模型本身只能生成文本。
Agent 想要读取实时信息、执行代码、查询数据库、创建文件,就必须把外部能力包装成 Tool。
Tool 可以理解成 Agent 连接现实世界的接口:
- 读取新信息,比如搜索、数据库、内部系统。
- 执行外部动作,比如发请求、写文件、调用业务接口。
- 把模型不擅长的事情交给确定性的代码,比如计算、校验、格式转换。
先记住一句话:模型负责决定要不要调用 Tool,以及生成 Tool 参数;代码负责真正执行 Tool。
Tool 解决什么问题
没有 Tool 时,模型只能基于已有上下文回答。
它不能自己访问数据库,也不能自己读取文件,更不能真的执行一个外部 API。
例如:直接问模型"现在是什么时间",它可能会告诉你自己无法实时获取当前时间,因为这类问题依赖运行时环境,不属于模型静态知识。
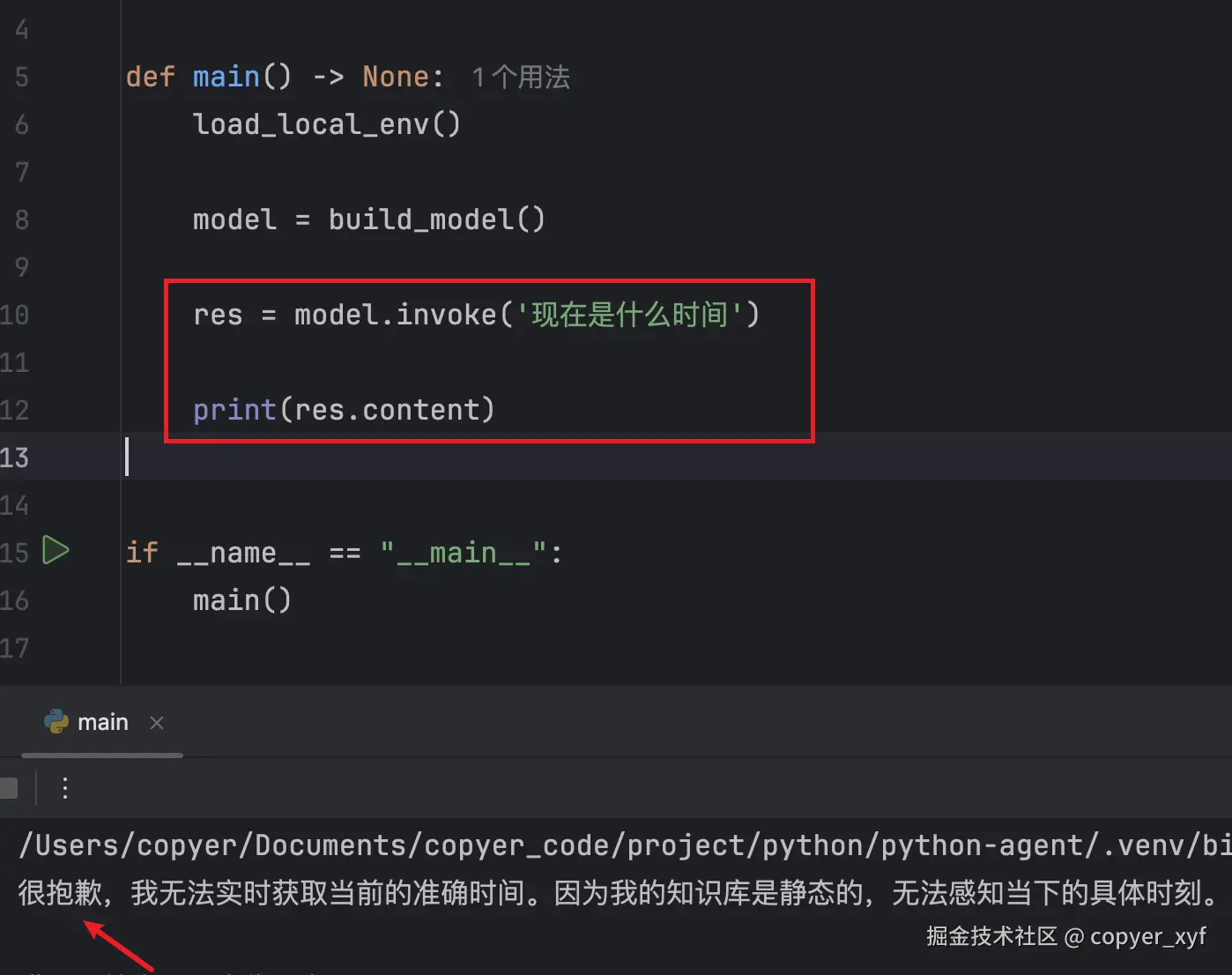
Tool 的作用就是把一段代码能力暴露给模型,让模型在需要时生成调用意图。
txt
用户问题 -> 模型判断需要 Tool -> 生成 tool_calls -> 程序执行 Tool -> ToolMessage 回传结果 -> 模型继续回答这里要分清两个动作:
- 模型生成的是"调用计划",不是实际执行。
- 真正执行 Tool 的是你的程序。
tool_calls 从哪里来
模型并不是"真的知道"你的函数。
你把 Tool 的 name、description、args_schema 绑定给模型后,模型会根据这些信息预测下一步要不要调用 Tool。
AIMessage.tool_calls 里通常会包含:
txt
name:模型想调用哪个 Tool
args:模型为 Tool 生成的参数
id:这次 Tool 调用的唯一标识所以 Tool 调用本质上是一个闭环:
txt
invoke -> 读取 tool_calls -> 执行 Tool -> 回传 ToolMessage -> 再次 invoke只要模型还在返回 tool_calls,程序就继续执行 Tool 并把结果交回去。
定义 Tool
Python 里可以用 @tool 把普通函数包装成 LangChain Tool。
python
from datetime import datetime
from typing import Literal
from zoneinfo import ZoneInfo
from pydantic import BaseModel, Field
from langchain_core.tools import tool
class CurrentTimeInput(BaseModel):
"""查询当前时间需要的参数。"""
time_zone: Literal["Asia/Shanghai", "UTC", "America/New_York"] = Field(
default="Asia/Shanghai",
description="IANA 时区名称。北京时间用 Asia/Shanghai。",
)
@tool(
"get_current_time",
args_schema=CurrentTimeInput,
description="查询指定时区的当前日期和时间",
)
