谷歌这把「香蕉」太狠了!何恺明等引爆视觉Transformer时刻 - 智源社区
谷歌再发香蕉!通用视觉模型Vision Banana刷新2D/3D多项SOTA,何恺明谢赛宁参与
NLP领域早期的质疑:能生成文本的模型,真的理解语言吗?
AI发展到现在,LLM用事实证明,生成预训练本身就是最好的理解训练。 语言模型在生成文本的过程中,自然学会了语法、语义、推理、知识。
那视觉领域呢?
过去的视觉研究,大多走判别式学习路线,监督判别学习、对比学习、自举学习、自编码......几乎都不属于生成式建模。 分类、检测、分割、深度估计各搞一套架构、各用一批数据,模型专精但不通用。
而Vision Banana的回答是:
图像生成模型早就悄悄学会了理解视觉世界,只是没人教它怎么把理解结果输出出来。一个能画出极其逼真图像的模型,天然就「理解」了图像里的结构、层次和语义关系。
该模型基于图像生成底座 Nano Banana Pro ,通过轻量级指令微调,证明了"生成即理解"的假设,将分割、深度估计等传统感知任务统一转化为 RGB 图像生成任务。
过去的尝试大多是在模型内部硬塞多个任务头,本质上还是「多个专用模块共享一个骨干网络」。Vision Banana的做法更彻底------它连任务头都不要了,所有输出都是像素。Vision Banana把输出统一到了最底层,反而获得了最大的灵活性。
1、一个模型,统治所有视觉任务
传统计算机视觉的逻辑是「分而治之」。目标检测靠回归框坐标,语义分割靠逐像素分类,图像生成靠噪声去噪。三条技术线各有各的损失函数、各有各的训练流程、各有各的SOTA排行榜。Vision Banana的逻辑完全反过来:不管你问什么视觉问题,答案都是一张图。这背后有一个极其反直觉的发现------强大的生成能力,能反哺理解精度。
2、指令微调
Vision Banana的诞生路径,堪称工程美学的典范。 它不是从零开始烧掉几万张显卡的产物,而是基于基础模型Nano Banana Pro的一次「点睛之笔」。 研究团队采用了一种极度克制、甚至有些反直觉的策略:极低比例的数据混入 。 他们只将一小部分具备「可逆格式」的任务数据,像添加催化剂一样,混入Nano Banana Pro自身的庞大训练集中。 这种轻量级的指令微调(Instruction Tuning),既没有洗掉模型原有的「生成本性」,又成功将模型内部涌现出的生成式表征,精准对齐到了真实的物理世界。
在与母体Nano Banana Pro的正面对决中,Vision Banana在文本生图任务(GenAI-Bench)中获得了53.5%的人类评估胜率,在图像编辑任务(ImgEdit)中获得了47.8%的胜率。

2.1 指令微调 Nano Banana Pro
我们通过在一系列以可逆方式格式化的视觉任务上对基础模型Nano Banana Pro进行指令微调,从而创建了Vision Banana。
具体而言,我们将视觉任务数据以极低的比例混合到Nano Banana Pro自身的训练数据集中。
