Nginx的access_log每天产生几百万行,绝大多数运维团队对它的利用方式是:出了故障之后上去grep。
这相当于有一台24小时运转的心电图仪,但只在人已经倒下之后才去看回放。
实际上,access_log里有三类信号是可以实时监控并主动告警的:
- 5xx错误率------后端在崩,但用户还没大面积投诉之前你就能知道
- 请求耗时分布------接口在变慢,还没到完全超时但已经在退化
- 请求频率异常------某个IP在疯狂请求,可能是爬虫也可能是攻击前兆
我们在给一个电商客户做运维时,就靠access_log的5xx告警在凌晨3点发现了后端服务OOM------比用户投诉早了40分钟,比APM告警(因为采样率设了10%,漏掉了)早了15分钟。
下面是完整方案,从log_format设计到告警规则,直接能用。
一、前提:标准化log_format(不标准的日志没法监控)
很多Nginx还在用默认的combined格式,这个格式最大的问题是没有请求耗时字段------你连哪个请求慢都看不出来。
1.1 推荐的log_format配置
nginx
# /etc/nginx/nginx.conf
http {
# 标准化日志格式(包含所有监控所需字段)
log_format monitor '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'$request_time $upstream_response_time '
'$upstream_addr $upstream_status';
access_log /var/log/nginx/access.log monitor;
error_log /var/log/nginx/error.log warn;
}各字段说明:
| 字段 | 含义 | 监控用途 |
|---|---|---|
$status |
HTTP状态码 | 5xx/4xx统计 |
$request_time |
请求总耗时(秒) | 慢请求检测 |
$upstream_response_time |
后端响应耗时 | 区分Nginx慢还是后端慢 |
$upstream_status |
后端返回状态码 | 后端故障定位 |
$body_bytes_sent |
响应体大小 | 带宽异常检测 |
$remote_addr |
客户端IP | 异常IP检测 |
1.2 按域名分文件(多站点场景)
nginx
server {
server_name api.example.com;
access_log /var/log/nginx/api_access.log monitor;
}
server {
server_name www.example.com;
access_log /var/log/nginx/www_access.log monitor;
}分文件的好处:每个服务独立统计,告警时直接知道哪个服务出问题。
二、整体架构:日志采集→统计→告警
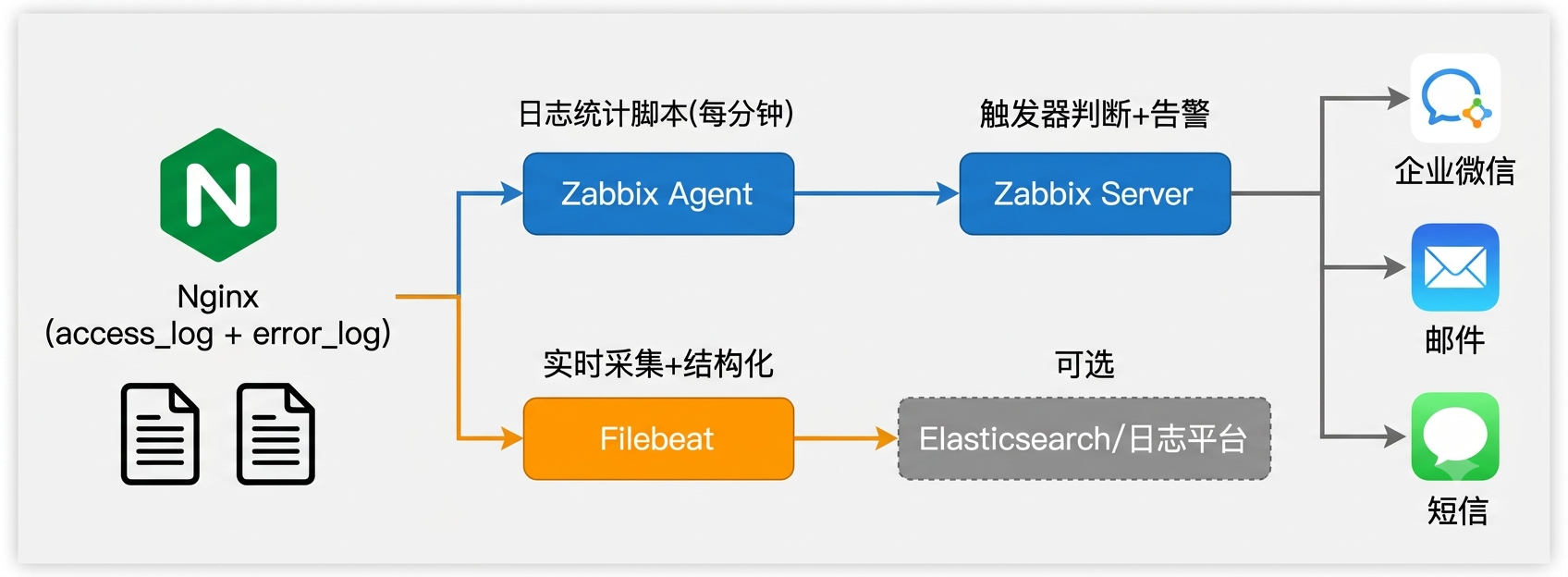
方案选型说明:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Zabbix Agent + 脚本 | 轻量、无额外组件 | 统计逻辑在脚本里 | 中小规模(<20台Nginx) |
| Filebeat + ES + 告警 | 实时性好、查询灵活 | 需要维护ES集群 | 大规模/已有ELK |
| 两者结合 | 告警走Zabbix(成熟)、查询走ES | 双链路维护成本 | 推荐(兼顾告警+排查) |
本文重点讲Zabbix Agent + 统计脚本这条路(轻量、落地快、90%场景够用),Filebeat采集配置附在最后作为扩展。