def get_current_time(time_zone: str = "Asia/Shanghai") -> str:
# 这里是真正执行的代码:由运行时环境读取当前时间
current_time = datetime.now(ZoneInfo(time_zone))
return current_time.strftime("%Y-%m-%d %H:%M:%S %Z")这段代码分成两层:
- 执行逻辑:
get_current_time() - Tool 说明:Tool 名、
description、args_schema
description 和 Field(description=...) 很重要。
模型并不会读你的函数实现,它主要靠 Tool 描述和字段描述来判断:
txt
什么时候调用这个 Tool
调用时应该填哪些参数
每个参数应该是什么含义如果模型经常传错参数,通常先检查描述是不是写得太模糊。
直接执行 Tool
Tool 本质上仍然是一段可执行代码。
绑定给模型之前,可以先直接调用它,确认 Tool 本身逻辑没问题。
python
# 直接传入符合 args_schema 的参数
result = get_current_time.invoke(
{
"time_zone": "Asia/Shanghai",
}
)
print(result)这一步和模型无关。
它只是验证:如果参数正确,Tool 能不能正常返回结果。
绑定 Tool
定义 Tool 之后,还要把 Tool 绑定给模型。
python
# bind_tools 会把 Tool 的 name、description、args_schema 注入到模型请求中
model_with_tools = model.bind_tools(
[get_current_time],
# strict 会要求模型严格遵守 Tool 参数 schema
strict=True,
# auto 表示让模型自己判断是否需要调用 Tool
tool_choice="auto",
)可以这样理解:
txt
@tool:把函数变成 Tool
bind_tools():把 Tool 列表交给模型tool_choice 控制模型能不能调用 Tool:
"auto":模型自己判断,最常用。"none":禁止 Tool 调用,模型只能直接回答。- 指定某个 Tool:强制模型调用某个 Tool。
生产环境里建议尽量开启 strict=True。
它能减少模型生成错误参数结构的概率。
读取 tool_calls
绑定 Tool 后,模型第一次回答时不一定直接给最终答案。
如果它判断需要 Tool,会在 tool_calls 里给出调用计划。
python
from langchain_core.messages import HumanMessage
messages = [
HumanMessage(content="现在北京时间是几点?"),
]
# 这一步只是让模型决定要不要调用 Tool
ai_message = model_with_tools.invoke(messages)
print("第一次模型返回:")
print(f"content: {ai_message.content}")
