一.可变参数模版
1.什么是可变参数模版
在 C 语言中,如果想实现参数个数不固定的函数,可以使用:

或者:

这里的 ... 表示参数个数不固定。
但是 C 风格可变参数有很多缺点:
类型不安全
编译器无法检查参数类型
必须依赖格式字符串
所以 C++11 提供了:
可变参数模板
能够做到:
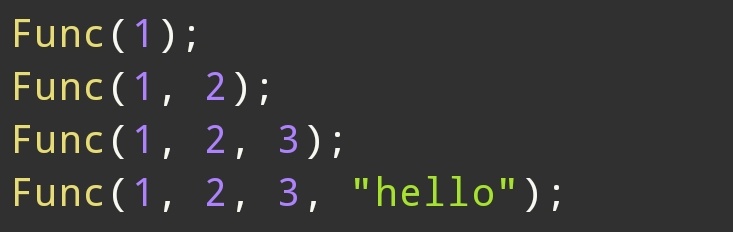
参数个数任意
2. 基本语法
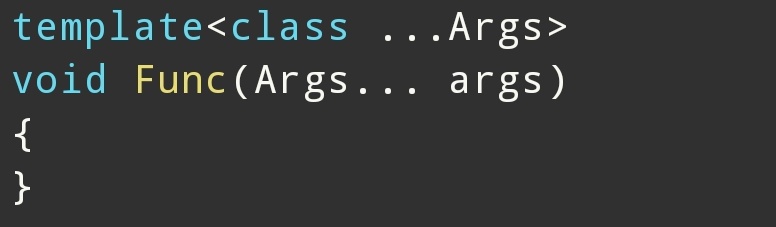
这里有两个包:

是模版参数包

是函数参数包
例如:

编译器推导:

于是函数变成:

3. 什么叫参数包
模板参数包

表示:

可以包含:

任意多个类型。
例如:
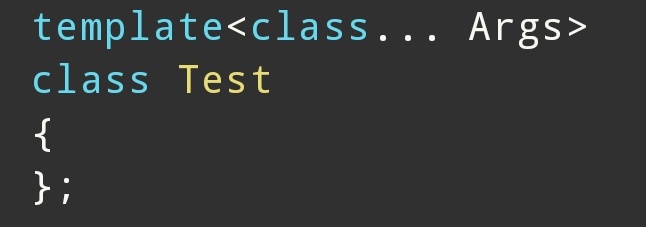
实例化:

这里:

分别是:
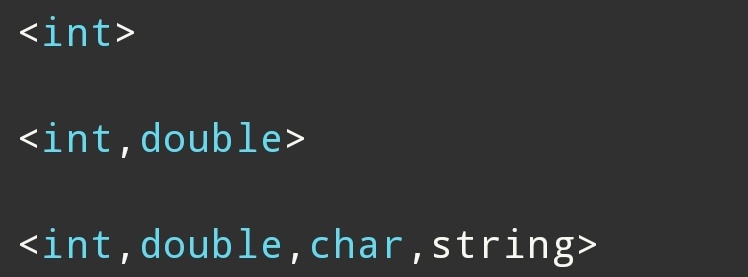
函数参数包

表示:

是多个函数参数。
例如:

推导:

函数实际变成:
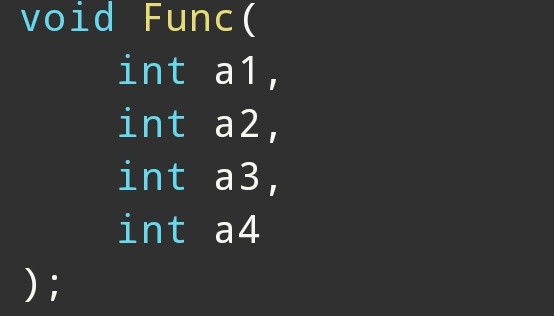
4.三种写法
第一种:值传递
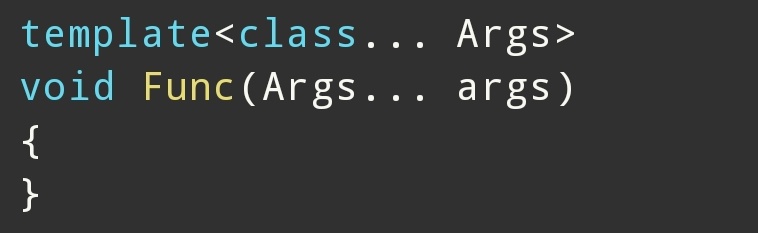
例如:

推导:

实例化:

会发生拷贝
第二种:左值引用
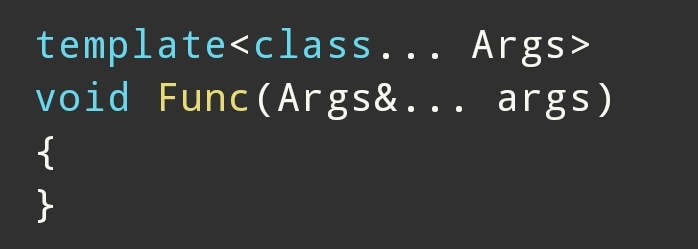
例如:
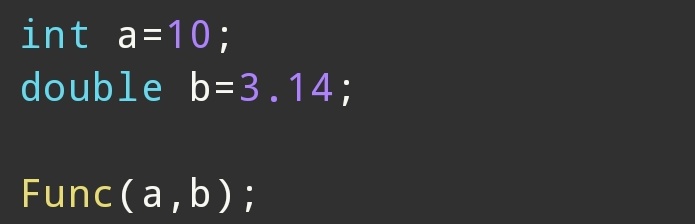
推导:

实例化:

只能接收左值
第三种:万能引用
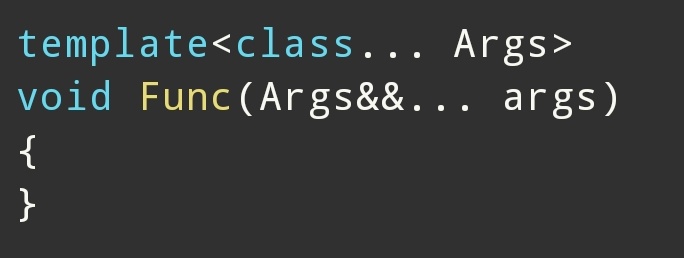
例如:

推导:

引用折叠:

变成:

调用:

推导:

得到:

所以:

能够同时接收:
左值
右值
这就是完美转发的基础。
5.sizeof...(Args)
1.sizeof...运算符计算参数包中的参数个数

表示:
模板参数包数量
例如:
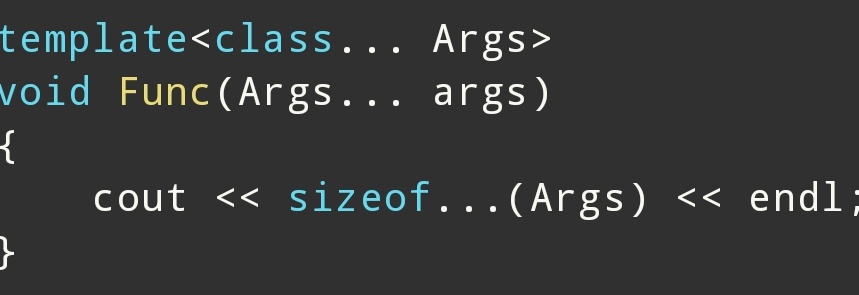
调用:

输出: 0
调用:

输出: 1
调用:

输出: 3
2.统计函数参数包

调用:

输出: 5
完整示例

运行结果:

5.包扩展
除了能计算参数个数,我们能做的唯⼀的事情就是扩展它
什么叫包扩展
例如:
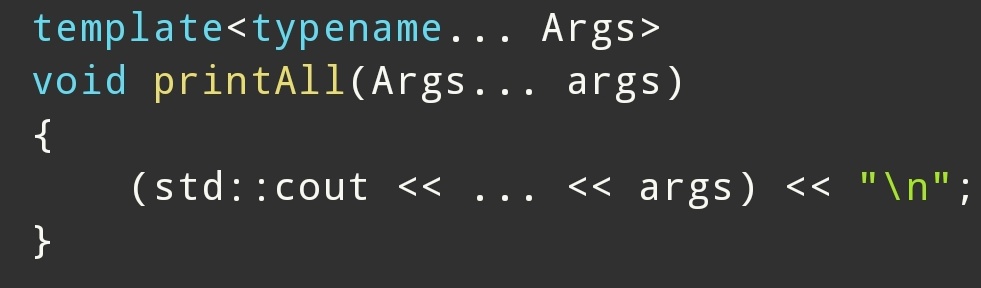
这里Args... args 是一个参数包
(std::cout << ... << args) 就是一个 包扩展
意思:
把 args 中每个参数拿出来
按照模式 (std::cout << arg) 依次处理
扩展后得到一条完整的表达式
例如:

底层等价于:

包扩展的语法

模式(Pattern)可以是任何表达式,通常包含参数包的一个元素
省略号 ... 表示"把参数包依次套用模式"
在 C++11 没有折叠表达式之前,我们用递归函数展开参数包:

调用:

等价于:

扩展规则
1.每个元素都应用模式
例如 (func(args), ...) 中每个参数都调用 func
2.模式可以是任意表达式
不仅限于函数调用,还可以用操作符、模板实例化等
3.扩展顺序
从左到右依次展开
复杂的包扩展

这里发生了 两个操作:
右值/左值完美转发
参数包展开
底层等价于:

所以 C++ 可以直接把参数包展开成函数的多个实参。
6.empalce系列接⼝
C++98 时代容器主要使用:

例如:

执行过程:

相当于:
需要:
构造一次
拷贝一次(或移动一次)
C++11 新增:

直接把构造参数传进去。
容器内部:

直接在容器空间构造对象。
少一次临时对象。
所以效率更高。
push_back 和 emplace_back 对比
push_back
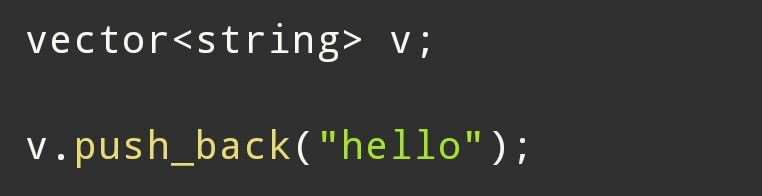
实际上:


emplace_back

 相当于
相当于

少一步
emplace_back 的核心实现
假设 list 节点:
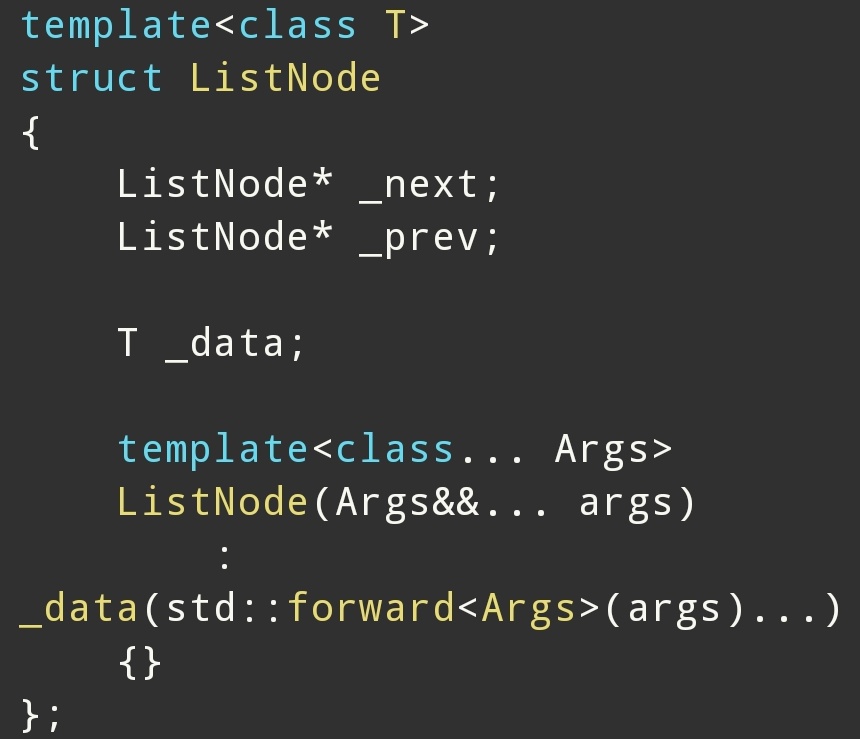
关键:

直接调用 T 的构造函数
例如:

最终变成:

即:

直接构造
二.新的类功能
1.默认的移动构造和移动赋值
C++98 默认成员函数
C++98 下,每个类都有 6 个默认成员函数(如果你没写的话,编译器会帮你生成):

C++11 新增成员函数
C++11 在原来的 6 个基础上新增 2 个:

移动构造和移动赋值生成规则:
1. 条件生成
编译器 会自动生成默认移动构造和移动赋值,前提是:
你没有手动实现:
析构函数
拷贝构造函数
拷贝赋值运算符
也就是如果你手动实现了上述任意一个,编译器就 不生成默认移动函数。
注意:只要你写了移动构造或移动赋值,编译器就不会再生成拷贝构造和拷贝赋值。
2. 默认移动构造函数行为
假设类:

编译器生成默认移动构造:

规则:
内置类型成员:直接按字节拷贝(int, double 等)
自定义类型成员:
如果该成员类有移动构造函数 → 调用它
如果没有移动构造函数 → 调用拷贝构造函数
3.默认移动赋值运算符行为

规则和移动构造一样:
内置类型按值赋
自定义类型有移动赋值 → 调用它
自定义类型没有移动赋值 → 调用拷贝赋值
2.defult和delete
1.=default
作用:告诉编译器请帮我生成这个默认版本的函数

例如:
 等价于:
等价于:

但是=default表示:
使用编译器生成的默认实现,而不是自己写的实现
为什么需要 =default?
例如:

因为你自己写了拷贝构造
编译器认为你已经接管对象管理了
于是移动构造不会自动生成

就不会存在
如果你又想保留移动构造
可以写:

这样就告诉编译器:
虽然我写了拷贝构造
但是移动构造仍然帮我生成
=delete
作用:禁止某个函数使用

例如:
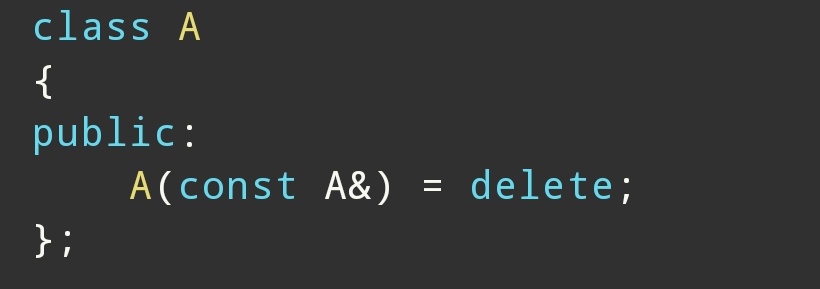
表示禁止拷贝构造
为什么需要 =delete?
C++98时代想禁止拷贝
必须这样写:

只声明不实现,然后放 private。
如果别人写:

则编译错误
但是这种写法很麻烦。
而且错误信息不直观。
C++11:

直接表达:这个类不允许拷贝
更清晰。
三.lambda
1.lambda表达式语法
Lambda 本质
Lambda 是一个匿名函数对象
与普通函数不同:
可以定义在函数内部
可以直接捕获外部作用域变量
类型没有名字,所以一般用 auto 或模板参数来接收

