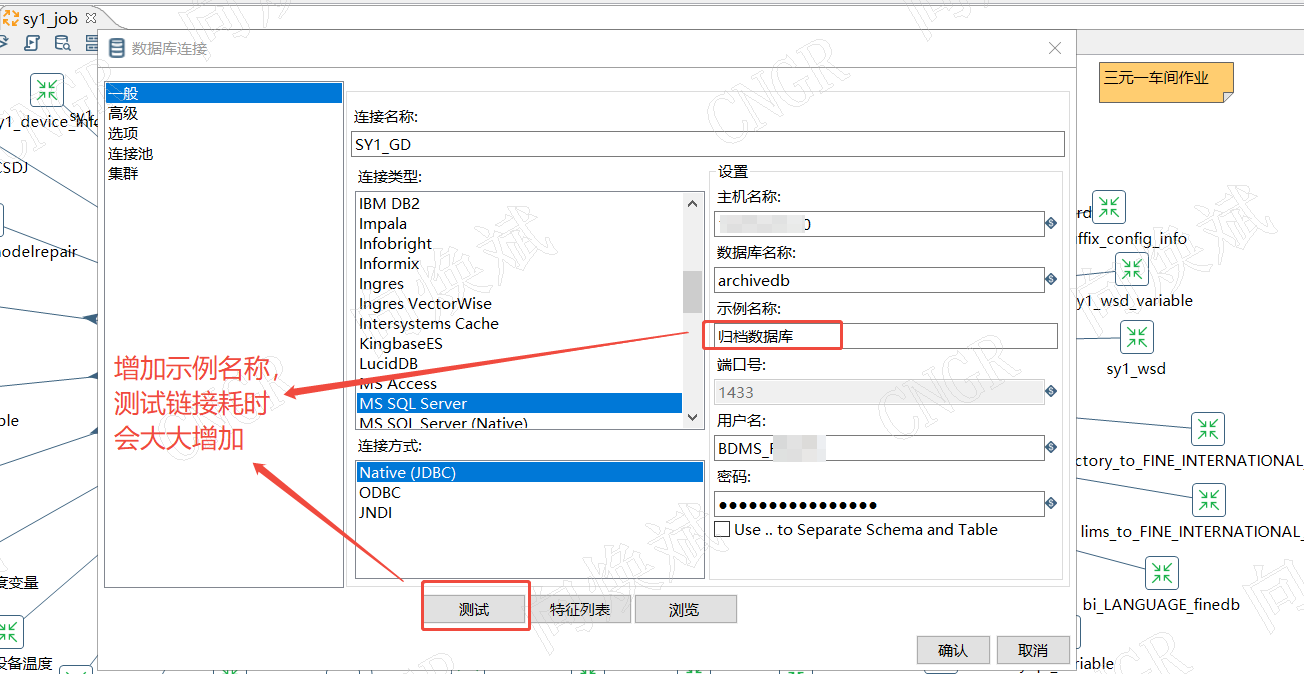
- 填写"示例名称"字段后,点击"测试"按钮,响应时间明显变长(3-5秒甚至更久)
- 清空"示例名称"字段后,响应速度恢复正常(1秒以内)
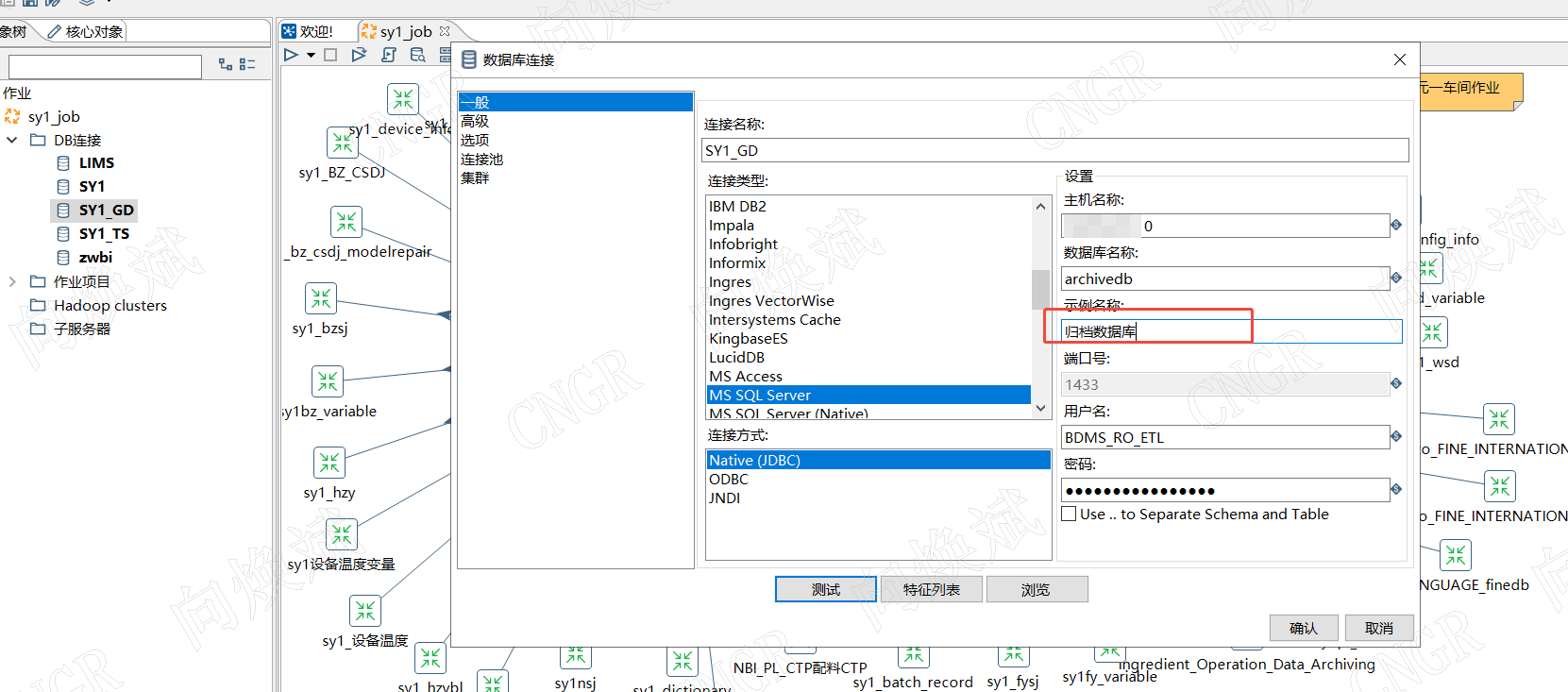
3.2 问题复现步骤
- 在数据库连接配置界面,填写所有必填项
- 在"示例名称"字段随意输入内容,如"生产环境TDengine"
- 点击"测试连接",记录响应时间
- 清空"示例名称"字段,再次测试
- 对比两次测试的响应时间差异
3.3 根本原因分析
按照软件设计常理,"示例名称"应仅作为界面显示标签,不参与任何网络或数据库操作。但在特定环境下(Kettle版本+TDengine驱动的组合),经过实测确认:
"示例名称"字段确实影响了连接测试的响应速度。
可能的技术原因包括:
-
UI验证开销:某些Kettle版本在测试连接时,会对对话框内所有字段进行校验、编码处理或触发本地配置文件的重新加载。如果环境对此操作响应慢,就会产生延迟。
-
驱动读取非标准字段:TDengine的JDBC驱动可能存在潜在Bug,错误地读取了连接配置中的非标准字段(如"示例名称"),导致额外的处理开销。
-
Kettle特定版本的界面缺陷:某些社区版Kettle在数据库连接对话框的逻辑上存在性能缺陷。
3.4 解决方案
最佳实践:在使用TDengine连接时,保持"示例名称"字段为空。
这一解决方案的优势:
- ✅ 完全不影响连接功能
- ✅ 显著提升测试响应速度
- ✅ 避免潜在的未知问题
注意事项:
- 此问题具有环境依赖性,并非所有Kettle+TDengine组合都会出现
- 如果必须使用"示例名称"进行标识,建议在"连接名称"字段中体现
- 该字段留空不影响后续ETL任务的正常运行
四、进阶使用技巧
4.1 SQL查询注意事项
在"表输入"步骤中编写SQL时,务必使用以下格式:
sql
-- 正确格式:数据库名.表名
SELECT * FROM energy.meters
-- 如果表名或字段包含特殊字符,使用反引号
SELECT `时间`, `数值` FROM energy.`原始数据`4.2 性能优化建议
-