print(f"tool_calls: {ai_message.tool_calls}")tool_calls 可能长这样:
python
[
{
"name": "get_current_time",
"args": {
"time_zone": "Asia/Shanghai",
},
"id": "call_123",
"type": "tool_call",
}
]
# 这里是列表,说明模型一次可能会生成多个 Tool 调用
注意:这时候 Tool 还没执行。
模型只是说:"我想调用 get_current_time,参数是这些。"
执行 Tool 并回填结果
拿到 tool_calls 后,程序要找到对应 Tool 并执行。
执行结果不能随便拼回对话里,而要作为 ToolMessage 回填给模型。
Python 里把完整 tool_call 传给 Tool 的 invoke() 时,LangChain 会帮你生成带 tool_call_id 的 ToolMessage。
python
from langchain_core.messages import HumanMessage
from langchain_core.tools import BaseTool
# 收集 tools
tools = [get_current_time]
def find_tool(tools: list[BaseTool], name: str) -> BaseTool:
# 根据模型生成的 tool call name 找到本地 Tool
for current_tool in tools:
if current_tool.name == name:
return current_tool
raise RuntimeError(f"模型调用了不存在的 Tool: {name}")
messages = [
HumanMessage(content="现在北京时间是几点?请用一句话告诉我结果"),
]
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
# 遍历 ai_message 找到的 tool_calls
for tool_call in ai_message.tool_calls:
# 1. 根据模型返回的 name 找到本地 Tool
selected_tool = find_tool(tools, tool_call["name"])
# 2. 传入完整 tool_call,LangChain 会保留 tool_call_id
tool_message = selected_tool.invoke(tool_call)
# tool_message 是 ToolMessage,里面会带上 content 和 tool_call_id
# 3. 把 Tool 结果回填到消息历史
messages.append(tool_message)
# 4. 再次调用模型,让模型基于 Tool 结果生成最终回答
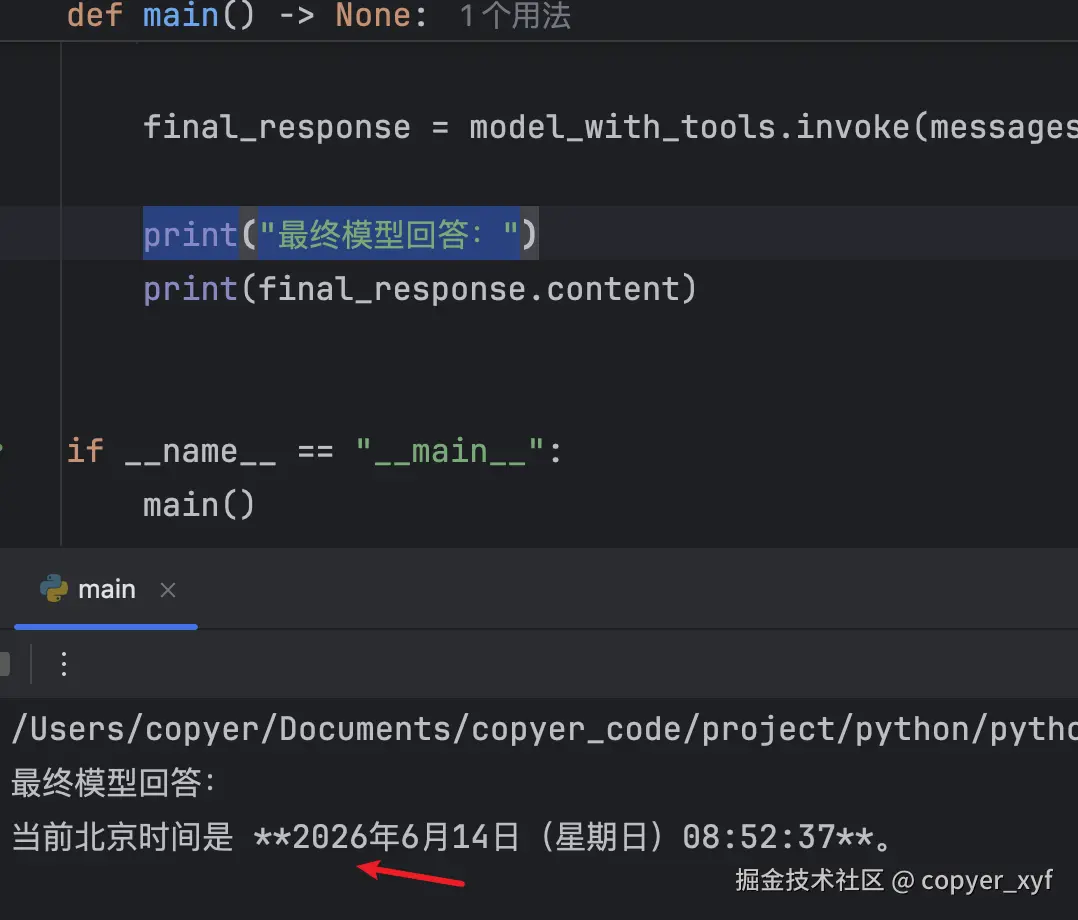
final_message = model_with_tools.invoke(messages)
print("最终模型回答:")
