这不是一篇教你"怎么用 epoll"的文章,而是一篇回答------Go 的高并发网络服务背后,epoll 是怎样被"驯化"进 goroutine 调度体系的。因此在看本文之前,如果你还不是很了解什么是epoll,可以先看一下下面几篇博客稍微了解一下什么是epoll:
1 从餐厅故事到 I/O 多路复用------我们到底在解决什么问题?
1.1 一个goroutine per conn 为什么不会崩
你肯定见过这样字的 "Go TCP"服务代码:
Go
func main() {
ln, _ := net.Listen("tcp", ":8080")
for {
conn, _ := ln.Accept()
go serve(conn) // 一个连接 = 一个 goroutine
}
}
func serve(conn net.Conn) {
defer conn.Close()
buf := make([]byte, 4096)
conn.Read(buf)
conn.Write(buf)
}直觉告诉我们:如果每个连接一个线程一连接(像传统 C 模型那样),几万连接就把 OS 压垮了。但 Go 跑几十万连接却轻轻松松------关键不在于 go关键字有多魔法,而在于 Go 的网络 I/O 从不让 OS thread 因为"等数据"而阻塞。
这背后依赖的,就是 epoll + netpoll + GMP 调度 三者的协作。但要理解它,我们得先退一步,看看 epoll 要解决的根本问题是什么。
1.2 三种模型的演进
| 模型 | 做法 | 问题 |
|---|---|---|
| **阻塞 I/O(BIO)** | 每个 fd 配一个 thread,read(fd)没数据就阻塞 thread |
1 thread = 1 fd,thread 昂贵,无法扩展 |
| **非阻塞 I/O + 忙轮询(NIO)** | 把所有 fd 设为 non-blocking,循环 tryRead(fd);没数据就 EAGAIN跳过 |
thread 永不休眠 → CPU 空转,不可接受 |
| **I/O 多路复用(epoll)** | 把一批 fd 交给内核监视 ,thread 在没有事件时睡过去 ;有事件就绪时内核唤醒 thread,并精确告诉哪些 fd 就绪 | ✅ 正确解法 |
用餐厅做个比喻:
- BIO:一个服务员只盯着一张桌子,这个桌子客人没点菜就不能服务下一个桌子的客人 -> 人效极低
- NIO忙轮询:一个服务员在桌子间来回跑,不断询问"要点菜吗",哪怕没人叫他他也会询问 -> 服务员累死(CPU空转)
- epoll :服务员告诉厨房"有需求再来叫我",然后去打盹 ;谁喊了,厨房摇铃把他叫醒,还告诉他具体哪桌 → 人效最优
一句话 :epoll 的本质贡献是两点------thread 可以睡(省 CPU) ,以及醒了知道是谁(省遍历) 。
2 epoll 内核机制------三件套与事件回调
这一章只讲 epoll 本身(Linux 视角),不讲 Go。先把地基看清。
2.1 三个指令分工
Go
// 1) 建池
int epfd = epoll_create1(EPOLL_CLOEXEC);
// 2) 增/改/删 fd
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET; // 关心"读就绪",边缘触发
ev.data.fd = fd; // 回调上下文
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);
// 3) 等事件
struct epoll_event events[MAX];
int n = epoll_wait(epfd, events, MAX, timeout);
// timeout=-1 阻塞 / timeout=0 非阻塞 / timeout>0 超时- epoll_create:在内核开辟一块持久空间(epoll 实例),管理一张"我要监听的 fd 表"。(红黑树)
- epoll_ctl(ADD/MOD/DEL) :增删改这张表。内核用红黑树 存 fd(key=fd),所以增删改 O(logN);而且fd 注册是一次性的,不像 select 每一轮都要把整个 fd set 从用户态拷进内核态。
