Python 学习第 33 天。
一、PyQuery 模块简介
PyQuery 是一个类似于 jQuery 的 Python 库,用于解析和操作 HTML 文档。它支持 CSS 选择器,提供了强大的 HTML 元素选择、属性操作和节点遍历功能,非常适合网页数据提取和爬虫开发。
二、PyQuery 的安装
在代码块中输入:
pip install pyquery运行结果末端部分出现以下文字,表明安装成功:
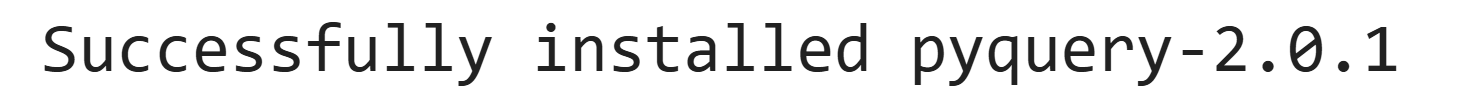
三、PyQuery 的使用
以以下 HTML 文档为例:
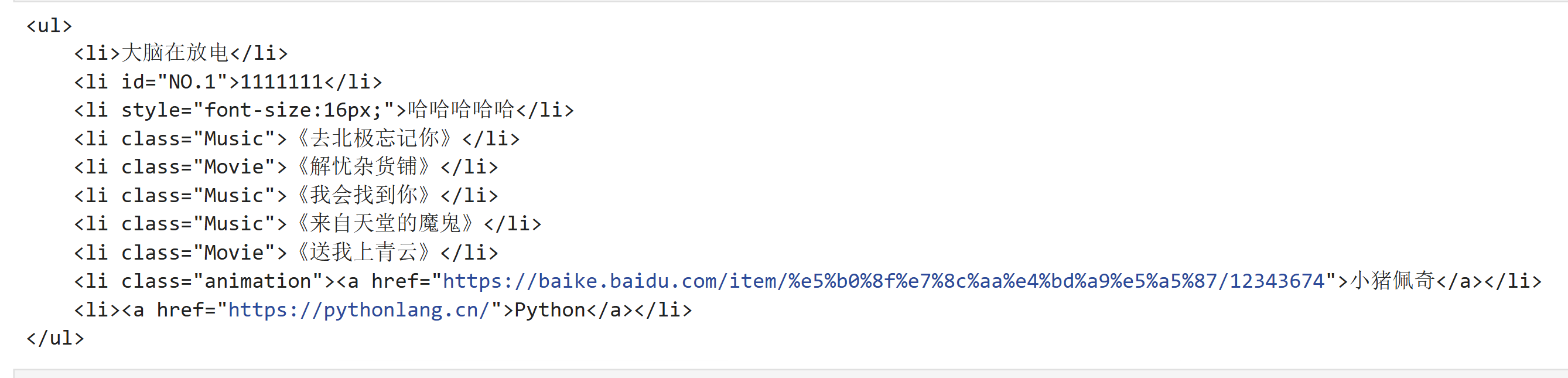
html = """
<ul>
<li>大脑在放电</li>
<li id = "NO.1">1111111</li>
<li style = "font-size:16px;">哈哈哈哈哈</li>
<li class = "Music">《去北极忘记你》</li>
<li class = "Movie">《解忧杂货铺》</li>
<li class = "Music">《我会找到你》</li>
<li class = "Music">《来自天堂的魔鬼》</li>
<li class = "Movie">《送我上青云》</li>
<li class = "animation"><a href = "https://baike.baidu.com/item/%e5%b0%8f%e7%8c%aa%e4%bd%a9%e5%a5%87/12343674">小猪佩奇</a></li>
<li><a href = "https://pythonlang.cn/">Python</a></li>
</ul>
"""1. 导入包
from pyquery import PyQuery2. 初始化对象
格式:变量名 = PyQuery(HTML文档所在的对象名)
oj = PyQuery(html)3. 获取标签
格式:初始化后的变量名("选择器"),选择器相关内容参考本专栏第 30 篇《Python 爬虫 · HTML 与 CSS 基础》中的 CSS 部分。
(1) 填入标签选择器
代码示例1:获取标签,当文档中该标签只有一个时,会将其存入列表中返回
oj("ul")运行结果1:\
代码示例2:获取标签,当文档中该标签有多个,也会将其作为元素存入列表中并返回。值得注意的是,如果标签中具有 ID 或 Class 属性,其在存储过程中就会被标注出来。
oj("li")运行结果2:\
代码示例3:获取标签中的具体内容
result_1 = oj("ul")
print(result_1)运行结果3:
代码示例4:
result_2 = oj("li")
print(result_2)运行结果4:

代码示例5:链式操作
result_3 = oj("li")("a")
print(result_3)运行结果5:

(2) 填入后代选择器
代码示例:
result_4 = oj("li a")
print(result_4)运行结果:

(3) 填入 ID 选择器
代码示例:
result_5 = oj("#NO\.1")
print(result_5)运行结果:<li id="NO.1">1111111</li>
注意:因为**.** 在 Python 中有特殊含义,常作为连接符连接某个对象与其子对象。所以,要将它当作字符串输出时,需要在前边加上转义字符 \。
(4) 填入类选择器
代码示例:
result_6 = oj(".Music")
print(result_6)运行结果:

4. 常用函数
(1) .attr():
格式:初始化后的对象名("选择器").attr("属性名"),获取标签中的属性值
result_7 = oj("li a").attr("href")
result_8 = oj("li").attr("style")
print(result_7)
print(result_8)运行结果:
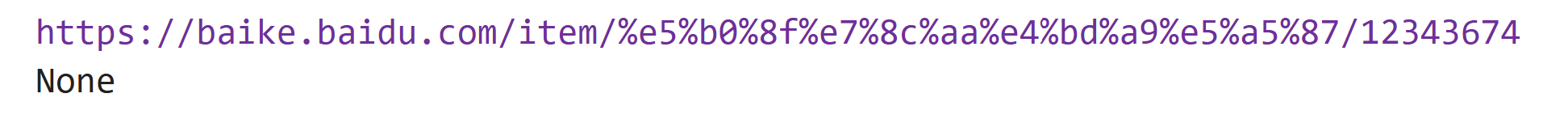
**注意:**如果选择器对应着多个标签,attr() 函数只会默认返回第一个标签中所含的该属性。
如果想返回全部的属性值,可以用 for 循环遍历:
for i in oj("li"):
print(oj(i).attr("style"))运行结果:

(2) .text()
格式:初始化后的对象名("选择器").text(),获取标签中包含的所有内容文本
代码示例:
result_9 = oj("li a").text()
result_10 = oj("li").text()
print(result_9)
print(result_10)运行结果:

5. 增、改、删
(1) .atter()
格式:初始化后的对象名("用于定位的标签").after("""需要在定位标签后增加的标签及内容""")
代码示例:
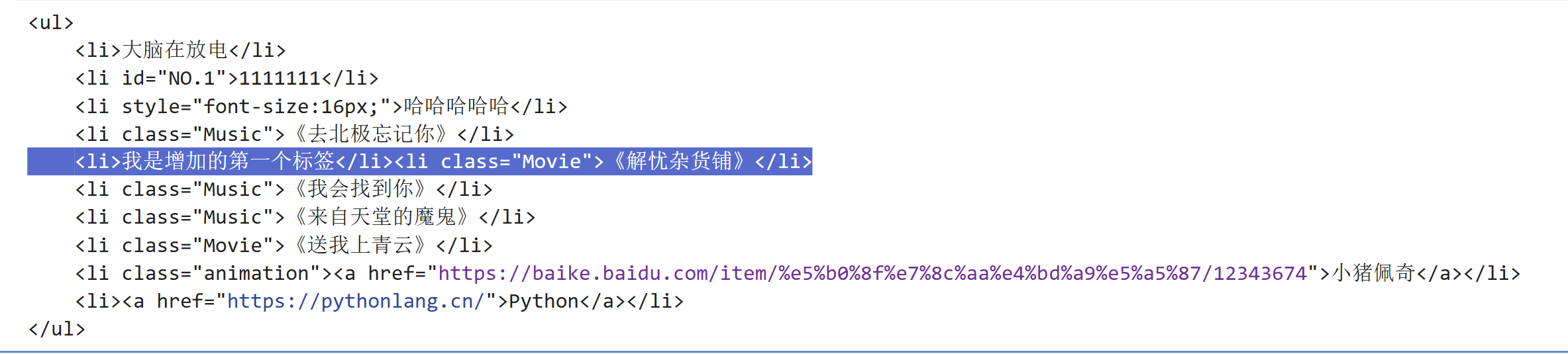
oj("li.Music").after("""<li>我是增加的第一个标签</li>""")
print(oj)运行结果:
(2) .append()
格式:初始化后的对象名("用于定位的标签").append("""需要在定位标签中的内容后方增加的标签及内容""")
代码示例:
oj("li#NO\.1").append("""<p>南波万</p>""")
print(oj)运行结果:

(3) .attr()
格式1:初始化后的对象名("需要修改属性的标签").attr("需要修改的属性名", "修改后的属性值")
代码示例:
oj("li.Music").attr("class", "TOP")
print(oj)运行结果:

格式2:初始化后的对象名("需要增加属性的标签").attr("需要增加的属性名", "属性值")
代码示例:
oj("li#NO\.1").attr("style", "font-size = 21px")
print(oj)运行结果:
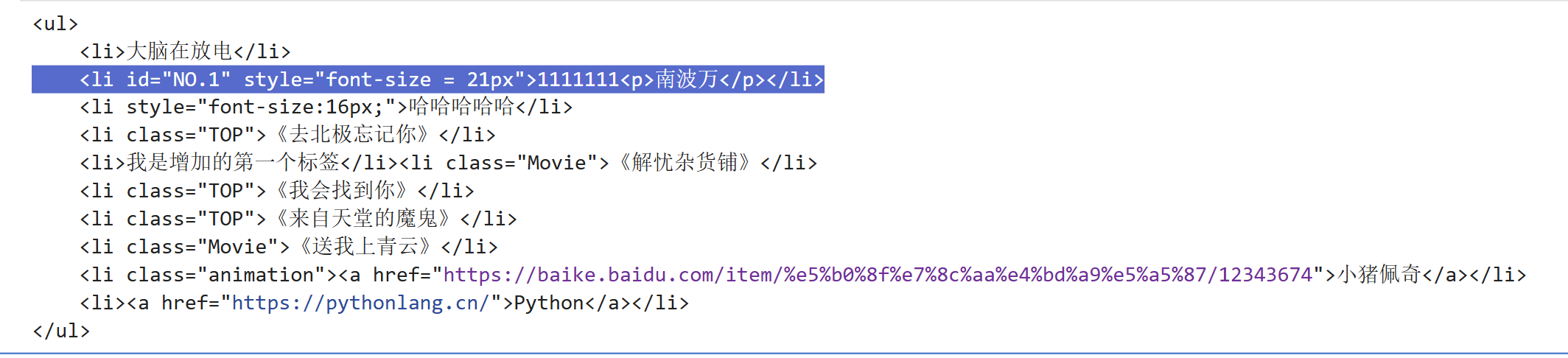
(4) .remove()
格式:初始化后的对象名("需要删除的标签").remove()
代码示例:
oj("li.Movie").remove()
print(oj)运行结果:
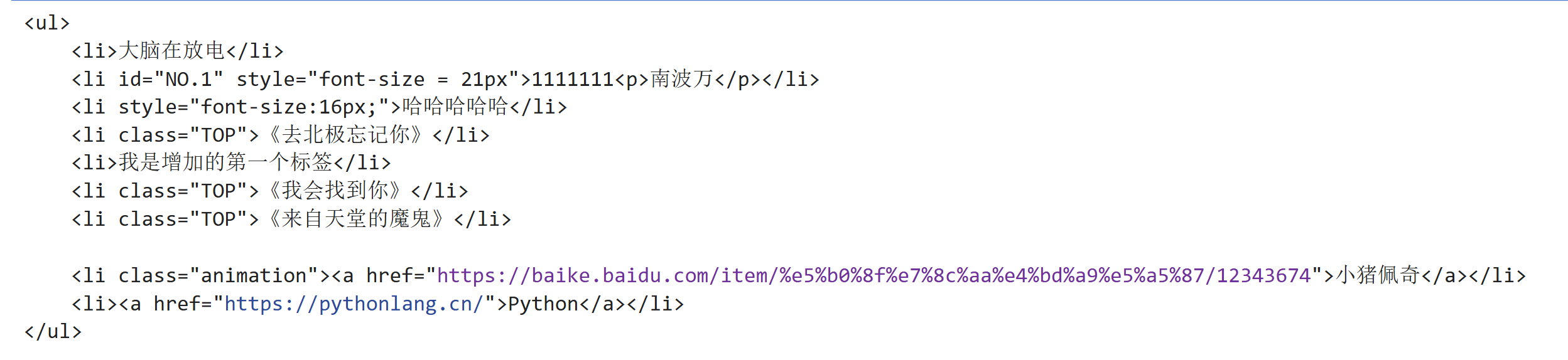