这一过程使我们能够将模型所生成的潜在表示与可测量的物理几何结构和语义标签进行对齐,从而使我们的通用模型能够被评估并与其他任务特定的专家模型进行比较。
以较低比例混合视觉数据,是一种轻量级的指令微调策略,可确保我们的视觉任务对齐不会降低模型原有的生成先验。
2.2 视觉任务与数据
我们对框架在两个基本的视觉理解类别上进行了评估:二维场景理解与三维结构推理。
二维任务包括参考表达式分割、语义分割和实例分割,共同测试模型将自然语言与对应物体进行关联并进行分割的能力。
对于三维理解,我们专注于单目度量深度估计 和表面法向估计,这些任务需要几何推理以及对物体尺度的内在知识。
为了收集指令微调的数据,我们使用了内部模型对网络爬取的二维图像进行标注,并利用渲染引擎生成的合成数据用于三维任务。关键的是,指令微调混合数据中不包含任何来自我们评估基准的训练数据,以确保我们的结果真实反映模型的通用能力。
3、视觉模型统一
Vision Banana 将一个视觉生成模型作为"基础"模型,并通过指令微调使其根据提示以期望的格式生成视觉输出。
该模型被要求生成RGB图像,这些图像可解码为计算机视觉输出。
此类指令提示和可解码的可视化方案旨在连接并校准视觉生成结果,使其适用于可衡量的基准指标格式。
该策略具有三大主要优势。
- 首先,它通过一个统一的模型支持多种任务------在指令微调后,所有任务共享相同的权重,仅提示部分发生变化。
- 其次,由于指令微调仅用于教会模型如何将计算机视觉输出格式化为RGB,因此所需的新训练数据相对较少。
- 第三,由于输出仅为新的RGB图像,该策略有助于模型保留其原有的图像生成能力。
3.1 2D语义理解
3.1.1 语义分割
为了教导模型听懂指令,并直接「画」出视觉任务的结果,Vision Banana 实行图像化输出解码。例如在语义分割中,提示词会规定「把滑板画成纯黄色 <255, 255, 0>」,模型就会直接生成一张带有颜色掩码的 RGB 图片,随后只需将对应颜色的像素提取出来,就能完美还原出分割结果。

Vision Banana Banana 可根据指令提示进行语义分割,支持多种提示风格。它能够对文本提示中指定的任何内容进行分割,从单个名词到短语均可。该模型能生成具有精细细节的分割掩码,例如示例1(中间)中的猫咪胡须。
我们的方法是开放词汇的:目标类别不受固定集合的限制,可以在提示中动态指定,并附带相应的颜色映射。我们支持多种提示方式,包括自然语言描述(例如:"马卡龙蛋糕用黄色表示")和结构化的JSON映射,颜色可通过命名颜色、十六进制代码或RGB元组指定。在定量评估中,我们对生成的图像进行后处理,将每个像素分配到其目标颜色在RGB空间中最接近的类别。
3.1.2 实例分割
与语义分割不同,实例分割要求模型能够区分属于同一类别的单个对象。例如,如果一张图像包含五只狗,我们期望模型为每只动物生成一个独立的掩码。这给Vision Banana带来了独特挑战:由于实例数量事先未知,我们无法预先为提示中指定特定的颜色。