- epoll_wait :取"就绪事件"。当 fd 上有 I/O 事件到达,内核通过事件回调 把对应 entry 挂到就绪链表 ;
epoll_wait只需扫这个链表 → O(1) 返回精确就绪集。

2.2 边沿触发(ET)VS水平触发(LT)
Go 使用的是 EPOLLET(边沿 **触发)** 模式,这是理解 netpoll 行为的前提:
| LT(默认) | ET | |
|---|---|---|
| 就绪通知 | fd 就绪就一直通知 | fd 就绪只在状态变化时通知一次 |
| 你必须做 | 无所谓 | 必须读完/写完直到 EAGAIN,否则可能饿死这个 fd |
| Go 的做法 | --- | 天然匹配:Go 外层已经是"循环 tryRead → EAGAIN → gopark"模式 ✅ |
所以,go使用边沿触发因为它与 Go 自身的 非阻塞循环 + gopark 阻塞 的 I/O 模型高度契合。
假设使用水平触发, fd 上有 100 字节数据,Go 一次 read 只取了 50 字节(因为缓冲区大小限制或调度原因),剩余 50 字节还在内核缓冲区。
- LT 模式 :下次
epoll_wait会再次立即返回这个 fd,即使没有新数据到达。这会迫使 Go 再次唤醒 goroutine 去读剩下的 50 字节。 - 但 Go 的 goroutine 被唤醒后,需要经过调度、上下文切换、再次执行
epoll_wait...... 这些开销本可以避免------因为 goroutine 已经在循环中,完全可以一次性读完。
LT 的缺点 :会导致不必要的重复唤醒,增加系统调用次数和调度开销。尤其是当数据量小且频繁时,LT 会放大开销。
2.3 epoll天花板
虽然epoll很强大,但是有一个致命的缺点:
epoll 认识的只有 fd,不认识 goroutine。epoll_wait 阻塞的是 thread(M),不是 G。
而 Go 的核心承诺是------并发粒度是 goroutine,不是 thread 。这个错位,就是 netpoll要解决的。可以理解为,netpoll需要当一个从fd -> goroutine的翻译官的角色,让GMP架构认识并且能够调用起来。
3 Go 的 netpoll------把"fd就绪"翻译成"G可运行"
这是全文最核心的一章。理解了这一章,你就理解了那两篇文章里反复强调的
poll_wait ≠ epoll_wait
3.1 为什么 Go 不能直接用 epoll_wait来挂起 goroutine?
假如你这么写:
Go
// ❌ 假如 Go 允许这样
conn.Read(buf)
// 底层直接调 epoll_wait 等待这个 fd问题是:epoll_wait的调用单元是 thread(M) 。一旦 M 阻塞在 epoll_wait上,它就停住了------同 M 上其他 goroutine(哪怕是纯计算的)也跟着陪葬。这和 Go 承诺的"goroutine 级并发"直接矛盾。
所以 Go 的正确答案必须是:当 G 因 I/O 未就绪而需要等待时 → 挂起的是 G(goroutine 粒度),不是 M(thread 粒度)→ M 立刻回去调度别的 G。
而 fd 就绪后 → 找到当初等这个 fd 的那个 G → 把它变回 runnable → 送进调度队列。
这就是 netpoll 的定位:epoll 的"fd级事件"与 GMP 的"G级调度"之间的翻译层。
3.2 pollDesc:fd ↔ G 的反向映射表
Go 在每个被纳入 epoll 管理的 fd 上绑定一个 pollDesc:
Go
type pollDesc struct {
fd uintptr
rg atomic.Uintptr // 等"读就绪"的 G(或 pdReady/pdWait 状态符)
wg atomic.Uintptr // 等"写就绪"的 G(或 pdReady/pdWait 状态符)
lock mutex
// ...
}rg/ wg就是这个翻译层的关键------它们回答一个问题:"这个 fd 的读/写事件如果就绪了,该唤醒哪个 G?"