print(final_message.content)这里最容易漏的是 tool_call_id。
它是 Tool 调用和 Tool 结果之间的对应关系:
txt
AIMessage.tool_calls[0]["id"] -> ToolMessage.tool_call_id把完整 tool_call 传给 Tool 时,LangChain 会自动处理这个对应关系。
那么经过这一轮"执行 Tool -> 回填结果 -> 再次调用模型"之后,就可以拿到正确的时间了。
invoke 接收消息列表
前面很多示例都写成:
python
model.invoke("现在北京时间是几点?")这是最简单的写法,相当于只传一条用户消息。
但在 Agent Tool 调用里,更常见的是把消息整理成列表:
python
messages = [
HumanMessage(content="现在北京时间是几点?"),
]
ai_message = model_with_tools.invoke(messages)invoke(messages) 的意思是:把这一组消息作为本轮上下文交给模型。
所以 Tool 调用不是一次 invoke() 就结束,而是围绕这个 messages 列表不断补充上下文。
大致关系是:
txt
HumanMessage:用户原始问题
AIMessage:模型返回的 tool_calls
ToolMessage:Tool 执行结果
AIMessage:模型基于 Tool 结果生成最终回答代码里反复出现 messages.append(...),就是在维护这个传给 invoke() 的消息列表:
messages.append(ai_message):把模型的 Tool 调用请求放回上下文。messages.append(tool_message):把 Tool 执行结果放回上下文。- 再次
invoke(messages):让模型基于完整上下文继续回答。
如果不把这些消息放回列表,模型下一轮就看不到 Tool 结果,也不知道刚刚发生了哪次 Tool 调用。
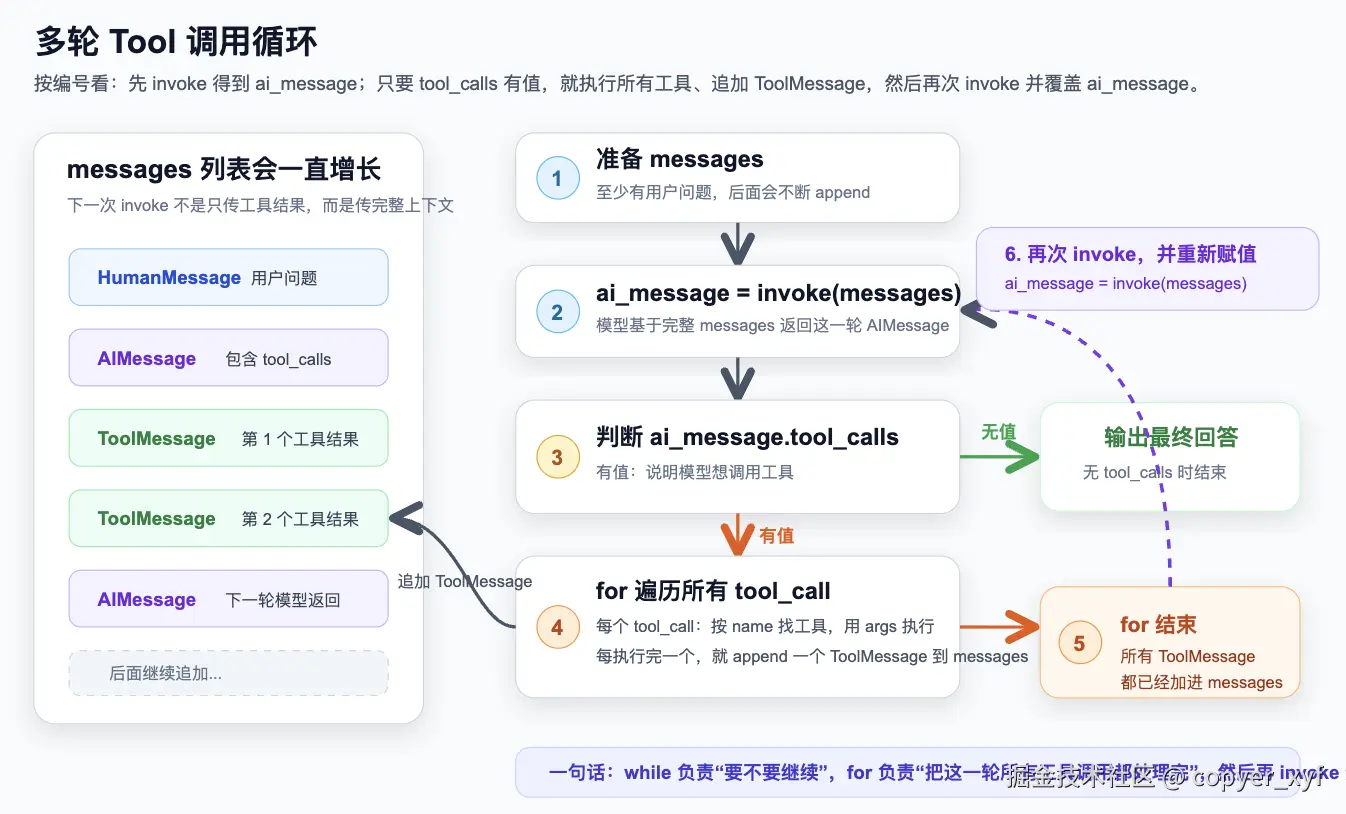
多轮 Tool 循环
一个真实 Agent 不一定只调用一次 Tool。
模型可能调用 Tool A,看到结果后又决定调用 Tool B。
所以通常要写一个循环:
python
from langchain_core.messages import HumanMessage
from langchain_core.tools import BaseTool
# 收集 tools,这里可能会存在很多个
tools = [get_current_time]
def find_tool(tools: list[BaseTool], name: str) -> BaseTool:
# 根据 Tool 名查找本地 Tool
for current_tool in tools:
if current_tool.name == name:
return current_tool
raise RuntimeError(f"模型调用了不存在的 Tool: {name}")
messages = [
HumanMessage(content="现在北京时间是几点?如果已经过了 18 点,提醒我整理日报"),