Lambda 基本语法

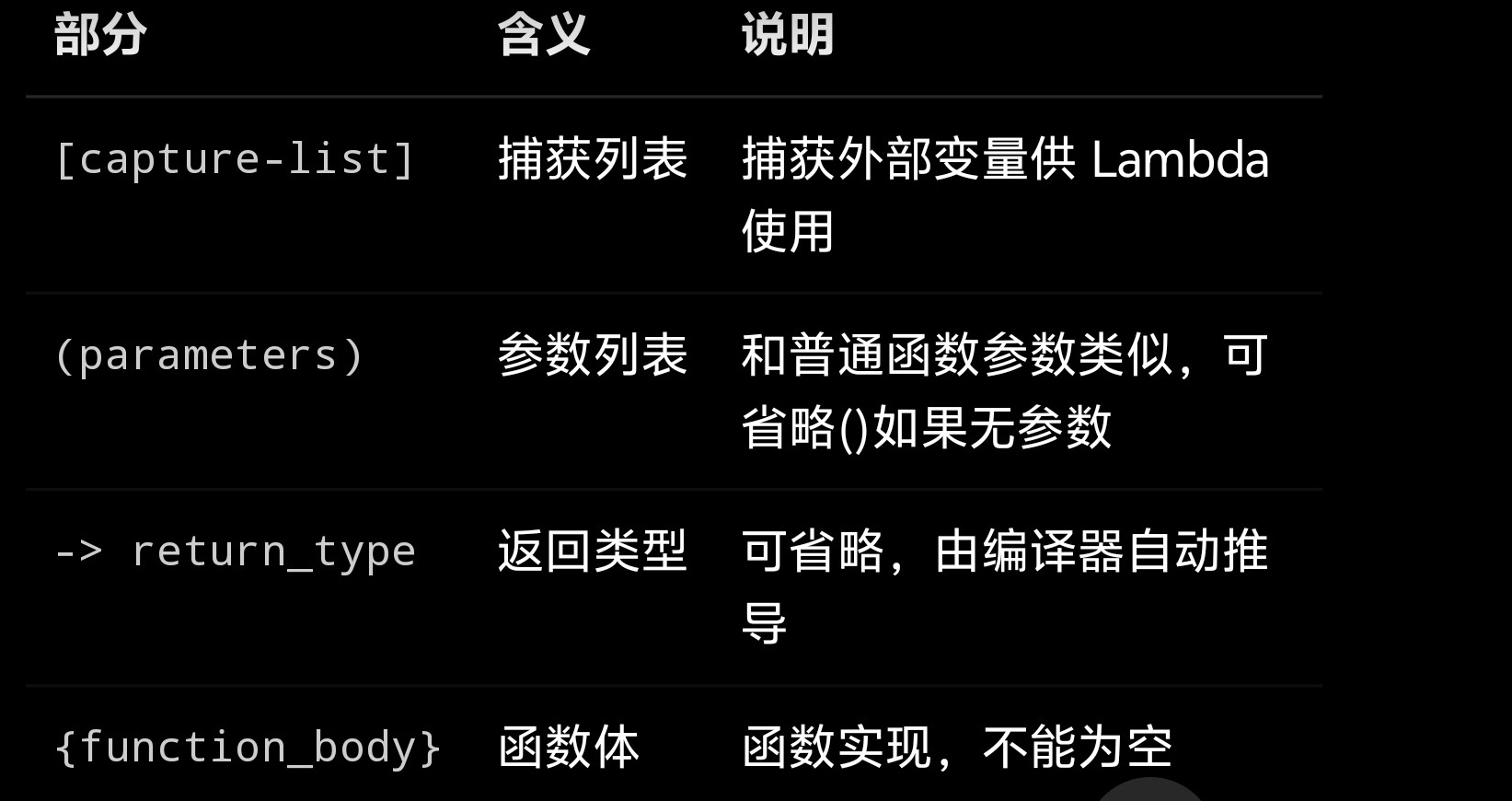
捕获列表
捕获外部变量供 Lambda 使用
语法:

捕获列表为空 [] 也不能省略,表示不捕获任何外部变量。
示例:

a被复制到 Lambda 内部b直接引用外部变量
参数列表
- 与普通函数参数列表类似
- 可以省略
()如果没有参数

返回类型
- 可以显示声明返回类型,也可以省略
- 当返回值类型复杂或 Lambda 有多个 return 时,最好显式指定

如果返回类型明确,编译器可以自动推导,可省略:

函数体
- 内部可以使用:
- Lambda 参数
- 捕获的外部变量
- 函数体不能为空
{}也不能省略
示例:
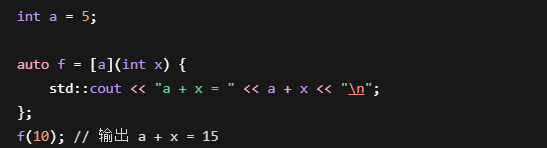
2.捕捉列表
为什么需要捕捉

编译报错:

因为:Lambda 本质是一个独立的函数对象
它默认只能访问:
- 自己的参数
- 自己内部定义的变量
不能直接访问外部局部变量。
所以:

必须先捕捉。
显式捕捉
1.值捕捉
输出:10
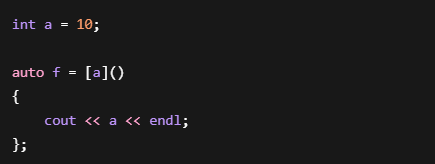
可以理解成:
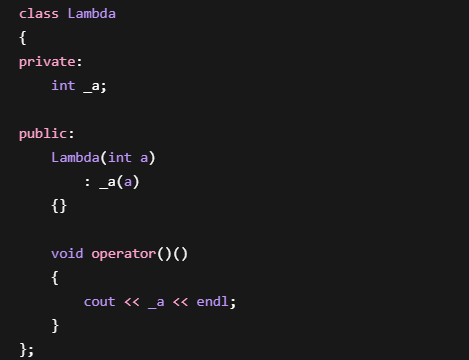
Lambda 内部保存了一份副本。
2. 引用捕捉
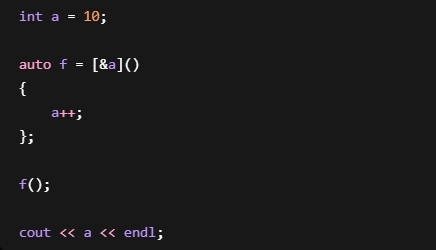
输出:11
因为Lambda内部保存的是a的引用
相当于:

3. 多变量捕捉

表示:

隐式捕捉
1. =
全部值捕捉
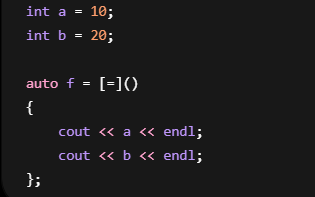
等价于:

注意:
编译器只捕捉实际使用到的变量。
例如:
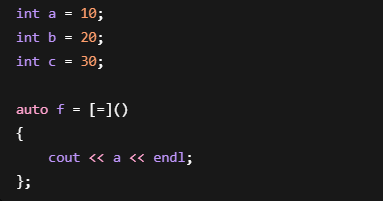
实际上只会捕捉a
2. \&
全部引用捕捉

等价于:

混合捕捉
大部分变量按值
某个变量按引用
1.=, \&x
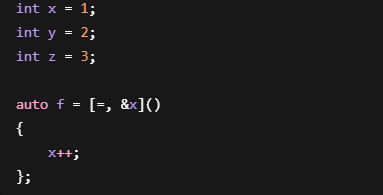
表示:

2.\&, x, y
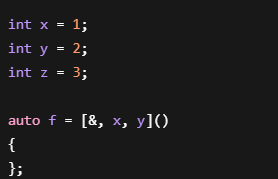
表示:

3.Lambda 到底能捕捉谁?

可以捕捉
局部变量:

不需要捕捉
全局变量:

直接:
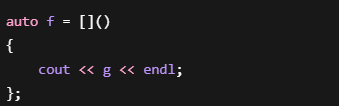
合法
不需要捕捉
静态局部变量:

直接:
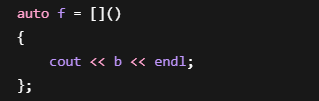
合法
全局位置定义 Lambda
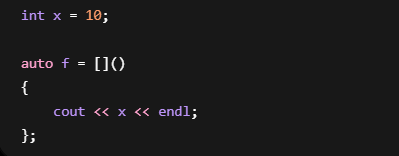
合法
但:
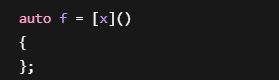
非法
因为全局作用域没有局部变量可捕捉
所以全局位置定义Lambda捕捉列表必须为空
默认情况下不能修改值捕捉变量

报错
因为值捕捉后,变成:
注意:

默认带:

所以:

不允许
4.mutable
如果想修改值捕捉的副本:
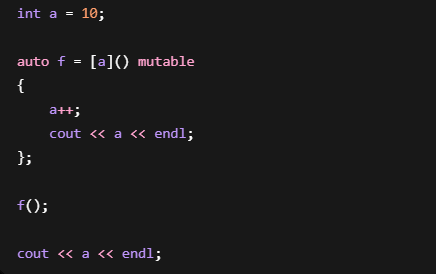
输出:11
10
过程:
外部a = 10
复制一份给Lambda
Lambda里的a变11
外面的a仍然10
mutable 要求括号不能省略
正常:

无参数时:

也可以
但加了 mutable:

错误
必须写:
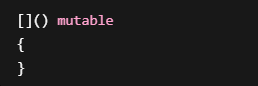
因为语法规定:
mutable 必须放在参数列表后面
**5.**lambda的应用
实际上 Lambda 出现之前,STL 里大量地方都只能用:
- 函数指针
- 仿函数(函数对象)
而这两种方式都有缺点。
1. 函数指针太麻烦
例如:
函数指针:

特别复杂一点:

很多人看不懂
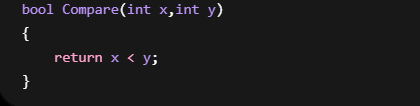
2. 仿函数需要定义类
例如:

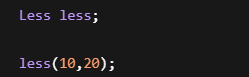
为了写一个比较函数:
居然要定义一个类
代码非常多
Lambda解决问题
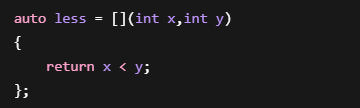
直接就能用:

非常简单
STL排序中的应用
之前:

Lambda

Lambda最大的优势:捕捉变量
函数指针做不到。
例如:

想排序:按照离100最近排序
仿函数:
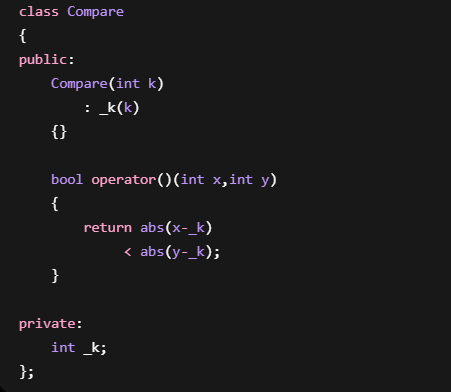
调用:

Lambda:

直接捕捉:

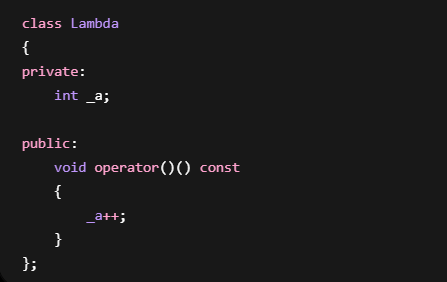
6.Lambda原理
lambda 的原理和范围for很像
编译器最终会展开成:
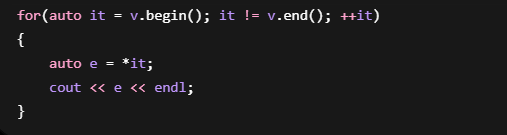
实际上根本不存在范围for
只是编译器帮你翻译了。
Lambda也一样。
例如:
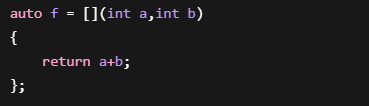
编译后:
根本不存在Lambda,编译器会生成一个仿函数类。
最简单的Lambda
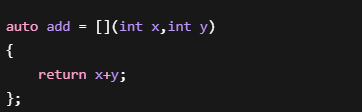
编译器大致生成:

然后:

所以:

实际上变成:

Lambda为什么没有类型?

为什么必须用:

因为编译器生成的类名是内部名字:
例如:
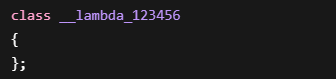
或者:
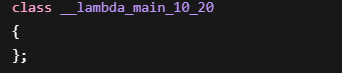
具体名字编译器决定。
用户看不到。
所以:

根本写不了。
只能:
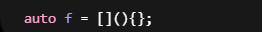
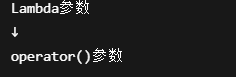
Lambda参数去哪了?
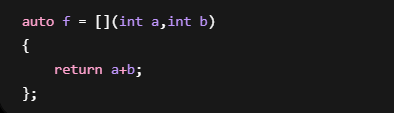
Lambda部分:

会变成:


所以:
Lambda返回值去哪了?

编译器生成:

所以:

捕捉列表到底去哪了?
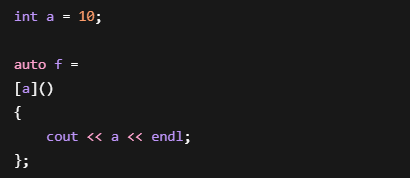
编译器生成:

创建Lambda对象:

所以:

实际上就是

成员变量