状态机用一个精巧的 CAS 协议实现(精简表述):
Go
rg/wg 的可能值:
0 → 空闲
pdReady → 事件已就绪(提前到达的)
pdWait → 有个 G 正在等
G指针 → 那个正在等的 G(通过 netpollblockcommit 写入)3.3 poll_wait:G 级阻塞怎么做(G 视角)
以conn.Read(buf)为例子,当fd非阻塞read返回EAGIN(未就绪)时:
Go
① 外层循环:尝试非阻塞 read(conn_fd)
↓ EAGAIN(数据没到)
② poll_wait 路径:
- CAS 将 pollDesc.rg 从 0 → pdWait
- 调用 gopark() ← 关键!挂起当前 G
→ 状态 _Grunning → _Gwaiting
→ dropg()(G 与 M 解绑)
→ M 切回 g0 → schedule() 去找别的 G
- G 的"等待身份"保存在 pollDesc.rg 中注意 :这里完全没有调 epoll_wait来等待。G 只是被 park 了,fd 早就被注册在 epoll 表里了。
3.4 netpoll:什么时候收割 fd 就绪事件(调度器视角)
netpoll(delay)才是真正调 epoll_wait的地方,而且它在 GMP 的调度循环内部:
Go
// runtime/proc.go → findrunnable() 中
if netpollinited() && netpollWaiters > 0 && ... {
list := netpoll(0) // delay=0 → 非阻塞模式
// list 里是被唤醒的 G,状态还是 _Gwaiting
// injectglist 把它们标为 _Grunnable 送入全局/本地队列
}netpoll()内部做的事:
Go
① epoll_wait(epfd, events, 128, waitms)
↓ 内核返回就绪 fd 列表
② 对每个就绪 event:
- ev.data → pollDesc(反向映射)
- 看 event type → 决定 mode='r' or 'w'
- netpollunblock(pollDesc, mode)
→ CAS 把 rg/wg 从"G指针"抢回来 → 拿到 G
→ 把 G 加入返回列表
③ 返回 gList 给上层然后上层(schedule / sysmon / startTheWorld)把这些 G 送进就绪队列,等待被选中执行------下次 G 被调度到时,它从 gopark后面 恢复执行,看到 rg已被换成 pdReady,就知道"条件满足了",继续走 read。
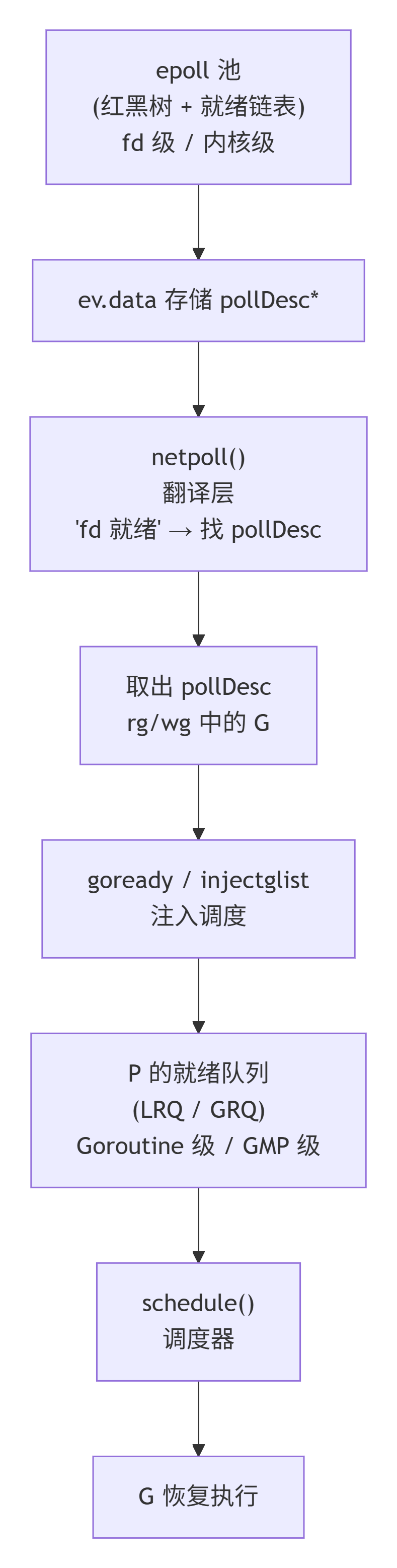
总结一句话:epoll 管"fd 有数据了吗",netpoll 管"那是谁的 G",GMP 管"什么时候跑"。三者各司其职。
4 完整链路源码级走读(一条连接的一生)
我们把四个关键时刻串起来,你会发现每一步都严丝合缝。
4.1 net.Listen ------ epoll创建 + listener fd注册
Go
net.Listen(":8080")
→ syscall.Socket (创建 fd)
→ syscall.Bind / Listen
→ pollDesc.init()
→ runtime_pollServerInit
→ netpollinit()
→ epoll_create1() // 内核建 epoll 池
→ runtime_pollOpen(fd)
→ netpollopen()
→ epoll_ctl(ADD) // fd 注册进 epoll,监听 EPOLLIN|EPOLLOUT|EPOLLET于是在netpollopen函数中会进行一次翻译:
Go
func netpollopen(fd uintptr, pd *pollDesc) int32 {
// 将待监听的 socket fd 添加到 epoll 池中,并注册好回调路径
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}- fd 数据到达 / 可写 / 连接到来 ...