]
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
while ai_message.tool_calls:
for tool_call in ai_message.tool_calls:
# 1. 根据模型返回的 name 找到本地 Tool
selected_tool = find_tool(tools, tool_call["name"])
# 2. 传入完整 tool_call,执行 Tool 并生成 ToolMessage
tool_message = selected_tool.invoke(tool_call)
# 3. 把 Tool 结果回填到 messages,下一轮模型才能看到
messages.append(tool_message)
# 4. Tool 结果都回填完后,再让模型继续判断下一步
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
print(ai_message.content)这个循环就是 Agent 的雏形:
txt
模型思考 -> 调用 Tool -> 观察结果 -> 继续思考读取文件 Tool
再看一个更接近开发场景的 Tool:读取项目里的文本文件。
python
from pathlib import Path
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.tools import BaseTool, tool
PROJECT_ROOT = Path.cwd()
MAX_FILE_CHARS = 2000
class ReadFileInput(BaseModel):
# 尽量要求模型使用项目内相对路径
file_path: str = Field(description="项目内文本文件路径,例如 src/main.py")
@tool(
"read_file",
args_schema=ReadFileInput,
description="读取指定路径的文本文件内容。当用户询问文件内容或代码时使用。",
)
def read_file(file_path: str) -> str:
root = PROJECT_ROOT.resolve()
target = Path(file_path)
# 1. 相对路径按项目根目录解析
if not target.is_absolute():
target = root / target
resolved_target = target.resolve()
# 2. 防止读取项目目录外的文件
if root not in resolved_target.parents and resolved_target != root:
return "读取失败: 文件路径必须位于当前项目目录内"
if not resolved_target.is_file():
return f"读取失败: 文件不存在 {file_path}"
try:
# 3. 只读取 UTF-8 文本文件
content = resolved_target.read_text(encoding="utf-8")