三、核心实现:Zabbix Agent自定义监控项
3.1 日志统计脚本
这个脚本每分钟跑一次,统计过去1分钟内access_log的各项指标:
bash
#!/bin/bash
# /etc/zabbix/scripts/nginx_log_monitor.sh
# 用途:解析Nginx access_log,输出过去1分钟的统计指标
# 被Zabbix Agent的UserParameter调用
LOG_FILE="${1:-/var/log/nginx/access.log}"
METRIC="${2}"
# 获取1分钟前的时间戳(用于过滤日志行)
ONE_MIN_AGO=$(date -d '1 minute ago' '+%d/%b/%Y:%H:%M' 2>/dev/null || \
date -v-1M '+%d/%b/%Y:%H:%M') # 兼容Linux和macOS
# 提取最近1分钟的日志(基于时间戳前缀匹配)
CURRENT_MIN=$(date '+%d/%b/%Y:%H:%M')
RECENT_LOGS=$(awk -v t1="$ONE_MIN_AGO" -v t2="$CURRENT_MIN" \
'$0 ~ t1 || $0 ~ t2' "$LOG_FILE")
case "$METRIC" in
total_requests)
echo "$RECENT_LOGS" | wc -l | tr -d ' '
;;
status_5xx)
echo "$RECENT_LOGS" | awk '{print $9}' | grep -c '^5[0-9][0-9]$'
;;
status_4xx)
echo "$RECENT_LOGS" | awk '{print $9}' | grep -c '^4[0-9][0-9]$'
;;
status_2xx)
echo "$RECENT_LOGS" | awk '{print $9}' | grep -c '^2[0-9][0-9]$'
;;
slow_requests)
# request_time > 3秒的请求数量($11是request_time字段位置)
echo "$RECENT_LOGS" | awk '$11 > 3.0 {count++} END {print count+0}'
;;
avg_request_time)
# 平均请求耗时(毫秒)
echo "$RECENT_LOGS" | awk '$11 ~ /^[0-9]/ {sum+=$11; count++} END {
if(count>0) printf "%.0f", sum/count*1000; else print 0}'
;;
p95_request_time)
# P95请求耗时(毫秒)
echo "$RECENT_LOGS" | awk '$11 ~ /^[0-9]/ {print $11}' | sort -n | \
awk '{a[NR]=$1} END {idx=int(NR*0.95); if(idx>0) printf "%.0f", a[idx]*1000; else print 0}'
;;
top_ip_count)
# 单IP最高请求数
echo "$RECENT_LOGS" | awk '{print $1}' | sort | uniq -c | sort -rn | head -1 | awk '{print $1}'
;;
bandwidth_mb)
# 出流量(MB)
echo "$RECENT_LOGS" | awk '{sum+=$10} END {printf "%.2f", sum/1024/1024}'
;;
error_log_count)