- 内核把它放进 epoll 就绪链
- 下次
epoll_wait返回这个 fd 的 event - event.data 里放的是 pollDesc(Go在ADD时填进去的)*
netpoll 里做"翻译"的关键段(语义级):
Go
for i := 0; i < n; i++ {
ev := &events[i]
// 从 epoll event.data 把 fd 对应的 pollDesc 找回来
pd := *(**pollDesc)(unsafe.Pointer(&ev.data))
// 根据事件类型决定 mode=r/w
// 然后 netpollready(&toRun, pd, mode)
}- epoll 给的是 fd
- Go 通过
pd = *(**pollDesc)(&ev.data)找回 pollDesc - 再从
pd.rg / pd.wg里取出 等它的那个G - 放进返回的
gList
4.2 ln.Accept ------ 非阻塞尝试连接 -> 无连接则gopark
Go
for {
d, err := syscall.Accept(fd) // NON-BLOCK 模式
if err == EAGAIN:
fd.pd.waitRead() // ↓
→ poll_runtime_pollWait() // ↓
→ netpollblock()
→ CAS(rg, 0→pdWait)
→ gopark() // ★ G 挂起!M 立刻去跑别的 G
}此时这个 G 的状态是 _Gwaiting,它"挂在" pollDesc.rg上,而不是挂在任何线程上。
4.3 谁来唤醒? ------ netpoll的三处触发
| 触发点 | 在哪里 | 作用 |
|---|---|---|
| schedule → findrunnable | 每轮调度找 G 时 | netpoll(0)非阻塞收割,有就绪 G 直接拿来跑 |
| sysmon | 独立监控线程,每 ~10ms | netpoll(0)非阻塞检查,唤醒的 G 送全局队列 |
| idle P 留守 | 所有 P 都找不到活时 | netpoll(-1)阻塞等(此时合理------没 G 可跑) |
以 findrunnable中最常见的路径为例:
Go
list := netpoll(0) // 非阻塞 → epoll_wait 拿就绪 fd
→ 对每个就绪 fd → pollDesc → rg/wg → 取回 G
injectglist(&list) // G: _Gwaiting → _Grunnable → 入队列然后 schedule()选中的 G 从 gopark后面恢复,重新 syscall.Accept→ 这次大概率成功 → 拿到 conn fd → conn.Read()同理循环。
也许你会有疑问,为什么netpoll传入参数为0,也就是说为什么采用的时非阻塞的方式?采用非阻塞方式不会导致CPU空转吗?
- 一方面,
p本就是基于轮询模型不断寻找合适的 g 进行调度,而 net_poll 恰好是其寻找 g 的诸多方式的其中一种,因此这个轮询机制是与 gmp 天然契合的,并非是 golang netpoll 机制额外产生的成本; - 再者,这种轮询不是墨守成规,而是随机应变的. 如果一个 p 经历了一系列检索操作后,仍找不到合适的 g 进行调度,那么它不会无限空转,而是会适时地进行
缩容操作------首先保证全局会留下一个 p 进行netpoll 留守,其会通过阻塞或超时模式触发执行epoll_wait操作,保证有 io 事件就绪时不产生延迟;而在有留守 p 后,其它空闲的 p 会将 m 和 p 自身都置为idle 态,让出 cpu 执行权,等待后续有新的 g 产生时再被重新唤醒
4.4 conn.Read()/conn.Write ------ 同样模式
Go
conn.Read(buf)
→ 非阻塞 syscall.Read(fd)
→ EAGAIN?
→ pollDesc.waitRead() → gopark() // 挂起 G
(等 netpoll 通过 epoll 事件唤醒)
→ 被唤醒后重试 Read → 读到数据 → 返回所有网络 I/O 的"阻塞",在 Go 里都是同一套伪装:看起来像阻塞调用,实际上是 goroutine 粒度 park + epoll 事件驱动唤醒。
5 收束------netpoll 在 Go 并发世界观里的位置
回到最开头的问题:为什么 Go 能扛百万连接?
答案不是"epoll 牛逼"这么简单。epoll 只是 Linux 给的零件,真正让零件变成引擎的是:
- GMP调度器:保证执行权永远在G粒度流转,M永不因G的I/O停滞
- gopark/goready原语:提供"挂起G/唤醒G"的原语语义
- netpoll(pollDesc + rg/wg + epoll收割):把内核fd事件翻译成为G的就绪事件,接入调度队列
三者缺一不可:
| 缺了谁 | 后果 |
|---|---|
| 有 epoll 无 GMP | thread 还是被 epoll_wait 阻塞,回到 C/C++ 的老路 |
| 有 GMP 无 netpoll | goroutine 碰到网络 read/write 要么阻塞 thread,要么得手动回调地狱 |
| 有 epoll + GMP 无 pollDesc | 内核告诉你 fd 4 就绪了------但你不知道是哪个 G 在等 fd 4 |
所以 netpoll 从来不是"Go 用 epoll 的方式",而是 "Go 让 epoll 屈服于 goroutine 调度的方式"。
一句话总结全文 :epoll 负责感知 I/O 就绪(fd 级、内核级),netpoll 负责把就绪翻译成"哪个 G 可以恢复了"(G 级),GMP 负责真正把那个 G 调度到 CPU 上跑------这就是 Go 高并发网络模型的完整三层翻译链。