except UnicodeDecodeError:
return "读取失败: 只支持 UTF-8 文本文件"
# 4. 截断过长内容,避免一次塞太多 token 给模型
if len(content) > MAX_FILE_CHARS:
return content[:MAX_FILE_CHARS] + "\n...(内容过长,已截断)"
return content
def find_tool(tools: list[BaseTool], name: str) -> BaseTool:
for current_tool in tools:
if current_tool.name == name:
return current_tool
raise RuntimeError(f"模型调用了不存在的 Tool: {name}")
tools = [read_file]
model_with_tools = model.bind_tools(tools, strict=True, tool_choice="auto")
messages = [
SystemMessage(content="回答文件相关问题前,必须先调用 read_file 读取文件内容。"),
HumanMessage(content="请读取 src/main.py,并解释这个文件做了什么。"),
]
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
while ai_message.tool_calls:
for tool_call in ai_message.tool_calls:
# 1. 根据模型返回的 name 找到本地 Tool
selected_tool = find_tool(tools, tool_call["name"])
# 2. 传入完整 tool_call,执行 Tool 并生成 ToolMessage
tool_message = selected_tool.invoke(tool_call)
# 3. 把 Tool 结果回填到 messages,下一轮模型才能看到
messages.append(tool_message)
# 4. Tool 结果都回填完后,再让模型继续判断下一步
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
print(ai_message.content)这个例子里,模型不负责读取文件。
模型只负责判断:
txt
用户在问文件内容 -> 应该调用 read_file -> 参数是 src/main.py真正的文件读取、安全校验、内容截断都在 Tool 函数里完成。
小结
这一篇要记住几个核心点:
- Tool 是 Agent 连接外部世界的接口。
- 模型不会真的执行 Tool,它只生成
tool_calls。 name、description、args_schema决定模型能不能正确调用 Tool。bind_tools()会把 Tool 定义注入给模型。- Tool 结果要作为 ToolMessage 回填给模型。
tool_call_id必须和模型生成的 tool call id 对齐。- Tool 循环就是 Agent "思考-行动-观察"的基础结构。