为解决这一问题,我们仅在提示中提供目标类别和背景颜色,并指示模型为每个独立实例分配唯一且不同的颜色。然后让模型动态地为该类别下的不同实例分配不同的颜色。下图展示了若干定性示例。
Vision Banana Banana 可以逐个类别进行实例分割,并用不同颜色渲染不同的实例。它还能理解细微的语言概念。

3.1.3 参考表达分割
与传统的固定类别分割不同,参照表达分割评估模型根据给定的自然语言描述对象进行分割的能力。该任务要求模型能够理解并推理出自然语言表达中的细微差别,同时捕捉对象之间的复杂关系。

3.2 单目图像的3D三维理解
Vision Banana 可以从二维单目图像推断出三维结构。我们通过两个经典任务来评估这一能力:单目度量深度估计和表面法线估计。
3.2.1 单目度量深度估计
深度估计的目标是从单目图像中生成深度图,其中每个像素的值表示从相机平面到所观察物体的实际物理距离。然而,深度估计本质上是ill-posed问题,因为二维投影会不可避免地丢失关键的三维几何信息。
尽管相机内参是已知的,但是由于缺少多视角设置中可用的视差提示, 单目深度估计更具有挑战性。
在深度学习时代,研究界普遍将深度估计视为一种密集的逐像素监督回归问题,采用专门的网络架构和领域特定的损失函数。大多数SOTA在训练、推理或两者过程中都依赖相机内参。尽管使用内参有助于缓解深度估计固有的歧义性,但也需要专门的模型设计。
Vision Banana基于一个假设:生成建模本身具有寻找模式的特性,能够自然地解决训练目标的歧义性,从而无需依赖这些特殊技术。此外,预训练过程中获得的广泛世界知识,使模型相比针对特定任务的模型具备更强的物体尺寸与距离先验知识。为了使Nano Banana Pro能够以米为单位估计深度,我们指导模型输出一个精心构建的伪彩色深度值可视化图像。
为了将深度图可视化为RGB图片,我们建立了一个映射,将区间 0, ∞) 中的无界深度值与区间  中的有界RGB 值相对应。
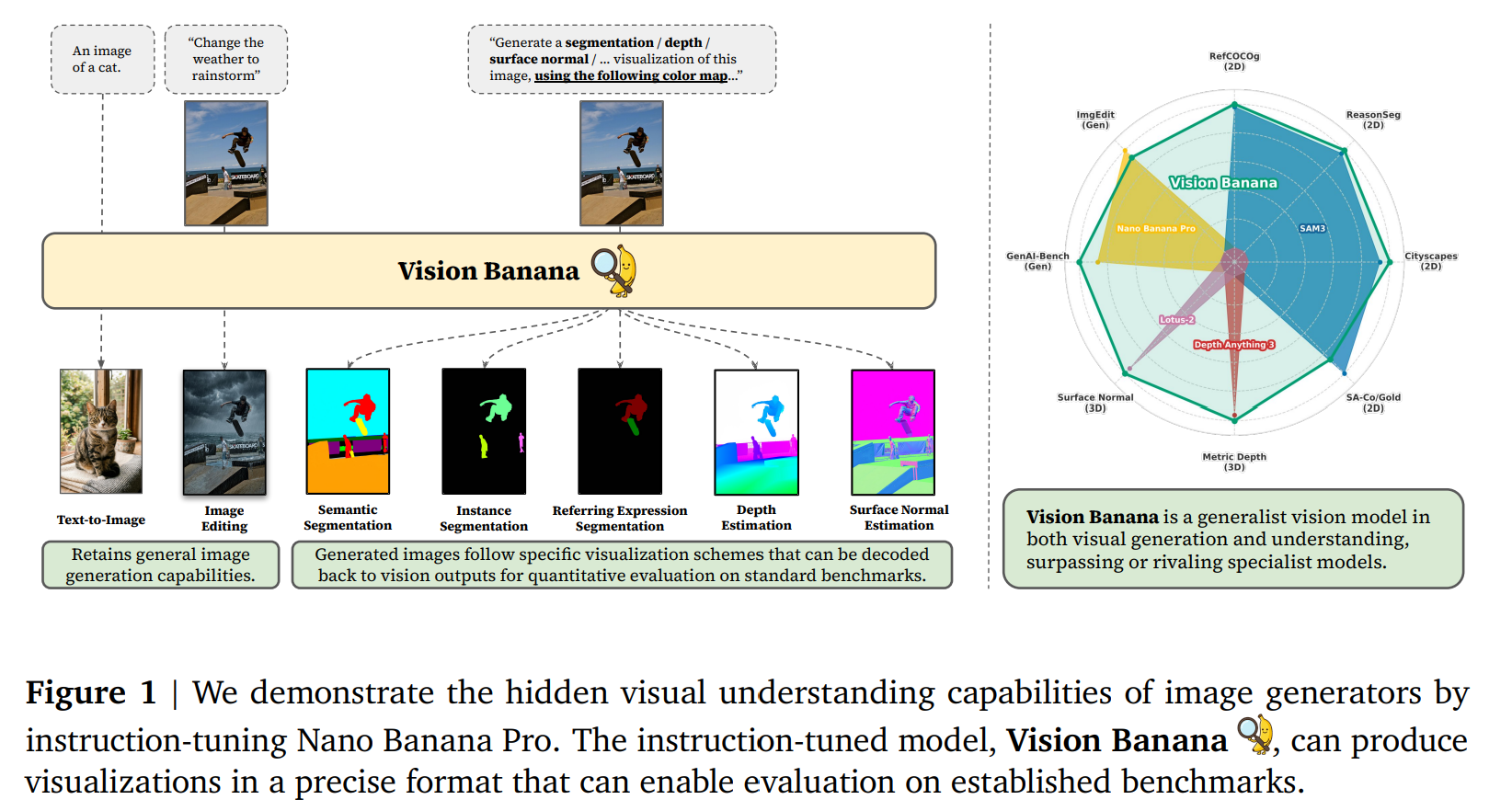
在做 3D 深度估计时,他们则设计了一套严格可逆的数学映射机制(利用幂律变换),将物理世界中从 0 到无穷大的度量深度映射到 RGB 色彩立方体的边缘上。模型输出一张渐变的「伪色彩图」,解码后就能直接换算成精准的物理深度距离。我们将幂变换限制在 < −1 范围内,并重新缩放,使度量距离 d ∈ [0, ∞)) 映射到归一化的距离 [0, 1)。
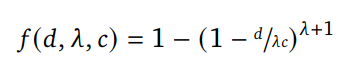
在所有的实验中,形状参数=-3,尺度参数c=10/3。
被用于沿一个分段线性函数进行插值,该函数沿着 RGB 立方体的边缘运行,从黑色到白色,类似于三维希尔伯特曲线的第一次迭代。