# error_log最近1分钟的error/crit/alert行数
ERROR_LOG="${LOG_FILE/access/error}"
if [[ -f "$ERROR_LOG" ]]; then
awk -v t1="$ONE_MIN_AGO" -v t2="$CURRENT_MIN" \
'$0 ~ t1 || $0 ~ t2' "$ERROR_LOG" | grep -c -E '\[(error|crit|alert)\]'
else
echo 0
fi
;;
*)
echo "Usage: $0 <log_file> <metric>"
echo "Metrics: total_requests|status_5xx|status_4xx|status_2xx|slow_requests|avg_request_time|p95_request_time|top_ip_count|bandwidth_mb|error_log_count"
exit 1
;;
esac部署:
bash
# 放到Zabbix脚本目录
chmod +x /etc/zabbix/scripts/nginx_log_monitor.sh
# 确保zabbix用户能读取Nginx日志
usermod -aG adm zabbix # Debian/Ubuntu
# 或者
setfacl -m u:zabbix:r /var/log/nginx/access.log3.2 Zabbix Agent配置
ini
# /etc/zabbix/zabbix_agentd.d/nginx_log.conf
# Nginx access_log 监控项
UserParameter=nginx.log[*],/etc/zabbix/scripts/nginx_log_monitor.sh $1 $2
# 使用示例:
# nginx.log[/var/log/nginx/access.log,total_requests] → 过去1分钟总请求数
# nginx.log[/var/log/nginx/access.log,status_5xx] → 过去1分钟5xx数量
# nginx.log[/var/log/nginx/access.log,slow_requests] → 过去1分钟慢请求数
# nginx.log[/var/log/nginx/api_access.log,status_5xx] → API服务的5xx(多站点)重启Agent生效:
bash
systemctl restart zabbix-agent
# 本地验证
zabbix_agentd -t 'nginx.log[/var/log/nginx/access.log,total_requests]'
# 期望输出:nginx.log[/var/log/nginx/access.log,total_requests] [t|1234]3.3 Zabbix Server侧配置监控项
在Zabbix Web界面为Nginx主机添加监控项(或做成模板批量应用):
yaml
# Template: Template_Nginx_Log_Monitor
# 监控项列表
items:
- name: "Nginx - 每分钟总请求数"
key: nginx.log[/var/log/nginx/access.log,total_requests]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - 每分钟5xx错误数"
key: nginx.log[/var/log/nginx/access.log,status_5xx]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - 每分钟4xx错误数"