(5) .remove_attr()
格式:初始化后的对象名("需要删除的标签").remove_attr("属性名")
代码示例:
oj("li#NO\.1").remove_attr("style")
print(oj)运行结果:
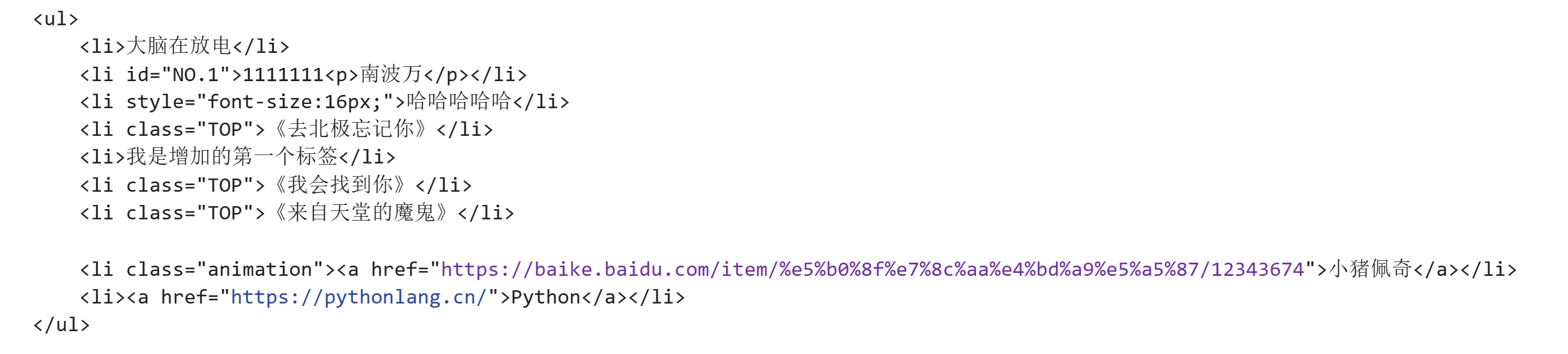
总结规律:
1. 对于标签的定位可以用链式结构 对象名()(),甚至多个括号检索出来,也可以用后代标签的形式直接查询;
2. 获取文本内容用 text() 函数;
3, 与属性相关用 attr() 函数,且默认对查找到的第一个元素做操作;
4.after() 用于在标签外的后方增加标签,append() 用于在标签内内容的后方增加标签,且都默认对查找到的第一个标签进行操作;
5. remove() 相关的函数是删除符合条件的所有元素。