在训练过程中,我们将此映射应用于真实深度图,以生成RGB训练目标。在推理时,我们使用逆映射将模型生成的RGB图像解码回度量深度,从而能够在标准深度基准上进行方向评估。为了增强模型在不同颜色表示下的鲁棒性,我们在训练数据中加入了多种替代颜色映射,例如Plasma、Inferno、Viridis以及灰度图。


Vision Banana 在野外进行深度估计。(a)本文作者使用普通手机在金阁寺附近拍摄了一张照片。(b)Vision Banana 生成了深度估计图像。这个 绿色星标位置的深度值解码为13.71米。(c)作者随后使用谷歌地图测量实际距离,结果为12.87米。此时的绝对相对误差约为0.065。
3.2.2 表面法线估计
相比深度,表面法向量的可视化方案则要自然得多。表面法向量由 (x, y, z) 三个分量构成,值域为 -1.0, 1.0,与 RGB 颜色通道天然对齐。研究者采用右手坐标系(+x 向右、+y 向上、+z 朝外),将三个方向分量直接映射为 R、G、B 通道:朝左的表面呈现粉红色调,朝上的呈浅绿色,面向摄像机的呈浅蓝 / 紫色。 这种内在的对齐使得法向量估计几乎无需额外设计,直接沿用生成模型的原生能力即可。
表面法向量估计方面,Vision Banana 在四个公开基准的室内场景平均值上取得最低的均值和中值角度误差,在户外场景上与 Lotus-2 相当。定性对比显示,Vision Banana 生成的法向量图视觉保真度和细节粒度均明显优于 Lotus-2,即使在定量指标略逊的室外数据集(Virtual KITTI 2)上,其视觉质量依然更胜一筹。

3.3 生成能力验证
轻量级指令微调是否会损伤 Nano Banana Pro 原有的图像生成能力? 研究团队在 GenAI-Bench(文字生成图像)和 ImgEdit(图像编辑)两个基准上进行了人类偏好评估,Vision Banana 对 Nano Banana Pro 的胜率分别为 53.5% 和 47.8%(见图 1)。 这一结果清晰地表明,经过指令微调的 Vision Banana 与基础模型的生成能力基本持平,「通晓理解,不忘生成」。
4、展望
2017年,NLP领域经历了从「专用模型时代」到「通用模型时代」的范式切换。
Transformer一统江湖之后,整个领域的研究方式、工程实践、商业逻辑全部重写。 计算机视觉到现在还没完成这个切换。
ViT出来之后,Transformer进了视觉领域,但任务层面的统一一直没有实现。检测、分割、生成,依然是三条独立的技术线。
Vision Banana可能是补上这最后一块拼图的那个模型。
当所有视觉任务都变成「生成像素」,一个直接的后果是:未来的视觉AI不再是「看图识字」的工具,而是具备「视觉想象力」的系统。 它通过在生成空间内推理,来应对现实世界中无穷无尽的变体。 它背后的野心则是构建一个统一的视觉世界模型(World Model)。
Gemini统一了文本和多模态理解,Vision Banana统一了视觉理解和生成。两者如果接通,一个真正意义上的「世界模型」的雏形就出现了------既能理解世界,又能想象世界。