key: nginx.log[/var/log/nginx/access.log,status_4xx]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - 慢请求数(>3s)"
key: nginx.log[/var/log/nginx/access.log,slow_requests]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - 平均响应时间(ms)"
key: nginx.log[/var/log/nginx/access.log,avg_request_time]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - P95响应时间(ms)"
key: nginx.log[/var/log/nginx/access.log,p95_request_time]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - 单IP最高请求数/分钟"
key: nginx.log[/var/log/nginx/access.log,top_ip_count]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s
- name: "Nginx - 每分钟出流量(MB)"
key: nginx.log[/var/log/nginx/access.log,bandwidth_mb]
type: ZABBIX_AGENT
value_type: FLOAT
delay: 60s
- name: "Nginx - error_log错误数/分钟"
key: nginx.log[/var/log/nginx/access.log,error_log_count]
type: ZABBIX_AGENT
value_type: UNSIGNED
delay: 60s四、5类异常模式告警规则
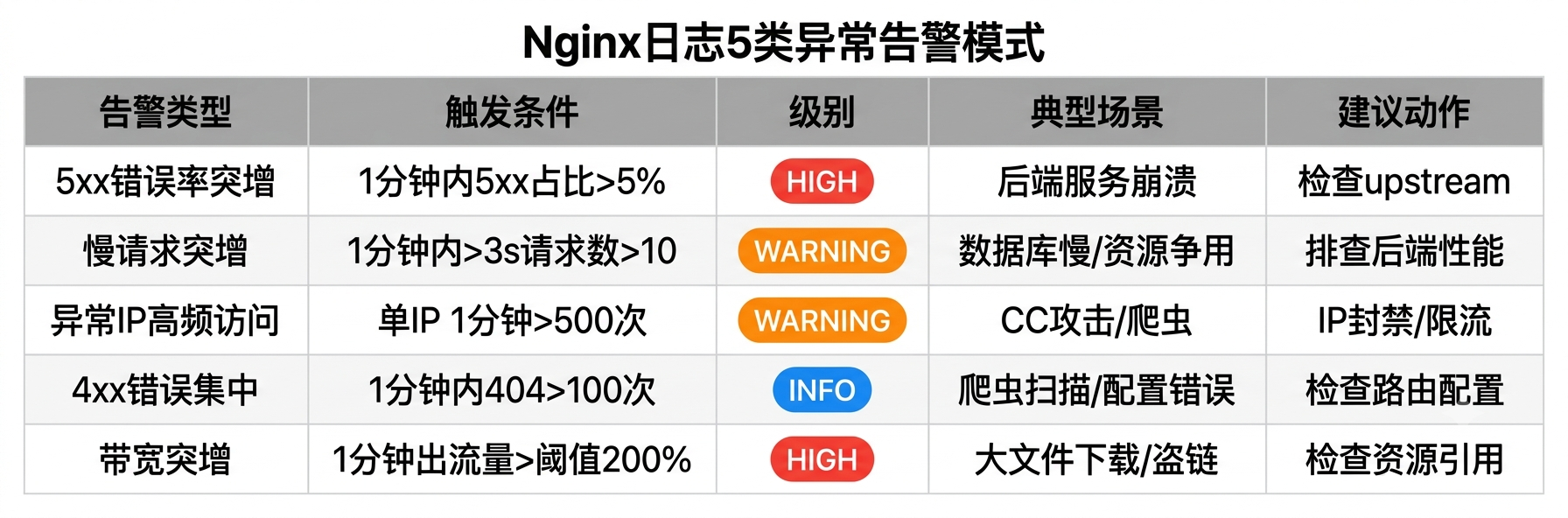
4.1 告警一:5xx错误率突增
这是最高优先级告警------5xx意味着后端返回了服务端错误,通常是服务崩溃、OOM、数据库连接池耗尽。
yaml
# 触发器1:5xx绝对数量
trigger:
name: "Nginx 5xx错误突增({HOST.NAME})"
expression: "last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,status_5xx])>20"
severity: HIGH
description: "过去1分钟5xx错误数超过20次"
# 触发器2:5xx比率(避免低流量误报)
trigger:
name: "Nginx 5xx错误率>5%({HOST.NAME})"
expression: >
last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,status_5xx]) /
last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,total_requests]) > 0.05
and
last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,total_requests]) > 100
severity: HIGH
description: "5xx占比超5%且请求总量>100(排除低流量时段干扰)"为什么要"绝对值+比率"双条件?