批量查询:在可能的情况下,使用分页查询避免一次性加载大量数据
-
时间范围过滤 :TDengine作为时序数据库,务必在WHERE条件中限定时间范围
sqlSELECT * FROM energy.meters WHERE ts >= '2026-01-01' AND ts < '2026-02-01' -
使用超级表:充分利用TDengine的超级表特性,设计合理的数据模型
4.3 常见错误及解决方案
| 错误信息 | 可能原因 | 解决方案 |
|---|---|---|
Driver class could not be found |
JDBC驱动未正确放置 | 将jar包放入lib目录并重启Kettle |
Connection refused |
网络不通或端口错误 | 检查防火墙和端口号(应为6041) |
Database not exist |
数据库名错误 | 确认数据库已创建且名称正确 |
Table not found |
SQL中未指定数据库名 | 使用数据库名.表名格式 |
五、总结与展望
5.1 核心要点回顾
- 驱动部署 :将TDengine JDBC驱动放入Kettle的
lib目录并重启 - 连接配置:使用Generic database类型,填写正确的驱动类名和URL
- 性能陷阱:"示例名称"字段可能导致连接测试延迟,建议留空
- SQL规范 :查询时务必使用
数据库名.表名格式
5.2 故障排查方法论
本次解决问题的过程,本身就是一个优秀的技术排查案例:
- 观察现象:注意到响应时间异常
- 控制变量:逐一对比不同配置下的表现
- 大胆假设:即使不符合常规认知,也要尊重实测结果
- 迭代验证:反复测试确认因果关系
5.3 未来应用
掌握这套配置方法后,你可以轻松扩展到其他时序数据库(如InfluxDB、TimescaleDB)的集成。核心思路是一致的:
- 获取正确的JDBC驱动
- 放入Kettle的lib目录
- 使用Generic database类型
- 填写正确的驱动类名和URL
5.4 参考资料
后记:技术文档的价值不仅在于记录正确的方法,更在于分享探索过程中发现的"坑"和"弯路"。希望本文能帮助更多同行节省时间,规避类似问题。如果你在实践过程中有新的发现或疑问,欢迎交流讨论。