只看绝对值:凌晨流量低的时候,3个5xx就报警(可能就是某个爬虫触发的)。
只看比率:高峰期5xx有100个但比率才1%不报警(实际上100个用户已经受影响了)。
建议:高峰期用绝对值兜底,低谷期用比率触发。
4.2 告警二:慢请求突增
yaml
# 触发器:慢请求数量
trigger:
name: "Nginx慢请求突增(>3s请求超10个/分钟)({HOST.NAME})"
expression: "last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,slow_requests])>10"
severity: WARNING
description: "过去1分钟超过3秒的请求数>10个"
# 触发器:P95响应时间
trigger:
name: "Nginx P95响应时间>2s({HOST.NAME})"
expression: "last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,p95_request_time])>2000"
severity: WARNING
description: "P95响应时间超过2000ms"
# 触发器:P95持续恶化(连续3个周期)
trigger:
name: "Nginx P95持续恶化(连续3分钟>1.5s)({HOST.NAME})"
expression: "min(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,p95_request_time],3m)>1500"
severity: HIGH
description: "P95响应时间连续3分钟>1500ms,服务持续退化"4.3 告警三:异常IP高频访问
yaml
trigger:
name: "单IP请求频率异常(>500次/分钟)({HOST.NAME})"
expression: "last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,top_ip_count])>500"
severity: WARNING
description: "某个IP在过去1分钟请求超过500次,可能是CC攻击或恶意爬虫"
trigger:
name: "单IP请求频率严重异常(>2000次/分钟)({HOST.NAME})"
expression: "last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,top_ip_count])>2000"
severity: HIGH
description: "某个IP请求>2000次/分钟,疑似攻击"收到这个告警后的自动化响应脚本(可配成Zabbix Action):
bash
#!/bin/bash
# /etc/zabbix/scripts/auto_block_ip.sh
# 自动封禁高频IP(配合Zabbix Action触发)
LOG_FILE="/var/log/nginx/access.log"
THRESHOLD=2000
BLOCK_DURATION=3600 # 封禁1小时
# 找出超过阈值的IP
CURRENT_MIN=$(date '+%d/%b/%Y:%H:%M')
BAD_IPS=$(awk -v t="$CURRENT_MIN" '$0 ~ t {print $1}' "$LOG_FILE" | \
sort | uniq -c | sort -rn | awk -v th="$THRESHOLD" '$1>th {print $2}')
for ip in $BAD_IPS; do
# 使用iptables临时封禁
if ! iptables -C INPUT -s "$ip" -j DROP 2>/dev/null; then
iptables -A INPUT -s "$ip" -j DROP
echo "$(date) Blocked $ip (will unblock after ${BLOCK_DURATION}s)" >> /var/log/zabbix/blocked_ips.log
# 定时解封
(sleep $BLOCK_DURATION && iptables -D INPUT -s "$ip" -j DROP) &
fi
done4.4 告警四:4xx集中爆发
yaml
trigger:
name: "Nginx 404集中爆发(>100次/分钟)({HOST.NAME})"
expression: "last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,status_4xx])>100"
severity: INFORMATION
description: "过去1分钟404超过100次,可能是爬虫扫描路径或配置变更导致路由失效"4.5 告警五:出流量突增
yaml
trigger:
name: "Nginx出流量突增(>正常值200%)({HOST.NAME})"
expression: >
last(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,bandwidth_mb]) >
avg(/Template_Nginx_Log_Monitor/nginx.log[/var/log/nginx/access.log,bandwidth_mb],1h) * 2
severity: HIGH
description: "当前分钟出流量超过最近1小时平均值的2倍,可能有大文件下载/盗链/异常抓取"五、告警通知模板(企业微信Webhook示例)
告警内容不能只是"Nginx有5xx"------值班人员需要知道哪个服务、什么时候开始、当前多严重。
python
#!/usr/bin/env python3
# /etc/zabbix/alertscripts/wechat_nginx_alert.py
# Zabbix告警通知脚本 - 企业微信机器人
import sys
import json
import urllib.request
WEBHOOK_URL = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=YOUR_KEY"
def send_alert(subject, message):
# 解析Zabbix传入的参数
alert_data = {
"msgtype": "markdown",
"markdown": {
"content": f"""## ⚠️ Nginx告警
> **{subject}**
{message}
**处理建议**:
1. 检查`nginx -t`配置是否正常
2. 查看upstream后端服务状态
3. `tail -100 /var/log/nginx/error.log` 看错误详情
4. 若为攻击,检查WAF/限流规则"""
}
}
req = urllib.request.Request(
WEBHOOK_URL,
data=json.dumps(alert_data).encode('utf-8'),
headers={'Content-Type': 'application/json'}
)
urllib.request.urlopen(req)
if __name__ == "__main__":
send_alert(sys.argv[1], sys.argv[2])六、进阶:Filebeat采集配置(大规模场景)
如果Nginx台数超过20台,或者需要日志查询(而不仅仅是告警),推荐加一条Filebeat采集链路:
yaml
# /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
log_type: nginx_access
env: production
# 解析log_format中的字段
processors:
- dissect:
tokenizer: '%{client_ip} - %{user} [%{timestamp}] "%{method} %{url} %{http_version}" %{status} %{bytes} "%{referer}" "%{user_agent}" %{request_time} %{upstream_time} %{upstream_addr} %{upstream_status}'
field: "message"
target_prefix: "nginx"
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
fields:
log_type: nginx_error
env: production
multiline:
pattern: '^\d{4}/\d{2}/\d{2}'
negate: true
match: after
output.elasticsearch:
hosts: ["http://es-server:9200"]
indices:
- index: "nginx-access-%{+yyyy.MM.dd}"
when.equals:
fields.log_type: "nginx_access"
- index: "nginx-error-%{+yyyy.MM.dd}"
when.equals:
fields.log_type: "nginx_error"七、实际效果和避坑
我们部署这套方案半年,几个数据:
| 指标 | 部署前 | 部署后 |
|---|---|---|
| 5xx发现时间 | 用户投诉后(平均45分钟) | 1分钟内告警 |
| 慢请求发现 | 周例会看APM报表 | 实时告警+趋势追踪 |
| CC攻击响应 | 运维手动发现封IP | 自动检测+自动封禁 |
| 故障定位时间 | 需要登录机器grep日志 | 看Zabbix图表直接定位时间段 |
踩坑记录
坑1:日志轮转导致统计中断
Nginx默认用logrotate每天切割日志,切割后access.log变成空文件,统计脚本读到0。
解决:
bash
# /etc/logrotate.d/nginx 中确保使用copytruncate而不是rename
/var/log/nginx/*.log {
daily
rotate 14
compress
delaycompress
copytruncate # 关键:截断而非重命名,脚本不会读到空文件
notifempty
}坑2:高并发下awk统计脚本本身变慢
日志量大(每分钟>10万行)时,每分钟全量awk一次access.log会消耗较多CPU。
解决:改用增量读取------记录上次读取的offset,只处理新增部分:
bash
# 使用logtail2(Zabbix官方推荐的增量日志读取工具)
OFFSET_FILE="/tmp/nginx_access.offset"
NEW_LINES=$(logtail2 -f "$LOG_FILE" -o "$OFFSET_FILE")
echo "$NEW_LINES" | awk '{print $9}' | grep -c '^5[0-9][0-9]$'坑3:时区问题导致统计偏移
Nginx日志时间戳用的是服务器本地时区,如果date命令和Nginx时区不一致,过滤会错位。
解决:统一用UTC或确保系统时区和Nginx一致。
bash
# 确认时区一致
date +%Z # 系统时区
grep -i timezone /etc/nginx/nginx.conf # Nginx通常跟系统走八、和运维体系的打通
单纯的Nginx日志告警只是"发现问题"的第一步。如果告警发出来没人跟进、没有记录、下次同样的问题还是靠人肉排查,那这套监控就只完成了一半。
我们实际项目里把Nginx告警接到了冠服云EMS平台------告警触发后自动创建事件工单,工单里带有告警时间段的日志快照链接(Zabbix Graph URL),值班人员打开工单就能看到"什么时候开始的、当时的5xx数量曲线、哪些IP在访问"。处理完之后工单关闭自动归档到知识库,下次同类告警触发时工单里会关联历史处理记录。整个链路是:Nginx日志→Zabbix告警→EMS工单→处理→闭环归档,不需要人记着"上次这种情况是怎么处理的"。
小结
Nginx日志监控不需要复杂架构,核心就三步:
- 标准化log_format :必须有
$request_time和$upstream_response_time,否则慢请求和后端故障区分不了 - 轻量统计+精准告警:Zabbix Agent + 一个shell脚本就能实现5类核心告警模式,不需要ELK
- 告警规则要分层:绝对值兜底+比率触发+持续性确认,三层过滤避免误报
一台Nginx跑起来之后,再用Zabbix模板批量克隆到所有Nginx节点------配置一次,覆盖所有。
站内链接:
CSDN-44(Redis监控):https://blog.csdn.net/weixin_70758133/article/details/161310134?spm=1011.2415.3001.5331
CSDN-46(告警升级):https://blog.csdn.net/weixin_70758133/article/details/161418720?spm=1011.2415.3001.5331